文本处理命令(sort+uniq+cut+tr+wc)+三剑客之sed
文本处理命令+三剑客之sed
一、文本处理命令
1、排序命令 sort
1、排序命令 sort
用于将文件内容加以排序,默认以'''每一行第一个字符'''来判定顺序
举例: cat a.txt | sort
PS:空行会排在第一行,即最前面。
创建一个num.txt,里面添加各种数字做举例使用。
无参数:# 依照每一行第一个字符来判定顺序
-n # 依照数值的大小排序 [root@linux ~]# cat num.txt | sort -n
-r # 以相反的顺序来排序 [root@linux ~]# cat num.txt | sort -r
-k # 以某列字符串进行排序 [root@linux ~]# cat num.txt | sort -nk2
文本内必须有多列内容(并非以第二个字符为第二列,而是对齐的第二列字符串)
-t # 指定分割符,默认是以空格为分隔符 [root@linux ~]# cat num.txt | sort -nr -k2 -t ' '
cat 3.txt | sort -n -r -k3 -t '|'
知识储备:1,% s/ /|/g # 将空格替换为|管道符(在vim编辑里使用)
解释:
1,% :意思是 1到所有 的数据
2、检查/删除命令 uniq
用于检查及删除文本文件中重复出现的行列,一般与 sort 命令结合使用
-c # 在每列旁边显示该行重复出现的次数。
某一行出现2次,这一行前面的号码就是2 [root@linux ~]# cat num.txt | uniq -c
-d # 仅显示重复出现的行列。
(c参数:前面出现次数) [root@linux ~]# cat num.txt | uniq -dc
结合 sort 使用(排序): [root@linux ~]# cat num.txt | sort -n | uniq -dc
-u # 仅显示出一次的行列。
(c参数:空行也会显示1) [root@linux ~]# cat num.txt | uniq -cu
3、 cut 显示特定部分命令
cut命令用来显示行中的指定部分,删除文件中指定字段
-d # 指定字段的分隔符,默认的字段分隔符为"TAB";
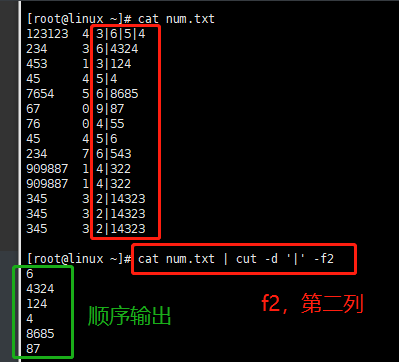
cut -d后面指定一个分隔符 >>> [root@linux ~]# cat num.txt | cut -d '|' -f2
-f # 显示指定字段的内容;
-f2 显示以分隔符'|'分开的第二列数据
可以结合 sort 使用:
[root@linux ~]# cat num.txt | sort -nrk1 | cut -d '|' -f2
结合 uniq 使用:
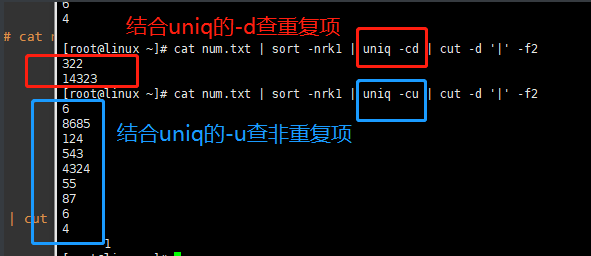
uniq -d [root@linux ~]# cat num.txt | sort -nrk1 | uniq -cd | cut -d '|' -f2
uniq -u [root@linux ~]# cat num.txt | sort -nrk1 | uniq -cu | cut -d '|' -f2
被分割后,可能会不显示 -c 参数的重复行数
sort命令和cut命令连用:

4、 替换或删除命令 tr
不添加参数替换(存在问题):
将前面的数据 修改为 后面的数据:[root@linux ~]# cat num.txt | tr 123123 696969
替换原理:一个字符一个字符的替换,即1换成6,再2换成9,再3换成6...以此类推至结束。
-d # 删除字符
[root@linux ~]# cat num.txt | tr -d '76'
解释:把这个文本中,每一行带有的7和6都删除,非7非6的其他数据不进行操作。
5、统计 计算数字命令 wc
-c # 统计文件的Bytes数; [root@linux ~]# cat ceshi.txt | wc -c
-l # 统计文件的行数; [root@linux ~]# cat ceshi.txt | wc -l
-w # 统计文件中单词的个数,默认以空白字符做为分隔符 [root@linux ~]# cat ceshi.txt | wc -w
'''PS:默认以空白字符做为分隔符'''
注:在Linux系统中,一段连续的数字或字母组合为一个词。
举例:123 456>>> 数字123与数字456之间有一个空格' '将其分开,所以是两个单词。
举例:123!456>>> 数字123与数字456之间有一个叹号'!',只有空格分割才有效,所以是一个单词。
二、linux三剑客之sed
sed是linux中,流媒体编辑器。
1、sed的格式
sed [参数] '处理规则' [操作对象]
grep : 过滤文本
sed : 修改文本
awk : 处理文本
2、参数
-e : 允许多项编辑
分别删除第3行和第4行 [root@linux ~]# sed -e '3d' -e '4d' num.txt
-n : 取消默认输出
(就是我只想打印第一行,其他的不打印,加命令-n,就只显示第一行内容)
[root@linux ~]# sed -n '5p' num.txt
-i : 就地编辑
'''(只有此命令是编辑之后就生效了,因为直接修改了源文件)''' [root@linux ~]# sed -i '5p' num.txt
-r : 支持拓展正则
(就是临时可以使用正则表达式的规则,在两个/之间。) [root@linux ~]# sed -r '/123/d' num.txt
-f : 指定sed匹配规则脚本文件
(将正则写在另一个文件里 1.txt,进行调用) [root@linux ~]# sed -f 1.txt num.txt
3、定位(# 四个之中最重要)
1、数字定位法
指定行号。
sed '3d' 4.txt >>> 指删除第3行内容 [root@linux ~]# sed '3d' 4.txt
sed '2,3d' 4.txt >>> 指删除第2到第3行内容 [root@linux ~]# sed '2,3d' 4.txt
2、正则定位法
指定正则定位。
sed '/^g/d' 2.txt >>> 指将以g开头的本行内容都删除
举例:[root@linux ~]# sed '/123/d' num.txt
3、数字和正则定位法
sed '3,/^g/d' 2.txt >>> 从第3行到以g开头的内容删除
举例:[root@linux ~]# sed '1,/^45/d' num.txt
(如果下面还有以 45开头的,不进行删除)
4、正则正则定位法
sed '/^g/,/^j/d' 2.txt >>> 以g开头的行 到以j开头的行删除
举例:[root@linux ~]# sed '/^23/,/^90/d' num.txt
4、sed的编辑模式(# 重要程度次之)
* 所有内容都是在正则中进行,即//之中进行。
d :删除
p :打印
'''如果选第5行打印,则在第5行基础上再复制1行,如果加命令 -n后,只显示打印的第5行,其他不显示。
a : 在当前行后添加一行或多行
sed '2axxx' 4.txt >>> 在第2行通过a命令模式将内容 xxx添加到num.txt中
举例:[root@linux ~]# sed '2aQQQQQQ' num.txt
c :用新文本修改(替换)当前行
sed '2cxxx' 4.txt >>> 在第2行修改文本整体修改为,或者替换为xxx,无论这一行有多少内容。
举例:[root@linux ~]# sed '2cQQQQQQ' num.txt
i : 在当前行之前,插入文本(#单独使用时)
sed '2ixxx' 4.txt >>> 在第2行之前插入一行,内容为xxx
举例:[root@linux ~]# sed '2iQQQQQQ' num.txt
r : 在文件中读内容
sed '2r r.txt' 2.txt >>> 将文件r.txt中的内容 读到第2行的下一行
举例:[root@linux ~]# sed '2r 1.txt' num.txt
w : 将指定行写入文件
sed '2w 1.txt' 2.txt >>> 将 第2行的内容 写入到1.txt中,并且会覆盖1.txt中的内容
举例:[root@linux ~]# sed '2w 1.txt' num.txt
y : 将字符转换成另一个字符
sed '2y/fa/FA/' 2.txt >>> 将第2行的f和a,依次各自替换成F和A。(这里是字符,不是字符串)
举例:[root@linux ~]# sed '2y/fa/FA/' 2.txt
s : 将字符串转换成另一个字符串(每一行只替换一次) s 命令需放在前面
sed 's/11/22/' 6.txt >>> 将所有含有的11,替换成且只替换一次成22
举例:[root@linux ~]# sed 's/123/333/' num.txt
g : 全部执行 (g是没有替换功能的,只是将前面的s功能应用到整行里面去了)
sed 's/11/22/g' 6.txt >>> 将所有含有的11,都替换成22
举例:[root@linux ~]# sed 's/123/333/g' num.txt
i : 忽略大小写(跟 s 模式一起使用时)
[root@linux ~]# sed 's/f/abc/gi' num.txt
& :代表前面匹配到的内容
三、案例练习
1、将nginx.conf中的注释行全部去掉
[root@localhost ~]# sed '/^ *#/d' /etc/nginx/nginx.conf
'''将以空格和其他内容开头,再加上#井号键的内容删除
2、将nginx.conf中每一行之前增加注释
[root@localhost ~]# sed 's/.*/# &/g' /etc/nginx/nginx.conf
'''&符号,表示前面匹配到的内容,即(.*),相当于一个变量了,& = .* '''
3、要求一键修改本机的ip
192.168.15.100 ---> 192.168.15.101
172.16.1.100 ---> 172.16.1.101
sed -i 's#.100#.101#g' /etc/sysconfig/network-scripts/ifcfg-eth[01]
引号''内的# 警号 跟/斜杠作用一样,起到隔离作用
sed -i 's/.100/.101/g' /etc/sysconfig/network-scripts/ifcfg-eth[01]
sed -i -e 's/192.168.15.100/192.168.15.101/' -e 's/172.16.1.100/172.16.1.101/' /etc/sysconfig/network-scripts/ifcfg-eth[01]
4、将/etc/passwd中的root修改成ROOT
sed -i 's#root#ROOT#g' /etc/passwd
也可以将其写为:
sed -i 's/root/ROOT/g' /etc/passwd
文本处理命令(sort+uniq+cut+tr+wc)+三剑客之sed的更多相关文章
- 【转帖】linux sort,uniq,cut,wc,tr,xargs命令详解
linux sort,uniq,cut,wc,tr,xargs命令详解 http://embeddedlinux.org.cn/emb-linux/entry-level/201607/21-5550 ...
- linux sort,uniq,cut,wc命令详解
linux sort,uniq,cut,wc命令详解 sort sort 命令对 File 参数指定的文件中的行排序,并将结果写到标准输出.如果 File 参数指定多个文件,那么 sort 命令将这些 ...
- (转)linux sort,uniq,cut,wc命令详解
linux sort,uniq,cut,wc命令详解 sort sort 命令对 File 参数指定的文件中的行排序,并将结果写到标准输出.如果 File 参数指定多个文件,那么 sort 命令将这些 ...
- linux sort,uniq,cut,wc,tr命令详解
sort是在Linux里非常常用的一个命令,对指定文件进行排序.去除重复的行 sort 命令对 File 参数指定的文件中的行排序,并将结果写到标准输出.如果 File 参数指定多个文件,那么 sor ...
- 文件上传下载,命令之wget / curl / which / sort / uniq / cut / wc /tr /sed
目录 命令 1.文件的上传下载 2.从外网下载文件wget 3.curl文件下载 4.查找命令which 5.字符处理命令-排序sort 6.字符处理-去重uniq 7.字符处理-截取cut 8.字符 ...
- [转]linux sort,uniq,cut,wc命令详解
sort sort 命令对 File 参数指定的文件中的行排序,并将结果写到标准输出.如果 File 参数指定多个文件,那么 sort 命令将这些文件连接起来,并当作一个文件进行排序. sort语法 ...
- Linux之 sort,uniq,cut,wc命令详解
sort sort 命令对 File 参数指定的文件中的行排序,并将结果写到标准输出.如果 File 参数指定多个文件,那么 sort 命令将这些文件连接起来,并当作一个文件进行排序. sort语法 ...
- Ubuntu 14.10 下sort,uniq,cut,wc命令详解
sort sort 命令对 File 参数指定的文件中的行排序,并将结果写到标准输出.如果 File 参数指定多个文件,那么 sort 命令将这些文件连接起来,并当作一个文件进行排序. sort语法 ...
- linux sort,uniq,cut,wc命令详解 (转)
sort sort 命令对 File 参数指定的文件中的行排序,并将结果写到标准输出.如果 File 参数指定多个文件,那么 sort 命令将这些文件连接起来,并当作一个文件进行排序. sort语法 ...
随机推荐
- js 调用同级的 iframe 方法
有两个 iframe <iframe id="a"> <script> function food(a){ return a+1; } </scrip ...
- c# - 数据类型转换和控制台输入
1.使用c#自带的 Convert类转换数据类型 2.源码 using System; namespace ConsoleApp1.toValue { class excutejiecheng { s ...
- 转雅虎web前端网站优化 34条军规
雅虎给出了优化网站加载速度的34条法则(包括Yslow规则22条) 详细说明,下载转发 ponytail 的译文 1.Minimize HTTP Requests 减少HTTP请求 图片.css.sc ...
- 查询并导出表结构为Excel
应公司要求将数据库结构用表格形式来展示给客户,最开始我手工弄了两张表效率实在太低了,于是就想偷懒了,就去网上找了一段儿sql查询语句效率提高了70%一执行就出来了,导出查询结果剩下的就只需要调整一下e ...
- 使用.NET 6开发TodoList应用(29)——实现静态字符串本地化功能
系列导航及源代码 使用.NET 6开发TodoList应用文章索引 需求 在开发一些需要支持多种语言的应用程序时,我们需要根据切换的语言来对应展示一些静态的字符串字段,在本文中我们暂时不去讨论如何结合 ...
- Linux增加用户
Linux增加用户 注意一个不加-m不会出现家目录 sudo useradd Hans -m sudo passwd Hans sudo usermod -s /bin/bash Hans sudo ...
- 1010day-人口普查系统
1.xiugai.java package com.edu.ia; import java.io.IOException;import java.sql.SQLException; import ja ...
- cesium结合geoserver利用WFS服务实现图层删除(附源码下载)
前言 cesium 官网的api文档介绍地址cesium官网api,里面详细的介绍 cesium 各个类的介绍,还有就是在线例子:cesium 官网在线例子,这个也是学习 cesium 的好素材. 内 ...
- 猪齿鱼 Choerodon 的数据初始化设计解析
数智化效能平台猪齿鱼Choerodon 作为一个微服务框架,需要解决微服务数据初始化本身具有的问题和复杂性,同时也需要满足框架本身特有的数据初始化需求,下面为大家介绍一下这方面的设计思想和实现. 微服 ...
- 浅析Java中的线程池
Java中的线程池 几乎所有需要异步或并发执行任务的程序都可以使用线程池,开发过程中合理使用线程池能够带来以下三个好处: 降低资源消耗 提高响应速度 提高线程的可管理性 1. 线程池的实现原理 当我们 ...