Nebula Graph 的 Ansible 实践
本文首发于 Nebula Graph 公众号 NebulaGraphCommunity,Follow & 看大厂图数据库技术实践
{kind=link}

背景
在 Nebula-Graph 的日常测试中,我们会经常在服务器上部署 Nebula-Graph。为了提高效率,我们需要一种工具,能帮我们做到快速部署,主要的需求:
- 可以使用非 root 账户部署 Nebula Graph,这样我们可以针对这个用户设置 cgroup 做资源限制。
- 可以在操作机上更改配置文件,然后分发到部署的集群上,方便我们做各种调参的测试。
- 可以使用脚本调用,方便以后我们继承在测试的平台或工具上。
工具选择上,早期有 Fabric 和 Puppet,比较新的工具有 Ansible 和 SaltStack。
Ansible 在 GitHub 上有 40K+ star, 而且在 2015年被 Red Hat 收购,社区比较活跃。很多开源项目都提供了 Ansible 的部署方式,比如 Kubernetes 中的 kubespray和 TiDB 中的 tidb-ansible。
综合下来,我们使用 Ansible 来部署 Nebula Graph。
Ansible 介绍
特点
Ansible 是开源的,自动化部署工具(Ansible Tower 是商业的)。具有以下的几个特点:
- 默认协议是基于 SSH,相比于 SaltStack不 需要额外部署 agent。
- 使用 playbook, role, module 来定义部署过程,比较灵活。
- 操作行为幂等。
- 模块化开发,模块比较丰富。
优缺点比较明显
- 使用 SSH 协议,优点是大多数机器默认只要有账号密码就可以通过 Ansible 完成部署,而缺点性能上会差一些。
- 使用 playbook 来定义部署过程,Python 的 Jinja2 作为模板渲染引擎,对于熟悉的人来说会比较方便,而对于没有使用过的人,会增加学习成本。
综上,适用于小批量机器的批量部署,不需要关心额外部署 agent 的场景,和我们的需求比较匹配。
部署逻辑
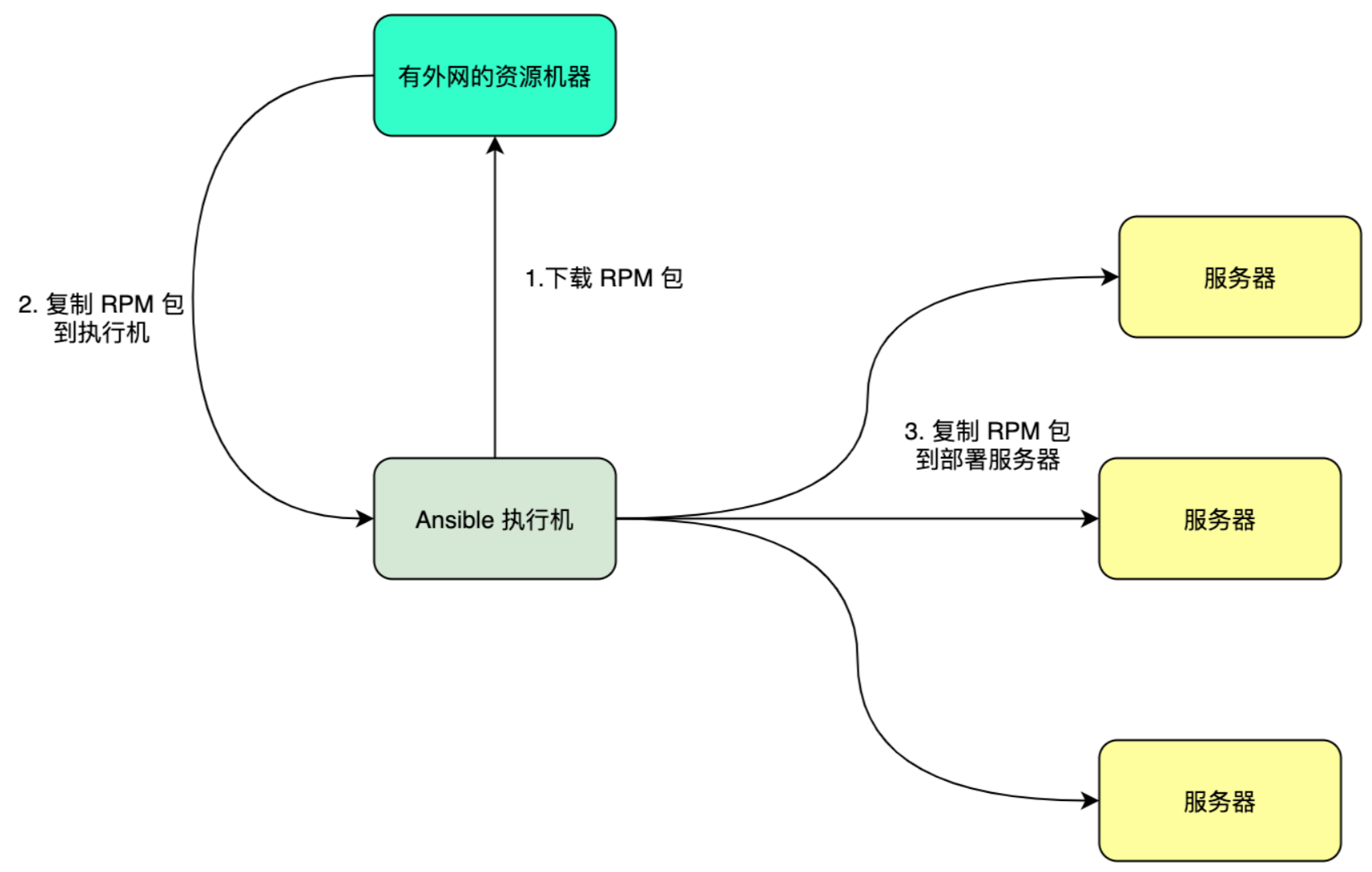
通常为了离线部署,可以把机器分为 3种角色。
- Ansible 执行机:运行 Ansible 的机器,需要能通过 SSH 连到所有机器。
- 有外网的资源机:运行需要连接外网的任务,比如下载 RPM 包。
- 服务器:即运行服务的服务器,可以网络隔离,通过执行机来部署
任务逻辑
Ansible 中,主要有三种层次的任务:
- Module
- Role
- Playbook
Module 分为 CoreModule 和 CustomerModule,是 Ansible 任务的基本单元。
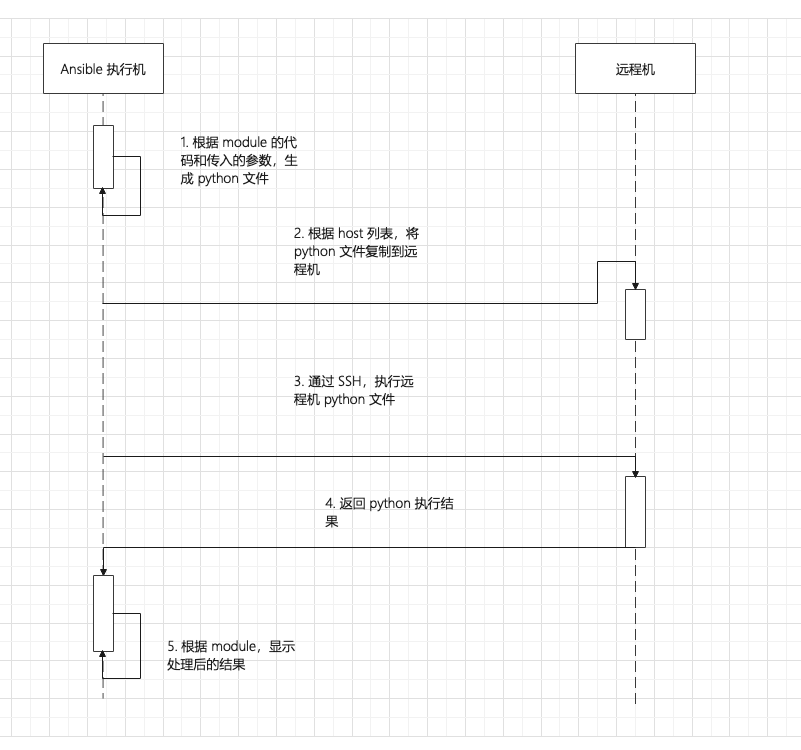
在运行任务的时候,首先 Ansible 会根据 module 的代码,将参数代入,生成一个新的 Python 文件,通过 SSH 放到远程的 tmp 文件夹,然后通过 SSH 远程执行 Python 将输出结果返回,最后把远程目录删除。
# 设置不删除 tmp 文件
export ANSIBLE_KEEP_REMOTE_FILES=1
# -vvv 查看 debug 信息
ansible -m ping all -vvv
<192.168.8.147> SSH: EXEC ssh -o ControlMaster=auto -o ControlPersist=30m -o ConnectionAttempts=100 -o UserKnownHostsFile=/dev/null -o StrictHostKeyChecking=no -o KbdInteractiveAuthentication=no -o PreferredAuthentications=gssapi-with-mic,gssapi-keyex,hostbased,publickey -o PasswordAuthentication=no -o 'User="nebula"' -o ConnectTimeout=10 -o ControlPath=/home/vesoft/.ansible/cp/d94660cf0d -tt 192.168.8.147 '/bin/sh -c '"'"'/usr/bin/python /home/nebula/.ansible/tmp/ansible-tmp-1618982672.9659252-5332-61577192045877/AnsiballZ_ping.py && sleep 0'"'"''
可以看到有这样的日志输出,AnsiballZ_ping.py 就是根据 module 生成的 Python 文件,可以登录到那台机器,执行 Python 语句看一下结果。
python3 AnsiballZ_ping.py
#{"ping": "pong", "invocation": {"module_args": {"data": "pong"}}}
返回了运行 Python 文件的标准输出,然后 Ansible 再对返回的结果做额外处理。
Role 是串联 module 的一系列任务,可以通过 register 来传递上下文参数。
典型例子:
- 创建目录
- 如果创建目录成功,继续安装,否则退出整个部署工程。
Playbook 是组织部署机器和 role 之间的关联。
通过在 inventory 对不同机器进行分组,对不同分组使用不同的 role 来部署,完成非常灵活的安装部署任务。
当 playbook 定义好之后,不同的环境,只要变更 inventory 中的机器配置,就可以完成一样的部署过程。
模块定制
自定义 filter
Ansible 使用 Jinja2 作为模板渲染引擎,可以用 Jinja2 自带的 filter ,比如
# 使用 default filter,默认输出 5
ansible -m debug -a 'msg={{ hello | default(5) }}' all
有时候,我们会需要自定义的 filter 来操作变量,典型的场景就是 nebula-metad 的 地址 --meta_server_addrs。
- 当只有 1 个 metad 的时候,格式是
metad1:9559, - 当有 3 个 metad 的时候,格式是
metad1:9559,metad2:9559,metad3:9559
在 ansible playbook 的工程下,新建 filter_plugins 目录,创建一个 map_fomat.py Python文件,文件内容:
# -*- encoding: utf-8 -*-
from jinja2.utils import soft_unicode
def map_format(value, pattern):
"""
e.g.
"{{ groups['metad']|map('map_format', '%s:9559')|join(',') }}"
"""
return soft_unicode(pattern) % (value)
class FilterModule(object):
""" jinja2 filters """
def filters(self):
return {
'map_format': map_format,
}
{{ groups['metad']|map('map_format', '%s:9559')|join(',') }} 即为我们想要的值。
自定义 module
自定义 module 需要符合 Ansible 框架的格式,包括获取参数,标准返回,错误返回等。
写好的自定义 module,需要在 ansible.cfg 中配置 ANSIBLE_LIBRARY,让 ansible 能够获取到。
具体参考官网:https://ansible-docs.readthedocs.io/zh/stable-2.0/rst/developing_modules.html
Nebula Graph 的 Ansible 实践
因为 Nebula Graph 本身启动并不复杂,使用 Ansible 来完成 Nebula-Graph 的部署十分简单。
- 下载 RPM 包。
- 复制 RPM 包到部署机,解压后,放到目的文件夹。
- 更新配置文件。
- 通过 shell 启动。
使用通用的 role
Nebula Graph 有三个组件,graphd、metad、storaged,三个组件的命名和启动使用一样的格式,可以使用通用的 role,graphd、metad、storaged 分别引用通用的 role。
一方面更容易维护,另一方面部署的服务更有细粒度。比如 A B C 机器部署 storaged, 只有 C 机器部署 graphd,那 A B 机器上,就不会有 graphd 的配置文件。
# 通用的 role, 使用变量 install/task/main.yml
- name: config {{ module }}.conf
template:
src: "{{ playbook_dir}}/templates/{{ module }}.conf.j2"
dest: "{{ deploy_dir }}/etc/{{ module }}.conf"
# graphd role,将变量传进来 nebula-graphd/task/main.yml
- name: install graphd
include_role:
name: install
vars:
module: nebula-graphd
在 playbook 中,graphd 的机器组来运行 graphd 的 role,如果 A B 不在 graphd 的机器组,就不会将 graphd 的配置文件上传。
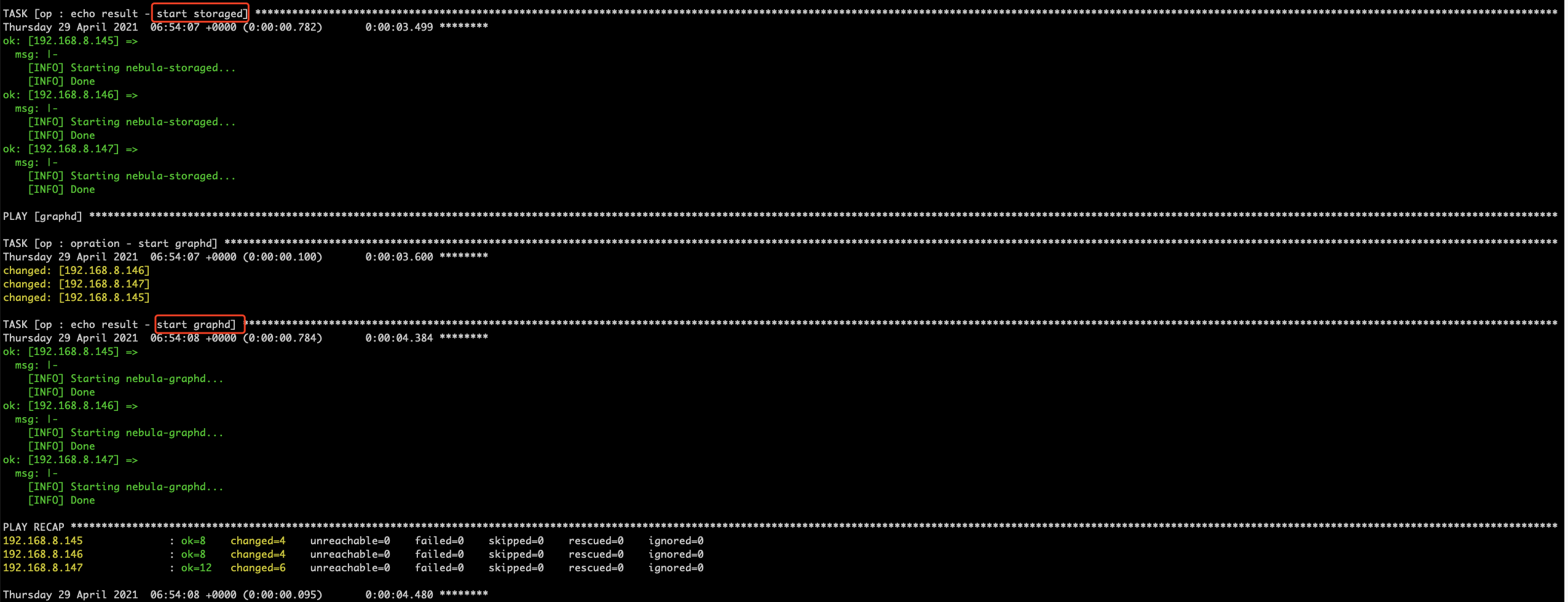
这样部署后,就不能使用 Nebula-Graph 的 nebula.service start all 来全部启动,因为有的机器上会没有 nebula-graphd.conf 的配置文件。类似的,可以在 playbook 中,通过参数,来指定不同的机器组,传不同的参数。
# playbook start.yml
- hosts: metad
roles:
- op
vars:
- module: metad
- op: start
- hosts: storaged
roles:
- op
vars:
- module: storaged
- op: start
- hosts: graphd
roles:
- op
vars:
- module: graphd
- op: start
这样会相当于多次 ssh 去执行启动脚本,虽然执行效率没有 start all 更好,但是服务的启停会更为灵活。
使用 vars_prompt 结束 playbook
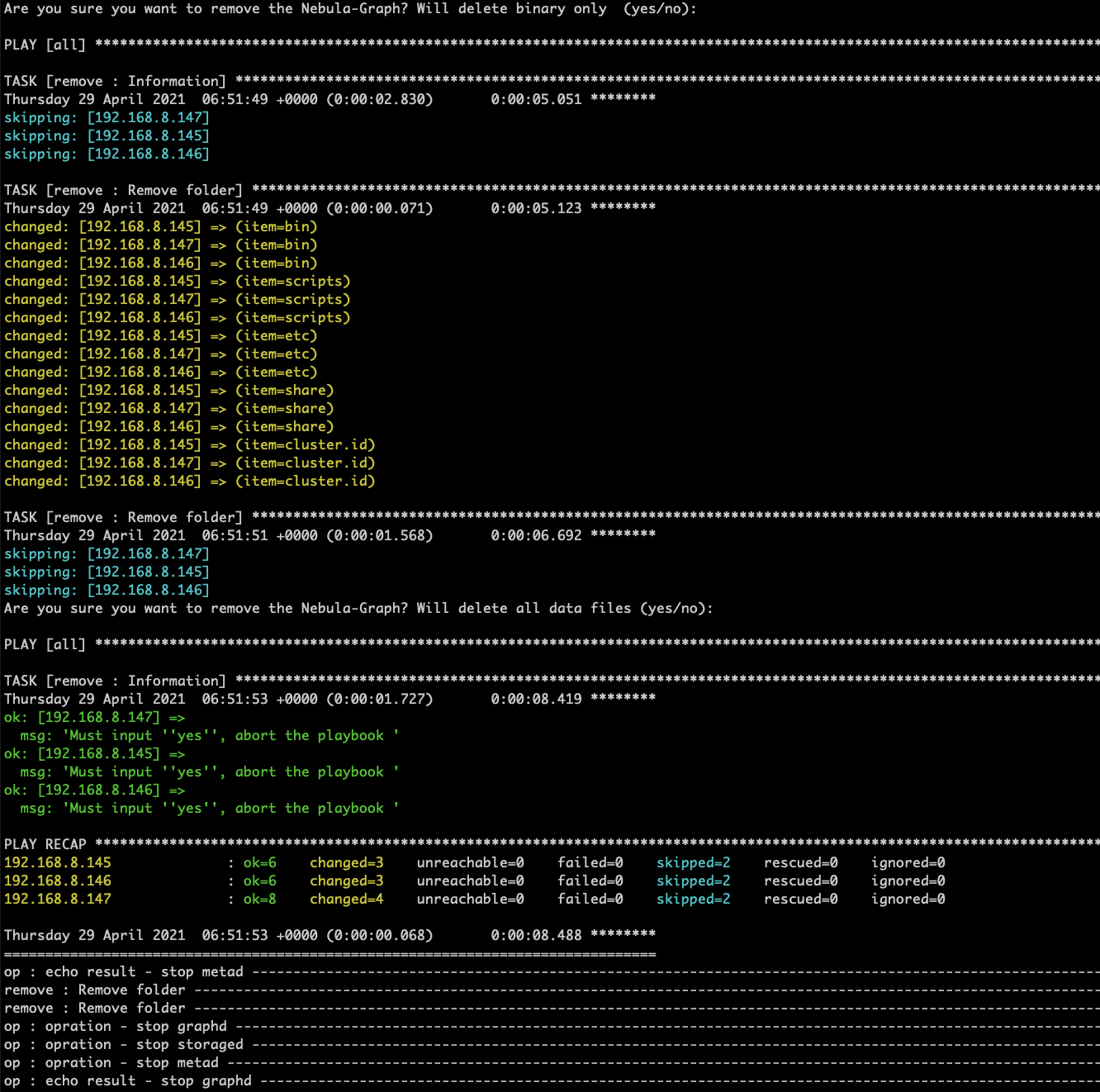
当只想更新二进制,不想删除数据目录的时候,
可以在 remove 的 playbook 中,添加 vars_prompt 二次确认,如果二次确认了,才会删除数据,否则会退出 playbook。
# playbook remove.yml
- hosts: all
vars_prompt:
- name: confirmed
prompt: "Are you sure you want to remove the Nebula-Graph? Will delete binary only (yes/no)"
roles:
- remove
而在 role 里,会校验二次确认的值
# remove/task/main.yml
---
- name: Information
debug:
msg: "Must input 'yes', abort the playbook "
when:
- confirmed != 'yes'
- meta: end_play
when:
- confirmed != 'yes
效果如图,删除时可以二次确认,如果不为 yes,就会取消执行这次的 playbook,这样可以只删除二进制,而不删除 nebula 集群的数据。
交流图数据库技术?加入 Nebula 交流群请先填写下你的 Nebulae 名片,Nebula 小助手会拉你进群~~
推荐阅读
Nebula Graph 的 Ansible 实践的更多相关文章
- 分布式图数据库 Nebula Graph 的 Index 实践
导读 索引是数据库系统中不可或缺的一个功能,数据库索引好比是书的目录,能加快数据库的查询速度,其实质是数据库管理系统中一个排序的数据结构.不同的数据库系统有不同的排序结构,目前常见的索引实现类型如 B ...
- GraphX 在图数据库 Nebula Graph 的图计算实践
不同来源的异构数据间存在着千丝万缕的关联,这种数据之间隐藏的关联关系和网络结构特性对于数据分析至关重要,图计算就是以图作为数据模型来表达问题并予以解决的过程. 一.背景 随着网络信息技术的飞速发展,数 ...
- Nebula Graph 在微众银行数据治理业务的实践
本文为微众银行大数据平台:周可在 nMeetup 深圳场的演讲这里文字稿,演讲视频参见:B站 自我介绍下,我是微众银行大数据平台的工程师:周可,今天给大家分享一下 Nebula Graph 在微众银行 ...
- Neo4j 导入 Nebula Graph 的实践总结
摘要: 主要介绍如何通过官方 ETL 工具 Exchange 将业务线上数据从 Neo4j 直接导入到 Nebula Graph 以及在导入过程中遇到的问题和优化方法. 本文首发于 Nebula 论坛 ...
- 解析 Nebula Graph 子图设计及实践
本文首发于 Nebula Graph 公众号 NebulaGraphCommunity,Follow 看大厂图数据库技术实践. 前言 在先前的 Query Engine 源码解析中,我们介绍了 2.0 ...
- Nebula Graph 在网易游戏业务中的实践
本文首发于 Nebula Graph Community 公众号 当游戏上知识图谱,网易游戏是如何应对大规模图数据的管理问题,Nebula Graph 又是如何帮助网易游戏落地游戏内复杂的图的业务呢? ...
- 分布式图数据库 Nebula Graph 中的集群快照实践
1 概述 1.1 需求背景 图数据库 Nebula Graph 在生产环境中将拥有庞大的数据量和高频率的业务处理,在实际的运行中将不可避免的发生人为的.硬件或业务处理错误的问题,某些严重错误将导致集群 ...
- Nebula Graph 技术总监陈恒:图数据库怎么和深度学习框架进行结合?
引子 Nebula Graph 的技术总监在 09.24 - 09.30 期间同开源中国·高手问答的小伙伴们以「图数据库的设计和实践」为切入点展开讨论,包括:「图数据库的存储设计」.「图数据库的计算设 ...
- 图数据库 Nebula Graph 的安装部署
Nebula Graph:一个开源的分布式图数据库.作为唯一能够存储万亿个带属性的节点和边的在线图数据库,Nebula Graph 不仅能够在高并发场景下满足毫秒级的低时延查询要求,还能够实现服务高可 ...
随机推荐
- android消息线程和消息队列
基于消息队列的线程通信: 消息队列与线程循环 MessageQueue: 利用链表来管理消息. Mess ...
- Bug调试专项训练四笔记
Ajax案例一 导入项目直接运行出现联想无反应 错误原因: 错误1: 55行找不到方法: 错误1解决方案: 解决错误1点击仍无反应 错误2:通过浏览器得出错误2:58行找不到方法 错误2解决方案: 解 ...
- DenseNet的个人总结
DenseNet这篇论文是在ResNet之后一年发表的,由于ResNet在当时引起了很大的轰动,所以DenseNet也将ResNet作为了主要的对比方法,读起来还是比较容易的,全篇只有两个数学公式,也 ...
- 《Selenium自动化测试实战:基于Python》之 Selenium IDE插件的安装与使用
第3章 Selenium IDE插件的安装与使用 京东:https://item.jd.com/13123910.html 当当:http://product.dangdang.com/292045 ...
- 鸿蒙运行报错:Failure[INSTALL_PARSE_FAILED_USESDK_ERROR] Error while Deploying HAP
问题描述 近期,使用DevEco-Studio新建手机类型的工程,编译成功,发布到模拟器(鸿蒙P40)时出错,如下图: 原因分析 本地DevEco-Studio使用的SDK版本与设备(P40)不匹配导 ...
- 导出目录的JS代码,与目录的三级标题测试
二级标题 三级标题 三级标题 三级标题 三级标题 三级标题 二级标题 三级标题 三级标题 三级标题 三级标题 三级标题 这里是现在页尾目录功能的代码源码: <!-- 目录索引列表生成 --> ...
- HTML5和CSS3 PC端静态网页琐碎知识点
1.PC端为了兼容IE9以及IE9以下,尽量要使用float进行布局,兼容性好,一般不要用flex进行布局. 2.问起CSS选择器的分类,先说id选择器,类选择器,属性选择器,伪类选择器,伪元素选择器 ...
- 【C/C++】malloc和new的区别
malloc和new的区别 malloc是C语言的内存申请函数.new是C++语言的运算符.所以在.c文件中无法使用new. malloc申请空间时,传递的是size.new申请空间时,传递的是typ ...
- BUAA_2020_OO_UNIT3_REVIEW
OO第三单元总结 1. JML语言的理论基础.应用工具链情况 1.1 JML理论基础 我觉得就是<离散数学>中的数理逻辑 由于我的<离散数学>是速成的,导致我不会写规格,只能勉 ...
- 2020 OO 第二单元总结
只要跑得够快即使从头关到尾你也喜欢吗? 一.设计策略 1.1 总体策略概述 在多线程的协同和同步控制方面,我三次作业都是采用生产者/消费者模式(还憨憨地在内部分了customer.producer.t ...