Java 并发编程(六)并发容器和框架
传统 Map 的局限性
HashMap
JDK 1.7 的
HashMapJDK 1.7 中
HashMap的实现只是单纯的 “数组 + 链表 ” 的组合方式,具体的组成如下: [1]
[1]在 JDK 1.7 的实现中,HashMap 内部会维护一个数组,数组中的每个元素都是一个单向链表。这是因为不同的对象可能会有相同的
hashCodeHashMap关键的几个属性 :capacity:表示当前数组的容量,是中为 2^n,可以对数组进行扩容,扩容后的大小为原来数组长度的两倍loadFactor:负载因子,默认为 0.75,用于衡量当前数组的填充情况threshold:扩容时需要达到的阈值,为 \(capacity * loadFactor\)
put方法的实现,对应的源代码:public V put(K key, V value) {
// 处理 key 为 null 的情况,null 表示一个特殊的对象
if (key == null)
return putForNullKey(value);
/*
获取这个 key 对象的 hashCode,这个获取的过程很复杂,
只需要知道它能够尽可能地获取一个不会发生冲突的 code 就行了
*/
int hash = hash(key);
/*
通过得到的 hashCode 得到 key 在数组中所处的位置索引
在 JDK 1.7 中就是和 (table.length - 1) 执行按位与的操作
*/
int i = indexFor(hash, table.length); /*
遍历这个位置的不链表,检查是否这个 key 对象是否已经存在链表中了(这里需要使用到 equals 方法)
如果这个 key 已经存在于链表中了,那么只需要更新这个 key 所在的 Entry 的 value 即可
*/
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
} // 执行到这里就说明 key 对象不在原有的 HashMap 中 modCount++;
addEntry(hash, key, value, i); // 将这个键值对添加到这个数组位置对应的链表中
return null;
}
比较关系的是
addEntry方法的实现,具体的代码如下所示:void addEntry(int hash, K key, V value, int bucketIndex) {
/*
为了能够得到更好的效果,哈希表的数组的大小一般是元素的两倍,但是由于当前使用的 “数组 + 链表” 的组合结构
只要不超过当前的阈值即可达到近似的效果,因此当当前 HashMap 的元素个数已经达到了阈值时,
需要进行扩容以达到更好的效果
*/
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length); // 扩容,在此略过
/*
参考上文提到的生成 hashCode 的操作,当前数组的长度已经变了,
那么 key 的 hashCode 也是需要重新计算的
*/
hash = (null != key) ? hash(key) : 0;
// 下标也是需要重新计算的
bucketIndex = indexFor(hash, table.length);
} createEntry(hash, key, value, bucketIndex);
} // 插入新的 Entry
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex]; // 记录当前链表的头指针
// 很明显,这里使用到的是 “头插法” 的方式插入的元素
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}
现在,分析一下 JDK 1.7 中
HashMap在并发情况下可能会发生的一些问题,主要问题发生在 “插入新的 Entry” 这里,当存在多个线程同时插入元素时,由于没有任何同步机制来确保操作的可见性,因此可能会使得部分新插入的数据丢失,因此它不是线程安全的;除了这个问题之外,在极端的情况下,可能由于 “头插法” 的插入方式,使得多个线程同时修改后续结点的连接关系,这种情况下,很有可能导致这些节点之间的链接存在 “环”,是的HashMap的某些操作无法正常执行。JDK 1.8 的
HashMapJDK 1.8 的
HashMap与 JDK 1.7 最大的不同点在与使用的数据结构,JDK 1.8 继承了原有的 “数组 + 链表” 的组成结构,同时也引入了 “红黑树” 的数据结构来处理在元素个数较多的情况。现在 JDK 1.8
HashMap的一般结构如下: [1]
[1]“数组 + 链表” 和 “数组 + 红黑树” 在同一时刻只能有一种组合是有效的,
HashMap会自动根据当前的元素的数量自动地实现这两种组合之间的转换相关的比较重要的属性已经在 JDK 1.7 的
HashMap中提及到了,在此不做过多的赘述对于并发场景,主要关心的是
put方法,对应的源代码如下:public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
} // putVal
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
/*
JDK 1.8 使用 Node 替换掉了 Entry,但是如果使用 “数组 + 红黑树” 的组合结构的话,
那么将使用 TreeNode 作为 Entry 的实现
*/
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
/*
在 “数组 + 红黑树” 的组合情况下插入新的节点,相当于在红黑树中插入或者更新一个新的节点
同样是缺少同步机制的
*/
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
/*
重点在这,使用 “数组 + 链表” 的组合情况下,插入节点,
结合这里的条件,不难发现,这里的插入方式是 “尾插法”
*/
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize(); afterNodeInsertion(evict);
return null;
}
JDK 1.8 中 “数组 + 链表” 的插入方式改为了 “尾插法”,解决了 JDK 1.7 中可能会出现环的问题,但是由于缺少同步机制,不管是使用何种组合方式,都无法保证这个插入操作是线程安全的。
Hashtable
Hashtable 通过使得每个操作都加上 synchronized 修饰,使得每个操作都只能通过单个线程来访问,从根源上解决了并发带来的问题。但是缺点也很明显,每个操作都只能由单个线程访问,因此完全无法得到多线程带来的性能提升。
在实际使用过程中,由于 JVM 的锁消除机制,大部分的情况下 HashTable 的同步机制实际上是没有效果的,而且由于 Hashtable 无法得到多线程带来的性能提升,实际上很少会使用到,一般情况下都会直接使用 HashMap,如果要保证线程安全,那么一般会使用 ConcurrentHashMap,从而能够得到多线程带来的性能的提升
ConcurrentHashMap
如果想要使得 HashMap 成为一个线程安全的 Map 结构,可以通过 Collections.synchronizedMap(map) 将 HashMap 转换成为一个 SynchronizedMap,这种方式与使用 Hashtable 并没有什么不同,更好的选择方案是使用 ConcurrentHashMap。
Java 7 的 ConcurrentHashMap
JDK 1.7 中的 ConcurrentHashMap 通过引入分段锁的方式来提高并发操作的能力,在 JDK 1.7 中,ConcurrentHashMap 的结构如下:
 [1]
[1]
JDK 1.7 中ConcurrentHashMap 中常量字段如下:
// 默认初始容量
static final int DEFAULT_INITIAL_CAPACITY = 16;
// 默认负载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 默认并发级别
static final int DEFAULT_CONCURRENCY_LEVEL = 16;
static final int MAXIMUM_CAPACITY = 1 << 30;
static final int MIN_SEGMENT_TABLE_CAPACITY = 2;
static final int MAX_SEGMENTS = 1 << 16;
// 重试次数
static final int RETRIES_BEFORE_LOCK = 2;
JDK 1.7 中 ConcurrentHashMap 的构造函数如下:
// 最终都会走到这个构造函数
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
// Find power-of-two sizes best matching arguments
/*
通过 concurrencyLevel 计算并行级别 ssize,ssize 应当是大于或者等于
concurrencyLevel 的最小的 2 的 n 次方
*/
int sshift = 0;
int ssize = 1; // segment 数组的长度
while (ssize < concurrencyLevel) {
++sshift;
/*
为了能够通过按位于的散列算法来定位 segments 数组的索引,
必须保证 segments 数组额的长度是 2 的 n 次方
*/
ssize <<= 1;
}
// 计算并行级别结束
this.segmentShift = 32 - sshift; // 段偏移量,默认为 28
this.segmentMask = ssize - 1; // 段掩码,默认为 15
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;
// segment 内部数组的初始化容量,默认为 2
int cap = MIN_SEGMENT_TABLE_CAPACITY;
while (cap < c)
cap <<= 1; // 需要保证 segment 内部数组的长度也是 2 的 n 次方
// create segments and segments[0]
Segment<K,V> s0 =
new Segment<K,V>(loadFactor, (int)(cap * loadFactor),
(HashEntry<K,V>[])new HashEntry[cap]);
Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];
UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]
this.segments = ss;
}
put 方法:
public V put(K key, V value) {
Segment<K,V> s;
if (value == null)
throw new NullPointerException();
/*
第一次计算 hash 值,用于定位当前 key 在 segment 数组中的位置
*/
int hash = hash(key);
int j = (hash >>> segmentShift) & segmentMask; // 定位到segment
if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
s = ensureSegment(j); // 第一次访问segment时,创建segment对象(确保 segment 是存在的)
return s.put(key, hash, value, false); // 委托给特定的段
}
Segment 对象中的 put 方法:
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
/*
tryLock()加锁,不成功则执行scanAndLockForPut,先完成节点实例化
*/
HashEntry<K,V> node = tryLock() ? null : scanAndLockForPut(key, hash, value);
V oldValue;
try {
HashEntry<K,V>[] tab = table;
// 第二次 hash 用于获取在 Segment 数组中的索引
int index = (tab.length - 1) & hash;
HashEntry<K,V> first = entryAt(tab, index);
for (HashEntry<K,V> e = first;;) { // 进行元素定位即更新操作
if (e != null) {
K k;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) { // key 已存在
oldValue = e.value;
if (!onlyIfAbsent) { // onlyIfAbsent决定是否更新值
e.value = value;
++modCount; // 修改次数
}
break;
}
e = e.next;
}
else {
if (node != null)
node.setNext(first); // 头插法, node已经在尝试获取锁的时候实例化过了
else
node = new HashEntry<K,V>(hash, key, value, first); // 头插法, 未实例化过
int c = count + 1;
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node); // 扩容, 只对当前segment 扩容, 和 hashmap 扩容 类似
else
/*
设置 node 在 segment 中元素数组的位置,由于 table 是 volatile 变量,
因此对于 table 的写入操作对于其它线程来讲是可见的
*/
setEntryAt(tab, index, node); // 头插法
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
unlock();
}
return oldValue;
}
get 方法对应的源代码:
public V get(Object key) {
Segment<K,V> s; // manually integrate access methods to reduce overhead
HashEntry<K,V>[] tab;
int h = hash(key);
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE; // 定位到segment
/*
table、next 等共享变量都是 volatile 变量,因此对于它们的写入都会发生在读操作之前,
因此在这里就不需要再加锁
*/
if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&
(tab = s.table) != null) {
for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile
// 定位到在 segment 数组中的位置
(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);
e != null; e = e.next) {
K k;
if ((k = e.key) == key || (e.hash == h && key.equals(k)))
return e.value;
}
}
return null;
}
size 方法对应的源代码:
public int size() {
/*
先尝试两次不对Segment加锁方式来统计count值,如果统计过程中count发生变化了,再加锁。
如果没有改变,则返回size。
*/
final Segment<K,V>[] segments = this.segments;
int size;
boolean overflow; // true if size overflows 32 bits
long sum; // sum of modCounts
long last = 0L; // previous sum
int retries = -1; // first iteration isn't retry
try {
for (;;) {
if (retries++ == RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
ensureSegment(j).lock(); // force creation 两次尝试失败了,加锁
}
sum = 0L;
size = 0;
overflow = false;
for (int j = 0; j < segments.length; ++j) {
Segment<K,V> seg = segmentAt(segments, j);
if (seg != null) {
sum += seg.modCount;
int c = seg.count;
if (c < 0 || (size += c) < 0)
overflow = true;
}
}
/*
尝试成功(通过判断两次的总修改次数没有变化) 或者是 加锁之后肯定满足条件
*/
if (sum == last)
break;
last = sum;
}
} finally {
if (retries > RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
segmentAt(segments, j).unlock();
}
}
return overflow ? Integer.MAX_VALUE : size;
}
Java 8 的 ConcurrentHashMap
JDK 1.8 与 JDK 1.7 相比,具有以下的不同:
- 放弃分段锁
- 使用
Node+CAS+syncronized来保证线程安全性 - 底层使用 “数组 + 链表” 和 “数组 + 红黑树” 的方式来存储元素
源码分析在此略过。。。。。。
ConcurrentLinkedQueue
ConcurrentLinkedQueue 具有以下特点:
- 基于链接节点的先进先出的无界线程安全队列
- 使用
CAS来保证线程安全性
以 JDK 1.7 为例,介绍一下关于 ConcurrentLinkedQueue 的入队和出队操作
入队的 offer() 方法:
// 通过对 tailer (volatile 变量)的读来减少对 tailer 的写入次数
public boolean offer(E e) {
if (e == null) throw new NullPointerException();
final Node<E> n = new Node<E>(e); // 入队前,创建一个入队节点
retry:
// 使得入队的操作在 CAS 中最终能够成功
for (;;) {
// 创建一个指向tail节点的引用
Node<E> t = tail;
// p用来表示队列的尾节点,默认情况下等于tail节点。
Node<E> p = t;
/*
只有 tailer 距离新插入的节点长度大于 hops 时,才考虑更新 tailer,
这样就能够使得对 tailer 的写入次数减少,从而提高了性能
这种方式的缺点在于现在 tailer 的位置已经不再是实际尾节点了,
因此每次都需要再遍历 hops 次才能得到实际的尾节点
*/
for (int hops = 0; ; hops++) {
// 获得p节点的下一个节点。
Node<E> next = succ(p);
// next 节点不为空,说明 p 不是尾节点,需要更新 p 后在将它指向 next 节点
if (next != null) {
/*
如果已经至少越过了两个节点,且 tail 被修改
(tail 被修改,说明其他线程向队列添加了新的节点,且更新 tail 成功 )
*/
if (hops > HOPS && t != tail)
continue retry; // 跳出内层循环,重新开始迭代(因为 tail 刚刚被其他线程更新了)。
p = next;
}
// 如果 p 是尾节点,则设置 p 节点的 next 节点为入队节点。
else if (p.casNext(null, n)) {
/*
如果已经至少越过了一个节点(此时,tail 至少滞后尾节点两个节点)才去更新尾节点。
更新失败了也没关系,因为失败了表示有其他线程成功更新了 tail 节点
*/
if (hops >= HOPS)
casTail(t, n); // 更新 tail 节点,允许失败
return true;
}
// CAS 更新失败,p 有 next 节点, 则重新设置 p 节点
else {
p = succ(p);
}
}
}
}
// succ 的实现
final Node<E> succ(Node<E> p) {
Node<E> next = p.next;
/*
如果 p 节点的 next 域链接到自身(p 节点是哨兵节点, 也就是被出队的节点)
就跳转到 head,从 head 开始继续遍历,否则向后推进到下一个节点
从上面的 updateHead 方法 可以看出
*/
return (p == next) ? head : next;
}
出队操作的 poll 方法:
// 与 offer 方法类似,head 也不会在每次出队时就更新,这样就可以减少对 head 的写入操作从而提高性能
public E poll() {
Node<E> h = head;
// p表示头节点,需要出队的节点
Node<E> p = h;
for (int hops = 0;; hops++) {
// 获取p节点的元素
E item = p.item;
/*
如果p节点的元素不为空,使用CAS设置p节点引用的元素为null,
如果成功则返回p节点的元素。
*/
if (item != null && p.casItem(item, null)) {
if (hops >= HOPS) { // 通过 hops 变量来减少对 head 的写入次数
// 将p节点下一个节点设置成head节点
Node<E> q = p.next;
updateHead(h, (q != null) ? q:p);
}
return item;
}
/*
如果头节点的元素为空或头节点发生了变化,这说明头节点已经被另外
一个线程修改了。那么获取p节点的下一个节点
*/
Node<E> next = succ(p);
// 如果p的下一个节点也为空,说明这个队列已经空了
if (next == null) {
// 更新头节点。
updateHead(h, p);
break;
}
// 如果下一个元素不为空,则将头节点的下一个节点设置成头节点
p = next;
}
return null;
}
由于篇幅原因,JDK 1.8 的源码在此略过。。。。
阻塞队列
阻塞队列的类结构图如下所示:
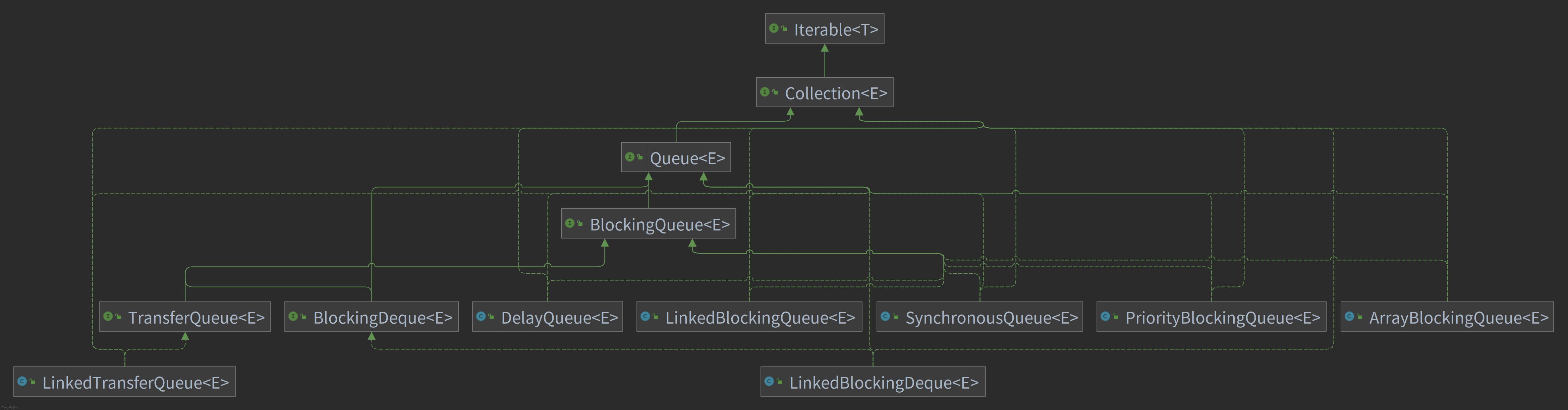
阻塞队列的阻塞体现在当队列已满或者队列为空时,对于队列的入队和出队操作都将导致当前的访问线程阻塞,直到满足对应操作的基本条件
方法的规范如下:

常见的阻塞队列的实现类:
ArrayBlockingQueue由数组组成的有界阻塞队列,默认情况下不保证线程公平地访问队列
LinkedBlockingQueue由链表组成的有界阻塞队列
PriorityBlockingQueue带有优先级的有界阻塞队列
DelayQueue使用优先队列实现的无界的延时阻塞队列,支持延时获取元素。使用场景:缓存系统的设计;定时任务调度
SynchronousQueue不存储元素的阻塞队列,表示每个
put操作都需要等待一个get操作,默认情况下不使用公平地访问队列使用场景:适合传递性的使用场景
LinkedTransferQueue由链表组成的无界阻塞队列
LinkedBlockingDeque由链表结构组成的双向阻塞队列
Fork/Join 框架
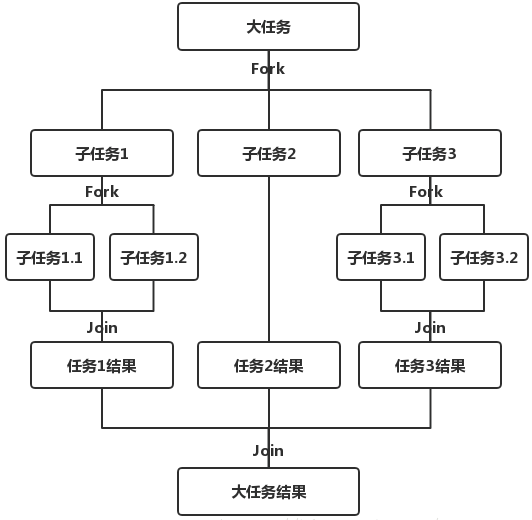
Fork 将一个大的任务拆分成多个小任务,使得小任务能够并发地执行;Join则是将多个子任务合并起来,汇总小任务的结果得到大任务的最终结果
处理结果如下图所示:
基本使用
创建任务
需要通过定一个类,继承
java.util.concurrent.ForkJoinTask来定义具体的任务,但是一般情况下,只需要继承java.util.concurrent.RecursiveTask或java.util.concurrent.RecursiveAction即可,两者分别处理含有返回结果和不包含处理结果的任务现在,使用
Fork/Join框架来处理从 \(1+2+3+……+100\) 的任务首先,定义一个任务,用于分割任务和实际处理任务:
static class CountTask extends RecursiveTask<Integer> {
private static final int THRESHOLD = Runtime.getRuntime().availableProcessors(); // 阈值
private static volatile int unit = -1;
private final int start;
private final int end; public CountTask(int start, int end) {
this.start = start;
this.end = end;
} @Override
protected Integer compute() {
int sum = 0;
boolean canCompute = (end - start) <= unit; if (canCompute) {
// 如果任务足够小就计算任务
for (int i = start; i <= end; i++) {
sum += i;
}
} else {
// 如果任务大于阈值,就分裂成多个子任务计算
CountTask[] tasks = new CountTask[THRESHOLD];
int[] res = new int[THRESHOLD];
// 第一次访问时设置 unit
if (unit < 0) unit = (int) Math.ceil((end - start) * 1.0 / THRESHOLD);
for (int i = 0; i < THRESHOLD; ++i) {
if (i == 0)
tasks[i] = new CountTask(start, start + (i + 1) * unit);
else
tasks[i] = new CountTask(start + i * unit + 1, Math.min(start + (i + 1) * unit, end));
} // 启动所有的子任务
for (CountTask task : tasks) task.fork(); // 等待子任务执行完,并得到其结果
for (int i = 0; i < res.length; ++i) {
res[i] = tasks[i].join();
} // 合并子任务
for (int val : res) sum += val;
} return sum;
}
}
运行任务
首先,任务运行要之
ForkJoinPool中才能运行,因此首先需要创建一个ForkJoinPool:ForkJoinPool pool = new ForkJoinPool();
随后,定义任务。并且获取结果:
CountTask task = new CountTask(1, 1000);
Future<Integer> res = pool.submit(task); if (task.isCompletedAbnormally()) {
task.getException().printStackTrace();
} System.out.println(res.get());
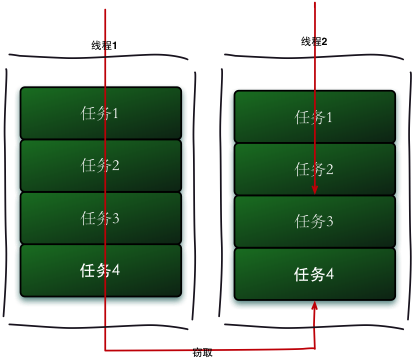
工作窃取算法
某个已经执行完自身小任务的线程从其它线程那里获取未执行的任务来执行,这样可以尽可能地得到多线程带来的性能提升
具体的处理情况如下:
参考:
[1] https://javadoop.com/post/hashmap
Java 并发编程(六)并发容器和框架的更多相关文章
- Java并发编程:同步容器
Java并发编程:同步容器 为了方便编写出线程安全的程序,Java里面提供了一些线程安全类和并发工具,比如:同步容器.并发容器.阻塞队列.Synchronizer(比如CountDownLatch). ...
- 【转】Java并发编程:同步容器
为了方便编写出线程安全的程序,Java里面提供了一些线程安全类和并发工具,比如:同步容器.并发容器.阻塞队列.Synchronizer(比如CountDownLatch).今天我们就来讨论下同步容器. ...
- 8、Java并发编程:同步容器
Java并发编程:同步容器 为了方便编写出线程安全的程序,Java里面提供了一些线程安全类和并发工具,比如:同步容器.并发容器.阻塞队列.Synchronizer(比如CountDownLatch). ...
- Java并发编程:并发容器ConcurrentHashMap
Java并发编程:并发容器之ConcurrentHashMap(转载) 下面这部分内容转载自: http://www.haogongju.net/art/2350374 JDK5中添加了新的concu ...
- Java并发编程:并发容器之CopyOnWriteArrayList(转载)
Java并发编程:并发容器之CopyOnWriteArrayList(转载) 原文链接: http://ifeve.com/java-copy-on-write/ Copy-On-Write简称COW ...
- Java并发编程:并发容器之ConcurrentHashMap(转载)
Java并发编程:并发容器之ConcurrentHashMap(转载) 下面这部分内容转载自: http://www.haogongju.net/art/2350374 JDK5中添加了新的concu ...
- Java并发编程:并发容器之ConcurrentHashMap
转载: Java并发编程:并发容器之ConcurrentHashMap JDK5中添加了新的concurrent包,相对同步容器而言,并发容器通过一些机制改进了并发性能.因为同步容器将所有对容器状态的 ...
- Java并发编程:并发容器之CopyOnWriteArrayList
转载: Java并发编程:并发容器之CopyOnWriteArrayList Copy-On-Write简称COW,是一种用于程序设计中的优化策略.其基本思路是,从一开始大家都在共享同一个内容,当某个 ...
- 【Java并发编程】并发编程大合集-值得收藏
http://blog.csdn.net/ns_code/article/details/17539599这个博主的关于java并发编程系列很不错,值得收藏. 为了方便各位网友学习以及方便自己复习之用 ...
- 【转】Java并发编程:并发容器之CopyOnWriteArrayList
Copy-On-Write简称COW,是一种用于程序设计中的优化策略.其基本思路是,从一开始大家都在共享同一个内容,当某个人想要修改这个内容的时候,才会真正把内容Copy出去形成一个新的内容然后再改, ...
随机推荐
- android图片缩放双击旋转效果
需要jar源码的请留言吧. 部分源码 demo下载地址 package uk.co.senab.photoview.sample; import android.app.ListActivity ...
- HBuilderX内置终端无法使用不能输入
找到HBuilderX的目录打开plugins\builtincef3terminal\script找到main.js用记事本或其他什么打开他 把这部分代码替换成这个再重启hbuilderX就可以了 ...
- Linux 在多个文件中搜索关键字
摘要:使用grep或者rg在当前目录下所有文件中查找关键字. 在Linux操作系统下,搜索文件中的关键字可帮助用户快速找到所需的信息,满足快速排查问题的需求.在大型系统中,文件可能被保存在多个目录 ...
- ansible 命令行模
ansible 命令行模 ansible命令格式 命令格式:ansible <组名> -m <模块> -a <参数列表> 查看已安装的模块 ansible-doc ...
- vite介绍
什么是 Vite 借用作者的原话: Vite,一个基于浏览器原生 ES imports 的开发服务器.利用浏览器去解析 imports,在服务器端按需编译返回,完全跳过了打包这个概念,服务器随起随用. ...
- 特殊符号传到后端发生变异 & "<>
业务遇到bug,前端传回数据 & ,到后台接收到的数据就是 & 后台接收到的数据就携带了amp;的后缀 网上查找原因,大部分说法是前端传回的数据导致,但是实际并不是,这里是框架的正则过 ...
- 嵌入式C编码规范
每个程序员都有自己的编码风格,自己喜欢就好. 嵌入式C编码规范 上述博文来自转载
- go基础-接口
一.概述 接口是面向对象编程的重要概念,接口是对行为的抽象和概括,在主流面向对象语言Java.C++,接口和类之间有明确关系,称为"实现接口".这种关系一般会以"类派生图 ...
- Python输入某年某月某日,判断这一天是这一年的第几天?
while 1: year = int(input('year:\n')) #输入年.月.日 month = int(input('month:\n')) day = int(input('day:\ ...
- JAVA学习week1
本周: 认识到Java是一门面向对象的编程语言,不仅吸收了C++语言的各种优点,还摒弃了C++里难以理解的多继承.指针等概念,因此Java语言具有功能强大和简单易用两个特征.Java语言作为静态面向对 ...