商店销售预测(回归&随机森林)
目录
一、题目概要
二、导入包和数据集
三、数据处理
四、描述性分析
五、探索性数据分析
六、模型一:线性回归
七、模型2:随机森林
一、题目概要
在Kaggle竞赛中,要求我们应用时间序列预测,根据厄瓜多尔大型杂货零售商Corporación Favorita的数据预测商店销售情况,建立一个模型,准确地预测在不同商店销售的商品的单位销量。准确的预测可以减少与库存过多相关的食物浪费,提高客户满意度。
在六个可用的数据文件中,我们分析了其中的三个,即训练、测试和存储。虽然我们在这个项目中没有研究每日油价或假日事件的影响,但我们希望在这门课之外花更多的时间来深入学习和成长。
在我们的分析中,我们探索了两种不同的时间序列预测模型:线性回归和随机森林。通过准备线性回归的数据,我们发现了一些有趣的见解,包括周末的销售增长,公共部门支付工资时的销售增长,以及11月和12月的销售增长。我们也注意到2014年和2015年的销量大幅下降。这两种增加和减少都可能是由于商店促销、假期、油价或世界事件,我们无法在分析中调查。
对于线性回归,我们删除了没有在该特定商店销售的产品族,对商店进行聚类,并将销售较低的产品分组到一个产品族中。我们调查并去除异常值,并评估训练数据的季节性。
对于随机森林,我们处理分类变量并去除异常值。
线性回归被证明是低效的,表现出指数性质,而随机森林被证明是一个更容易实现的模型。然而,如果没有线性回归的数据处理,我们将无法发现我们所做的洞察,因为随机森林是一个黑盒模型。
我们还包含了一些关于特征重要性、超参数优化和残差图的进一步发现的最终想法。
综上所述,随机森林是预测商店销售额的较好模型。
#This Python 3 environment comes with many helpful analytics libraries installed
#It is defined by the kaggle/python Docker image: https://github.com/kaggle/docker-python
#For example, here's several helpful packages to load
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
#Input data files are available in the read-only "../input/" directory
#For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))
#You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All"
#You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session
/kaggle/input/store-sales-time-series-forecasting/oil.csv
/kaggle/input/store-sales-time-series-forecasting/sample_submission.csv
/kaggle/input/store-sales-time-series-forecasting/holidays_events.csv
/kaggle/input/store-sales-time-series-forecasting/stores.csv
/kaggle/input/store-sales-time-series-forecasting/train.csv
/kaggle/input/store-sales-time-series-forecasting/test.csv
/kaggle/input/store-sales-time-series-forecasting/transactions.csv
二、导入包和数据集
#Import packages
#BASE
# ------------------------------------------------------
import numpy as np
import pandas as pd
import os
import gc
import warnings
#Machine Learning
# ------------------------------------------------------
import statsmodels.api as sm
import sklearn
#Data Visualization
# ------------------------------------------------------
#import altair as alt
import plotly.graph_objects as go
import matplotlib.pyplot as plt
import seaborn as sns
import plotly.express as px
warnings.filterwarnings('ignore')
from plotly.offline import init_notebook_mode, iplot
init_notebook_mode(connected=True)
#Import datasets
train = pd.read_csv("/kaggle/input/store-sales-time-series-forecasting/train.csv",parse_dates=['date'])
test = pd.read_csv("/kaggle/input/store-sales-time-series-forecasting/test.csv",parse_dates=['date'])
stores = pd.read_csv("/kaggle/input/store-sales-time-series-forecasting/stores.csv")
我们将检查以下数据集中每个列的数据类型。为了使用我们导入的包执行时间序列预测,我们必须确保已将日期解析为日期。稍后,我们将把“对象”数据类型转换为类别。我们还将查看我们的数据集,看看是否需要进行任何清理或操作。
train.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3000888 entries, 0 to 3000887
Data columns (total 6 columns):
| Column | Dtype | |
|---|---|---|
| 0 | id | int64 |
| 1 | date | datetime64[ns] |
| 2 | store_nbr | int64 |
| 3 | family | object |
| 4 | sales | float64 |
| 5 | onpromotion | int64 |
dtypes: datetime64ns, float64(1), int64(3), object(1)
memory usage: 137.4+ MB
train.head()
id date store_nbr family sales onpromotion
0 0 2013-01-01 1 AUTOMOTIVE 0.0 0
1 1 2013-01-01 1 BABY CARE 0.0 0
2 2 2013-01-01 1 BEAUTY 0.0 0
3 3 2013-01-01 1 BEVERAGES 0.0 0
4 4 2013-01-01 1 BOOKS 0.0 0
stores.head()
store_nbr city state type cluster
0 1 Quito Pichincha D 13
1 2 Quito Pichincha D 13
2 3 Quito Pichincha D 8
3 4 Quito Pichincha D 9
4 5 Santo Domingo Santo Domingo de los Tsachilas D 4
三、数据处理
从train.csv和transactions.csv中:
date-记录数据的日期。
store_nbr -标识销售产品的商店。
family-标识所售产品的类型。
sales -给出给定日期某一特定商店某一产品系列的总销售额。小数值是可能的。
onpromotion -给出在给定日期某商店促销的产品族的总数量。
transactions -在给定日期在商店中发生的交易总数。
删除不销售特定系列产品的商店的销售
在快速查看我们的训练数据集之后,我们可以看到有很多零。有些商店可能不销售某些产品,因为它们不是该产品的合适商店。在这种情况下,我们将删除这些值,当预测,他们不应该有任何销售。
zeros = train.groupby(['id', 'store_nbr', 'family']).sales.sum().reset_index().sort_values(['family','store_nbr'])
zeros = zeros[zeros.sales == 0]
zeros
id store_nbr family sales
0 0 1 AUTOMOTIVE 0.0
10692 10692 1 AUTOMOTIVE 0.0
30294 30294 1 AUTOMOTIVE 0.0
40986 40986 1 AUTOMOTIVE 0.0
53460 53460 1 AUTOMOTIVE 0.0
... ... ... ... ...
2981153 2981153 54 SEAFOOD 0.0
2984717 2984717 54 SEAFOOD 0.0
2986499 2986499 54 SEAFOOD 0.0
2993627 2993627 54 SEAFOOD 0.0
2998973 2998973 54 SEAFOOD 0.0
#full outer joining the tables and removing the rows where they match to get rid of the zeros
join = train.merge(zeros[zeros.sales == 0].drop("sales",axis = 1), how='outer', indicator=True)
train1 = join[~(join._merge == 'both')].drop(['id', '_merge'], axis = 1).reset_index()
train1 = train1.drop(['index', 'onpromotion'], axis=1)
train1
date store_nbr family sales
0 2013-01-01 25 BEAUTY 2.000
1 2013-01-01 25 BEVERAGES 810.000
2 2013-01-01 25 BREAD/BAKERY 180.589
3 2013-01-01 25 CLEANING 186.000
4 2013-01-01 25 DAIRY 143.000
... ... ... ... ...
2061753 2017-08-15 9 POULTRY 438.133
2061754 2017-08-15 9 PREPARED FOODS 154.553
2061755 2017-08-15 9 PRODUCE 2419.729
2061756 2017-08-15 9 SCHOOL AND OFFICE SUPPLIES 121.000
2061757 2017-08-15 9 SEAFOOD 16.000
集群存储
训练数据集就是我们用来创建模型的数据。共有 54 家商店,每家商店有 33 个产品系列。由于这是一个拥有 300 多万行的大型数据集,将商店分组将大大减少我们后续模型的计算量。幸运的是,"商店 "数据集已经为我们将商店聚类为 17 个聚类。为了简单起见和时间限制,我们还选择忽略 "促销 "变量。
def group_clusters (df) :
#left join train and stores on store number
jointr = df.merge(stores, on='store_nbr', how='left', indicator=False)
#replacing all store numbers with their cluster and grouping them by cluster
grouped = jointr.groupby(['date', 'cluster', 'family']).sum('sales').reset_index()
#removing columns id, store_nbr, and type as they are aggregated values with no significance
grouped = grouped.drop(['store_nbr'], axis=1)
return grouped
grouped = group_clusters (train1)
grouped
date cluster family sales
0 2013-01-01 1 BEAUTY 2.000
1 2013-01-01 1 BEVERAGES 810.000
2 2013-01-01 1 BREAD/BAKERY 180.589
3 2013-01-01 1 CLEANING 186.000
4 2013-01-01 1 DAIRY 143.000
... ... ... ... ...
742573 2017-08-15 17 PLAYERS AND ELECTRONICS 25.000
742574 2017-08-15 17 POULTRY 686.941
742575 2017-08-15 17 PREPARED FOODS 91.976
742576 2017-08-15 17 PRODUCE 5031.190
742577 2017-08-15 17 SEAFOOD 52.876
产品系列分组
接下来,我们将对这些系列进行探讨,以帮助我们更好地了解哪些系列对商店的总销售额贡献最大,从而有可能对它们进行分组。
#group by 'family', then sort by sales, and create a column for aggregate sales percent
temp = grouped.groupby('family').sum('sales').reset_index().sort_values(by='sales', ascending=False)
#aggregated sales
temp = temp[['family','sales']]
temp['percent']=(temp['sales']/temp['sales'].sum())
temp['percent'] = temp['percent'].apply(lambda x: f'{x:.0%}')
temp['cumulative']=(temp['sales']/temp['sales'].sum()).cumsum()
temp['cumulative'] = temp['cumulative'].apply(lambda x: f'{x:.0%}')
temp.head()
family sales percent cumulative
12 GROCERY I 3.434627e+08 32% 32%
3 BEVERAGES 2.169545e+08 20% 52%
30 PRODUCE 1.227047e+08 11% 64%
7 CLEANING 9.752129e+07 9% 73%
8 DAIRY 6.448771e+07 6% 79%
上表显示了对所有商店和日期的销售额贡献最大的五个系列:食品杂货 I、饮料、农产品、清洁和奶制品。食品杂货 I 在总销售额中所占比例最大,为 32%。前五大产品系列占总销售额的 79%。下图更清楚地显示了各产品系列的累计销售百分比。
#plot ranked category sales
fig1 = px.bar(temp, x="family",y="sales",title = "Sales",text="cumulative")
fig1.show()
我们决定将其余产品系列归入一个名为 "其他 "的系列,以减少系列类别的数量。这将使我们以后使用虚拟变量进行回归时更加方便。
#list of the top 5 families
top5 = ['GROCERY I','BEVERAGES','PRODUCE','CLEANING','DAIRY']
#removing the top 5 families so we can get the list of remaining families
tmp = grouped[~grouped['family'].isin(top5)]
#the list of families that we want to group into 'OTHERS'
tmp['family'].unique()
#replace the above list with 'OTHERS'
trainc = grouped.copy()
trainc['family'] = grouped['family'].replace(['AUTOMOTIVE', 'BABY CARE', 'BEAUTY', 'BOOKS', 'BREAD/BAKERY',
'CELEBRATION', 'DELI', 'EGGS', 'FROZEN FOODS', 'GROCERY II',
'HARDWARE', 'HOME AND KITCHEN I', 'HOME AND KITCHEN II',
'HOME APPLIANCES', 'HOME CARE', 'LADIESWEAR', 'LAWN AND GARDEN',
'LINGERIE', 'LIQUOR,WINE,BEER', 'MAGAZINES', 'MEATS',
'PERSONAL CARE', 'PET SUPPLIES', 'PLAYERS AND ELECTRONICS',
'POULTRY', 'PREPARED FOODS', 'SCHOOL AND OFFICE SUPPLIES',
'SEAFOOD'],'OTHERS')
newtrain = trainc.groupby(['date', 'cluster', 'family']).sum('sales').reset_index()
newtrain
date cluster family sales
0 2013-01-01 1 BEVERAGES 810.000000
1 2013-01-01 1 CLEANING 186.000000
2 2013-01-01 1 DAIRY 143.000000
3 2013-01-01 1 GROCERY I 700.000000
4 2013-01-01 1 OTHERS 672.618999
... ... ... ... ...
165214 2017-08-15 17 CLEANING 1357.000000
165215 2017-08-15 17 DAIRY 1377.000000
165216 2017-08-15 17 GROCERY I 4756.000000
165217 2017-08-15 17 OTHERS 3773.369000
165218 2017-08-15 17 PRODUCE 5031.190000
总之,我们现在已经删除了从未有过销售额的产品系列,将商店聚类为 17 个群组,并将销售额较低的产品系列归入 "其他 "群组。这样,我们就大大减少了数据集中的记录数量,从而改进了计算,方便了稍后的回归。
四、描述性分析
newtrain.groupby('family').describe()['sales'].applymap(lambda x: f"{x:.2f}")
count mean min 25% 50% 75% max std
family
BEVERAGES 28398.00 7639.78 242.00 2990.25 5536.50 10469.50 58848.00 6686.87
CLEANING 28399.00 3433.97 186.00 1462.00 2846.00 4639.00 22544.00 2545.52
DAIRY 28398.00 2270.85 66.00 979.25 1838.00 3022.00 14339.00 1764.45
GROCERY I 28398.00 12094.61 700.00 5012.50 9925.00 16164.00 138535.00 9418.56
OTHERS 28399.00 8046.55 596.89 3704.74 6454.25 10780.98 105366.90 6125.40
PRODUCE 23227.00 5282.85 1.00 82.00 4045.53 7953.38 31994.97 5711.49
上表显示了产品系列的简要说明。我们将绘制产品系列分组图,以确定数据的形状以及是否存在异常值。
# Create a subplot grid with 3 rows and 2 columns
fig, axes = plt.subplots(3, 2, figsize=(12, 12))
# Flatten axes for easier indexing
axes = axes.ravel()
# Unique family categories
families = newtrain['family'].unique()
# Plot sales boxplots for different family categories
for i, family in enumerate(families):
filtered_data = newtrain[newtrain['family'] == family]
sns.boxplot(data=filtered_data, x='sales', ax=axes[i])
axes[i].set_xlabel('Sales')
axes[i].set_title(f'Boxplot of Sales for {family} Family')
# Hide extra subplots
for j in range(len(families), len(axes)):
axes[j].axis('off')
plt.tight_layout() # Automatically adjust subplot layout to prevent overlap
plt.show()

根据上述方框图,我们可以得出结论:它们高度偏斜。虽然直观地认为杂货店偶尔也会有一些高销量,但为了简单起见,我们还是决定按照方框图作为剔除异常值的理由。
我们还注意到,许多产品系列的销售额为零。虽然这可能是由于商店关闭造成的,但我们也不能忽视人为失误的可能性。然而,这些零销售额的存在可能会拉低平均值。因此,我们不会完全删除方框图之外的所有异常值。
删除异常值
#function for removing outliers
def remove_outliers (df) :
# Calculate the first quartile (Q1)
q1 = df.groupby('family')['sales'].transform('quantile', 0.25)
# Calculate the third quartile (Q3)
q3 = df.groupby('family')['sales'].transform('quantile', 0.75)
# Calculate the Interquartile Range (IQR)
IQR = q3 - q1
# Define the lower and upper bounds for outliers
lbound = q1 - 1.5 * IQR
ubound = q3 + 1.5 * IQR
# Filter the dataset to remove outliers
no_outliers = df[~((df['sales'] < lbound) | (df['sales'] > ubound))]
return no_outliers
no_outliers = remove_outliers (newtrain)
no_outliers
date cluster family sales
0 2013-01-01 1 BEVERAGES 810.000000
1 2013-01-01 1 CLEANING 186.000000
2 2013-01-01 1 DAIRY 143.000000
3 2013-01-01 1 GROCERY I 700.000000
4 2013-01-01 1 OTHERS 672.618999
... ... ... ... ...
165214 2017-08-15 17 CLEANING 1357.000000
165215 2017-08-15 17 DAIRY 1377.000000
165216 2017-08-15 17 GROCERY I 4756.000000
165217 2017-08-15 17 OTHERS 3773.369000
165218 2017-08-15 17 PRODUCE 5031.190000
# plot new boxplots for no_outliers
# Create a subplot grid with 3 rows and 2 columns
fig, axes = plt.subplots(3, 2, figsize=(12, 12))
# Flatten axes for easier indexing
axes = axes.ravel()
# Unique family categories
families = no_outliers['family'].unique()
# Plot sales boxplots for different family categories
for i, f in enumerate(families):
filtered = no_outliers[no_outliers['family'] == f]
sns.boxplot(data=filtered, x='sales', ax=axes[i])
axes[i].set_xlabel('Sales')
axes[i].set_title(f'Boxplot of Sales for {f} Family')
# Hide extra subplots
for j in range(len(families), len(axes)):
axes[j].axis('off')
plt.tight_layout() # Automatically adjust subplot layout to prevent overlap
plt.show()

五、探索性数据分析
现在,我们可以绘制前五大产品系列和 "其他 "产品系列的图表,以确定我们应该使用哪种回归方法。
wtrain = no_outliers.set_index("date").groupby("family").resample("W").sales.sum().reset_index()
top6 = ['GROCERY I','BEVERAGES','PRODUCE','CLEANING','DAIRY', 'OTHERS']
cond = wtrain['family'].isin(top6)
px.line(wtrain[cond], x = "date", y = "sales", color = "family", title = "Weekly Total Sales by Family")

上图显示了明显的周和月季节性迹象,以及所有产品系列的增长趋势。有趣的是,我们可以看到 2014 年以及 2015 年和 2017 年 8 月的两次销售大跌。这些下滑可能是由于世界重大事件、节假日或油价造成的,虽然我们已经获得了这些数据,但我们选择暂时忽略它们。也许将来可以对它们进行进一步调查。
然而,农产品销售却呈现出一种奇怪的模式,似乎没有任何销售。下面的图表将对此进行进一步研究。
#sns.set(rc={"figure.figsize":(17, 10)})
dtrain = no_outliers.set_index("date").groupby("family").resample("D").sales.sum().reset_index()
gfig = sns.lineplot(dtrain[dtrain['family']=='GROCERY I'],x='date',y='sales').set_title('GROCERY I SALES')

上图显示了杂货 I 在所有商店和日期的销售情况。它清楚地描述了每天的季节性和持续增长的趋势。每年年初的销售额似乎为零,这可能与年初的节日或活动有关,但我们不会在本报告中对此进行调查。
bfig = sns.lineplot(dtrain[dtrain['family']=='BEVERAGES'],x='date',y='sales').set_title('BEVERAGES SALES')

饮料销售也呈现出明显的季节性,但在 2014 年和 2015 年,季节性随着趋势的变化而增强,从 2015 年年中开始似乎趋于稳定。这可能是我们以后需要调查的问题。与杂货 I 的销售一样,年初似乎没有销售。
pfig = sns.lineplot(dtrain[dtrain['family']=='PRODUCE'],x='date',y='sales').set_title('PRODUCE SALES')
plt.xticks(rotation=45)
plt.show()

农产品销售的表现最为奇怪。2013 年的销售量似乎很低,多次出现销售高峰,然后再次下降。从 2015 年年中开始,销售量继续与季节性和趋势保持一致。
ptrain = dtrain[(dtrain['date'].dt.year == 2013) & (dtrain['family'] == 'PRODUCE')]
pfig2013 = sns.lineplot(ptrain,x='date',y='sales').set_title('PRODUCE SALES in 2013')
plt.xticks(rotation=45)
plt.show()

在上图中,我们可以更近距离地观察 2013 年的农产品销售情况。虽然销售量较低,但仍显示出明显的季节性。
cfig = sns.lineplot(dtrain[dtrain['family']=='CLEANING'],x='date',y='sales').set_title('CLEANING SALES')
dfig = sns.lineplot(dtrain[dtrain['family']=='DAIRY'],x='date',y='sales').set_title('DAIRY SALES')
ofig = sns.lineplot(dtrain[dtrain['family']=='OTHERS'],x='date',y='sales').set_title('OTHERS SALES')
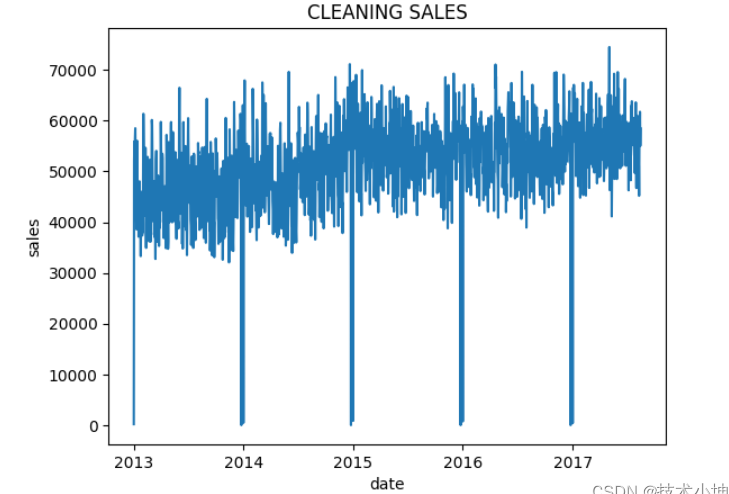


家庭清洁、乳制品和其他产品的销售表现出明显的每日季节性和一致的趋势。
下面两个数字简单地说明了每个类别的总销售额或平均销售额。
# plot a bar chart
sales_by_family = newtrain.groupby('family')['sales'].sum().reset_index().sort_values(by='sales', ascending=False)
sns.barplot(data=sales_by_family, x='family', y='sales').set_title("Sum Sales by Category")
Text(0.5, 1.0, 'Sum Sales by Category')

# plot a bar chart
sales_by_family2 = newtrain.groupby('family')['sales'].mean().reset_index().sort_values(by='sales', ascending=False)
sns.barplot(data=sales_by_family2, x='family', y='sales').set_title("Average Sales by Category")
Text(0.5, 1.0, 'Average Sales by Category')
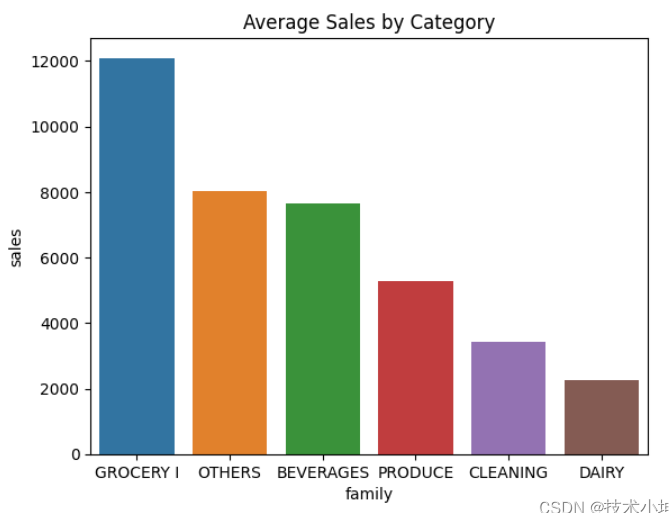
由于存在一些季节性因素,我们可以做一些工程,看看数据中的“天数”是否有意义.
六、模型一:线性回归
现在我们将尝试使用假人对以下数据集执行线性回归。由于我们分别处理每个聚类,我们将对每个聚类运行线性回归。
#function for running linear regression
def lin_reg (df, c):
y = df['sales']
#exclude family_6 and month_12
x = df[[
'4d_within_pay',
'weekend',
'family_1',
'family_2',
'family_3',
'family_4',
'family_5',
'month_1',
'month_2',
'month_3',
'month_4',
'month_5',
'month_6',
'month_7',
'month_8',
'month_9',
'month_10',
'month_11',
]]
x = sm.add_constant(x)
model = sm.OLS(y, x).fit()
#plotting the residual and normal probability plots side by side
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
sns.residplot(x=model.fittedvalues, y=model.resid, lowess=True, line_kws={"color": "red"}, ax=axes[0])
axes[0].set_xlabel('Predicted Sales')
axes[0].set_ylabel('Residuals')
axes[0].set_title(f'Residual Plot for Cluster {c}')
sm.qqplot(model.resid, line='s', ax=axes[1])
axes[1].set_xlabel('Predicted Sales')
axes[1].set_ylabel('Actual Sales')
axes[1].set_title(f'Normal Probability Plot for Cluster {c}')
plt.tight_layout
plt.show
return model
#cycling through the clusters and running linear regression on each one
for c in range(1,18):
result = lin_reg(train_m1[train_m1['cluster'] == c], c)
print("\nRegression Results for Cluster " + str(c) + "\n")
print(result.summary())

模型1的目的是观察销售是否随时间呈线性关系。由于这是最基本的回归方法,这将帮助我们确定下一步应该做什么。如果模型表现良好,我们就可以使用线性回归来预测销售。然而,这个模型被证明是很差的,我们可以在数据清洗过程中看到这一点,调整r平方,残差和正态概率图。
首先,数据处理花费了大量的时间。如上所述,有54家商店和33个产品系列,这已经在我们的数据中产生了太多不同的变量,迫使我们进行聚类和分组。还有季节性因素需要处理,为了让我们用多元回归来做这个,我们必须创造假人,这又创造了太多的变量。为了不违反简约原则,拥有太多变量并不是一个好主意,而且仅仅为了准备线性回归的数据集而需要进行的处理量是低效的。由于季节性似乎是加性的,我们可以探索指数平滑方法,如Holt-Winters,但我们选择不在这里继续研究。
由于我们的模型包括许多预测变量,我们将查看调整后的r平方值,这对于使用线性回归运行的每个集群来说都很差。虽然一些集群输出的调整后的r平方值高于0.7,这被认为是好的,但大多数集群的r平方值在0.5左右。这意味着大约50%的时间,我们的模型没有捕捉到销售数量的变化。然而,所有运行中预测变量的p值均小于0.05,表明它们具有显著性。
首先看一下集群1的残差图,这些点是随机的,正态概率图几乎是一条直线。这些都是一个好模型的代表。然而,当我们继续观察残差图时,我们注意到它们之间确实存在一种模式。虽然我们不能根据我们对不同类型回归的知识来定义这个模式,但这个模式确实证明了我们使用的线性回归模型不是一个很好的拟合。一些正态概率图也表现出指数增长,最值得注意的是集群12、15和16的图。在这种情况下,我们可以尝试通过对销售额取对数来使用指数趋势模型,但由于时间限制以及我们知道回归模型在这里不是很适合的事实,我们选择在此时不探索指数趋势。
我们已经得出结论,由于变量的数量,调整后的r平方和残差图,模型1不是预测该数据集中商店销售的好模型。然而,我们确实注意到,这个模型是在我们从分析中省略了促销、假期和油价等其他变量后创建的。如果我们选择包括这些,我们可能会得到更好的结果,但在这个时候,我们不会用它来做任何预测,而是将转向另一种可能给我们更好的结果的技术。
七、模型2:随机森林
我们在随机森林中创建预测商店销售模型的第二种方法。总之,随机森林是一种监督学习和集成算法,是决策树的扩展。它既可以用于分类模型,也可以用于回归模型,具有较高的精度,并且能够有效地处理大型数据集。然而,这是一个黑盒模型,因为我们不能真正解释随机森林中的单个决策树。
Random Forest能够处理数据中的许多商店、产品系列和季节性,因此我们不需要担心分组、创建假人和对销售额取对数。因此,我们可以回头查看未处理的数据。值得庆幸的是,随机森林有一个包,我们可以导入它,而不必分解决策树的细节。
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
#from sklearn.linear_model import LinearRegression
#from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import GridSearchCV,RandomizedSearchCV
id date store_nbr family sales onpromotion
0 0 2013-01-01 1 AUTOMOTIVE 0.000 0
1 1 2013-01-01 1 BABY CARE 0.000 0
2 2 2013-01-01 1 BEAUTY 0.000 0
3 3 2013-01-01 1 BEVERAGES 0.000 0
4 4 2013-01-01 1 BOOKS 0.000 0
... ... ... ... ... ... ...
3000883 3000883 2017-08-15 9 POULTRY 438.133 0
3000884 3000884 2017-08-15 9 PREPARED FOODS 154.553 1
3000885 3000885 2017-08-15 9 PRODUCE 2419.729 148
3000886 3000886 2017-08-15 9 SCHOOL AND OFFICE SUPPLIES 121.000 8
3000887 3000887 2017-08-15 9 SEAFOOD 16.000 0
# use original train dataset and drop all the zero sales value
train_rf = join[~(join._merge == 'both')].drop(['id', '_merge'], axis = 1).reset_index()
train_rf = train_rf.drop(['index'], axis=1)
train_rf
date store_nbr family sales onpromotion
0 2013-01-01 25 BEAUTY 2.000 0
1 2013-01-01 25 BEVERAGES 810.000 0
2 2013-01-01 25 BREAD/BAKERY 180.589 0
3 2013-01-01 25 CLEANING 186.000 0
4 2013-01-01 25 DAIRY 143.000 0
... ... ... ... ... ...
2061753 2017-08-15 9 POULTRY 438.133 0
2061754 2017-08-15 9 PREPARED FOODS 154.553 1
2061755 2017-08-15 9 PRODUCE 2419.729 148
2061756 2017-08-15 9 SCHOOL AND OFFICE SUPPLIES 121.000 8
2061757 2017-08-15 9 SEAFOOD 16.000 0
rotrain = remove_outliers(train_rf)
rotrain['codetime'] = (rotrain['date'] - rotrain['date'].min()).dt.days
rotrain['month'] = rotrain['date'].dt.month
rotrain['day'] = rotrain['date'].dt.day
rotrain['day_of_week'] = rotrain['date'].dt.dayofweek
train2 = rotrain.copy()
分类变量预处理与异常值去除
date store_nbr family sales onpromotion codetime month day day_of_week
0 2013-01-01 25 BEAUTY 2.000 0 0 1 1 1
1 2013-01-01 25 BEVERAGES 810.000 0 0 1 1 1
2 2013-01-01 25 BREAD/BAKERY 180.589 0 0 1 1 1
3 2013-01-01 25 CLEANING 186.000 0 0 1 1 1
4 2013-01-01 25 DAIRY 143.000 0 0 1 1 1
... ... ... ... ... ... ... ... ... ...
2061752 2017-08-15 9 PLAYERS AND ELECTRONICS 6.000 0 1687 8 15 1
2061753 2017-08-15 9 POULTRY 438.133 0 1687 8 15 1
2061754 2017-08-15 9 PREPARED FOODS 154.553 1 1687 8 15 1
2061755 2017-08-15 9 PRODUCE 2419.729 148 1687 8 15 1
2061757 2017-08-15 9 SEAFOOD 16.000 0 1687 8 15 1
在模型1中,我们在删除异常值之前将产品族分组在一起,但是现在我们将删除异常值,同时保持所有产品族的原样。
随机森林包需要将所有的分类变量转换为数值变量,因此我们将为每个家庭添加假人。
train2.info()
train2_dummy = pd.get_dummies(train2, columns=['family'])
train2_dummy
<class 'pandas.core.frame.DataFrame'>
Index: 1931233 entries, 0 to 2061757
Data columns (total 9 columns):
Column Dtype
0 date datetime64[ns]
1 store_nbr int64
2 family object
3 sales float64
4 onpromotion int64
5 codetime int64
6 month int32
7 day int32
8 day_of_week int32
dtypes: datetime64[ns](1), float64(1), int32(3), int64(3), object(1)
memory usage: 125.2+ MB
date store_nbr sales onpromotion codetime month day day_of_week family_AUTOMOTIVE family_BABY CARE ... family_MAGAZINES family_MEATS family_PERSONAL CARE family_PET SUPPLIES family_PLAYERS AND ELECTRONICS family_POULTRY family_PREPARED FOODS family_PRODUCE family_SCHOOL AND OFFICE SUPPLIES family_SEAFOOD
0 2013-01-01 25 2.000 0 0 1 1 1 False False ... False False False False False False False False False False
1 2013-01-01 25 810.000 0 0 1 1 1 False False ... False False False False False False False False False False
2 2013-01-01 25 180.589 0 0 1 1 1 False False ... False False False False False False False False False False
3 2013-01-01 25 186.000 0 0 1 1 1 False False ... False False False False False False False False False False
4 2013-01-01 25 143.000 0 0 1 1 1 False False ... False False False False False False False False False False
... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
2061752 2017-08-15 9 6.000 0 1687 8 15 1 False False ... False False False False True False False False False False
2061753 2017-08-15 9 438.133 0 1687 8 15 1 False False ... False False False False False True False False False False
2061754 2017-08-15 9 154.553 1 1687 8 15 1 False False ... False False False False False False True False False False
2061755 2017-08-15 9 2419.729 148 1687 8 15 1 False False ... False False False False False False False True False False
2061757 2017-08-15 9 16.000 0 1687 8 15 1 False False ... False False False False False False False False False True
# model training with RandomForest
Xrf = train2_dummy.drop(['sales','date'], axis=1)
yrf = train2_dummy['sales']
# splitting data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(Xrf, yrf, test_size=0.3)
# creating the RandomForest model (hyperparameter temporarily set to: n_estimators=50, max_depth=10, n_jobs=-1, random_state=42)
rfmodel = RandomForestRegressor(n_estimators=50, max_depth=10, n_jobs=-1, random_state=42)
# training the model
rfresult = rfmodel.fit(X_train, y_train)
# test the random forest model for the test part of dataset train2_dummy
y_pred = rfmodel.predict(X_test)
print('The model score is: ',rfmodel.score(X_test,y_test))
The model score is: 0.9150032211616177
# RMSE
#y_pred = rfmodel.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
rmse = mse**.5
print(mse)
print(rmse)
80046.52756956528
282.92495041894995
# RMSLE for train2_dummy
log_actual = np.log1p(y_test)
log_pred = np.log1p(y_pred)
rmsle = np.sqrt(np.mean((log_pred - log_actual) ** 2))
rmsle
print("RMSLE:", rmsle)
RMSLE: 1.4590769436890072
mse = mean_squared_error(y_test, y_pred)
mae = mean_absolute_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print("Mean Squared Error:", mse)
print("Mean Absolute Error:", mae)
print("R-squared:", r2)
Mean Squared Error: 80046.52756956528
Mean Absolute Error: 134.8164037890721
R-squared: 0.9150032211616177
模型2的讨论
模型2比模型1表现得好得多,我们将评估数据处理、性能度量和残差图,以了解为什么它表现得更好。
在查看模型2的调整后的r平方时,它远高于我们从模型1得到的调整后的r平方值0.9。这意味着90%的销售差异可以用商店数量和产品系列来解释。虽然我们无法看到任何p值或系数,但我们能够计算RMSE,如果我们决定在将来创建它们,可以将其与其他模型进行比较。
随机森林的残差图显示了一个明确的模式,尽管我们不能确定它是什么。这些模式可能源于其他预测变量,如促销、假期和石油销售,我们无法将其包含在本次分析中。
我们无法进一步研究随机森林模型中显示的趋势,但我们可以得出结论,模型2在预测商店销售方面比模型表现得更好。
商店销售预测(回归&随机森林)的更多相关文章
- 100天搞定机器学习|Day33-34 随机森林
前情回顾 机器学习100天|Day1数据预处理 100天搞定机器学习|Day2简单线性回归分析 100天搞定机器学习|Day3多元线性回归 100天搞定机器学习|Day4-6 逻辑回归 100天搞定机 ...
- Python数据科学手册-机器学习: 决策树与随机森林
无参数 算法 随机森林 随机森林是一种集成方法,集成多个比较简单的评估器形成累计效果. 导入标准程序库 随机森林的诱因: 决策树 随机森林是建立在决策树 基础上 的集成学习器 建一颗决策树 二叉决策树 ...
- PYTHON用户流失数据挖掘:建立逻辑回归、XGBOOST、随机森林、决策树、支持向量机、朴素贝叶斯和KMEANS聚类用户画像|附代码数据
原文链接:http://tecdat.cn/?p=24346 最近我们被客户要求撰写关于用户流失数据挖掘的研究报告,包括一些图形和统计输出. 在今天产品高度同质化的品牌营销阶段,企业与企业之间的竞争集 ...
- MATLAB随机森林回归模型
MATLAB随机森林回归模型: 调用matlab自带的TreeBagger.m T=textread('E:\datasets-orreview\discretized-regression\10bi ...
- python实现随机森林、逻辑回归和朴素贝叶斯的新闻文本分类
实现本文的文本数据可以在THUCTC下载也可以自己手动爬虫生成, 本文主要参考:https://blog.csdn.net/hao5335156/article/details/82716923 nb ...
- 常见算法(logistic回归,随机森林,GBDT和xgboost)
常见算法(logistic回归,随机森林,GBDT和xgboost) 9.25r早上面网易数据挖掘工程师岗位,第一次面数据挖掘的岗位,只想着能够去多准备一些,体验面这个岗位的感觉,虽然最好心有不甘告终 ...
- 逻辑斯蒂回归VS决策树VS随机森林
LR 与SVM 不同 1.logistic regression适合需要得到一个分类概率的场景,SVM则没有分类概率 2.LR其实同样可以使用kernel,但是LR没有support vector在计 ...
- 机器学习之路:python 集成回归模型 随机森林回归RandomForestRegressor 极端随机森林回归ExtraTreesRegressor GradientBoostingRegressor回归 预测波士顿房价
python3 学习机器学习api 使用了三种集成回归模型 git: https://github.com/linyi0604/MachineLearning 代码: from sklearn.dat ...
- 决策树与树集成模型(bootstrap, 决策树(信息熵,信息增益, 信息增益率, 基尼系数),回归树, Bagging, 随机森林, Boosting, Adaboost, GBDT, XGboost)
1.bootstrap 在原始数据的范围内作有放回的再抽样M个, 样本容量仍为n,原始数据中每个观察单位每次被抽到的概率相等, 为1/n , 所得样本称为Bootstrap样本.于是可得到参数θ的 ...
- 【R语言学习笔记】 Day1 CART 逻辑回归、分类树以及随机森林的应用及对比
1. 目的:根据人口普查数据来预测收入(预测每个个体年收入是否超过$50,000) 2. 数据来源:1994年美国人口普查数据,数据中共含31978个观测值,每个观测值代表一个个体 3. 变量介绍: ...
随机推荐
- [转帖]Sosreport:收集系统日志和诊断信息的工具
https://zhuanlan.zhihu.com/p/39259107 如果你是 RHEL 管理员,你可能肯定听说过 Sosreport :一个可扩展.可移植的支持数据收集工具.它是一个从类 Un ...
- buildkit ctr 与 k3s的简单学习
摘要 前面一部分学习了 buildkit的简单搭建 也学习会了如果build images的简单处理 但是搭建镜像只是万里长征第一步. 如何进行微服务部署,才是关键的第二步. 公司最近使用基于K3S的 ...
- 使用rpm打包nacos然后部署为systemd服务开机自动启动的方法
背景 Nacos是阿里开源的服务注册组件,能够简单的实现微服务的注册与发现机制. 但是官方并没有提供 sytemd的服务脚本, 也没有提供rpm包的方式. 公司里面使用 nacos的场景越来越多, 部 ...
- K8S 知识点
1. K8S集群大小 在 v1.7 版本中,Kubernetes 支持集群节点(node)数可达1000个.更具体地说,我们配置能够支持所有如下条件: 不超过2000个节点 不超过总共6000个 po ...
- 热更新适配ibatis原理浅析
一.热更新解决了什么问题? 在研发过程中,每个研发同学在联调.自测阶段中总会频繁的去执行编译.构建.打包的动作,遇到比较大的项目,执行一套流程下来,往往需要3-10分钟左右,极大的降低了研发的速度,基 ...
- JS中every的简单使用
every 方法 every()方法用于检测数组中的所有元素是否都满足指定条件. every()方法会遍历数组的每一项,如果有一项不满足条件,则返回false,剩余的项将不会再执行检测. 如果遍历完数 ...
- 从零开始配置vim(23)——lsp基础配置
上一章,我们初步认识了lsp,并且对 nvim-treesitter插件进行了配置,为编辑器提供了代码着色.自动格式化以及增量选中功能.算是初步体验了 lsp的相关功能.从这篇开始我们通过lsp的功能 ...
- TienChin-系统功能介绍
线索管理 添加线索 查看线索 删除线索 修改线索 分配线索: 将录入到系统的线索,分配给某一个市场专员去处理 跟进线索: 持续跟进一条线索 1.判断是否伪线索 2.持续跟进,每次跟进需要有记录 3 ...
- 【四】超级快速pytorch安装,三步走,分分钟完成!
相关文章: [一]tensorflow安装.常用python镜像源.tensorflow 深度学习强化学习教学 [二]tensorflow调试报错.tensorflow 深度学习强化学习教学 [三]t ...
- 8.3 Windows驱动开发:内核遍历文件或目录
在笔者前一篇文章<内核文件读写系列函数>简单的介绍了内核中如何对文件进行基本的读写操作,本章我们将实现内核下遍历文件或目录这一功能,该功能的实现需要依赖于ZwQueryDirectoryF ...