Python——第二章:字典(dictionary)以及 添、删、改、查
首先, 字典是以键值对的形式进行存储数据的,必须有键【key】,有值【value】
字典的表示方式: {key:value, key2:value, key3:value}
举例:
dic = {"jay": "周杰伦", "金毛狮王": "谢逊"}
val = dic["金毛狮王"] # 和列表的使用区别只是把索引位置换成了key
print(val)
#运行结果
谢逊*字典的key必须是可哈希的数据类(不可变)
dic = {[]:123}
print(dic)
#执行结果
dic = {[]:123}
^^^^^^^^
TypeError: unhashable type: 'list'*字典的value可以是任何数据类型
dic = {"汪峰的孩子": ["孩子1", "孩子2"]}字典的增、删、改、查
字典新增
dic = dict()#创建一个空字典
#给字典赋值'jay'和1两对儿键值
dic['jay'] = "周杰伦"
dic[1] = 123
print(dic)
#输出字典dic
{'jay': '周杰伦', 1: 123}另一种新增方式dic.setdefault()# 设置默认值方式
这种新增方式叫做设置默认值,如果设置的key不存在,会增加一对儿键值
dic = {'jay': '周杰伦', 1: 123}
dic.setdefault("tom", "胡辣汤")
print(dic)
#运行结果
{'jay': '周杰伦', 1: 123, 'tom': '胡辣汤'}如果该key的value值已存在,将没有任何效果
dic = {'jay': '周杰伦', 1: 123}
dic.setdefault("jay", "胡辣汤") # 设置默认值. 如果以前已经有了jay了. setdefault就不起作用了
print(dic)
#运行结果
{'jay': '周杰伦', 1: 123}字典修改
字典中不允许有2个完全相同的key存在,当已有key存在时,就变成了value值的修改操作了
dic['jay'] = "昆凌" # 此时, 字典中已经有了jay. 此时执行的就是修改操作了
print(dic)
#执行结果
{'jay': '昆凌', 1: 123}字典的查询
print(dic['jay'])
print(dic.get('jay')) 如果出现不存在的key,其中print(dic['jay10010'])的查询方式会报错
print(dic['jay10010']) # 如果key不存在. 程序会报错. 当你确定你的key是没问题的, 可以用
#运行结果
print(dic['jay10010']) # 如果key不存在. 程序会报错. 当你确定你的key是没问题的, 可以用
~~~^^^^^^^^^^^^
KeyError: 'jay10010'而这种查询方式print(dic.get('jay10086'))会返回None
print(dic.get('jay10086')) # 如果key不存在. 程序返回None. 当不确定你的key的时候. 可以用
#运行结果
None*这两种查询操作,在实际中被使用的比例是50:50的
当确定你的key是没问题的, 可以用:print(dic['jay10010']) # 如果key不存在. 程序会报错.
当不确定你的key的时候. 可以用:print(dic.get('jay10086')) # 如果key不存在. 程序返回None.
这里特意强调解释一下None的概念
None 是Python中的一个关键字,还被特殊标记了特殊的醒目颜色
None空还是一个单独的类型NoneType,单纯的就是空, 表示没有的意思。还不能做任何操作
a = None
print(type(a))
#输出结果
<class 'NoneType'>空字符串与空的区别:
空字符串可以做其他操作
空什么都不可以操作,操作就报错
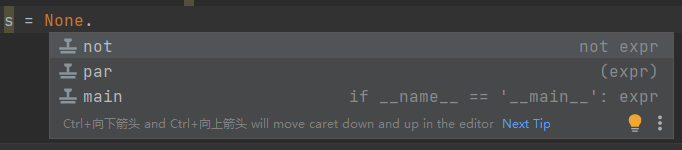
s = None.xxx
^^^^^^^^
AttributeError: 'NoneType' object has no attribute 'xxx'空存在的意义就是当出现这种查询不到的情况时,返回一个没有的信息,以提示用户没有任何返回,避免程序报错。
举例:
dic = {
"赵四": "特别能歪嘴",
"刘能": "老, 老四啊...",
"大脚": "跟这个和那个搞对象",
"大脑袋": "瞎折腾....",
}
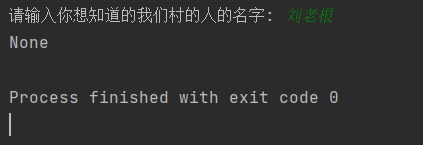
name = input("请输入你想知道的我们村的人的名字: ")
val = dic.get(name)
print(val)如果你输入了一个不存在的名字(刘老根),就会返回:None
因此一般我们还会加入if判断,以回复不同的情况,这里就充分用到了None
dic = {
"赵四": "特别能歪嘴",
"刘能": "老, 老四啊...",
"大脚": "跟这个和那个搞对象",
"大脑袋": "瞎折腾....",
}
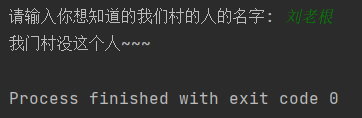
name = input("请输入你想知道的我们村的人的名字: ")
val = dic.get(name)
if val is None:
print("我门村没这个人~~~")
else:
print(val)运行后的结果:
字典的删除
dic = {
"赵四": "特别能歪嘴",
"刘能": "老, 老四啊...",
"大脚": "跟这个和那个搞对象",
"大脑袋": "瞎折腾....",
}
dic.pop("大脚") # 根据key去删除
print(dic)
#输出结果
{'赵四': '特别能歪嘴', '刘能': '老, 老四啊...', '大脑袋': '瞎折腾....'}还有一种强烈不建议的删除方法
del dic['jay']
#执行结果
{1: 123}*如果需要使用for循环删除,那么不能直接对原字典pop操作,因为在每执行过一次后,字典的大小会发生改变,因此会出现错乱的现象(类似之前的for循环删除列表的逻辑)
举例:删除key中以“大”字开头的
for key in dic:
if key.startswith("大"):
dic.pop(key)
print(dic)
#运行结果
for key in dic:
RuntimeError: dictionary changed size during iteration #在运行过程中,字典的大小发生了改变。因此我们需要优化代码,先将需要删除的key转存出来,然后执行pop操作
这次循环读取的是列表的字段,删除的是字典中的内容,这里不是循环字典再删除字典
temp = [] # 存放即将要删除的key
for key in dic:
if key.startswith("大"):
temp.append(key)
#dic.pop(key) # dictionary changed size during iteration
for t in temp: # *循环读取的是列表的字段,删除的是字典中的内容,这里不是循环字典再删除字典
dic.pop(t)
print(dic)
#执行结果
{'赵四': '特别能歪嘴', '刘能': '老, 老四啊...'}Python——第二章:字典(dictionary)以及 添、删、改、查的更多相关文章
- 简学Python第二章__巧学数据结构文件操作
#cnblogs_post_body h2 { background: linear-gradient(to bottom, #18c0ff 0%,#0c7eff 100%); color: #fff ...
- python数据类型:字典Dictionary
python数据类型:字典Dictionary 字典是一种可变容器模型,可以存储任意类型对象 键是唯一的,但是值不需要唯一 值可以取任何数据类型,但是键必须是不可变的,如字符串,数字,元组 创建字典: ...
- python学习-62 类属性的增 删 该 查
类属性 1.类属性 类属性又称为静态变量,或者是静态数据.这些数据是与它们所属的类对象绑定的,不依赖于任何类实例. 2.增 删 改 查 class zoo: country = 'china' def ...
- iOS sqlite3 的基本使用(增 删 改 查)
iOS sqlite3 的基本使用(增 删 改 查) 这篇博客不会讲述太多sql语言,目的重在实现sqlite3的一些基本操作. 例:增 删 改 查 如果想了解更多的sql语言可以利用强大的互联网. ...
- django ajax增 删 改 查
具于django ajax实现增 删 改 查功能 代码示例: 代码: urls.py from django.conf.urls import url from django.contrib impo ...
- 好用的SQL TVP~~独家赠送[增-删-改-查]的例子
以前总是追求新东西,发现基础才是最重要的,今年主要的目标是精通SQL查询和SQL性能优化. 本系列主要是针对T-SQL的总结. [T-SQL基础]01.单表查询-几道sql查询题 [T-SQL基础] ...
- iOS FMDB的使用(增,删,改,查,sqlite存取图片)
iOS FMDB的使用(增,删,改,查,sqlite存取图片) 在上一篇博客我对sqlite的基本使用进行了详细介绍... 但是在实际开发中原生使用的频率是很少的... 这篇博客我将会较全面的介绍FM ...
- Python 第二章-列表和元组
第二章-列表和元组 2.0 在Python中,最基本的数据结构是序列(sequence).序列中的每个元素被分配一个序列号-即元素的位置, 也称为索引.第一个索引是0,第二个是1,以此类推. ...
- ADO.NET 增 删 改 查
ADO.NET:(数据访问技术)就是将C#和MSSQL连接起来的一个纽带 可以通过ADO.NET将内存中的临时数据写入到数据库中 也可以将数据库中的数据提取到内存中供程序调用 ADO.NET所有数据访 ...
- MVC EF 增 删 改 查
using System;using System.Collections.Generic;using System.Linq;using System.Web;//using System.Data ...
随机推荐
- Spring Cache + Caffeine实现本地缓存
Caffeine简介 Caffeine是一个高性能,高命中率,低内存占用,near optimal 的本地缓存,简单来说它是 Guava Cache 的优化加强版 依赖 <dependency& ...
- 洛谷题解 | AT_abc321_c Primes on Interval
目录 题目翻译 题目描述 输入格式 输出格式 样例 #1 样例输入 #1 样例输出 #1 样例 #2 样例输入 #2 样例输出 #2 样例 #3 样例输入 #3 样例输出 #3 题目简化 题目思路 A ...
- Java虚拟机(JVM):第三幕:自动内存管理 - 垃圾收集器与内存分配策略
前言:Java与C++之间有一堵高墙,主要是有内存动态分配和垃圾收集技术组成的.墙外的人想要进来,墙内的人想要出去. 一.概述 每一个栈帧中分配多少内存基本上是在类结构确定下来时就已知的.内存的分配和 ...
- ApiPost发送请求报错UT000036: Connection terminated parsing multipart data
发送请求报错Caused by: java.io.IOException: UT000036: Connection terminated parsing multipart data 这个报错是因为 ...
- 4款.NET开源的Redis客户端驱动库
前言 今天给大家推荐4款.NET开源免费的Redis客户端驱动库(以下排名不分先后). Redis是什么? Redis全称是REmote DIctionary Service,即远程字典服务.Redi ...
- docker 下拉取oracle_11G镜像配置
1.拉取镜像 docker pull registry.cn-hangzhou.aliyuncs.com/helowin/oracle_11g#查看镜像信息docker images 2.创建容器 # ...
- 定时重启Nginx、MySql等服务
利用 Linux Crontab,每天定时重启 Nginx.MySQL等服务. 命令行格式说明 f1 f2 f3 f4 f5 program 其中 f1 是表示分钟,f2 表示小时,f3 表示一个月份 ...
- vue本地能够访问图片,打包项目之后图片无法访问
//template中 <img :src="boxHerf" /> //js let boxHerf = ref('/src/assets/images/contai ...
- Altium designer 设置覆铜与板框间距
新版Altium designer不再推荐使用 Keep-Out 层作为板框 以前使用 Keep-Out 作为板框的一个很大原因是因为 Keep-Out 自带板框间距属性.省去甚至不用考虑铺铜的边缘问 ...
- Jdk_HashMap 源码 —— hash(Object)
Jdk 源码 HashMap 的源码是在面试中考的算是比较多的,其中有很多高性能的经典写法,也值得多学习学习. 本文是本人在阅读和学习源码的过程中的笔记(不是教程),如有错误欢迎指正. Jdk Ver ...