CaiT:Facebook提出高性能深度ViT结构 | ICCV 2021
CaiT通过LayerScale层来保证深度ViT训练的稳定性,加上将特征学习和分类信息提取隔离的class-attention层达到了很不错的性能,值得看看
来源:晓飞的算法工程笔记 公众号
论文: Going deeper with Image Transformers

Introduction
自ResNet出现以来,残差架构在计算机视觉中非常突出:
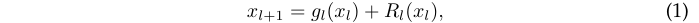
其中函数\(g_l\)和\(R_l\)定义了网络如何更新第l层的输入\(x_l\)。函数\(g_l\)通常是恒等式,而残差分支\(R_l\)则是网络构建的核心模块,许多研究都着力于残差分支\(R_l\)的变体以及如何对\(R_l\)进行初始化。实际上,残差结构突出了训练优化和结构设计之间的相互作用,正如ResNet作者所说的:残差结构没有提供更好的特征表达能力,之所以取得更好的性能,是因为残差结构更容易训练。
目前很火的ViT网络可认为是实现了一种特定形式的残差架构:在将输入图像转换为一组\(x_0\)的向量之后,网络交替进行自注意力层 (SA) 与前馈网络 (FFN) 处理:
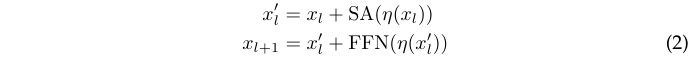
其中\(\eta\)是LayerNorm算子。
对于卷积神经网络和应用于NLP或语音任务的Transformer,如何对残差架构的残差分支进行归一化、加权或初始化受到了广泛关注。作者也在ViT上对不同初始化、优化和架构设计之间的相互作用进行了分析,并且提出了LayerScale层。LayerScale层包含一个初始权值接近于零的可学习对角矩阵,加在每个残差模块的输出上,可以有效地改进更深层架构的训练。
此外,作者还提出了class-attention层。类似于编码器/解码器架构,显示地将用于token间特征提取的transformer层与将token整合成单一向量进行分类的class-attention层分开,避免了两种目标不同的处理混合的矛盾现象。
通过实验验证,论文的主要贡献如下:
- LayerScale能够显着促进了训练收敛并提高了深度更大的ViT的准确性,仅需在训练时向网络添加了数千个参数(对比总参数量可以忽略不计)。
- 具有class-attention的架构提供了更高效的class embedding的处理。
- 在Imagenet-Real和Imagenet V2 matched frequency上,CaiT无需额外的训练数据就达到了SOTA性能。在ImageNet1k-val上,CaiT与最先进的模型 (86.5%) 相当,但仅需要更少的 FLOPs (329B vs 377B)和更少的参数(356M vs 438M)。
- 在迁移学习方面也取得了相当的结果。
Deeper image transformers with LayerScale
作者的目标是在提高Transformer架构的深度同时,提升图像分类训练优化的稳定性。在ViT和DeiT两项工作中,都没有研究仅在Imagenet上训练时,更大的深度可以带来任何好处:更深的ViT架构性能反而更低,而DeiT则只考虑了12层的架构。
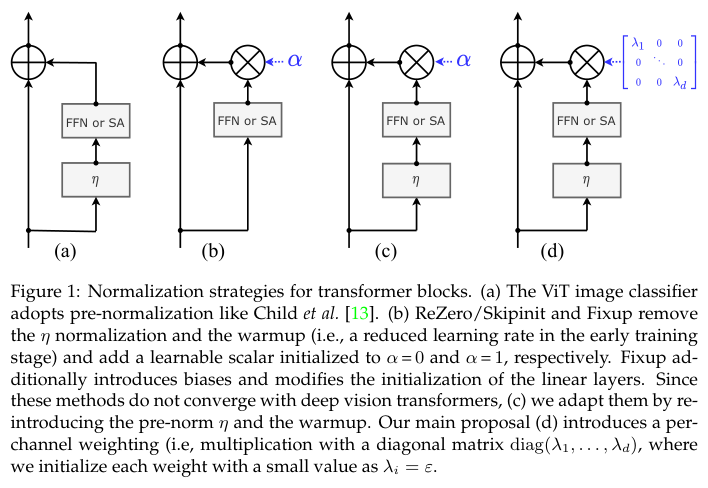
图1展示了可能有助于优化的主要变体,图a是标准的预归一化结构。图b则是Fixup、ReZero和SkipInit这类引入可学习标量\(a_l\)的结构,该类结构会同时去掉预归一化层和学习率warmup:
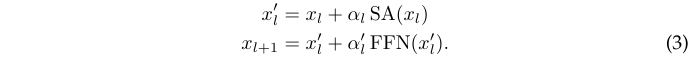
ReZero简单地初始化为\(\alpha = 0\),而Fixup则初始化为\(\alpha = 1\)并进行其他修改:采用不同的权值的初始化策略,添加了几个偏置权值。但在作者的实验中,即使对超参数进行了调整,这些方法也难以收敛。
经过观察,移除warmup和层归一化是导致Fixup和T-Fixup训练不稳定的原因。因此作者重新引入这两部分,使Fixup和T-Fixup在DeiT模型上收敛,如图1c所示。当深度增加时,以较小的值初始化的可学习标量\(a_l\)确实有助于收敛。
Our proposal LayerScale
作者提出的LayerScale对输出进行通道级别的乘法,而不是单个标量,如图1d所示,将权值更新与特定输出通道关联。公式上,可认为LayerScale是对每个残差分支输出的对角矩阵乘积:
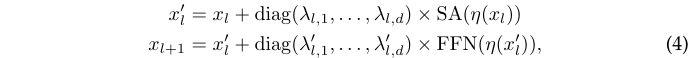
其中参数\(\lambda_{l,i}\)和\(\lambda^{'}_{l,i}\)是可学习权值,初始化为一个固定的小值\(\varepsilon\):
- 深度小于18时,设置为\(\varepsilon=0.1\)。
- 深度小于24时,设置为\(\varepsilon=10^{-5}\)。
- 对于更深的网络,设置为\(\varepsilon=10^{-6}\)。
该公式类似于其他归一化策略,如ActNorm或LayerNorm,但是在残差分支的输出上执行。此外,实际目的也有很大区别:
- ActNorm是数据相关的初始化,使输出具有零均值和单位方差,就像batchnorm操作。而LayerScale用较小的值初始化对角线,使其对残差分支的初始影响很小。因此,LayerScale更接近于ReZero、SkipInit、Fixup和T-Fixup等方法:先训练接近恒等函数的网络,然后在训练过程中让网络逐步集成额外参数。
- LayerScale在优化方面提供了更多的多样性,而不仅仅是通过一个可学习的标量调整,这也是LayerScale优于现有方法的决定性优势。
添加这些参数不会改变架构的特征表达能力,因为也可以集成到SA和FFN层的矩阵参数中,无需更改网络的实现。
Specializing layers for class attention
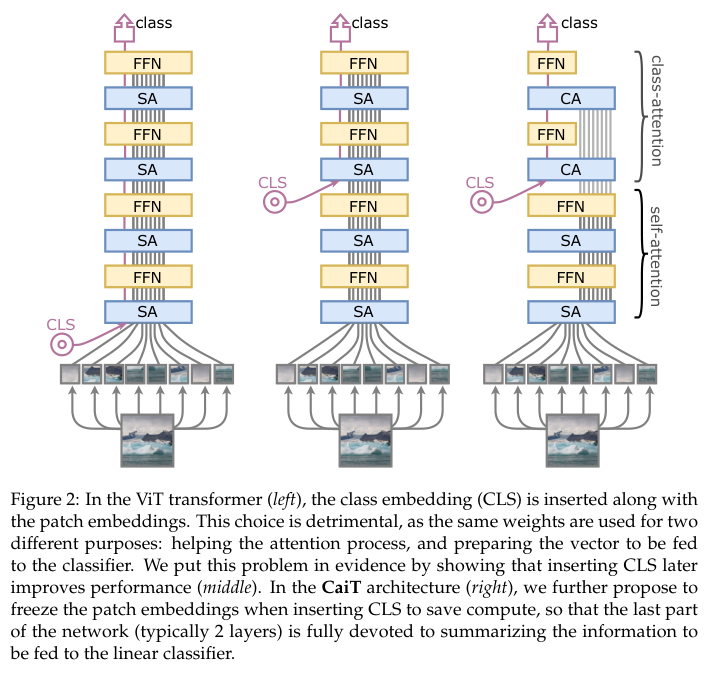
CaiT架构如图2右,设计核心旨在规避ViT架构要求权值训练同时优化两个相互矛盾的目标的问题。两个矛盾的目标分别是:
- 学习token之间的自我注意。
- 总结token间对分类有用的信息。
为此,CaiT的核心就是将上面两个矛盾完全分隔开。
Later class token
作为对比,在网络中间中插入Class token,这样前面的层可以专注于执行自我注意计算。作为不受矛盾目标影响的baseline,作者还考虑了将输出的平均池化用于分类的做法
Architecture
CaiT包含两个不同的处理阶段:
- self-attention阶段与ViT转换器类似,但没有Class token。
- class-attentio阶段是一组层,将token集合成class token,随后将输入到线性分类器中。
class-attention阶段依次交替由多头类注意(CA)和FFN组成的层,在这个阶段只有class token会更新。
Multi-heads class attention
CA的作用是从token中提取信息,与SA 类似,但CA只计算class toekn \(x_{class}\)和\(x_{class}\)与冻结的token \(x_{patches}\)的集合之间的注意力。
定义具有h个head和p个token的网络,d为token维度,将多头类注意力参数化为投影矩阵\(W_q、W_k、W_v、W_o \in \mathbb{R}^{d\times d}\)和偏置\(b_q, b_k, b_v, b_o \in R_d\)。基于上述定义,CA参数分支的计算可公式化为:
- 先将输入token扩充为\(z=[x_{class}, x_{patches}]\),执行以下映射:
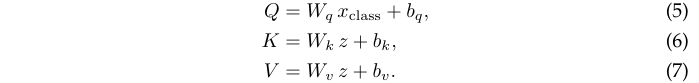
- 计算类注意力权重,其中\(Q\cdot K^T\in\mathbb{R}^{h\times 1\times p}\):
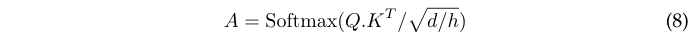
- 将注意力用于加权得到残差分支输出:
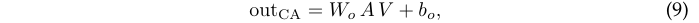
- 将输出叠加到\(x_{class}\)中以进行后续处理。
CA从特征token中提取有用信息整合到class token中。在实验中发现,第一个CA和FFN模块提供了主要的性能提升,叠加第二个模块就足以达到性能提升上限。
Complexity
CA函数在内存和计算方面也比SA更轻量,因为CA只计算class token和token集合之间的注意力:
- 对于CA,\(Q\in\mathbb{R}^d\),\(Q\cdot K^T\in\mathbb{R}^{h\times 1\times p}\)。
- 对于SA,\(Q\in\mathbb{R}^{p\times d}\),\(Q\cdot K^T\in\mathbb{R}^{h\times p\times p}\)。
这意味着,与token数量成二次方的计算复杂度在CaiT层中变为线性计算负责度。
Experiments
Preliminary analysis with deeper architectures
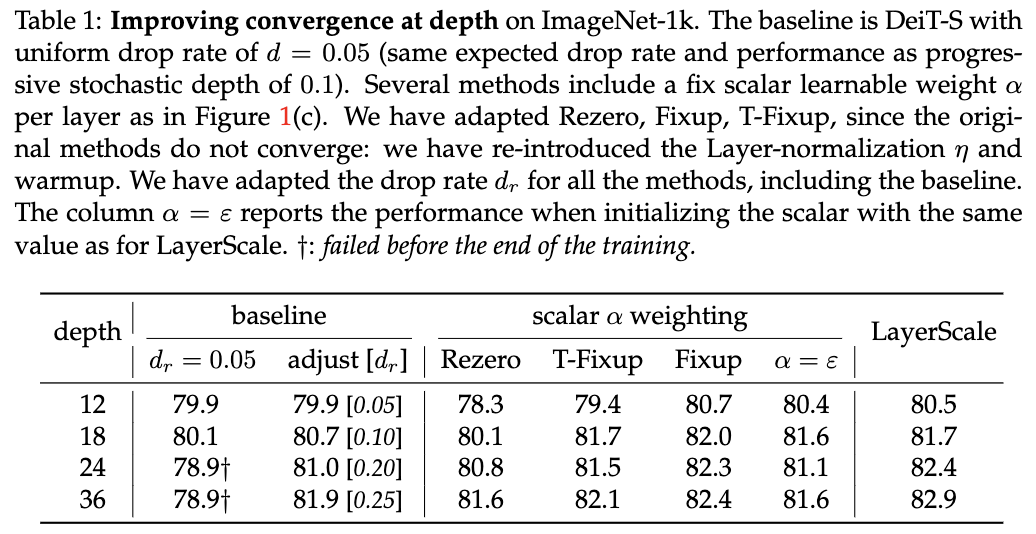
直接扩展网络深度,对不同训练超参数进行分析。
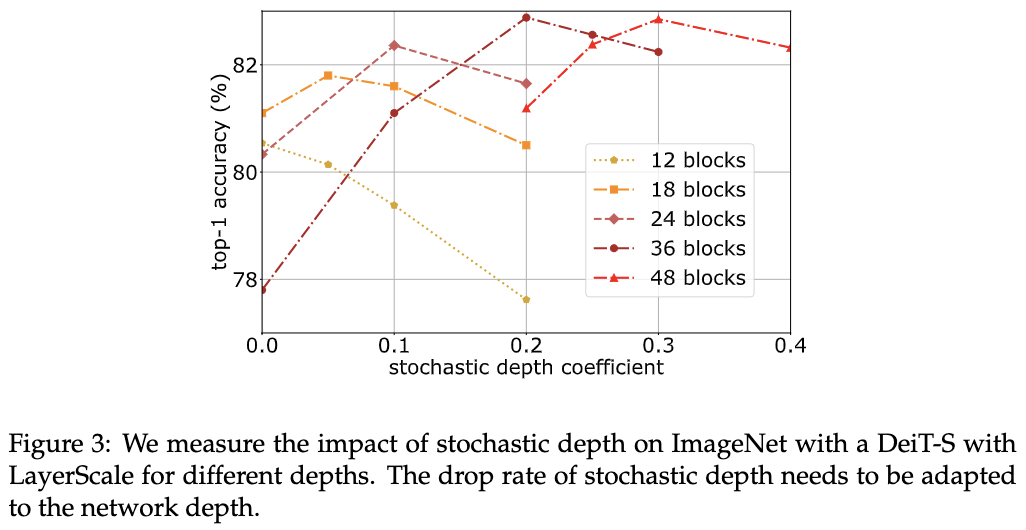
对比不同随机深度丢弃比例以及不同归一化策略的性能。
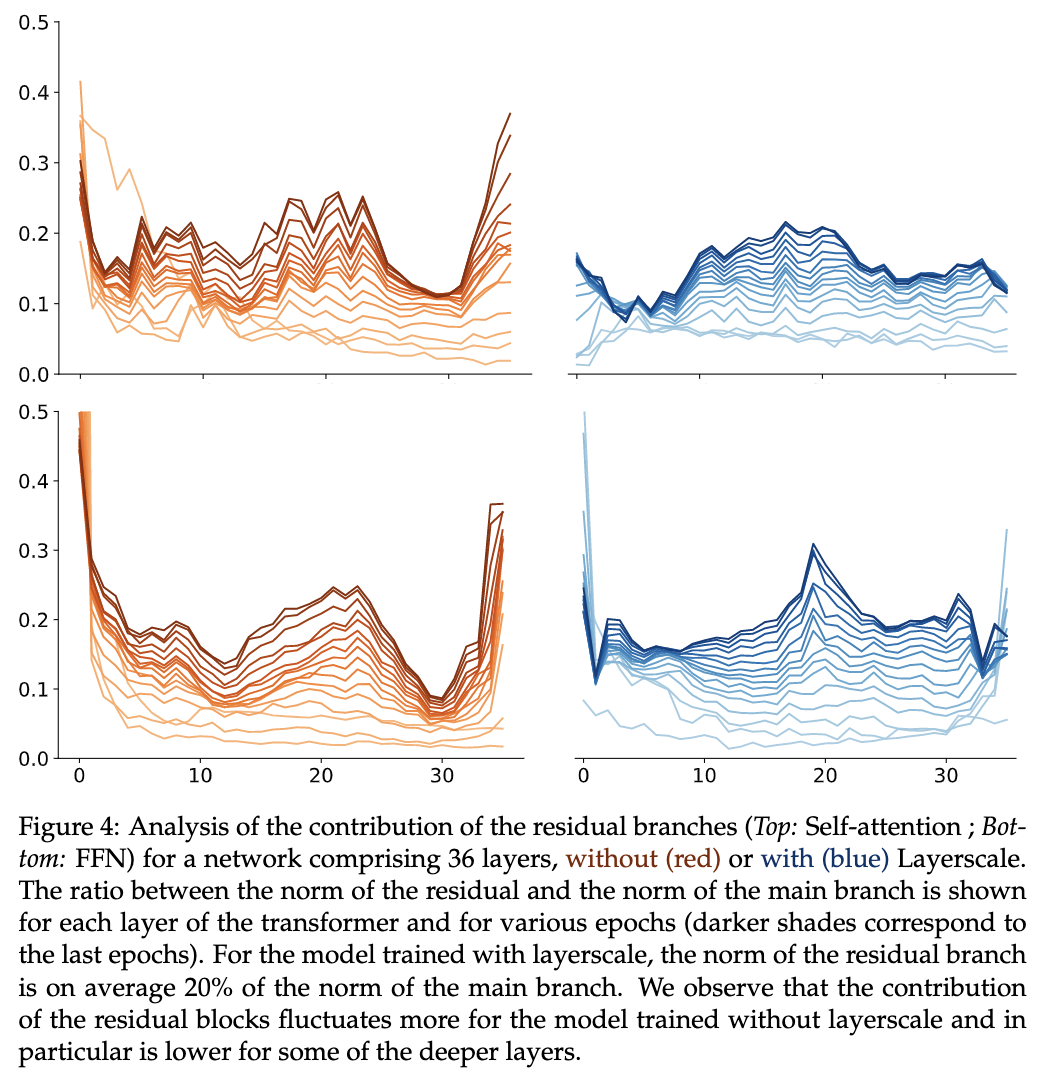
不同层的残差分支的权重可视化,使用LayerScale的权重会比较平稳。
Class-attention layers
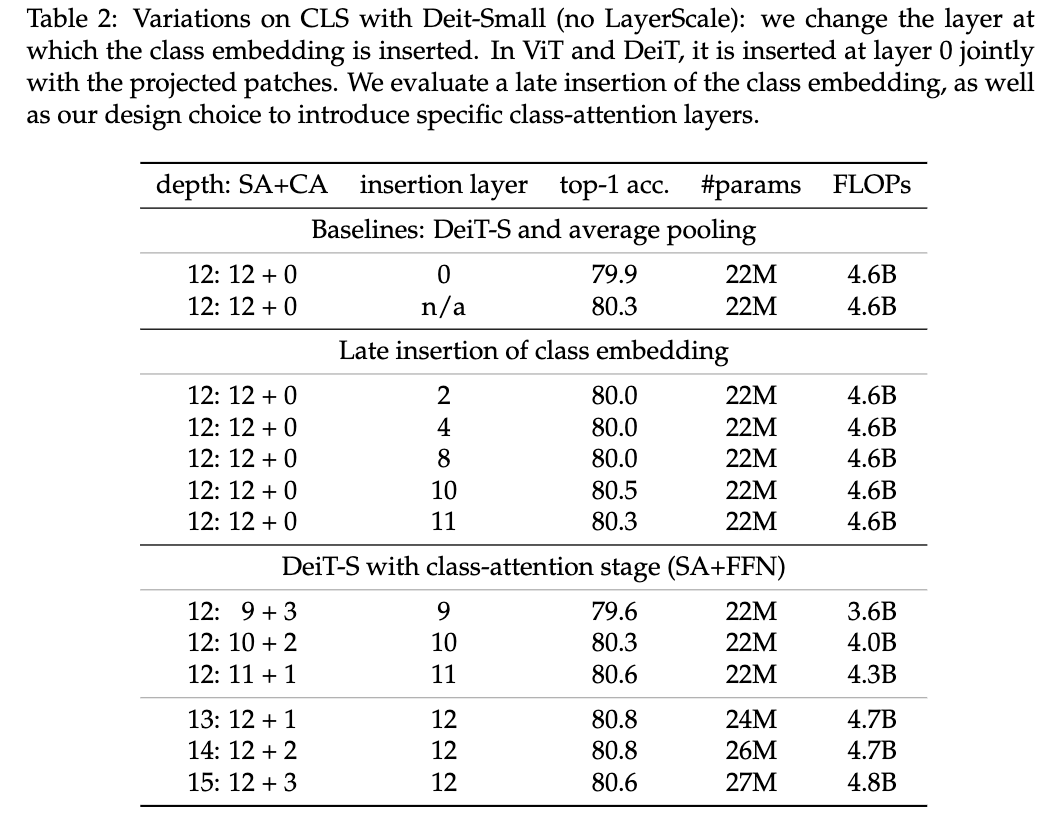
对图2的三种架构进行对比分析,最后是对比不同的SA和CA组合比例。
Our CaiT models
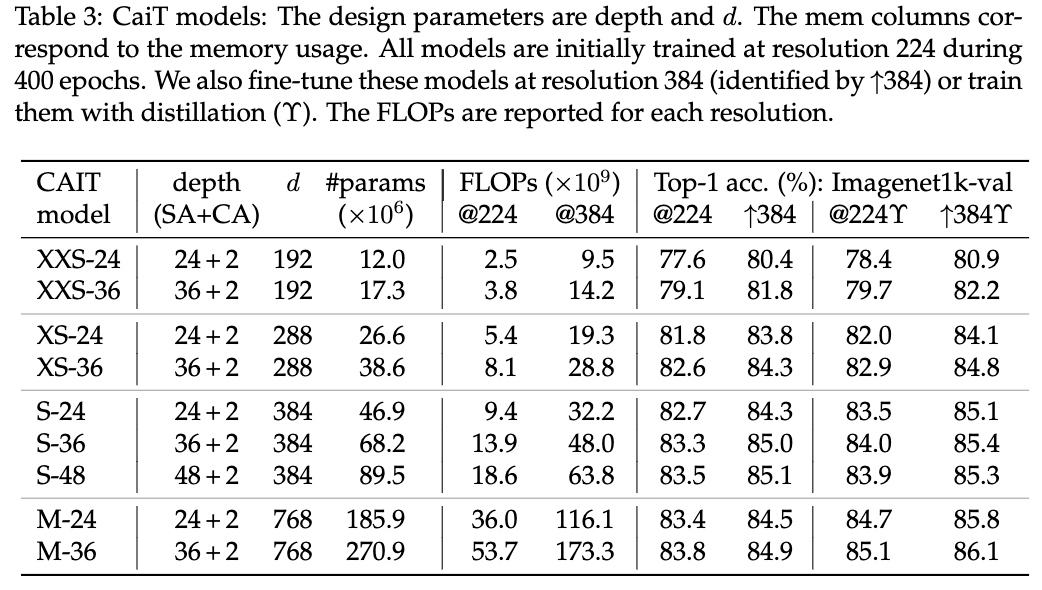

不同大小的CaiT模型性能对比以及对应的超参。
Results
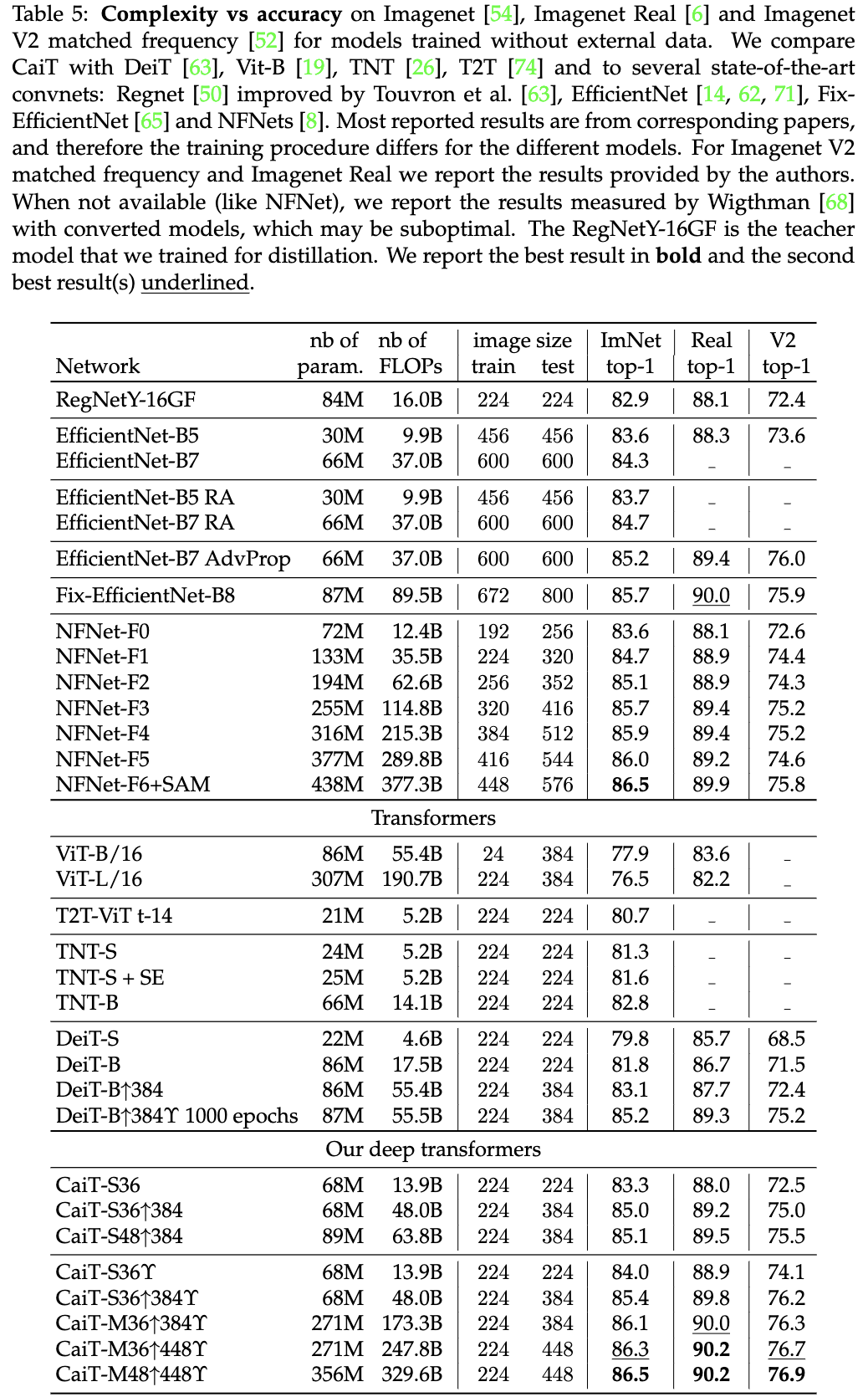
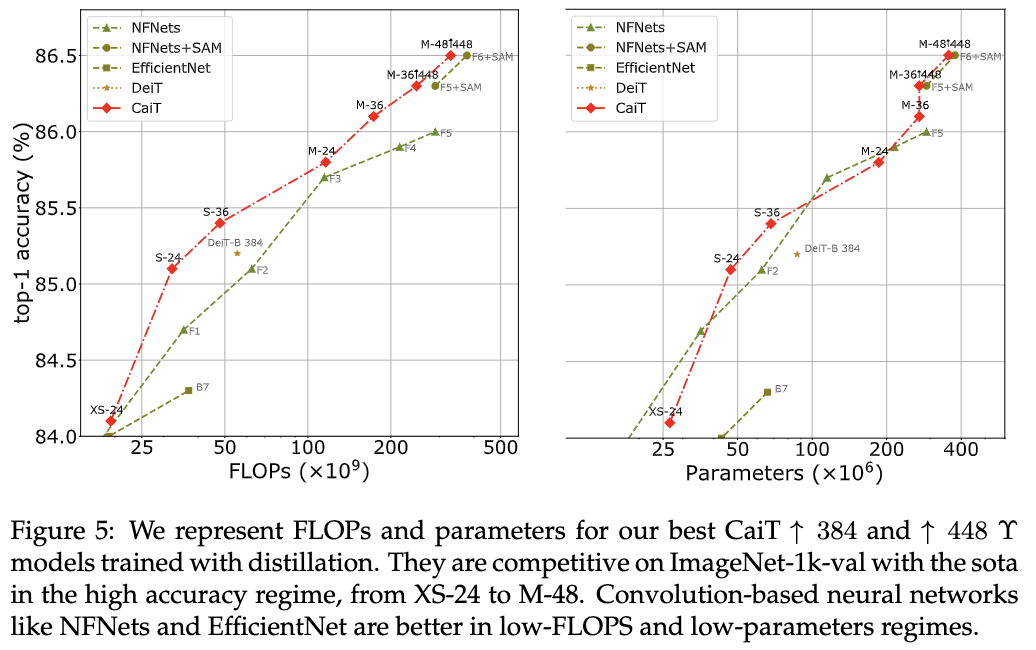
与SOTA模型对比,\(\uparrow\)代表使用高像素finetune,\(\gamma\)代表使用Deit的蒸馏训练。
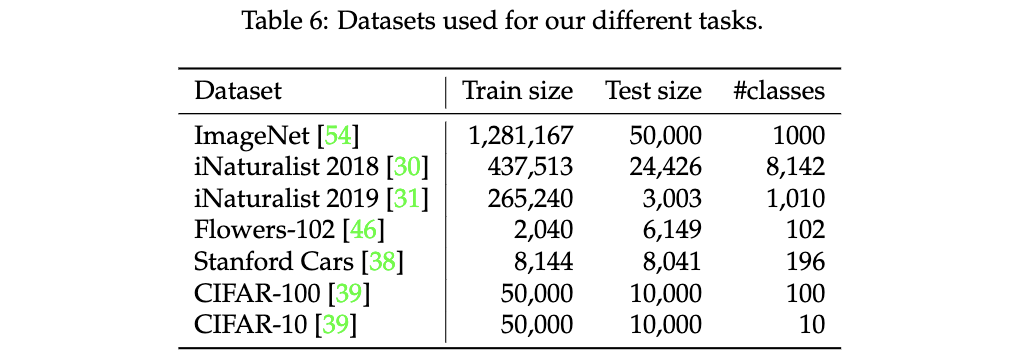
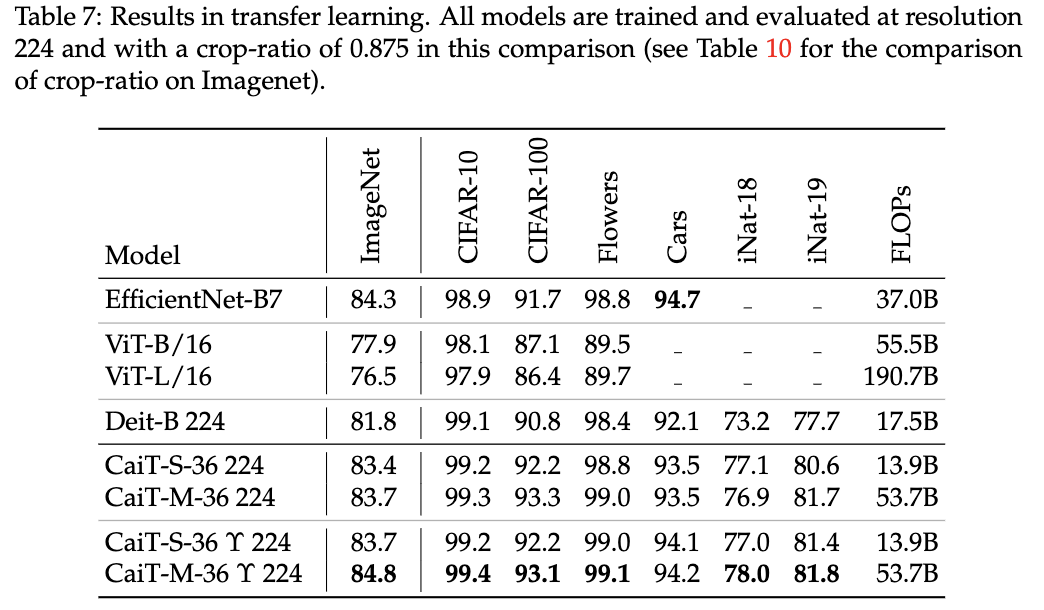
从ImageNet预训练迁移到其它分类数据集的性能对比。
Ablation
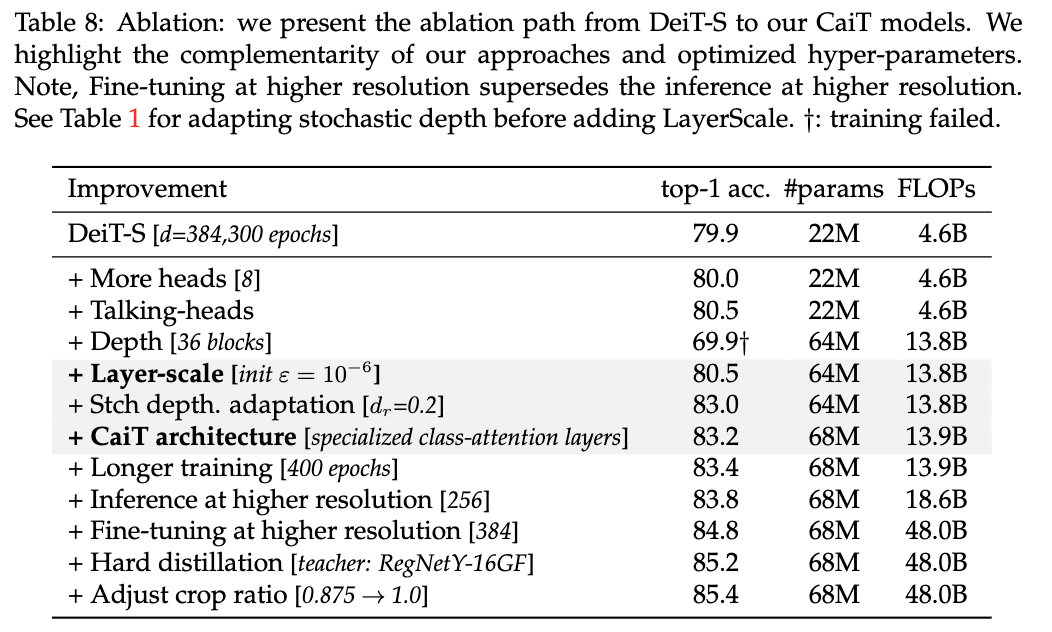
从DeiT过渡到CaiT的性能对比。
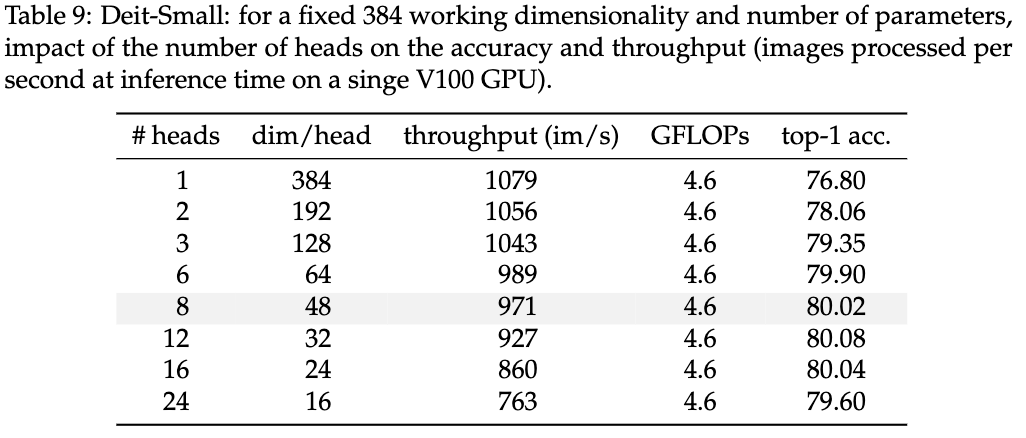
Head数量对性能的影响。
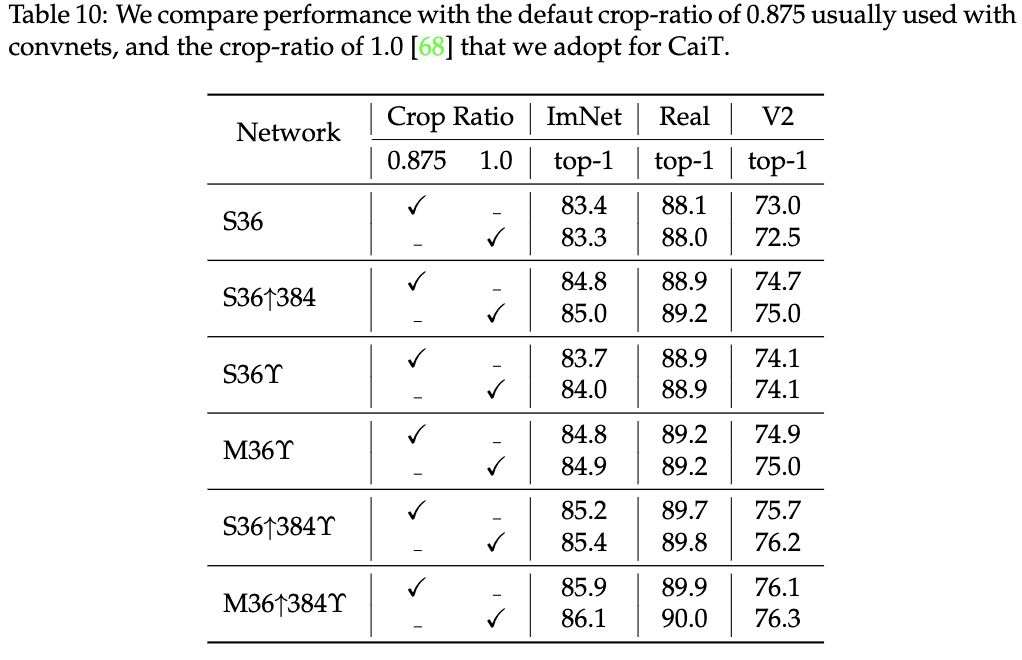
数据增强Crop Ratio对性能的影响。
Conclusion
CaiT通过LayerScale层来保证深度ViT训练的稳定性,加上将特征学习和分类信息提取隔离的class-attention层达到了很不错的性能,值得看看。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】

CaiT:Facebook提出高性能深度ViT结构 | ICCV 2021的更多相关文章
- NVIDIA TensorRT高性能深度学习推理
NVIDIA TensorRT高性能深度学习推理 NVIDIA TensorRT 是用于高性能深度学习推理的 SDK.此 SDK 包含深度学习推理优化器和运行时环境,可为深度学习推理应用提供低延迟和高 ...
- ICCV 2021口罩人物身份鉴别全球挑战赛冠军方案分享
1. 引言 10月11-17日,万众期待的国际计算机视觉大会 ICCV 2021 (International Conference on Computer Vision) 在线上如期举行,受到全球计 ...
- Facebook提出DensePose数据集和网络架构:可实现实时的人体姿态估计
https://baijiahao.baidu.com/s?id=1591987712899539583 选自arXiv 作者:Rza Alp Güler, Natalia Neverova, Ias ...
- 【深度森林第三弹】周志华等提出梯度提升决策树再胜DNN
[深度森林第三弹]周志华等提出梯度提升决策树再胜DNN 技术小能手 2018-06-04 14:39:46 浏览848 分布式 性能 神经网络 还记得周志华教授等人的“深度森林”论文吗?今天, ...
- 深度可分离卷积结构(depthwise separable convolution)计算复杂度分析
https://zhuanlan.zhihu.com/p/28186857 这个例子说明了什么叫做空间可分离卷积,这种方法并不应用在深度学习中,只是用来帮你理解这种结构. 在神经网络中,我们通常会使用 ...
- face recognition[翻译][深度人脸识别:综述]
这里翻译下<Deep face recognition: a survey v4>. 1 引言 由于它的非侵入性和自然特征,人脸识别已经成为身份识别中重要的生物认证技术,也已经应用到许多领 ...
- paper 53 :深度学习(转载)
转载来源:http://blog.csdn.net/fengbingchun/article/details/50087005 这篇文章主要是为了对深度学习(DeepLearning)有个初步了解,算 ...
- Facebook React完全解析
2004年,对于前端社区来说,是里程碑式的一年.Gmail横空出世,它带来基于前端渲染的原生应用级别的体验,相对于之前的服务端渲染网页可谓提升了一个时代,触动了用户的G点.自此,前端渲染的网站成为无数 ...
- 用深度学习(CNN RNN Attention)解决大规模文本分类问题 - 综述和实践
https://zhuanlan.zhihu.com/p/25928551 近来在同时做一个应用深度学习解决淘宝商品的类目预测问题的项目,恰好硕士毕业时论文题目便是文本分类问题,趁此机会总结下文本分类 ...
- [转] 用深度学习(CNN RNN Attention)解决大规模文本分类问题 - 综述和实践
转自知乎上看到的一篇很棒的文章:用深度学习(CNN RNN Attention)解决大规模文本分类问题 - 综述和实践 近来在同时做一个应用深度学习解决淘宝商品的类目预测问题的项目,恰好硕士毕业时论文 ...
随机推荐
- C 语言编程 — 指令行参数
目录 文章目录 目录 前文列表 命令行参数 前文列表 <程序编译流程与 GCC 编译器> <C 语言编程 - 基本语法> <C 语言编程 - 基本数据类型> < ...
- 10-flask博客项目
centos7 编译安装python3.7.1 安装步骤 centos7自带python2,由于执行yum需要python2,所以即使安装了python3也不能删除python21.安装依赖包yum ...
- Redis CPU过高排查
Redis CPU过高 测试环境经常卡住,经过排查是鉴权的不稳定,鉴权又经过redis查询.来到redis机器,发现cpu100%.redis的锅 top redis竟然cpu使用率达到100% 保存 ...
- 基于 GoLang 编写的 IOT 物联网在线直播抓娃娃企业级项目
基于 GoLang 编写的 IOT 物联网在线直播抓娃娃企业级项目 引言 前几年,娱乐物联网的热度很高.我当时所在的公司启动了一个将线下娃娃机的玩法,迁移到线上的项目,因此公司决定开发一个在线直播抓娃 ...
- Android 13 - Media框架(32)- ACodec(八)
关注公众号免费阅读全文,进入音视频开发技术分享群! 拖了好久都没有更新,前面写的东西都有些忘了,回过头来再看之前写的内容,觉得有很多地方写的不好,或者说现在又有了新的理解,想要重新修改但是需要修改的内 ...
- Deepin15.11+WIN10 双系统安装过程与遇到的问题(一)
一.deepin安装流程 1.下载 下载深度系统最新版本官网https://www.deepin.org/zh/download/下载深度系统专用U盘启动盘制作工具https://www.deepin ...
- 安装图形化界面时候报错 Transaction check error: file /boot/efi/EFI/centos from install of fwupdate-efi-12-5.el7.centos.x86_64 conflicts with file from package grub2-common-1:2.02-0.65.el7.centos.2.noarch
报错 Transaction check error:file /boot/efi/EFI/centos from install of fwupdate-efi-12-5.el7.centos.x8 ...
- vmware vmnat1和vmnat8在真机网络适配器中消失
在真机的网络适配器中,发现只有两张网卡.缺少vmnat1和vmnat8 一,查看虚拟网络编辑器是否连接 二,如果没有连接,勾选连接就好了. 三,如果连接了,真机网络适配器仍然只有两张网络适配器. 1. ...
- pandas rank()函数简介
本文简单的说一下自己对pandas的rank()函数的简单讲解. 函数原型:rank(axis=0, method: str = 'average', numeric_only: Union[bool ...
- 用 Sentence Transformers v3 训练和微调嵌入模型
Sentence Transformers 是一个 Python 库,用于使用和训练各种应用的嵌入模型,例如检索增强生成 (RAG).语义搜索.语义文本相似度.释义挖掘 (paraphrase min ...