MindSpore实践:对篮球运动员目标的检测
摘要:本文讲述的是MindSpore对篮球运动员目标的检测应用,通过AI技术辅助对篮球赛场进行分析。
本文分享自华为云社区《MindSpore大V博文系列:AI对篮球运动员目标的检测》,原文作者:李锐锋。
MindSpore作为一个端边云协同的开源的全场景AI框架,今年3月份开源以来,受到了发展中国家的广泛关注和应用,欢迎大家参与开源贡献,模型众智合作,行业创新与应用,学术合作等,贡献您在云侧,端侧 (HiMindSpore应用程序),侧向以及安全领域的应用案例。MindSpore与您在AI领域共同成长,让AI使能千行百业,释放出强大的性能。 MindSpore对篮球运动员目标的检测应用,通过AI技术辅助对篮球赛场进行分析。
一、AI在篮球运动检测方面的使用
想必大家对篮球运动都比较熟悉,在看球赛时,通过我们的肉眼看到的画面,对赛场情况进行观察,可以分析出一些有用的信息。现在随着AI技术的迅速发展,通过深度学习算法也可以对篮球赛场上的画面进行学习,然后对篮球运动员的数量、行为等提取一些有用的信息,比如:通过对球员衣服颜**分出各篮球队的成员,也可以通过对球员的行为分析出球员正在执行什么动作以及赛场的比分等,如图1所示为通过ModelArts平台完成推理后展示的球员信息。

图1 深度学习推理出球员信息
那么怎么通过AI技术对篮球赛场进行分析呢,首先我们选择AI架构是基于华为自研AI计算框架MindSpore。MindSpore提供全场景统一API,为全场景AI的模型开发、模型运行、模型部署提供端到端能力。同时,MindSpore采用端-边-云按需写作分布式架构、微分原生编程新范式以及AI Native新执行模式,实现更好的资源效率、安全可信,同时降低行业AI开发门槛、释放昇腾芯片算力,助力普惠AI。
选择AI框架之后,我们这次选择的网络模型是基于MindSpore框架开发的yolov3_darknet53网络模型。
如果你想要查看篮球运动员检测的网络代码,可以访问MindSpore社区的开源代码,地址:https://github.com/mindspore-ai/mindspore-21-days-tutorials/tree/main/chapter4
在MindSpore开源社区也可以找到基于MindSpore框架的yolov3_darknet53网络的源码,使用的是coco2014数据集,参考链接:https ://gitee.com/mindspore/mindspore/tree/master/model_zoo/official/cv/yolov3_darknet53
以下是对该网络模型及应用实现的详细介绍。
二、yolo简介
yolo(You only look once)是一种经典的单阶段目标检测算法,在16年提出了第一个版本yolov1,后面还提出了多个版本,yolov3就是第三个版本。
yolo这个算法,在不同版本均有改进之处,下面大致介绍下yolov算法的三种版本的区别和改进:
1、yolov1是将目标检测作为回归问题来解决,使用一个神经网络直接从整个图片中预测边界框和类别概率,由于速度很快,所以可以做到实时目标检测
2、yolov2比yolov1速度很快,并且更准,改进点比较多,如:使用了BatchNorm,让网络更容易拟合;使用了anchor,去除了yolov1中的全连接层;使用了维度聚类的方法及多尺度训练等改进措施。
3、yolov3比yolov2精度会更高,不过速度会有点下降。yolov3的改进之处为:
1) 特征提取网络采用了残差结构,并且层数更多。
2) yolov3在3个尺度上进行检测,依次检测大、中、小目标。
三、yolov3网络结构
yolov3使用的基础网络是用Darknet53, Darknet53是全卷积结构,如图2所示,左边为yolov2的Darknet19,右边是yolov3使用的Darknet53。Darknet53去掉了所有的Maxpooling层,并增加了卷积层数。它总共有23个残差模块,经过5次下采样,最后网络输出是网络输入的1/32。因为网络加深的原因,yolov3网络的运行速度比yolov2稍慢。
yolov3网络结构中Conv2D block包含了5个卷积层,整个网络结构相对简单一些,同时,该网络为单阶段检测方法,相对faster rcnn 要容易许多。
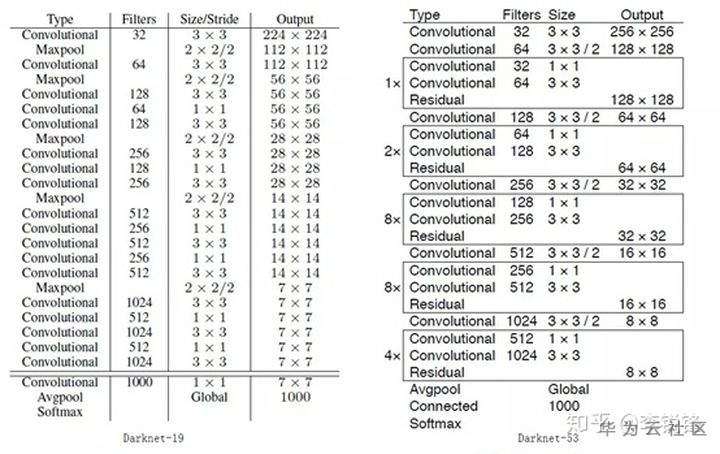
图2 Darknet网络结构
四、yolov3_darknet53在篮球运动检测方面的实现
我们选择的网络模型正是上一节中介绍的yolov3_darknet53模型,数据集则是一段篮球比赛相关的数据集,使用的AI框架是华为推出的MindSpore深度学习框架。最后,使用MindSpore的API来执行网络模型的训练和推理工作。
1、数据准备
本次使用的数据是图片数据,图片可以是在球赛现场拍摄的图片,也可以视频中的图片,我们这次使用的数据来源是网上下载篮球比赛相关的视频。
视频其实是有一帧一帧图片连续播放实现的,所以,反过来我们从视频中可以读取一帧一帧的图片,最后将图片保存到相关目录。由于视频中每秒包含的视频帧比较多,一些相邻的图片内容非常相似,看不出什么差异性,所以在获取视频帧时,适当插入时间间隔,按一定时间频率截取视频中的一张张图片,这样提取出来的图片差异性比较大,很少有相同的图片,这种数据的质量比较好。
生成好了数据后,还需要对数据进行标注,这个可以在华为云的ModelArts平台上进行数据标注操作,最后将准备好的数据拷贝到相应的目录当中,并且将数据集分成训练数据和推理数据,供后续模型训练和推理使用。
2、模型训练脚本
本次模型的搭建主要是调用MindSpore的API接口,如:可以调用context.set_context()接口配置现在使用的环境,如果我们环境用的是升腾910芯片,并且采用图模式进行训练,则可以通过以下指令进行配置:
context.set_context(mode=context.GRAPH_MODE, device_target="Ascend")
本次模型训练脚本,所用到的MindSpore相关接口如下所示:
import mindspore as ms
import mindspore.nn as nn
import mindspore.context as context
from mindspore import Tensor
from mindspore.nn.optim.momentum import Momentum
from mindspore.train.callback import ModelCheckpoint, RunContext
from mindspore.train.callback import _InternalCallbackParam, CheckpointConfig
from mindspore.train.serialization import load_checkpoint, load_param_into_net
这些配置或接口的使用在MindSpore官网上的教程和API文档都能找到详细的说明,官网链接:https : //www.mindspore.cn/tutorial/training/zh-CN/master/index.htm
yolov3_darknet53网络模型脚本的主要结构如下所示:

图3 yolov3_darknet53网络模型脚本结构
下面介绍下网络结构中主要的一些脚本。
1) train.py:这是该网络的训练脚本,主要是配置环境参数、网络调用、预训练模型的调用、训练数据集读取、优化器配置、ckpt文件保存设置、模型训练脚本等。在模型训练时,需要配置一些训练参数,这些参数可以在src目录下的config.py文件中设置好,也可以在执行训练命令时,将参数传入给训练模型,这个下面会有说明。以下是训练脚本的部分代码,分别是配置环境参数、网络调用、数据集读取、优化器配置等,仅供参考。
context.set_context(mode=context.GRAPH_MODE, enable_auto_mixed_precision=True,
device_target="Ascend", save_graphs=False)
network = YOLOV3DarkNet53(is_training=True)
ds, data_size = create_yolo_dataset(image_dir=os.path.join(local_data_path, 'images'), anno_path=os.path.join(local_data_path, 'annotation.json'), is_training=True, batch_size=args.per_batch_size, max_epoch=args.epoch_size, device_num=args.group_size, rank=args.rank, config=config)
opt = Momentum(params=get_param_groups(network), learning_rate=Tensor(lr),
momentum=args.momentum,
weight_decay=args.weight_decay,
loss_scale=args.loss_scale)
2) eval.py:这是该网络的推理模型,yolov3_darknet53网络做推理时,也需要配置环境、网络调用、推理数据集读取、主要还需要使用网络训练时保存好的训练模型、推理等,为了对推理过程的了解,需要打印一些推理过程中生成的一些日志信息。以下为实现推理过程的部分代码,仅供参考。
context.set_context(mode=context.GRAPH_MODE, device_target="Ascend", save_graphs=False)
network = YOLOV3DarkNet53(is_training=False)
param_dict = load_checkpoint(local_ckpt_path)
param_dict_new = {}
for key, values in param_dict.items():
if key.startswith('moments.'):
continue
elif key.startswith('yolo_network.'):
param_dict_new[key[13:]] = values
else:
param_dict_new[key] = values
load_param_into_net(network, param_dict_new)
detection = DetectionEngine(args)
input_shape = Tensor(tuple(config.test_img_shape), ms.float32)
for i, data in enumerate(ds.create_dict_iterator()):
image = Tensor(data["image"])
image_shape = Tensor(data["image_shape"])
image_id = Tensor(data["img_id"])
prediction = network(image, input_shape)
output_big, output_me, output_small = prediction
output_big = output_big.asnumpy()
output_me = output_me.asnumpy()
output_small = output_small.asnumpy()
image_id = image_id.asnumpy()
image_shape = image_shape.asnumpy()
detection.detect([output_small, output_me, output_big], args.per_batch_size,
image_shape, image_id, config=config)
3) src目录下主要是训练脚本和推理脚本需要调用的一些模块,如:yolo.py文件中主要的yolov3_darknet53网络结构脚本、yolo_dataset.py文件是模型读取并处理数据的脚本等。
4) scripts目录下则是网络模型训练和推理运行时候的一些执行命令,整合到sh文件中,方面直接执行,如:训练执行命令可以参考如下方式:
python train.py \
--data_dir=./dataset/coco2014 \
--pretrained_backbone=darknet53_backbone.ckpt \
--is_distributed=0 \
--lr=0.001 \
--loss_scale=1024 \
--weight_decay=0.016 \
--T_max=320 \
--max_epoch=320 \
--warmup_epochs=4 \
--training_shape=416 \
--lr_scheduler=cosine_annealing > log.txt 2>&1 &
3、模型推理
yolov3_darknet53网络可以对批量数据进行推理,这里有一点需要注意,推理的数据和训练的数据要分开,它们之间不要有相同的数据,否则影响到最后的推理精度。
在做模型推理时,有两个参数对最后的结果影响比较大:
1) ignore_threshold:这个参数是设置最后推理结果的置信度,比如,最后对目标检测出的目标置信度有大有小,置信度越大,说明推理的结果正确的概率越大,反之,则结果正确的概率越小。这时可以设置改置信度的大小,将小于该置信度的目标剔除,这对最后的结果展示效果会有较好帮助。
2) nms_thresh:该参数是设置检测的目标框的重合度,当两个框的重合度大于该参数时,则认为这两个目标是同一个目标,只显示一个框,反之,当两个框的重合度小于该参数时,则两个框都保留。 以上两个参数的设置需要一些现场的经验,根据现场实际情况进行调整。
五、总结与扩展
yolov3相比yolov2加深了网络,并采用了3中尺度进行检测,引入了更多的anchor,速度虽然有所下降,但是提升了精度,对检测小目标来说,效果要更好。
yolov3可广泛应用在图像分类、图像检测等方面,如人员戴口罩检测、特殊区域安全帽佩戴检测等。总之,通过深度学习算法这种AI技术已深入到生活各个方面,减少人工的干预,提高人员的安全性,给生活带来很大便利等。感兴趣的童鞋尽快动手试试吧。
MindSpore实践:对篮球运动员目标的检测的更多相关文章
- RCNN (Regions with CNN) 目标物检测 Fast RCNN的基础
Abstract: 贡献主要有两点1:可以将卷积神经网络应用region proposal的策略,自底下上训练可以用来定位目标物和图像分割 2:当标注数据是比较稀疏的时候,在有监督的数据集上训练之后到 ...
- 编写Java程序,模拟教练员和运动员出国比赛场景,其中运动员包括乒乓球运动员和篮球运动员。教练员包括乒乓球教练和篮球教练。为了方便出国交流,根乒乓球相关的人员都需要学习英语。
需求说明: 模拟教练员和运动员出国比赛场景,其中运动员包括乒乓球运动员和篮球运动员.教练员包括乒乓球教练和篮球教练.为了方便出国交流,根乒乓球相关的人员都需要学习英语.具体分析如下: (1)共同的属性 ...
- 以resnet作为前置网络的ssd目标提取检测
http://blog.csdn.net/zhangjunbob/article/details/53119959
- 目标检测:YOLO(v1 to v3)——学习笔记
前段时间看了YOLO的论文,打算用YOLO模型做一个迁移学习,看看能不能用于项目中去.但在实践过程中感觉到对于YOLO的一些细节和技巧还是没有很好的理解,现学习其他人的博客总结(所有参考连接都附于最后 ...
- [炼丹术]YOLOv5目标检测学习总结
Yolov5目标检测训练模型学习总结 一.YOLOv5介绍 YOLOv5是一系列在 COCO 数据集上预训练的对象检测架构和模型,代表Ultralytics 对未来视觉 AI 方法的开源研究,结合了在 ...
- [目标检测]YOLO原理
1 YOLO 创新点: 端到端训练及推断 + 改革区域建议框式目标检测框架 + 实时目标检测 1.1 创新点 (1) 改革了区域建议框式检测框架: RCNN系列均需要生成建议框,在建议框上进行分类与回 ...
- [目标检测]PVAnet原理
创新点:基于Faster-RCNN使用更高效的基础网络 1.1 创新点 PVAnet是RCNN系列目标方向,基于Faster-RCNN进行改进,Faster-RCNN基础网络可以使用ZF.VGG.Re ...
- 目标检测之YOLO V1
前面介绍的R-CNN系的目标检测采用的思路是:首先在图像上提取一系列的候选区域,然后将候选区域输入到网络中修正候选区域的边框以定位目标,对候选区域进行分类以识别.虽然,在Faster R-CNN中利用 ...
- AI佳作解读系列(二)——目标检测AI算法集杂谈:R-CNN,faster R-CNN,yolo,SSD,yoloV2,yoloV3
1 引言 深度学习目前已经应用到了各个领域,应用场景大体分为三类:物体识别,目标检测,自然语言处理.本文着重与分析目标检测领域的深度学习方法,对其中的经典模型框架进行深入分析. 目标检测可以理解为是物 ...
- 第十八节、基于传统图像处理的目标检测与识别(HOG+SVM附代码)
其实在深度学习中我们已经介绍了目标检测和目标识别的概念.为了照顾一些没有学过深度学习的童鞋,这里我重新说明一次:目标检测是用来确定图像上某个区域是否有我们要识别的对象,目标识别是用来判断图片上这个对象 ...
随机推荐
- 【PHP正则表达式】
[PHP正则表达式] 最近写题总是遇到php正则表达式的匹配函数,于是进行一个总结. 1.什么是正则表达式 是php在进行搜索时用于匹配的模式字符串.一般用于php对特定字符序列的替换和搜索. 2.正 ...
- 网络层IP数据包
网络层 功能 选择数据通过网络(IP地址)的最佳路径 协议字段 版本号(4bit):指IP协议版本.并且通信双方使用的版本必须一致,目前我们使用的是IPv4,表示为0100 十进制 是4 首部长度(4 ...
- 机器学习实战5-KMeans聚类算法
概述 聚类 VS 分类 有监督学习 VS 无监督学习 sklearn中的聚类算法 KMeans KMeans参数&接口 n_clusters n_clusters就是KMeans中的K就是告诉 ...
- 从windows到linux,图形化操作到命令行操作讲解
作为一个后端开发人员,刚开始进入到职场中,linux还不是必备项.但是随着开发经验的提升,慢慢就会接触到linux,所以就有了那句:开发必须要会linux.一开始我也不知道linux是干嘛的,学那些命 ...
- JavaScript 简介与引用
作者:WangMin 格言:努力做好自己喜欢的每一件事 我们通常写好的HTML网页是处于一个静态的效果,在用户体验这一方面就不是很好,给人一种死板的感觉.这里我们就可以用到JavaScript来为网页 ...
- 国产瀚高数据库简单实践 及 authentication method 13 not supported 错误解决方法
近几年IT界软硬件"国产化"搞得很密集,给很多公司带来了商机.但是有些公司拿国外的代码改改换个皮肤,就是"自主知识产权"的国产软件,光明正大卖钱,这个有点... ...
- C#中HttpWebQuest发起HTTP请求,如何设置才能达到最大并发和性能
在C#中使用HttpWebRequest发起HTTP请求时,达到最大并发和性能可以从以下几个方面改进: 1. ServicePointManager设置 ServicePointManager 类是一 ...
- 初探webpack之单应用多端构建
初探webpack之单应用多端构建 在现代化前端开发中,我们可以借助构建工具来简化很多工作,单应用多端构建就是其中应用比较广泛的方案,webpack中提供了loader与plugin来给予开发者非常大 ...
- [ABC278G] Generalized Subtraction Game
Problem Statement This is an interactive task (where your program interacts with the judge's program ...
- 效率工具:Hutool 嘎嘎香,被秀到了!
在日常开发中,我们会使用很多工具类来提升项目开发的速度,而国内用的比较多的 Hutool 框架,就是其中之一. 先来看官方对于 Hutool 的定义: Hutool 是一个小而全的 Java 工具类库 ...