快速上手 dbt 数据转换工具 -- dbt core 命令进阶篇

引
根据第一篇文章的约定,我想通过接下来的几篇文章带大家进一步了解 dbt 的用法,原计划这篇文章我会介绍 dbt 命令的进阶用法,进一步认识 dbt 的配置以及如何创建增量表等等零零散散十几个方面的知识点,结果在我写完命令部分发现篇幅就过长了,考虑到大家对于知识的吸收,想了想还是把命令单独作为一个篇章,那么通过本文,你将了解 dbt 命令的如下几个知识点:
- 如何运行执行条件的命令,比如指定项目,指定目录,指定 tag
- 如何运行某个模型以及它的所有上下游模型
- 如何运行同时符合多个条件下的模型
- 使用通配符指定模型
- 如何排除特定模型
- 如何强制更新增量表模型
那么让我们开始本篇文章的学习。
一、运行指定条件的 model
在第一篇文章中,我们知道 dbt run 可用于启动并运行整个 dbt 项目,一个命令可直接运行你项目中的所有 models,但事实上有时候我们只更新了一个 model,且我只希望更新这一个 model,那么这时候你可以通过 --select 指定你需要运行的 model。
这是运行指定条件 model 的一些说明:
dbt run --select "my_dbt_project_name" # runs all models in your project
dbt run --select "my_dbt_model" # runs a specific model
dbt run --select "path.to.my.models" # runs all models in a specific directory
dbt run --select "my_package.some_model" # run a specific model in a specific package
dbt run --select "tag:nightly" # run models with the "nightly" tag
dbt run --select "path/to/models" # run models contained in path/to/models
dbt run --select "path/to/my_model.sql" # run a specific model by its path
让我来解释这些命令:
你也许已经在思考 dbt run --select "my_dbt_project_name" 与 dbt run 的区别了,事实上假设我们并未使用任何三方的 dbt package,那么这两个命令将毫无区别,但假设我们在自己的项目中使用了例如 dbt-ga4 的三方包,那么这个命令将派上用场。
事实上,任何一个 dbt package 都是一个独立的 dbt 项目,我们使用的三方 dbt package 其实就是把别人的项目引入到自己项目中而已。
假设我现在在项目中安装了三方包 dbt-ga4,如果我现在执行 dbt run,那么它将会执行我在项目中定义的以及 dbt-ga4 中所有的模型;但如果现在的需求是我只希望更新 dbt-ga4 这个三方包中的模型,或者只更新我们自己项目定义的模型,那么使用上面的命令将解决你的问题,比如:
-- 只运行自己项目中的模型,而不会运行三方包的模型
dbt run --select "my_dbt_project_name"
-- 只运行 dbt-ga4 中的模型
dbt run --select "ga4"
而项目的名称,我们可以在 dbt_project.yml 文件的 name 字段获取你的项目名称。
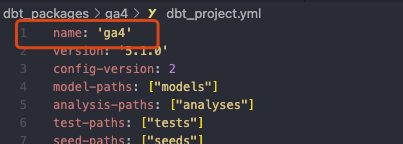
第二条命令好理解的多,比如我只希望运行项目中的 users model,你可以这样:
dbt run --select users
假设你希望 users 和 records 两个 model,可以使用空格隔开:
dbt run --select users records
第三条命令用于运行特定目录下的所有模型,毕竟如果一个目录下模型较多,一个个指定模型名称会比较麻烦,假设我们的目录如下:
my_project/
├── models/
│ ├── model1.sql
│ ├── model2.sql
│ └── my_directory/
│ ├── model3.sql
│ └── model4.sql
我想运行 my_directory 目录中的所有模型,您可以这样做:
dbt run --select "my_project.my_directory"
第四条命令用于运行指定 package 下某个目录下的所有模型,它与第三条命令的区别在于一个是我们自己的 dbt 项目,一个是我们引入的三方包,我知道你在想那我不如直接 dbt run --select model来运行某个模型,何必指定包名;有些时候引入的包过多可能存在 model 重名的情况,那么指定包名可以解决这个问题:
dbt run --select "my_package.some_model"
第五条命令用于运行执行 tag 的 model,在 dbt 中,我们可以给模型添加标签,以便于对模型进行分类和筛选。例如,如果有一些模型需要每晚运行,我们可以给这些模型添加 nightly 标签,然后使用这个命令来运行它们。
{{ config(tags = "nightly") }}
-- 模型的 SQL 代码
然后运行:
dbt run --select tag:nightly
第六条和第七条命令都用于运行 dbt 项目根目录路径下指定目录或者指定文件的模型,它与第三条命令的功能其实相同:
my_project/
├── models/
│ ├── model1.sql
│ ├── model2.sql
│ └── my_directory/
│ ├── model3.sql
│ └── model4.sql
dbt run --select "my_project.models.my_directory"
dbt run --select "my_project.models.my_directory.model3"
二、运行指定模型的上下游模型
除了上面提到的运行执行条件的模型外,在日常开发中,我们常常还有运行执行模型的上游或者下游模型的需求,举个例子,我现在更新了 users 模型,我希望更新 users 以及所有依赖 users 的下游模型(子模型),那么我们可以通过给 users 添加 + 来达到这个需求,命令如下:
dbt run --select "my_model+" # select my_model and all children
dbt run --select "+my_model" # select my_model and all parents
dbt run --select "+my_model+" # select my_model, and all of its parents and children
为了更好的理解,假设我们现在的模型依赖关系如下:

假设我们运行的是dbt run --select model_d+,那么它等同于运行:
dbt run --select model_d model_e model_f model_g
简单来理解 model_d+ 会运行 model_d 以及它的所有子模型。
同理,+my_model 会运行它以及所有它依赖的父模型,也就是上游模型:
dbt run --select +model_d
-- 等同于
dbt run --select model_a model_b model_c model_d
你也许会想,难道 dbt 自己会知道 model 的依赖顺序关系吗?比如先执行 model_a 再运行 model_d,关于这一点我会在后面的模型引用来解释这一点,事实上我们确实不太需要关注这个依赖关系,因为 dbt 就是会帮我维护好这份依赖关系。
当我们执行 dbt run --select +my_model+,很明显它会运行所有的上下游模型。
那么问题来了,假定 model_d 的上下游模型非常多,层级特别深,而我们确实只更新了上游的第一层模型,也就是 model_b 和 model_c,那么此时我们可以在 + 前添加数字用于指定层级,比如:
dbt run --select "my_model+1" # select my_model and its first-degree children
dbt run --select "2+my_model" # select my_model, its first-degree parents, and its second-degree parents ("grandparents")
dbt run --select "3+my_model+4" # select my_model, its parents up to the 3rd degree, and its children down to the 4th degree
假设我们运行的是 model_d+1,它等同于:
dbt run --select model_d model_e model_f
除了 + 之外,dbt 还提供了一个特殊符号 @ 用于执行执行模型的子模型以及子模型的父模型,我们假定有如下模型关系:
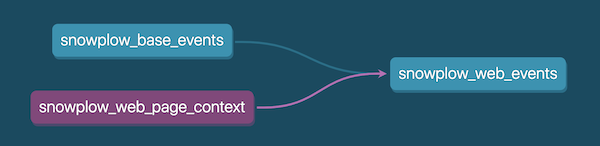
当我们执行
dbt run --models @snowplow_web_page_context # select my_model, its children, and the parents of its children
它等同于运行:
dbt run --models snowplow_web_page_context snowplow_base_events snowplow_web_events
三、使用,运算符
在上文,我们知道可以通过空格隔开多个模型名称,以达到同时运行多个模型,比如:
dbt run --select "+snowplow_sessions +fct_orders"
上述模型会运行 snowplow_sessions 和 fct_orders 以及它们所有的上游模型。
其实除了空格,dbt 还提供 , 来表示某些复杂的模型关系,比如两个模型公共的上游模型:
dbt run --select "+snowplow_sessions,+fct_orders"
以上语句会运行 snowplow_sessions、snowplow_sessions 以及他们所有的共同拥有的上游模型。
同理,下面的命令就表示运行这两个模型以及它们公共的下游模型:
dbt run --select "stg_invoices+,stg_accounts+"
除了模型之间的公共关系,, 还能表示条件的共有关系,比如下面的命令:
dbt run --select "marts.finance,tag:nightly"
这条命令用于运行marts.finance目录下所有 tag 为 nightly 的命令,如果需求中有这种条件关系,灵活使用 , 将非常有效。
四、运行某个模型之外的模型
我们可以通过 --select 用于运行执行模型,其实大家很容易想到另一个场景,假设我的项目中有 10 个模型,我需要运行除了 users 外的另外 9 个,那难道我们通过 --select 选择另外 9 个,其实 dbt 已经提供了 --exclude 用于排除某些模型,比如:
dbt run --select "my_package".*+ --exclude "my_package.a_big_model+" # select all models in my_package and their children except a_big_model and its children
比如上面的命令用于 my_package 下除了 a_big_model 以及它的下游模型之外的所有模型,是不是非常好理解。
当然,像--select 和 --exclude 除了给 dbt run 外,你一样能给 seed 或者 test 命令使用,比如:
dbt seed --exclude "account_parent_mappings" # load all seeds except account_parent_mappings
dbt test --exclude "orders" # test all models except tests associated with the orders model
五、使用 Unix 通配符匹配模型
如果你的 dbt 版本在 1.5 或者以上,你能使用 Unix 通配符来匹配特定的模型,以下是说明和例子:
| Wildcard | Description |
|---|---|
| * | matches any number of any characters (including none) |
| ? | matches any single character |
| [abc] | matches one character given in the bracket |
| [a-z] | matches one character from the range given in the bracket |
现在我们为每个通配符举例:
*:匹配任意数量的任意字符(包括零个字符)。例如,dbt run --select "orders*" 命令会运行所有以 “orders” 开头的模型。
?:匹配任意单个字符。例如,dbt run --select "orders_?" 命令会运行 orders_1、orders_2 等模型,但不会运行 orders_10,因为 10 是两个字符。
[abc]:匹配方括号中给出的任意一个字符。例如,dbt run --select "orders_[abc]" 命令会运行 orders_a、orders_b 和 orders_c 这三个模型。
[a-z]:匹配方括号中给出的字符范围内的任意一个字符。例如,dbt run --select "orders_[a-c]" 命令会运行 orders_a、orders_b 和 orders_c 这三个模型。
如果你对于正则表达式有些了解,我相信通配符对于你会非常好理解。
六、强制刷新模型
最后,我们来聊下强制刷新模型,事实上 dbt 中所有的模型可以是视图也可以是表,而如果我们创建表也可以创建普通表或者增量表,这两者的区别在于:
- 普通表:每次执行 model 都会完整销毁并重新
- 增量表:每次只增量更新给定时间范围内的数据模型,比如每天只更新昨天的数据。
增量表在对于时间分片表做增量更新时会非常好用,毕竟你不需要每次都全量运行所有模型。
由于增量表每次运行都只会更新指定时间范围的数据,假设我在后续就是增加了一个表字段,我希望全量更新全表,此时我们就能通过 --full-refresh 来全量更新表,比如 users 是一个增量模型,我现在希望全量更新:
dbt run --select users --full-refresh
那么到这里,我们完整的介绍了 dbt 中你可能用到的绝大多数命令,希望对你有所帮助。
同时,我在写这篇文章时已经是 2023 年的最后一天了,12月一直忙于年底的绩效统计以及晋升准备,迟迟未能更新,本文也算解决了这个月的拖延症,最后祝福你我新年快乐,2024年再继续加油吧,晚安。
快速上手 dbt 数据转换工具 -- dbt core 命令进阶篇的更多相关文章
- 数据转换工具DBT介绍及实操
一.什么是DBT dbt (data build tool)是一款流行的开源数据转换工具,能够通过 SQL 实现数据转化,将命令转化为表或者视图,提升数据分析师的工作效率.dbt 主要功能在于转换数据 ...
- 使用PowerApps快速构建基于主题的轻业务应用 —— 进阶篇
作者:陈希章 发表于 2017年12月14日 在上一篇 使用PowerApps快速构建基于主题的轻业务应用 -- 入门篇 中,我用了三个实际的例子演示了如何快速开始使用PowerApps构建轻业务应用 ...
- 一篇文章教你快速上手接口管理工具swagger
一.关于swagger 1.什么是swagger? swagger是spring fox的一套产品,可以作为后端开发者测试接口的工具,也可以作为前端取数据的接口文档. 2.为什么使用? 相比于传统的接 ...
- 快速上手Java开发工具Eclipse之简易手册
Eclipse下载,可以下载最新版本,文档是以2020-12R版本为例 http://www.eclipse.org/downloads/ 下载Packages即可 安装Eclipse 解压安装 除了 ...
- (绝对官方好用,快速上手)针对grunt之前写的那篇有些乱,这次总结个清晰的
安装 Grunt基于Node.js,安装之前要先安装Node.js,然后运行下面的命令. sudo npm install grunt-cli -g grunt-cli表示安装的是grunt的命令行界 ...
- Linux命令进阶篇-文件查看与查找
上一篇的博客对于Linux如何在不同目录下跳转和查看目录下内容做出了总结,主要靠cd和ls,很常见也很实用.但是你看到目录下面那么多不同花花绿绿的文件,心里是不是痒痒,是不是想进去一探究竟,有办法! ...
- Linux命令进阶篇之一
利用file命令查看那文件的类型 cd /etc 这里面的文件 命令:file 语法:file [-bLvz] 文件 解释:-b:显示结果,但是不显示文件名称 -L:直接显示符号链接所指向的文件的类型 ...
- linux 命令进阶篇之二
一.预备知识 选取init的进程. cat :由第一行开始显示文件内容 tac:由最后一行开始显示,有没有发现和cat是反过来写的 more:一页一页的显示内容 less:与more相似,但是可以往前 ...
- linu命令进阶篇
预备知识: 本实验要求实验者具备如下的相关知识. 前面我们学习了linux的文件系统,了解的文件系统的结构,也学了linux档案的属性和权限,以及其设定. 当我们执行命令操作一个文件的时候,却不知道这 ...
- Linux命令进阶篇之二
实验内容: cat :由第一行开始显示文件内容 tac:由最后一行开始显示,有没有发现和cat是反过来写的 more:一页一页的显示内容 less:与more相似, ...
随机推荐
- 解读Redis常见命令
Redis数据结构介绍 Redis是一个key-value的数据库,key一般是String类型,不过value的类型多种多样: 贴心小建议:命令不要死记,学会查询就好啦 Redis为了方便我们学习, ...
- RabbitMQ保姆级教程最佳实践
一.消息队列介绍 1.消息队列概念 1.MQ全称为Message Queue,消息队列(MQ)是⼀种应⽤程序对应⽤程序的通信⽅法. 应⽤程序通过读写出⼊队列的消息(针对应⽤程序的数据)来通信,⽽⽆需专 ...
- 全局重写Element UI中的Message消息提示显示时长
需求:Message消息提示显示时长过长 环境:"vue": "2.6.12"."element-ui": "^2.15.6&qu ...
- 探秘公有IP地址与私有IP地址的区别及其在路由控制中的作用
引言 IP地址是互联网通信中至关重要的组成部分.虽然在前一章节我们讲解了IP一些基础知识,但在我们日常生活中,我们经常听到公有IP地址和私有IP地址这两个术语.那么,公有IP地址和私有IP地址有何区别 ...
- C#/.NET/.NET Core优秀项目和框架2023年9月简报
前言 公众号每月定期推广和分享的C#/.NET/.NET Core优秀项目和框架(公众号每周至少推荐两个优秀的项目和框架当然节假日除外),公众号推文有项目和框架的介绍.功能特点以及部分截图等(打不开或 ...
- c语言代码练习2(1)
//利用while循环计算1-10阶乘的和#define _CRT_SECURE_NO_WARNINGS 1 #include <stdio.h> int main( ) { int i ...
- Arduino 麦克风声音传感器指南
麦克风声音传感器 麦克风声音传感器,顾名思义,检测声音.它可以测量声音的响度. 这些传感器的种类繁多. 在下图中,您可以看到 Arduino 最常用的. 最左边是KY-038,右边是LM393麦克风 ...
- .netCore 图形验证码,非System.Drawing.Common
netcore需要跨平台,说白点就是放在windows服务器要能用,放在linux服务器上也能用,甚至macos上. 很多时候需要使用到图形验证码,这就有问题了. 旧方案1.引入包 <Packa ...
- DRTREE - Dynamically-Rooted Tree 题解
DRTREE - Dynamically-Rooted Tree 本题建议评蓝. 思路: 题目就是要对一颗不定根树求子树权值和. 这题不带修,如果带修难度会增加一点,就跟 遥远的国度 差不多. 首先分 ...
- Speex详解(2019年09月25日更新)
Speex详解 整理者:赤勇玄心行天道 QQ号:280604597 微信号:qq280604597 QQ群:511046632 博客:www.cnblogs.com/gaoyaguo 大家有什么不明白 ...