Hive之分析函数
一、sum() over(partition by)
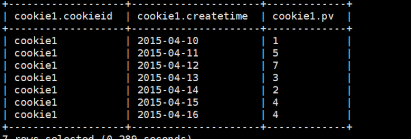
- 数据准备
cookie1,2015-04-10,1
cookie1,2015-04-11,5
cookie1,2015-04-12,7
cookie1,2015-04-13,3
cookie1,2015-04-14,2
cookie1,2015-04-15,4
cookie1,2015-04-16,4
- 查询语句
select
cookieid,
createtime,
pv,
sum(pv) over (partition by cookieid order by createtime rows between unbounded preceding and current row) as pv1,
sum(pv) over (partition by cookieid order by createtime) as pv2,
sum(pv) over (partition by cookieid) as pv3,
sum(pv) over (partition by cookieid order by createtime rows between 3 preceding and current row) as pv4,
sum(pv) over (partition by cookieid order by createtime rows between 3 preceding and 1 following) as pv5,
sum(pv) over (partition by cookieid order by createtime rows between current row and unbounded following) as pv6
from cookie1;
- 查询结果
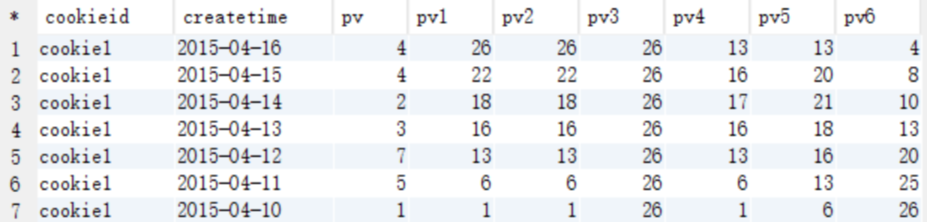
查询结果说明
- pv1: 分组内从起点到当前行的pv累积,如,11号的pv1=2015-04-10号的pv + 2015-04-11号的pv, 2015-04-12号=10号+11号+12号
- pv2: 同pv1
- pv3: 分组内(cookie1)所有的pv累加
- pv4: 分组内当前行+往前3行,如,11号=10号+11号, 12号=10号+11号+12号, 13号=10号+11号+12号+13号, 14号=11号+12号+13号+14号
- pv5: 分组内当前行+往前3行+往后1行,如,14号=11号+12号+13号+14号+15号=5+7+3+2+4=21
- pv6: 分组内当前行+往后所有行,如,13号=13号+14号+15号+16号=3+2+4+4=13,14号=14号+15号+16号=2+4+4=10
partition by 的参数说明
如果不指定ROWS BETWEEN,默认为从起点到当前行;
如果不指定ORDER BY,则将分组内所有值累加;
关键是理解ROWS BETWEEN含义,也叫做WINDOW子句:
PRECEDING:往前
FOLLOWING:往后
CURRENT ROW:当前行
UNBOUNDED:起点,
UNBOUNDED PRECEDING 表示从前面的起点,
UNBOUNDED FOLLOWING:表示到后面的终点
–其他AVG,MIN,MAX,和SUM用法一样。
二、avg()、min()、max() over(partition)
avg()、min()、max() over(partition) 与 sum() over(partition) 类似,都是对窗口做操作
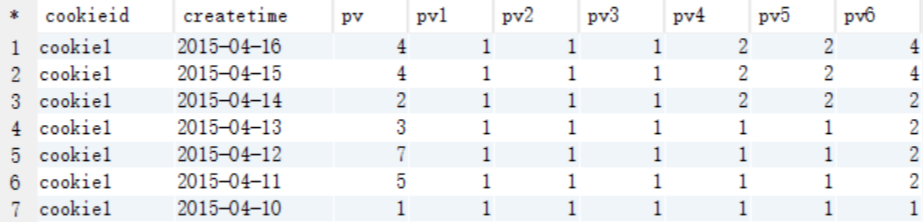
- min() over(partition) 的查询语句
select
cookieid,
createtime,
pv,
min(pv) over (partition by cookieid order by createtime rows between unbounded preceding and current row) as pv1, -- 默认为从起点到当前行
min(pv) over (partition by cookieid order by createtime) as pv2, --从起点到当前行,结果同pv1
min(pv) over (partition by cookieid) as pv3, --分组内所有行
min(pv) over (partition by cookieid order by createtime rows between 3 preceding and current row) as pv4, --当前行+往前3行
min(pv) over (partition by cookieid order by createtime rows between 3 preceding and 1 following) as pv5, --当前行+往前3行+往后1行
min(pv) over (partition by cookieid order by createtime rows between current row and unbounded following) as pv6 --当前行+往后所有行
from cookie1;
- 结果展示
三、row_number() over(partition by)
row_number()从1开始,为每一条分组记录返回一个数字
row_number() OVER (ORDER BY id DESC) 是先把id列降序,再为降序以后的每条id记录返回一个序号。
row_number() OVER (PARTITION BY COL1 ORDER BY COL2) 表示根据COL1分组,在分组内部根据 COL2排序,而此函数计算的值就表示每组内部排序后的顺序编号(组内连续的唯一的)
- 数据准备
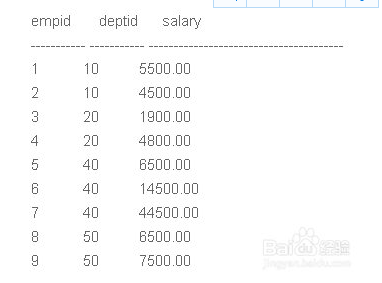
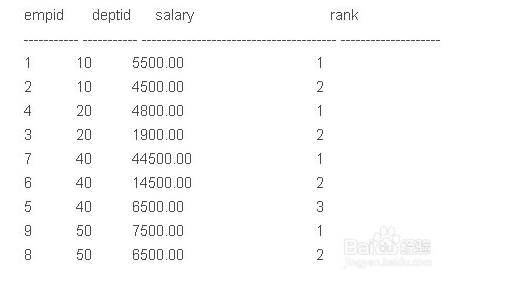
- 查询:需根据部门分组,显示每个部门的工资等级
SELECT *, Row_Number() OVER (partition by deptid ORDER BY salary desc) rank FROM employee
四、用over(partition by) 还是 group by
总结区别:over(partition by) 和 group by的区别
- group by:单纯分组,要查询非group by字段时需要用 collect_set()[0]处理,或者子查询处理
- over(partition by):不仅能分组,还能同时查询非分区字段,不仅可以使用sum()、avg()、min()、max()等功能,还可以使用row_number() 对数据进行排名功能
group by
在hive中使用group by时,是不能select 非group by 字段的。
select name,sex from people group by sex;
---------------------------------------------------
会报错:
FAILED: SemanticException [Error 10025]: Line 1:15 Expression not in GROUP BY key 'name'
解决这个问题的方式有很多:在子查询中做group by然后用left join 连接,在外层selec。还有就是用collect_set()包围这个非group by字段
select collect_set(name)[0],sex from people group by sex;
- over(partition by)
当然,用over(partition by)也能解决分组问题,在分组的同时会对相同key的进行回填处理
数据展示
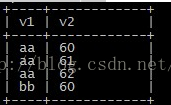
查询语句
select v1,v2,sum(v2) over(partition by v1) as sum from wmg_test;
结果展示
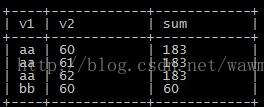
所以要做到取一条分组数据,就在外层去重
select distinct v1,sum_01
from (
select v1,sum(v2) over(partition by v1) as sum_01
from wmg_test
) a;
结果展示

Hive之分析函数的更多相关文章
- [Hive_10] Hive 的分析函数
0. 说明 Hive 的分析函数 窗口函数 | 排名函数 | 最大值 | 分层次 | lead && lag 统计活跃用户 | cume_dist 1. 窗口函数(开窗函数) ove ...
- hive窗口函数/分析函数详细剖析
hive窗口函数/分析函数 在sql中有一类函数叫做聚合函数,例如sum().avg().max()等等,这类函数可以将多行数据按照规则聚集为一行,一般来讲聚集后的行数是要少于聚集前的行数的.但是有时 ...
- hive中分析函数window子句
hive中有些分析函数功能确实很强大,在和sum,max等聚合函数结合起来能实现不少功能. 直接上代码演示吧 原始数据 channel1 2016-11-10 1 channel1 2016-11-1 ...
- Hive 窗口分析函数
1.窗口函数 1.LAG(col,n,DEFAULT) 用于统计窗口内往上第n行值 第一个参数为列名,第二个参数为往上第n行(可选,默认为1),第三个参数为默认值(当往上第n行为NULL时候,取默认值 ...
- Hive的分析函数的使用
原文: https://www.toutiao.com/i6769120000578945544/?group_id=6769120000578945544 我们先准备数据库.表和数据 开窗分析函数相 ...
- Hive Ntile分析函数学习
NTILE(n) 用于将分组数据按照顺序切分成n片,返回当前记录所在的切片值 NTILE不支持ROWS BETWEEN,比如 NTILE(2) OVER(PARTITION BY cookieid O ...
- Hive—简单窗口分析函数
hive 窗口分析函数 : jdbc:hive2:> select * from t_access; +----------------+---------------------------- ...
- Hive 分析函数lead、lag实例应用
Hive的分析函数又叫窗口函数,在oracle中就有这样的分析函数,主要用来做数据统计分析的. Lag和Lead分析函数可以在同一次查询中取出同一字段的前N行的数据(Lag)和后N行的数据(Lead) ...
- Hive简记
在大数据工作中难免遇到数据仓库(OLAP)架构,以及通过Hive SQL简化分布式计算的场景.所以想通过这篇博客对Hive使用有一个大致总结,希望道友多多指教! 摘要: 1.Hive安装 2.Hive ...
随机推荐
- DOS命令行(11)——更多实用的命令行工具
start 启动另一个窗口运行指定的程序或命令,所有的DOS命令和命令行程序都可以由start命令来调用.该命令不仅能运行程序,还能运行协议对应的程序 命令格式:START ["title& ...
- 为什么catch了异常,但事务还是回滚了?
前几天我发了这篇文章<我来出个题:这个事务会不会回滚?>得到了很多不错的反馈,也有不少读者通过微信.群或者邮件的方式,给了我一些关于test4的回复.其中还有直接发给我测试案例,来证明我的 ...
- Java基础篇(JVM)——字节码详解
这是Java基础篇(JVM)的第一篇文章,本来想先说说Java类加载机制的,后来想想,JVM的作用是加载编译器编译好的字节码,并解释成机器码,那么首先应该了解字节码,然后再谈加载字节码的类加载机制似乎 ...
- <题解>世界树
世界树<题解> 首先我们拿到这个题之后,能想到的一定是虚树,如果想不到的话,还是重新学一遍去吧 所以我们应该怎么做呢 虚树的板子不需要我再讲一遍了吧 所以对于这个题来说,怎么根据虚树上的节 ...
- Docker入门与进阶(上)
Docker入门与进阶(上) 作者 刘畅 时间 2020-10-17 目录 1 Docker核心概述与安装 1 1.1 为什么要用容器 1 1.2 docker是什么 1 1.3 docker设计目标 ...
- 15、mysql事物和引擎
15.1.数据库事物介绍: 1.什么是数据库事物:
- 无法push项目到gitlab的解决方案
gitlab项目组下创建项目 $ git push -u git@192.168.101.129:/DrvOps/Dev_Test : 报错信息如下: remote: ================ ...
- MyBatis-HotSwap, MyBatis热部署
https://github.com/xiaochenxinqing/MyBatis-HotSwap 1 https://github.com/xiaochenxinqing/MyBatis-Ho ...
- JNI小记
本文参考<较详细的介绍JNI>一文,并添加了一些方法,代码已经过测试,留待日后工作使用.关于JNI的HelloWorld的例子,就不赘述了. java代码: 1 package com.c ...
- 《Linux基础知识及命令》系列分享专栏
<Linux基础知识及命令>系列分享专栏 本专题详细为大家讲解了Linux入门基础知识,思路清晰,简单易懂.本专题非常适合刚刚学习Linux的小白来学习,通过学习该专题会让你由入门达到中级 ...