MySQL 查询操作
基本语法
select 查询的列 from 表名;
注意:
select 语句中不区分⼤⼩写,查询的结果放在⼀个表格中,表格的第1⾏称为列头,第2⾏开始是数据,类属于⼀个⼆维数组。
查询常量
select 常量值1,常量值2,常量值3;
mysql> select 1,'a';
+---+---+
| 1 | a |
+---+---+
| 1 | a |
+---+---+
1 row in set (0.00 sec)
查看表达式
select 表达式;
mysql> select 1+2,3*10,10/3;
+-----+------+--------+
| 1+2 | 3*10 | 10/3 |
+-----+------+--------+
| 3 | 30 | 3.3333 |
+-----+------+--------+
1 row in set (0.00 sec)
查询函数
select 函数;
mysql> select sum(1+2);
+----------+
| sum(1+2) |
+----------+
| 3 |
+----------+
1 row in set (0.00 sec)
查询指定字段
select 字段1,字段2,字段3 from 表名;
查询所有列
select * from 表名;
列别名
select 列 [as] 别名 from 表;
表别名
select 别名.字段,别名.* from 表名 [as] 别名;
注意
- 建议别名前⾯跟上 as 关键字
- 查询数据的时候,避免使⽤ select *,建议需要什么字段写什么字段
条件查询
select 列名 from 表名 where 列 运算符 值
条件查询运算符
- 等于(=)
- 不等于(<>、!=) # 两者意义相同,在可移植性上前者优于后者
- 大于(>) # 字符按照 ASCII 码对应的值进⾏⽐较,⽐较时按照字符对应的位置⼀个字符⼀个字符的⽐较。
- 小于(<)
- 小于等于(<=)
- 大于等于(>=)
逻辑查询运算符
AND(并且)
OR(或者)
like(模糊查询)
- %:表⽰匹配任意⼀个或多个字符
- _:表⽰匹配任意⼀个字符
BETWEEN ... AND(区间查询)# 可以提⾼语句的简洁度
IN 查询
- in 后⾯括号中可以包含多个值,对应记录的字段满⾜ in 中任意⼀个都会被返回
- in 列表的值类型必须⼀致或兼容
- in 列表中不⽀持通配符
NOT IN 查询:与 IN 查询相反
NULL 值专用查询
查询运算符、like 、between ... and 、in 、not in 对 NULL 值查询不起效
- IS NULL (返回值为空的记录):select 列名 from 表名 where 列 is null;
- IS NOT NULL(返回值不为空的记录):select 列名 from 表名 where 列 is not null;
<=> (安全等于):既可以判断NULL值,又可以判断普通的数值,可读性较低,⽤得较少
排序与分页
排序查询(order by)
select 字段名 from 表名 order by 字段1 [asc|desc], 字段2 [asc|desc];
- 需要排序的字段跟在 order by 之后;
- asc|desc 表⽰排序的规则(asc:升序,desc :降序,默认为 asc)
- ⽀持多个字段进⾏排序,多字段排序之间⽤逗号隔开
排序方式
- 单字段排序
- 多字段排序
- 按别名排序
- 按函数排序
limit
limit ⽤来限制 select 查询返回的⾏数,常⽤于分页等操作
select 列 from 表 limit [offset,] count;
limit 中 offset 和 count 的值不能⽤表达式,只能够跟明确的数字(不能为负数)
分页查询:select 列 from 表名 limit (page - 1) * pageSize, pageSize;
分组查询
SELECT column, group_function,... FROM table
[WHERE condition]
GROUP BY group_by_expression
[HAVING group_condition];
- group_function:聚合函数
- group by expression :分组表达式,多个之间⽤逗号隔开。
- group_condition :分组之后对数据进⾏过滤
分组中 select 后⾯只能有两种类型的列
- 出现在 group by 后的列
- 使⽤聚合函数的列
聚合函数
聚合函数对一组值执行计算并返回单一的值
- max:求最大值
- min:求最小值
- sum:求累加和
- avg:求平均值
- count:统计行的数量
单字段分组
GROUP BY X # 意思是将所有具有相同X字段值的记录放到一个分组里
多字段分组
GROUP BY X, Y # 意思是将所有具有相同X字段值和Y字段值的记录放到一个分组里
分组前筛选数据
分组前对数据进⾏筛选,使⽤ where 关键字
分组后筛选数据
分组后对数据筛选,使⽤having 关键字
where 和 having 的区别
- where 是在分组(聚合)前对记录进⾏筛选,⽽ having 是在分组结束后的结果⾥筛选,最
后返回整个 sql 的查询结果。- 可以把 having 理解为两级查询,即含having 的查询操作先获得不含 having ⼦句时的sql查询
结果表,然后在这个结果表上使⽤having 条件筛选出符合的记录,最后返回这些记录,因
此,having 后是可以跟聚合函数的,并且这个聚集函数不必与 select 后⾯的聚集函数相
同。
where & group by & having & order by & limit ⼀起协作
where、group by 、having 、order by 、limit 这些关键字⼀起使⽤时,先后顺序有明确的限
制,语法如下:
select 列 from
表名
where [查询条件]
group by [分组表达式]
having [ 分组过滤条件]
order by [排序条件]
limit [offset,] count;
注意:必须按照上⾯的顺序写 SQL 语句,否则报错
MySQL 常用函数汇总
MySQL 数值型函数
- abs:求绝对值
- sqrt:求二次方根
- mod:求余数
- ceil 和 ceiling:向上取整
- floor:向下取整
- rand:生成随机数
- round:四舍五入
- sign:返回参数的符号(正数:1 负数:-1 零:0)
- pow 和 power:次方
- sin:正弦
MySQL 字符串函数
- length:返回字符串字节长度
- concat:合并字符串
- insert:替换字符串
- lower:将字符串转换为小写
- upper:将字符串转换为大写
- left:从左侧截取字符串
- right:从右侧截取字符串
- trim:删除字符串两侧空格
- replace:字符串替换
- substr 和 substring:截取字符串
- reverse:反转字符串
MySQL 日期和时间函数
curdate 和 current_date:返回当前系统日期
mysql> select curdate();
+------------+
| curdate() |
+------------+
| 2021-02-28 |
+------------+
1 row in set (0.01 sec)
curtime 和 current_time:返回当前系统时间
mysql> select curtime();
+-----------+
| curtime() |
+-----------+
| 20:02:42 |
+-----------+
1 row in set (0.00 sec)
now 和 sysdate:返回当前系统日期和时间
mysql> select now();
+---------------------+
| now() |
+---------------------+
| 2021-02-28 20:03:22 |
+---------------------+
1 row in set (0.00 sec)
unix_timestamp:获取 UNIX 时间戳
mysql> select unix_timestamp();
+------------------+
| unix_timestamp() |
+------------------+
| 1614513856 |
+------------------+
1 row in set (0.00 sec)
# UNIX_TIMESTAMP(date) 若⽆参数调⽤,返回⼀个⽆符号整数类型的 UNIX 时间戳('1970-01-01 00:00:00'GMT 之后的秒数)
from_unixtime:时间戳转日期
mysql> select from_unixtime(1614513856);
+---------------------------+
| from_unixtime(1614513856) |
+---------------------------+
| 2021-02-28 20:04:16 |
+---------------------------+
1 row in set (0.00 sec)
month:获取指定日期月份
monthname:获取指定日期月份的英文名称
dayname:获取指定日期的星期名称
dayofweek:获取日期对应的周索引(1 表⽰周⽇,7 表⽰周六)
week:获取指定日期是一年的第几周
dayofyear:获取指定日期在一年中的位置
dayofmonth:获取指定日期在一个月中的位置
year:获取年份
time_to_sec:将时间转换为秒值
sec_to_time:将秒值转换为时间格式
date_add 和 adddate:日期加法运算
date_sub 和 subdate:日期减法运算
addtime:时间加法运算
subtime:时间减法运算
datediff:获取两个日期的时间间隔
date_format:格式化指定日期
mysql> select date_format(now(),'%Y-%m-%d %H:%i:%s') as time;
+---------------------+
| time |
+---------------------+
| 2021-02-28 20:16:11 |
+---------------------+
1 row in set (0.00 sec)
weekday:获取指定日期在一周内的索引(0:星期⼀ 6:星期日)
MySQL 流程控制函数
if:判断
ifnull:判断是否为空
case:搜索语句,类似于java 中的if..else if..else
# ⽅式1:
CASE <表达式>
WHEN <值1> THEN <操作>
WHEN <值2> THEN <操作>
...
ELSE <操作>
END CASE; # ⽅式2:
CASE
WHEN <条件1> THEN <命令>
WHEN <条件2> THEN <命令>
...
ELSE commands
END CASE;
子查询
嵌套在 select 语句中的 select 语句,称为⼦查询或内查询。外部的 select 查询语句,称为主查询或外查询。
子查询分类
按结果集的⾏列数不同分类
标量子查询(结果集中只有一行一列)
SELECT * FROM employees a
WHERE a. salary > (SELECT salary
FROM employees
WHERE last_name = 'Abel');
列子查询(结果集中只有一列多行)
SELECT a.last_name FROM employees a
WHERE a. department_id IN (SELECT DISTINCT department_id
FROM departments
WHERE location_id IN (1400, 1700));
行子查询(结果集中只有一行多列)
SELECT * FROM employees a
WHERE a. employee_id = (SELECT min (employee_id) FROM employees)
AND salary = (SELECT max (salary) FROM employees);
表子查询(结果集中有多行多列)
按⼦查询出现在主查询中的不同位置分类
select 后⾯:仅仅⽀持标量⼦查询
SELECT
a.*,
(SELECT count(*)
FROM employees b
WHERE b. department_id = a.department_id ) AS employee_num
FROM departments a;
from 后⾯:⽀持表⼦查询
将⼦查询的结果集充当⼀张表,要求必须起别名,否者这个表找不到。然后将真实的表和⼦查询结果表进⾏连接查询。
SELECT
t1.department_id,sa AS '平均⼯资',t2.grade_level
FROM (SELECT department_id, avg (a. salary ) sa FROM employees a
GROUP BY a.department_id ) t1, job_grades t2
WHERE
t1.sa BETWEEN t2.lowest_sal AND t2. highest_sal ;
where 或 having 后⾯:⽀持标量⼦查询(单列单⾏)、列⼦查询(单列多⾏)、⾏⼦查询(多列多⾏)
in ,any ,some,all分别是⼦查询关键词之⼀
- in :in 常⽤于 where 表达式中,其作⽤是查询某个范围内的数据
- any 和 some⼀样:可以与 =、>、>=、<、<=、<> 结合起来使⽤,分别表⽰等于、⼤于、⼤于等于、⼩于、⼩于等于、不等于其中的任何⼀个数据
- all:可以与=、>、>=、<、<=、<>结合是来使⽤,分别表⽰等于、⼤于、⼤于等于、⼩于、⼩于等于、不等于其中的其中的所有数据
exists 后⾯(即相关⼦查询):表⼦查询(多⾏、多列)
- exists查询结果:1 或 0,exists 查询的结果⽤来判断⼦查询的结果集中是否有值;⼀般来说,能⽤exists的⼦查询,绝对都能⽤ in 代替,所以 exists ⽤的少
- 和前⾯的查询不同,这先执⾏主查询,然后主查询查询的结果,在根据⼦查询进⾏过滤,⼦查询中涉及到主查询中⽤到的字段,所以叫相关⼦查询
SELECT exists (SELECT employee_id FROM employees WHERE salary = 300000 ) AS 'exists返回1或者0';
注意⼦查询中列的值为 NULL 的时候,外查询的结果为空(大坑)
连接查询
笛卡尔积(交叉连接)
有两个集合 A 和 B,笛卡尔积表⽰ A 集合中的元素和 B 集合中的元素,任意相互关联产⽣的所有可能的结果。
select 字段 from 表1,表2[, 表N]; # 隐式交叉连接
或者
select 字段 from 表1 join 表2 [join 表N]; # 显示交叉连接
内连接
内连接相当于在笛卡尔积的基础上加上了连接的条件。当没有连接条件的时候,内连接上升为笛卡尔积。
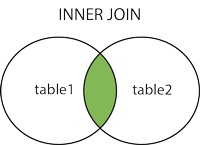
select 字段 from 表1 inner join 表2 on 连接条件;
或
select 字段 from 表1 join 表2 on 连接条件;
或
select 字段 from 表1, 表2 [where 关联条件];
内连接也称为等值连接,结果为返回两张表都满足条件的部分
外连接
外连接涉及到 2 个表,分为:主表和从表,要查询的信息主要来⾃于哪个表,谁就是主表。外连接查询结果为主表中所有记录。如果从表中有和它匹配的,则显⽰匹配的值,这部分相当于内连接查询出来的结果;如果从表中没有和它匹配的,则显⽰ null 。
外连接查询结果 = 内连接的结果 + 主表中有的⽽内连接结果中没有的记录
左外连接
取左边的表的全部,右边的表按条件,符合的显示,不符合则显示 null
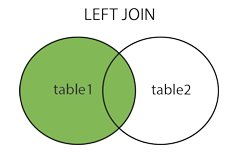
select 列 from 主表 left join 从表 on 连接条件;
右外连接
取右边的表的全部,左边的表按条件,符合的显示,不符合则显示 null
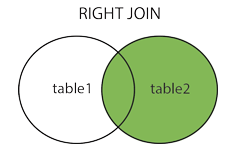
select 列 from 从表 right join 主表 on 连接条件;
全连接
使用 full join 关键字,全连接返回左外连接和右外连接的结果
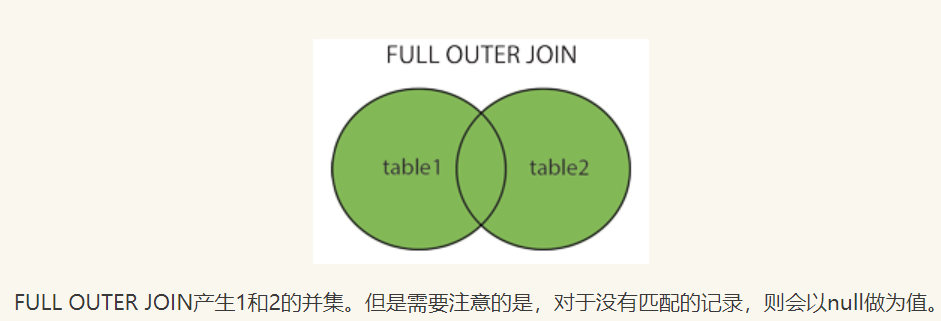
select 列 from 从表 full join 主表 on 连接条件;
自连接
自连接是指使用表的别名实现表与其自身连接的查询方法。
MySQL 查询操作的更多相关文章
- MySQL查询操作——2
-----------查询操作--------------------------- 查询表中的所有字段SELECT * FROM employees; 查询常量值SELECT 100;SELECT ...
- MYSQL查询操作 详细
学习目标 1 掌握select查询所有字段.指定字段的数据 2 掌握消除重复行命令distinct 3 掌握as给字段.表起别名 4 掌握条件查询where后跟比较运算符.逻辑运算符的用法 5 掌握条 ...
- mysql查询操作之单表查询、多表查询、子查询
一.单表查询 单表查询的完整语法: .完整语法(语法级别关键字的排列顺序如下) select distinct 字段1,字段2,字段3,... from 库名.表名 where 约束条件 group ...
- MySQL查询操作
查询执行路径中的组件:查询缓存.解析器.预处理器.优化器.查询执行引擎.存储引擎SELECT语句的执行流程: FROM Clause --> WHERE Clause --> GROUP ...
- mysql查询操作1
##1.在已有的表中插入一行记录 insert into tb_name values("",""...); ##2.查询语句的框架和用法 select 字段名 ...
- MySQL查询操作select
查找记录 SELECT select_expr [,select_expr ...] [ FROM table_references(表的参照) [WHERE where_condition](条件) ...
- C#参数化执行SQL语句,防止漏洞攻击本文以MySql为例【20151108非查询操作】
为什么要参数化执行SQL语句呢? 一个作用就是可以防止用户注入漏洞. 简单举个列子吧. 比如账号密码登入,如果不用参数, 写的简单点吧,就写从数据库查找到id和pw与用户输入一样的数据吧 sql:se ...
- MySQL(三) 数据库表的查询操作【重要】
序言 1.MySQL表操作(创建表,查询表结构,更改表字段等), 2.MySQL的数据类型(CHAR.VARCHAR.BLOB,等), 本节比较重要,对数据表数据进行查询操作,其中可能大家不熟悉的就对 ...
- MySQL数据库学习笔记(九)----JDBC的ResultSet接口(查询操作)、PreparedStatement接口重构增删改查(含SQL注入的解释)
[声明] 欢迎转载,但请保留文章原始出处→_→ 生命壹号:http://www.cnblogs.com/smyhvae/ 文章来源:http://www.cnblogs.com/smyhvae/p/4 ...
随机推荐
- 201871030131-谢林江 实验二 个人项目—《D{0-1} KP》项目报告
项目 内容 课程班级博客链接 班级博客 这个作业要求链接 作业要求 我的课程学习目标 1.学习编写PSP2.完成个人项目实验要求3.在Github建仓 这个作业在哪些方面帮助我实现学习目标 1.首次编 ...
- 报错:Method definition shorthands are not supported by current JavaScript version
当你在html中使用调用js中的方法时,会出现这行报错: method definition shorthands are not supported by current JavaScript ve ...
- 网络编程NIO之Reactor线程模型
目录 单Reactor线程模型 基于工作线程的Reactor线程模型 多Reactor线程模型 多Reactor线程模型示例 结束语 上篇文章中写了一些NIO相关的知识以及简单的NIO实现示例,但是示 ...
- 网络编程之BIO和NIO
目录 OSI网络七层模型 TCP/UDP协议 TCP消息头 TCP三次握手.四次挥手 UDP协议 TCP协议/UDP协议区别 HTTP协议 HTTP协议请求头 HTTP协议响应头 HTTP状态码 so ...
- JDBC_15_悲观锁和乐观锁
悲观锁和乐观锁 并发控制 当程序中可能出现并发操作的情况时,就需要保证在并发操作的情况下数据的准确性,以此确保当前用户和其他用户一起操作时,所得到的结果和某个用户单独操作时的结果是一样的.这种手段就叫 ...
- Java并发的背景
在操作系统中,并发是指一个时间段中有几个程序都处于已启动运行到运行完毕之间,且这几个程序都是在同一个处理机上运行,但任一个时刻点上只有一个程序在处理机上运行. 并发与操作系统的生命历程息息相关.进程的 ...
- Dubbo学习笔记(二) Dubbo的基本配置
Check启动检查 根据之前的学习,我们简单理解的Dubbo远程调用的基本流程,服务提供者注册到注册中心,然后服务消费者通过监听注册中心达到远程调用的目的,那么如果注册中心中没有消费者对应的接口会怎么 ...
- 1.1.09- 序列赋值 is , is not运算符
两个变量的交换算法 代码如下: a = 10000 b = 20000 temp = a a = b b = temp print(a) print(b) 序列赋值: a,b = b,aprint(a ...
- POJ 2762 单连通图
题意: 给你一个有向图,问你这个图是不是单连通图,单连通就是任意两点之间至少存在一条可达路径. 思路: 先强连通所点,重新建图,此时的图不存在环,然后我们在看看是否存在一条路径可以 ...
- 编译Android 4.4.4 r1的源码刷Nexus 5手机详细教程
本文博客地址:http://blog.csdn.net/qq1084283172/article/details/54562606 网上关于编译Android源码的教程已经很多了,但是讲怎么编译And ...