仿Linux内核链表实现合并有序链表、逆序单链表功能,C版本 JavaScript版本
直接贴上已经码好的:
list_sort.c:
#include <stdio.h>
#include <string.h>
#include <assert.h>
#include <stdlib.h>
#include <unistd.h> /**** 双向链表,非双向循环链表哦!
*
* gcc -m32 : 在64位系统上编译出32位的程序(指针大小4字节),
* 这样编译本代码不会编译报警告
*
*****/ #define use_double_direction_list //关闭双向非循环链表模式,则默认开启单向非循环链表模式 /*计算member在type中的位置*/
#define offsetof(type, member) (unsigned int)(&((type*)0)->member) /*根据member的地址获取type的起始地址*/
#define container_of(ptr, type, member) ({ \
const typeof(((type *)0)->member)*__mptr = (ptr); \
(type *)((char *)__mptr - offsetof(type, member)); }) typedef struct _inside_link{
struct _inside_link* pNext; #if defined(use_double_direction_list)
struct _inside_link* pFront;
#endif }inside_link; typedef struct _usr_data_pack{
unsigned char* name0;
unsigned int data0;
}usr_data_pack; typedef struct _usrdata_templ{
inside_link link; usr_data_pack usr_data;
}usrdata_templ; void usrdata_set(usrdata_templ* pusr_data_list, usr_data_pack* pdata_pack){ memset(&pusr_data_list->usr_data, 0, sizeof(usr_data_pack));
memcpy(&pusr_data_list->usr_data, pdata_pack, sizeof(usr_data_pack));
} static void print_usr_data_pack(usr_data_pack* pdata_pack){ printf("pdata_pack->name0 = \033[0;31m %s,\t\033[0m pdata_pack->data0 = \033[0;33m %d \033[0m\n", \
pdata_pack->name0, pdata_pack->data0); } void usrdata_print(usrdata_templ* pusr_data_list){ if(pusr_data_list != NULL){
print_usr_data_pack(&pusr_data_list->usr_data);
} inside_link* pNext_link = pusr_data_list->link.pNext; while(pNext_link){
usrdata_templ* pNext_templ = NULL;
pNext_templ = container_of(pNext_link, usrdata_templ, link); print_usr_data_pack(&pNext_templ->usr_data); pNext_link = pNext_link->pNext;
}
} void link_init(inside_link* plink){
#if defined(use_double_direction_list)
plink->pFront = NULL; #endif plink->pNext = NULL;
} /***** 对比内核链表
下面是内核从尾部添加函数:
static inline void list_add_tail(struct list_head *newer, struct list_head *head)
{
__list_add(newer, head->prev, head);
}
内核链表使用了双向循环链表,这里找到尾巴节点,只要从头节点向前推一个节点就找到了,很方便。
而我使用了双向非循环链表,就需要遍历了,代码也更难看了。
心得: 双向循环链表相对于双向非循环链表,几乎不增加内存成本,而且能够提高效率。
以后写代码,编写组件,都要使用双向循环链表。
*******/ /**
* list_add_tail没有检查同一个链表节点两次被加入的情况。
* 但是我这个函数检查了
* **/
int link_tail_add(inside_link* plink, inside_link* pnode){ inside_link* pcurrent_node = plink->pNext;
inside_link* pformer_node = plink; if(plink == pnode){ /****检查同一个链表节点两次及以上次数被加入*****/
return -1;
} while(pcurrent_node){
if(pnode == pcurrent_node){ /****检查同一个链表节点两次及以上次数被加入*****/
return -1;
} pformer_node = pcurrent_node;
pcurrent_node = pcurrent_node->pNext;
} #if defined(use_double_direction_list)
pnode->pFront = pformer_node;
#endif pformer_node->pNext = pnode; return 0;
} void create_usrdaralist1(usrdata_templ* phead){ link_init(&phead->link); // add first node, then print
usr_data_pack pack0 = {"jack 170", 170};
usrdata_set(phead, &pack0); #if 0
// add second node, then print
usrdata_templ* pnode1 = (usrdata_templ*)malloc(sizeof(usrdata_templ));
usr_data_pack pack1 = {"jack 171", 171};
link_init(&pnode1->link);
usrdata_set(pnode1, &pack1); if(!link_tail_add(&phead->link, &pnode1->link)){ }else{ printf("\033[0;33m this Node add Fail! \033[0m \n");
}
#endif // add third node, then print
usrdata_templ* pnode2 = (usrdata_templ*)malloc(sizeof(usrdata_templ));
usr_data_pack pack2 = {"jack 172", 172};
link_init(&pnode2->link);
usrdata_set(pnode2, &pack2); if(!link_tail_add(&phead->link, &pnode2->link)){ }else{ printf("\033[0;33m this Node add Fail! \033[0m \n");
} // add 4th node, then print
// 这里尝试将实验3处的节点再次添加到链表上,
// 即实验一个链表节点多次被添加
if(!link_tail_add(&phead->link, &pnode2->link)){ }else{ printf("\033[0;33m this Node add Fail! \033[0m \n");
} #if 1
// add 4th node agian, then print
usrdata_templ* pnode3 = (usrdata_templ*)malloc(sizeof(usrdata_templ));
usr_data_pack pack3 = {"jack 178", 178};
link_init(&pnode3->link);
usrdata_set(pnode3, &pack3); if(!link_tail_add(&phead->link, &pnode3->link)){ //usrdata_print(phead);
//printf("Creat List1 Done ----------\n\n"); }else{ printf("\033[0;33m this Node add Fail!! \033[0m \n");
}
#endif usrdata_print(phead);
printf("Creat List1 Done ----------\n\n"); } void create_usrdaralist2(usrdata_templ* phead){ link_init(&phead->link); // add first node, then print
usr_data_pack pack0 = {"merry 172", 172};
usrdata_set(phead, &pack0); //usrdata_print(phead); // add second node, then print
usrdata_templ* pnode1 = (usrdata_templ*)malloc(sizeof(usrdata_templ));
usr_data_pack pack1 = {"merry 173", 173};
link_init(&pnode1->link);
usrdata_set(pnode1, &pack1); if(!link_tail_add(&phead->link, &pnode1->link)){
//usrdata_print(phead);
}else{ printf("\033[0;33m this Node add Fail! \033[0m \n");
} // add third node, then print
usrdata_templ* pnode2 = (usrdata_templ*)malloc(sizeof(usrdata_templ));
usr_data_pack pack2 = {"merry 174", 174};
link_init(&pnode2->link);
usrdata_set(pnode2, &pack2); if(!link_tail_add(&phead->link, &pnode2->link)){
//usrdata_print(phead);
}else{ printf("\033[0;33m this Node add Fail! \033[0m \n");
} // add 4th node, then print
// 这里尝试将实验3处的节点再次添加到链表上,
// 即实验一个链表节点多次被添加
if(!link_tail_add(&phead->link, &pnode2->link)){
//usrdata_print(phead);
}else{ printf("\033[0;33m this Node add Fail! \033[0m \n");
} // add 4th node agian, then print
usrdata_templ* pnode3 = (usrdata_templ*)malloc(sizeof(usrdata_templ));
usr_data_pack pack3 = {"merry 175", 175};
link_init(&pnode3->link);
usrdata_set(pnode3, &pack3); if(!link_tail_add(&phead->link, &pnode3->link)){ usrdata_print(phead);
printf("Create List2 Done ----------\n\n"); }else{ printf("\033[0;33m this Node add Fail!! \033[0m \n");
}
} void combine_2_becomes_1(usrdata_templ*plist1, usrdata_templ*plist2){ inside_link* p_list1_curlink = &plist1->link;
inside_link* p_list2_curlink = &plist2->link; //inside_link* p_list1_baklink = NULL;
//inside_link* p_list2_baklink = NULL; usrdata_templ* p_cur_usrdata1 = NULL;
usrdata_templ* p_cur_usrdata2 = NULL; usrdata_templ newlist = {
.link = {0}, .usr_data = {
.name0 = "我是头节点",
.data0 = 0,
}
};
link_init(&newlist.link); int flagloop = 1; do{
usleep(100000);
printf(" time: 100 ms \n"); // 1. 取
if(NULL != p_list1_curlink){
p_cur_usrdata1 = container_of(p_list1_curlink, usrdata_templ, link);
//printf("%s, %d \n", p_cur_usrdata1->usr_data.name0, p_cur_usrdata1->usr_data.data0);
}
else{
break;
} if(NULL != p_list2_curlink){
p_cur_usrdata2 = container_of(p_list2_curlink, usrdata_templ, link);
//printf("%s, %d \n", p_cur_usrdata2->usr_data.name0, p_cur_usrdata2->usr_data.data0);
}
else{
break;
} // 2.比
if(p_cur_usrdata1->usr_data.data0 <= p_cur_usrdata2->usr_data.data0){ // 3. 存
usrdata_templ *pnode = (usrdata_templ *)malloc(sizeof(usrdata_templ));
usr_data_pack pack = {0};
memcpy(&pack, &p_cur_usrdata1->usr_data, sizeof(usr_data_pack));
link_init(&pnode->link);
usrdata_set(pnode, &pack); if(!link_tail_add(&newlist.link, &pnode->link)){
printf("\033[0;34m Add Success. Line: %d \033[0m \n", __LINE__);
}
else{
printf("\033[0;33m this Node add Fail! Line: %d \033[0m \n", __LINE__);
} // 4. 移
p_list1_curlink = p_list1_curlink->pNext; }else{ // 3. 存
usrdata_templ *pnode = (usrdata_templ *)malloc(sizeof(usrdata_templ));
usr_data_pack pack = {0};
memcpy(&pack, &p_cur_usrdata2->usr_data, sizeof(usr_data_pack));
link_init(&pnode->link);
usrdata_set(pnode, &pack); if(!link_tail_add(&newlist.link, &pnode->link)){
printf("\033[0;34m Add Success. Line: %d \033[0m \n", __LINE__);
}
else{
printf("\033[0;33m this Node add Fail! Line: %d \033[0m \n", __LINE__);
} // 4. 移
p_list2_curlink = p_list2_curlink->pNext; } }while(1); // 4. 比 printf("p_list1_curlink = 0x%x, p_list2_curlink = 0x%x \n", \
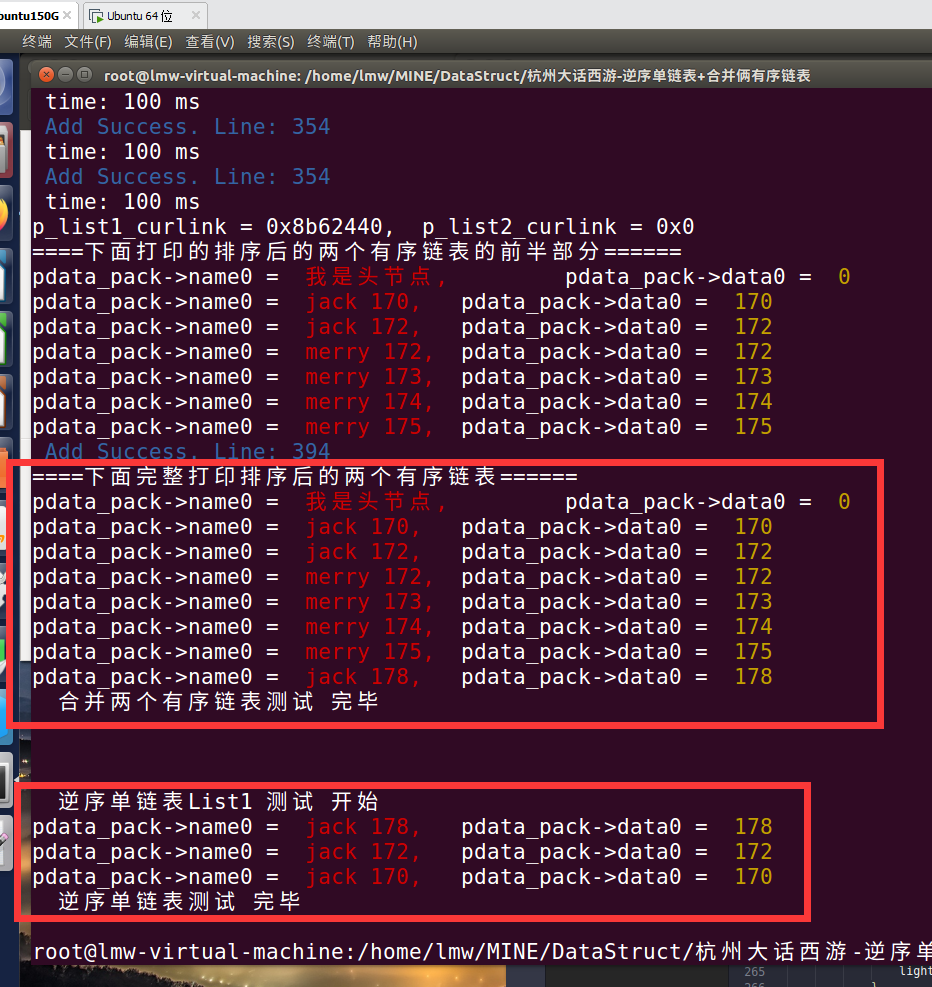
(unsigned int)p_list1_curlink, (unsigned int)p_list2_curlink); inside_link* p_list_left = NULL; printf("====下面打印的排序后的两个有序链表的前半部分======\n");
usrdata_print(&newlist); if(NULL != p_list1_curlink){
p_list_left = p_list1_curlink;
} if(NULL != p_list2_curlink){
p_list_left = p_list2_curlink;
} while(p_list_left){ usrdata_templ* p_left_usrdata = container_of(p_list_left, usrdata_templ, link); usrdata_templ *pnode = (usrdata_templ *)malloc(sizeof(usrdata_templ));
usr_data_pack pack = {0};
memcpy(&pack, &p_left_usrdata->usr_data, sizeof(usr_data_pack));
link_init(&pnode->link);
usrdata_set(pnode, &pack); if(!link_tail_add(&newlist.link, &pnode->link)){
printf("\033[0;34m Add Success. Line: %d \033[0m \n", __LINE__);
}
else{
printf("\033[0;33m this Node add Fail! Line: %d \033[0m \n", __LINE__);
} p_list_left = p_list_left->pNext; } printf("====下面完整打印排序后的两个有序链表======\n");
usrdata_print(&newlist); } usrdata_templ* reverse_single_direction_list(usrdata_templ*plist){ usrdata_templ* plist_local = plist; inside_link *p_list_curlink = &plist_local->link;
inside_link *p_list_baklink_former = NULL, *p_list_baklink_former_former = NULL; unsigned int the_single_list_node_cnt = 0; usrdata_templ* p_cur_usrdata; while(p_list_curlink->pNext){ /** 如果单链表有N个节点,那么退出该while时,the_single_list_node_cnt值为(N-1) **/
the_single_list_node_cnt++; p_list_baklink_former_former = p_list_baklink_former;
p_list_baklink_former = p_list_curlink;
p_list_curlink = p_list_curlink->pNext; if(the_single_list_node_cnt >= 2){ p_list_baklink_former->pNext = p_list_baklink_former_former;
}
} p_list_curlink->pNext = p_list_baklink_former; if(the_single_list_node_cnt >= 1){
/**只要存在两个以上节点,就要把第一个节点的pNext指针值为NULL(即将其设置为尾节点)**/
plist_local->link.pNext = NULL;
} if(0 == the_single_list_node_cnt){
printf("\033[0;33m 该list只有1个节点,不需要逆序! \033[0m \n");
} p_cur_usrdata = container_of(p_list_curlink, usrdata_templ, link); return p_cur_usrdata;
} int main(){ usrdata_templ* phead1 = (usrdata_templ*)malloc(sizeof(usrdata_templ));
create_usrdaralist1(phead1); usrdata_templ* phead2 = (usrdata_templ*)malloc(sizeof(usrdata_templ));
create_usrdaralist2(phead2); #if 1
printf(" 合并两个有序链表测试 开始\n\n");
combine_2_becomes_1(phead1, phead2);
printf(" 合并两个有序链表测试 完毕 \n\n\n");
#endif #if 1
printf("\n 逆序单链表List1 测试 开始\n"); usrdata_templ* p_reverse = reverse_single_direction_list(phead1);
usrdata_print(p_reverse); printf(" 逆序单链表测试 完毕\n\n");
#endif return 0;
}
makefile:
do:
#gcc list_sort.c
gcc -m32 list_sort.c
./a.out
运行:
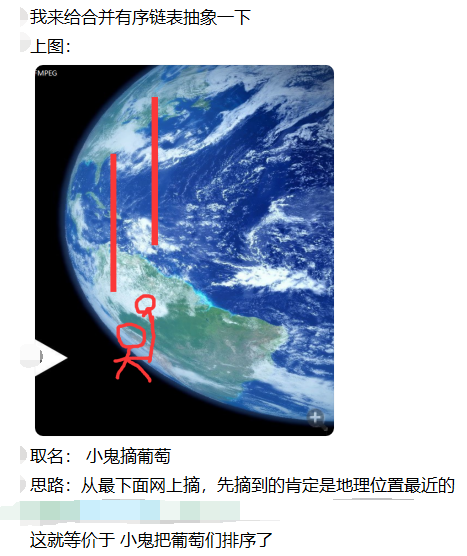
解题思路:
合并有序链表思路: 小鬼摘葡萄
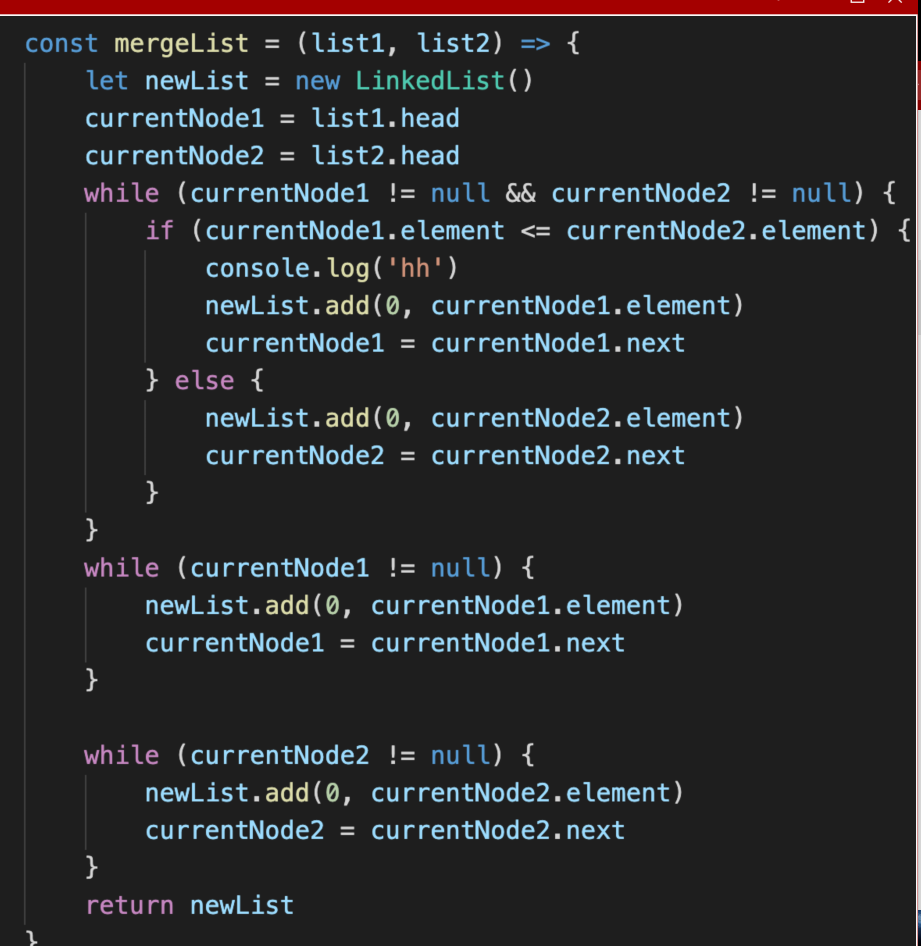
领略JavaScript风采
同样的思路,同样的原理(和上述C版本的一模一样),JavaScript版本的核心代码:
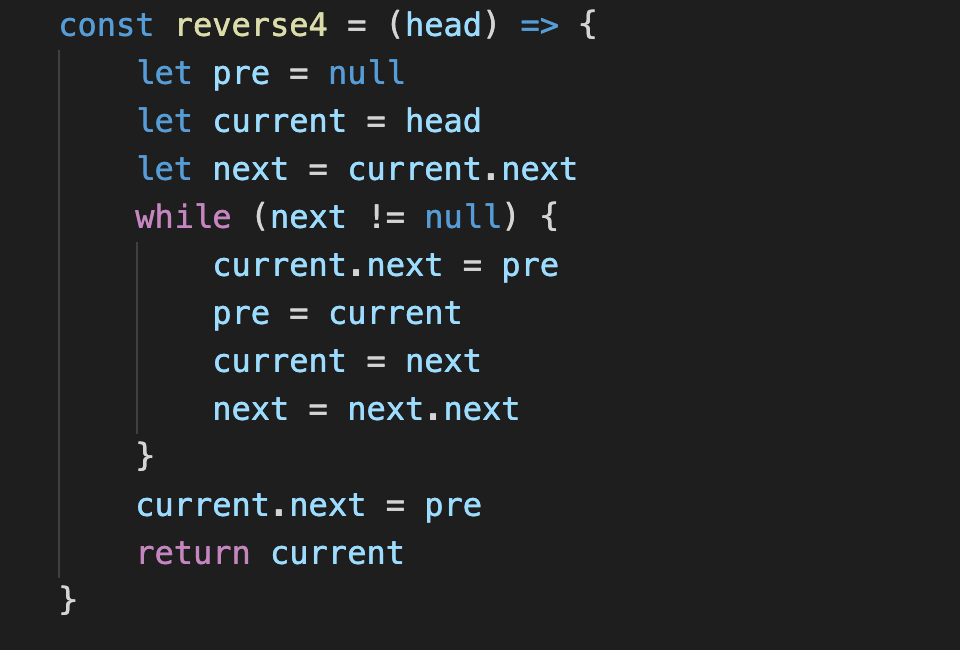
JavaScript版本实现的单链表逆序的核心代码,此版本思路较我上面的C版本更简洁,更佳,所以上面的C代码还可以参考此代码进行改进
个人心得:
对于链表的使用,不仅仅是学习其侵入式链表的特点,还要领会其循环链表的优点, 双向、循环、侵入式、每个都是值得学习的地方。
话外(吐槽):
对于面试造飞机,要在一小时内写完一张卷子,还包括几道这种题目,难度的确大。
备战面试笔试,我们要做到不假思索就能写出来,不仅靠调试能力(面试笔试只有笔和纸,甚至都不能调试),可能还需要记和背了。
本例子实现的链表不仅完成了基本功能,还具有一定的可复用特点,具有一定的工程意义,所以足以应付笔试标准。
但是对外提供的API还不够丰富,且未做线程安全处理, 达不到实际工程标准,在实际工程中,我们应该参考Linux内核链表去实现,而不要凭空自己去实现。
.
仿Linux内核链表实现合并有序链表、逆序单链表功能,C版本 JavaScript版本的更多相关文章
- 剑指Offer03 逆序输出链表&链表逆序
多写了个逆序链表 /************************************************************************* > File Name: ...
- 面试:用 Java 逆序打印链表
昨天的 Java 实现单例模式 中,我们的双重检验锁机制因为指令重排序问题而引入了 volatile 关键字,不少朋友问我,到底为啥要加 volatile 这个关键字呀,而它,到底又有什么神奇的作用呢 ...
- 剑指offer面试题5:逆序打印单链表(Java)
Java创建单链表(头插法.尾插法),并逆序打印单链表: package day_0324; import java.util.Scanner; import java.util.Stack; cla ...
- SDUT OJ 数据结构实验之链表二:逆序建立链表
数据结构实验之链表二:逆序建立链表 Time Limit: 1000 ms Memory Limit: 65536 KiB Submit Statistic Discuss Problem Descr ...
- php数据结构课程---2、链表(php中 是如何实现单链表的(也就是php中如何实现对象引用的))
php数据结构课程---2.链表(php中 是如何实现单链表的(也就是php中如何实现对象引用的)) 一.总结 一句话总结: php是弱类型语言,变量即可表示数值,也可表示对象:链表节点的数据域的值就 ...
- SDUT-2117_数据结构实验之链表二:逆序建立链表
数据结构实验之链表二:逆序建立链表 Time Limit: 1000 ms Memory Limit: 65536 KiB Problem Description 输入整数个数N,再输入N个整数,按照 ...
- Leetcode23--->Merge K sorted Lists(合并k个排序的单链表)
题目: 合并k个排序将k个已排序的链表合并为一个排好序的链表,并分析其时间复杂度 . 解题思路: 类似于归并排序的思想,lists中存放的是多个单链表,将lists的头和尾两个链表合并,放在头,头向后 ...
- Leetcode21--->Merge Two Sorted Lists(合并两个排序的单链表)
题目: 给出两个排序的单链表,合并两个单链表,返回合并后的结果: 解题思路: 解法还是很简单的,但是需要注意以下几点: 1. 如果两个链表都空,则返回null; 2. 如果链表1空,则返回链表2的 ...
- C语言两个升序递增链表逆序合并为一个降序递减链表,并去除重复元素
#include"stdafx.h" #include<stdlib.h> #define LEN sizeof(struct student) struct stud ...
- 已知单链表的数据元素为整型数且递增有序,L为单链表的哨兵指针。编写算法将表中值大于X小于Y的所有结点的顺序逆置。(C语言)
对此题目的完整示例可直接运行代码如下: #include <stdio.h> #include <stdlib.h> typedef struct LNode{ int dat ...
随机推荐
- WPF/C#:实现导航功能
前言 在WPF中使用导航功能可以使用Frame控件,这是比较基础的一种方法.前几天分享了wpfui中NavigationView的基本用法,但是如果真正在项目中使用起来,基础的用法是无法满足的.今天通 ...
- 关于c++出现的易错问题
比如我一个对象,经常操作用的指针ptr,原生指针比如ClassA* ca =; 但是我要保存ca,在另一个地方操作,比如: cb =ca; 这样子是不行的,因为我要操作的是ca,而不是ca的值,为什么 ...
- UE5 打包DedicatedServer
UE5开发Dedicate Server直接按教程用Replicated那种蓝图开发即可. 如果打包的话,服务器端需要无界面的运行模式,不同于正常的开发,所以为了打包,这里步骤如下: 1.到githu ...
- 查询当前网段的所有在用IP
查询当前网段的所有在用IP For /L %i in (0,1,254) DO ping 192.168.10.%i >>D:\IP.txt https://www.cnblogs.com ...
- 【Hibernate】03 配置文件 & API
映射器文件: - 字段的Column属性可以不写缺省,这将表示和实体类的属性标识一样 - type 属性用于声明表字段在Java中的类型,这个属性可不写缺省,自动匹配 Hibernate 4个核心AP ...
- Jax框架的static与Traced Operations —— Static vs Traced Operations
相关: Jax框架的jit编译是否可以使用循环结构,如果使用循环结构需要注意什么 Jax的static和Traced都是指jit编译的函数内的对象的属性的,jit装饰的函数其输入参数和输出参数都是Tr ...
- ( Ubuntu环境下 )Vim插件推荐-Python自动补齐Vim插件jedi-vim的安装(使用插件管理器vundle进行安装)
Ubuntu系统下,为 Vim 安装python自动补齐的插件 jedi-vim . 1. jedi-vim安装依赖 首先,jedi-vim插件需要当前Vim版本支持python,在终端输 ...
- 网站的备案信息更改后是否需要及时更新 —— ICP 备案巡检
引自: https://developer.qiniu.com/kodo/8556/set-the-custom-source-domain-name ICP 备案巡检 自2022年6月8日起,执行 ...
- mybatis-plus系统化学习之配置精讲
1.背景 mybatis-plus给出了很多配置, 大部分的配置使用默认的就可以了, 但是还是有很多需要的配置比如: # mybatis-plus相关配置 mybatis-plus: # xml扫描, ...
- 大模型时代的程序员:不会用AIGC编程,未来5年将被淘汰?
作者 | 郭炜 策划 | 凌敏 前言 下面是一段利用 Co-Pilot 辅助开发的小视频,这是 Apache SeaTunnel 开发者日常开发流程中的一小部分.如果你还没有用过 Co-Pilot.C ...