python 爬虫新手入门教程
python 爬虫新手教程
一、什么是爬虫
爬虫就是把一个网站里的内容读取下来
这里我们就要学习一个知识
我们看到的网页是有一种叫HTML的语言编写的
他可以给文字显示不同的样式
如:<p>hello</p> 就会显示段落:hello
二、如何获取网页的内容
一般爬虫不会把网页内容爬下来
而是把网页源代码爬下来
就好比说:hello 会爬到 <p>hello</p>
如果要在浏览器上看源代码
只需在网页上右键点击 选择查看网页源代码即可
那么怎么用python把源代码爬下来呢?
这是要下载一个模块
在cmd里输入:
pip install requests
然后就可以用模块requests爬网页了
import requests # 导入模块 url = 'https://sina.com.cn' # 要爬的网址
html = requests.get(url) # 获取网页源代码
print(html.text) # 输出 注:需要text函数来返回源代码
输出:
细心的人可以看到后面的代码有编码问题

要把代码转成utf-8中文编码
import requests url = 'https://sina.com.cn'
html = requests.get(url)
html.encoding = 'utf-8' # 将编码设为utf-8中文编码
print(html.text)
输出

三、分析源代码
最后要在源代码中筛选出我们要的数据
需要用到模块 lxml
在cmd里输入:
pip install lxml
然后就要使用lxml来筛选数据
import requests
from lxml import etree url = 'https://sina.com.cn'
html = requests.get(url)
html.encoding = 'utf-8'
element = etree.HTML(html.text) # 获取html
result = element.xpath('//a/text()') # 进行筛选 for i in result:
print(i) # 输出
输出:

其中核心语句是
result = element.xpath('//a/text()')
而 //a/text() 的意思是获取所以的a标签的值
而常用的xpath语法如下
nodename 选取此节点的所有子节点
/ 从当前节点选取直接子节点
// 从当前节点选取子孙节点
. 选取当前节点
.. 选取当前节点的父节点
@ 选取属性
* 通配符,选择所有元素节点与元素名
@* 选取所有属性
[@attrib] 选取具有给定属性的所有元素
[@attrib='value'] 选取给定属性具有给定值的所有元素
[tag] 选取所有具有指定元素的直接子节点
[tag='text'] 选取所有具有指定元素并且文本内容是text节点
四、筛选实例
如果要在sina.com.cn读取部分新闻
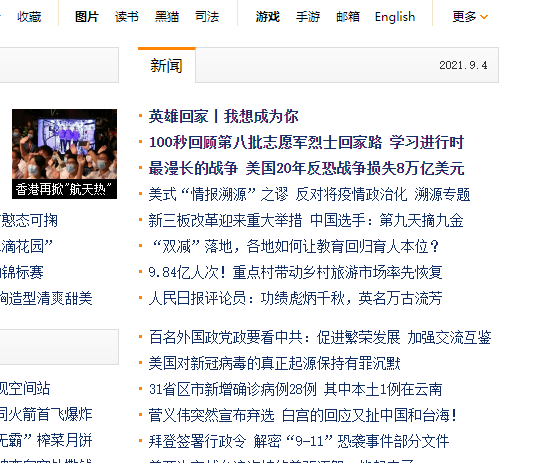
那么要在键盘上按下F12
点左上角的按钮
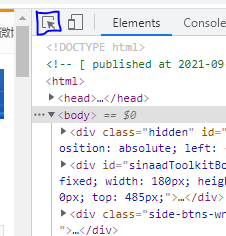
鼠标悬停在新闻上再点击
在代码栏中找新闻
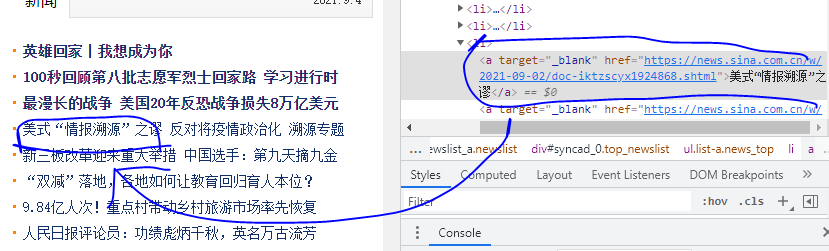
再找到所有新闻的父元素
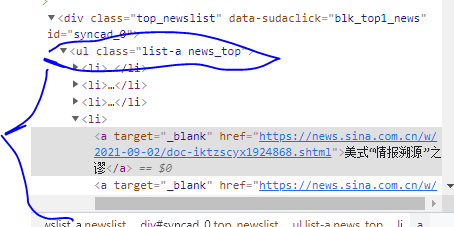
这里可以看到ul的class为list-a news_top
在python中写:
import requests
from lxml import etree url = 'https://sina.com.cn'
html = requests.get(url)
html.encoding = 'utf-8'
element = etree.HTML(html.text)
result = element.xpath('//ul[@class="list-a news_top"]//a/text()') # 进行筛选 for i in result:
print(i)
输出

python 爬虫新手入门教程的更多相关文章
- Python爬虫框架Scrapy教程(1)—入门
最近实验室的项目中有一个需求是这样的,需要爬取若干个(数目不小)网站发布的文章元数据(标题.时间.正文等).问题是这些网站都很老旧和小众,当然也不可能遵守 Microdata 这类标准.这时候所有网页 ...
- 《Python爬虫学习系列教程》学习笔记
http://cuiqingcai.com/1052.html 大家好哈,我呢最近在学习Python爬虫,感觉非常有意思,真的让生活可以方便很多.学习过程中我把一些学习的笔记总结下来,还记录了一些自己 ...
- python爬虫如何入门
学爬虫是循序渐进的过程,作为零基础小白,大体上可分为三个阶段,第一阶段是入门,掌握必备的基础知识,第二阶段是模仿,跟着别人的爬虫代码学,弄懂每一行代码,第三阶段是自己动手,这个阶段你开始有自己的解题思 ...
- [转]《Python爬虫学习系列教程》
<Python爬虫学习系列教程>学习笔记 http://cuiqingcai.com/1052.html 大家好哈,我呢最近在学习Python爬虫,感觉非常有意思,真的让生活可以方便很多. ...
- 安卓自动化测试(2)Robotium环境搭建与新手入门教程
Robotium环境搭建与新手入门教程 准备工具:Robotium资料下载 知识准备: java基础知识,如基本的数据结构.语法结构.类.继承等 对Android系统较为熟悉,了解四大组件,会编写简单 ...
- Xorboot-UEFI新手入门教程
Xorboot-UEFI新手入门教程 Xorboot-UEFI是一款UEFI下轻量级的图形化多系统引导程序,pauly于2014年国庆节期间发布了预览版.搜了下论坛,关于Xorboot- ...
- python爬虫-基础入门-python爬虫突破封锁
python爬虫-基础入门-python爬虫突破封锁 >> 相关概念 >> request概念:是从客户端向服务器发出请求,包括用户提交的信息及客户端的一些信息.客户端可通过H ...
- python爬虫-基础入门-爬取整个网站《3》
python爬虫-基础入门-爬取整个网站<3> 描述: 前两章粗略的讲述了python2.python3爬取整个网站,这章节简单的记录一下python2.python3的区别 python ...
- python爬虫-基础入门-爬取整个网站《2》
python爬虫-基础入门-爬取整个网站<2> 描述: 开场白已在<python爬虫-基础入门-爬取整个网站<1>>中描述过了,这里不在描述,只附上 python3 ...
随机推荐
- 如何在 Matlab 中绘制带箭头的坐标系
如何在 Matlab 中绘制带箭头的坐标系 如何在 Matlab 中绘制带箭头的坐标系 实现原理 演示效果 完整代码 实现原理 使用 matlab 的绘制函数时,默认设置为一个方框形的坐标系, 图1 ...
- WPF基础:Dispatcher介绍
Disaptcher作用 不管是WinForm应用程序还是WPF应用程序,实际上都是一个进程,一个进程可以包含多个线程,其中有一个是主线程,其余的是子线程.在WPF或WinForm应用程序中,主线程负 ...
- Mysql数据库优化(1)
1.尽量不要留null select id from t where num is null,可以,但尽量不要留null,null也占空间:使用not null填充数据库,像varchar(100)这 ...
- systemd.service — 服务单元配置
转载:http://www.jinbuguo.com/systemd/systemd.service.html 名称 systemd.service - 服务单元配置 大纲 service.servi ...
- SQL 练习23
查询男生.女生人数 SELECT Ssex,COUNT(Ssex) 人数 from Student GROUP BY Ssex
- 题解 math
传送门 赛时用一个奇怪的方法过掉了 首先\(b_i\)的有效范围是\([0, k-1]\) 发现不同的\(a_i*b_i\)会有很多重的 考虑把\(a_i\%k\),然后由小到大排序 按顺序扫,如果某 ...
- 黑马JVM教程——自学笔记(三)
四.类加载与字节码技术 4.1.类文件结构 首先获得.class字节码文件 方法: 在文本文档里写入java代码(文件名与类名一致),将文件类型改为.java java终端中,执行javac X:.. ...
- idea的properties文件乱码问题解决
设置编码格式: File============>Settings,打开设置后,设置成下面的即可解决:
- Git进行clone的时候,报错:remote: HTTP Basic: Access denied fatal: Authentication failed for ...
先执行: git config --system --unset credential.helper 原因:用户名或者密码错: 会提示让重新输入用户名和密码,输入正确的用户名和密码即可! 这样以后发现 ...
- Asp.NetCore 中Aop的应用
前言 其实好多项目中,做一些数据拦截.数据缓存都有Aop的概念,只是实现方式不一样:之前大家可能都会利用过滤器来实现Aop的功能,如果是Asp.NetCore的话,也可能会使用中间件: 而这种实现方式 ...