macbook苹果m1芯片训练机器学习、深度学习模型,resnet101在mnist手写数字识别上做加速,torch.device("mps")
apple的m1芯片比以往cpu芯片在机器学习加速上听说有15倍的提升,也就是可以使用apple mac训练深度学习pytorch模型!!!惊呆了
安装apple m1芯片版本的pytorch
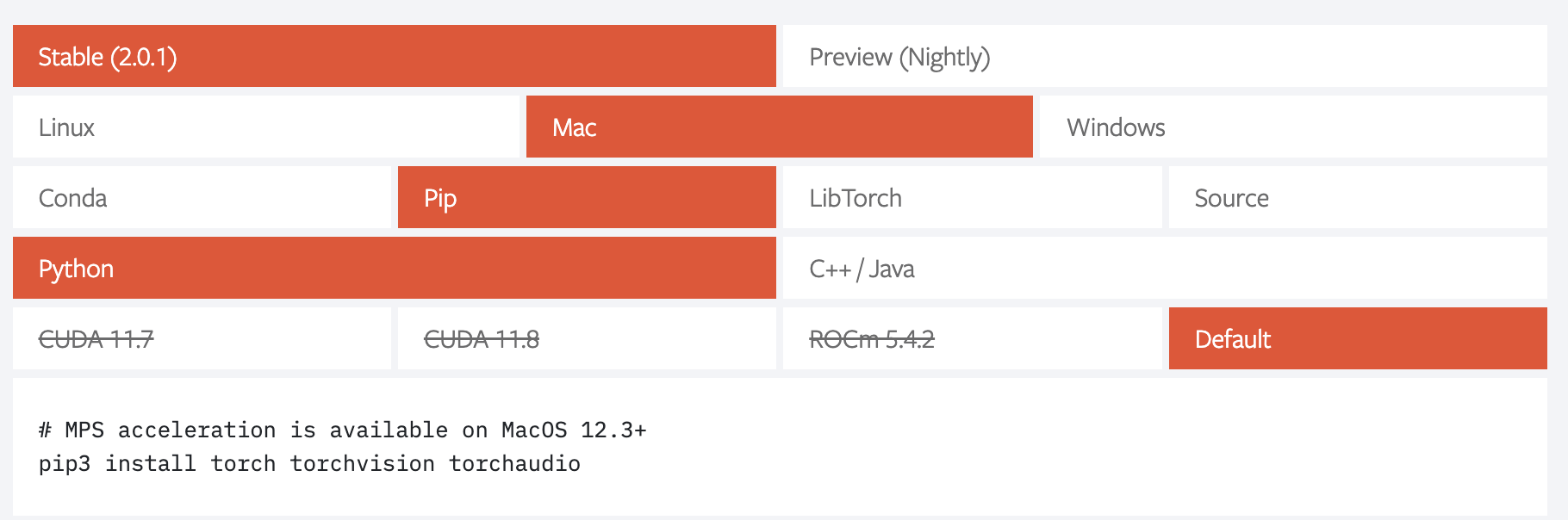
然后使用chatGPT生成一个resnet101的训练代码,这里注意,如果网络特别轻的话是没有加速效果的,还没有cpu的计算来的快
这里要选择好设备不是"cuda"了,cuda是nvidia深度学习加速的配置
# 设置设备
# device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device = torch.device("mps") #torch.device("cpu")
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision.datasets import MNIST
from torchvision.transforms import ToTensor
from torchvision.models import resnet101
from tqdm import tqdm # 设置设备
# device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device = torch.device("mps") #torch.device("cpu") # 加载 MNIST 数据集
train_dataset = MNIST(root="/Users/xinyuuliu/Desktop/test_python/", train=True, transform=ToTensor(), download=True)
test_dataset = MNIST(root="/Users/xinyuuliu/Desktop/test_python/", train=False, transform=ToTensor()) # 创建数据加载器
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False) # 定义 ResNet-101 模型
model = resnet101(pretrained=False)
model.conv1 = nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3, bias=False)
model.fc = nn.Linear(2048, 10) # 替换最后一层全连接层
model.to(device) # 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001) # 训练和评估函数
def train(model, dataloader, optimizer, criterion):
model.train()
running_loss = 0.0
for inputs, labels in tqdm(dataloader, desc="Training"):
inputs = inputs.to(device)
labels = labels.to(device) optimizer.zero_grad() outputs = model(inputs)
loss = criterion(outputs, labels) loss.backward()
optimizer.step() running_loss += loss.item() * inputs.size(0) epoch_loss = running_loss / len(dataloader.dataset)
return epoch_loss def evaluate(model, dataloader):
model.eval()
correct = 0
total = 0
with torch.no_grad():
for inputs, labels in tqdm(dataloader, desc="Evaluating"):
inputs = inputs.to(device)
labels = labels.to(device) outputs = model(inputs)
_, predicted = torch.max(outputs.data, 1) total += labels.size(0)
correct += (predicted == labels).sum().item() accuracy = correct / total * 100
return accuracy # 训练和评估
num_epochs = 10 for epoch in range(num_epochs):
print(f"Epoch {epoch+1}/{num_epochs}")
train_loss = train(model, train_loader, optimizer, criterion)
print(f"Training Loss: {train_loss:.4f}") test_acc = evaluate(model, test_loader)
print(f"Test Accuracy: {test_acc:.2f}%")
结果:
在mps device上,训练时间在10分钟左右

在cpu device上,训练时间在50分钟左右,明显在mps device上速度快了5倍

macbook苹果m1芯片训练机器学习、深度学习模型,resnet101在mnist手写数字识别上做加速,torch.device("mps")的更多相关文章
- 【深度学习系列】PaddlePaddle之手写数字识别
上周在搜索关于深度学习分布式运行方式的资料时,无意间搜到了paddlepaddle,发现这个框架的分布式训练方案做的还挺不错的,想跟大家分享一下.不过呢,这块内容太复杂了,所以就简单的介绍一下padd ...
- 深度学习(一):Python神经网络——手写数字识别
声明:本文章为阅读书籍<Python神经网络编程>而来,代码与书中略有差异,书籍封面: 源码 若要本地运行,请更改源码中图片与数据集的位置,环境为 Python3.6x. 1 import ...
- mnist手写数字识别——深度学习入门项目(tensorflow+keras+Sequential模型)
前言 今天记录一下深度学习的另外一个入门项目——<mnist数据集手写数字识别>,这是一个入门必备的学习案例,主要使用了tensorflow下的keras网络结构的Sequential模型 ...
- 深度学习之 mnist 手写数字识别
深度学习之 mnist 手写数字识别 开始学习深度学习,先来一个手写数字的程序 import numpy as np import os import codecs import torch from ...
- 用MXnet实战深度学习之一:安装GPU版mxnet并跑一个MNIST手写数字识别
用MXnet实战深度学习之一:安装GPU版mxnet并跑一个MNIST手写数字识别 http://phunter.farbox.com/post/mxnet-tutorial1 用MXnet实战深度学 ...
- SVM学习笔记(二)----手写数字识别
引言 上一篇博客整理了一下SVM分类算法的基本理论问题,它分类的基本思想是利用最大间隔进行分类,处理非线性问题是通过核函数将特征向量映射到高维空间,从而变成线性可分的,但是运算却是在低维空间运行的.考 ...
- 【机器学习】k-近邻算法应用之手写数字识别
上篇文章简要介绍了k-近邻算法的算法原理以及一个简单的例子,今天再向大家介绍一个简单的应用,因为使用的原理大体差不多,就没有没有过多的解释. 为了具有说明性,把手写数字的图像转换为txt文件,如下图所 ...
- 深度学习之PyTorch实战(3)——实战手写数字识别
上一节,我们已经学会了基于PyTorch深度学习框架高效,快捷的搭建一个神经网络,并对模型进行训练和对参数进行优化的方法,接下来让我们牛刀小试,基于PyTorch框架使用神经网络来解决一个关于手写数字 ...
- 学习笔记CB009:人工神经网络模型、手写数字识别、多层卷积网络、词向量、word2vec
人工神经网络,借鉴生物神经网络工作原理数学模型. 由n个输入特征得出与输入特征几乎相同的n个结果,训练隐藏层得到意想不到信息.信息检索领域,模型训练合理排序模型,输入特征,文档质量.文档点击历史.文档 ...
- TensorFlow.NET机器学习入门【5】采用神经网络实现手写数字识别(MNIST)
从这篇文章开始,终于要干点正儿八经的工作了,前面都是准备工作.这次我们要解决机器学习的经典问题,MNIST手写数字识别. 首先介绍一下数据集.请首先解压:TF_Net\Asset\mnist_png. ...
随机推荐
- Linux & 标准C语言学习 <DAY12_1>
10.函数指针 函数名就是一个地址(整数),代表了该函数在代码段中的位置 函数指针就是专门指向某种函数的指针,它里面存储的是该函数在代码段中的位置(函数名) ...
- 万字血书Vue—路由
多个路由通过路由器进行管理. 前端路由的概念和原理 (编程中的)路由(router)就是一组key-value对应关系,分为:后端路由和前端路由 后端路由指的是:请求方式.请求地址和function处 ...
- java注解与反射--2
java注解与反射--2 反射:java.Reflection 因为反射,使java具有了一定的动态性. java反射机制概述 动态语言: 是一类在运行时可以改变其结构的语言:例如新的函数.对象.甚至 ...
- 全网最详细中英文ChatGPT-GPT-4示例文档-从0到1快速入门计算时间复杂度应用——官网推荐的48种最佳应用场景(附python/node.js/curl命令源代码,小白也能学)
目录 Introduce 简介 setting 设置 Prompt 提示 Sample response 回复样本 API request 接口请求 python接口请求示例 node.js接口请求示 ...
- Clion 连接 WSL 编译Unix环境
Clion 连接 WSL 编译Unix环境 安装 WSL Ubuntu 18版本,创建后不要换源,upgrade后安装CMake.g++.gcc 安装 Clion,创建项目 进入setting 在 B ...
- 一款针对EF Core轻量级分表分库、读写分离的开源项目
在项目开发中,如果数据量比较大,比如日志记录,我们往往会采用分表分库的方案:为了提升性能,把数据库查询与更新操作分开,这时候就要采用读写分离的方案. 分表分库通常包含垂直分库.垂直分表.水平分库和水平 ...
- 念一句咒语 AI 就帮我写一个应用,我人麻了...
原文链接:https://forum.laf.run/d/232 作为人类,我们时常会有自己独特的想法和脑洞大开的创意.然而,这些想法往往因为成本过高而无法实现,毕竟每个人的能力和精力都是有限的,尤其 ...
- CentOS&RHEL内核升级
在安装部署一些环境的时候,会要求内核版本的要求,可以通过YUM工具进行安装配置更高版本的内核,当然更新内核有风险,在操作之前慎重,严谨在生产环境操作! 安装源 # 为 RHEL-8或 CentOS-8 ...
- pandas之sql操作
我们知道,使用 SQL 语句能够完成对 table 的增删改查操作,Pandas 同样也可以实现 SQL 语句的基本功能.本节主要讲解 Pandas 如何执行 SQL 操作.首先加载一个某连锁咖啡厅地 ...
- 请求被中止: 未能创建 SSL/TLS 安全通道 解决方案
最近项目改造https,有部分请求出现"请求被中止: 未能创建 SSL/TLS 安全通道". 原因应该是,接口方变更了安全协议,而客户端并未启用该协议. 解决办法自然就是:让客户端 ...