Hadoop完整搭建过程(三):完全分布模式(虚拟机)
1 完全分布模式
完全分布模式是比本地模式与伪分布模式更加复杂的模式,真正利用多台Linux主机来进行部署Hadoop,对集群进行规划,使得Hadoop各个模块分别部署在不同的多台机器上,这篇文章介绍的是通过三台虚拟机进行集群配置的方式,主要步骤为:
- 准备虚拟机:准备虚拟机基本环境
ip+Host配置:手动设置虚拟机ip以及主机名,需要确保三台虚拟机能互相ping通ssh配置:生成密钥对后复制公钥到三台虚拟机中,使其能够实现无密码相互连接Hadoop配置:core-site.xml+hdfs-site.xml+workersYARN配置:yarn-site.xml
2 虚拟机安装
需要使用到三台虚拟机,其中一台为Master节点,两台Worker节点,首先安装虚拟机并配置环境,最后进行测试。
2.1 镜像下载
使用VirtualBox进行虚拟机的安装,先去CentOS官网下载最新版本的镜像:
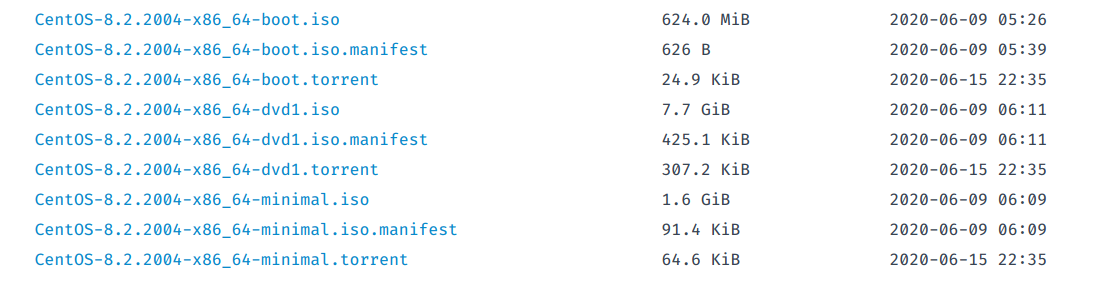
这里有三种不同的镜像:
boot:网络安装版dvd1:完整版minimal:最小化安装版
这里为了方便选择最小化安装版的,也就是不带GUI的。
2.2 安装
下载后,打开Virtual Box并点击New,选择专家模式:
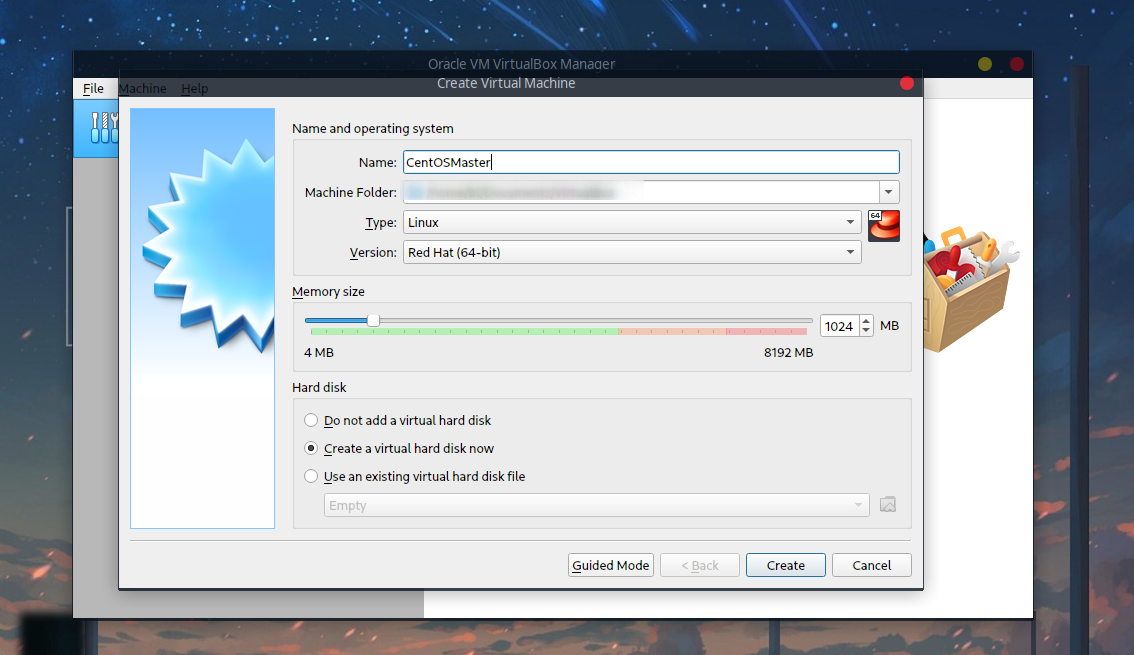
命名为CentOSMaster,作为Master节点,并且分配内存,这里是1G,如果觉得自己内存大的可以2G:
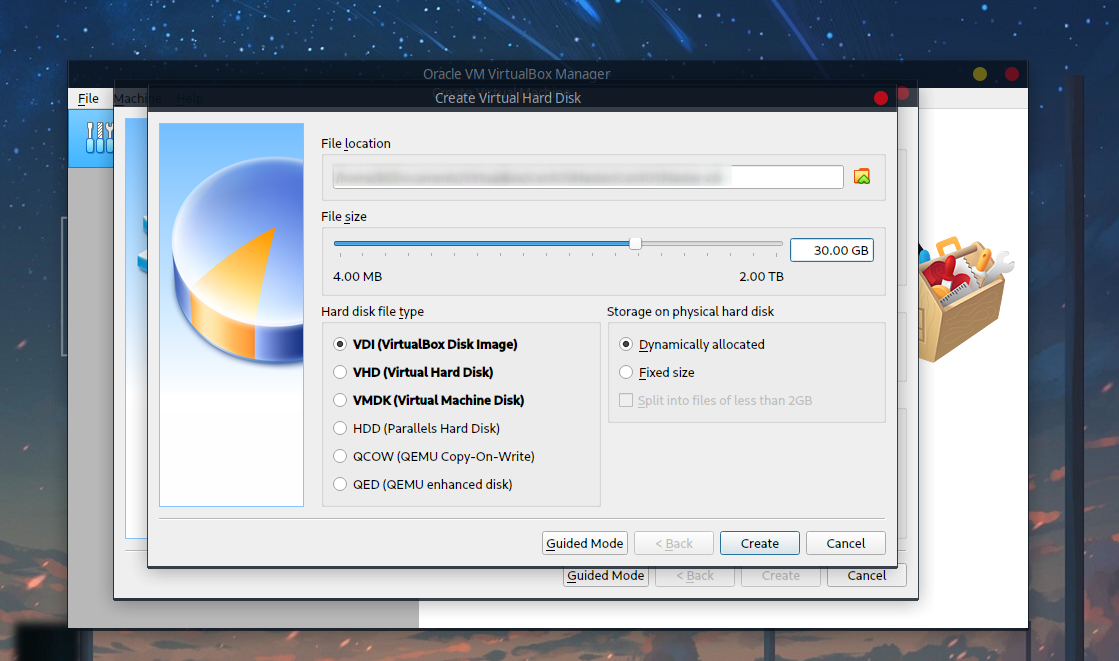
磁盘30G足够,其他可以保持默认:
创建好后从设置中的存储中,选择下载的镜像:
启动后会提示选择启动盘,确定即可:
好了之后会出现如下提示画面,选择第一个安装:
等待一会后进入安装界面:
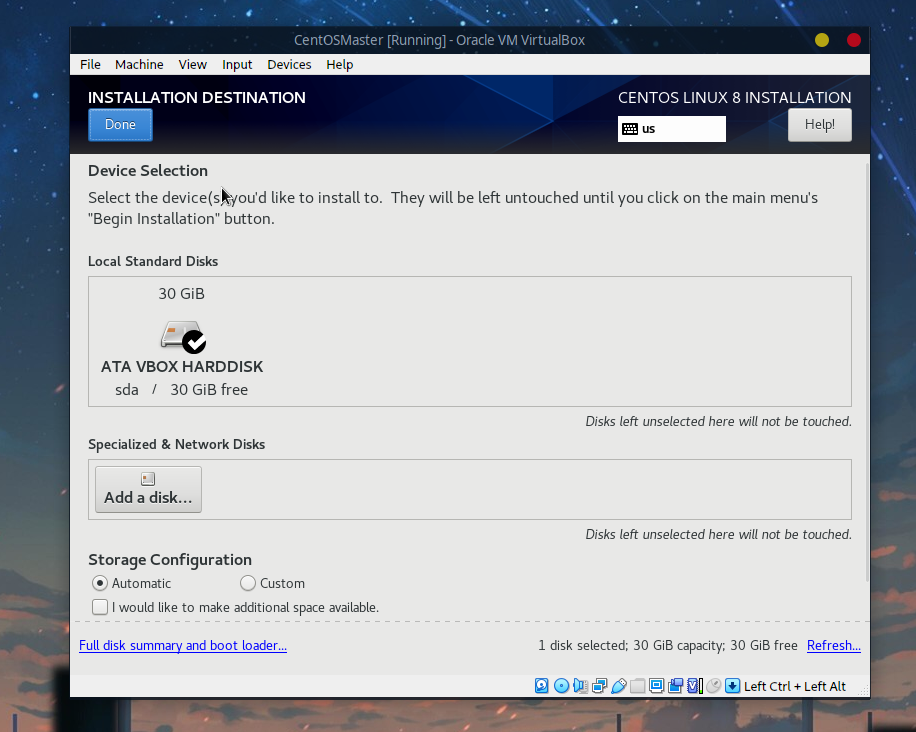
接下来对安装位置以及时区进行配置,首先选择安装位置:
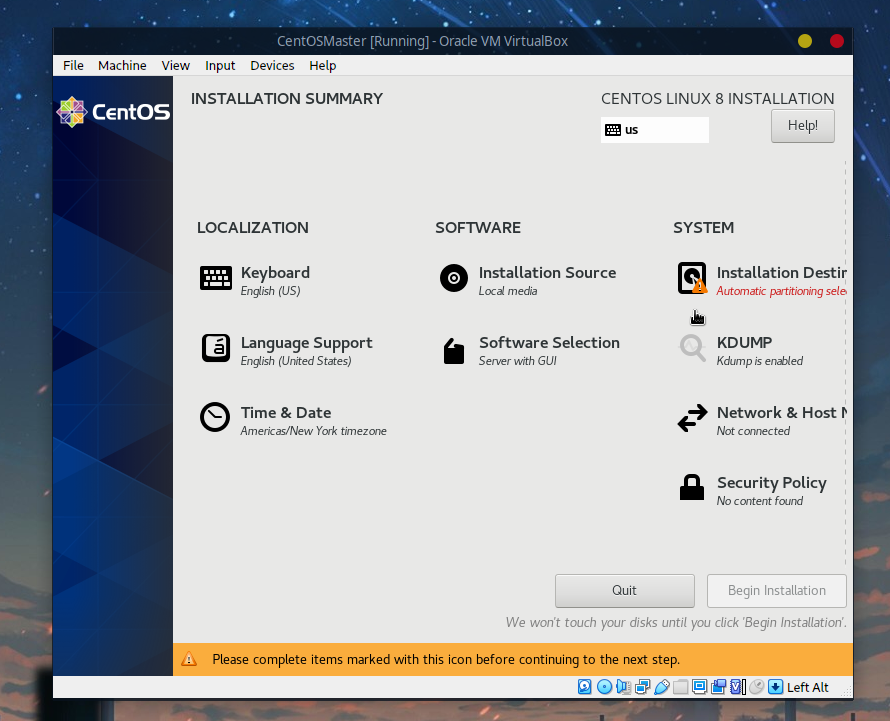
由于是虚拟的单个空磁盘,选择自动分区即可:
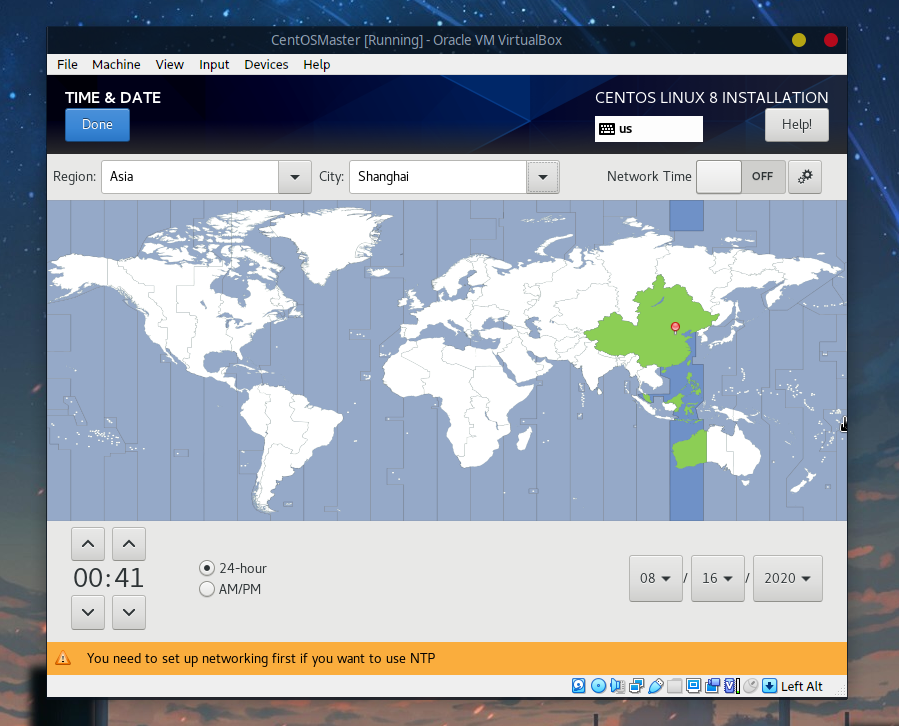
时区这里可以选择中国的上海:
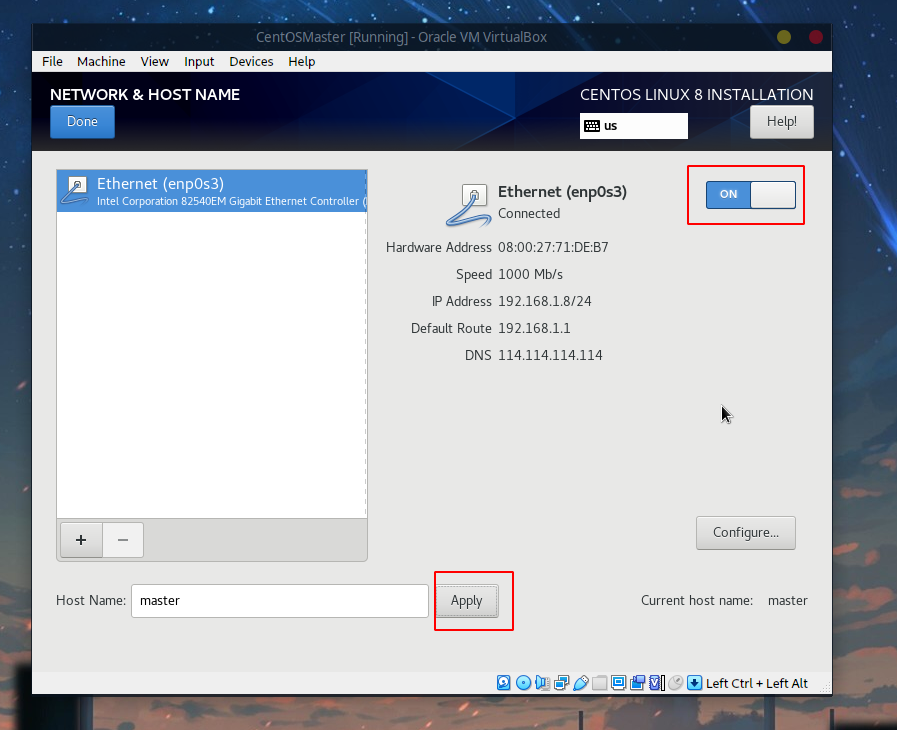
接着选择网络,首先修改主机名为master:
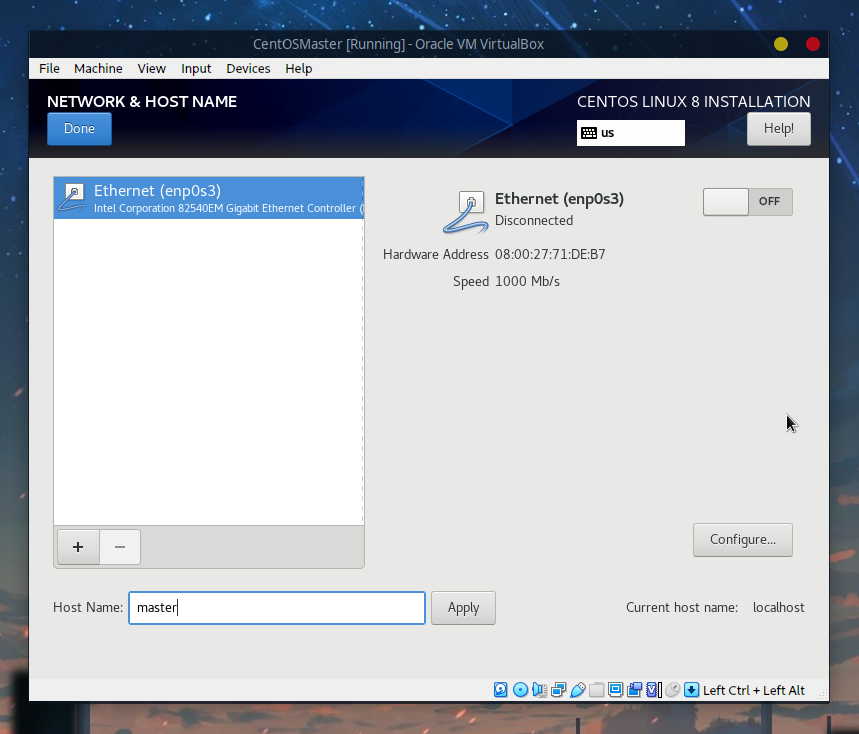
接着点击Configure:
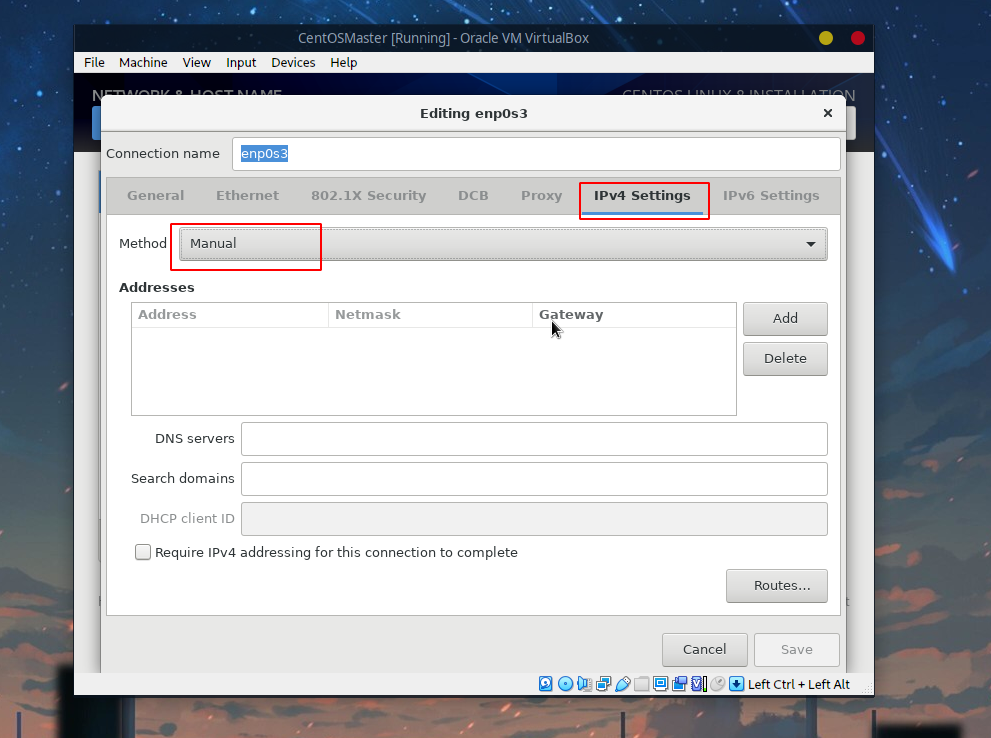
添加ip地址以及DNS服务器,ip地址可以参考本机,比如笔者的机器本地ip为192.168.1.7,则:
- 虚拟机的
ip可以填192.168.1.8 - 子网掩码一般为
255.255.255.0 - 默认网关为
192.168.1.1 DNS服务器为114.114.114.114(当然也可以换其他的公共DNS比如阿里的223.5.5.5、百度的180.76.76.76等)
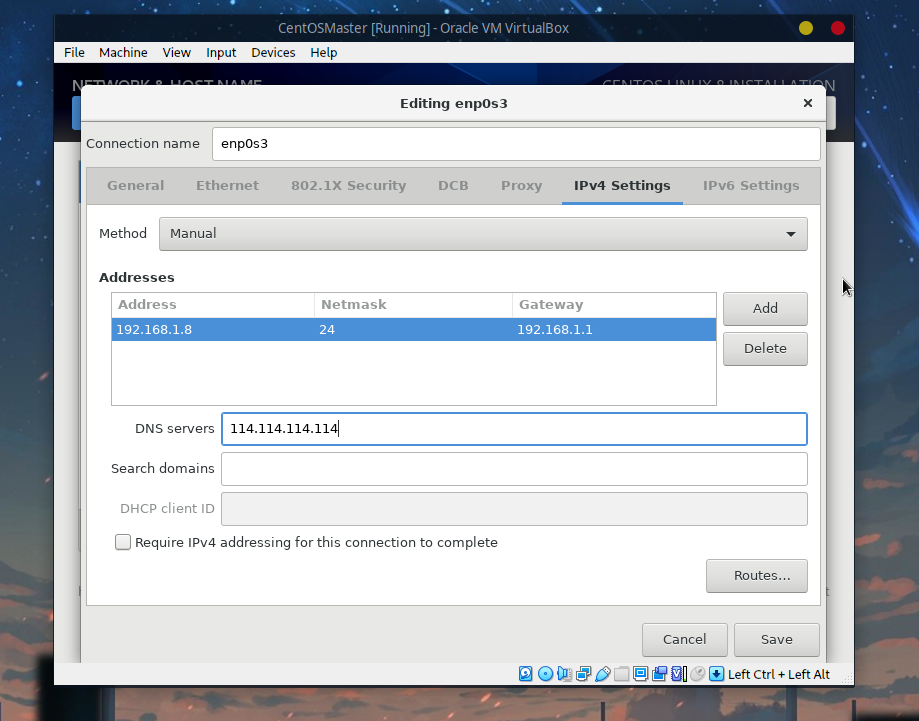
点击Save后应用主机名并开启:
没问题的话就可以安装了:
安装的时候设置root用户的密码以及创建用户:
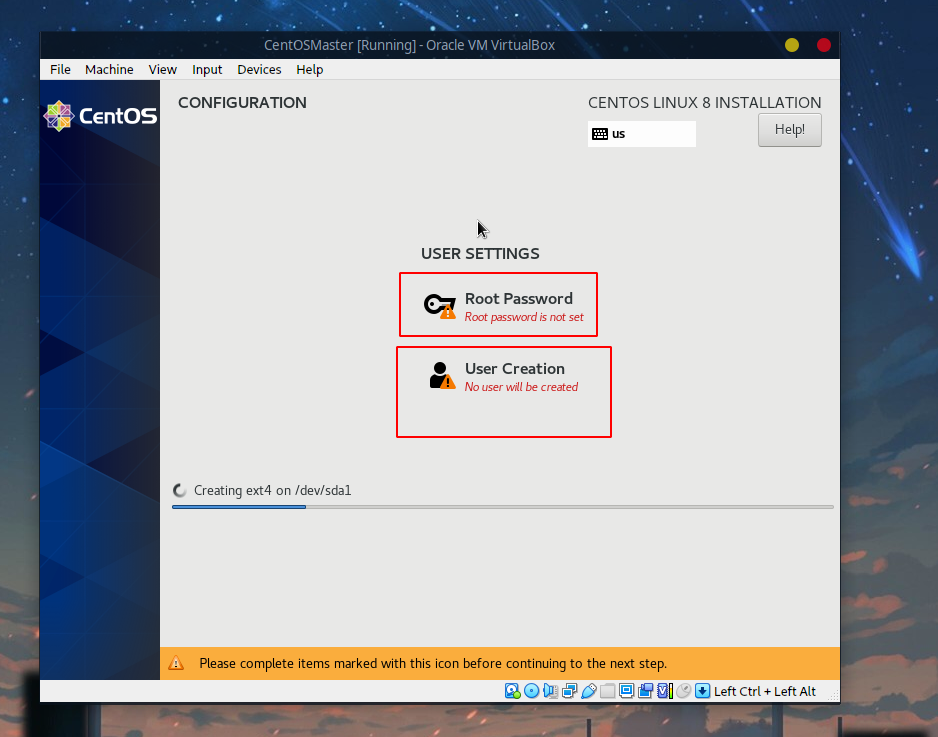
用户这里采用一个叫hadoopuser的用户,后面的操作都直接基于该用户:
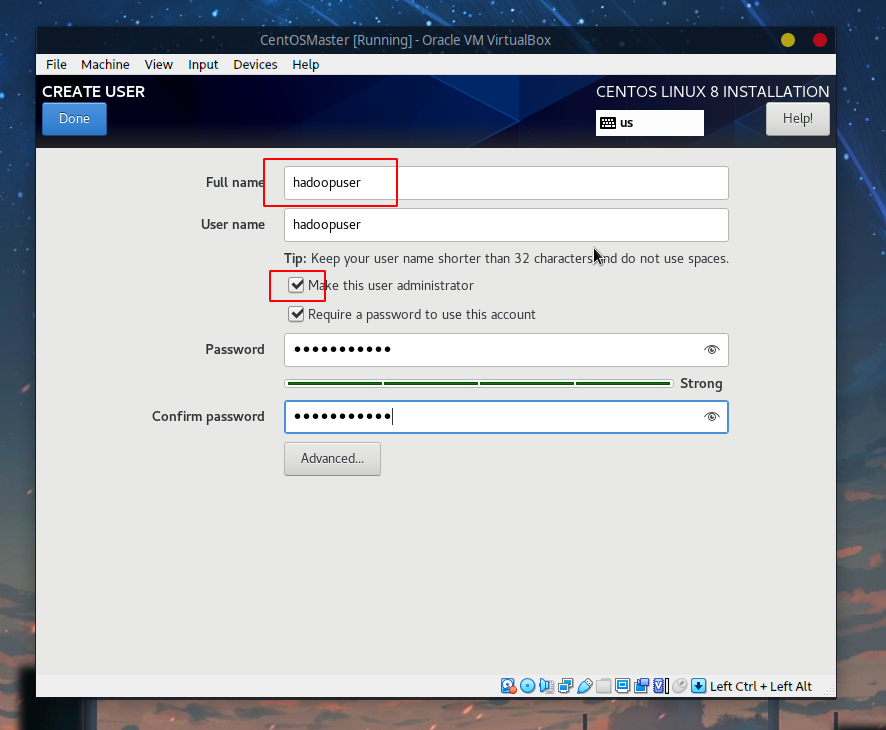
等待一段时间后安装完成重启即可。
2.3 启动
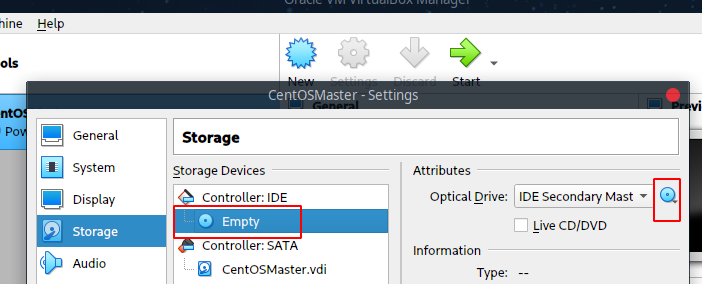
在启动之前首先把原来的镜像去掉:
启动后是黑框界面:
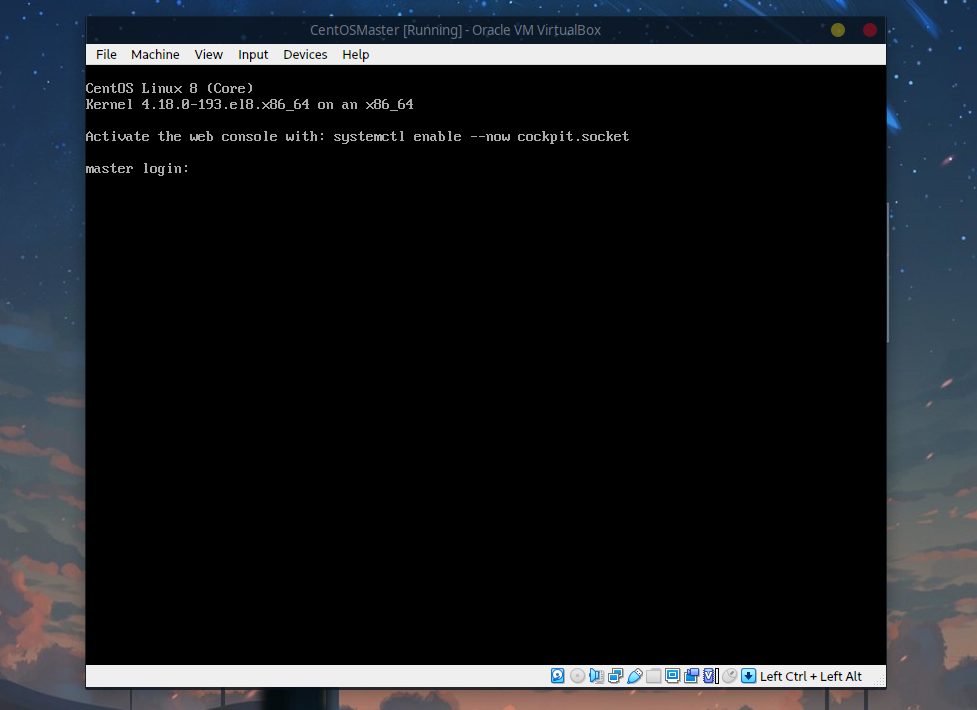
登录刚才创建的hadoopuser用户即可。
3 ssh连接虚拟机
默认的话是不能连接外网的,需要在菜单栏中的Devices中选择Network,设置为Bridged Adapter(桥接模式):
使用ping测试:
接着可以测试能否ping通本地机器:
通了之后可以通过ssh连接虚拟机,像平时操作服务器一样,在本地终端中连接虚拟机,首先添加指纹:

接着输入密码连接即可:
如果想偷懒可以使用密钥连接的方式,在本地机器中:
ssh-keygen -t ed25519 -a 100
ssh-copy-id -i ~/.ssh/id_ed25519.pub hadoopuser@192.168.1.8
4 基本环境搭建
基本环境搭建就是安装JDK以及Hadoop,使用scp上传OpenJDK以及Hadoop。
4.1 JDK
首先去下载OpenJDK,然后在本地机器上使用scp上传:
scp openjdk-11+28_linux-x64_bin.tar.gz hadoopuser@192.168.1.8:/home/hadoopuser
接着在本地上切换到连接虚拟机的ssh中,
cd ~
tar -zxvf openjdk-11+28_linux-x64_bin.tar.gz
sudo mv jdk-11 /usr/local/java
下一步是编辑/etc/profile,添加bin到环境变量中,在末尾添加:
sudo vim /etc/profile
# 没有vim请使用vi
# 或安装:sudo yum install vim
# 添加
export PATH=$PATH:/usr/local/java/bin
然后:
. /etc/profile
测试:

4.2 Hadoop
Hadoop的压缩包scp上传到虚拟机后,解压并移动到/usr/local:
scp hadoop-3.3.0.tar.gz hadoopuser@192.168.1.8:/home/hadoopuser
虚拟机ssh终端:
cd ~
tar -xvf hadoop-3.3.0.tar.gz
sudo mv hadoop-3.3.0 /usr/local/hadoop
同时修改etc/hadoop/hadoop-env.sh配置文件,填入Java路径:
sudo vim /usr/local/hadoop/etc/hadoop/hadoop-env.sh
# 填入
export JAVA_HOME=/usr/local/java # 修改为您的Java目录
5 克隆
因为需要一个Master节点以及两个Worker节点,将Master节点关机,并选择配置好的CentOSMaster,右键进行克隆:
并选择完全克隆:
克隆出CentOSWorker1以及CentOSWorker2。
6 主机名+ip设置
这里的两个Worker节点以Worker1以及Worker2命名,首先操作Worker1,修改主机名:
sudo vim /etc/hostname
# 输入
# worker1
对于ip,由于Master节点的ip为192.168.1.8,因此这里修改两个Worker的节点分别为:
192.168.1.9192.168.1.10
sudo vim /etc/sysconfig/network-scripts/ifcfg-xxxx # 该文件因人而异
# 修改IPADDR
IPADDR=192.168.1.9
修改完成后重启Worker1,对Worker2进行同样的修改主机名以及ip操作。
7 Host设置
需要在Master以及Worker节点进行Host设置:
7.1 Master节点
sudo vim /etc/hosts
# 添加
192.168.1.9 worker1 # 与上面的ip对应一致
192.168.1.10 worker2
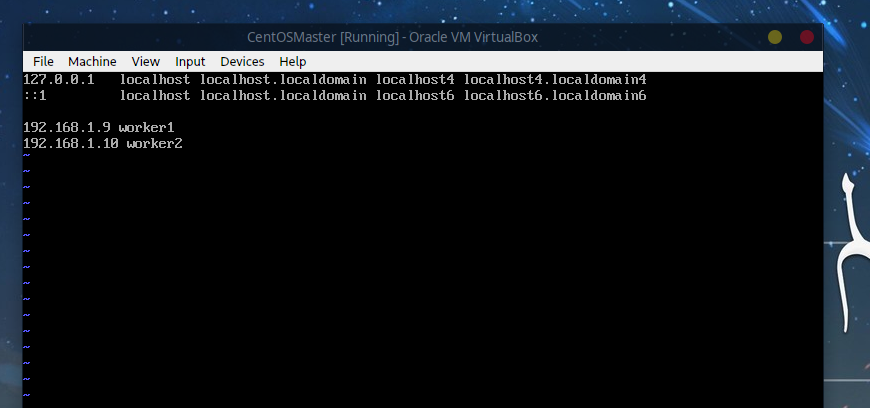
7.2 Worker1节点
sudo vim /etc/hosts
# 添加
192.168.1.8 master
192.168.1.10 worker2
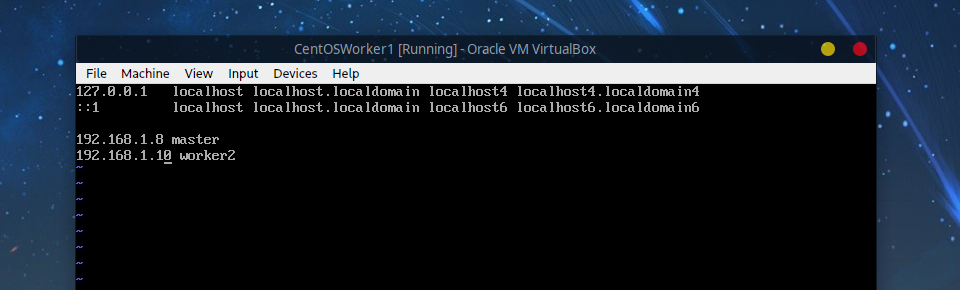
7.3 Worker2节点
sudo vim /etc/hosts
# 添加
192.168.1.8 master
192.168.1.9 worker1
7.4 互ping测试
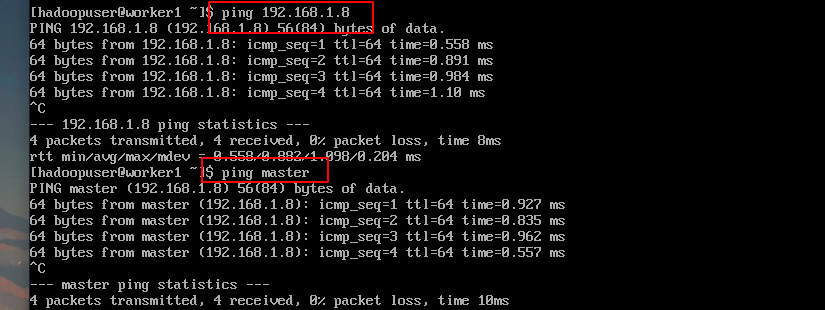
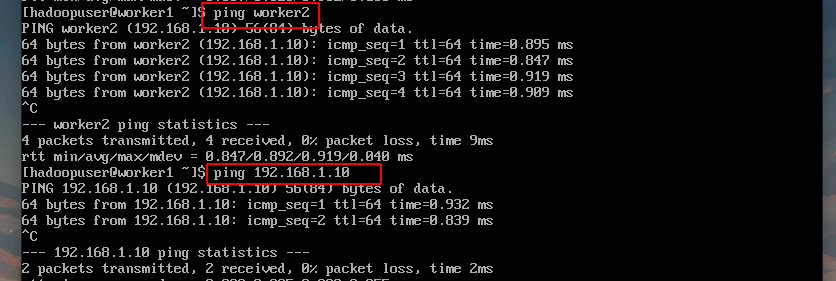
在三台虚拟机中的其中一台ping另外两台的ip或者主机名,测试通过后就可以进行下一步了,这里使用Worker1节点测试:
8 配置ssh
8.1 sshd服务
需要在三个节点(包括自身)之间配置ssh无密码(密钥)连接,首先使用
systemctl status sshd
检查sshd服务是否开启,没开启的使用
systemctl start sshd
开启。
8.2 复制公钥
三个节点都进行如下操作:
ssh-keygen -t ed25519 -a 100
ssh-copy-id master
ssh-copy-id worker1
ssh-copy-id worker2
8.3 测试
在其中一个节点中直接ssh连接其他节点,无需密码即可登录,比如在Master节点中:
ssh master # 都是hadoopuser用户,所以省略了用户
ssh worker1
ssh worker2
9 Master节点Hadoop配置
在Master节点中,修改以下三个配置文件:
HADOOP/etc/hadoop/core-site.xmlHADOOP/etc/hadoop/hdfs-site.xmlHADOOP/etc/hadoop/workers
9.1 core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/data/tmp</value>
</property>
</configuration>
fs.defaultFS:NameNode地址hadoop.tmp.dir:Hadoop临时目录
9.2 hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop/data/datanode</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
dfs.namenode.name.dir:保存FSImage的目录,存放NameNode的metadatadfs.datanode.data.dir:保存HDFS数据的目录,存放DataNode的多个数据块dfs.replication:HDFS存储的临时备份数量,有两个Worker节点,因此数值为2
9.3 workers
最后修改workers,输入(与上面设置的主机名一致):
worker1
worker2
9.4 复制配置文件
把Master节点的配置复制到Worker节点:
scp /usr/local/hadoop/etc/hadoop/* worker1:/usr/local/hadoop/etc/hadoop/
scp /usr/local/hadoop/etc/hadoop/* worker2:/usr/local/hadoop/etc/hadoop/
10 HDFS格式化并启动
10.1 启动
在Master节点中:
cd /usr/local/hadoop
bin/hdfs namenode -format
sbin/start-dfs.sh
运行后可以通过jps命令查看:

在Worker节点中:


10.2 测试
浏览器输入:
master:9870
# 如果没有修改本机Host可以输入
# 192.168.1.8:9870
但是。。。
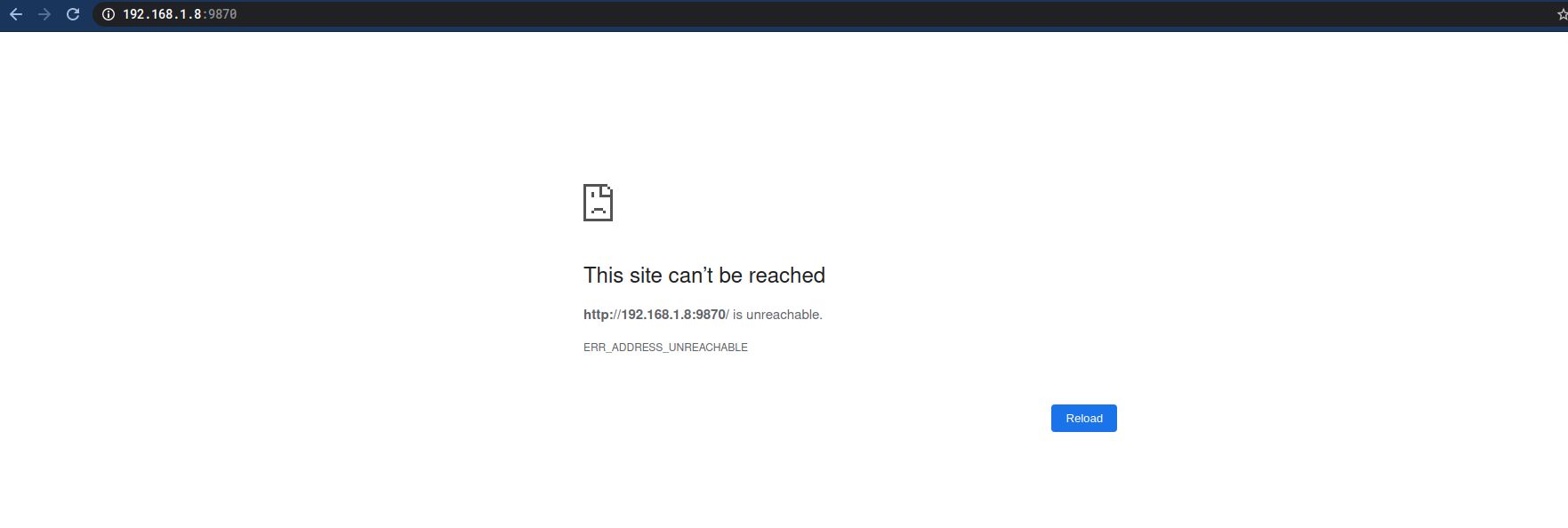
本以为做了这么多能看到成果了。
然后检查过了一遍本机+虚拟机Host,还有Hadoop的配置文件,都没有问题。
最后,
才定位到问题是
防火墙。
10.3 防火墙
CentOS8默认开启了防火墙,可以使用:
systemctl status firewalld
查看防火墙状态。
由于是通过9870端口访问,首先查询9870是否开放,Master节点中输入:
sudo firewall-cmd --query-port=9870/tcp
# 或
sudo firewall-cmd --list-ports
如果输出为no:

则表示没有开放,手动开放即可:
sudo firewall-cmd --add-port=9870/tcp --permanent
sudo firewall-cmd --reload # 使其生效

再次在浏览器输入:
master:9870
# 如果没有修改本地Host
# 192.168.1.8:9870
可以看到一个友好的页面了:
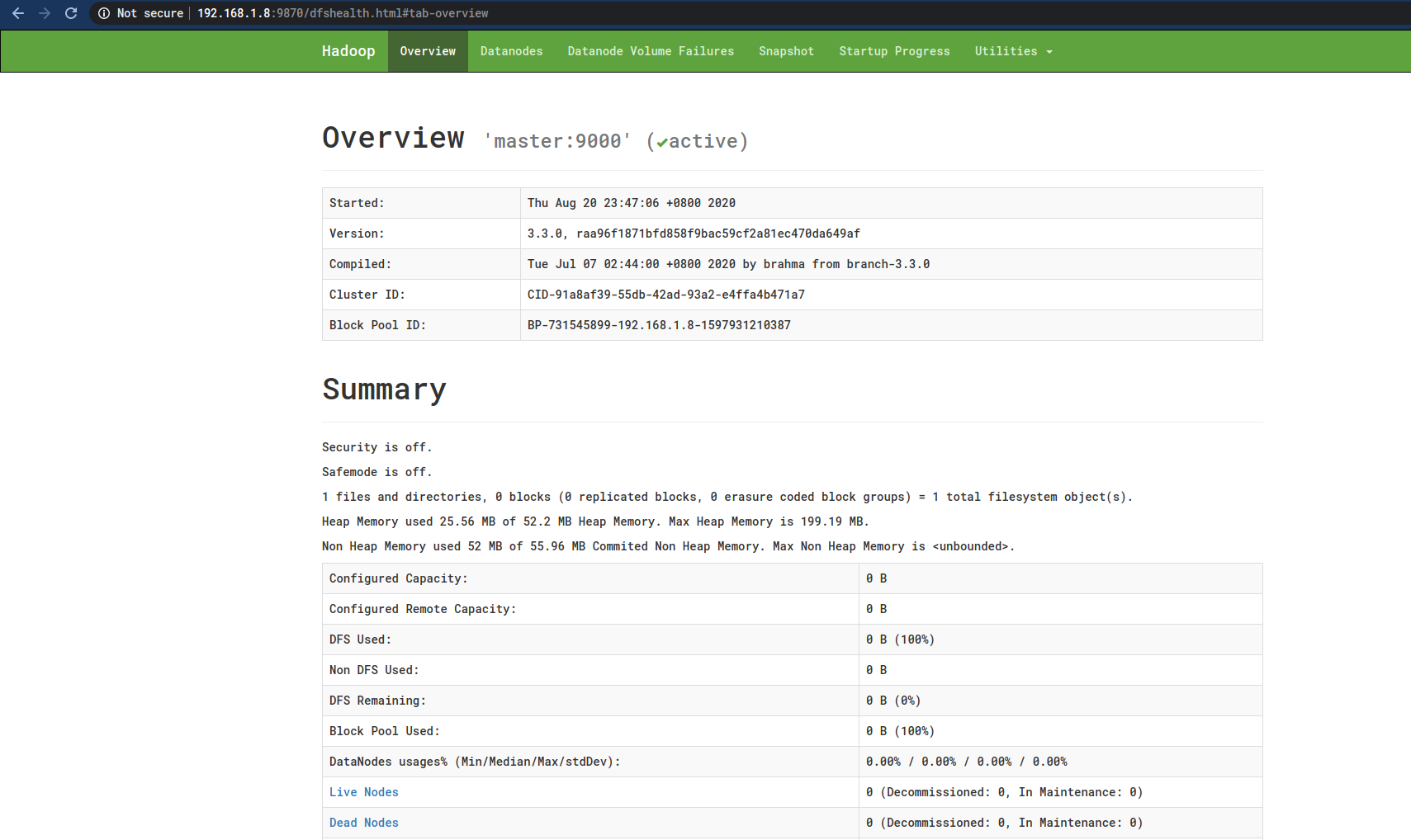
但是,有一个问题就是这里没有显示Worker节点,上图中的Live Nodes数目为0 ,而Datanodes这里什么也没有显示:
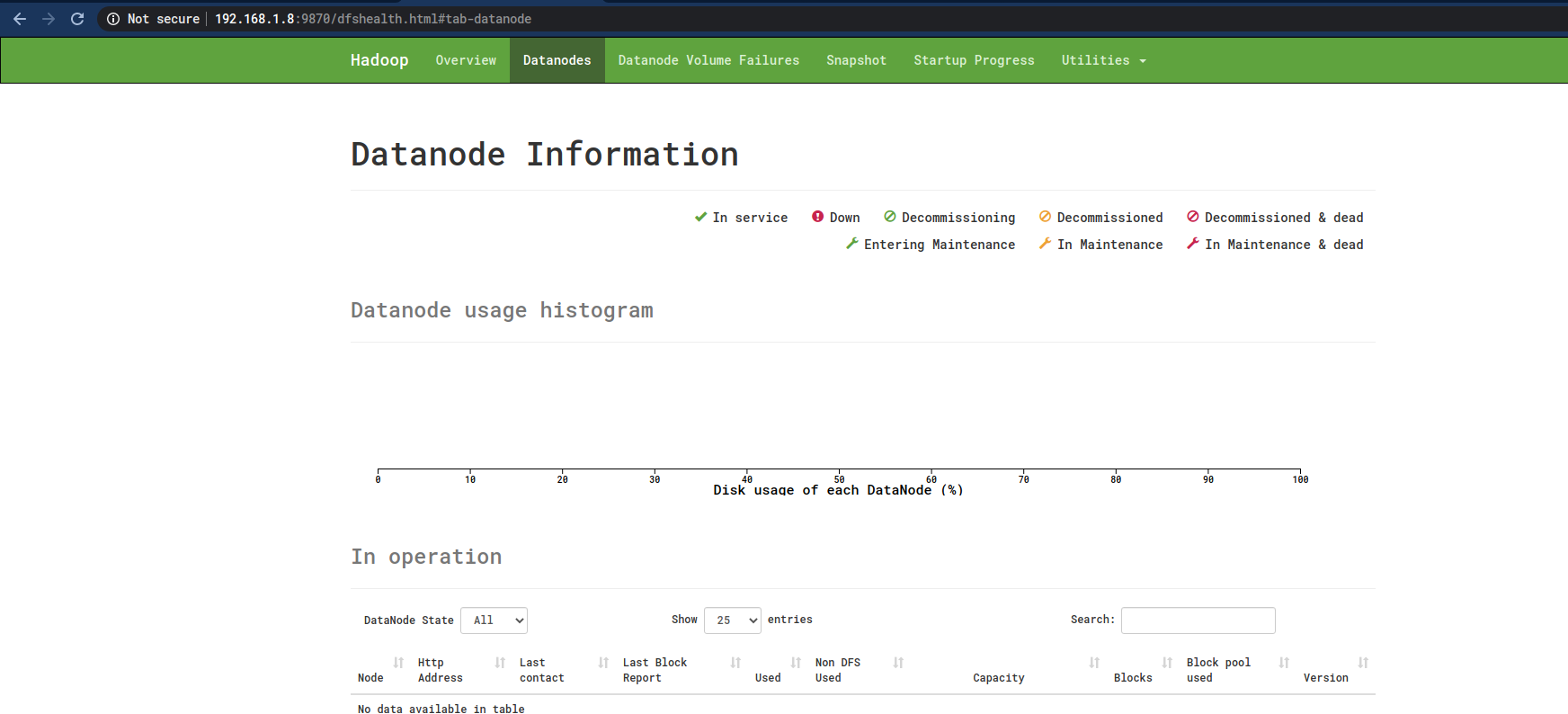
但是在Worker节点中的确可以看到有Datanode的进程了:


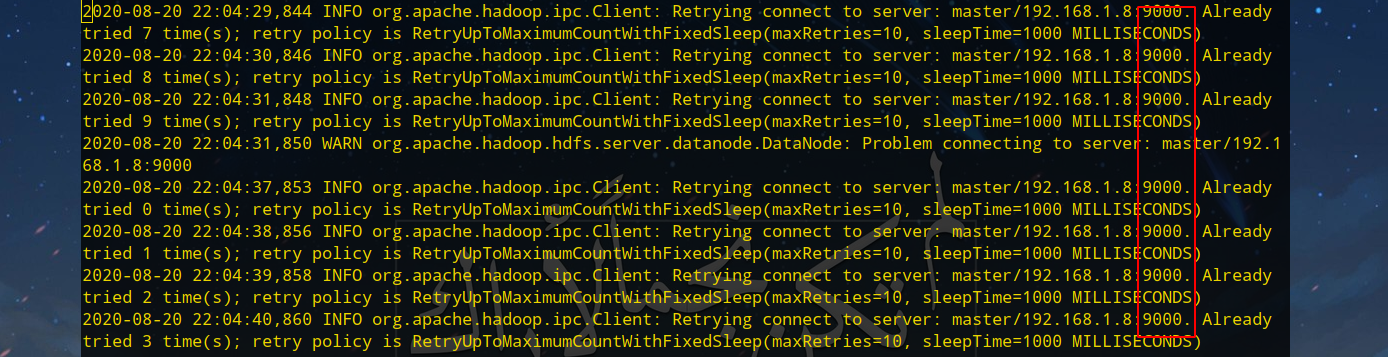
查看Worker节点的日志(/usr/local/hadoop/logs/hadoop-hadoopuser-datanode-worker1.log)可以看到应该是Master节点9000端口的没有开启的问题:
回到Master节点,先执行stop-dfs.sh关闭,并开放9000端口后执行start-dfs.sh开启:
/usr/local/hadoop/sbin/stop-dfs.sh
sudo firewall-cmd --add-port=9000/tcp --permanent
sudo firewall-cmd --reload
/usr/local/hadoop/sbin/start-dfs.sh
再次在浏览器访问:
master:9000
# 或
# 192.168.1.8:9000
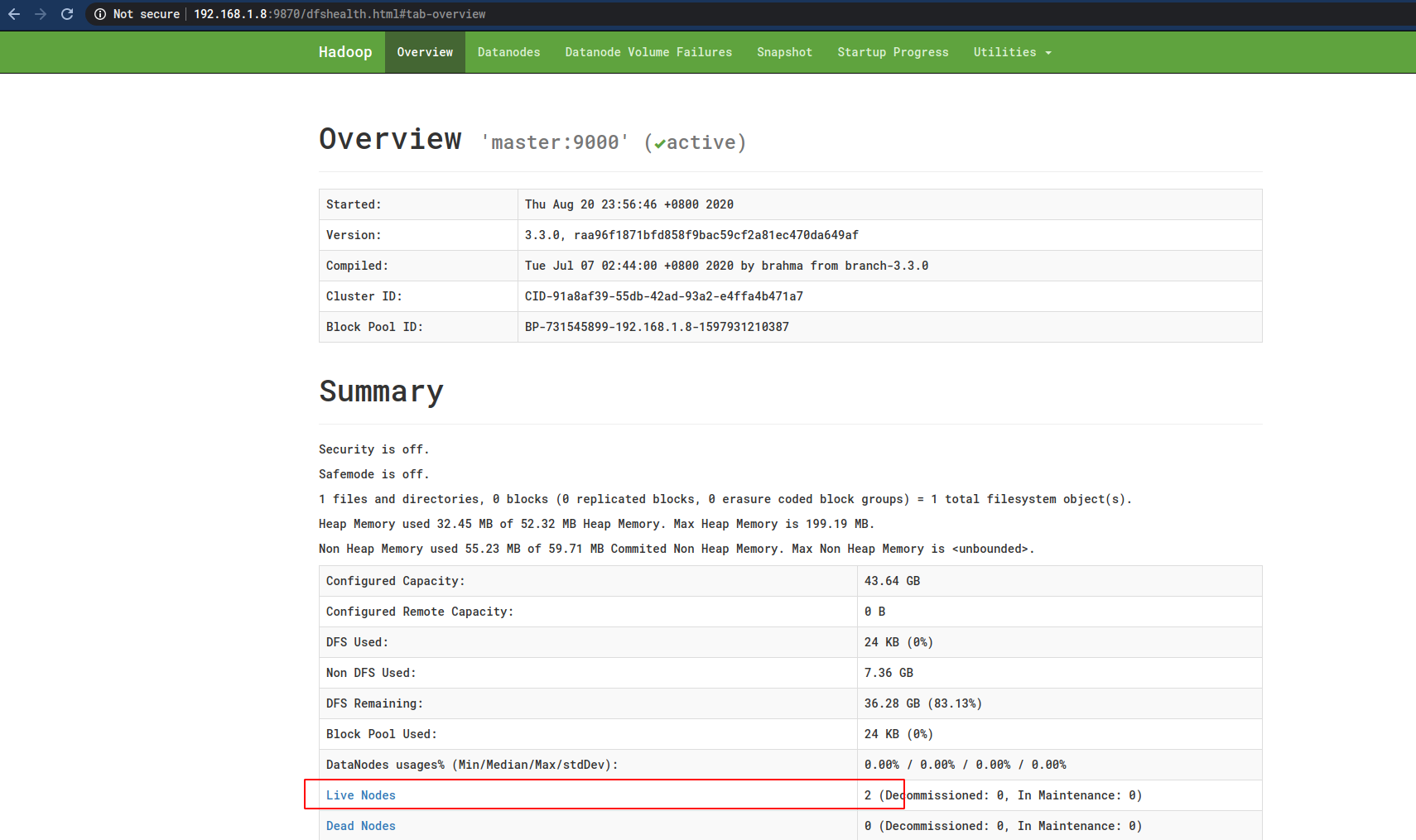
这时候就可以看见Worker节点了:
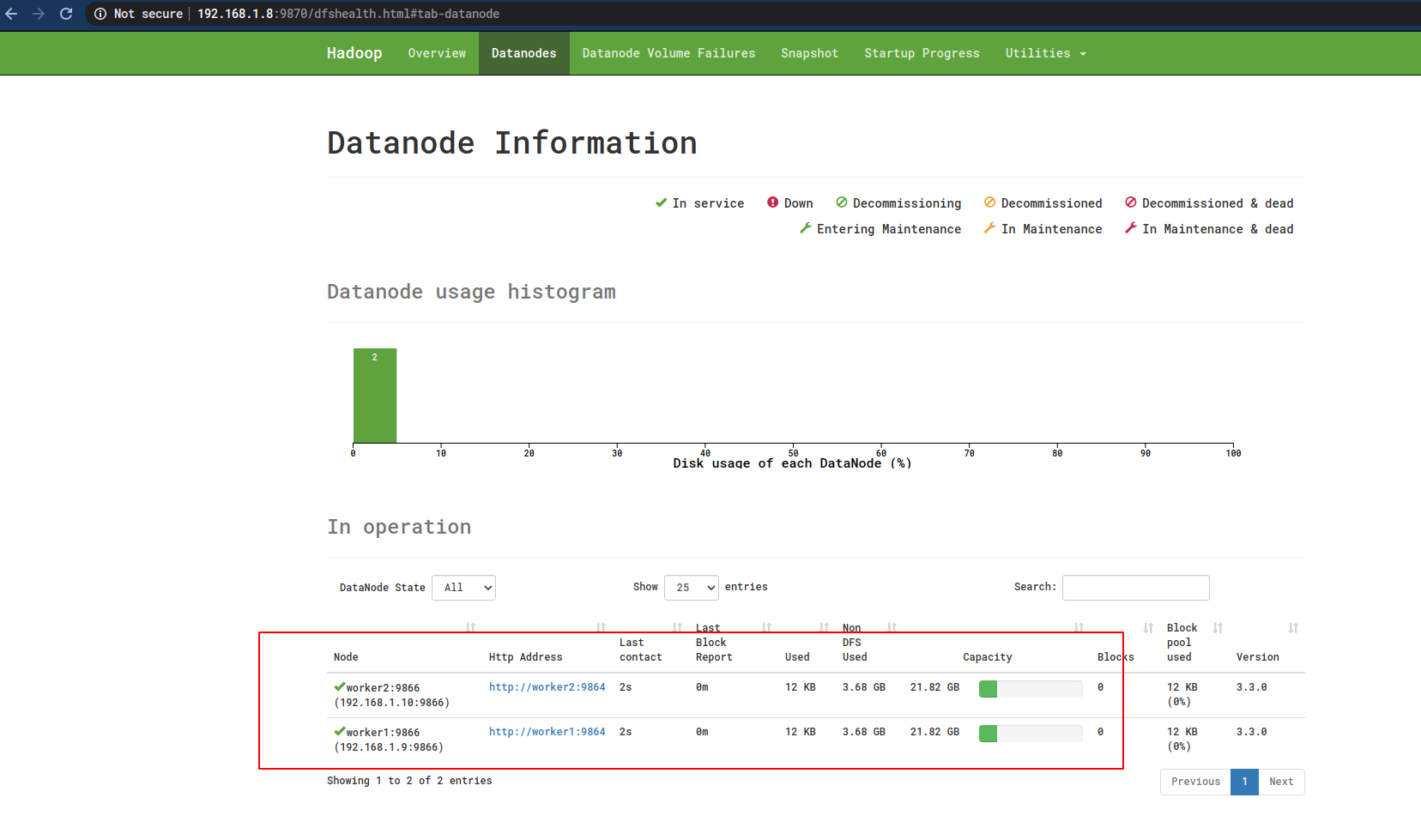
11 配置YARN
11.1 YARN配置
在两个Worker节点中修改/usr/local/hadoop/etc/hadoop/yarn-site.xml:
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
11.2 开启YARN
Master节点中开启YARN:
cd /usr/local/hadoop
sbin/start-yarn.sh
同时开放8088端口为下面的测试做准备:
sudo firewall-cmd --add-port=8088/tcp --permanent
sudo firewall-cmd --reload
11.3 测试
浏览器输入:
master:8088
# 或
# 192.168.1.8:8088
应该就可以访问如下页面了:
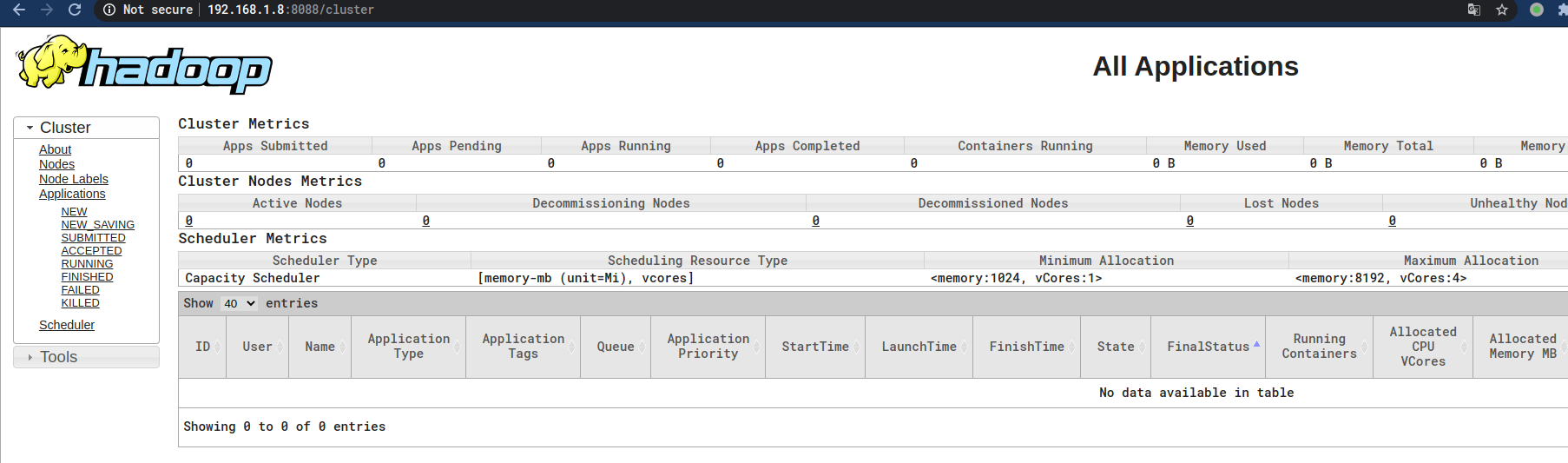
同样道理没有看到Worker节点,查看Worker节点的日志,发现也是端口的问题:
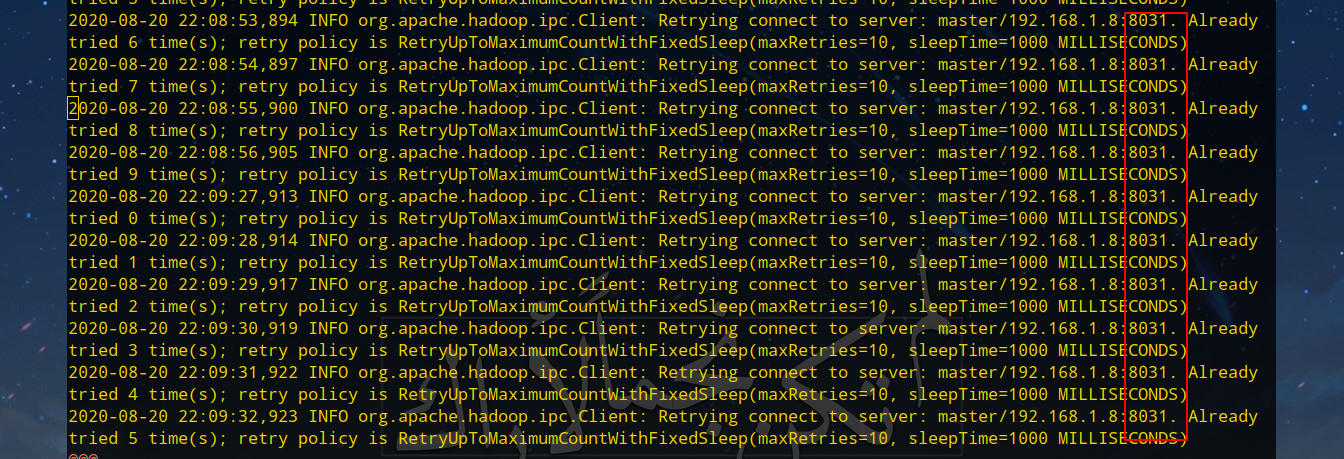
Master节点先关闭YARN,开放8031端口,并重启YARN:
/usr/local/hadoop/sbin/stop-yarn.sh
sudo firewall-cmd --add-port=8031/tcp --permanent
sudo firewall-cmd --reload
/usr/local/hadoop/sbin/start-yarn.sh
再次访问:
master:8088
# 或
# 192.168.1.8:8088
就可以看到Worker节点了:
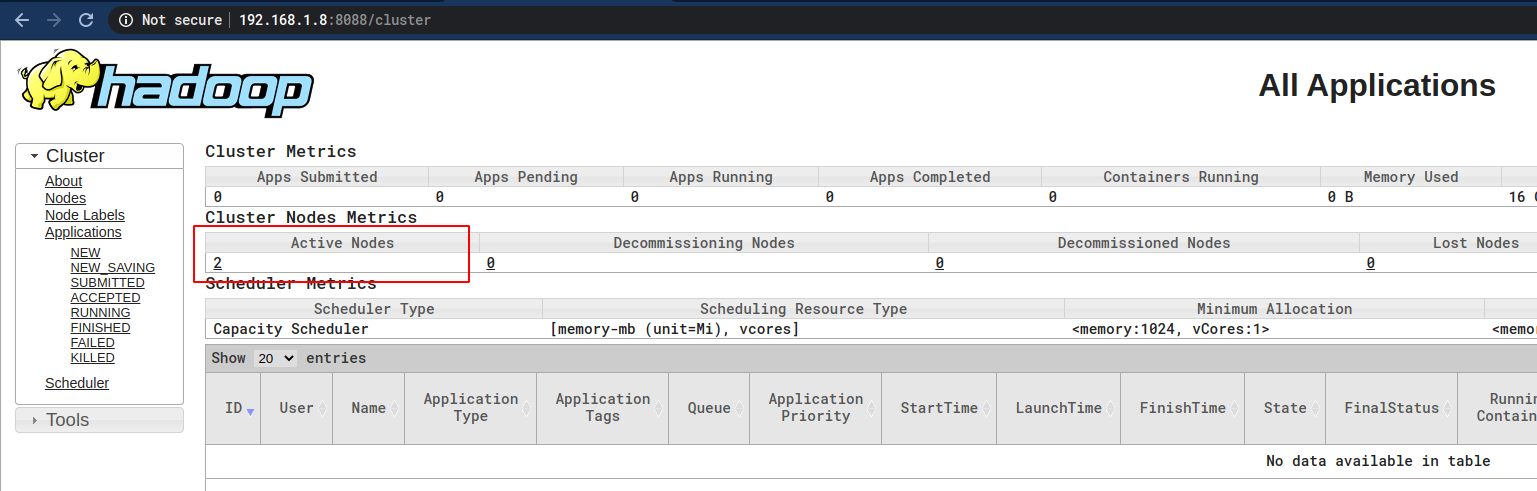
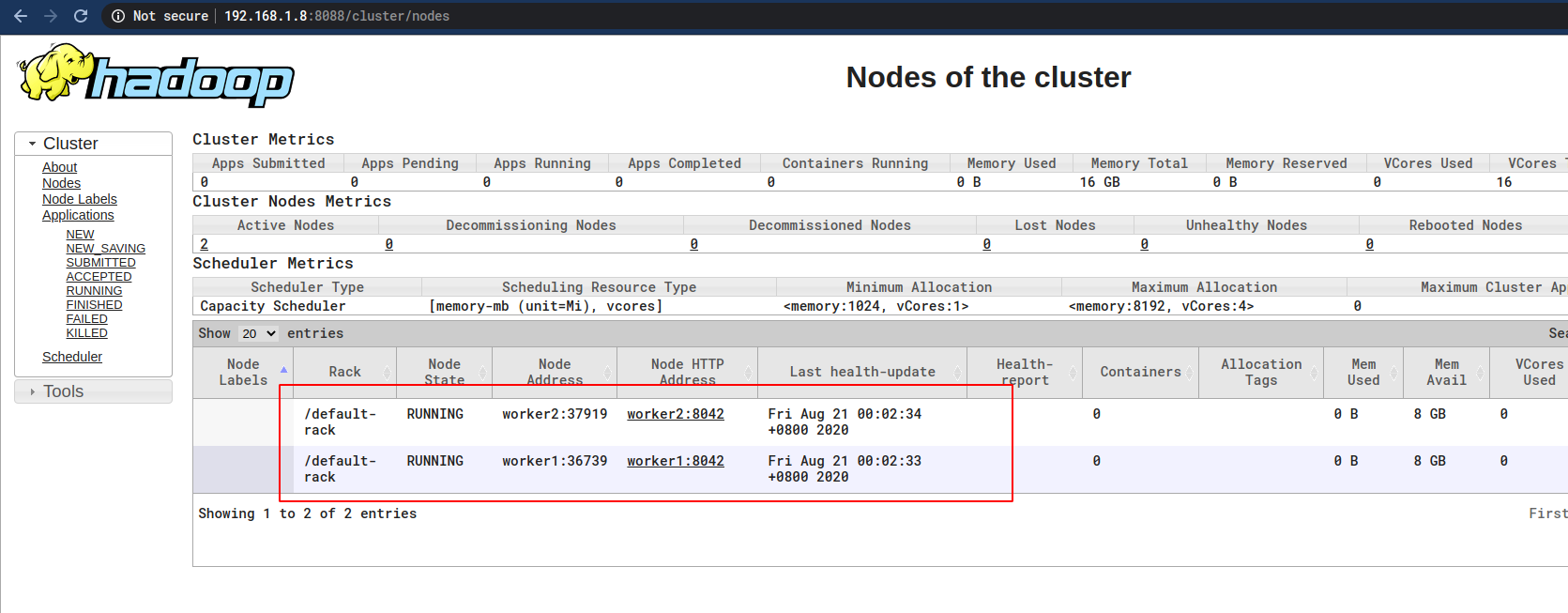
至此,虚拟机组成Hadoop集群正式搭建完成。
12 参考
- CSDN-GitChat·大数据 | 史上最详细的Hadoop环境搭建
- How To Set Up a Hadoop 3.2.1 Multi-Node Cluster on Ubuntu 18.04 (2 Nodes)
- How to Install and Set Up a 3-Node Hadoop Cluster
- CSDN-virtualBox实现主机和虚拟机相互ping通,配置静态IP地址
Hadoop完整搭建过程(三):完全分布模式(虚拟机)的更多相关文章
- 本地+分布式Hadoop完整搭建过程
1 概述 Hadoop在大数据技术体系中极为重要,被誉为是改变世界的7个Java项目之一(剩下6个是Junit.Eclipse.Spring.Solr.HudsonAndJenkins.Android ...
- Hadoop完整搭建过程(二):伪分布模式
1 伪分布模式 伪分布模式是运行在单个节点以及多个Java进程上的模式.相比起本地模式,需要进行更多配置文件的设置以及ssh.YARN相关设置. 2 Hadoop配置文件 修改Hadoop安装目录下的 ...
- Hadoop完整搭建过程(四):完全分布模式(服务器)
1 概述 上一篇文章介绍了如何使用虚拟机搭建集群,到了这篇文章就是实战了,使用真实的三台不同服务器进行Hadoop集群的搭建.具体步骤其实与虚拟机的差不多,但是由于安全组以及端口等等一些列的问题,会与 ...
- Hadoop完整搭建过程(一):本地模式
1 本地模式 本地模式是最简单的模式,所有模块都运行在一个JVM进程中,使用本地文件系统而不是HDFS. 本地模式主要是用于本地开发过程中的运行调试用,下载后的Hadoop不需要设置默认就是本地模式. ...
- 转载——Asp.Net MVC+EF+三层架构的完整搭建过程
转载http://www.cnblogs.com/zzqvq/p/5816091.html Asp.Net MVC+EF+三层架构的完整搭建过程 架构图: 使用的数据库: 一张公司的员工信息表,测试数 ...
- Hadoop环境搭建|第三篇:spark环境搭建
一.环境搭建 1.1.上传spark安装包 创建文件夹用于存放spark安装文件命令:mkdir spark 1.2.解压spark安装包 命令:tar -zxvf spark-2.1.0-bin-h ...
- Hadoop环境搭建过程中遇到的问题以及解决方法
1.启动hadoop之前,ssh免密登录slave主机正常,使用命令start-all.sh启动hadoop时,需要输入slave主机的密码,说明ssh文件权限有问题,需要执行以下操作: 1)进入.s ...
- Asp.Net MVC+EF+三层架构的完整搭建过程
架构图: 使用的数据库: 一张公司的员工信息表,测试数据 解决方案项目设计: 1.新建一个空白解决方案名称为Company 2.在该解决方案下,新建解决方案文件夹(UI,BLL,DAL,Model) ...
- Hadoop完全分布式搭建过程中遇到的问题小结
前一段时间,终于抽出了点时间,在自己本地机器上尝试搭建完全分布式Hadoop集群环境,也是借助网络上虾皮的Hadoop开发指南系列书籍一步步搭建起来的,在这里仅代表hadoop初学者向虾皮表示衷心的感 ...
随机推荐
- HTTP/1.1 有点慢,我想优化下!
问你一句:「你知道 HTTP/1.1 该如何优化吗?」 我想你第一时间想到的是,使用 KeepAlive 将 HTTP/1.1 从短连接改成长链接. 这个确实是一个优化的手段,它是从底层的传输层这一方 ...
- http server源码解析
本文主要过下http生成服务和处理请求的主要流程,其他功能并未涉及. 使用例子 const http = require('http'); http.createServer((req, res) = ...
- PHP中间件
定义 首先什么是php的中间件? 根据zend-framework中的定义: 所谓中间件是指提供在请求和响应之间的,能够截获请求,并在其基础上进行逻辑处理,与此同时能够完成请求的响应或传递到下一个中间 ...
- 前端问题录——在导入模块时使用'@'时提示"Modile is not installed"
前情提要 为了尽可能解决引用其他模块时路径过长的问题,通常会在 vue.config.js 文件中为 src 目录配置一个别名 '@' configureWebpack: { resolve: { a ...
- 如何用Eggjs从零开始开发一个项目(1)
前言 "纸上得来终觉浅,绝知此事要躬行."虽然node一直在断断续续地学,但总是东一榔头西一榔头的,没有一点系统,所以打算写一个项目来串联一下之前的学习成果. 为什么选择Eggjs ...
- 【转】理解Serverless
理解Serverless No silver bullet. - The Mythical Man-Month 许多年前,我们开发的软件还是C/S(客户端/服务器)和MVC(模型-试图-控制器)的形式 ...
- 最近没事DIY了个6通道航模遥控器
在网上买了个外壳,挖空后换成自己的电路版. 开机后图: 液晶屏是320x240的,没有合适的贴纸,直接就这么用了 遥控器的内部电路有点乱哈,没办法,低成本就只能全靠跳线了 还好都能正常工作. 接收器也 ...
- Linux速通 大纲
1.Linux操作系统安装及初始化配置(熟悉) 2.Linux操作系统目录组成结构及文件级增删改查操作(重点) 3.Linux操作系统用户.权限管理(重点) 4.开源软件及Linux下软件包的管理(重 ...
- 精确率precession和召回率recall
假设有两类样本,A类和B类,我们要衡量分类器分类A的能力. 现在将所有样本输入分类器,分类器从中返回了一堆它认为属于A类的样本. 召回率:分类器认为属于A类的样本里,真正是A类的样本数,占样本集中所有 ...
- Chrome OS超便捷安装指南
Chrome OS是一款Google开发的基于PC的操作系统. Google Chrome OS是一款基于Linux的开源操作系统.Google在自己的官方博客表示,初期,这一操作系统将定位于上网本. ...