[MapReduce_add_2] MapReduce 实现年度最高气温统计
0. 说明
编写 MapReduce 程序实现年度最高气温统计
1. 气温数据分析
气温数据样例如下:
++023450FM-+000599999V0202701N015919999999N0000001N9-+99999102001ADDGF108991999999999999999999
++023450FM-+000599999V0202901N008219999999N0000001N9-+99999102001ADDGF104991999999999999999999
++023450FM-+000599999V0209991C000019999999N0000001N9-+99999102001ADDGF108991999999999999999999
++023450FM-+000599999V0201801N008219999999N0000001N9-+99999101831ADDGF108991999999999999999999
++023450FM-+000599999V0201801N009819999999N0000001N9-+99999101761ADDGF108991999999999999999999
对气温数据进行分析可以得出以下的结论
1. 年份的索引为 15-19 ,以此作为 Key
2. 气温的索引为 87-92 ,以此作为 Value
【思路】
在 Map 阶段将原始数据映射成满足要求的 K-V 对,在 Reduce 阶段对相同 Key 的值进行比较,得到最大值
2. 代码编写
[2.1 MaxTempMapper.java]
package hadoop.mr.maxtemp; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /**
* Mapper 类
*/
public class MaxTempMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 将 value 变为 String 格式
String line = value.toString();
// 获得年份
String year = line.substring(15, 19);
// 获得温度
int temp = Integer.parseInt(line.substring(87, 92)); // 存在脏数据 9999,所以要将其过滤
if (temp != 9999) {
// 输出年份与温度
context.write(new Text(year), new IntWritable(temp));
} }
}
[2.2 MaxTempReducer.java]
package hadoop.mr.maxtemp; import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; /**
* Reducer 类
*/
public class MaxTempReducer extends Reducer<Text, IntWritable, Text, DoubleWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
Integer max = Integer.MIN_VALUE; // 得到最大值
for (IntWritable value : values) {
max = Math.max(max, value.get());
} // 输出年份与最大温度
context.write(key, new DoubleWritable(max / 10.0));
}
}
[2.3 MaxTempApp.java]
package hadoop.mr.maxtemp; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /**
* max Temp APP
*/
public class MaxTempApp {
public static void main(String[] args) throws Exception {
// 初始化配置文件
Configuration conf = new Configuration(); // 仅在本地开发时使用
conf.set("fs.defaultFS", "file:///"); // 初始化文件系统
FileSystem fs = FileSystem.get(conf); // 通过配置文件初始化 job
Job job = Job.getInstance(conf); // 设置 job 名称
job.setJobName("max Temp"); // job 入口函数类
job.setJarByClass(MaxTempApp.class); // 设置 mapper 类
job.setMapperClass(MaxTempMapper.class); // 设置 reducer 类
job.setReducerClass(MaxTempReducer.class); // 设置 map 的输出 K-V 类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class); // 设置 reduce 的输出 K-V 类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(DoubleWritable.class); // 新建输入输出路径
Path pin = new Path("E:/file/temp");
Path pout = new Path("E:/test/wc/out"); // 打包后自定义输入输出路径
// Path pin = new Path(args[0]);
// Path pout = new Path(args[1]); // 设置输入路径和输出路径
FileInputFormat.addInputPath(job, pin);
FileOutputFormat.setOutputPath(job, pout); // 判断输出路径是否已经存在,若存在则删除
if (fs.exists(pout)) {
fs.delete(pout, true);
} // 执行 job
job.waitForCompletion(true);
}
}
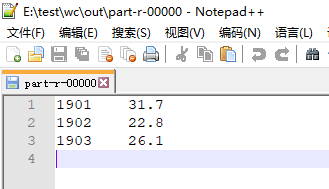
3. 测试
本地模式下运行代码的结果如下
4. 部署到集群上
【4.1 修改代码 MaxTempApp.java】


【4.2 打包程序】


【4.3 运行程序】
开启 Hadoop 集群,然后将 temp 数据文件上传到 HDFS 中,过程略
运行以下命令
hadoop jar myhadoop-1.0-SNAPSHOT.jar hadoop.mr.maxtemp.MaxTempApp /testdata/temp /testdata/out
【查看结果】
命令行下可以看到结果,Web UI 查看 http://s101:8088

[MapReduce_add_2] MapReduce 实现年度最高气温统计的更多相关文章
- [Hive_add_7] Hive 实现最高气温统计
0. 说明 Hive 通过 substr() 函数实现最高气温统计 1. Hive 实现最高气温统计 1.1 思路 将一行文本加载为 String 通过 substr() 函数截取年份和温度 1.2 ...
- MapReduce项目之气温统计
在本博文,我们要学习一个挖掘气象数据的程序.气象数据是通过分布在美国全国各地区的很多气象传感器每隔一小时进行收集,这些数据是半结构化数据且是按照记录方式存储的,因此非常适合使用 MapReduce 程 ...
- [Spark Core] Spark 实现气温统计
0. 说明 聚合气温数据,聚合出 MAX . MIN . AVG 1. Spark Shell 实现 1.1 MAX 分步实现 # 加载文档 val rdd1 = sc.textFile(" ...
- Mapreduce的序列化和流量统计程序开发
一.Hadoop数据序列化的数据类型 Java数据类型 => Hadoop数据类型 int IntWritable float FloatWritable long LongWritable d ...
- P1567 气温统计
P1567 题目描述 炎热的夏日,KC 非常的不爽.他宁可忍受北极的寒冷,也不愿忍受厦门的夏天.最近,他开始研究天气的变化.他希望用研究的结果预测未来的天气. 经历千辛万苦,他收集了连续 N(1≤N≤ ...
- Hadoop工程师面试题(1)--MapReduce实现单表汇总统计
数据源格式描述: 输入t1.txt源数据,数据文件分隔符"*&*",字段说明如下: 字段序号 字段英文名称 字段中文名称 字段类型 字段长度 1 TIME_ID 时间(到时 ...
- [MapReduce_5] MapReduce 中的 Combiner 组件应用
0. 说明 Combiner 介绍 && 在 MapReduce 中的应用 1. 介绍 Combiner: Map 端的 Reduce,有自己的使用场景 在相同 Key 过多的情况下 ...
- 【合集】Hadoop 合集
0. 说明 Hadoop 随笔的目录 1. HDFS 主要内容: [HDFS_1] HDFS 的概念和特性 [HDFS_2] HDFS 的 Shell 操作 [HDFS_3] HDFS 工作机制 [H ...
- Hadoop基础-MapReduce的Combiner用法案例
Hadoop基础-MapReduce的Combiner用法案例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.编写年度最高气温统计 如上图说所示:有一个temp的文件,里面存放 ...
随机推荐
- Oracle 插入时间时 报错:ORA-01861: 文字与格式字符串不匹配 的解决办法
一.写sql的方式插入到Oracle中 往oracle中插入时间 '2007-12-28 10:07:24'如果直接按照字符串方式,或者,直接使用to_date('2007-12-28 10:07: ...
- 解决Android Studio 3.x版本的安装时没有SDK,运行时出现SDK tools错误
好久没更新了,最近手机上的闹钟APP没一个好用的,所以想自己写个. 那Android开发环境搭起来,注意先装好jdk. 1.安装Android Studio google的Android开发网站已经有 ...
- ASP.NET Core 中的 ORM 之 Dapper
目录 Dapper 简介 使用 Dapper 使用 Dapper Contrib 或其他扩展 引入工作单元 Unit of Work 源代码 参考 Dapper 简介 Dapper是.NET的一款轻量 ...
- PHP打印指定日期
打印某一日期的前一天 echo date("Y-m-d",(strtotime("2009-01-01") - 3600*24)); (1)打印明天此时的时间戳 ...
- Tomcat启动时项目重复加载的问题
最近在项目开发测试的时候,发现Tomcat启动时项目重复加载,导致资源初始化两次的问题 导致该问题的原因: 如下图:在Eclipse中将Server Locations设置为“Use Tomcat ...
- Java提高篇之抽象类与接口
接口和内部类为我们提供了一种将接口与实现分离的更加结构化的方法. 抽象类与接口是java语言中对抽象概念进行定义的两种机制,正是由于他们的存在才赋予java强大的面向对象的能力.他们两者之间对抽象概念 ...
- 【学习笔记】深入理解async/await
参考资料:理解javaScript中的async/await,感谢原文作者的总结,本文在理解的基础上做了一点小小的修改,主要为了加深自己的知识点掌握 学完了Promise,我们知道可以用then链来解 ...
- .NET JSON 转换 Error ” Self referencing loop detected for type“
在进行实体转换为Json格式报错如下图: Self referencing loop detected for property 'md_agent' with type 'System.Data.E ...
- Receiver 和 Direct方式的区别
Kafka direct 跟receiver 方式接收数据的区别? Receiver是使用Kafka的高层次Consumer API来实现的.Receiver从Kafka中获取的数据都是存储在Spar ...
- Python全栈学习_day001知识点
今日大纲: . 变量. ***** . 常量.** . 注释.*** . 基础数据类型初识(int,str,bool). ***** . 用户输入 input ***** . 流程控制语句if. ** ...