2023-05-26:golang关于垃圾回收和析构函数的选择题,多数人会选错。
2023-05-26:golang关于垃圾回收和析构的选择题,代码如下:
package main
import (
"fmt"
"runtime"
"time"
)
type ListNode struct {
Val int
Next *ListNode
}
func main0() {
a := &ListNode{Val: 1}
b := &ListNode{Val: 2}
runtime.SetFinalizer(a, func(obj *ListNode) {
fmt.Printf("a被回收--")
})
runtime.SetFinalizer(b, func(obj *ListNode) {
fmt.Printf("b被回收--")
})
a.Next = b
b.Next = a
}
func main() {
main0()
time.Sleep(1 * time.Second)
runtime.GC()
time.Sleep(1 * time.Second)
runtime.GC()
time.Sleep(1 * time.Second)
runtime.GC()
time.Sleep(1 * time.Second)
runtime.GC()
time.Sleep(1 * time.Second)
runtime.GC()
fmt.Print("结束")
}
代码的运行结果是什么?并说明原因。注意析构是无序的。
A. 结束
B. a被回收--b被回收--结束
C. b被回收--a被回收--结束
D. B和C都有可能
答案2023-05-26:
golang的垃圾回收算法跟java一样,都是根可达算法。代码中main0函数里a和b是互相引用,但是a和b没有外部引用。因此a和b会被当成垃圾被回收掉。而析构函数的调用不是有序的,所以B和C都有可能,答案选D。让我们看看答案是什么,如下:
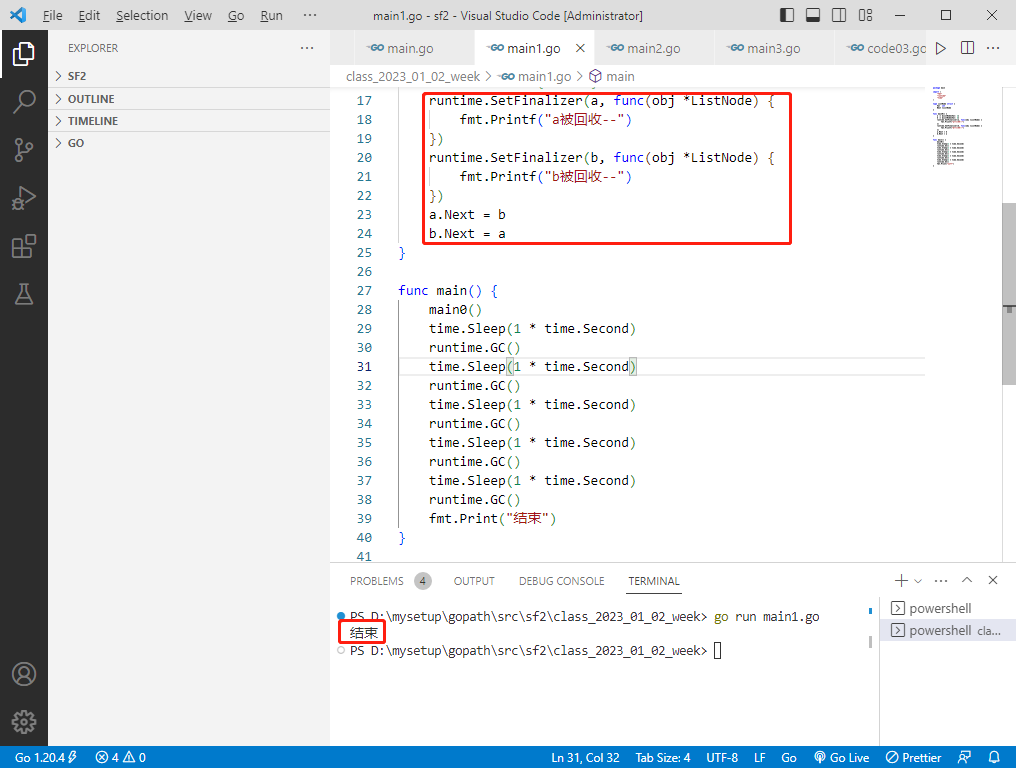
看运行结果,答案不是选D,而是选A。这肯定会出乎很多人意料,golang的垃圾回收算法是根可达算法难不成是假的,大家公认的八股文难道是错的?有这个疑问是好事,但不能全盘否定。让我们看看析构函数的源码吧。代码在 src/runtime/mfinal.go 中,如下:
// SetFinalizer sets the finalizer associated with obj to the provided
// finalizer function. When the garbage collector finds an unreachable block
// with an associated finalizer, it clears the association and runs
// finalizer(obj) in a separate goroutine. This makes obj reachable again,
// but now without an associated finalizer. Assuming that SetFinalizer
// is not called again, the next time the garbage collector sees
// that obj is unreachable, it will free obj.
//
// SetFinalizer(obj, nil) clears any finalizer associated with obj.
//
// The argument obj must be a pointer to an object allocated by calling
// new, by taking the address of a composite literal, or by taking the
// address of a local variable.
// The argument finalizer must be a function that takes a single argument
// to which obj's type can be assigned, and can have arbitrary ignored return
// values. If either of these is not true, SetFinalizer may abort the
// program.
//
// Finalizers are run in dependency order: if A points at B, both have
// finalizers, and they are otherwise unreachable, only the finalizer
// for A runs; once A is freed, the finalizer for B can run.
// If a cyclic structure includes a block with a finalizer, that
// cycle is not guaranteed to be garbage collected and the finalizer
// is not guaranteed to run, because there is no ordering that
// respects the dependencies.
//
// The finalizer is scheduled to run at some arbitrary time after the
// program can no longer reach the object to which obj points.
// There is no guarantee that finalizers will run before a program exits,
// so typically they are useful only for releasing non-memory resources
// associated with an object during a long-running program.
// For example, an os.File object could use a finalizer to close the
// associated operating system file descriptor when a program discards
// an os.File without calling Close, but it would be a mistake
// to depend on a finalizer to flush an in-memory I/O buffer such as a
// bufio.Writer, because the buffer would not be flushed at program exit.
//
// It is not guaranteed that a finalizer will run if the size of *obj is
// zero bytes, because it may share same address with other zero-size
// objects in memory. See https://go.dev/ref/spec#Size_and_alignment_guarantees.
//
// It is not guaranteed that a finalizer will run for objects allocated
// in initializers for package-level variables. Such objects may be
// linker-allocated, not heap-allocated.
//
// Note that because finalizers may execute arbitrarily far into the future
// after an object is no longer referenced, the runtime is allowed to perform
// a space-saving optimization that batches objects together in a single
// allocation slot. The finalizer for an unreferenced object in such an
// allocation may never run if it always exists in the same batch as a
// referenced object. Typically, this batching only happens for tiny
// (on the order of 16 bytes or less) and pointer-free objects.
//
// A finalizer may run as soon as an object becomes unreachable.
// In order to use finalizers correctly, the program must ensure that
// the object is reachable until it is no longer required.
// Objects stored in global variables, or that can be found by tracing
// pointers from a global variable, are reachable. For other objects,
// pass the object to a call of the KeepAlive function to mark the
// last point in the function where the object must be reachable.
//
// For example, if p points to a struct, such as os.File, that contains
// a file descriptor d, and p has a finalizer that closes that file
// descriptor, and if the last use of p in a function is a call to
// syscall.Write(p.d, buf, size), then p may be unreachable as soon as
// the program enters syscall.Write. The finalizer may run at that moment,
// closing p.d, causing syscall.Write to fail because it is writing to
// a closed file descriptor (or, worse, to an entirely different
// file descriptor opened by a different goroutine). To avoid this problem,
// call KeepAlive(p) after the call to syscall.Write.
//
// A single goroutine runs all finalizers for a program, sequentially.
// If a finalizer must run for a long time, it should do so by starting
// a new goroutine.
//
// In the terminology of the Go memory model, a call
// SetFinalizer(x, f) “synchronizes before” the finalization call f(x).
// However, there is no guarantee that KeepAlive(x) or any other use of x
// “synchronizes before” f(x), so in general a finalizer should use a mutex
// or other synchronization mechanism if it needs to access mutable state in x.
// For example, consider a finalizer that inspects a mutable field in x
// that is modified from time to time in the main program before x
// becomes unreachable and the finalizer is invoked.
// The modifications in the main program and the inspection in the finalizer
// need to use appropriate synchronization, such as mutexes or atomic updates,
// to avoid read-write races.
func SetFinalizer(obj any, finalizer any) {
if debug.sbrk != 0 {
// debug.sbrk never frees memory, so no finalizers run
// (and we don't have the data structures to record them).
return
}
e := efaceOf(&obj)
etyp := e._type
if etyp == nil {
throw("runtime.SetFinalizer: first argument is nil")
}
if etyp.kind&kindMask != kindPtr {
throw("runtime.SetFinalizer: first argument is " + etyp.string() + ", not pointer")
}
ot := (*ptrtype)(unsafe.Pointer(etyp))
if ot.elem == nil {
throw("nil elem type!")
}
if inUserArenaChunk(uintptr(e.data)) {
// Arena-allocated objects are not eligible for finalizers.
throw("runtime.SetFinalizer: first argument was allocated into an arena")
}
// find the containing object
base, _, _ := findObject(uintptr(e.data), 0, 0)
if base == 0 {
// 0-length objects are okay.
if e.data == unsafe.Pointer(&zerobase) {
return
}
// Global initializers might be linker-allocated.
// var Foo = &Object{}
// func main() {
// runtime.SetFinalizer(Foo, nil)
// }
// The relevant segments are: noptrdata, data, bss, noptrbss.
// We cannot assume they are in any order or even contiguous,
// due to external linking.
for datap := &firstmoduledata; datap != nil; datap = datap.next {
if datap.noptrdata <= uintptr(e.data) && uintptr(e.data) < datap.enoptrdata ||
datap.data <= uintptr(e.data) && uintptr(e.data) < datap.edata ||
datap.bss <= uintptr(e.data) && uintptr(e.data) < datap.ebss ||
datap.noptrbss <= uintptr(e.data) && uintptr(e.data) < datap.enoptrbss {
return
}
}
throw("runtime.SetFinalizer: pointer not in allocated block")
}
if uintptr(e.data) != base {
// As an implementation detail we allow to set finalizers for an inner byte
// of an object if it could come from tiny alloc (see mallocgc for details).
if ot.elem == nil || ot.elem.ptrdata != 0 || ot.elem.size >= maxTinySize {
throw("runtime.SetFinalizer: pointer not at beginning of allocated block")
}
}
f := efaceOf(&finalizer)
ftyp := f._type
if ftyp == nil {
// switch to system stack and remove finalizer
systemstack(func() {
removefinalizer(e.data)
})
return
}
if ftyp.kind&kindMask != kindFunc {
throw("runtime.SetFinalizer: second argument is " + ftyp.string() + ", not a function")
}
ft := (*functype)(unsafe.Pointer(ftyp))
if ft.dotdotdot() {
throw("runtime.SetFinalizer: cannot pass " + etyp.string() + " to finalizer " + ftyp.string() + " because dotdotdot")
}
if ft.inCount != 1 {
throw("runtime.SetFinalizer: cannot pass " + etyp.string() + " to finalizer " + ftyp.string())
}
fint := ft.in()[0]
switch {
case fint == etyp:
// ok - same type
goto okarg
case fint.kind&kindMask == kindPtr:
if (fint.uncommon() == nil || etyp.uncommon() == nil) && (*ptrtype)(unsafe.Pointer(fint)).elem == ot.elem {
// ok - not same type, but both pointers,
// one or the other is unnamed, and same element type, so assignable.
goto okarg
}
case fint.kind&kindMask == kindInterface:
ityp := (*interfacetype)(unsafe.Pointer(fint))
if len(ityp.mhdr) == 0 {
// ok - satisfies empty interface
goto okarg
}
if iface := assertE2I2(ityp, *efaceOf(&obj)); iface.tab != nil {
goto okarg
}
}
throw("runtime.SetFinalizer: cannot pass " + etyp.string() + " to finalizer " + ftyp.string())
okarg:
// compute size needed for return parameters
nret := uintptr(0)
for _, t := range ft.out() {
nret = alignUp(nret, uintptr(t.align)) + uintptr(t.size)
}
nret = alignUp(nret, goarch.PtrSize)
// make sure we have a finalizer goroutine
createfing()
systemstack(func() {
if !addfinalizer(e.data, (*funcval)(f.data), nret, fint, ot) {
throw("runtime.SetFinalizer: finalizer already set")
}
})
}
看代码,看不出什么。其端倪在注释中。注意如下注释:
// Finalizers are run in dependency order: if A points at B, both have
// finalizers, and they are otherwise unreachable, only the finalizer
// for A runs; once A is freed, the finalizer for B can run.
// If a cyclic structure includes a block with a finalizer, that
// cycle is not guaranteed to be garbage collected and the finalizer
// is not guaranteed to run, because there is no ordering that
// respects the dependencies.
这段英文翻译成中文如下:
Finalizers(终结器)按照依赖顺序运行:如果 A 指向 B,两者都有终结器,并且它们除此之外不可达,则仅运行 A 的终结器;一旦 A 被释放,可以运行 B 的终结器。如果一个循环结构包含一个具有终结器的块,则该循环体不能保证被垃圾回收并且终结器不能保证运行,因为没有符合依赖关系的排序方式。
这意思很明显了,析构函数会检查当前对象A是否有外部对象指向当前对象A。如果有外部对象指向当前对象A时,A的析构是无法执行的;如果有外部对象指向当前对象A时,A的析构才能执行。
代码中的a和b是循环依赖,当析构判断a和b时,都会有外部对象指向a和b,析构函数无法执行。析构无法执行,内存也无法回收。因此答案选A。
去掉析构函数后,a和b肯定会被释放的。不用析构函数去证明,那如何证明呢?用以下代码就可以证明,代码如下:
package main
import (
"fmt"
"runtime"
"time"
)
type ListNode struct {
Val [1024 * 1024]bool
Next *ListNode
}
func printAlloc() {
var m runtime.MemStats
runtime.ReadMemStats(&m)
fmt.Printf("%d KB\n", m.Alloc/1024)
}
func main0() {
printAlloc()
a := &ListNode{Val: [1024 * 1024]bool{true}}
b := &ListNode{Val: [1024 * 1024]bool{false}}
a.Next = b
b.Next = a
// runtime.SetFinalizer(a, func(obj *ListNode) {
// fmt.Printf("a被删除--")
// })
printAlloc()
}
func main() {
fmt.Print("开始")
main0()
time.Sleep(1 * time.Second)
runtime.GC()
time.Sleep(1 * time.Second)
runtime.GC()
time.Sleep(1 * time.Second)
runtime.GC()
time.Sleep(1 * time.Second)
runtime.GC()
time.Sleep(1 * time.Second)
runtime.GC()
fmt.Print("结束")
printAlloc()
}
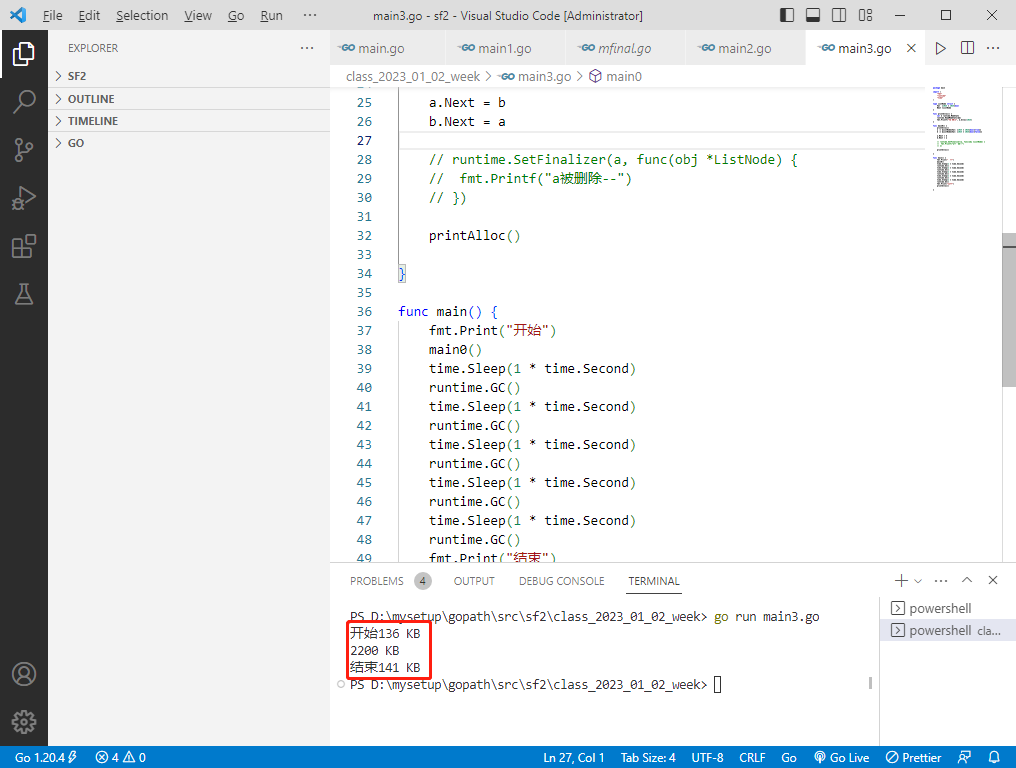
根据运行结果,内存大小明显变小,说明a和b已经被回收了。
让我们再看看有析构函数的情况,运行结果是咋样的,如下:
package main
import (
"fmt"
"runtime"
"time"
)
type ListNode struct {
Val [1024 * 1024]bool
Next *ListNode
}
func printAlloc() {
var m runtime.MemStats
runtime.ReadMemStats(&m)
fmt.Printf("%d KB\n", m.Alloc/1024)
}
func main0() {
printAlloc()
a := &ListNode{Val: [1024 * 1024]bool{true}}
b := &ListNode{Val: [1024 * 1024]bool{false}}
a.Next = b
b.Next = a
runtime.SetFinalizer(a, func(obj *ListNode) {
fmt.Printf("a被删除--")
})
printAlloc()
}
func main() {
fmt.Print("开始")
main0()
time.Sleep(1 * time.Second)
runtime.GC()
time.Sleep(1 * time.Second)
runtime.GC()
time.Sleep(1 * time.Second)
runtime.GC()
time.Sleep(1 * time.Second)
runtime.GC()
time.Sleep(1 * time.Second)
runtime.GC()
fmt.Print("结束")
printAlloc()
}
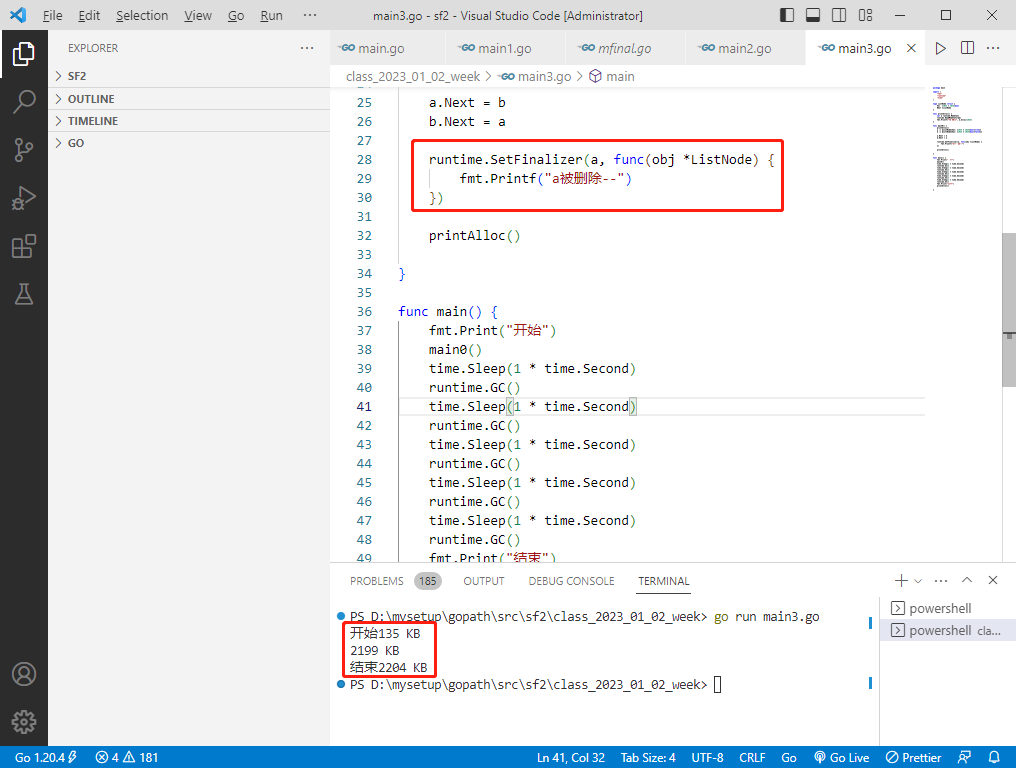
根据运行结果,有析构函数的情况下,a和b确实是无法被回收。
总结
1.不要怀疑八股文的正确性,golang的垃圾回收确实是根可达算法。
2.不要用析构函数去测试无用对象被回收的情况,上面的例子也看到了,两对象的循环引用,析构函数的测试结果就是错误的。只能根据内存变化,看无用对象是否被回收。
3.在写代码的时候,能手动设置引用为nil,最好手动设置,这样能更好的避免内存泄漏。
2023-05-26:golang关于垃圾回收和析构函数的选择题,多数人会选错。的更多相关文章
- golang的垃圾回收(GC)机制
golang的垃圾回收采用的是 标记-清理(Mark-and-Sweep) 算法 就是先标记出需要回收的内存对象快,然后在清理掉: 在这里不介绍标记和清理的具体策略(可以参考https://lengz ...
- 从golang的垃圾回收说起(上篇)
本文来自网易云社区 1 垃圾回收中的重要概念 1.1 定义 In computer science, garbage collection (GC) is a form of automatic me ...
- Golang GC 垃圾回收机制详解
摘要 在实际使用 go 语言的过程中,碰到了一些看似奇怪的内存占用现象,于是决定对go语言的垃圾回收模型进行一些研究.本文对研究的结果进行一下总结. 什么是垃圾回收? 曾几何时,内存管理是程序员开发应 ...
- Golang之垃圾回收
本篇主要是参考了: http://legendtkl.com/2017/04/28/golang-gc/ 说是参考,但其实基本上是原封不动. GC算法简介: 1. 引用计数 引用计数的思想非常简单:每 ...
- 从golang的垃圾回收说起(下篇)
文章来自网易云社区 4 Golang垃圾回收的相关参数 4.1 触发GC gc触发的时机:2分钟或者内存占用达到一个阈值(当前堆内存占用是上次gc后对内存占用的两倍,当GOGC=100时) # 表示 ...
- golang GC 垃圾回收机制
垃圾回收(Garbage Collection,简称GC)是编程语言中提供的自动的内存管理机制,自动释放不需要的对象,让出存储器资源,无需程序员手动执行. Golang中的垃圾回收主要应用三色标记法, ...
- 05.python语法入门--垃圾回收机制
# (1)垃圾回收机制GC# 引用计数# x = 10 # 值10引用计数为1# y = x # 值10引用计数为2## y = 1000 # 值10引用计数减少为1# del x # 值 ...
- C#GC垃圾回收和析构函数和IDisposable的使用
一,什么是GC 1,GC是垃圾回收器,一般来说系统会自动检测不会使用的对象或变量进行内存的释放,不需要手动调用,用Collect()就是强制进行垃圾回收,使内存得到及时的释放,让程序效率更高. 2,G ...
- Golang——垃圾回收GC(2)
1 垃圾回收中的重要概念 1.1 定义 In computer science, garbage collection (GC) is a form of automatic memory manag ...
- 【GoLang】golang垃圾回收 & 性能调优
golang垃圾回收 & 性能调优 参考资料: 如何监控 golang 程序的垃圾回收_Go语言_第七城市 golang的垃圾回收(GC)机制 - 两只羊的博客 - 博客频道 - CSDN.N ...
随机推荐
- Feign报错:The bean 'xxxxx.FeignClientSpecification' could not be registered.
解决方法: spring: main: allow-bean-definition-overriding: true 参考博客:https://www.cnblogs.com/lifelikeplay ...
- 灵感宝盒图谱全新改版!代码实验室开启报名丨RTE NG-Lab 双周报
前言 RTE NG-Lab 计划已经推出一段时间了,计划目前包含灵感宝盒(Idea Box).代码实验室(Code Lab).独立开发者孵化器(NGLab Incubator)三个项目.我们希望借助这 ...
- CSS必知必会
CSS概念 css的使用是让网页具有统一美观的页面,css层叠样式表,简称样式表,文件后缀名.css css的规则由两部分构成:选择器以及一条或者多条声明 选择器:通常是需要改变的HTML元素 声明: ...
- 在Vue3+TypeScript 前端项目中使用事件总线Mitt
事件总线Mitt使用非常简单,本篇随笔介绍在Vue3+TypeScript 前端项目中使用的一些场景和思路.我们在Vue 的项目中,经常会通过emits 触发事件来通知组件或者页面进行相应的处理,不过 ...
- swagger-ui 导出离线文档md格式
<dependency> <groupId>io.github.swagger2markup</groupId> <artifactId>swagger ...
- 万字长文带你入门docker
1 Docker dockerfiler 镜像构建 Compose是在单机进行容器编排 Horbor 镜像仓库 Docker swarm 在多机进行容器编排 Docker Compose缺点是不能在分 ...
- Django笔记十五之in查询及date日期相关过滤操作
这一篇介绍关于范围,日期的筛选 in range date year week weekday quarter hour 1.in in 对应于 MySQL 中的 in 操作,可以接受数组.元组等类型 ...
- 中英文拼写检测纠正开源项目使用入门 word-checker 1.1.0
项目简介 word-checker 本项目用于单词拼写检查.支持英文单词拼写检测,和中文拼写检测. 特性说明 可以迅速判断当前单词是否拼写错误 可以返回最佳匹配结果 可以返回纠正匹配列表,支持指定返回 ...
- 7.OAuth2
1.近几天在学习OAuth2协议,实际开发中用的最多的就是授权码模式 2.OAuth2的授权码模式流程:首先是用户去访问资源服务器,服务器会给用户一个授权码:用户根据授权码去访问认证服务器,服务器 ...
- 移除List的统一逻辑写法 LeetCode 203
原理:通过创建一个新的结点,放在头结点的前面,作为真正头结点的前驱结点,这样头结点就成为了意义上的非头结点,这样就可以统一操作结点的删除操作. 需要注意的是:这个新的结点是虚拟头结点,真的的头结点依然 ...