Web安全-信息收集
信息收集
前言:在渗透测试过程中,信息收集是非常重要的一个环节,此环节的信息将影响到后续成功几率,掌握信息的多少将决定发现漏洞的机会的大小,换言之决定着是否能完成目标的测试任务。也就是说:渗透测试的思路就是从信息收集开始,你与大牛的差距也是这里开始的。
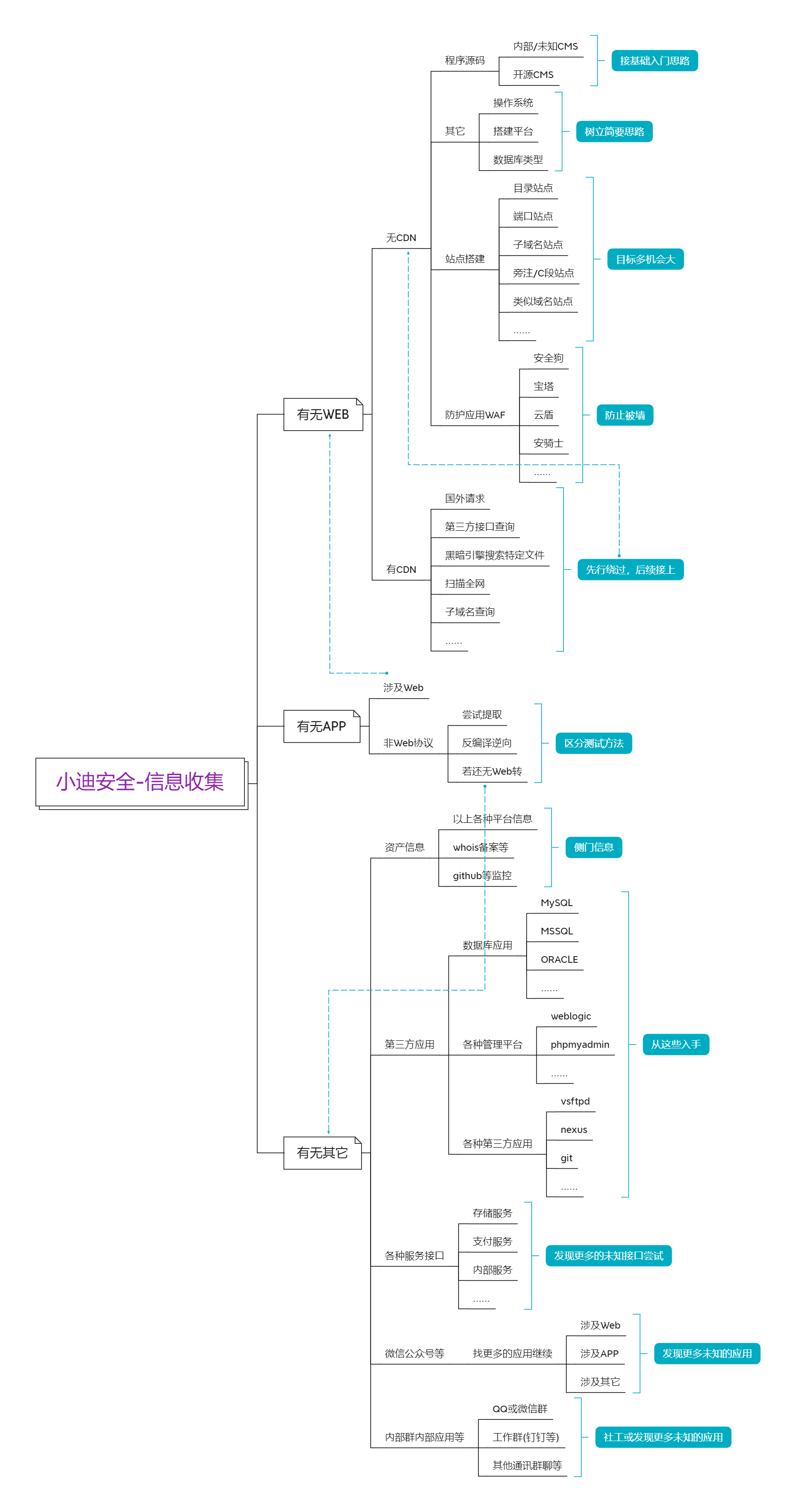
Part1:信息收集-架构、搭建、WAF等
# CMS识别技术
网上有现成的CMS识别平台
# 源码获取技术
# 架构信息获取
# 站点搭建分析
搭建习惯-目录型站点
搭建习惯-端口类站点
搭建习惯-子域名站点
搭建习惯-类似域名站点
搭建习惯-旁注[同服务器不同站点,又称同IP站点查询],C段站点[C段查询]
搭建习惯-搭建软件特征站点
# WAF 防护分析
什么是WAF应用?
如何快速识别WAF?
识别WAF对于安全测试的意义
案例演示:
▲sti.blcu-bbs-目录型站点分析
sti.blcu.edu.cn/ 和 sti.blcu.edu.cn/bbs 这两个站点的区别仅仅在于一个目录,任意一个出现问题就都得遭殃
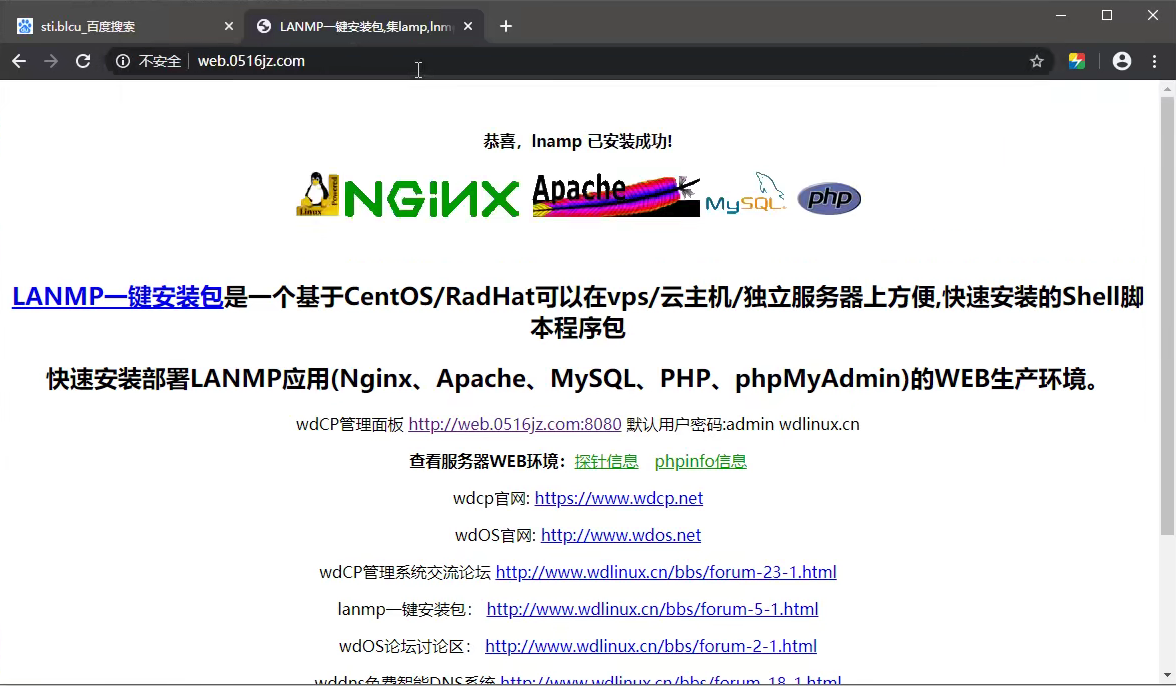
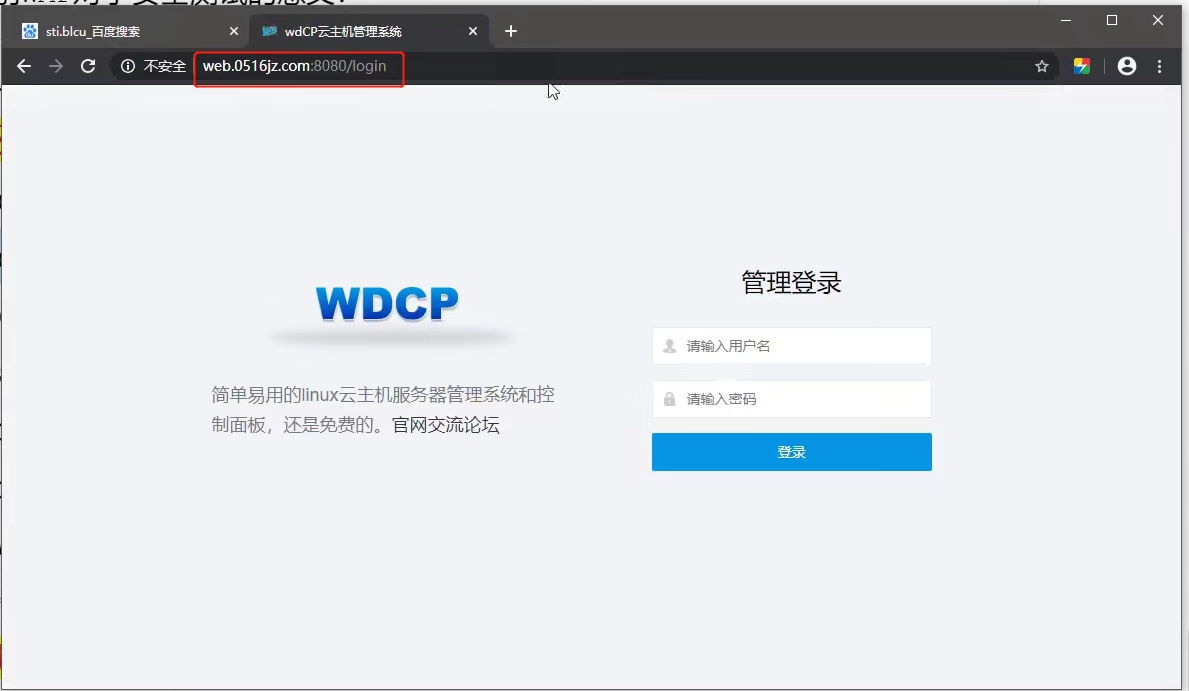
▲web.0516jz-8080-端口类站点分析
不同的端口对应不同的站点,但是归根到底他们两个还是在同一台服务器上,任意一个站点出现安全问题都会导致服务器出现安全问题。
▲goodlift-www.bbs-子域名两套 CMS
主站 www.goodlift.net 和子域名 bbs.goodlift.net 是用不同的CMS搭建的,这个时候就存在了一个问题,这两个网站就有可能不在同一台服务器上面。
▲jmlsd-cn.com.net等-各种常用域名后缀
▲weipan-qqyewu-查询靶场同服务器站点[同IP站点查询]
▲weipan-phpstudy-查询特定软件中间件等
我们用phpstudy搭建的在F12这里查看到的Server信息是一样的,我们就可以去佛法搜索Server信息,然后查到的就都是用phpstudy搭建的。【其它中间件也类似】
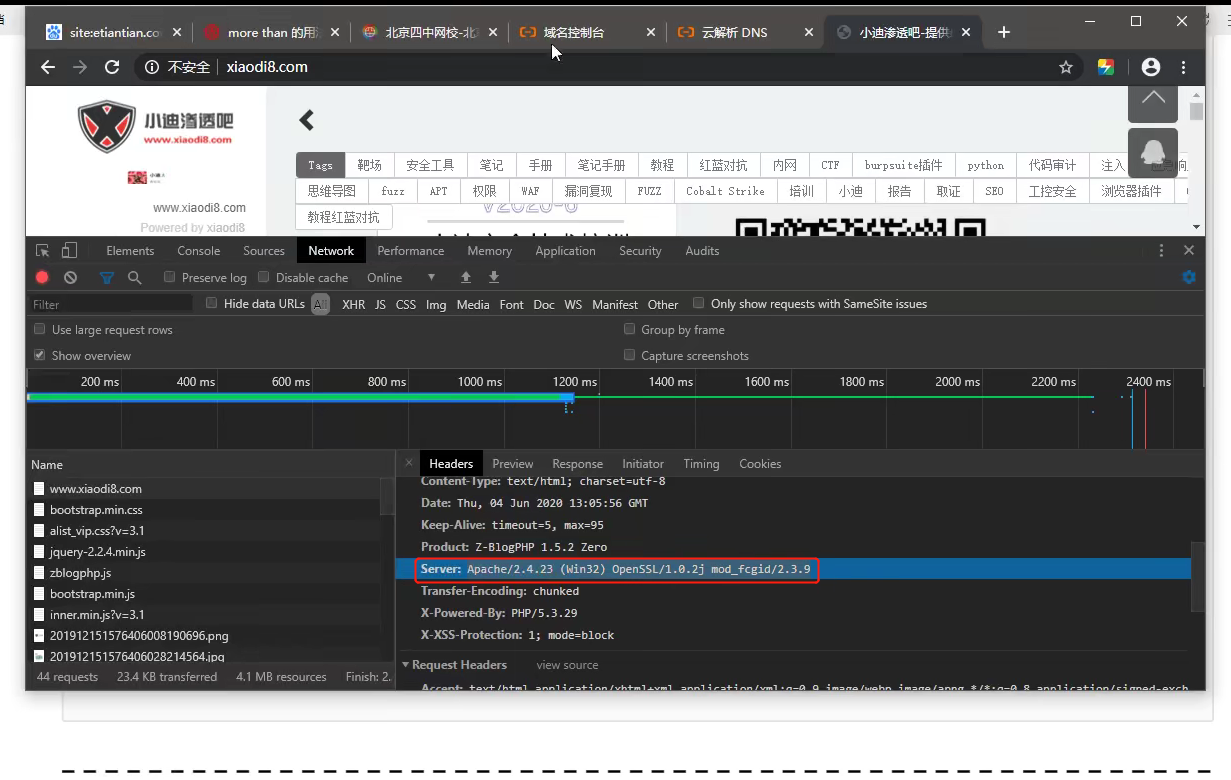
wafw00f-shodan(X-Powered-By: WAF)-147.92.47.120
识别WAF方法:
①按F12查询到数据包中出现 X-Powered-By: WAF 的,基本上就是有WAF
②用工具wafw00f
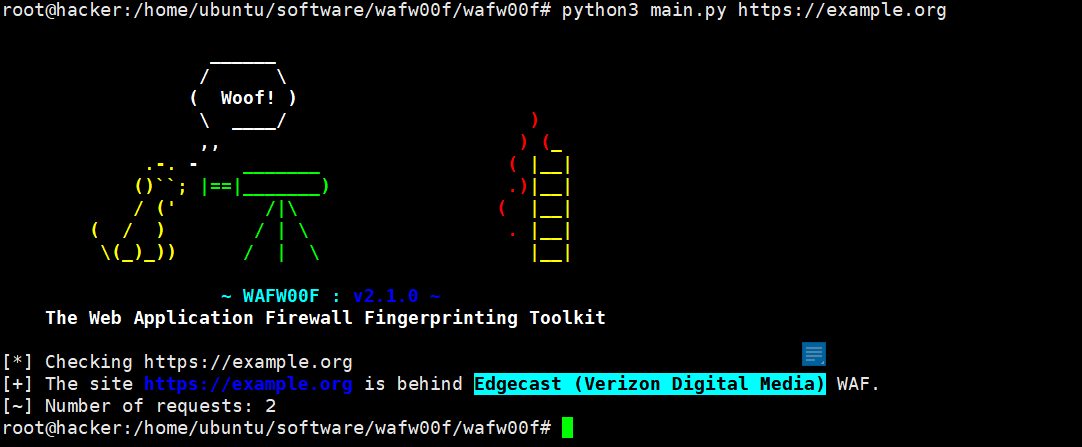
使用教程:https://www.cnblogs.com/qingchengzi/articles/13451885.html
涉及资源:
https://github.com/EnableSecurity/wafw00f
Part2:信息收集-APP及其他资产
前言:在安全测试中,若 Web无法取得进展,或者无WAF的情况下,我们需要借助APP或者其他资产再进行信息收集,从而开始后续渗透,那么其中的信息收集就尤为重要,接下来我们就用案例讲解试试吧。
# APP 提取一键反编译提取【工具:漏了个大洞】
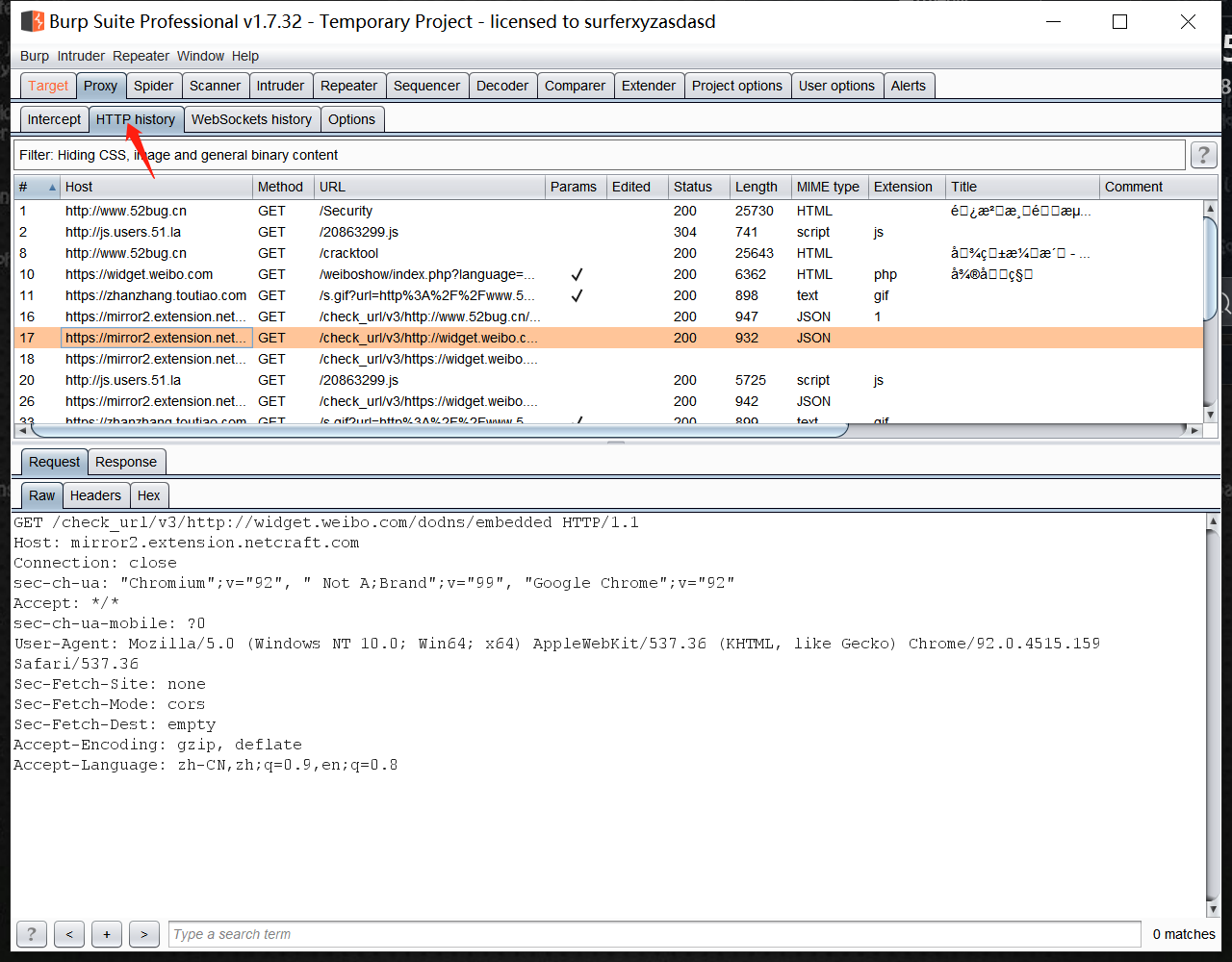
# APP 抓数据包进行工具配合【模拟器+Burp】
# 各种第三方应用相关探针技术
# 各种服务接口信息相关探针技术
案例演示:
APP 提取及抓包及后续配合
某APK一键提取反编译
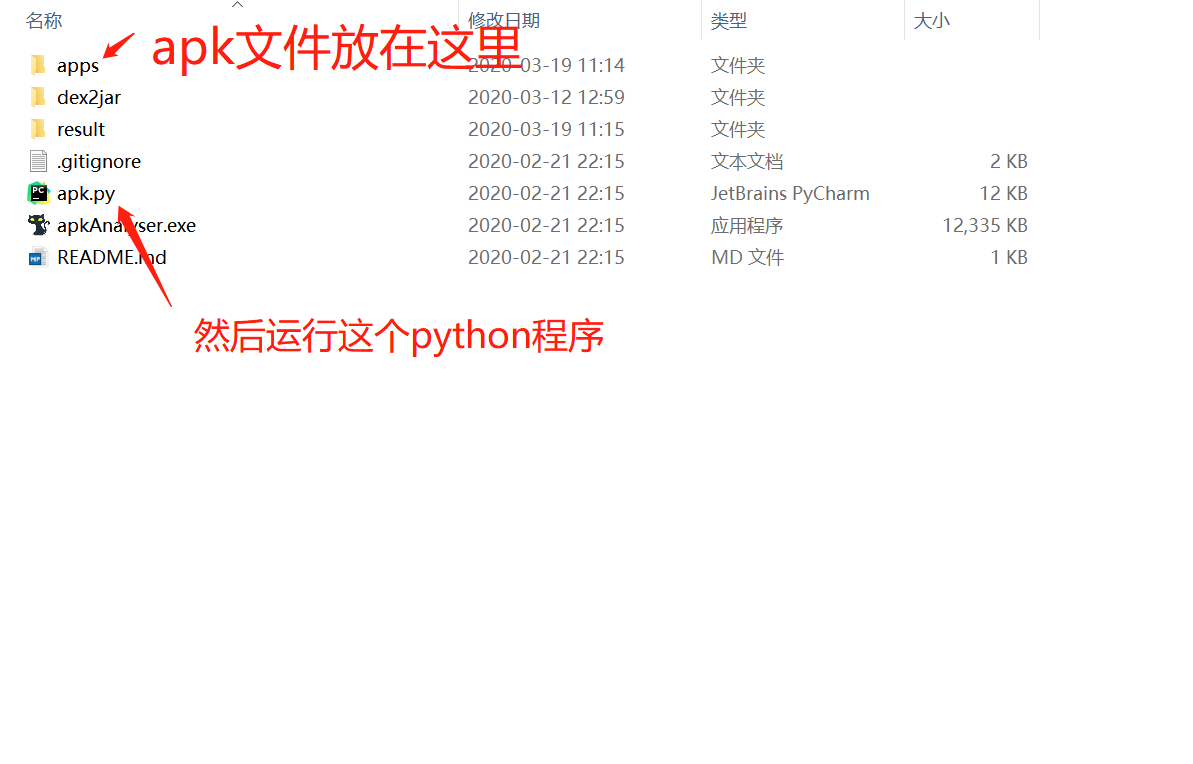
利用Burp历史抓更多URL
实际案例Web服务测试【https://www.caredaily.com/】

从网站表面看存在漏洞的可能性比较小,因为这个网站上面的功能都比较简单
那么我们接下来就从这5个方面开始进行信息收集
我们直接去fofa、shodan、zoomeye进行域名搜索
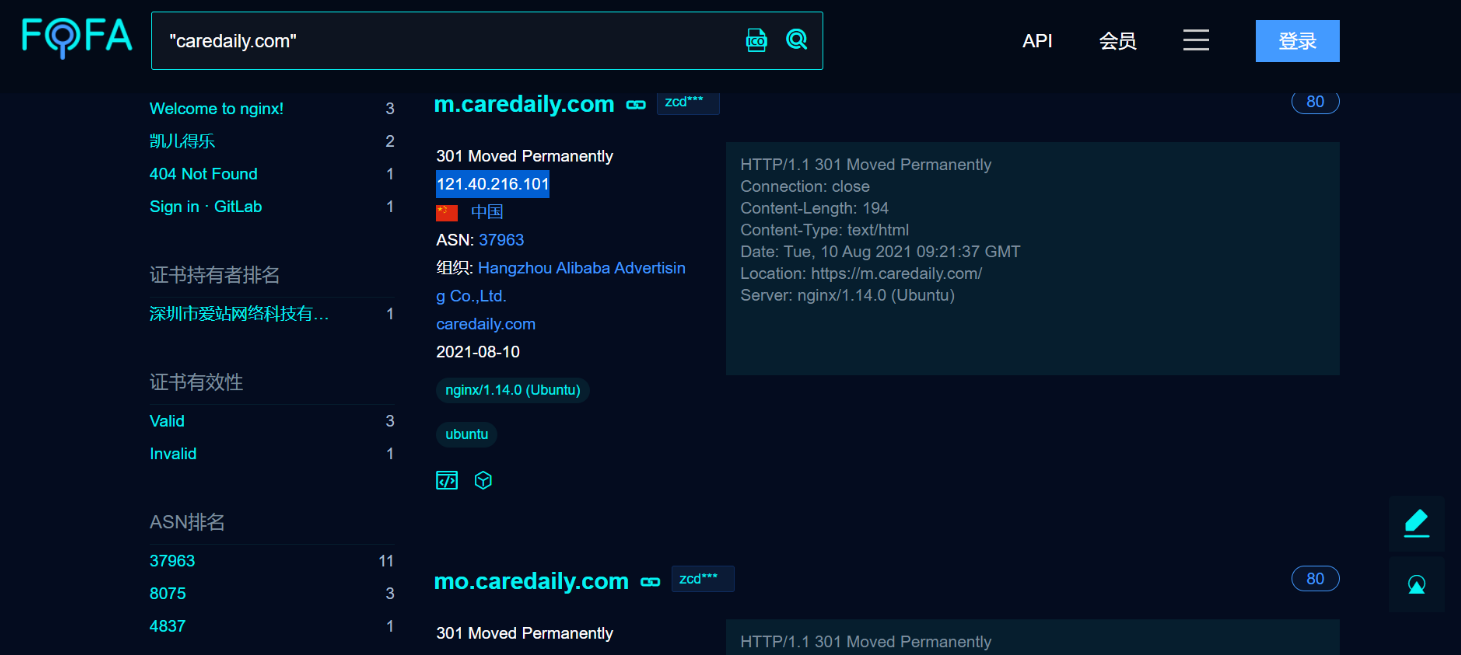
我们注意到这里8000端口出现了OpenSSH服务,我们就可以去搜对应版本存在的漏洞,去验证

我们又注意到他这27017开了MongoDB,那么就可能存在MongoDB数据库相关的漏洞,我们也可以去进行尝试

这个地方又可以成为一个攻击点。其他端口也类似,端口代表着服务,有服务就代表可能存在相应的服务的漏洞,我们就可以先记录下来,然后最后统一对各个点进行攻击。
我们还可以搜索它的目录站点、子域名站点、旁注/C段站点进一步扩大我们的攻击面【利用工具:7kbScan御剑扫描、Layer子域名挖掘机、同IP站点查询】
最后讲一下类似域名怎么找?
我们可以用接口查,第①步就是查找备案信息【需要VIP】
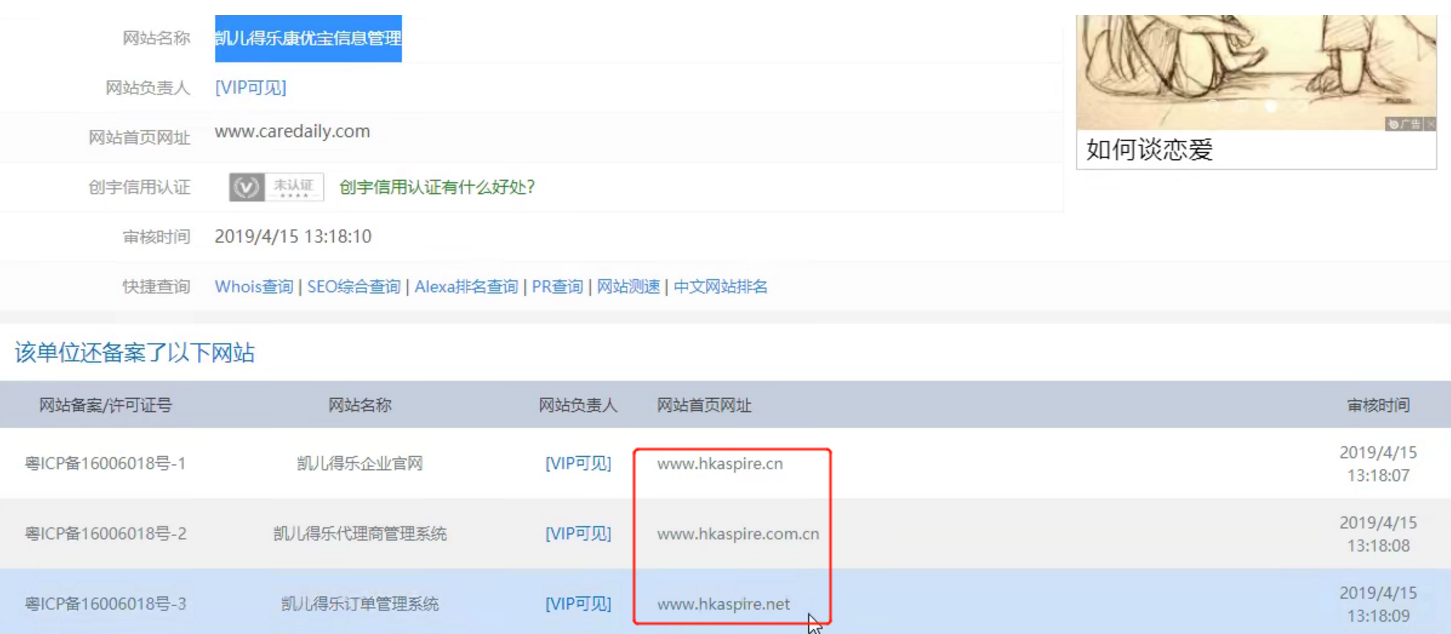
通过对备案公司的查询,我们可以查到该公司还注册了几个别的域名:
http://hkaspire.net/ 和 https://hkaspire.cn/
在 http://hkaspire.net/ 这个网站我们发现这里可以点击,点击之后跳转到一个新的页面 http://hkaspire.net:8080/login
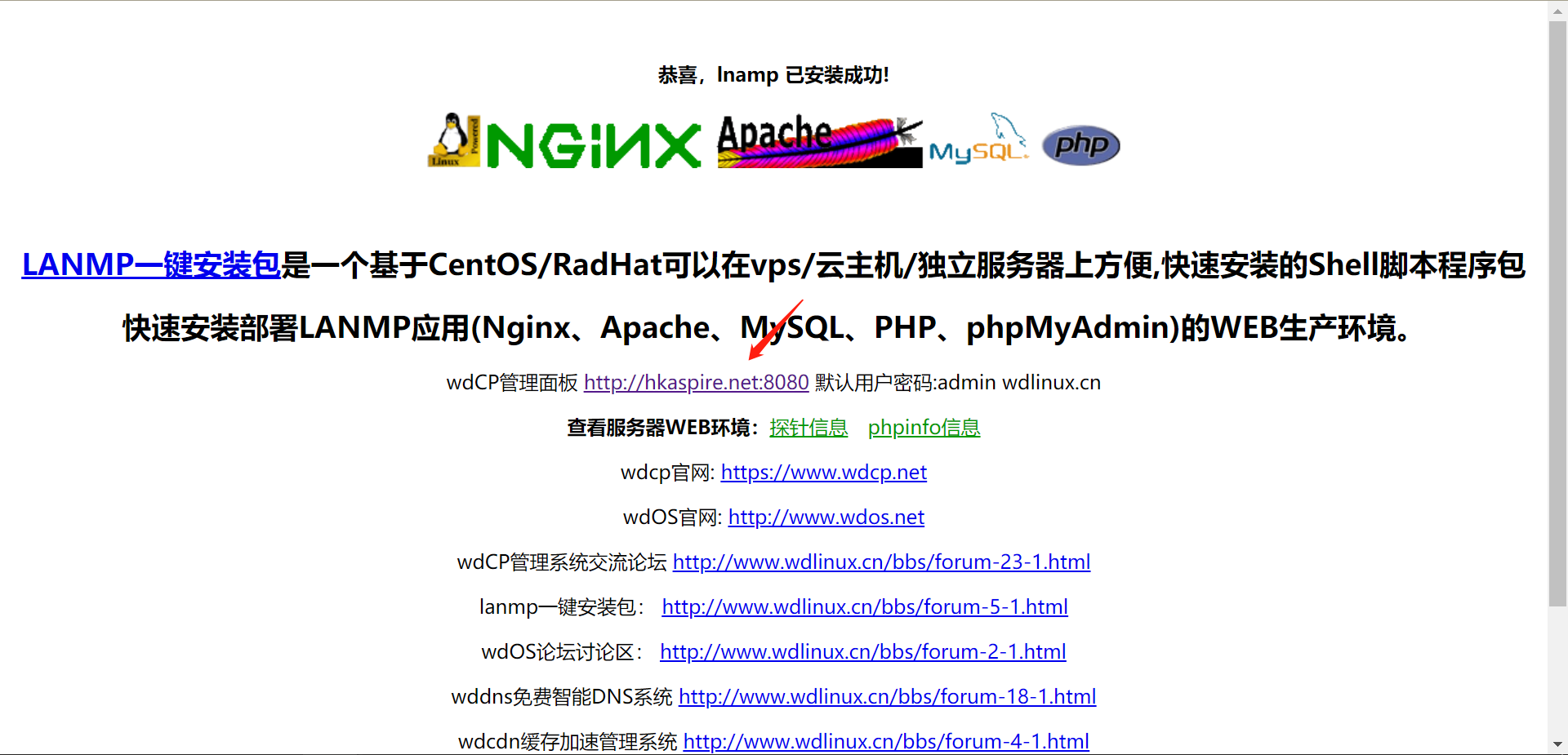
这其实也是可以成为一个攻击面的
他这里其实还暴露了很多,类似于探针信息,phpinfo信息
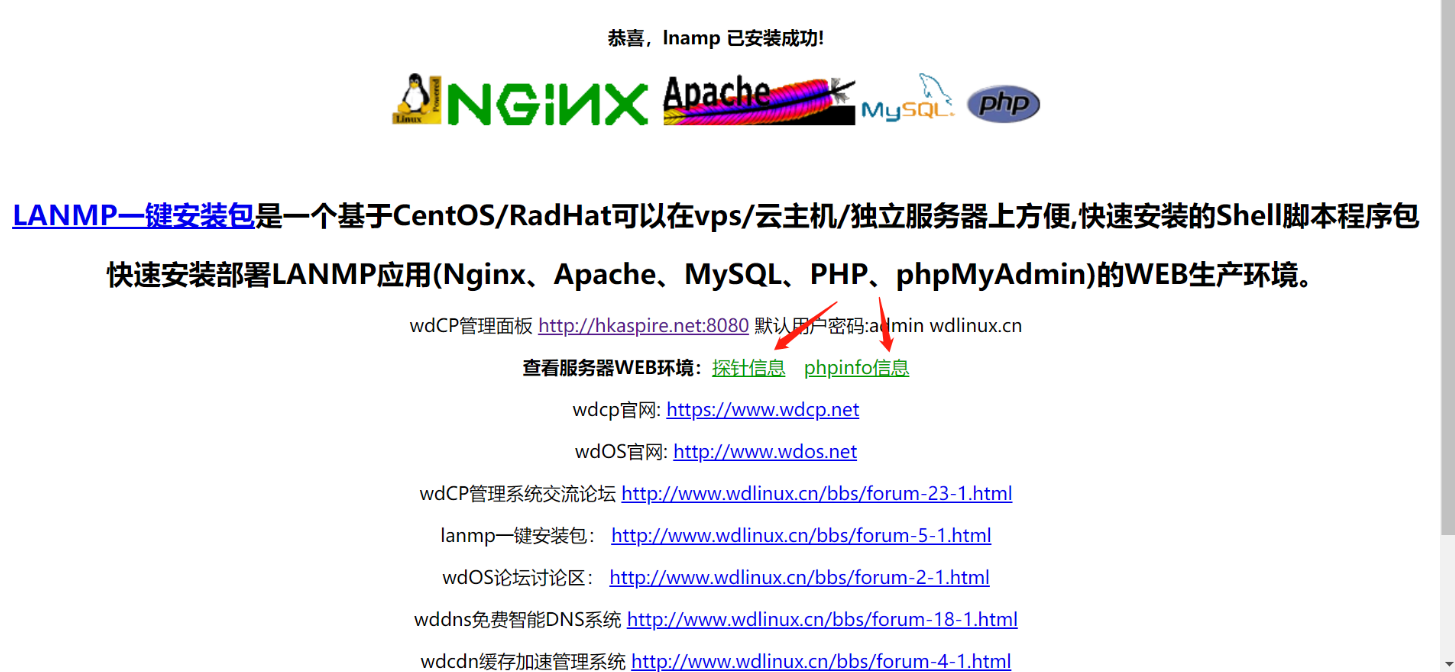
针对这个WDCP登陆系统,我们也可以直接在网上搜漏洞,进行漏洞测试
针对这个 https://hkaspire.cn/ 网站,这也是个系统,我们也可以进行漏洞测试
与此同时,这个域名https://hkaspire.cn/也涉及到新的IP地址,我们也可以针对这个IP地址进行测试【进行fofa的搜索】
同样进行这5步的测试
所以能做的事情是很多的
这样还没完,我们可以拿这种网站的标题去百度|谷歌搜索
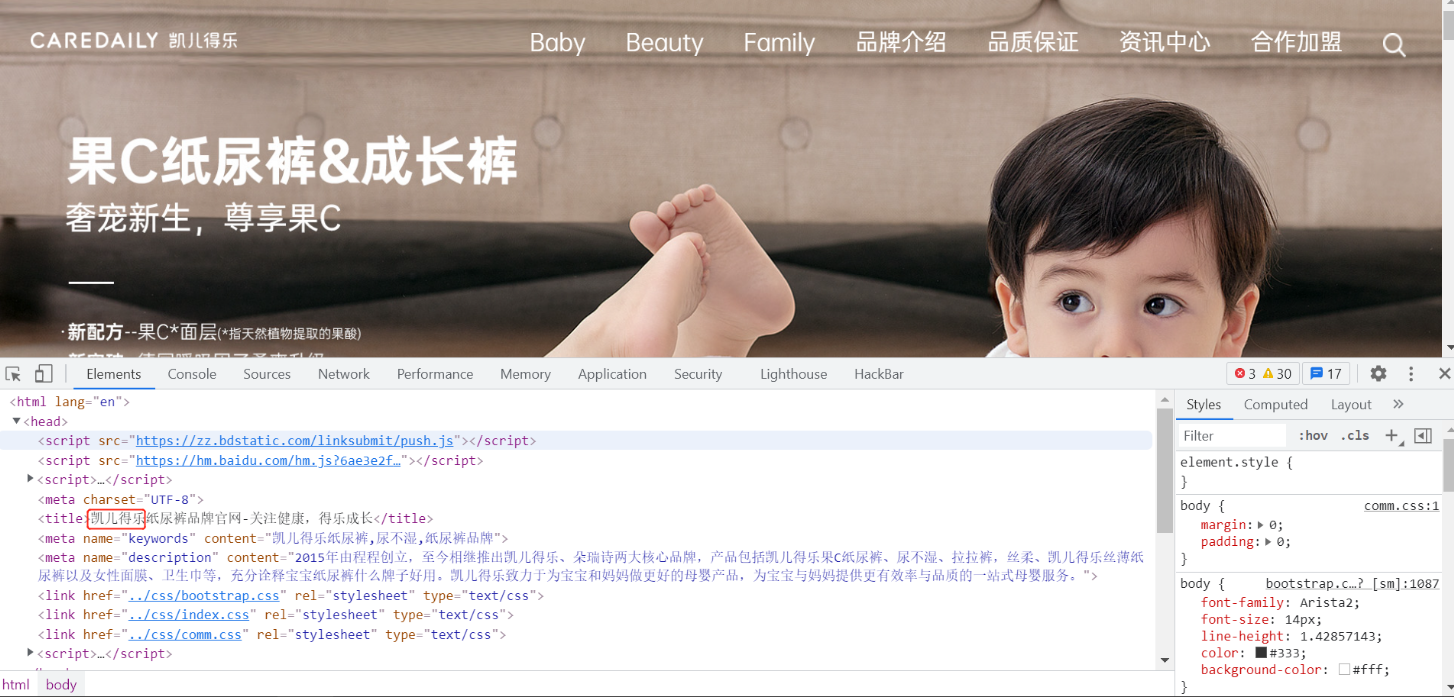
像是域名差不多的都可以进行测试
我们还可以去搜索域名的关键字【尽量用Google去搜索】
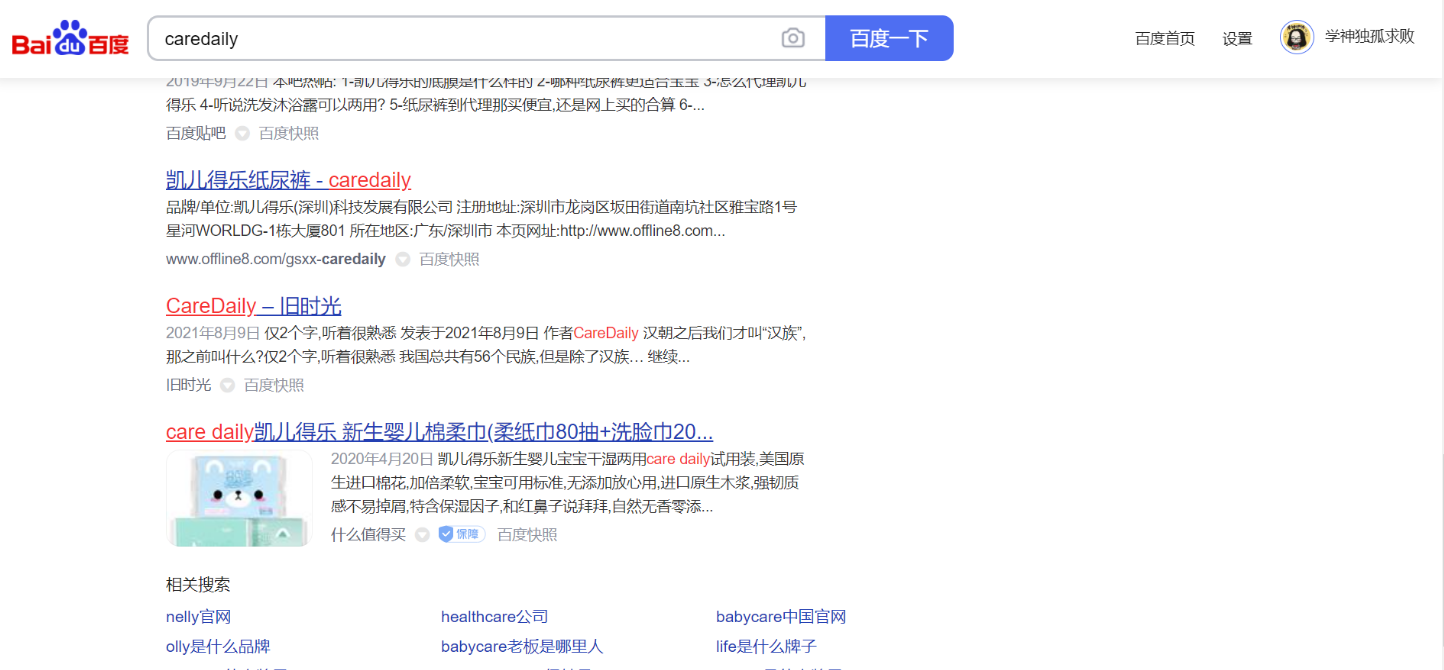
这个是我们通过谷歌搜到的 http://caredaily.xyz/
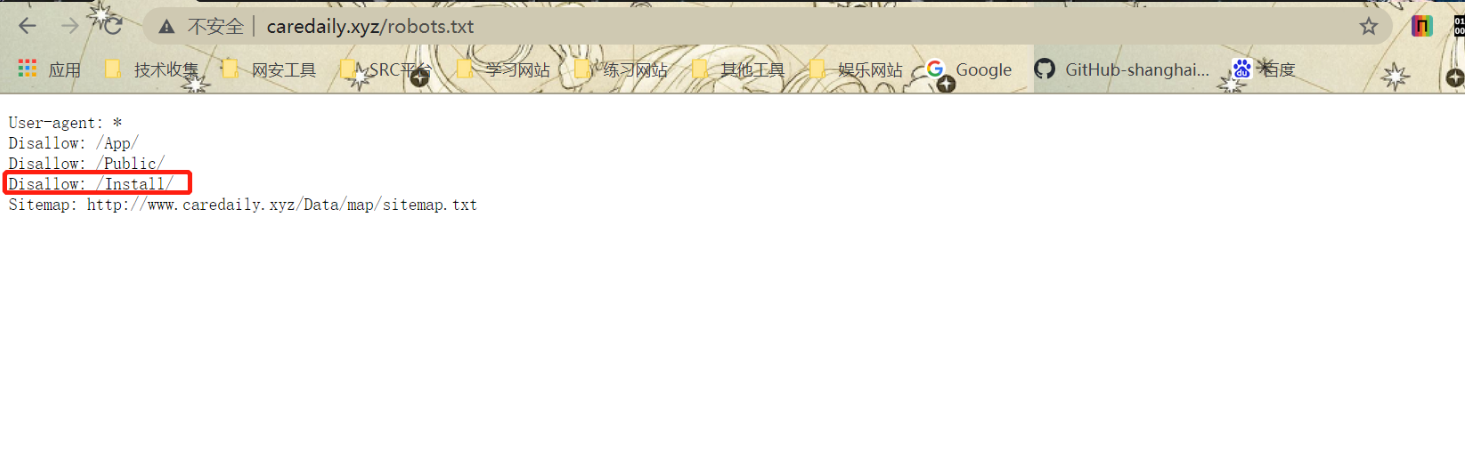
我们查看其robots.txt可以查到其一些路径
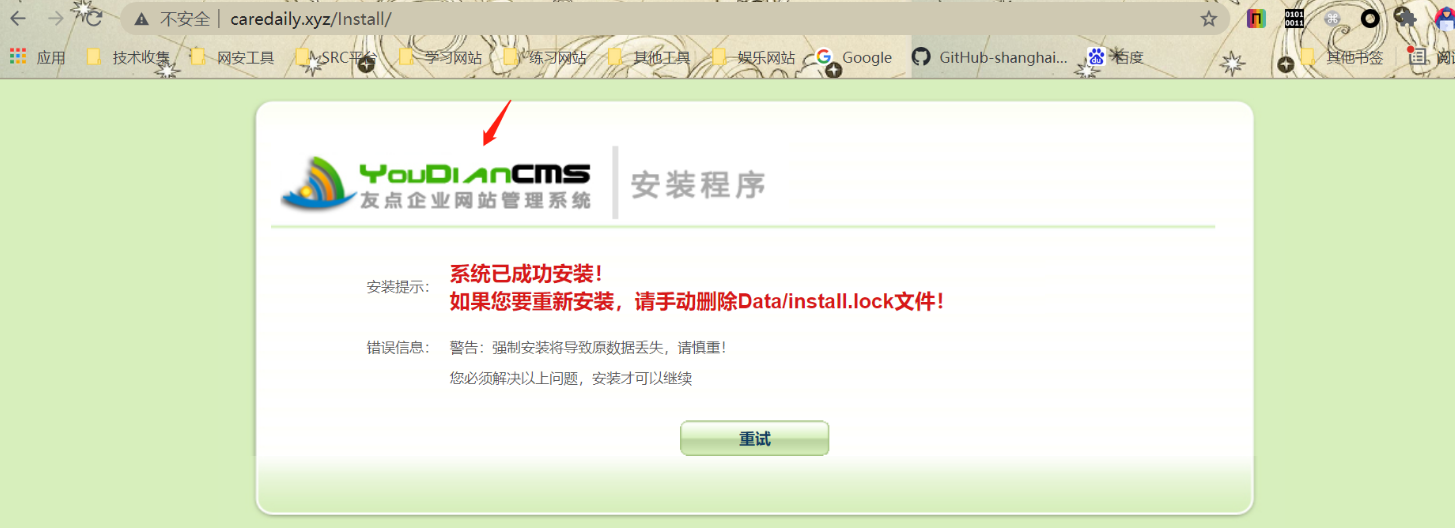
我们进这个Install看看
然后我们发现它使用youdiancms搭建的
然后我们就又可以去百度搜索youdiancms漏洞
这搜到的信息已经足够多了,而且我们每个得到的域名对应的每个IP,每个端口都要扫,我们会拿到相当多信息,足够我们进行渗透测试
涉及资源
https://nmap.org/download.html
Part3:信息收集-资产监控拓展
# Github监控
便于收集整理最新的EXP和POC
便于发现相关测试目标的资产
# 各种子域名查询
# 全球节点请求CDN
枚举爆破或解析子域名对应
便于发现管理员相关的注册信息
# 黑暗引擎相关搜索
fofa,shodan,zoomeye
# 微信公众号接口获取
# 内部群|内部应用|内部接口
▲各种子域名查询方法

▲监控最新的 EXP 发布及其他
# Title: wechat push CVE-2020
# Date: 2020-5-9
# Exploit Author: weixiao9188
# Version: 4.0
# Tested on: Linux,windows
# coding:UTF-8
import requests
import json
import time
import os
import pandas as pd
time_sleep = 20 #每隔20秒爬取一次
while(True):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400"}
#判断文件是否存在
datas = []
response1=None
response2=None
if os.path.exists("olddata.csv"):
#如果文件存在则每次爬取10个
df = pd.read_csv("olddata.csv", header=None)
datas = df.where(df.notnull(),None).values.tolist()#将提取出来的数据中的nan转化为None
response1 = requests.get(url="https://api.github.com/search/repositories?q=CVE-2020&sort=updated&per_page=10",
headers=headers)
response2 = requests.get(url="https://api.github.com/search/repositories?q=RCE&ssort=updated&per_page=10",
headers=headers)
else:
#不存在爬取全部
datas = []
response1 = requests.get(url="https://api.github.com/search/repositories?q=CVE-2020&sort=updated&order=desc",headers=headers)
response2 = requests.get(url="https://api.github.com/search/repositories?q=RCE&ssort=updated&order=desc",headers=headers)
data1 = json.loads(response1.text)
data2 = json.loads(response2.text)
for j in [data1["items"],data2["items"]]:
for i in j:
s = {"name":i['name'],"html":i['html_url'],"description":i['description']}
s1 =[i['name'],i['html_url'],i['description']]
if s1 not in datas:
#print(s1)
#print(datas)
params = {
"text":s["name"],
"desp":" 链接:"+str(s["html"])+"\n简介"+str(s["description"])
}
print("当前推送为"+str(s)+"\n")
print(params)
requests.get("https://sc.ftqq.com/XXXX.send",params=params,timeout=10)
#time.sleep(1)#以防推送太猛
print("推送完成!")
datas.append(s1)
else:
pass
#print("数据已处在!")
pd.DataFrame(datas).to_csv("olddata.csv",header=None,index=None)
time.sleep(time_sleep)
▲ 黑暗引擎实现域名端口等收集
▲ 全自动域名收集枚举优秀脚本使用
工具:teemo和Layer子域名挖掘机
以xxxxxx为例,从标题,域名等收集
以xxxxxx为例,全自动脚本使用收集
teemo.py
▲ SRC中的信息收集全覆盖
Part4:信息收集-补充部分
信息收集过程中需要收集的其他信息:
1.whois信息【域名注册时留下的信息】
网址: http://whois.chinaz.com/(站长之家)
https://www.whois.com/(国外网站)
通过whois我们可以找到更多的域名,一般来说主站的安全是比较强的,我们可以去搞分站,而且我们还有可能查到邮箱,通过邮箱我们也可以做很多的事。
2.CMS指纹识别
https://s.threatbook.cn/
http://finger.tidesec.com/ 潮汐指纹【推荐】
常见端口和服务对应关系:
445-局域网文件共享服务【永恒之蓝】
3389-远程桌面
80-web搭建默认端口
3306-MySQL默认端口
21-Ftp
22-SSH服务
1433-SQL Server默认端口
6379-Redis数据库默认端口
8888-宝塔默认端口
nmap的使用:
nmap+ip #最简单的使用方法
nmap+ip/24 #C段探测
nmap -p [port1,port2,...] [ip] #探测指定端口
nmap -p 1-65535 [ip] #全端口扫描
nmap -v [ip] #执行命令的同时显示每一步具体做了什么
nmap -Pn [ip] #目标禁ping时可以使用
nmap -h #查看所有命令
nmap -O [ip] #探测主机是什么操作系统
nmap -A [ip] #最强指令,把所有的扫描|探测方法都用上
网站状态码对应信息:
200-网站正常访问
302-重定向
404-页面不存在
403-权限不足,但是页面存在
502-服务器内部错误
谷歌hacking语法:
filetype:指定文件类型
inurl:指定url包含内容
site:指定域名
intitle:指定title包含内容
intext:指定内容
inurl:/admin/index #这种很容易找到别人的后台
inurl:/admin.php #这种就很容易找到admin.php的内容
site:edu.cn inurl:.php?id=123 #找SQL注入站点时可以这么找
Web安全-信息收集的更多相关文章
- WEB安全信息收集
目录 信息收集 子域名&敏感信息 敏感信息收集--Googlehack 敏感信息收集--收集方向 空间测绘引擎域名资产收集 子域名收集 WEB指纹 端口扫描 IP查询 cms识别 WAF识别 ...
- ctfshow WEB入门 信息收集 1-20
web1 题目:开发注释未及时删除 查看页面源代码即可 web2 题目:js把鼠标右键和f12屏蔽了 方法一: 禁用JavaScript 方法二: url前面加上view-source: web3 题 ...
- Web应用程序信息收集工具wig
Web应用程序信息收集工具wig 很多网站都使用成熟的Web应用程序构建,如CMS.分析网站所使用的Web应用程序,可以快速发现网站可能存在的漏洞.Kali Linux新增加了一款Web应用程序信 ...
- Web信息收集-目标扫描-OpenVAS
Web信息收集-目标扫描-OpenVAS 一.OpenVAS简述 二.部署OpenVAS 2.1 升级Kali Linux 2.2 安装OpenVAS 2.3 修改admin账户密码 2.4 修改默认 ...
- Web信息收集-目标扫描-Nmap
Web信息收集-目标扫描-Nmap 一.Nmap简介 二.扫描示例 使用主机名扫描: 使用IP地址扫描: 扫描多台主机: 扫描整个子网 使用IP地址的最后一个字节扫描多台服务器 从一个文件中扫描主机列 ...
- Web信息收集之搜索引擎-Zoomeye Hacking
Web信息收集之搜索引擎-Zoomeye Hacking https://www.zoomeye.org ZoomEye(钟馗之眼)是一个面向网络空间的搜索引擎,"国产的Shodan&quo ...
- Web信息收集之搜索引擎-Shodan Hacking
Web信息收集之搜索引擎-Shodan Hacking 一.Shodan Hacking简介 1.1 ip 1.2 Service/protocol 1.3 Keyword 1.4 Cuuntry 1 ...
- Web信息收集之搜索引擎-GoogleHacking
Web信息收集之搜索引擎-GoogleHacking 一.信息收集概述 二.Google Hacking 2.1 site 2.2 filetype 2.3 inurl 2.4 intitle 2.5 ...
- web安全之信息收集篇
信息收集 1.网络信息 网络信息就包括网站的厂商.运营商,网站的外网出口.后台.OA. 2.域名信息 通过域名可以查洵网站的所有人.注册商.邮箱等信息 --->Whois 第三方查询,查询子域网 ...
随机推荐
- python基础之文件的读取
#文件名 txt文件的读取#文件的读取 open("文件","读写方法") with open("文件","读写方法") ...
- 使用turtle库画一朵玫瑰花带文字
参考链接:https://jingyan.baidu.com/article/d169e18689f309026611d8c8.html https://blog.csdn.net/weixin_41 ...
- jvm源码解读--10 enum WKID 枚举
源码中对于枚举类型WKID的使用 static bool initialize_wk_klass(WKID id, int init_opt, TRAPS); static void initiali ...
- Java 正则表达式 简单用法
正则表达式的具体写法网上有很多了,这里只记录在 Java 中怎么使用. java.util.regex.Matcher.java.util.regex.Pattern 主要有: String.matc ...
- 17Java进阶——反射、进程、Java11新特性
1.Java反射机制 Java反射(Reflection)概念:在运行时动态获取类的信息以及动态调用对象方法的功能. 1.1反射的应用--通过全类名获取类对象及其方法 package two.refl ...
- jquey 定位到有某个类
$active = $('.g-pop-box .box-option a[class="on"]')
- 为什么大家都在用WebRTC?
WebRTC代表网络实时通信.它是一种非常令人兴奋,强大且具有高度破坏性的尖端技术和标准.自从WebRTC诞生以来,80%的浏览器都开始支持它.有数据显示,2017年~2021年期间,WebRTC市场 ...
- 终拿字节Offer...动态规划复盘...
大家好!我是 Johngo 呀! 和大家一起刷题不快不慢,没想到已经进行到了第二阶段,「动态规划」这部分题目很难,而且很不容易理解,目前我的题目做了一半,凭着之前对于「动态规划」的理解和最近做的题目做 ...
- 精进 Spring Boot 03:Spring Boot 的配置文件和配置管理,以及用三种方式读取配置文件
精进 Spring Boot 03:Spring Boot 的配置文件和配置管理,以及用三种方式读取配置文件 内容简介:本文介绍 Spring Boot 的配置文件和配置管理,以及介绍了三种读取配置文 ...
- JUC学习笔记(四)
JUC学习笔记(一)https://www.cnblogs.com/lm66/p/15118407.html JUC学习笔记(二)https://www.cnblogs.com/lm66/p/1511 ...