时间序列预测——Tensorflow.Keras.LSTM
1、测试数据下载
https://datamarket.com/data/set/22w6/portland-oregon-average-monthly-bus-ridership-100-january-1973-through-june-1982-n114#!ds=22w6&display=line
2、LSTM预测
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import datetime
from dateutil.relativedelta import relativedelta df = pd.read_csv("C:\\Users\\\Administrator\\Downloads\\portland-oregon-average-monthly-.csv",
index_col=0) df.index.name=None #将index的name取消
df.reset_index(inplace=True)
df.drop(df.index[114], inplace=True)
start = datetime.datetime.strptime("1973-01-01", "%Y-%m-%d") #把一个时间字符串解析为时间元组
date_list = [start + relativedelta(months=x) for x in range(0,114)] #从1973-01-01开始逐月增加组成list
df['index'] =date_list
df.set_index(['index'], inplace=True)
df.index.name=None
df.columns= ['riders']
df['riders'] = df.riders.apply(lambda x: int(x)*100)
df.riders.plot(figsize=(12,8), title= 'Monthly Ridership', fontsize=14)
plt.show() data = df.iloc[:,0].tolist() def data_processing(raw_data, scale=True):
if scale == True:
return (raw_data-np.mean(raw_data))/np.std(raw_data)#标准化
else:
return (raw_data-np.min(raw_data))/(np.max(raw_data)-np.min(raw_data))#极差规格化
TIMESTEPS = 12 '''样本数据生成函数'''
def generate_data(seq):
X = []#初始化输入序列X
Y= []#初始化输出序列Y
'''生成连贯的时间序列类型样本集,每一个X内的一行对应指定步长的输入序列,Y内的每一行对应比X滞后一期的目标数值'''
for i in range(len(seq) - TIMESTEPS - 1):
X.append([seq[i:i + TIMESTEPS]])#从输入序列第一期出发,等步长连续不间断采样
Y.append([seq[i + TIMESTEPS]])#对应每个X序列的滞后一期序列值
return np.array(X, dtype=np.float32), np.array(Y, dtype=np.float32) '''对原数据进行尺度缩放'''
data = data_processing(data) '''将所有样本来作为训练样本'''
train_X, train_y = generate_data(data) '''将所有样本作为测试样本'''
test_X, test_y = generate_data(data) from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import LSTM model = Sequential()
model.add(LSTM(16, input_shape=(train_X.shape[1], train_X.shape[2])))
model.add(Dense(train_y.shape[1]))
model.compile(loss='mse', optimizer='adam', metrics=['accuracy'])
model.fit(train_X, train_y, epochs=1000, batch_size=len(train_X), verbose=2, shuffle=False) #scores = model.evaluate(train_X, train_y, verbose=0)
#print("Model Accuracy: %.2f%%" % (scores[1] * 100)) result = model.predict(train_X, verbose=0) '''自定义反标准化函数'''
def scale_inv(raw_data,scale=True):
data1 = df.iloc[:, 0].tolist()
if scale == True:
return raw_data*np.std(data1)+np.mean(data1)
else:
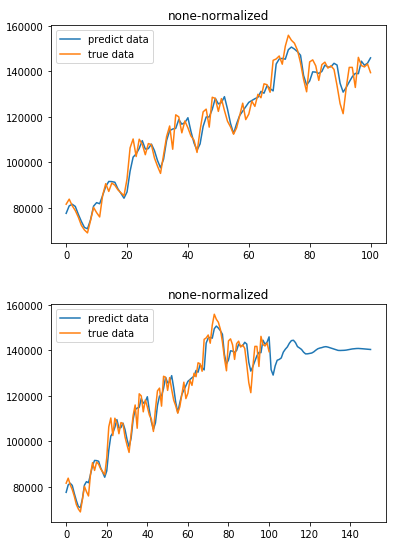
return raw_data*(np.max(data1)-np.min(data1))+np.min(data1) '''绘制反标准化之前的真实值与预测值对比图'''
plt.figure()
plt.plot(scale_inv(result), label='predict data')
plt.plot(scale_inv(test_y), label='true data')
plt.title('none-normalized')
plt.legend()
plt.show() def generate_predata(seq):
X = []#初始化输入序列X
X.append(seq)
return np.array(X, dtype=np.float32) datalist = data.tolist()
pre_result = []
for i in range(50):
pre_x = generate_predata(datalist[len(datalist) - TIMESTEPS:])
#pre_x = pre_x[np.newaxis,:,:]
pre_x = np.reshape(pre_x, (1, 1, TIMESTEPS))
pre_y = model.predict(pre_x)
pre_result.append(pre_y.tolist()[0])
datalist.append(pre_y.tolist()[0][0])
all = result.tolist()
all.extend(pre_result)
'''绘制反标准化之前的真实值与预测值对比图'''
plt.figure()
plt.plot(scale_inv(np.array(all)), label='predict data')
plt.plot(scale_inv(test_y), label='true data')
plt.title('none-normalized')
plt.legend()
plt.show()
3、运行效果

时间序列预测——Tensorflow.Keras.LSTM的更多相关文章
- Kesci: Keras 实现 LSTM——时间序列预测
博主之前参与的一个科研项目是用 LSTM 结合 Attention 机制依据作物生长期内气象环境因素预测作物产量.本篇博客将介绍如何用 keras 深度学习的框架搭建 LSTM 模型对时间序列做预测. ...
- 使用tensorflow的lstm网络进行时间序列预测
https://blog.csdn.net/flying_sfeng/article/details/78852816 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog. ...
- 基于 Keras 用 LSTM 网络做时间序列预测
目录 基于 Keras 用 LSTM 网络做时间序列预测 问题描述 长短记忆网络 LSTM 网络回归 LSTM 网络回归结合窗口法 基于时间步的 LSTM 网络回归 在批量训练之间保持 LSTM 的记 ...
- (数据科学学习手札40)tensorflow实现LSTM时间序列预测
一.简介 上一篇中我们较为详细地铺垫了关于RNN及其变种LSTM的一些基本知识,也提到了LSTM在时间序列预测上优越的性能,本篇就将对如何利用tensorflow,在实际时间序列预测任务中搭建模型来完 ...
- Python中利用LSTM模型进行时间序列预测分析
时间序列模型 时间序列预测分析就是利用过去一段时间内某事件时间的特征来预测未来一段时间内该事件的特征.这是一类相对比较复杂的预测建模问题,和回归分析模型的预测不同,时间序列模型是依赖于事件发生的先后顺 ...
- TensorFlow实现时间序列预测
常常会碰到各种各样时间序列预测问题,如商场人流量的预测.商品价格的预测.股价的预测,等等.TensorFlow新引入了一个TensorFlow Time Series库(以下简称为TFTS),它可以帮 ...
- Pytorch循环神经网络LSTM时间序列预测风速
#时间序列预测分析就是利用过去一段时间内某事件时间的特征来预测未来一段时间内该事件的特征.这是一类相对比较复杂的预测建模问题,和回归分析模型的预测不同,时间序列模型是依赖于事件发生的先后顺序的,同样大 ...
- facebook开源的prophet时间序列预测工具---识别多种周期性、趋势性(线性,logistic)、节假日效应,以及部分异常值
简单使用 代码如下 这是官网的quickstart的内容,csv文件也可以下到,这个入门以后后面调试加入其它参数就很简单了. import pandas as pd import numpy as n ...
- tensorflow keras导包混用
tensoboard 导入:导入包注意 否者会报错 :keras FailedPreconditionError: Attempting to use uninitialized value trai ...
随机推荐
- Docker-集群swarm(5)
Docker集群的概念 群集是一组运行Docker并加入集群的计算机.在此之后,您继续运行您习惯使用的Docker命令,但现在它们由群集管理器在群集上执行.群中的机器可以是物理的或虚拟的.加入群组后 ...
- Qt自定义控件大全+designer源码
抽空将自定义控件的主界面全部重写了一遍,采用左侧树状节点导航,看起来更精美高大上一点,后期准备单独做个工具专用每个控件的属性设计,其实qt自带的designer就具备这些功能,于是从qt4的源码中抽取 ...
- python 写入Excel
一.安装xlrd模块: 1.mac下打开终端输入命令: pip install XlsxWriter 2.验证安装是否成功: 在mac终端输入 python 进入python环境 然后输入 imp ...
- Java 中的几个算法
一.冒泡排序.插入排序.希尔排序.快速排序与归并排序 效率概要: 冒泡排序是蛮力法,使用两层嵌套循环,基本效率为 O(n^2) 插入排序是减治法,第一趟排序,最多比较一次,第二趟排序,最多比较两次,以 ...
- 【python】——三级菜单
作业需求: 打印三级菜单 可返回上一级 可随时退出程序 #!/usr/bin/env python # -*- coding:utf-8 -*- #Author: __Json.Zzgx__ menu ...
- export及export default的区别
在JavaScript ES6中,export与export default均可用于导出常量.函数.文件.模块等,你可以在其它文件或模块中通过import+(常量 | 函数 | 文件 | 模块)名的方 ...
- POI操作Excel详解,读取xls和xlsx格式的文件
package org.ian.webutil; import java.io.File; import java.io.FileInputStream; import java.io.FileN ...
- git fork代码并修改胡提交到自己的git仓库
最近在参加阿里天池大数据中间件比赛(毫无头绪,打酱油中).看参赛要求,需要将官网的git工程clone下来,在此基础上做修改后提交到自己的仓库中. 由于以前并没有使用过git,所以差了比较多的资料,做 ...
- 逆向工程之修改关键CALL返回值_破解视频转换专家
1)注册软件随便输入注册名注册码 2)进入软件根目录,发送到PEID查壳 3)发现无壳 4)发送到OD 4.1)右键菜单选择智能搜索 4.2)找到关键信息点注册 4.3)找到关键信息点双击进入汇编,向 ...
- 扫二维码登录实现原理,php版
基础的逻辑图就是这样,但是实际情况还是有几种可能 比如QQ登录,微信登录,微博登录,基本设计都差不多,根据实际情况会有一些差异 问题是,如果设计合理的接口在保证数据的安全性和快速性 设计到的技术不复杂 ...