Redis的五大数据类型(简单使用)
1:Redis的简单介绍?
- Redis(Remote Dictionary Server ):即远程字典服务
- 是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型Key-Value数据库,并提供多种语言的API。
- 从2010年3月15日起,Redis的开发工作由VMware主持。从2013年5月开始,Redis的开发由Pivotal赞助
2:Redis的性能:
- 由官方的bench-mark数据测试:
- 测试完成了50个并发执行100000个请求。
- 设置和获取的值是一个256字节字符串。
- Linux box是运行Linux 2.6,这是X3320 Xeon 2.5 ghz。
- 文本执行使用loopback接口(127.0.0.1)。
- 结果:读的速度是110000次/s,写的速度是81000次/s
- redis是基于内存的,内存的读写速度非常快 ;
- redis是单线程的,省去了很多上下文切换线程的时间;
- redis因为是基于内存的 不涉及io操作 所以单线程效率是最高的
回归正题
五大数据类型(狂神的redis笔记中的话):
- Redis是一个开源(BSD许可)
- 内存存储的数据结构服务器,可用作数据库,高速缓存和消息队列代理。
- 它支持字符串、哈希表、列表、集合、有序集合,位图,hyperloglogs等数据类型。
- 内置复制、Lua脚本、LRU收回、事务以及不同级别磁盘持久化功能,同时通过Redis Sentinel提供高可用,通过Redis Cluster提供自动分区
- Redis中的数据都是键值对的存储方式 key-value 然后通过进行对Redis-key的操作,来完成对数据库中数据的操作。
1:String(字符串类型):
- 字符串类型 也是redis中最常用的类型
- 相信大家绝对不陌生 来让我们看看redis中 string的作用与它的方法吧:
- 下面方法图片来自于:https://blog.csdn.net/DDDDeng_/article/details/108118544
常用方法:
方法实现:
127.0.0.1:6379> select 0 #切换数据库
OK
127.0.0.1:6379> set name jie #给name赋值
OK
127.0.0.1:6379> get name #读取值
"jie"
127.0.0.1:6379> move name 1 #把值移动到其他数据库中
(integer) 1
127.0.0.1:6379> EXISTS name #查找当前数据库的name
(integer) 0
127.0.0.1:6379> select 1 #切换到1数据库
OK
127.0.0.1:6379[1]> EXISTS name #查找数据库的name
(integer) 1
127.0.0.1:6379[1]> set name jie2
OK
127.0.0.1:6379[1]> keys * #查找所有key
1) "name"
127.0.0.1:6379[1]> del name #删除name
(integer) 1
127.0.0.1:6379[1]> get name
(nil)
127.0.0.1:6379[1]> set age 18
OK
127.0.0.1:6379[1]> EXPIRE age 10 #age设置过期时间
(integer) 1
127.0.0.1:6379[1]> ttl age #查看过期时间
(integer) 3
127.0.0.1:6379[1]> ttl age #过期了
(integer) -2
127.0.0.1:6379[1]> get age
(nil)
127.0.0.1:6379[1]> keys *
(empty array)
127.0.0.1:6379[1]> set name jie
OK
127.0.0.1:6379[1]> type name #查看数据类型
string
这只是一些常用方法:其他方法可以查看官网文档: http://www.redis.cn/commands.html
2:List(列表):
- 方法以l开头
常用方法: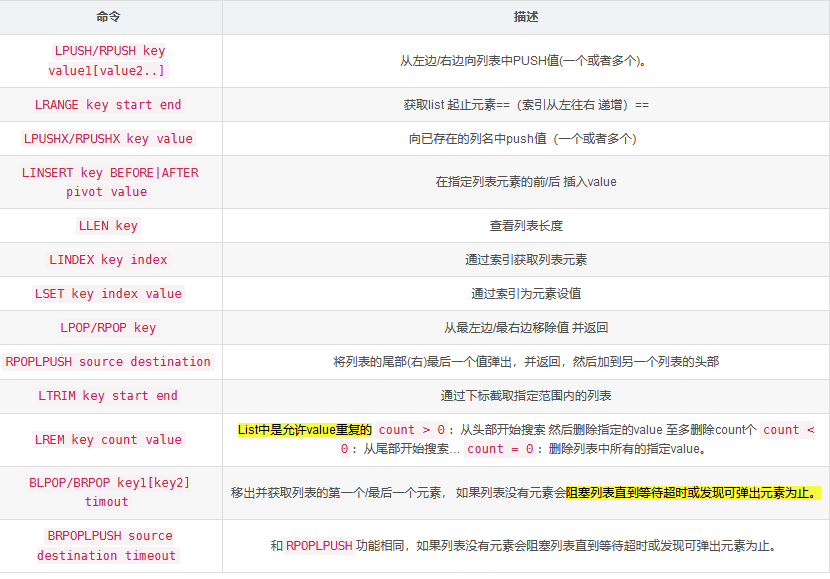
下面是实现过程:
127.0.0.1:6379[2]> lpush jielist 1 #往jielist中添加值
(integer) 1
127.0.0.1:6379[2]> lpush jielist 2
(integer) 2
127.0.0.1:6379[2]> LRANGE jielist 1 2 #查看jielist中的1——5值
3) "2"
4) "1"
127.0.0.1:6379[2]> LRANGE jielist 0 -1 #查看jielist中的所有值
4) "2"
5) "1"
127.0.0.1:6379[2]> LPUSHx jielist 5 6 #向jielist左边 push 5 6值
(integer) 7
127.0.0.1:6379[2]> LINSERT jielist after 2 50 #往jielist的2后插入50
(integer) 11
127.0.0.1:6379[2]> LLEN jielist #查看jielist中的长度
(integer) 11
127.0.0.1:6379[2]> LINDEX jielist 5 #获取下标为5的元素
"5"
127.0.0.1:6379[2]> lset jielist 5 12 #将下标为5的元素赋值为12
OK
127.0.0.1:6379[2]> lrange jielist 0 -1
1) "9"
2) "10"
3) "10"
4) "6"
5) "5"
6) "12"
7) "4"
8) "3"
9) "2"
10) "50"
11) "1"
127.0.0.1:6379[2]> lpop jielist #左边弹出元素
"9"127.0.0.1:6379[2]> rpop jielist #右边弹出元素
"1"
127.0.0.1:6379[2]> RPOPLPUSH jielist jie2list #将jielist的最后一个值弹出移动到jie2list中
"50"
127.0.0.1:6379[2]> LRANGE jie2list 0 -1
1) "50"
127.0.0.1:6379[2]> ltrim jielist 0 4 #截取0~4的部分
OK
127.0.0.1:6379[2]> lrange jielist 0 -1
1) "12"
2) "4"
127.0.0.1:6379[2]> LPUSH jielist 5
(integer) 2
127.0.0.1:6379[2]> LPUSH jielist 5
(integer) 3
127.0.0.1:6379[2]> lrem jielist 2 5 #从头部搜索 删除至多两个5
(integer) 2
127.0.0.1:6379[2]> lrange jielist 0 -1
1) "12"
127.0.0.1:6379[2]> LPUSH jielist 5
(integer) 2
127.0.0.1:6379[2]> LPUSH jielist 5
(integer) 3
127.0.0.1:6379[2]> LPUSH jielist 5
(integer) 4
127.0.0.1:6379[2]> LPUSH jielist 5
(integer) 5
127.0.0.1:6379[2]> lrem jielist -2 5 #从尾部搜索 删除至多两个5
(integer) 2
127.0.0.1:6379[2]> LRANGE jielist 0 -1
1) "5"
2) "5"
3) "12"
127.0.0.1:6379[2]> blpop jielist timeout 1 #移除并获取第一个元素 如果没有元素 则会堵塞 等待超时弹出为止
1) "jielist"
2) "5"
127.0.0.1:6379[2]>
可以把list当做链表
3:Set(集合):
- 常用方法:以s开头:

127.0.0.1:6379[8]> sadd set 1 2 3 4 #向set中添加4个数据
(integer) 4
127.0.0.1:6379[8]> SCArd set #查看set中的元素个数
(integer) 4
127.0.0.1:6379[8]> smembers set #查看set的所有元素
1) "1"
2) "2"
3) "3"
4) "4"
127.0.0.1:6379[8]> SISMEMBER set 10 #查看元素是否是set中的
(integer) 0 #不是为0
127.0.0.1:6379[8]> SISMEMBER set 2
(integer) 1 #是为1
127.0.0.1:6379[8]> SRANDMEMBER set 4 #随机返回4个元素
1) "1"
2) "2"
3) "3"
4) "4"
127.0.0.1:6379[8]> spop set 1 #随机移除1为元素
1) "4"127.0.0.1:6379[8]> smove set myset 1 #将set中的1移动到myset中
(integer) 1
127.0.0.1:6379[8]> SMEMBERS myset
1) "1"
127.0.0.1:6379[8]> srem set 2 #在set中移除2
(integer) 1
127.0.0.1:6379[8]> srem set 3
(integer) 1
127.0.0.1:6379[8]> SMEMBERS set
(empty array)
127.0.0.1:6379[8]> sadd set 1 2 3 4 #赋值
(integer) 4
127.0.0.1:6379[8]> sadd set1 3 4 5 6
(integer) 4
127.0.0.1:6379[8]> sadd set2 2 3 4
(integer) 3
127.0.0.1:6379[8]> sdiff set set1 set2 #返回所有的差集
1) "1"
127.0.0.1:6379[8]> sdiff set set1
1) "1"
2) "2"
127.0.0.1:6379[8]> sdiff set1 set2
1) "5"
2) "6"
127.0.0.1:6379[8]> sinter set set1 #求 set和set1的交集
1) "3"
2) "4"
127.0.0.1:6379[8]> sinter set set2
1) "2"
2) "3"
3) "4"
127.0.0.1:6379[8]> SUNION set set1 求set 和set1 的并集
1) "1"
2) "2"
3) "3"
4) "4"
5) "5"
6) "6"
127.0.0.1:6379[8]> SUNION set set2
1) "1"
2) "2"
3) "3"
4) "4"
特点: 无序 不可重复 类似于java中的set集合 redis中的set集合是哈希表实现的;
4:Hash(哈希):
- hash和之前的区别就是 之前是key value的 然后现在是key map(key value)
- 方法以h开头
常用方法: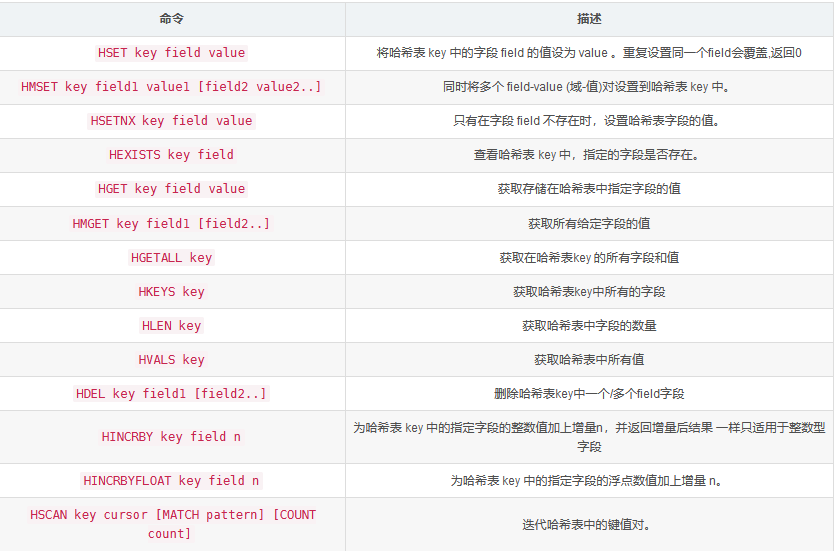
方法实现:
127.0.0.1:6379[5]> hset hash name jie #生成一个hash对象设置name为jie
(integer) 1
127.0.0.1:6379[5]> hset hash name jie
(integer) 0
127.0.0.1:6379[5]> hset hash age 10 #设age为10
(integer) 1
127.0.0.1:6379[5]> hset hash key jiejie
(integer) 1
127.0.0.1:6379[5]> HEXISTS hash name #查看name是否在hash中存在
(integer) 1
127.0.0.1:6379[5]> hmget hash name 查看 hash中的name的value
1) "jie"
127.0.0.1:6379[5]> hmget hash name age key #获得指定元素的多个value
1) "jie"
2) "10"
3) "jiejie"
127.0.0.1:6379[5]> HGETall hash #获得hash中所有key value
1) "name"
2) "jie"
3) "age"
4) "10"
5) "key"
6) "jiejie"
127.0.0.1:6379[5]> hkeys hash #获得hash中的所有key
1) "name"
2) "age"
3) "key"
127.0.0.1:6379[5]> hvals hash #获得hash中的所有value
1) "jie"
2) "10"
3) "jiejie"
127.0.0.1:6379[5]> hdel hash name #删除hash中的name
(integer) 1
127.0.0.1:6379[5]> HINCRBY hash age 10 #hash中的age值加10
(integer) 20
127.0.0.1:6379[5]> HINCRBY hash key 20 #非整数型不可 会报错
(error) ERR hash value is not an integer
Hash适合对象的存储 适合经常变动的信息
5:Zset(有序集合):
- 每个元素都会关联一个double类型的分数(score)。
- redis正是通过分数来为集合中的成员进行从小到大的排序。
- score相同:按字典顺序排序
- 有序集合的score可以相同但成员不能相同
- 方法以z开头
方法: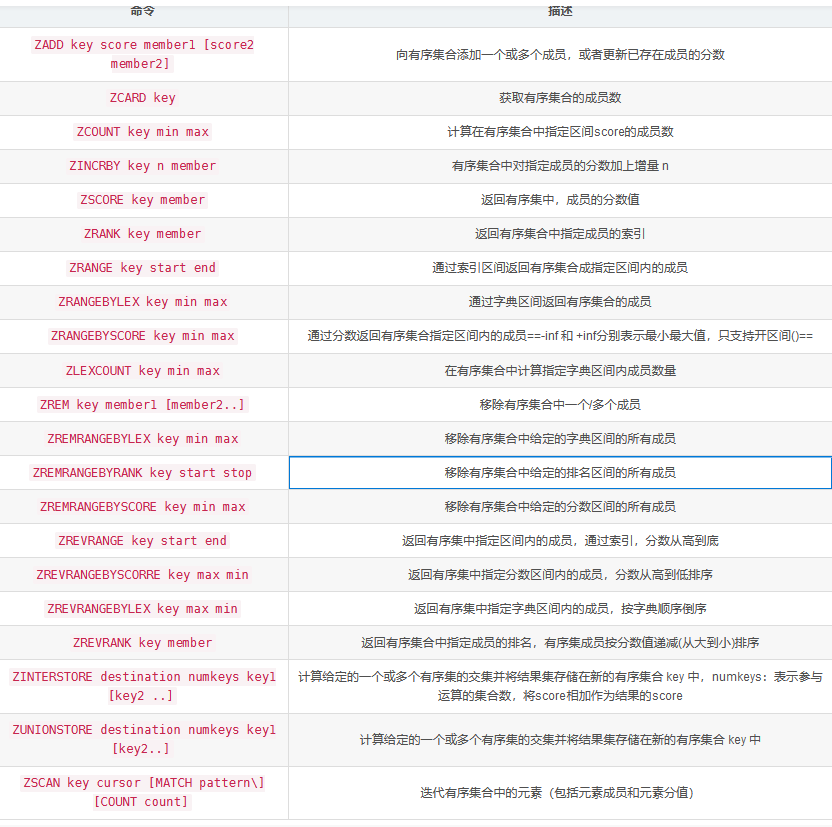
方法实现:
127.0.0.1:6379[2]> zadd zset1 1 lu 2 yun 3 jie #往zset1中添加元素lu 记得给数值来作为以后排序的标志
(integer) 3
127.0.0.1:6379[2]> ZCARD zset1 #查看zset1中有几个元素
(integer) 3
127.0.0.1:6379[2]> ZCOUNT zset1 0 2 #查看0到2区间的元素个数
(integer) 2
127.0.0.1:6379[2]> ZINCRBY zset1 2 lu #在lu的score+2
"3"
127.0.0.1:6379[2]> ZSCORE zset1 jie#查看jie的score
"3"
127.0.0.1:6379[2]> zrange zset1 0 -1#获取全部成员
1) "yun"
2) "jie"
3) "lu"
127.0.0.1:6379[2]> ZRANGEBYLEX zset1 - + #返回所有成员
1) "yun"
2) "jie"
3) "lu"
127.0.0.1:6379[2]> ZRANGEBYLEX zset1 - + limit 0 3 #分页显示第0-3的数据
1) "yun"
2) "jie"
3) "lu"127.0.0.1:6379[2]> ZRANGEBYLEX zset1 [jie [yun #显示[jie-yun]的字典区间的成员
1) "yun"
2) "jie"
3) "lu"
127.0.0.1:6379[2]> zrem zset1 jie #删除jie
(integer) 1
127.0.0.1:6379[2]> ZREMRANGEBYrank jie 0 1 #移除 0到1的所有成员
(integer) 2
127.0.0.1:6379[2]> ZREVRANGE jie 0 2 #按score递减排序 然后按照索引 返回结果0~2
1) "c"
127.0.0.1:6379[2]> zadd jie1 1 a 2 b 3 c
(integer) 3
127.0.0.1:6379[2]> ZREVRANGE jie1 0 3 #倒序
1) "c"
2) "b"
3) "a"127.0.0.1:6379[2]> ZRevrank jie1 b #按score递减排序 然后返回b的索引
(integer) 1
127.0.0.1:6379[2]> zadd xiaojie1 1 50 2 60 3 90
(integer) 3
127.0.0.1:6379[2]> zadd xiaojie2 1 60 2 60 3 90
(integer) 2
127.0.0.1:6379[2]> ZINTERSTORE xiaojie3 2 xiaojie1 xiaojie2 #合并两个集合然后放到xiaojie3里面
(integer) 2
127.0.0.1:6379[2]> zrange xiaojie3 0 -1 withscores #合并后的score是之前集合中所有score的和
1) "60"
2) "4"
3) "90"
4) "6"
127.0.0.1:6379[2]> zrange xiaojie3 0 -1 withscores #取一个集合的成员score最小值作为结果的1) "60"
2) "4"
3) "90"
4) "6"
今天心情阴沉 还有redis的三大特殊类型明天更!!!
Redis的五大数据类型(简单使用)的更多相关文章
- redis之五大数据类型
redis之五大数据类型 redis redis的两种链接方式 简单链接 1234 import redisconn = redis.Redis(host='10.0.0.200',port=6379 ...
- Redis(三)--- Redis的五大数据类型的底层实现
1.简介 Redis的五大数据类型也称五大数据对象:前面介绍过6大数据结构,Redis并没有直接使用这些结构来实现键值对数据库,而是使用这些结构构建了一个对象系统redisObject:这个对象系统包 ...
- Redis的五大数据类型以及key的相关操作命令
Redis的五大数据类型 redis的数据都是以key/value存储,所以说,五大类型指的是value的数据类型 String 字符串,作为redis的最基本数据类型 redis中的string类型 ...
- 面试官:讲讲Redis的五大数据类型?如何使用?(内含完整测试源码)
写在前面 最近面试跳槽的小伙伴有点多,给我反馈的面试情况更是千差万别,不过很多小伙伴反馈说:面试中的大部分问题都能够在我的公众号[冰河技术]中找到答案,面试过程还是挺轻松的,最终也是轻松的拿到了Off ...
- redis 哈希数据类型简单操作(实现购物车案例)
这里不累赘如何安装redis和php redis扩展,主要熟悉调用redis哈希数据类型 简单方法操作如下 1:hSet 2:hGet 4:hDel 5:hGetAll 4:hExists 5:hI ...
- 解析Redis操作五大数据类型常用命令
摘要:分享经常用到一些命令和使用场景总结,以及对Redis中五大数据类型如何使用cmd命令行的形式进行操作的方法. 本文分享自华为云社区<Redis操作五大数据类型常用命令解析>,作者:灰 ...
- Redis详解(五)------ redis的五大数据类型实现原理
前面两篇博客,第一篇介绍了五大数据类型的基本用法,第二篇介绍了Redis底层的六种数据结构.在Redis中,并没有直接使用这些数据结构来实现键值对数据库,而是基于这些数据结构创建了一个对象系统,这些对 ...
- Redis 详解 (五) redis的五大数据类型实现原理
目录 1.对象的类型与编码 ①.type属性 ②.encoding 属性和 *prt 指针 2.字符串对象 3.列表对象 4.哈希对象 5.集合对象 6.有序集合对象 7.五大数据类型的应用场景 8. ...
- redis的五大数据类型实现原理
1.对象的类型与编码 Redis使用前面说的五大数据类型来表示键和值,每次在Redis数据库中创建一个键值对时,至少会创建两个对象,一个是键对象,一个是值对象,而Redis中的每个对象都是由 redi ...
- redis之五大数据类型介绍
目录 redis五大数据类型 1. string(字符串) 特点: 格式: 基本操作: 2. hash(哈希) 特点: 格式: 基本操作 3. list(列表) 特点 格式 基本操作 4. set(集 ...
随机推荐
- linux中的sar命令
linux中的sar命令 sar命令的安装 [root@localhost test]# yum install sysstat 安装成功! sar命令说明 语法格式 sar [ 选项 ] [ < ...
- Vue element-ui 动态生成自定义table表头实现数据渲染
需求:1)表头的数据是动态的,有可能字段值很长且很多.解决方案自定义动态表头,字段长使用文字提示[el-tooltip组件]: 2)需要对表格data中的数据值进行枚举转成中文值,且显示不同的颜色. ...
- 前端设计模式:工厂模式(Factory)
00.基础概念 工厂模式封装了对象的创建new(),将消费者(使用)和生产者(实现)解耦. 工厂是干什么的?工厂是生产标准规格的商品的地方,建好工厂,投入原料(参数),产出特定规格的产品.so,工厂模 ...
- Python面向对象——封装
文章目录 内容回顾 封装 为何要隐藏? 作业 内容回顾 上节课复习: 1.编程范式/思想 面向过程 介绍: 核心是"过程"二字 过程就是"流水线" 过程终极奥义 ...
- 成本阶问题:财务模块axcr004合计金额检核表第18行合计金额与明细差异过大问题处理?
财务模块axcr004合计金额检核表第18行合计金额与明细差异过大问题处理? 可能原因:生产开立工单时元件未建在生产料件BOM明细中,导致成本阶没有算到,需要手动更改成本阶. 公式: 处理办法:修改成 ...
- android 中ids.xml资源的使用
ids.xml 前面我们见识过ids.xml文件,但是这个文件是什么意思呢?我们来看下文档中的介绍: 先看下它给的例子: XML file saved at res/values/ids.xml: 使 ...
- go defer简介
思考 开始之前,先考虑下下面的代码的执行结果: package main import "fmt" func test() int { i := 0 defer func() { ...
- CSP-J 2022 游记
10.9 早上睡到 7:00. 上午继续学习 Vim,学习哈希表. 10.11 白天线段树,区间加从六参改成四参就过了 晚上模拟赛,感觉良好 10.16 膜你赛,std变量命名毒瘤. 想用 geogb ...
- CSP2023 模拟赛总结合集
9.9 ZZFLS 感觉 ucup 剩下的题完全不可做了啊!先对比赛时间来写总结对队友道歉(鞠躬.jpg 开题策略很失败.开场 30min 得的分数是一整场考试的分数. 开题,发现 T1 是水题,30 ...
- 一步步带你剖析Java中的Reader类
本文分享自华为云社区<深入理解Java中的Reader类:一步步剖析>,作者:bug菌. 前言 在Java开发过程中,我们经常需要读取文件中的数据,而数据的读取需要一个合适的类进行处理.J ...