Scala 函数式编程思想
Spark 选择 Scala 作为开发语言
在 Spark 诞生之初,就有人诟病为什么 AMP 实验室选了一个如此小众的语言 - Scala,很多人还将原因归结为学院派的高冷,但后来事实证明,选择 Scala 是非常正确的,Scala 很多特性与 Spark 本身理念非常契合,可以说它们是天生一对。
Scala 背后所代表的函数式编程思想也越来越为人所知。
函数式编程思想早在 50 多年前就被提出,但当时的硬件性能太弱,并不能发挥出这种思想的优势。目前多核 CPU 大行其道,函数式编程在并发方面的优势也逐渐显示出了威力。这就好像 Java 在被发明之处,总是有人说消耗内存太多、运行速度太慢,但是随着硬件性能的翻倍,Java 无疑是一种非常好的选择。
何为函数式编程
函数式编程属于声明式编程,与其相对的是命令式编程,命令式编程是按照“程序是一系列改变状态的命令” 来建模的一种建模风格,而函数式编程思想是 ”程序是表达式和变换,以数学方程的形式建立模型,并且尽可能避免可变状态“。
函数式编程会有一些类别的操作,如映射、过滤或者归约,每一种都有不同的函数作为代表,如 filter、map、reduce。这些函数实现的是低阶变换,而用户定义的函数将作为这些函数的参数来实现整个方程,用户自定义的函数成为高阶变换。
命令式编程将计算机程序看成动作的序列,程序运行的过程就是求解的过程,而函数式编程则是从结果入手,用户通过函数定义了从最初输入到最终输出的映射关系,从这个角度上来说,用户编写代码描述了用户的最终结果(我想要什么),而并不关心(或者不需要关心)求解过程,因此函数式编程绝对不会去操作某个具体的值,这类似于用户编写的 SQL 语句
select age,count(*) from t_user group by age
SQL 是很典型的声明式编程,你只需要告诉 SQL 引擎要统计有多少同年人,至于底层是怎么执行的,你不需要关心。
函数式编程举例
可能听起来还是太抽象,举个例子吧
有一个数据清洗的任务,需要将姓名数组中的单字符姓名(脏数据)去掉,并将首字母大写,最后再拼成一个逗号分隔的字符串。比如有数据 [”rose","jim","Tom","k“,"david"],数据清洗后变成 "Rose, Jim,Tom,David" 即可。
先来看使用 Java 命令式编程实现如下:
List<String> names = new ArrayList<String>() {
{
add("rose");
add("jim");
add("Tom");
add("k");
add("david");
}
};
StringBuilder cleanNames = new StringBuilder();
for (String name : names) {
if (name.length() > 1) {
name = name.substring(0,1).toUpperCase() + name.substring(1);
cleanNames.append(name+",");
}
}
cleanNames.deleteCharAt(cleanNames.length()-1); //去掉最后的逗号
System.out.println(cleanNames.toString());
再来看使用 Scala 函数式编程实现如下:
val names = List("rose","jim","Tom","k","david");
val cleanNames = names
.filter(n => n.length > 1) // 过滤掉字符串长度小于等于 1
.map(n => n.capitalize) // 将所有字符串首字母转换为大写
.reduce((x,y) => x + ", " + y) //在两两字符串之间添加逗号
.toString
println(cleanNames)
从这个例子可以看出,在命令式编程的 Java 版本中,只执行了一次循环操作,而在函数式编程的 Scala 版本中,执行了 3 次循环操作(filter、map、reduce),每一次只完成一种变换逻辑。函数式编程是不是很像 Linux 管道,输入值经过一次逻辑变换就好比经过一次管道,然后将输出值又作为另一个逻辑变换的输入值。而每次逻辑变换都会操作一次输入数据。
从性能上来说,当然前者更为优秀,这说明了在硬件性能羸弱时,函数式的缺点会被放大,但我们也看到了,在函数式编程不用定义中间变量,维护中间状态,这对于并行计算场景非常友好。
函数式编程与数学函数
在严格的函数式编程中,所有函数都遵循数学函数的定义,必须有自变量(入参),必须有因变量(返回值)。用户定义的逻辑以高阶函数的形式体现,即用户可以将自定义函数以参数形式传入其他低阶函数中。
初学函数式编程的童靴,可能对函数作为参数难以理解,其实从数学的角度上来说,这是很自然的,下面是一个数学表达式:
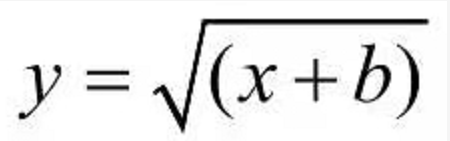
如果定义一个函数 f = x + b,以上函数括号中的 x + b 就可以使用函数 f 替代,这其实就是初中的复合函数的用法。相对与高阶函数,函数式语言一般会提供一些低阶函数用于构建整个流程,这些低阶函数都是无副作用的,非常适合并行计算。高阶函数可以让用户专注于业务逻辑,而不需要去费心构建整个数据流。
当你理解了函数式编程,再来理解 Spark 中提供的很多算子,就会明白其实就是函数式编程的低阶函数。
函数式编程的特点
简单灵活
函数式编程思想因为非常简单(输入参数得到返回值),所以特别灵活,用“太极生两仪,两仪生八卦” 这句话能很好的反映函数式编程灵活多变的特点。
可读性差
虽然函数式编程语言能显著减少代码行数(原因是很多代码由编程语言本身提供的大量低阶函数来完成),但通常让读代码的人苦不堪言。所以,初学函数式编程的童靴,会很不适应哈。没关系,看多了,就会越来越顺眼了。
没有变量
在纯粹的函数式编程中,是不存在变量的,所有的值都是不可变的,也就是说不允许像命令式编程那样多次给一个变量赋值。这样,在多个线程之间不需要共享状态,因此也不需要线程同步锁来保护可变状态,这使得函数式编程能更好地利用多核的计算能力。
低阶函数
如果使用低阶函数与高阶函数来完成我们的程序,这其实就是将程序控制权让为于语言,而我们专注于业务逻辑。这样做的好处还在于,有利于程序优化,享受免费的性能提升午餐,如语言开发者专注于优化低阶函数,而应用开发者则专注于优化高阶函数。低阶函数式复用的,因此当低阶函数性能提升时,程序不需要改一行代码就能得到提升。
核心数据结构
函数式编程语言通常只提供几种核心数据结构,供开发者选择,它希望开发者能基于这些简单的数据结构组合出复杂的数据结构,这与低阶函数的思想是一致的,很多函数式编程语言的特性会着重优化核心数据结构。
惰性求值
惰性求值(lazy evaluation)是函数式编程语言常见的一种特性,通常指尽量延后求解表达式的值,这样对于开销大的计算可以做到按需计算,利用惰性求值的特性可以构建无限大的集合。惰性求值其实和 MyBatis 的延时加载是一回事。
函数记忆
由于在函数式编程中,函数本身是无状态的,因此给定入参,一定能得到确定的结果。基于此,函数式语言会对函数进行记忆或者缓存,避免重复计算。函数记忆其实就是递归函数。
副作用少
函数副作用指的是当调用函数时,除了返回值之外,还会对调用函数产生附加的影响,例如修改全局变量或者修改参数。在函数式编程中,低阶函数本身没有副作用,高阶函数不会(很少)影响其他函数,这对于并发和并行来说非常有用。至于,程序中想要做到完全没有变量,没有状态,几乎是不可能的,只能尽量把副作用限制在指定范围内。
函数式编程最难的地方也就是如何编写副作用少的程序。如果对这方面有兴趣,可以阅读《Scala 函数式编程》这本书,专门讲解如何编写副作用少的函数。
总结
函数式编程思想和命令式编程思想相比,并没有所谓的优劣之分,还是取决于使用场景。Spark 选择 Scala 也是由于函数式语言在并行计算下的优势非常契合 Spark 的使用场景。
学习 Scala 语言的特性,你会发现 Spark 在很多宏观设计层面都借鉴了函数式编程思想,如下:
函数式编程接口
函数式编程思想的一大特点是低阶函数和核心数据结构,在 Spark API 中,这一点得到了很好的继承。Spark API 同样提供了 map、reduce、filter 等算子来构建数据处理管道,用户的业务逻辑以高阶函数的形式定义,用户通过高阶函数与算子之间的组合,像搭积木一样,构建了整个作业的执行过程。
此外,从根本上来说, Spark 最核心的数据结构只有一种:RDD(弹性分布式数据集),从 API 上来说,它和普通集合几乎完成相同,但是它却抽象了分布式文件系统中的文件,对于用户来说,这是透明的,从这个角度来说,RDD 是一个分布式的集合。
惰性求值
Spark 的算子分为两类,转换算子和行动算子,只有行动算子才会真正触发整个作业提交并运行。这样一来,无论用户采用了多少个转换算子来构建一个无比复杂的数据处理管道,只有最后的行动算子才能触发整个作业开始执行。
容错
在 Spark 的抽象中,处理的每一份数据都是不可变的,它们都是由它所依赖的上游数据集生成出来的,依赖关系由算子定义,在一个 Spark 作业中,这被称为血统。在考虑容错时,与其考虑如何持久化每一分数据,不如保存血统依赖和上游数据集,从而在下游数据集出现可用性问题时,利用血统依赖和上游数据集重算进行恢复。这是利用了函数(血统依赖)在给定参数(上游数据集)情况下,一定能够得到确定输出(下游数据集)的特性。
Scala 函数式编程思想的更多相关文章
- Scala 函数式编程(一) 什么是函数式编程?
为什么我们需要学习函数式编程?或者说函数式编程有什么优势?这个系列中我会用 scala 给你讲述函数式编程中的优势,以及一些函数式的哲学.不懂 scala 也没关系,scala 和 java 是类似的 ...
- Scala函数式编程(三) scala集合和函数
前情提要: scala函数式编程(二) scala基础语法介绍 scala函数式编程(二) scala基础语法介绍 前面已经稍微介绍了scala的常用语法以及面向对象的一些简要知识,这次是补充上一章的 ...
- Scala函数式编程(四)函数式的数据结构 上
这次来说说函数式的数据结构是什么样子的,本章会先用一个list来举例子说明,最后给出一个Tree数据结构的练习,放在公众号里面,练习里面给出了基本的结构,但代码是空缺的需要补上,此外还有预留的test ...
- Scala函数式编程(四)函数式的数据结构 下
前情提要 Scala函数式编程指南(一) 函数式思想介绍 scala函数式编程(二) scala基础语法介绍 Scala函数式编程(三) scala集合和函数 Scala函数式编程(四)函数式的数据结 ...
- Scala函数式编程(五) 函数式的错误处理
前情提要 Scala函数式编程指南(一) 函数式思想介绍 scala函数式编程(二) scala基础语法介绍 Scala函数式编程(三) scala集合和函数 Scala函数式编程(四)函数式的数据结 ...
- Scala函数式编程(六) 懒加载与Stream
前情提要 Scala函数式编程指南(一) 函数式思想介绍 scala函数式编程(二) scala基础语法介绍 Scala函数式编程(三) scala集合和函数 Scala函数式编程(四)函数式的数据结 ...
- Scala函数式编程进阶
package com.dtspark.scala.basics /** * 函数式编程进阶: * 1,函数和变量一样作为Scala语言的一等公民,函数可以直接赋值给变量: * 2, 函数更长用的方式 ...
- Scala函数式编程——近半年的痛并快乐着
从9月初啃完那本让人痛不欲生却又欲罢不能的<七周七并发模型>,我差不多销声匿迹了整整4个月.这几个月里,除了忙着讨食,便是继续啃另一本"锯著"--<Scala函数 ...
- Scala实战高手****第5课:零基础实战Scala函数式编程及Spark源码解析
Scala函数式编程 ----------------------------------------------------------------------------------------- ...
随机推荐
- 如何调试 Java 开源项目源码,记一种源码导入开发工具并调试的通用方法
楔子 说起读开源项目源码,很多朋友觉得高大上.大佬牛逼,云云~ 挡在很多人面前的不是源码怎么读,而是不知道如何导入源码到开发工具以及如何调试源码. 本文将以 spring-cloud-gateway ...
- BUAA_2021_SE_READING_#2
项目 内容 这个作业属于哪个课程 2021春季软件工程(罗杰 任健) 这个作业的要求在哪里 个人阅读作业#2 我在这个课程的目标是 通过课程学习,完成第一个可以称之为"软件"的项目 ...
- HTML5是什么
HTML5是目前超文本标记语言 (Hyper Text Markup Language)最新修订版.HTML可以理解为一门程序语言,HTML5字面的意思,这门程序语言的第五次修订,也是HTML的第五个 ...
- 源码编译安装MySQL8.0.20
1 概述 本文章主要讲述了如何从源码编译安装MySQL社区版8.0.20,首先会介绍一些编译安装的相关知识,然后开始编译安装 2 源码编译安装的相关知识 2.1 make与configure make ...
- DPAPI机制学习
0x00 前言 绝大多数应用程序都有数据加密保护的需求,存储和保护私密信息最安全的方式就是每次需要加密或解密时都从用户那里得到密码,使用后再丢弃.这种方式每次处理信息时都需要用户输入口令,对于绝大多 ...
- animation几个比较好玩的属性(alternate,及animation-fill-mode)
<!DOCTYPE html> <html> <head> <style> div { width:100px; height:100px; backg ...
- 病毒木马查杀实战第021篇:Ring3层主动防御之编程实现
前言 我们这次会依据上次的内容,编程实现一个Ring3层的简单的主动防御软件.整个程序使用MFC实现,程序开始监控时,会将DLL程序注入到explorer.exe进程中,这样每当有新的进程创建,程序首 ...
- Win64 驱动内核编程-34.对抗与枚举MiniFilter
对抗与枚举MiniFilter MiniFilter 是目前杀毒软件用来实现"文件系统自我保护"和"文件实时监控"的方法. 由于 MiniFilter 模型简单 ...
- JVM虚拟机-了解Java堆中对象分配、布局和访问的全过程
目录 前言 对象的创建 类加载检查 分配内存 内存空间分配方式 指针碰撞 空闲列表 并发时的内存分配 同步处理:CAS 本地线程分配缓冲:TLAB 初始化零值 设置对象头 执行 init 方法 对象的 ...
- Day003 数据类型拓展
数据类型拓展 整数拓展 进制 通常我们使用的都是10进制的整数,java中可以表示不同进制的整数 进制 表示方法 二进制 0b 八进制 0 十进制 默认 十六进制 0x 看看下面这个例子吧 int ...