pandas基础--汇总和计算描述统计
pandas含有是数据分析工作变得更快更简单的高级数据结构和操作工具,是基于numpy构建的。
本章节的代码引入pandas约定为:import pandas as pd,另外import numpy as np也会用到。
官方介绍:pandas - Python Data Analysis Library (pydata.org)
6 汇总和计算描述统计
pandas对象拥有一组常用的数学和统计方法,大部分术语约简和汇总设计,用于从Series中提取单个值或从DataFrame的行或列中提取一个Series。
DataFrame的sum方法会返回一个含有列小计的Series。
1 >>> df = pd.DataFrame([[1.4, np.nan], [7.1, -4.5], [np.nan, np.nan], [0.75, -1.3]], index=list('abcd'), columns=['one', 'two'])
2 >>> df
3 one two
4 a 1.40 NaN
5 b 7.10 -4.5
6 c NaN NaN
7 d 0.75 -1.3
8 >>>
9 >>> df.sum()
10 one 9.25
11 two -5.80
12 dtype: float64
13 >>> df.sum(axis=1)
14 a 1.40
15 b 2.60
16 c 0.00
17 d -0.55
18 dtype: float64
19 >>> df.mean(axis=1, skipna=False) #NA值会自动被排除,除非整个切片(指的行和列)都是NA
20 a NaN
21 b 1.300
22 c NaN
23 d -0.275
24 dtype: float64
25 >>>
下表是这些约简方法的常用选项。
| 选项 | 说明 |
|---|---|
| axis | 约简的轴。DataFrame的行用0,列用1 |
| skipna | 排除缺失值,默认为True |
| level | 如果轴是层次化索引的(即MultiIndex),则根据level分组简约 |
有些方法(如idxmin和idxmax)返回的是间接统计,也有一些是累计型的,还有一种方法,既不是约简型也不是累积性,如describe。
1 >>> df
2 one two
3 a 1.40 NaN
4 b 7.10 -4.5
5 c NaN NaN
6 d 0.75 -1.3
7 >>> df.idxmax() #间接统计
8 one b
9 two d
10 dtype: object
11 >>> df.cumsum() #累计型
12 one two
13 a 1.40 NaN
14 b 8.50 -4.5
15 c NaN NaN
16 d 9.25 -5.8
17 >>> df.describe() #一次性产生多个汇总数据
18 one two
19 count 3.000000 2.000000
20 mean 3.083333 -2.900000
21 std 3.493685 2.262742
22 min 0.750000 -4.500000
23 25% 1.075000 -3.700000
24 50% 1.400000 -2.900000
25 75% 4.250000 -2.100000
26 max 7.100000 -1.300000
对于非数值型数据,describe产生另外一种汇总统计。
1 >>> obj = pd.Series(['a', 'a', 'b', 'c'] * 4)
2 >>> obj
3 0 a
4 1 a
5 2 b
6 3 c
7 4 a
8 5 a
9 6 b
10 7 c
11 8 a
12 9 a
13 10 b
14 11 c
15 12 a
16 13 a
17 14 b
18 15 c
19 dtype: object
20 >>> obj.describe()
21 count 16
22 unique 3
23 top a
24 freq 8
25 dtype: object
26 >>>
下表是所有与描述统计相关的方法。
| 方法 | 说明 |
|---|---|
| count | 非NA值的数量 |
| describe | 针对Series或各DataFrame列计算汇总统计 |
| min、max | 计算最小值和最大值 |
| argmin、argmax | 计算能够获得最小值和最大值的索引位置(整数) |
| idxmin、idxmax | 计算能够获得最小值和最大值的索引值 |
| quantile | 计算样本的分位数(0到1) |
| sum | 值的总和 |
| mean | 值的平均数 |
| median | 值得算术中位数(50%分位数) |
| mad | 根据平均值计算平均绝对值偏差 |
| var | 样本值的方差 |
| std | 样本值的标准差 |
| skew | 样本值的偏离(三阶矩) |
| kurt | 样本值的峰度(四阶矩) |
| cumsum | 样本的累计和 |
| cummin、cummax | 样本值得累计最大值和累计最小值 |
| cumprod | 样本得累计积 |
| diff | 计算一阶差分(对时间序列很有用) |
| pct_change | 计算百分数变化,Percentage change between the current and a prior element. 时间序列比较有用 |
部分方法官方说明:
pandas.DataFrame.describe — pandas 1.3.4 documentation (pydata.org)
pandas.DataFrame.quantile — pandas 1.3.4 documentation (pydata.org)
pandas.DataFrame.mad — pandas 1.3.4 documentation (pydata.org)
来自百度:平均绝对离差(mean absolute deviation)是用样本数据相对于其平均值的绝对距离来度量数据的离散程度。平均绝对离差也称为平均离差(mean deviation)。平均绝对离差定义为各数据与平均值的离差的绝对值的平均数 。
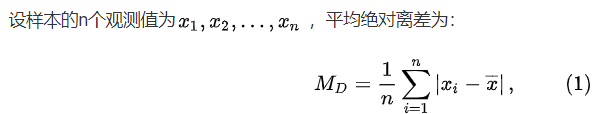
pandas.DataFrame.var — pandas 1.3.4 documentation (pydata.org)
样本方差:

pandas.DataFrame.std — pandas 1.3.4 documentation (pydata.org)

pandas.DataFrame.pct_change — pandas 1.3.4 documentation (pydata.org)
>>> df = pd.DataFrame([[1, np.nan], [2, 3], [np.nan, np.nan], [3, 3]], index=list('abcd'), columns=['one', 'two'])
>>> df
one two
a 1.0 NaN
b 2.0 3.0
c NaN NaN
d 3.0 3.0
>>> df.describe() #针对行操作
one two
count 3.0 2.0 #非NaN值的个数
mean 2.0 3.0 #样本值的平均值
std 1.0 0.0 #样本值的标准差
min 1.0 3.0 #样本的最小值
25% 1.5 3.0 #1+((3-1)/100)*25
50% 2.0 3.0 #中位数
75% 2.5 3.0 #1+((3-1)/100)*75
max 3.0 3.0 #样本的最大值
>>> df.quantile() #样本的分位数
one 2.0
two 3.0
Name: 0.5, dtype: float64
>>> df.quantile(q=0.25) #1+((3-1)/100)*25
one 1.5
two 3.0
Name: 0.25, dtype: float64
>>> df.mad() #样本的平均绝对离差
one 0.666667
two 0.000000
dtype: float64
>>> df.var() #样本的方差
one 1.0
two 0.0
dtype: float64
>>> df.std() #样本的标准差
one 1.0
two 0.0
dtype: float64
>>> df.cumsum() #样本的累加和
one two
a 1.0 NaN
b 3.0 3.0
c NaN NaN
d 6.0 6.0
>>> df.cummax() #样本值得累计最大值
one two
a 1.0 NaN
b 2.0 3.0
c NaN NaN
d 3.0 3.0
>>> df.cummin() #样本值得累计最小值
one two
a 1.0 NaN
b 1.0 3.0
c NaN NaN
d 1.0 3.0
>>> df.cumprod() #样本的累计积
one two
a 1.0 NaN
b 2.0 3.0
c NaN NaN
d 6.0 9.0
>>> df.pct_change() #百分数变化
one two
a NaN NaN
b 1.0 NaN #仅看one列,2.0比1.0大1倍,(2-1)/1 = 1
c 0.0 0.0
d 0.5 0.0 #仅看one列,3.0比2.0大0.5倍,(3.0-2.0)/2.0=0.5
6.2 相关系数和协方差
有些汇总统计(如相关系数和协方差)是通过参数对计算出来的。
Series的corr方法用于计算两个Series中重叠的、非NA的、按索引对齐的值的相关系数。
DataFrame的corr和cov方法将以DataFrame的形式返回完整的相关系数或协方差矩阵。
利用DataFrame的corrwith方法,可以计算其列或行跟另一个Series或DataFrame之间的相关系数。传入一个Series将会返回一个相关系数值Series(针对各列进行计算)。
传入一个DataFrame则会计算按列分配对的相关系数。
6.3 唯一值、值计数以及成员资格
从一维Series的值中抽取信息。
unique():可以得到Series中的唯一值数组;
value_counts():用于计算一个Series中各值出现的频率,也是一个顶级pandas方法;
isin():用于判断矢量化集合的成员资格。
1 >>> obj = pd.Series(list('cadaabbcc'))
2 >>> uniques = obj.unique()
3 >>> uniques
4 array(['c', 'a', 'd', 'b'], dtype=object)
5 >>> obj.value_counts()
6 a 3
7 c 3
8 b 2
9 d 1
10 dtype: int64
11 >>> pd.value_counts(obj.values, sort=False)
12 b 2
13 c 3
14 d 1
15 a 3
16 dtype: int64
17 >>> mask = obj.isin(['b', 'c'])
18 >>> mask
19 0 True
20 1 False
21 2 False
22 3 False
23 4 False
24 5 True
25 6 True
26 7 True
27 8 True
28 dtype: bool
29 >>> obj[mask]
30 0 c
31 5 b
32 6 b
33 7 c
34 8 c
35 dtype: object
pandas基础--汇总和计算描述统计的更多相关文章
- 利用Python进行数据分析(9) pandas基础: 汇总统计和计算
pandas 对象拥有一些常用的数学和统计方法. 例如,sum() 方法,进行列小计: sum() 方法传入 axis=1 指定为横向汇总,即行小计: idxmax() 获取最大值对应的索 ...
- python数据分析之Pandas:汇总和计算描述统计
pandas对象拥有一组常用的数学和统计方法,大部分都属于约简和汇总统计,用于从Series中提取单个的值,或者从DataFrame中的行或列中提取一个Series.相比Numpy而言,Numpy都是 ...
- 【学习】数据处理基础知识(汇总和计算描述统计)【pandas】
pd对象拥有一组常用的数学和统计方法.大部分都属于约简和汇总统计,用于从Series中单个值,如sum 和 mean 或从DF的行或列中提取一个Series. 1. 描述和汇总统计方法 #汇总和计算描 ...
- pandas汇总和计算描述统计
pandas 对象拥有一组常用的数学和统计方法. 他们大部分都属于简约和汇总统计, 用于从Series中提取单个值(如sum或mean) 或从DataFrame的行或列中提取一个Series.跟对应的 ...
- pandas(三)汇总和计算描述统计
pandas对象有一些常用的数学和统计的方法,大部分都属于约简或汇总统计. SUM方法 DataFrame对象的sum方法,返回一个含有列小计的Series >>> df = Dat ...
- pandas知识点(汇总和计算描述统计)
调用DataFrame的sum方法会返还一个含有列的Series: In [5]: df = DataFrame([[1.4,np.nan],[7.1,-4.5],[np.nan,np.nan],[0 ...
- 利用Python进行数据分析_Pandas_汇总和计算描述统计
申明:本系列文章是自己在学习<利用Python进行数据分析>这本书的过程中,为了方便后期自己巩固知识而整理. In [1]: import numpy as np In [2]: impo ...
- 利用Python进行数据分析(8) pandas基础: Series和DataFrame的基本操作
一.reindex() 方法:重新索引 针对 Series 重新索引指的是根据index参数重新进行排序. 如果传入的索引值在数据里不存在,则不会报错,而是添加缺失值的新行. 不想用缺失值,可以用 ...
- Python 数据分析(一) 本实验将学习 pandas 基础,数据加载、存储与文件格式,数据规整化,绘图和可视化的知识
第1节 pandas 回顾 第2节 读写文本格式的数据 第3节 使用 HTML 和 Web API 第4节 使用数据库 第5节 合并数据集 第6节 重塑和轴向旋转 第7节 数据转换 第8节 字符串操作 ...
- shell脚本语法基础汇总
shell脚本语法基础汇总 将命令的输出读入一个变量中,可以将它放入双引号中,即可保留空格和换行符(\n) out=$(cat text.txt) 输出1 2 3 out="$(cat te ...
随机推荐
- spring boot oauth2 取消认证
最近有一个项目需要从微服务中抽离,但是因为调用的包里关联了认证所以就算抽离处理还是会进oauth2默认的登入页面: @SpringBootApplication(exclude = {EurekaCl ...
- LeetCode - 最接近的三数之和
最接近的三数之和 你一个长度为 n 的整数数组 nums 和 一个目标值 target.请你从 nums 中选出三个整数,使它们的和与 target 最接近. 返回这三个数的和. 假定每组输入只存在恰 ...
- 力扣442(java)-数组中重复的数据(中等)
题目: 给你一个长度为 n 的整数数组 nums ,其中 nums 的所有整数都在范围 [1, n] 内,且每个整数出现 一次 或 两次 .请你找出所有出现 两次 的整数,并以数组形式返回. 你必须设 ...
- 三端一体计算方案:Unify SQL Engine
简介: 本文将介绍数仓建设过程中面对三种计算模式,较低的研发效率.不可控的数据质量,以及臃肿数据接口服务的困境的解决方案. 背景 在漫长的数仓建设过程中,实时数仓与离线数仓分别由不同的团队进行独立建设 ...
- 双龙贺岁,龙蜥 LoongArch GA 版正式发布
简介:Anolis OS 8.4 LoongArch 正式版发布产品包括 ISO.软件仓库.虚拟机镜像.容器镜像. 简介 继 Anolis OS LoongArch 预览版发布后,现迎来龙蜥 ...
- 阿里云云效发布研发协同工具,以新的产研协同工作方式助力实现BizDevOps
简介:2021云栖大会云效BizDevOps分论坛上,阿里云云效技术负责人陈鑫发布阿里云云效产品研发协同工具支撑ALPD理论,以新的产研协同工作方式助力实现BizDevOps. 编者按:10月21日 ...
- [DApp] ethers.js VS Moralis
ether.js 是 Web3 封装的 js 库,特别适合以太坊平台. Moralis 不仅是 Web3 的封装,还是一体化解决方案,包括服务端部署方案和适配各种链,使用范围更广. 在选择上,主要还是 ...
- [Go] gorm 错误处理 与 链式/Finisher方法
使用 gorm 在调用 Finisher 方法之后,建议都进行错误检查. Finishers 是会立即执行注册回调的方法,然后生成并执行 SQL,比如这些方法: Create, First, Find ...
- To Be Vegetable
求满足下述条件的 \(n\) 阶排列 \(a\) 的数目:对每个 \(i\),要么 \(a_i-i\le a_j-j+d\) 对所有 \(j\gt i\) 成立,要么 \(a_i\ge a_j\) 对 ...
- 2024-05-04:用go语言,给定一个起始索引为0的字符串s和一个整数k。 要进行分割操作,直到字符串s为空: 选择s的最长前缀,该前缀最多包含k个不同字符; 删除该前缀,递增分割计数。如果有剩余
2024-05-04:用go语言,给定一个起始索引为0的字符串s和一个整数k. 要进行分割操作,直到字符串s为空: 选择s的最长前缀,该前缀最多包含k个不同字符: 删除该前缀,递增分割计数.如果有剩余 ...