mysql变成类型字段varchar值更新变长或变短底层文件存储原理
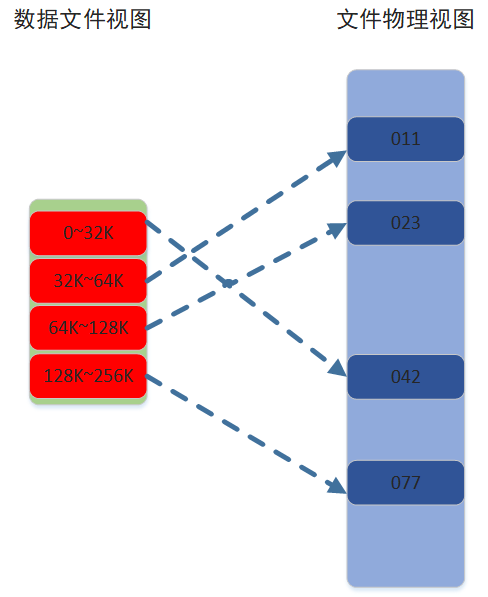
 图2
图2  图3
图3 mysql变成类型字段varchar值更新变长或变短底层文件存储原理的更多相关文章
- MySQL数据类型 int(M) 表示什么意思?详解mysql int类型的长度值问题
MySQL 数据类型中的 integer types 有点奇怪.你可能会见到诸如:int(3).int(4).int(8) 之类的 int 数据类型.刚接触 MySQL 的时候,我还以为 int(3) ...
- EtherType :以太网类型字段及值
Ethernet II即DIX 2.0:Xerox与DEC.Intel在1982年制定的以太网标准帧格式.Cisco名称为:ARPA Ethernet II类型以太网帧的最小长度为64字节(6+6+2 ...
- mysql int类型字段插入空字符串时自动转为0
mysql int类型字段插入空字符串时自动转为0 如果不想转的话可以修改配置文件 修改 my.ini 文件. # Set the SQL mode to strictsql-mode=”STRICT ...
- 关于Java读取mysql中date类型字段默认值'0000-00-00'的问题
今天在做项目过程中,查询一个表中数据时总碰到这个问题: java.sql.SQLException:Value '0000-00-00' can not be represented as ...
- mysql列类型char,varchar,text,tinytext,mediumtext,longtext的比较与选择
储存不区分大小写的字符数据 TINYTEXT 最大长度是 255 (2^8 – 1) 个字符. TEXT 最大长度是 65535 (2^16 – 1) 个字符. MEDIUMTEXT 最大长度是 16 ...
- Mysql各种类型字段长度
1.数值类型 列类型 需要的存储量 TINYINT 1 字节 SMALLINT 2 个字节 MEDIUMINT 3 个字节 INT 4 个字节 INTEGER 4 个字节 BIGINT 8 个字节 F ...
- mysql 字符串类型 char varchar
字符类型用在存储名字.邮箱地址.家庭住址等描述性数据 char指的是定长字符,varchar指的是变长字符 #官网:https://dev.mysql.com/doc/refman/5.7/en/ ...
- mysql int类型的长度值
整数类型的存储和范围(来自mysql手册) 类型 字节 最小值 最大值 (带符号的/无符号的) (带符号的/无符号的) TINYINT 1 -128 127 0 255 SMALLIN ...
- 详解mysql int类型的长度值问题【转】
mysql在建表的时候int类型后的长度代表什么? 是该列允许存储值的最大宽度吗? 为什么我设置成int(1), 也一样能存10,100,1000呢. 当时我虽然知道int(1),这个长度1并不代表允 ...
随机推荐
- JavaScript基础 数字类型
JavaScript 数字类型 目前有两种类型: number BigInt 是表示任意长度的整数 数字的三个特殊值 Infinity 属性用于存放表示正无穷大的数值. -Infinity 属性用于存 ...
- 基于Hyperledger Fabric实现ERC721
介绍 超级账本(Hyperledger)项目是首个面向企业应用场景的开源分布式账本平台.由linux基金会牵头,包括 IBM 等 30家初始企业成员共同成立的. 区块链网络主要有三种类型:公共区块链. ...
- xshell连接VMware中的Linux
[前言]最近想压测一下ITOO的考试系统,所以想在自己电脑上安装一下linux,然后安装一下jmeter进行压测一下. 不过为什么要连接xshell呢,因为在虚拟机上总是会和主机切换鼠标,而且也不能粘 ...
- Web前端安全之安全编码原则
随着Web和移动应用等的快速发展,越来越多的Web安全问题逐渐显示出来.一个网站或一个移动应用,如果没有做好相关的安全防范工作,不仅会造成用户信息.服务器或数据库信息的泄露,更可能会造成用户财产的损失 ...
- python socket zmq
本篇博客将介绍zmq应答模式,所谓应答模式,就是一问一答,规则有这么几条 1. 必须先提问,后回答 2. 对于一个提问,只能回答一次 3. 在没有收到回答前不能再次提问 上代码,服务端: #codin ...
- 【实验向】问题:假设计算机A和计算机B通信,计算机A给计算机B发送一串16个字节的二进制字节串,以数组形式表示:
问题: 假设计算机A和计算机B通信,计算机A给计算机B发送一串16个字节的二进制字节串,以数组形式表示: unsigned char[16] = {0x3f, 0xa0, 0x00, 0x00, 0x ...
- Spark RDD编程(博客索引,日常更新)
本篇主要是记录自己在中解决RDD编程性能问题中查阅的论文博客,为我认为写的不错的建立索引方便查阅,我的总结会另立他篇 1)通过分区(Partitioning)提高spark性能https://blog ...
- 初学Python “登录”案例 更新!!
更新内容:添加了登录次数,如果超过限制的次数,则提示账户被锁定,去某邮箱申请解锁账户! 此次仅把登录系统更新之后源代码放到这里,不在共享源文件在网盘了! 1 ''' 2 登录界面 3 ''' 4 5 ...
- 深度剖析Redis6的持久化机制(大量图片说明,简洁易懂)
Redis的强劲性能很大程度上是由于它所有的数据都存储在内存中,当然如果redis重启或者服务器故障导致redis重启,所有存储在内存中的数据就会丢失.但是在某些情况下,我们希望Redis在重启后能够 ...
- vue3双向数据绑定原理_demo
<!DOCTYPE html> <head> <meta charset="UTF-8" /> <meta name="view ...