[转帖]TIDB - 使用BR工具进行数据热备份与恢复
一、BR工具
BR 全称为 Backup & Restore,是 TiDB 分布式备份恢复的命令行工具,用于对 TiDB 集群进行数据备份和恢复。BR 只支持在 TiDB v3.1 及以上版本使用。
在前面的章节中,我们介绍了dumpling将数据导出的方式,也可以作为一种备份的方式,并且导出的数据是极为可读的sql文件,并且也可以将数据导入Mysql中,但是在买对大数据量下快速的全量备份的场景在使用dumpling导成sql文件就显得效率低下了,并且会降低TIDB的读写的QPS。同样BR工具就不同了,他是直接将TIDB存储的sst文件进行转存备份,除去了转化为SQL的工作量,但也有弊端,导出的数据是不可读的二进制数据,但仅对TIDB数据进行备份已经足够强大了。
因此相比 dumpling,BR 更适合大数据量的场景。
BR 将备份或恢复操作命令下发到各个 TiKV 节点。TiKV 收到命令后执行相应的备份或恢复操作。
在一次备份或恢复中,各个 TiKV 节点都会有一个对应的备份路径,TiKV 备份时产生的备份文件将会保存在该路径下,恢复时也会从该路径读取相应的备份文件。

二、准备工作
在数据备份前,先了解下BR备份的存储目录,TIDB默认会将每个TIKV节点的数据存储在本节点上,但这样就不利于数据的恢复,因为在恢复是每个TIKV节点读到的必须为全部备份数据,否则就会报各种奇葩的错误。因此在恢复时要么将每个TIKV节点中备份的数据拷贝到其他的节点中,要么就采用共享存储、远程磁盘挂载的方式,在文本中我们是采用共享存储、远程磁盘挂载的方式进行演示。
1. 查看集群状态
在备份之前先来看下我的TIDB集群的状态:
tiup cluster display tidb-test
- 1
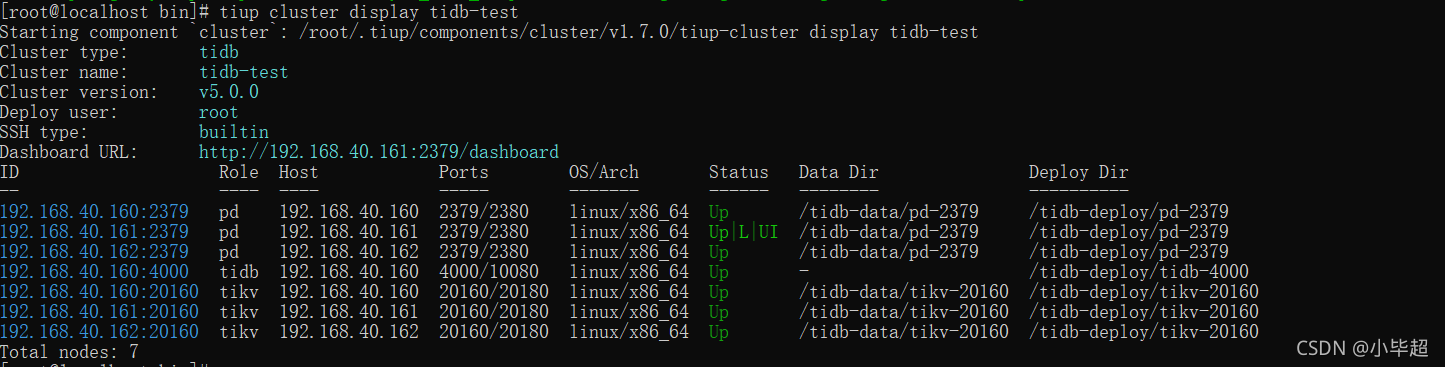
我的集群架构是,一个tidb-server,三台pd-server ,三台tikv-server,分别在160、161、162三个主机上。
2. 创建NFS目录挂载
关于NFS目录的挂载,请参考下面一篇我的博客,专门讲解了CenterOS下目录远程挂载的方式。
https://blog.csdn.net/qq_43692950/article/details/121591360
这里我们NFS服务器是装在了160中,接着我们在每个主机的根目录下都创建 /nfs/data目录,作为备份存储的目录:
mkdir -p /nfs/data && chmod -R 777 /nfs/data
- 1
然后将161和162中的/nfs/data挂载到160中:
mount 192.168.40.160:/nfs/data /nfs/data
- 1
挂载之后可以在161或162中/nfs/data下随便创建个文件,看其他节点是否可以读到文件,以验证挂载是否成功。
3. 下载tidb-toolkit工具
wget https://download.pingcap.org/tidb-toolkit-v5.0.1-linux-amd64.tar.gz
- 1
tar xvf tidb-toolkit-v5.0.1-linux-amd64.tar.gz
- 1
cd tidb-toolkit-v5.0.1-linux-amd64/bin/
- 1
可以看到里面有很多工具,包括我们在数据迁移文章中使用的dumpling、tidb-lightning等,这次我们就需要BR工具即可。
三、开始备份
在备份前先看下我们TIDB 中的数据:

可以看到我们有个testdb库及user表,并且表中仅有几条数据。
下面进入到上面解压出来的工具目录bin下,有以下下面指令:
对数据进行全备份:
./br backup full --pd "192.168.40.160:2379" --storage "local:///nfs/data" --ratelimit 120 --log-file backupfull.log- 1
–pd :连接 TiDB 数据库的 PD 节点,最好在 PD 节点上执行,即连接本节点。
–storage :备份文件存储在 TiKV 节点上的位置,使用我们的挂载目录。
–ratelimit :对于备份所用存储带宽限速,以免影响线上业务。
–log-file : 备份日志文件上面是对整个TIDB上的所有的库进行备份,如果就想备份某个数据库,则可以:
./br backup db --pd "192.168.40.160:2379" --db "testdb" --storage "local:///nfs/data" --log-file restoredb.log- 1
通过 --db 来指定数据库。
如果就想备份某个表:
./br backup db --pd "192.168.40.160:2379" --db "testdb" --table salaries --storage "local:///nfs/data" --log-file restoredb.log- 1
通过–table来指定表。
我们采用对某个数据库进行备份的方式,备份testdb数据库:
./br backup db --pd "192.168.40.160:2379" --db "testdb" --storage "local:///nfs/data" --log-file restoredb.log
- 1

查看备份文件

四、数据恢复
上面我们已经备份了数据,在恢复前,我们先删除testdb数据库:

下面还是进入到bin下,使用br restore 命令:
./br restore db --pd "192.168.40.160:2379" --db "testdb" --storage "local:///nfs/data" --log-file restoredb.log
- 1
参数和上面备份时的参数含义一样。

查看restoredb.log日志文件,可以看到已经成功。

再次查看数据库和表:

已恢复到最初的状态。

喜欢的小伙伴可以关注我的个人微信公众号,获取更多学习资料!


微信公众号

专注于JAVA、微服务、中间件等技术分享
[转帖]TIDB - 使用BR工具进行数据热备份与恢复的更多相关文章
- 微信小程序开发工具的数据,配置,日志等目录在哪儿? 怎么找?
原文地址:http://www.wxapp-union.com/portal.php?mod=view&aid=359 本文由本站halfyawn原创:感谢原创者:如有疑问,请在评论内回复 ...
- Linux下使用SSH、Crontab、Rsync三工具实现数据自动备份
Linux下使用SSH.Crontab.Rsync三工具实现数据自动备份 作为网管人员大概都无一例外的经历过系统备份,尤其是重要系统的备份.重要数据库系统的备份工作.由于备份是个频繁而琐碎的工作,如何 ...
- Navicat premium工具转储数据表的结构时,datatime字段报错
Navicat premium工具导出数据库: Navicat premium工具导入数据库: 运行SQL文件,遇到的错误,红色下划线提示,发现:(SQL文件的时间有问题) 不是insert语句有问题 ...
- [转帖]PostgreSQL pg_dump&psql 数据的备份与恢复
PostgreSQL pg_dump&psql 数据的备份与恢复 https://www.cnblogs.com/chjbbs/p/6480687.html 文章写的挺好 今天试了下 挺不 ...
- 使用neo4j图数据库的import工具导入数据 -方法和注意事项
背景 最近我在尝试存储知识图谱的过程中,接触到了Neo4j图数据库,这里我摘取了一段Neo4j的简介: Neo4j是一个高性能的,NOSQL图形数据库,它将结构化数据存储在网络上而不是表中.它是一个嵌 ...
- Nebula Exchange 工具 Hive 数据导入的踩坑之旅
摘要:本文由社区用户 xrfinbj 贡献,主要介绍 Exchange 工具从 Hive 数仓导入数据到 Nebula Graph 的流程及相关的注意事项. 1 背景 公司内部有使用图数据库的场景,内 ...
- Oracle数据库用户数据完整备份与恢复
使用PLSQL-Developer工具可以快速便捷地完成Oracle数据库用户.表的备份恢复. Oracle数据库用户数据完整备份与恢复 1. 备份 1.1 PL/SQL->工具->导 ...
- MongoDB 数据文件备份与恢复
备份与恢复数据对于管理任何数据存储系统来说都是非常重要的. 1.冷备份与恢复——创建数据文件的副本(前提是要停止MongoDB服务器),也就是直接copy MongoDB将所有数据都存储在数据目录下, ...
- Windows Server 2008 R2 数据离机备份与恢复操作手册
Windows Server 2008 R2 数据离机备份与恢复操作手册 实验环境 Windows server 2008 R2(服务器) IP地址:192.168.136.175 计算机名:CXH ...
- Webpack 开发工具与模块热替换
Webpack 开发工具与模块热替换 ⚠️ 注意: 永远不要在生产环境中使用这些工具,永远不要. devtool 当 JavaScript 异常抛出时,你常会想知道这个错误发生在哪个文件的哪一行.然 ...
随机推荐
- 2024-01-06:用go语言,在河上有一座独木桥,一只青蛙想沿着独木桥从河的一侧跳到另一侧 在桥上有一些石子,青蛙很讨厌踩在这些石子上 由于桥的长度和青蛙一次跳过的距离都是正整数 我们可以把独木桥
2024-01-06:用go语言,在河上有一座独木桥,一只青蛙想沿着独木桥从河的一侧跳到另一侧 在桥上有一些石子,青蛙很讨厌踩在这些石子上 由于桥的长度和青蛙一次跳过的距离都是正整数 我们可以把独木桥 ...
- .NET技术分享日活动20221022
2022年10月22日下午,个人组织举办了山东地区的第六次.NET技术分享日活动.围绕.NET.低代码Low Code.云原生 Cloud Native.大数据.算法等方向进行创新技术的实践分享. 本 ...
- 云图说|什么是可信智能计算服务TICS
阅识风云是华为云信息大咖,擅长将复杂信息多元化呈现,其出品的一张图(云图说).深入浅出的博文(云小课)或短视频(云视厅)总有一款能让您快速上手华为云.更多精彩内容请单击此处. 本文分享自华为云社区&l ...
- CANN开发实践:4个DVPP内存问题的典型案例解读
摘要:由于DVPP媒体数据处理功能对存放输入.输出数据的内存有更高的要求(例如,内存首地址128字节对齐),因此需调用专用的内存申请接口,那么本期就分享几个关于DVPP内存问题的典型案例,并给出原因分 ...
- GaussDB CN服务异常实例分析
摘要:先通过OPS确认节点状态是否已经恢复,或登录后台执行cm_ctl query -Cv确认集群是否已经Normal. 本文分享自华为云社区<[实例状态]GaussDB CN服务异常>, ...
- MindSpore:不用摘口罩也知道你是谁
[本期推荐专题]从三大主流前端技术出发,看看它们各自特性,以及如何从业务特性出发,选择合适的框架. 摘要:我们基于MindSpore设计了一种人脸识别算法,以解决口罩遮挡场景下的人脸识别问题.该算法的 ...
- 网站web服务器个人博客站开通那些端口合适?
一般网站服务器,只需要开通80 443,(ssh端口默认22,,建议修改) ping命令没有端口,因为ICMP 协议没有到tcp层,仅走ip层,由于IP层协议是一种点对点的协议,而非端对端的协议,它提 ...
- 如何注册appuploader账号
如何注册appuploader账号 我们上一篇讲到appuploader的下载安装,要想使用此软件呢,需要注册账号才能使用,今 天我们来讲下如何注册appuploader账号来使用软件. 1.A ...
- print('Hello World!')的新玩法
相信很多同学入门Python的第一行代码都是print('Hello World!') print是初学者最先接触的Python函数,但是很多人可能到现在也不完全清楚它的用法. print(*obje ...
- POJ 2387 Til the Cows Come Home(最短路板子题,Dijkstra算法, spfa算法,Floyd算法,深搜DFS)
Til the Cows Come Home Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 43861 Accepted: 14 ...