RDD的详解、创建及其操作
RDD的详解

RDD:弹性分布式数据集,是Spark中最基本的数据抽象,用来表示分布式集合,支持分布式操作!
RDD的创建
RDD中的数据可以来源于2个地方:本地集合或外部数据源

RDD操作
分类

转换算子

Map
···
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo03Map {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
conf.setAppName("Demo03Map").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
//读取文件数据
val linesRDD: RDD[String] = sc.textFile("spark/data/words.txt")
//对数据进行扁平化处理
val flatRDD: RDD[String] = linesRDD.flatMap(_.split(","))
//按照单词分组
val groupRDD: RDD[(String, Iterable[String])] = flatRDD.groupBy(w => w)
//聚合
val wordsRDD: RDD[String] = groupRDD.map(kv => {
val key: String = kv._1
val words: Iterable[String] = kv._2
key + "," + words.size
})
//分组+聚合
val mapRDD1: RDD[(String, Int)] = flatRDD.map((_, 1))
val words1: RDD[(String, Int)] = mapRDD1.reduceByKey(_ + _)
////分组+聚合
val mapRDD2: RDD[(String, Int)] = flatRDD.map((_, 1))
val words2: RDD[(String, Iterable[Int])] = mapRDD2.groupByKey()
val wordSum: RDD[(String, Int)] = words2.mapValues(_.size)
wordSum.foreach(println)
//输出
wordsRDD.foreach(println)
words1.foreach(println)
}
}
flatMap(数据扁平化处理)
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo04FlatMap {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("Demo04FlatMap").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val linesRDD: RDD[String] = sc.parallelize(List("java,scala,python", "map,java,scala"))
//扁平化处理
val flatRDD: RDD[String] = linesRDD.flatMap(_.split(","))
flatRDD.foreach(println)
}
}
Mappartitions
### map和mapPartitions区别
1)map:每次处理一条数据
2)mapPartitions:每次处理一个分区数据
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo05MapPartition {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("Demo05MapPartition").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val stuRDD: RDD[String] = sc.textFile("spark/data/words.txt",3)
stuRDD.mapPartitions(rdd => {
println("map partition")
// 按分区去处理数据
rdd.map(line => line.split(",")(1))
}).foreach(println)
}
}
fliter 过滤
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo06Filter {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("Demo05MapPartition").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val linesRDD: RDD[Int] = sc.parallelize(List(1, 2, 3, 4, 5))
//过滤,转换算子
linesRDD.filter(kv => {
kv % 2 == 1
}).foreach(println)
}
}
sample 取样
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object Demo07Sample {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("Demo05MapPartition").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
/**
* sample:对数据取样
* withReplacement 有无放回
* fraction 抽样比例
* withReplacement:表示抽出样本后是否在放回去,true表示会放回去
* 这也就意味着抽出的样本可能有重复
* fraction :抽出多少,这是一个double类型的参数,0-1之间,eg:0.3表示抽出30%
*/
val stuRDD: RDD[String] = sc.textFile("spark/data/students.txt",3)
stuRDD.sample(withReplacement = true,0.1).foreach(println)
}
}
union 将相同结结构的数据连接到一起
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo08Union {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("Demo05MapPartition").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
/**union
* 将两个相同结构的数据连接在一起
*/
val lineRDD1: RDD[String] = sc.parallelize(List("java,scala", "data,python"))
val lineRDD2: RDD[String] = sc.parallelize(List("spark,scala", "java,python"))
println(lineRDD1.getNumPartitions)
val unionRDD: RDD[String] = lineRDD1.union(lineRDD2)
println(unionRDD.getNumPartitions)
unionRDD.foreach(println)
}
}
mappatitionWIthindex
//mapPartitionsWithIndex也是一个转换算子
// 会在处理每一个分区的时候获得一个index
//可以选择的执行的分区
stuRDD.mapPartitionsWithIndex((index, rdd) => {
println("当前遍历的分区:" + index)
// 按分区去处理数据
rdd.map(line => line.split(",")(1))
}).foreach(println)
join 将数据按照相同key进行关联(数据必须是(K,V))
import java.io
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo09Join {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("Demo05MapPartition").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
// 构建K-V格式的RDD
val tuple2RDD1: RDD[(String, String)] = sc.parallelize(List(("001", "张三"), "002" -> "小红", "003" -> "小明"))
val tuple2RDD2: RDD[(String, Int)] = sc.parallelize(List(("001", 20), "002" -> 22, "003" -> 21))
val tuple2RDD3: RDD[(String, String)] = sc.parallelize(List(("001", "男"), "002" -> "女"))
//将文件进行join
val joinRDD: RDD[(String, (String, Int))] = tuple2RDD1.join(tuple2RDD2)
joinRDD.map(kv => {
val i: String = kv._1
val j: String = kv._2._1
val k: Int = kv._2._2
i + "," + j + "," + k
}).foreach(println)
//第二种方式
joinRDD.map {
case (id: String, (name: String, age: Int)) => id + "*" + name + "*" + age
}.foreach(println)
val leftJoinRDD: RDD[(String, (String, Option[String]))] = tuple2RDD1.leftOuterJoin(tuple2RDD3)
leftJoinRDD.map {
//存在关联
case (id: String, (name: String, Some(gender))) =>
id + "*" + name + "*" + gender
//不存在关联
case (id: String, (name: String, None)) =>
id + "*" + name + "*" + "_"
}
}
}
groupByKey 将kv格式的数据进行key的聚合
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo10GroupByKey {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("Demo10GroupByKey").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
/**
* groupBy 指定分组的字段进行分组
*/
// 统计班级人数
val linesRDD: RDD[String] = sc.textFile("spark/data/students.txt")
linesRDD.groupBy(word => word.split(",")(4))
.map(kv => {
val key = kv._1
val wordsCnt = kv._2.size
key + "," + wordsCnt
}).foreach(println)
val linesMap: RDD[(String, String)] = linesRDD.map(lines => (lines.split(",")(4), lines))
//按照key进行分组
linesMap.groupByKey()
.map(lines=>{
val key = lines._1
val wordsCnt: Int = lines._2.size
key+","+wordsCnt
}).foreach(println)
}
}
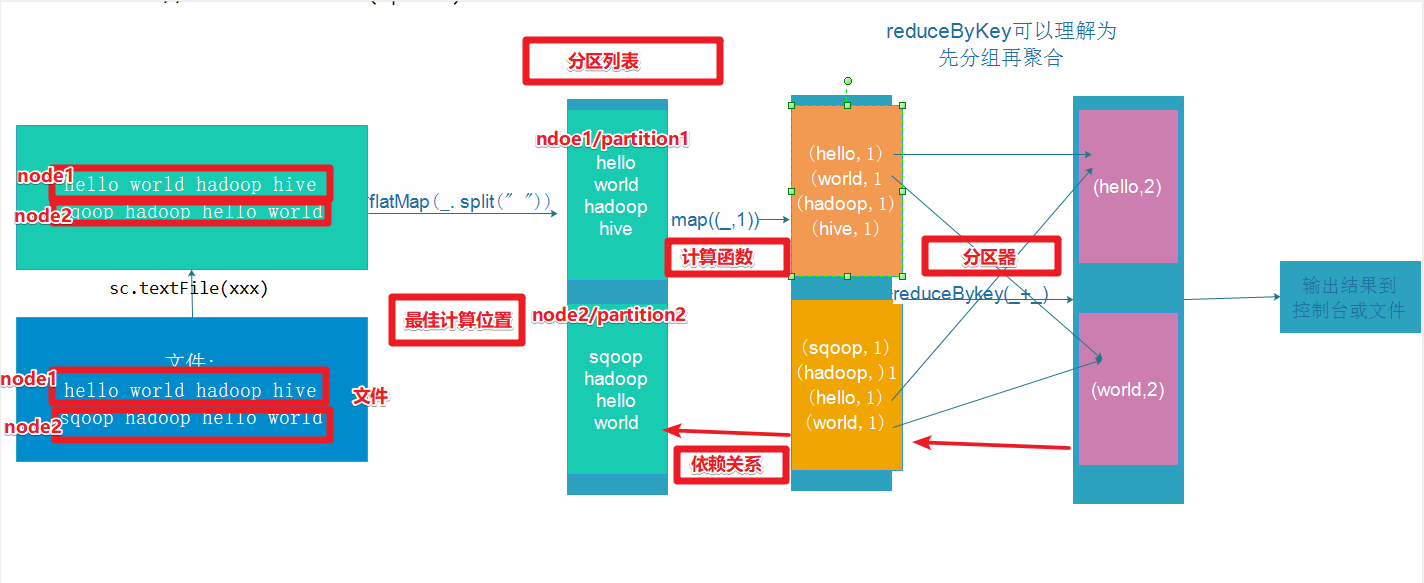
ReduceByKey
reduceByKey 需要接收一个聚合函数
首先会对数据按key分组 然后在组内进行聚合(一般是加和,也可以是Max、Min之类的操作)
相当于 MR 中的combiner
可以在Map端进行预聚合,减少shuffle过程需要传输的数据量,以此提高效率
相对于groupByKey来说,效率更高,但功能更弱
幂等操作
y = f(x) = f(y) = f(f(x))
reducebyKey与groupbykey的区别
reduceByKey:具有预聚合操作
groupByKey:没有预聚合
在不影响业务逻辑的前提下,优先采用reduceByKey。
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo11ReduceByKey {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("Demo11ReduceByKey").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val linesRDD: RDD[String] = sc.textFile("spark/data/students.txt")
//统计班级人数
linesRDD.map(lines => (lines.split(",")(4), lines))
.groupByKey()
.map(kv => {
val key = kv._1
val cnt = kv._2.size
key + "" + cnt
}).foreach(println)
//ReduceByKey
/**
* reduceByKey 需要接收一个聚合函数
* 首先会对数据按key分组 然后在组内进行聚合(一般是加和,也可以是Max、Min之类的操作)
* 相当于 MR 中的combiner
* 可以在Map端进行预聚合,减少shuffle过程需要传输的数据量,以此提高效率
* 相对于groupByKey来说,效率更高,但功能更弱
* 幂等操作
* y = f(x) = f(y) = f(f(x))
*/
linesRDD.map(lines=>(lines.split(",")(4),1))
.reduceByKey(_+_)
.foreach(println)
}
}
sort 排序,默认升序
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object Demo12Sort {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("Demo12Sort").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val linesRDD: RDD[String] = sc.textFile("spark/data/students.txt")
/**
* sortBy 转换算子
* 指定按什么排序 默认升序
*
* sortByKey 转换算子
* 需要作用在KV格式的RDD上,直接按key排序 默认升序
*/
linesRDD.sortBy(lines => lines.split(",")(2), ascending = false) //按照年纪降序
.take(10) //转换算子打印十行
.foreach(println)
val mapRDD: RDD[(String, String)] = linesRDD.map(l => (l.split(",")(2), l))
mapRDD.sortByKey(ascending = false)
.take(10)
.foreach(println)
}
}
Mapvalue
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo13MapValue {
def main(args: Array[String]): Unit = {
/**
* mapValues 转换算子
* 需要作用在K—V格式的RDD上
* 传入一个函数f
* 将RDD的每一条数据的value传给函数f,key保持不变
* 数据规模也不会改变
*/
val conf: SparkConf = new SparkConf().setAppName("Demo13MapValue").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val linesRDD: RDD[(String, Int)] = sc.parallelize(List(("zs", 10), ("zzw", 34), ("lm", 18)))
linesRDD.mapValues(lines=>lines*2)
.foreach(println)
}
### 行为算子
RDD的详解、创建及其操作的更多相关文章
- ASP.NET MVC Filters 4种默认过滤器的使用【附示例】 数据库常见死锁原因及处理 .NET源码中的链表 多线程下C#如何保证线程安全? .net实现支付宝在线支付 彻头彻尾理解单例模式与多线程 App.Config详解及读写操作 判断客户端是iOS还是Android,判断是不是在微信浏览器打开
ASP.NET MVC Filters 4种默认过滤器的使用[附示例] 过滤器(Filters)的出现使得我们可以在ASP.NET MVC程序里更好的控制浏览器请求过来的URL,不是每个请求都会响 ...
- App.Config详解及读写操作
App.Config详解及读写操作 App.Config详解 应用程序配置文件是标准的 XML 文件,XML 标记和属性是区分大小写的.它是可以按需要更改的,开发人员可以使用配置文件来更改设置,而 ...
- Spark RDD API详解(一) Map和Reduce
RDD是什么? RDD是Spark中的抽象数据结构类型,任何数据在Spark中都被表示为RDD.从编程的角度来看,RDD可以简单看成是一个数组.和普通数组的区别是,RDD中的数据是分区存储的,这样不同 ...
- [转载]App.Config详解及读写操作
App.Config详解 应用程序配置文件是标准的 XML 文件,XML 标记和属性是区分大小写的.它是可以按需要更改的,开发人员可以使用配置文件来更改设置,而不必重编译应用程序.配置文件的根节点是c ...
- (转)App.Config详解及读写操作
App.Config详解 应用程序配置文件是标准的 XML 文件,XML 标记和属性是区分大小写的.它是可以按需要更改的,开发人员可以使用配置文件来更改设置,而不必重编译应用程序.配置文件的根节点是c ...
- Spark RDD API详解之:Map和Reduce
RDD是什么? RDD是Spark中的抽象数据结构类型,任何数据在Spark中都被表示为RDD.从编程的角度来看, RDD可以简单看成是一个数组.和普通数组的区别是,RDD中的数据是分区存储的,这样不 ...
- mysql详解常用命令操作,利用SQL语句创建数据表—增删改查
关系型数据库的核心内容是 关系 即 二维表 MYSQL的启动和连接show variables; [所有的变量] 1服务端启动 查看服务状态 sudo /etc/init.d/mysql status ...
- python数据库操作常用功能使用详解(创建表/插入数据/获取数据)
实例1.取得MYSQL版本 复制代码 代码如下: # -*- coding: UTF-8 -*-#安装MYSQL DB for pythonimport MySQLdb as mdbcon = Non ...
- 版本控制之五:SVN trunk(主线) branch(分支) tag(标记) 用法详解和详细操作步骤(转)
使用场景: 假如你的项目(这里指的是手机客户端项目)的某个版本(例如1.0版本)已经完成开发.测试并已经上线了,接下来接到新的需求,新需求的开发需要修改多个文件中的代码,当需求已经开始开发一段时间的时 ...
随机推荐
- Windows下nginx报错解决:CreateFile() "xxx/logs/nginx.pid" failed
写在前面 本文给出Windows下nginx报错:CreateFile() "xxx/logs/nginx.pid" failed 的解决方法并分析了出错原因,其中 xxx 表示n ...
- CF891E-Lust【EGF】
正题 题目链接:https://www.luogu.com.cn/problem/CF891E 题目大意 \(n\)个数字的一个序列\(a_i\),每次随机选择一个让它减去一.然后贡献加上所有其他\( ...
- 用Fiddler抓不到https的包?因为你姿势不对!往这看!
前言 刚入行测试的小伙伴可能不知道,Fiddler默认抓http的包,如果要抓https的包,是需要装证书的!什么鬼证书?不明白的话继续往下看. Fiddler 抓取 https 数据 第一步:下载 ...
- amber模拟kcl水溶液
最近刚开始学习amber软件,看网上的教程勉强知道怎么操作这个amber了.就暂时跑了个分子动力学,其他的啥也没处理.先把我的操作过程记录下来吧,免得日后忘记. 一.构建kcl.pdb结构 利用Gau ...
- MyBatis-Plus——实践篇
MyBatis-Plus--实践篇 MyBatis-Plus (简称 MP)是一个 MyBatis的增强工具,在 MyBatis 的基础上只做增强不做改变,为简化开发.提高效率而生.进行数据库操作常用 ...
- t-SNE算法
t-SNE 算法 前言 t-SNE(t-distributed stochastic neighbor embedding) 是用于降维的一种机器学习算法,由 Laurens van der Maat ...
- 从零入门 Serverless | 一文详解 Serverless 技术选型
作者 | 李国强 阿里云资深产品专家 今天来讲,在 Serverless 这个大领域中,不只有函数计算这一种产品形态和应用类型,而是面向不同的用户群体和使用习惯,都有其各自适用的 Serverless ...
- 阿里云服务器上在docker部署jenkins
1.查询jenkins:docker search jenkins 2.拉取jenkins镜像 docker pull jenkins/jenkins:lts 3.新建jenkins的工作目录: mk ...
- Java(19)接口知识及综合案例
作者:季沐测试笔记 原文地址:https://www.cnblogs.com/testero/p/15201629.html 博客主页:https://www.cnblogs.com/testero ...
- (翻译)领域驱动设计实现-Implementing Domain Driven Design
简介 Implementing Domain Driven Design 领域驱动设计实现 A practical guide for implementing the Domain Driven D ...