初探语音识别ASR算法
摘要:语音转写文字ASR技术的基本概念与数学原理简介。
本文分享自华为云社区《新手语音入门(三): 语音识别ASR算法初探 | 编码与解码 | 声学模型与语音模型 | 贝叶斯公式 | 音素》,作者:黄辣鸡 。
语音识别技术的发展已有数十年发展历史,大体来看可以分成传统的识别的方法和基于深度学习网络的端到端的方法。
无论哪种方法,都会遵循“输入-编码-解码-输出”的过程。
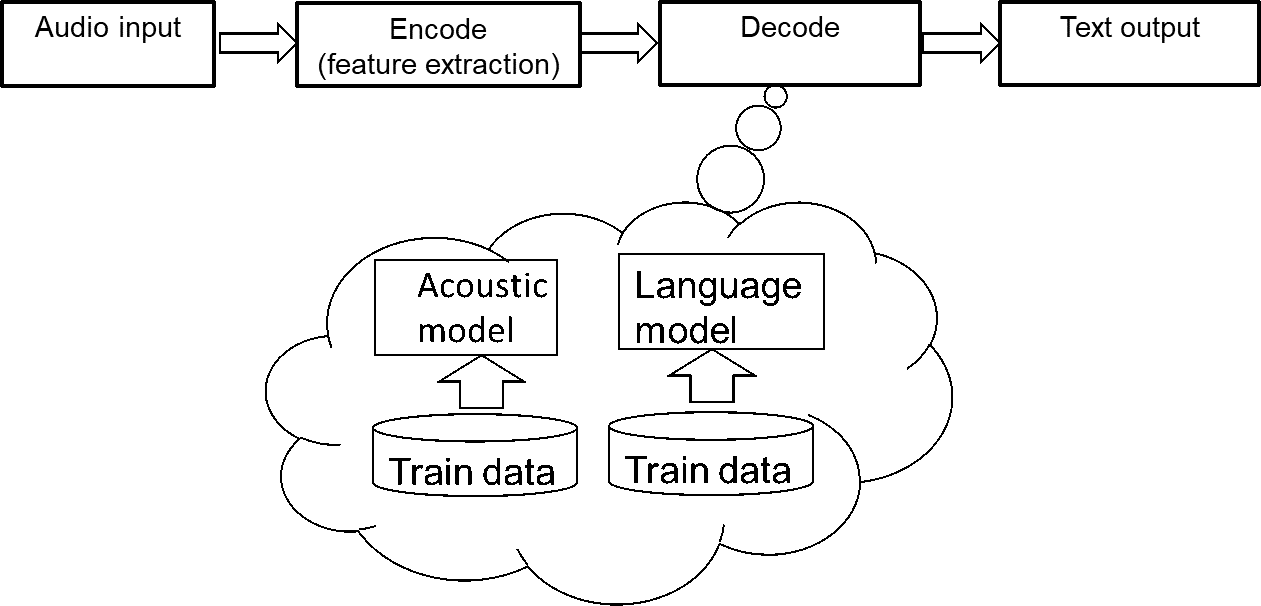
图1 语音识别过程
编码过程:
语音识别的输入是声音,属于计算机无法直接处理的信号,所以需要编码过程将其转变为数字信息,并提取其中的特征进行处理。编码时一般会将声音信号按照很短的时间间隔,切成小段,成为帧。对于每一帧,可以通过某种规则(例如MFCC特征)提取信号中的特征,将其变成一个多维向量。向量中的每个维度都是这帧信号的一个特征。

图2 语音识别编码过程
解码过程:
解码过程则是将编码得到的向量变成文字的过程,需要经过两个模型的处理,一个模型是声学模型,一个模型是语言模型。声学模型通过处理编码得到的向量,将相邻的帧组合起来变成音素,如中文拼音中的声母和韵母,再组合起来变成单个单词或汉字。语言模型用来调整声学模型所得到的不合逻辑的字词,使识别结果变得通顺。两者都需要大量数据用来训练。
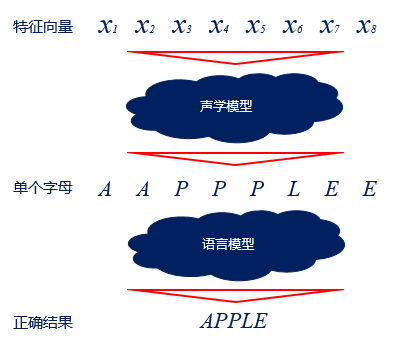
图3 语言模型处理过程
已知一段音频信号,处理成声学特征向量Acoustic Feature Vector后表示为X=[x1,x2,x3,…]X=[x1,x2,x3,…],其中x_ixi表示一帧特征向量;可能的文本序列表示为W=[w1,w2,w3,…]W=[w1,w2,w3,…],其中wi表示一个词,求W∗=argmaxwP(W∣X),这便是语音识别的基本出发点。并且由贝叶斯公式可知:
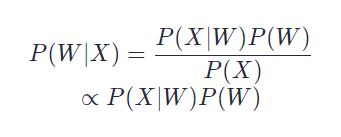
其中,P(X|W)P(X∣W)称之为声学模型(Acoustic Model, AM), P(W)P(W)称之为语言模型(Language Model, LM),由于P(W)P(W)一般是一个不变量,可以省去不算。
目前许多研究将语音识别问题看做声学模型与语音模型两部分,分别求取P(X|W)P(X∣W)和P(W)P(W)。后来,基于深度学习和大数据的端对端(End-to-End)方法发展起来,直接计算P(W|X)P(W∣X),把声学模型和语言模型融为了一体。
语音识别的问题可以看做是语音到文本的对应关系,语音识别问题大体可以归结为文本基本组成单位的选择上。单位不同,则建模力度也随之改变。
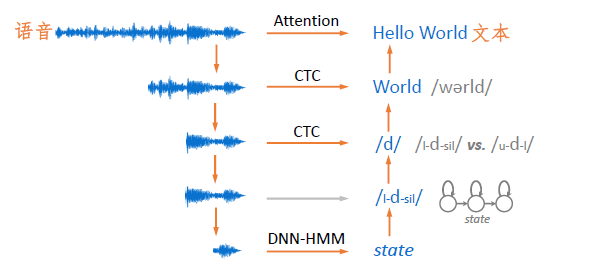
图4 语音识别的基本途径
根据图中文本基本组成单位从大到小分别是:
- 整句文本,如“Hello
World”,对应的语音建模尺度为整条语音。 - 词,如孤立词“Good”、“World”、对应的语音建模尺度大约为每个词的发音范围。
- 音素,如将“world”进一步表示为“/wɘrld//wɘrld/”,其中的每个音标作为基本单位,对应的语音建模尺度则缩减为每个音素的发音范围。
- 三音素,即考虑上下文的音素,如将音素“/d//d/”进一步表示为“{/l-d-sil, /u-d-l/,…}/l−d−sil,/u−d−l/,…”,对应的语音建模尺度是每个三音素的发音范围,长度与单音素差不多。
- 隐马尔可夫模型状态,即将每个三因素都用一个三状态隐马尔可夫模型表示,并用每个状态作为建模粒度,对应的语音建模尺度将进一步缩短。
上面每种实现方法都对应着不同的建模粒度,大体可以分为以隐马尔可夫模型结构和端对端的结构。后面两期博文将详细介绍基于两种结构的语音识别算法设计。
参考
- 语音识别基本法 - 清华大学语音和语言技术中心[PDF]
初探语音识别ASR算法的更多相关文章
- 语音识别ASR - HTK(HResults)计算字错率WER、句错率SER
HResults计算字错率(WER).句错率(SER) 前言 好久没发文,看到仍有这么多关注的小伙伴,觉得不发篇文对不住.确实好久没有输出经验总结相关的文档,抽了个时间,整理了下笔记,发一篇关于ASR ...
- .NetCore下B/S结构 初探基于遗传学算法的中学自动排课走班(二)
分析下染色体基因 这里用 老师 课程 班级 教室 周天 上下晚 课时作为染色体编码我封装了如下类 /// <summary> /// NP 授课事件 由教室.课程.班级 时间片段构成 li ...
- 初探STL之算法
算法 STL算法部分主要由头文件<algorithm>,<numeric>,<functional>组成.要使用 STL中的算法函数必须包括头文件<algor ...
- 初探DBSCAN聚类算法
DBSCAN介绍 一种基于密度的聚类算法 他最大的优势是可以发现任意形状的聚类簇,而传统的聚类算法只能使用凸的样本聚集类 两个参数: 邻域半径R和最少点数目minpoints. 当邻域半径R内的点的个 ...
- ASR测试方法---字错率(WER)、句错率(SER)统计
一.基础概念 1.1.语音识别(ASR) 语音识别(speech recognition)技术,也被称为自动语音识别(英语:Automatic Speech Recognition, ASR), 狭隘 ...
- FP-tree推荐算法
推荐算法大致分为: 基于物品和用户本身 基于关联规则 基于模型的推荐 基于物品和用户本身 基于物品和用户本身的,这种推荐引擎将每个用户和每个物品都当作独立的实体,预测每个用户对于每个物品的喜好程度,这 ...
- AI算法测评(二)--算法测试流程
根据算法测试过程中遇到的一些问题和管理规范, 梳理出算法测试工作需要关注的一些点: 编号 名称 描述信息 备注 1 明确算法测试需求 明确测试目的 明确测试需求, 确认测试需要的数据及场景 明确算法服 ...
- 花十分钟,让你变成AI产品经理
花十分钟,让你变成AI产品经理 https://www.jianshu.com/p/eba6a1ca98a4 先说一下你阅读本文可以得到什么.你能得到AI的理论知识框架:你能学习到如何成为一个AI产品 ...
- Jasper语音助理
1. 介绍 Jasper是一款基于树莓派的开源语音控制助理, 使用Python语言开发. Jasper工作原理主要是设备被动监听麦克风, 当收到唤醒关键字时进入主动监听模式, 此时收到语音指令后进行语 ...
- AI探索(一)基础知识储备
AI的定义 凡是通过机器学习,实现机器替代人力的技术,就是AI.机器学习是什么呢?机器学习是由AI科学家研发的算法模型,通过数据灌输,学习数据中的规律并总结,即模型内自动生成能表达(输入.输出)数据之 ...
随机推荐
- [论文研读]空天地一体化(SAGIN)的网络安全_A_Survey_on_Space-Air-Ground-Sea_Integrated_Network_Security_in_6G
------------恢复内容开始------------ 空天地一体化(SAGIN)的网络安全 目前关注的方面: 集中在安全通信.入侵检测.侧通道攻击.GPS欺骗攻击.网络窃听.消息修改/注入等方 ...
- Welcome to YARP - 5.压缩、缓存
目录 Welcome to YARP - 1.认识YARP并搭建反向代理服务 Welcome to YARP - 2.配置功能 2.1 - 配置文件(Configuration Files) 2.2 ...
- 排序:使数组唯一的最小增量 (3.22 leetcode每日打卡)
给定整数数组 A,每次 move 操作将会选择任意 A[i],并将其递增 1. 返回使 A 中的每个值都是唯一的最少操作次数. 示例 1: 输入:[1,2,2]输出:1解释:经过一次 move 操作, ...
- ELT安装
前言: ETL是将业务系统的数据经过抽取.清洗转换之后加载到数据仓库的过程, 目的是将企业中的分散.零乱.标准不统一的数据整合到一起,为企业的决策提供分析依据, ETL是BI(商业智能)项目重要的一个 ...
- 聊一聊 .NET高级调试 中必知的符号表
一:背景 1. 讲故事 在高级调试的旅行中,发现有不少人对符号表不是很清楚,其实简而言之符号表中记录着一些程序的生物特征,比如哪个地址是函数(签名信息),哪个地址是全局变量,静态变量,行号是多少,数据 ...
- windows端口被占用怎么办?
简单只需要按照一下命令查找到对应的端口kill掉就好了 1.查看本机所有的端口信息 netstat -ano 2.查看本机指定端口信息 netstat -ano | findstr "端口号 ...
- Java8新特性Stream流
1.是什么? Stream(流)是一个来自数据源的元素队列并支持聚合操作 2.能干嘛? Stream流的元素是特定类型的对象,形成一个队列. Java中的Stream并不会存储元素,而是按需计算. 数 ...
- 使用SPEL自定义表达式
自定义表达式 Spring提供了一个可以自定义表达式的接口 package com.qbb.qmall.item; import org.junit.Test; import org.springfr ...
- 自上而下的LL(1)语法分析法
LL(1)文法:从文法的开始符,向下推导,推出句子. 对文法G的句子进行确定的自顶向下语法分析的充分必要条件是,G的任意两个具有相同左部的 产生式A->α|β 满足下列条件: (1)如果α.β均 ...
- matlab 2018b 下载链接
matlab 2018b 功能强大下载地址为 https://pan.baidu.com/s/1QZO35BtzcIkh_yPYRIGVWg