Clickhouse - Replication机制
Clickhouse - Replication机制
1. Replication引擎族
Replication仅对于MergeTree引擎族提供支持, 两者是正交的:
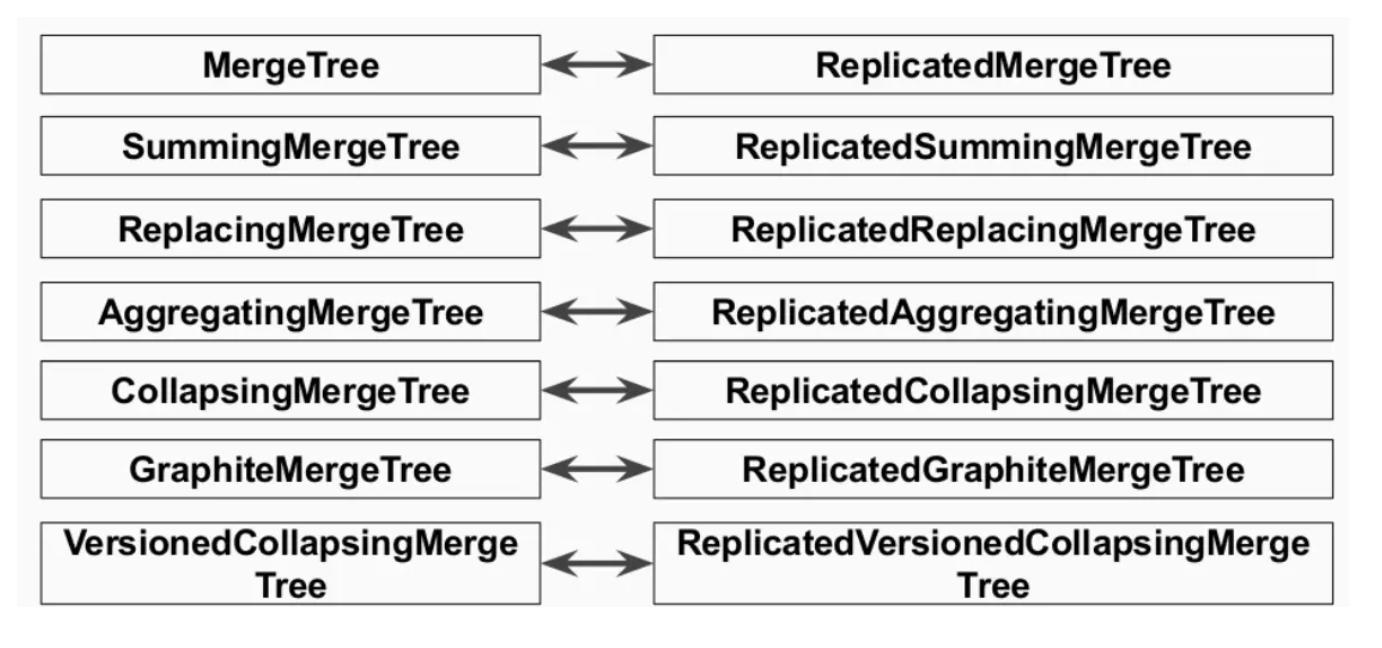
- ReplicatedMergeTree
- ReplicatedSummingMergeTree
- ReplicatedReplacingMergeTree
- ReplicatedAggregatingMergeTree
- ReplicatedCollapsingMergeTree
- ReplicatedVersionedCollapsingMergeTree
- ReplicatedGraphiteMergeTree
2. 工作机制
在Clickhouse中, Replication的机制工作在表级别, 而不是库, 或者是节点层级. 一个节点可以同时存储使用Replication引擎的表以及不使用Replication引擎的表.
Replication机制不依赖于分片(shard), 每个分片有自己独立的Replication机制. 夸分片的话, 就算是表名一致, 表引擎一致, 数据也不会进行同步.
在同一个节点上, Create, Drop, Attach, Detach以及Rename等查询并不会触发Replication机制.
- 当创建表语句(
CREATE TABLE)在一个节点上被执行时, 会创建一个新的Replication表. 如果在该集群中其他节点上已经存在该表, 那会添加一个新的副本. - 删除表语句(
DROP TABLE)会删除当前节点上的副本表. - 重命名表语句(
RENAME TABLE)会重命名当前节点的表名, 但不会修改该集群其他节点的表名. 即Replicated表在不同的副本上可以有不同的名字.
2.1. 依赖Zookeeper
Clickhouse使用zookeeper来存储副本的元数据信息(zk版本要求3.4.5或者更高). 当表引擎被指定为Replication引擎族时, Clickhouse将使用设定zk集群的一个目录作为自己元数据的存储地点(这个目录可以通过具体的表引擎语句来指定).
需要注意的是, 如果在clickhouse的配置文件中没有配置zk集群信息, 将不能创建使用Replication引擎族的表, 并且已存在的使用Replication引擎族的表将会被锁定在只读状态(read-only).
当查询表引擎为Replication引擎族的本地表时, Zookeeper集群并不会工作, SELECT查询语句的执行性能和不使用Replication引擎族的表是一样快的. 当查询表引擎为Replication引擎族的分布式表时, SELECT查询语句的执行由max_replica_delay_for_distributed_queries和fallback_to_stale_replicas_for_distributed_queries这两个参数控制, 合理的设置这两个参数可以有效提升查询分布式的速度.
对于INSERT插入语句而言, 所有被插入的数据会根据一定的规则划分为几个数据块Block, 每个数据块的相关元数据信息会通过事务来被提交到Zookeeper(一个数据块具体可以最多容纳多少条数据是由参数max_insert_block_size决定的). 这个机制导致了数据插入使用了Replication引擎的表的延迟会比使用了其他引擎的表稍高一些, 合理的数据写入机制能缓解这个延迟的影响.
如果Clickhouse集群的规模非常大, 可以为不同的分片(shard)使用不同的Zookeeper集群, 即一套Clickhouse集群搭配多套Zookeeper集群.
2.2. 数据同步
Replication副本机制是异步且多Master的(多Master指在同一个集群上, 随意节点都可以, 无需在master节点上).INSERT查询(ALTER查询也是)可以被发送到当前集群的所有正常工作的节点上. 数据会被插入到运行INSERT语句的节点上, 然后被同步到同一分片的其他节点上. 因为这个数据同步操作是异步执行的, 其他节点上的数据会存在一定的延迟时间(这个时间由不同节点间传输压缩数据块的时间决定). 同步时如果遇到部分节点不可用(挂掉了), 会当这些节点重新可用时, 再写入. 对复制表进行数据同步时所使用的线程数可以通过background_schedule_pool_size参数来设置.
默认情况下, INSERT查询会等待写入当前副本的结果. 如果数据成功写入到当前副本但是这个副本所在的服务挂掉了, 那么写入的数据将会丢失. 如果INSERT查询想要确认写入该分片的所有副本的结果, 可以使用insert_quorum选项.
INSERT的原子性
一个INSERT插入不一定是原子性的, 这需要考虑到这个ISNERT查询被分成了多少个数据块, 但对于数据块来说, 是可以保证原子性的. 换句话说, 如果一个INSERT插入的条数小于max_insert_block_size设定的值, 那么这个INSERT查询就是原子性的.
INSERT的幂等性
数据块是遵循重复删除原则的, 对于同一数据块(大小相同, 条数相同, 数据的顺序相同)的多次写入, 实际只会被写入一次, 多余的次数会被丢弃. 这样做的原因是当由于网络故障, 客户端不知道数据是否成功被写入到Clickhouse中, 可以不考虑其他, 直接重复执行INSERT操作(就算多写了一次, 也会因为相同数据块而实际上没有写入到CK中). 这样做就保证了多次INSERT操作的幂等性.
2.3. 数据保障
在replication机制执行过程中, 只有被插入的源数据在各个节点间传输. 进一步的数据转换(Merge操作)是以同样的方式在所有的副本上协调和执行的. 这最大限度的降低了对于网络传输的压力, 意味着当Clickhouse集群跨越了多个数据中心时, 可以最大程度的提升replication机制的执行效率.
您可以对同一数据进行任意数量的复制。Yandex.Metrica在生产中使用双重复制。每台服务器使用RAID-5或RAID-6,在某些情况下使用RAID-10。这是一个相对可靠和方便的解决方案。
Clickhouse系统会监控每个副本上的数据一致性, 在发生故障后能够自动回复. 在不同副本数据差异较小的情况下, 故障转移是自动或半自动的, 但如果数据差异过大(例如表结构不同), 那么就需要去手动处理了.
Clickhouse - Replication机制的更多相关文章
- mysql的Replication机制
mysql的Replication机制 参考文档:http://www.doc88.com/p-186638485596.html Mysql的 Replication 是一个异步的复制过程. 从上图 ...
- [How to]HBase集群备份方法--Replication机制
1.简介 HBase备份的方法在[How to]HBase集群备份方法文章中已经有些介绍,但是这些方法都不是HBase本身的特性在支持,都是通过MR计算框架结合HBase客户端的方式,或者直接拷贝HB ...
- mysql Replication机制
从上图可以看见MySQL 复制的基本过程如下: Slave 上面的IO线程连接上 Master,并请求从指定日志文件的指定位置(或者从最开始的日志)之后的日志内容: Master 接收到来自 Sl ...
- ClickHouse和他的朋友们(9)MySQL实时复制与实现
本文转自我司大神 BohuTANG的博客 . 很多人看到标题还以为自己走错了夜场,其实没有. ClickHouse 可以挂载为 MySQL 的一个从库 ,先全量再增量的实时同步 MySQL 数据,这个 ...
- MySQL Group Replication 技术点
mysql group replication,组复制,提供了多写(multi-master update)的特性,增强了原有的mysql的高可用架构.mysql group replication基 ...
- 关于Redis中的Replication
一.简介 Redis的replication机制允许slave从master那里通过网络传输拷贝到完整的数据备份.具有以下特点: 异步复制 可以配置一主多从 可以配置从服务器可以级联从服务器,既 M- ...
- Replication in Kafka
Replication简介 Kafka中的Replication功能是为了给每个partition提供备份,当某个Broker挂掉时可以迅速实现故障切换(failover).我们可以在创建或修改top ...
- 第 13 章 可扩展性设计之 MySQL Replication
前言: MySQL Replication 是 MySQL 非常有特色的一个功能,他能够将一个 MySQL Server 的 Instance 中的数据完整的复制到另外一个 MySQL Server ...
- 高性能nosql ledisdb设计与实现 (2):replication
ledisdb现在已经支持replication机制,为ledisdb的高可用做出了保障. 使用 假设master的ip为10.20.187.100,端口6380,slave的ip为10.20.187 ...
随机推荐
- C# 给PDF文档设置过期时间
我们可以给一些重要文档或者临时文件设置过期时间和过期信息提示来提醒读者或管理者文档的时效性,并及时对文档进行调整.更新等.下面,分享通过C#程序代码来给PDF文档设置过期时间的方法. 引入dll程序集 ...
- LINUX系统机器人
简介 在2016年,国内的软硬件尚不能有效支撑我们制造智能机器人,我们无法有效在Linux进行语音唤醒,只能使用斯坦福大学狮身人面像语音开源项目来进行英文识别我们对RIMA的呼唤,抗干扰性为0,意味着 ...
- echarts x轴的纵向区域随便点击获取点击的x轴那一纵向区域的值
1.现在xAxis里面配置一下: 2.在生成图表的后面加入框起来的部分 myChart.getZr().on('click', function (params) { /* 通过获取echarts上面 ...
- CSS基本语法(二)
目录 CSS基本语法(二) 八.CSS复合选择器 1.后代选择器** 2.子选择器 3.并集选择器** 4.伪类选择器 链接伪类选择器 :focus伪类选择器 总结 九.CSS的元素显示样式 1.概念 ...
- 关于new Date总结及注意事项
记录关于 new Date() 的一些常用方法及问题 new Date()基本方法: 创建一个日期对象的几种方法 注意: 由于浏览器差异和不一致性,强烈建议不要使用Date构造函数(和Date.par ...
- vue和react 相似和区别
相似之处 他们都是JavaScript的UI框架,专注于创造前端的富应用 不同于早期的JavaScript框架"功能齐全",Reat与Vue只有框架的骨架,其他的功能如路由.状态管 ...
- 关于使用学生或者教师身份免费使用JetBrains全家桶的说明
官网操作 JetBrains是一家捷克的软件开发公司,该公司位于捷克的布拉格,并在俄罗斯的圣彼得堡及美国麻州波士顿都设有办公室,该公司有众多的好用的IDE,比如pycharm,webstorm,Int ...
- springboot 配置百里香 thymeleaf?
一.1.1父级工程导入jar包. springboot已经完整把thymeleaf集成进框架中了,可以直接添加使用不需要任何的配置信息 <dependency> <groupId&g ...
- 支付宝同步请求检查appid,以及公钥,私钥是否正确
第一步:下载支付宝Demo 下载地址:https://opendocs.alipay.com/open/270/106291#%E8%BF%90%E8%A1%8C%E8%AF%B4%E6%98%8E ...
- Win10 提示凭证不工作问题
感谢大佬:https://cloud.tencent.com/developer/article/1337081 在公司局域网远程自己计算机的时候,突然无法远程了,提示"您的凭据不工作 之前 ...