Oracle Database 11g : SQL 基础
简介
1:课程目标

2:课程 目标

3:Oracle Database 11g 以及相关产品概览
1:Oracle Database 11g :重点领域
2:Oracle Fusion Middleware
3:Oracel Enterprise Manager Grid Control
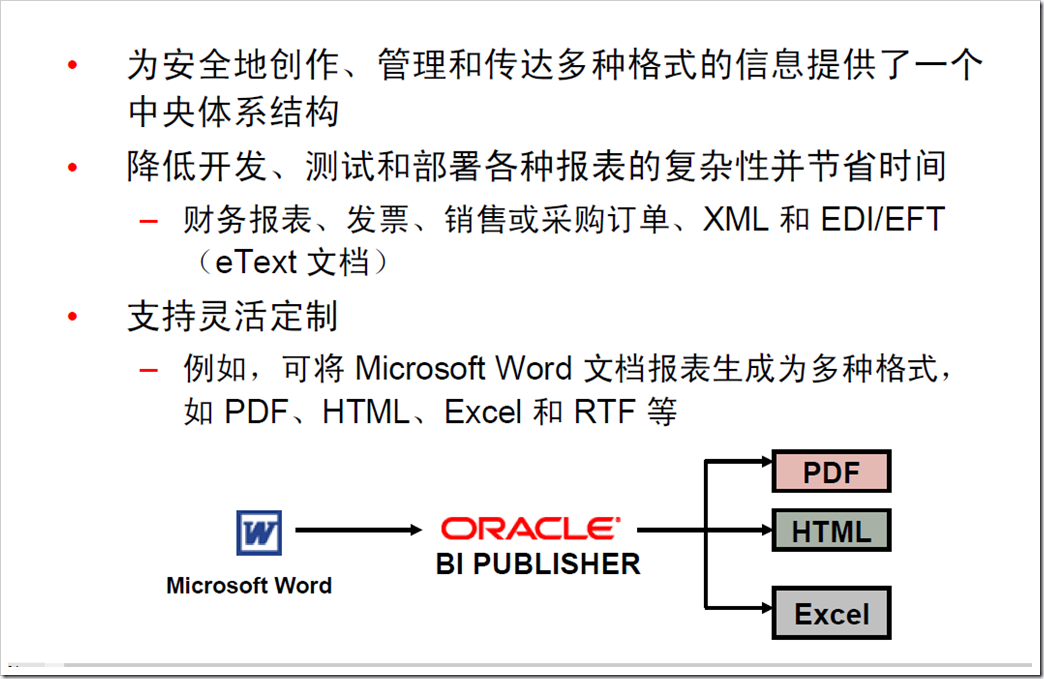
4:Oracle Bi Publisher




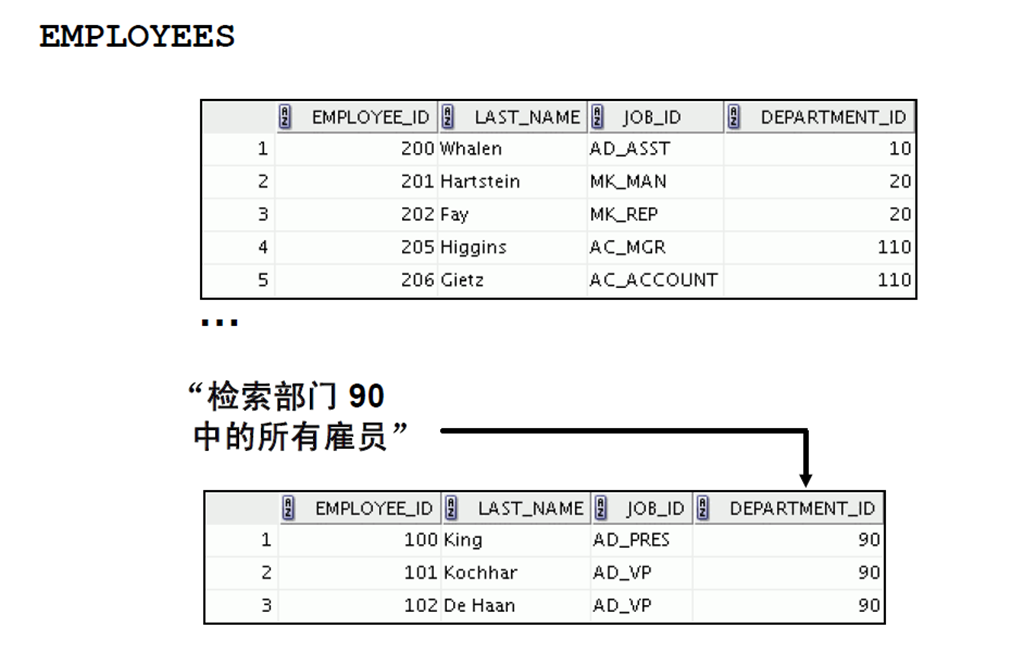
4:关系数据库管理概念和术语概览
1:关系和对象关系数据库管理系统
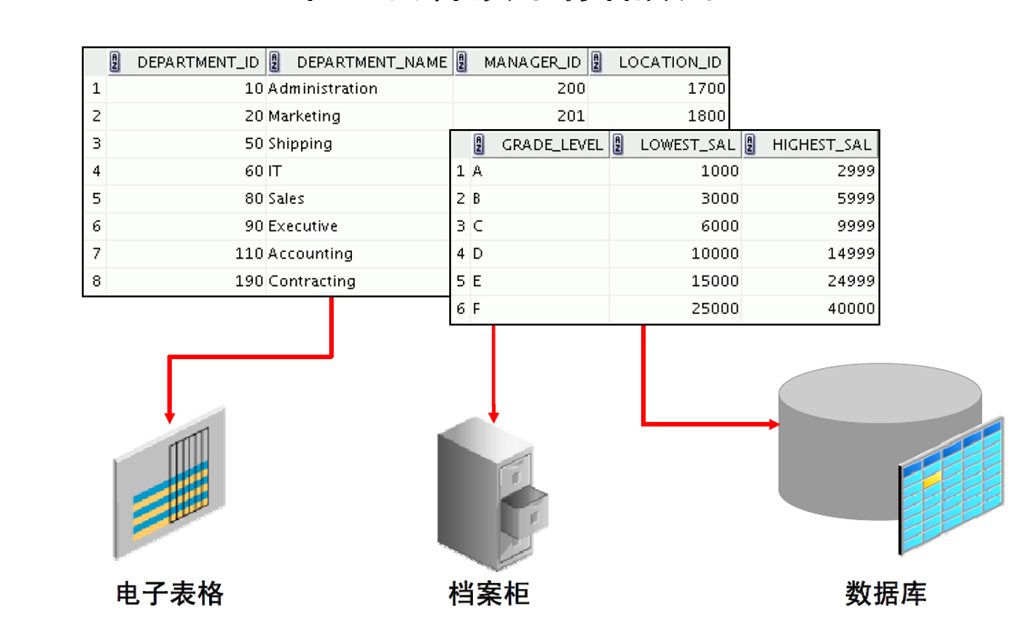
2:在不同介质中存储数据
3:关系数据库概念
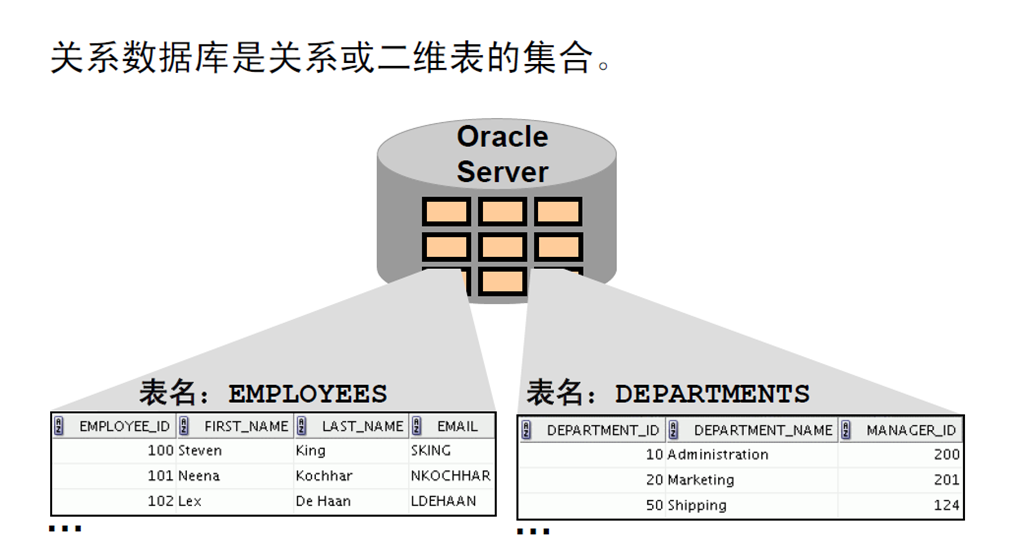
4:关系数据库的定义
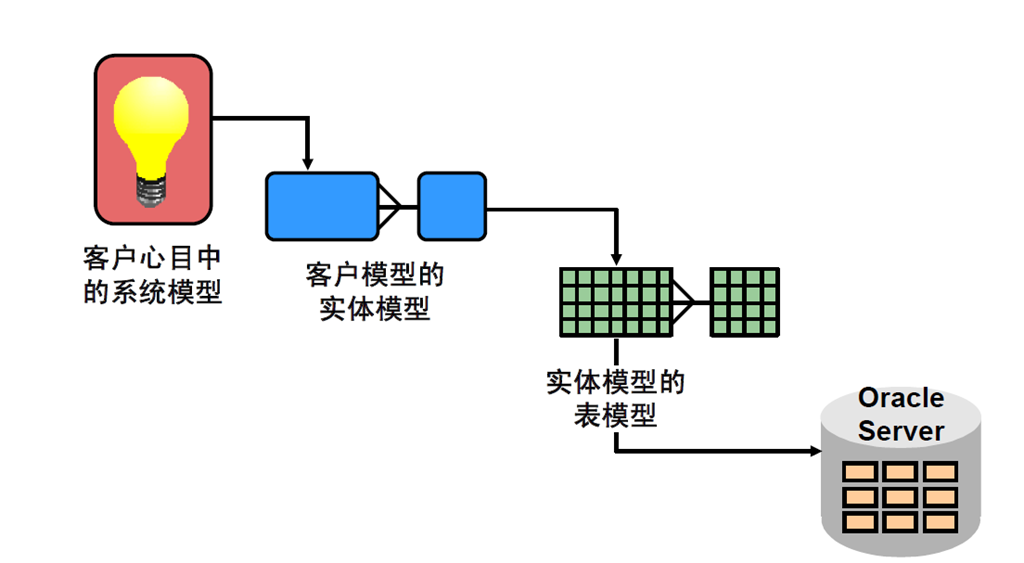
5:数据模型
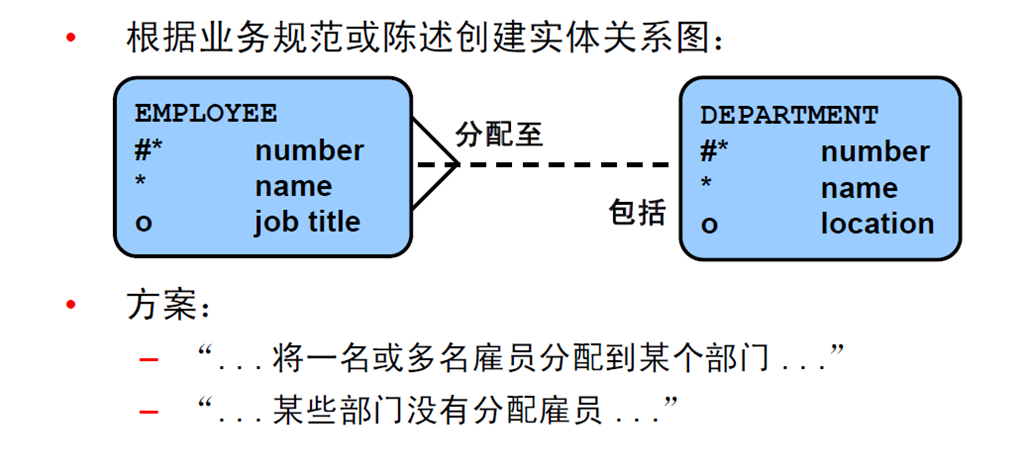
6:实体关系模型
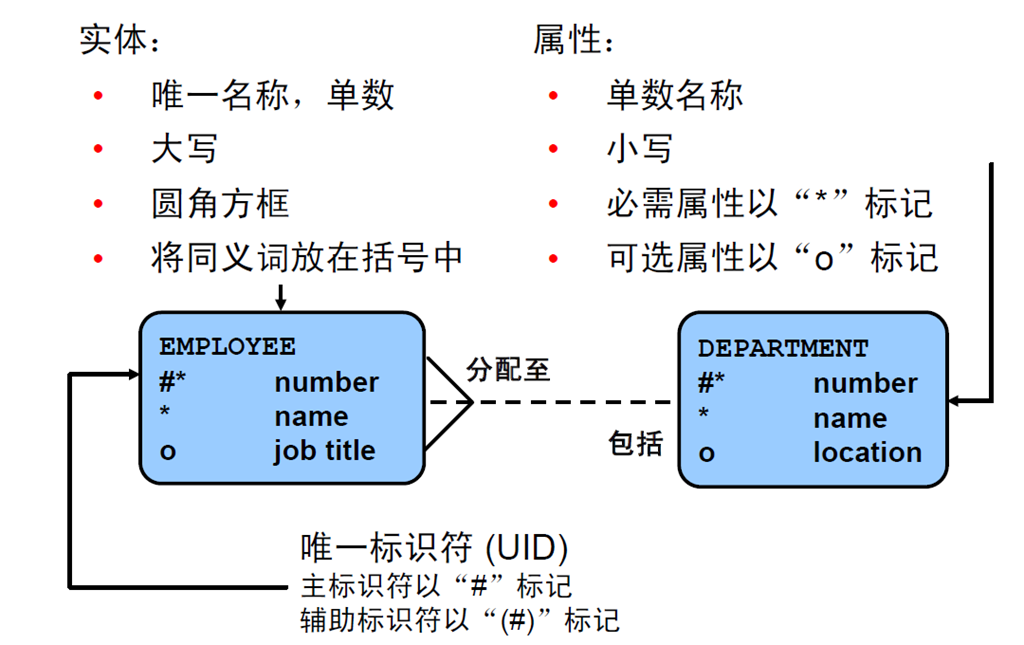
7:实体关系建模惯例
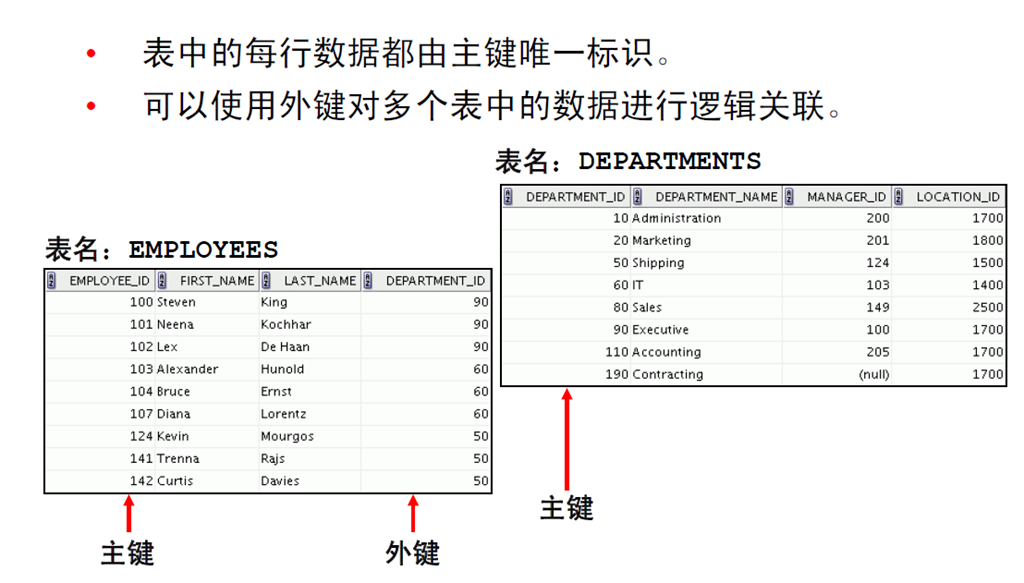
8:管理多个表
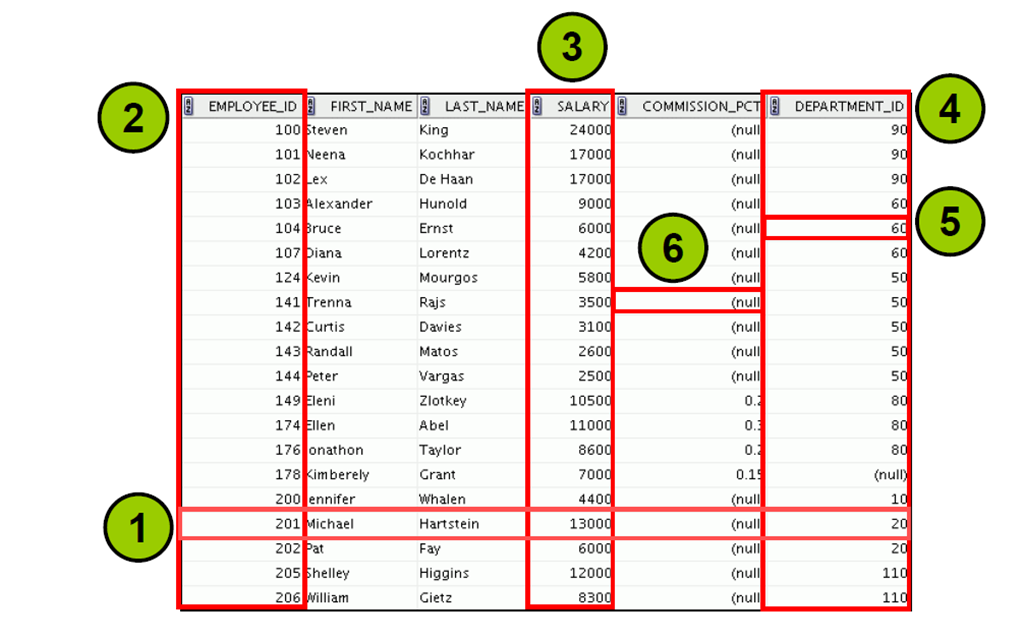
9:关系数据库术语


5:SQL 及其开发环境简介
1:使用SQL查询数据库
2:SQL语句
3:SQL开发环境
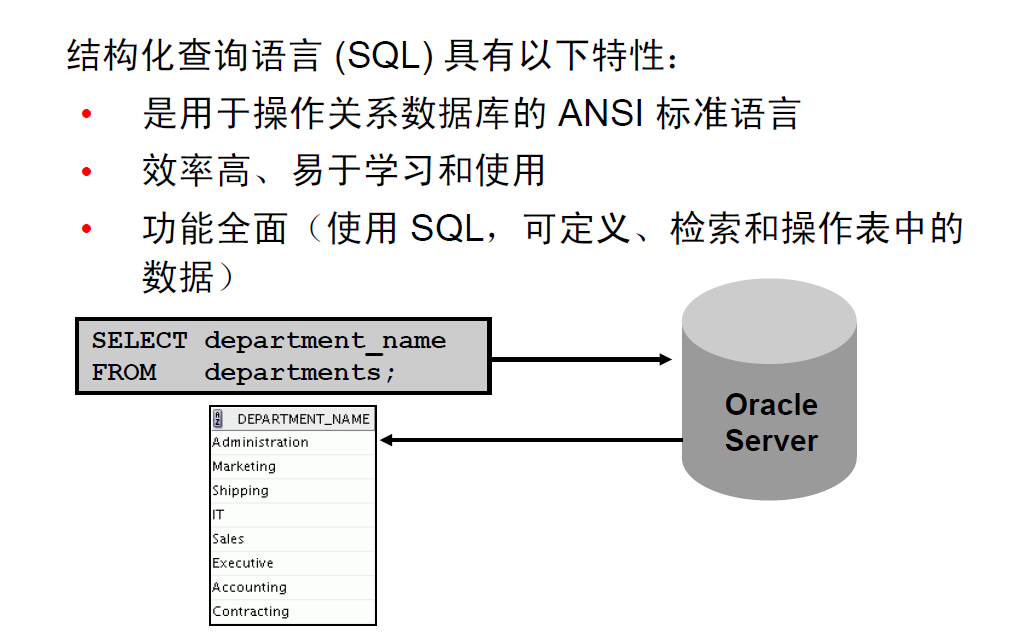


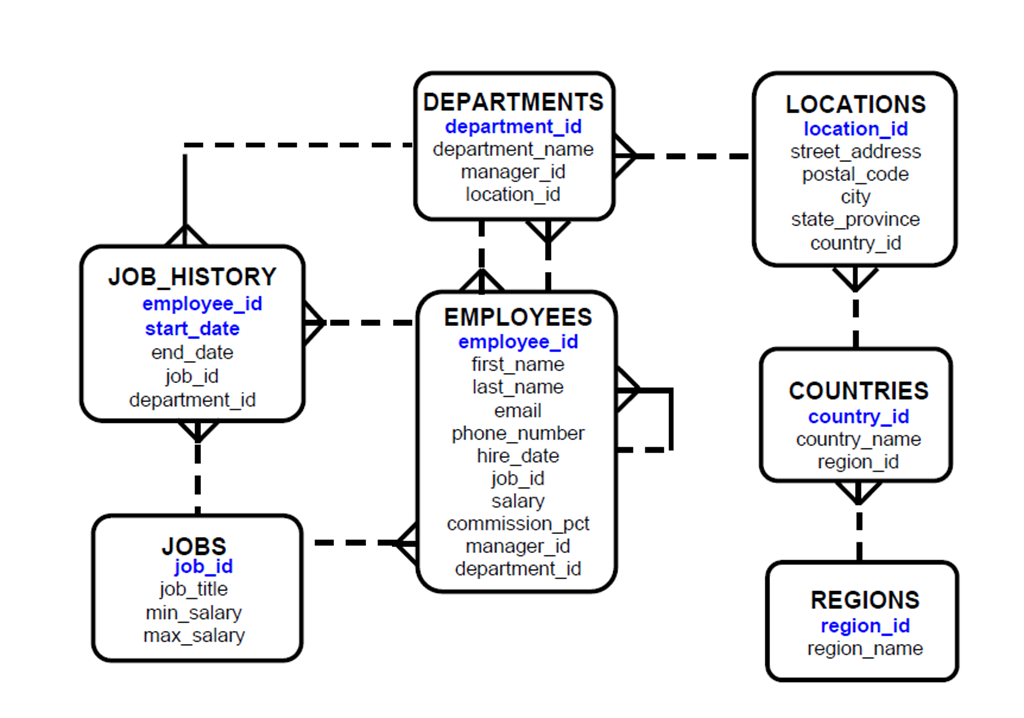
6:本课程中使用的HR方案和表
1:人力资源(HR)方案
2:本课程使用的表

7:Oracle Database 11g 的文档和其他资源
1:Oracle Database 11g 文档
2:其他资源


第一章:使用SQL SELECT 语句检索数据
1:课程目标

2:基本SELECT 语句
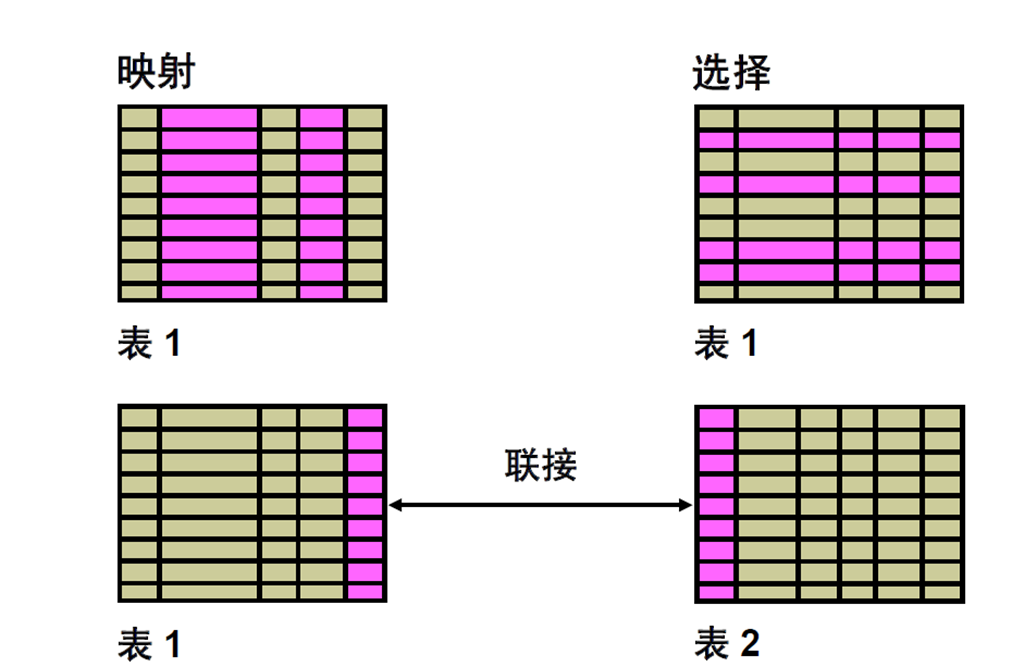
1:SQL SELECT 语句的功能
2:基本SELECT 语句
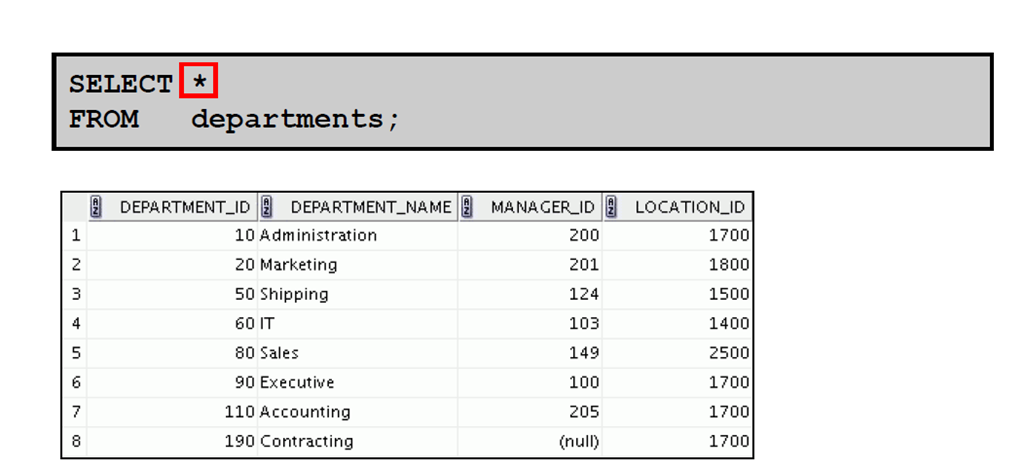
3:选择所有列
4:选择特定列
5:编写SQL 语句
6:列标题的默认设置

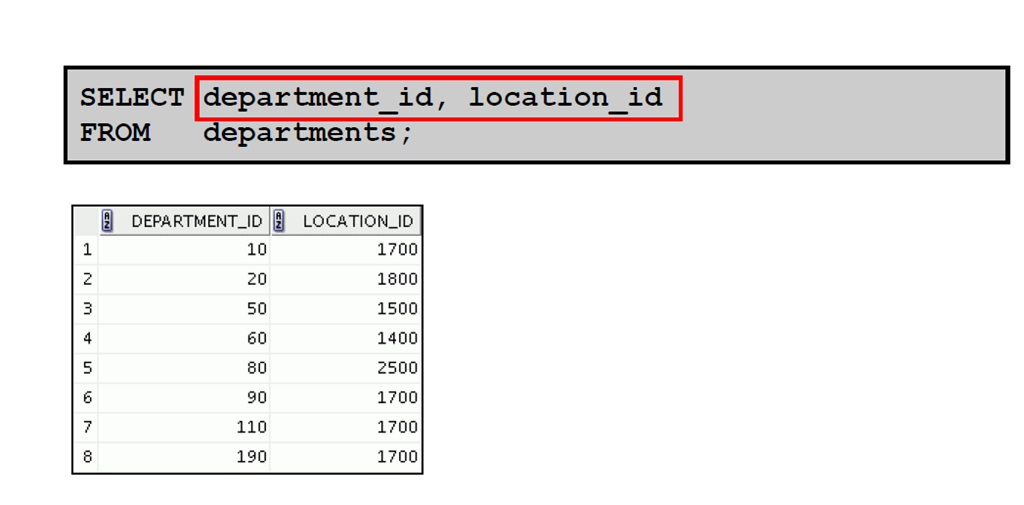


3:SELECT 语句中的算术表达式和空值
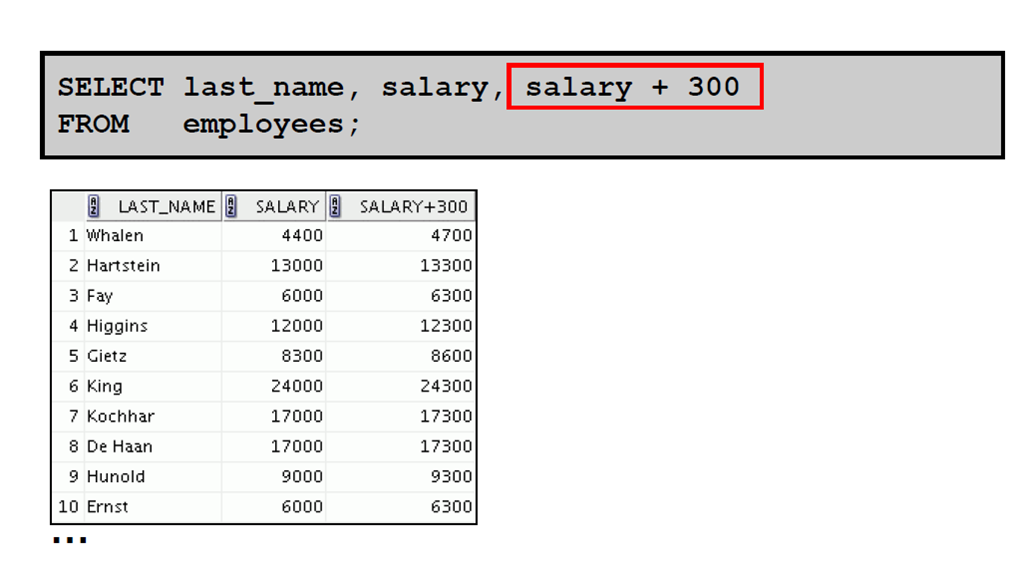
1:算术表达式
2:使用算术运算符
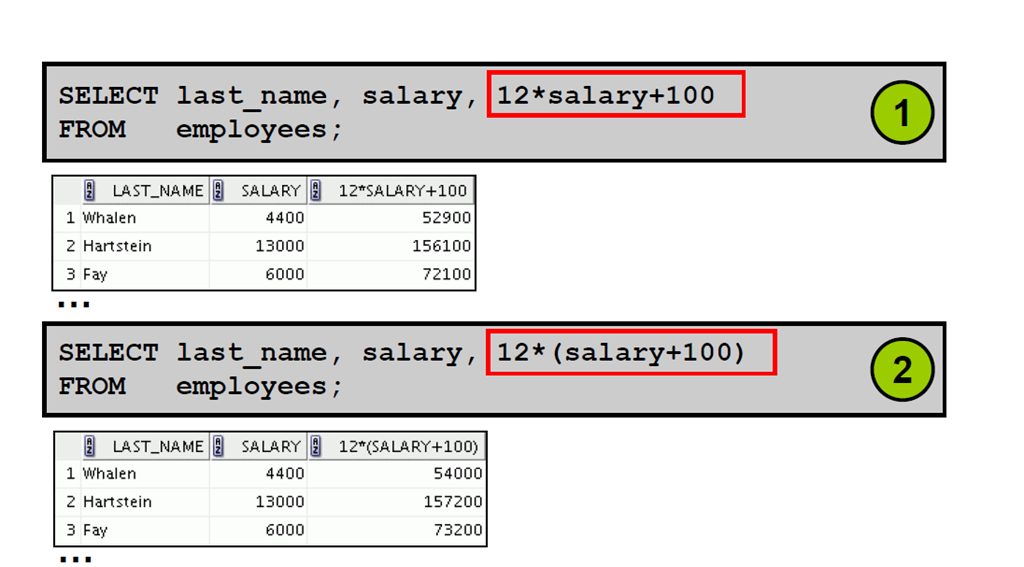
3:运算符优先级
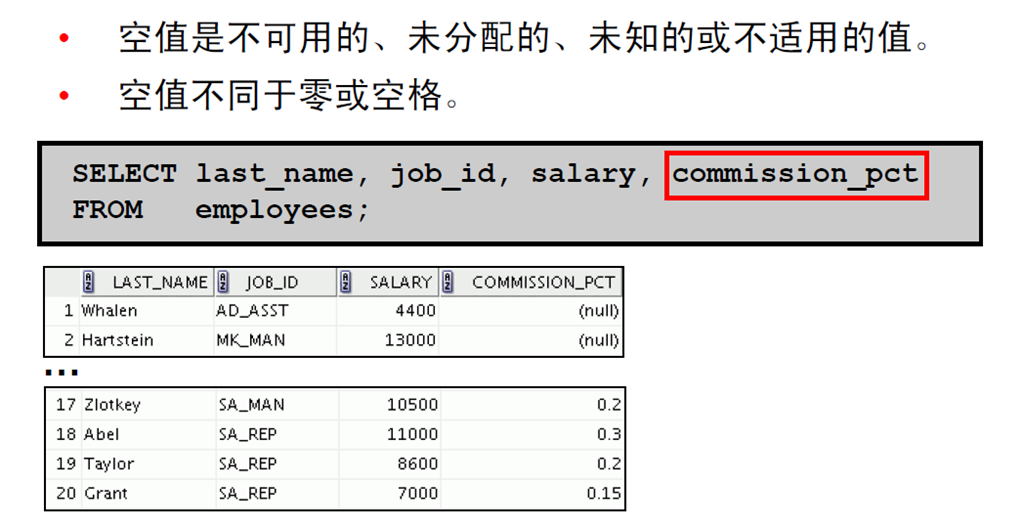
4:定义空值
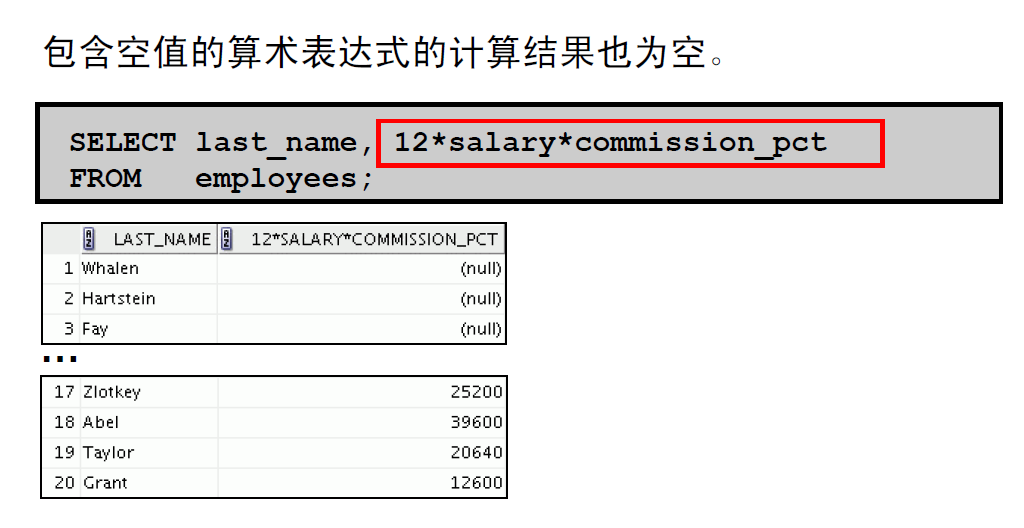
5: 算术表达式中的空值
4:列别名
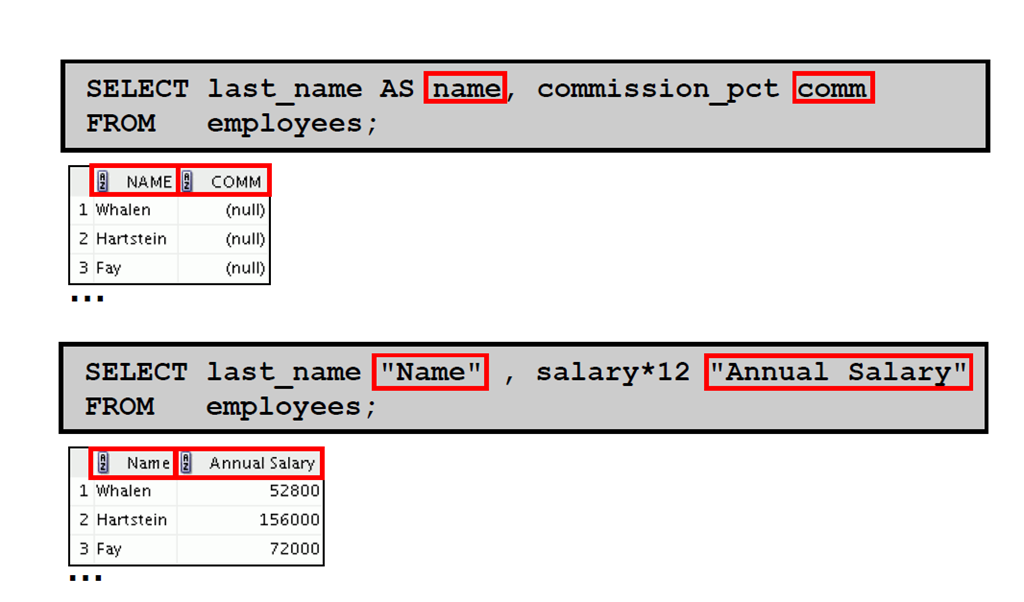
1:定义列别名
2:使用列别名

5:连接运算符、文字字符串、其它引号运算符和 DISTINCT 关键字的用法
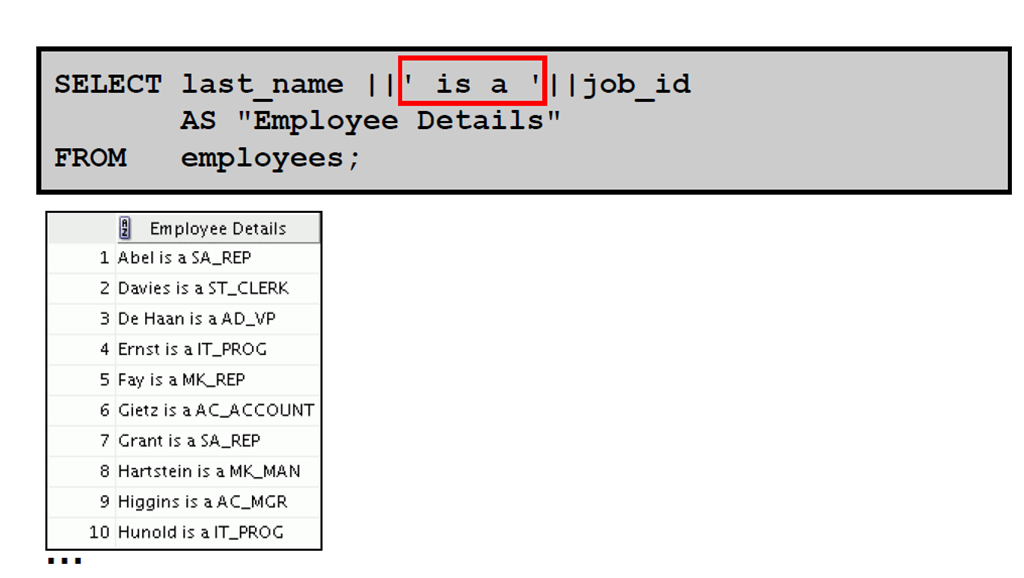
1:连接运算符
2:文字字符串
3:使用文字字符串
4:其它引号(q) 运算符
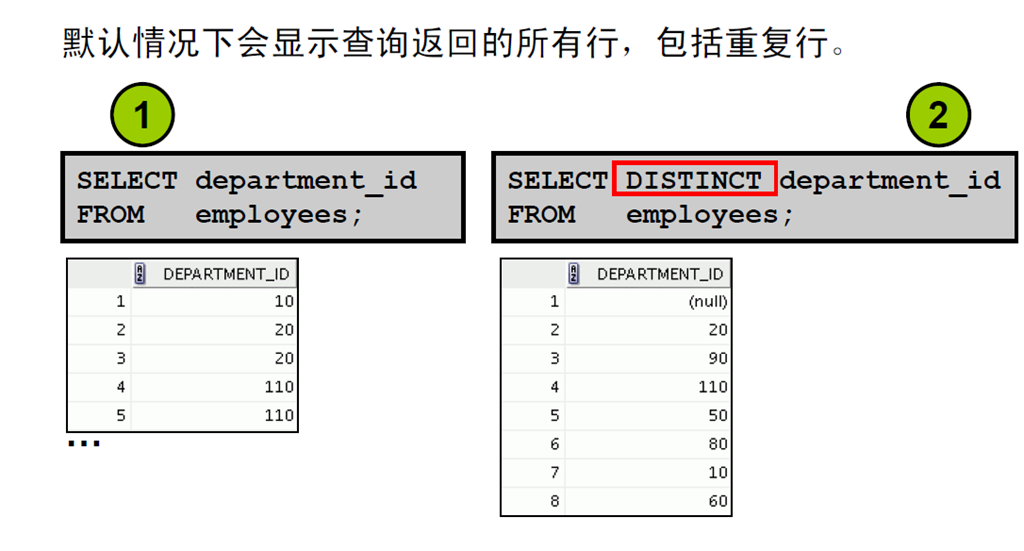
5:重复行


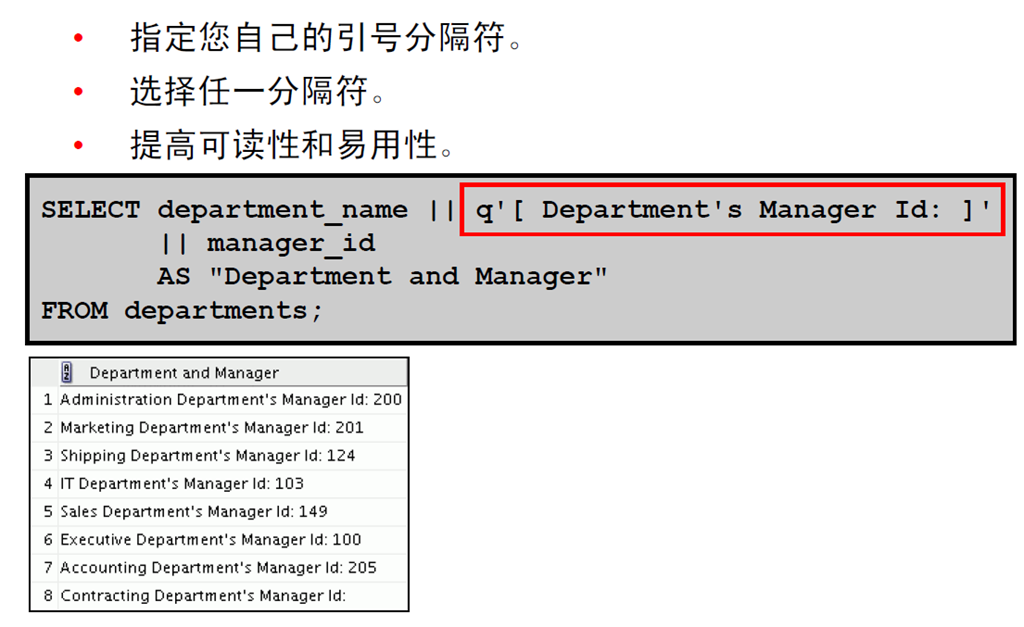
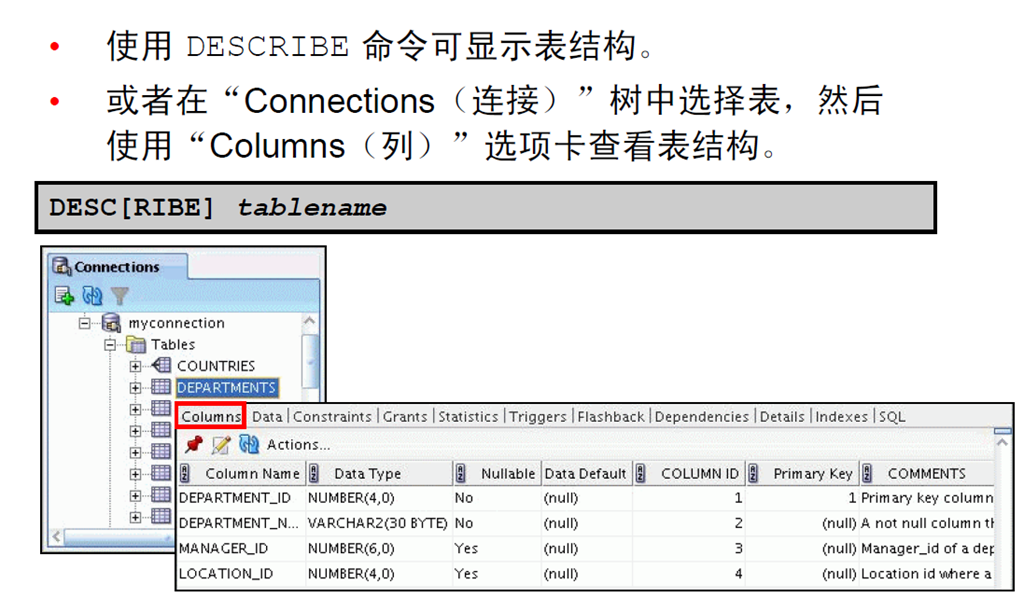
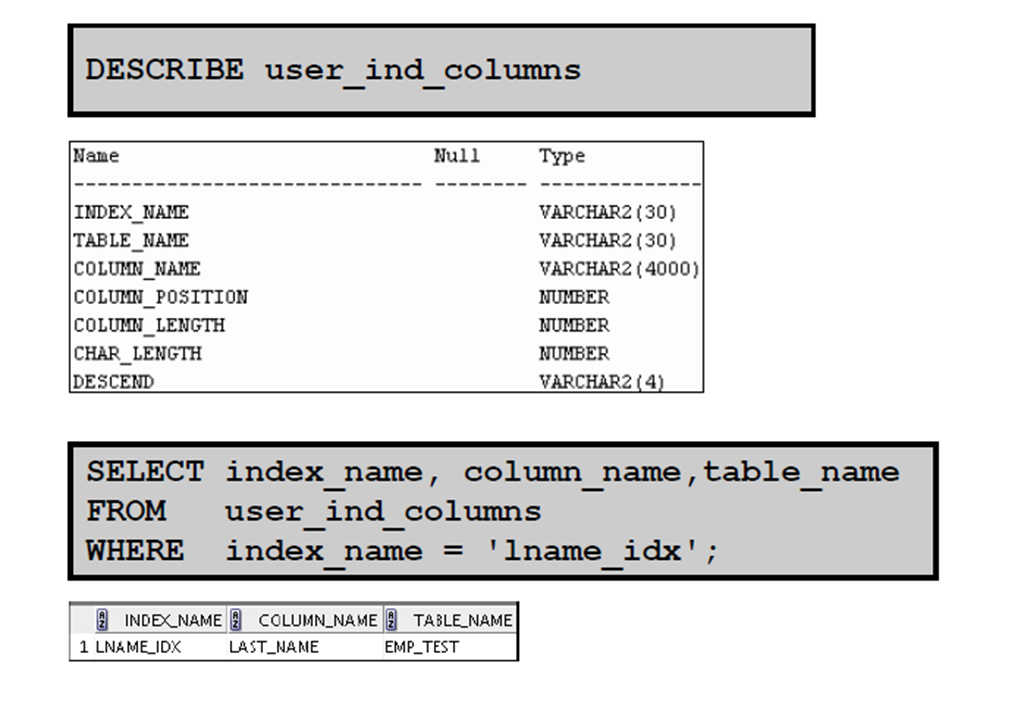
6:DESCRIBE 命令
1:显示表结构
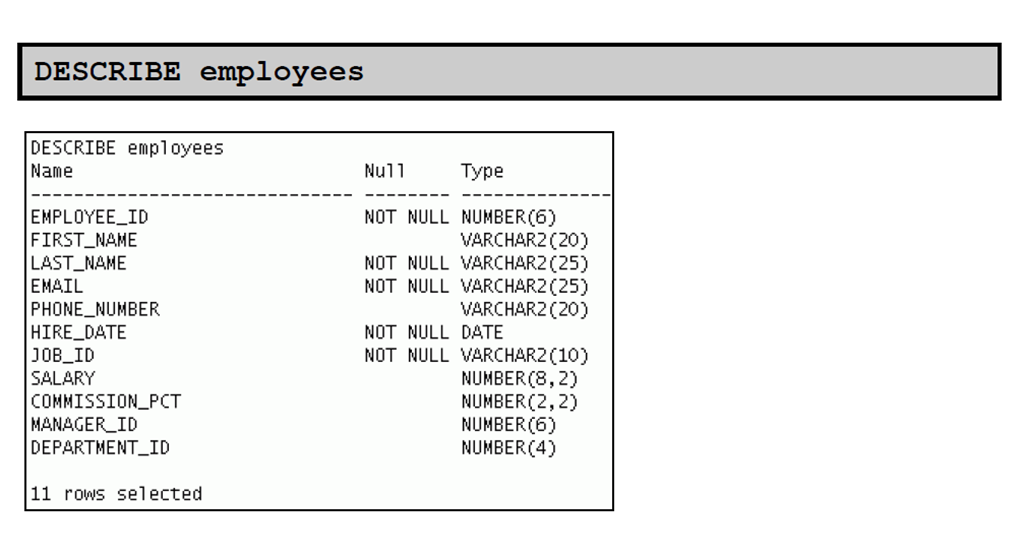
2:使用DESCRIBE 命令
第二章:对数据进行限制和排序
1:课程目标

2:使用以下项对行进行限制: – WHERE 子句 – 使用=、<=、BETWEEN、IN、LIKE 和NULL 条件的 比较条件 – 使用AND、OR 和NOT 运算符的逻辑条件
1:有选择地对行进行限制
2:对所选行进行限制
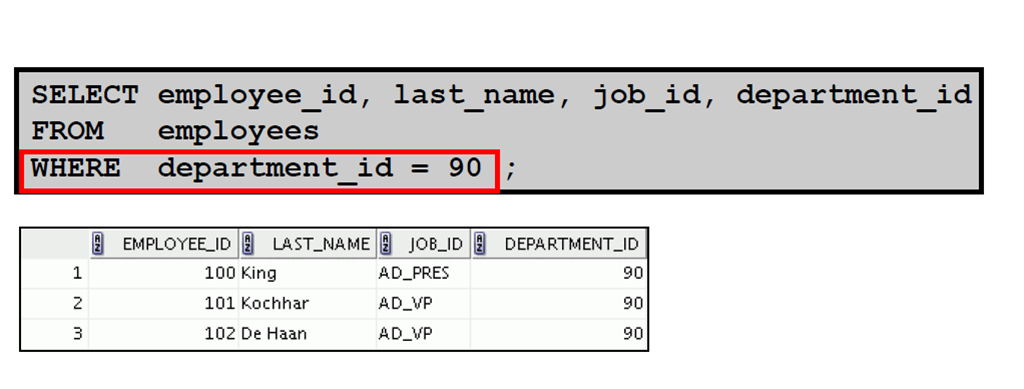
3:使用WHERE 子句
4:字符串和日期
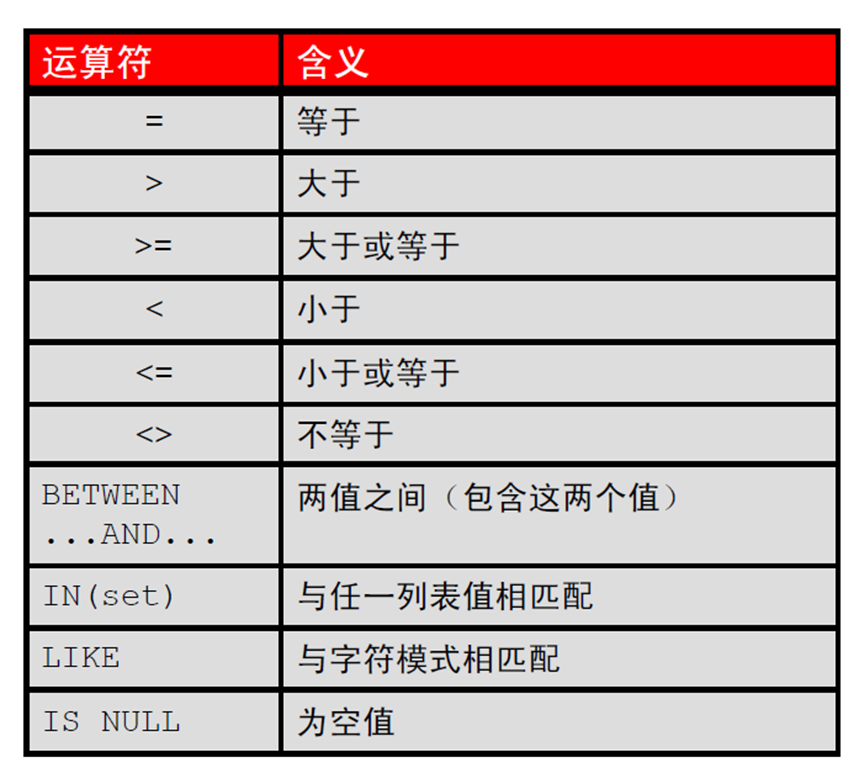
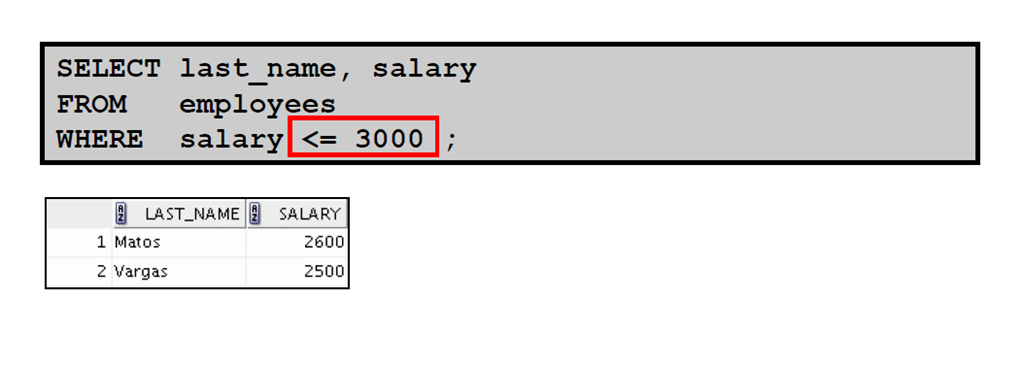
5:比较运算符
6:使用比较运算符
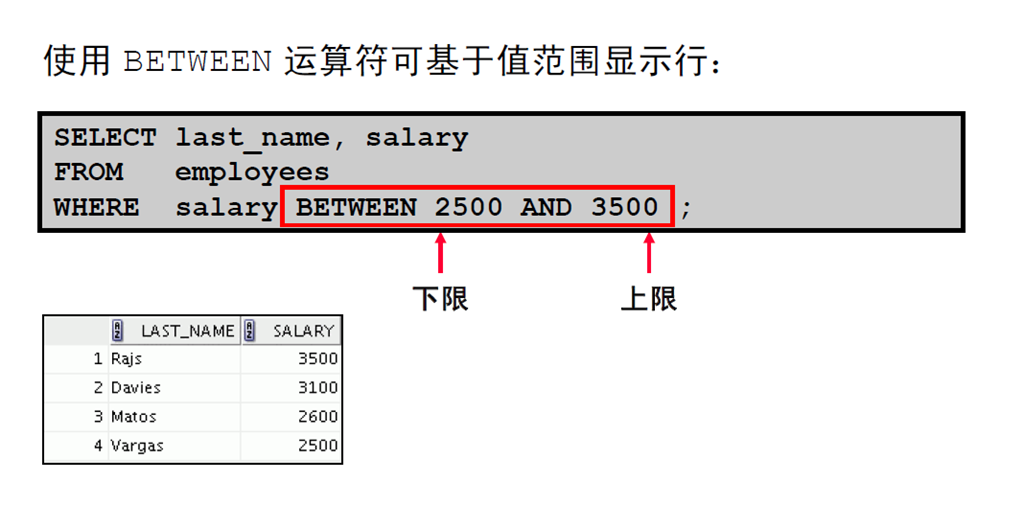
7:使用BETWEEN 运算符的范围条件
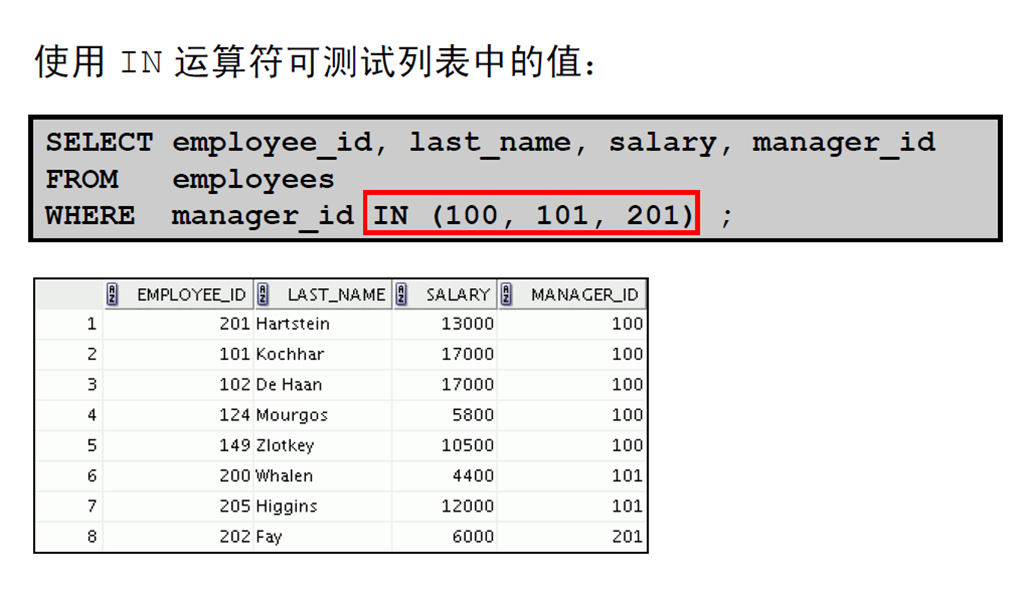
8:使用IN 运算符的成员条件
9:使用LIKE 运算符执行模式匹配
10:组合通配符字符
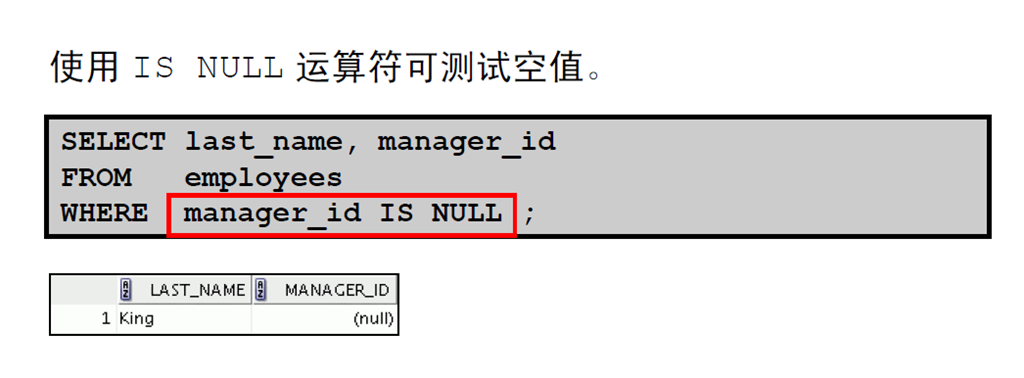
11:使用NULL 条件
12:使用逻辑运算符定义条件
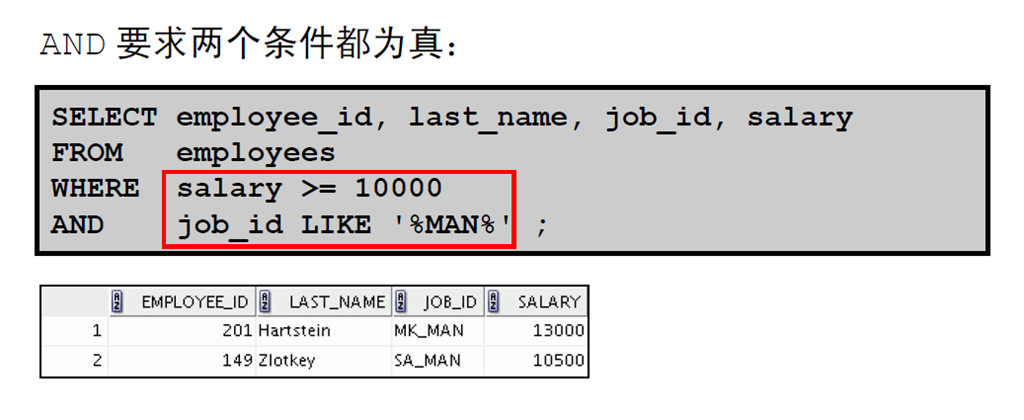
13:使用AND 运算符
14:使用OR 运算符
15:使用NOT 运算符





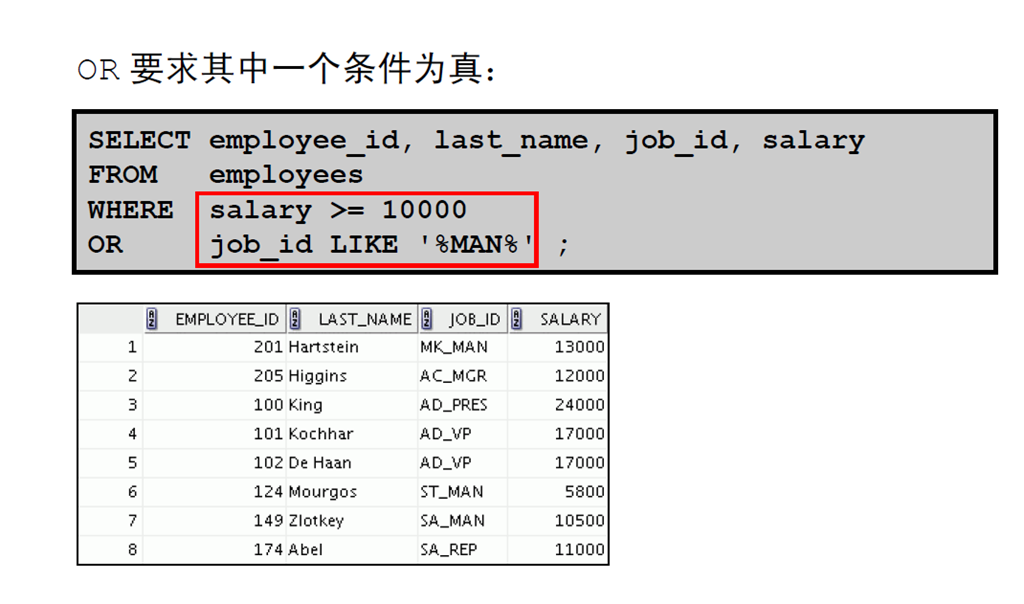
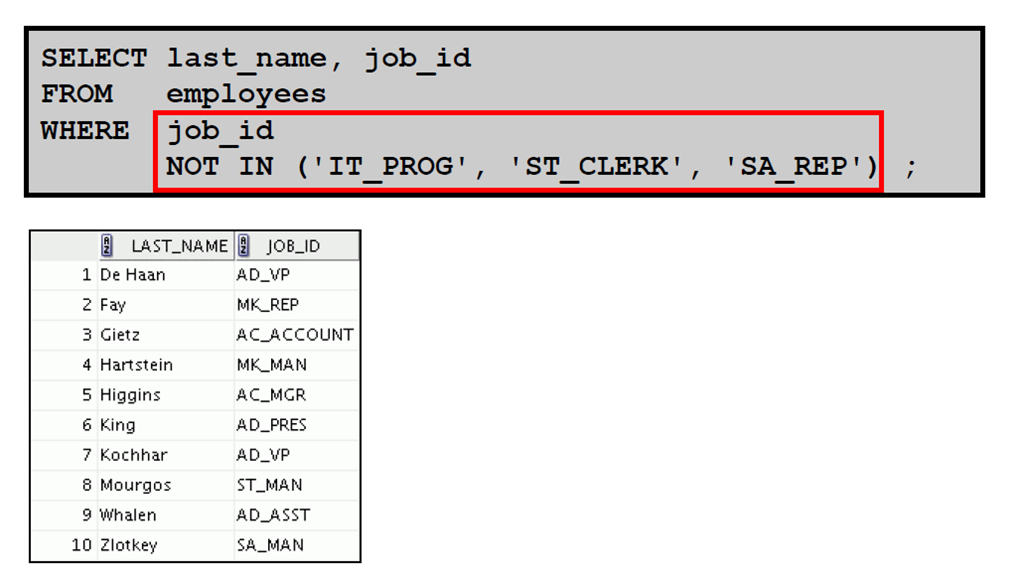
3:表达式中运算符的优先级规则
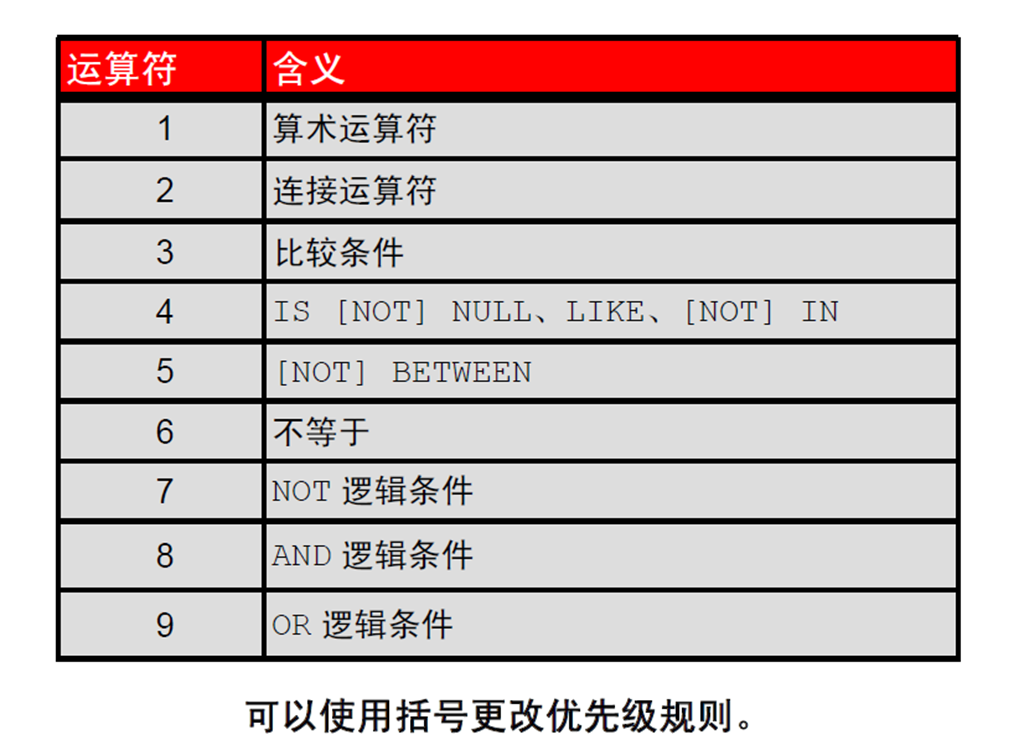
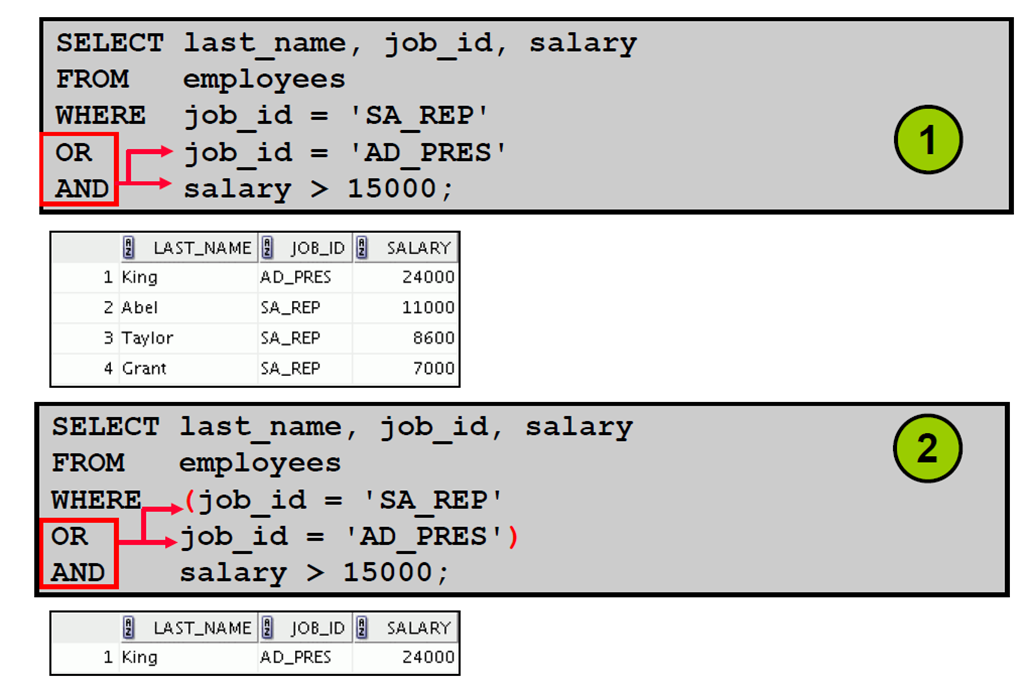
1:优先级规则
2:优先级规则
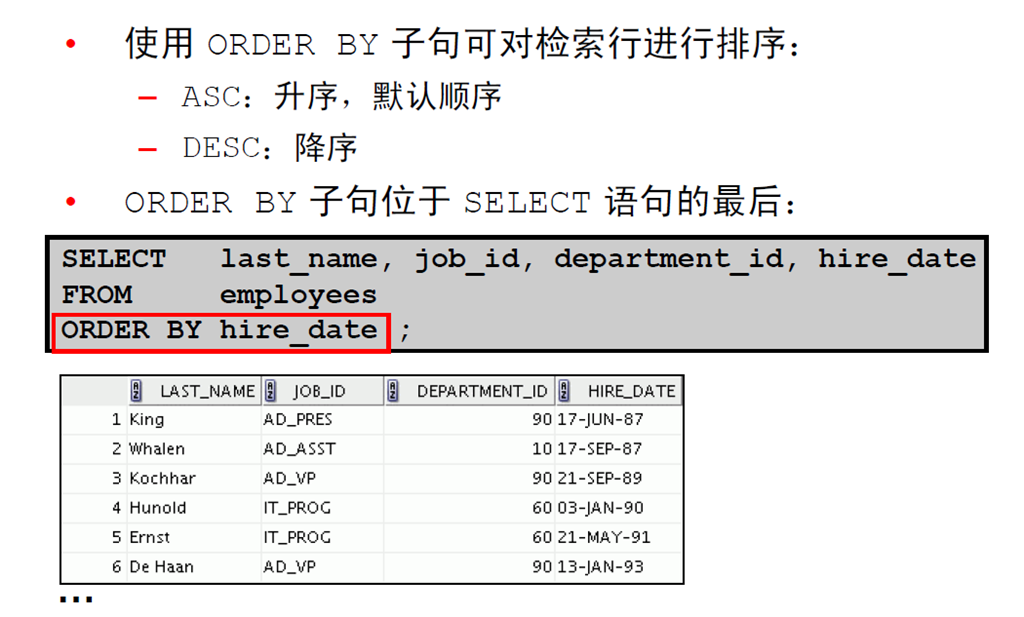
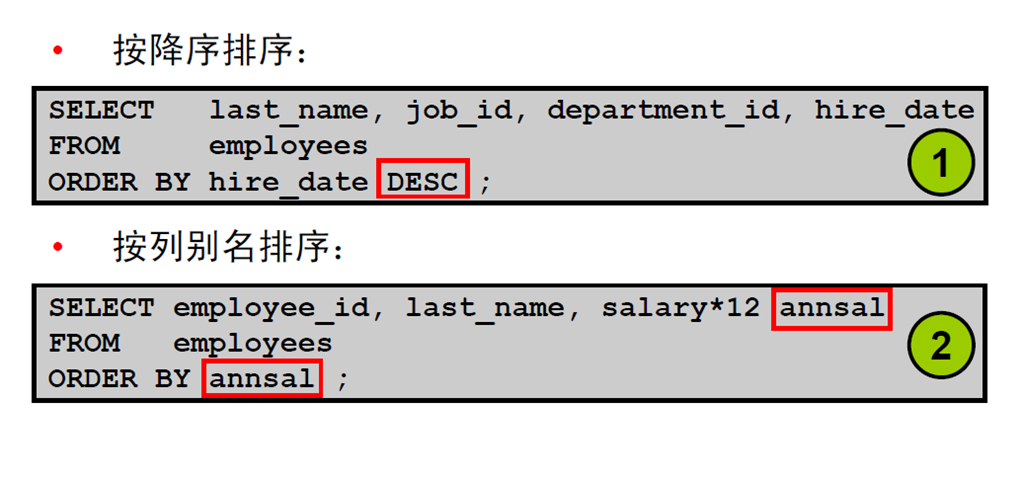
4:使用ORDER BY 子句对行进行排序
1:使用ORDER BY 子句
2:排序

5:替代变量
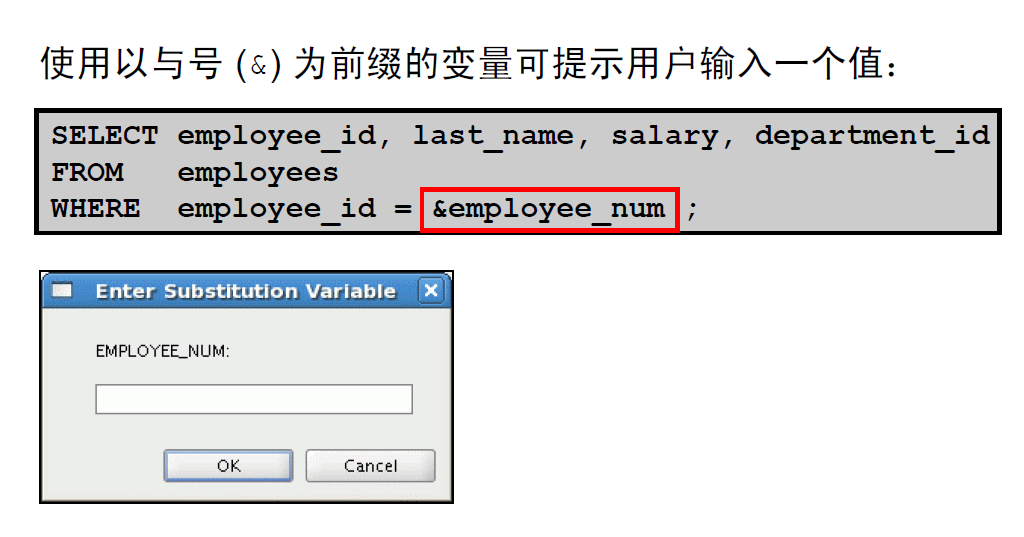
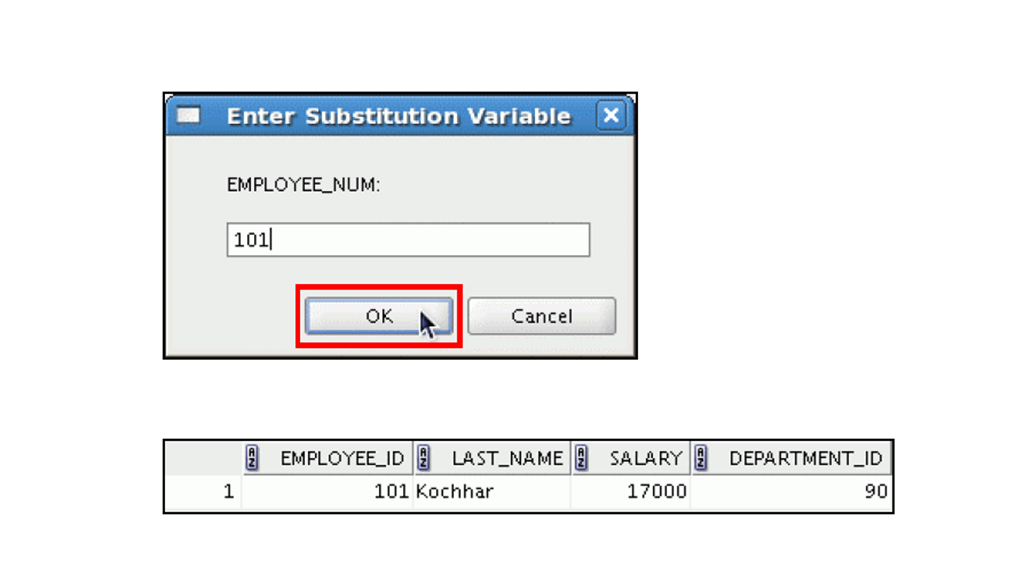
1:替代变量
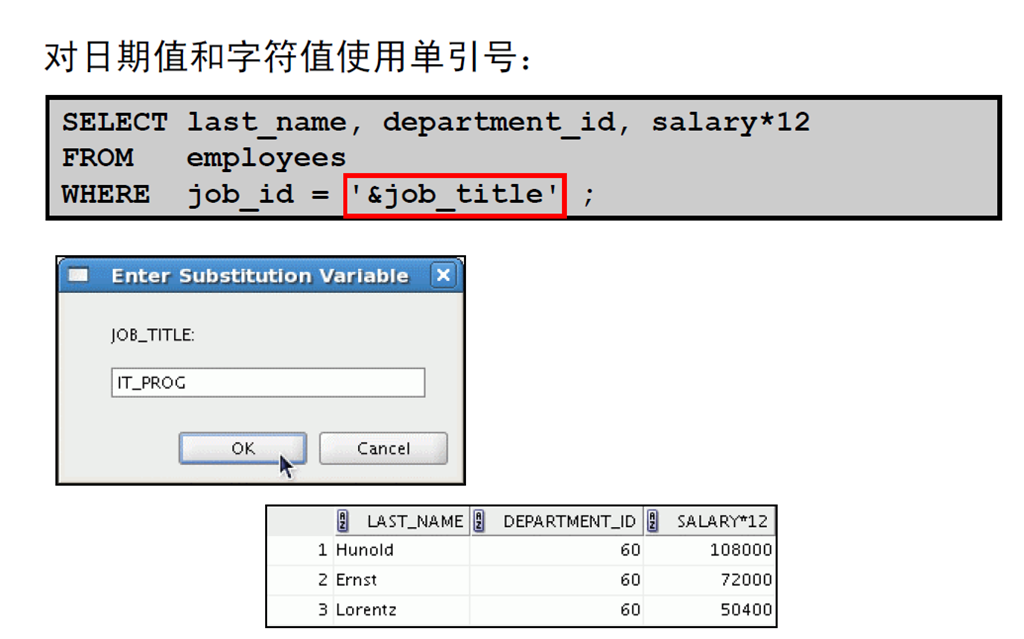
2:使用单与号替代变量
3:使用单与号替代变量
4:使用替代变量指定字符值和日期值
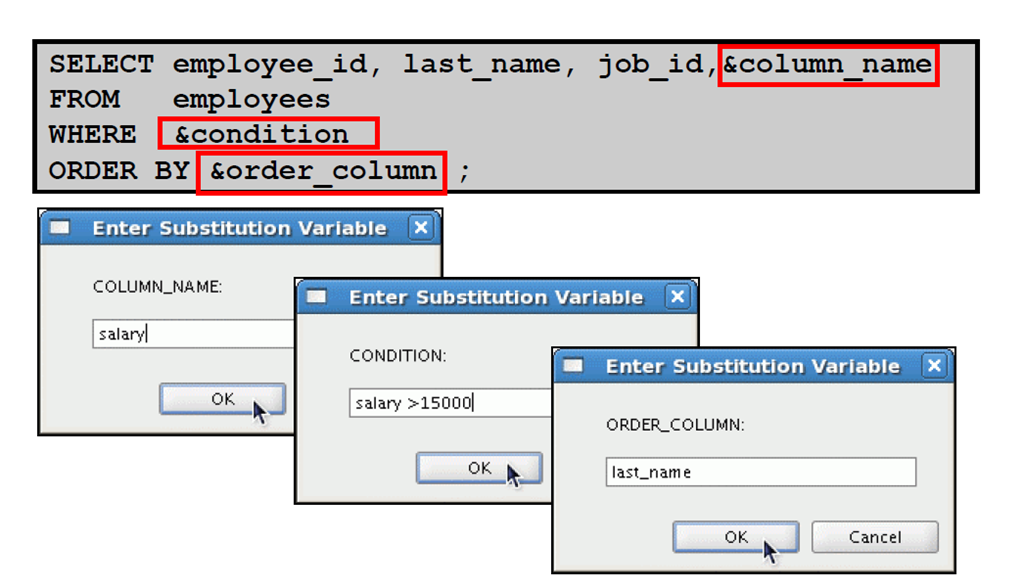
5:指定列名、表达式和文本
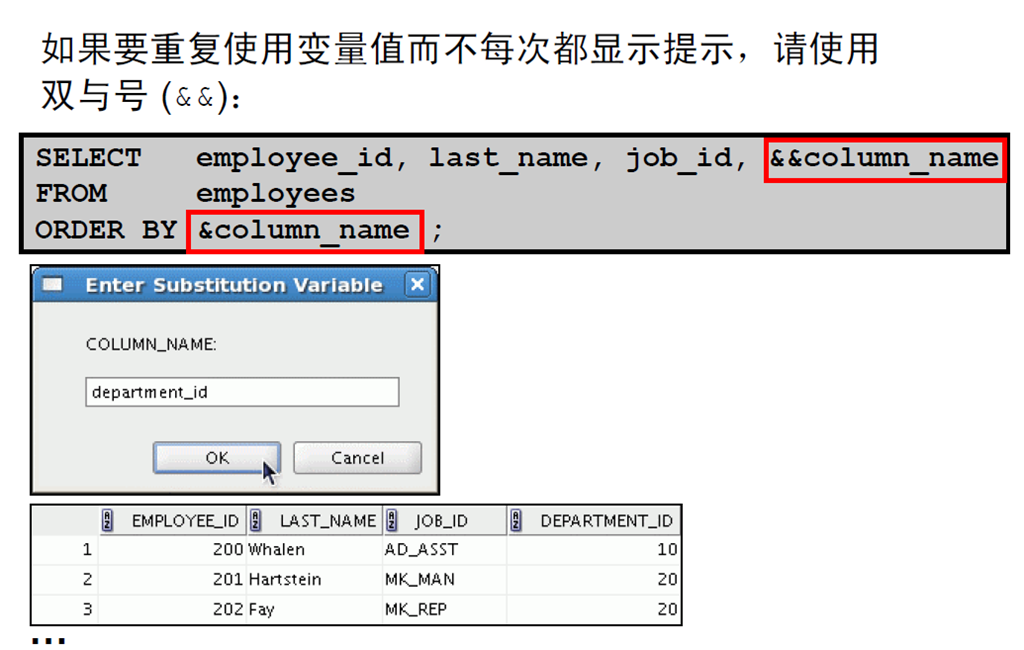
6:使用双与号替代变量


6:DEFINE 和VERIFY 命令
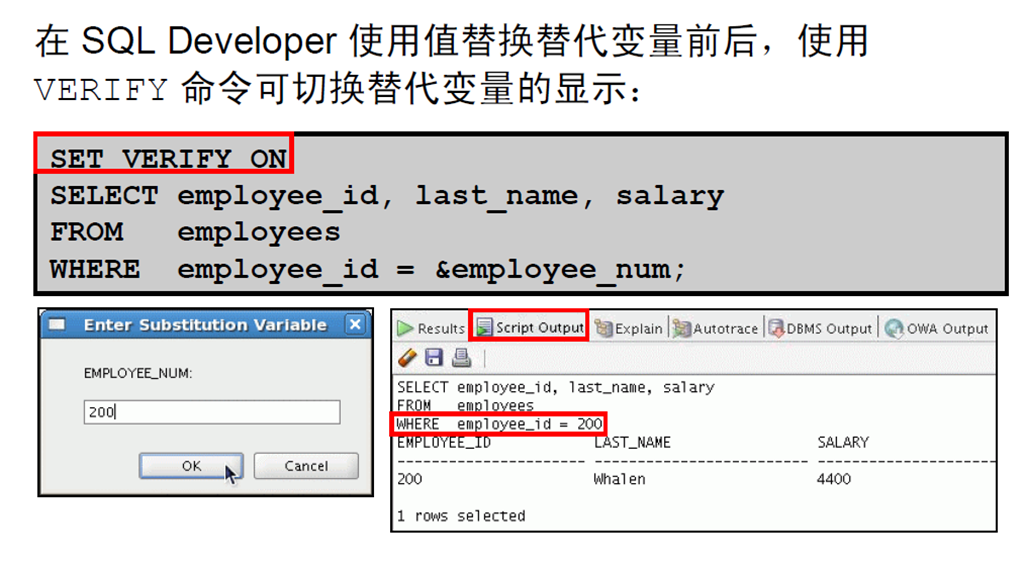
1:使用DEFINE 命令
2:使用VERIFY 命令

7:小结

第三章:使用单行函数定制输出
1:单行SQL 函数
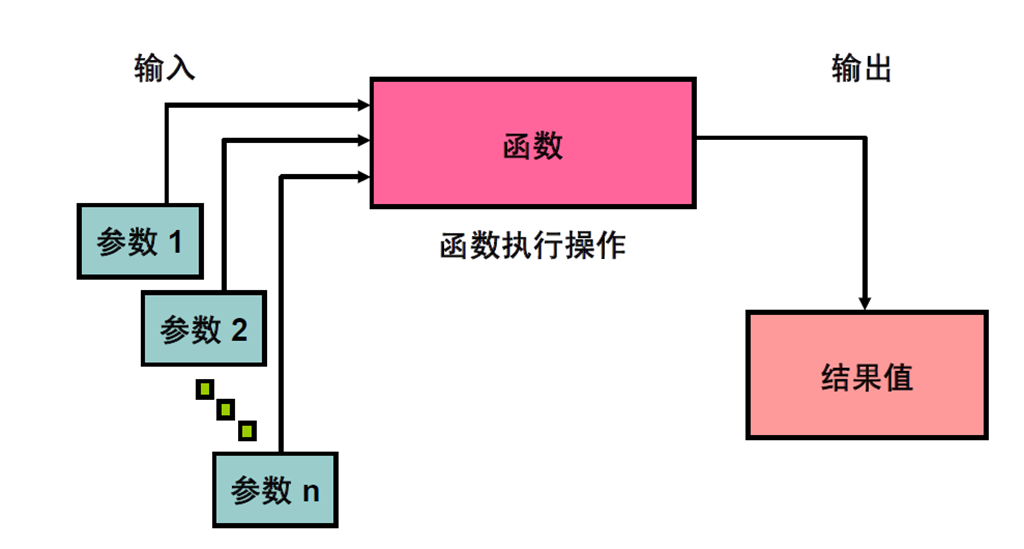
1:SQL 函数
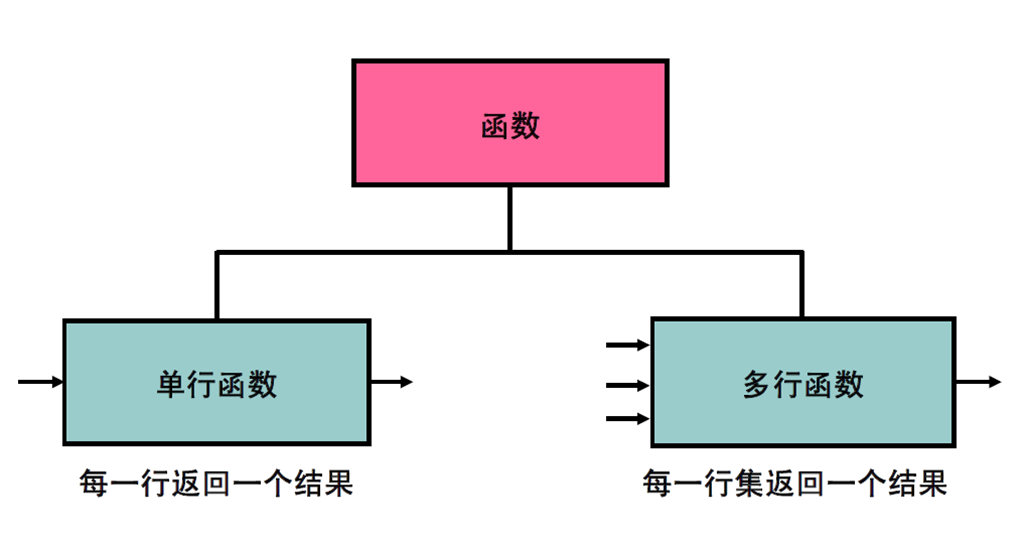
2:两种类型的SQL 函数
3:单行函数

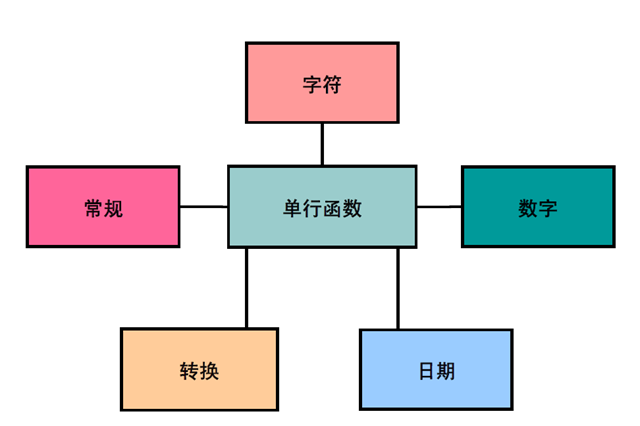
2:字符函数
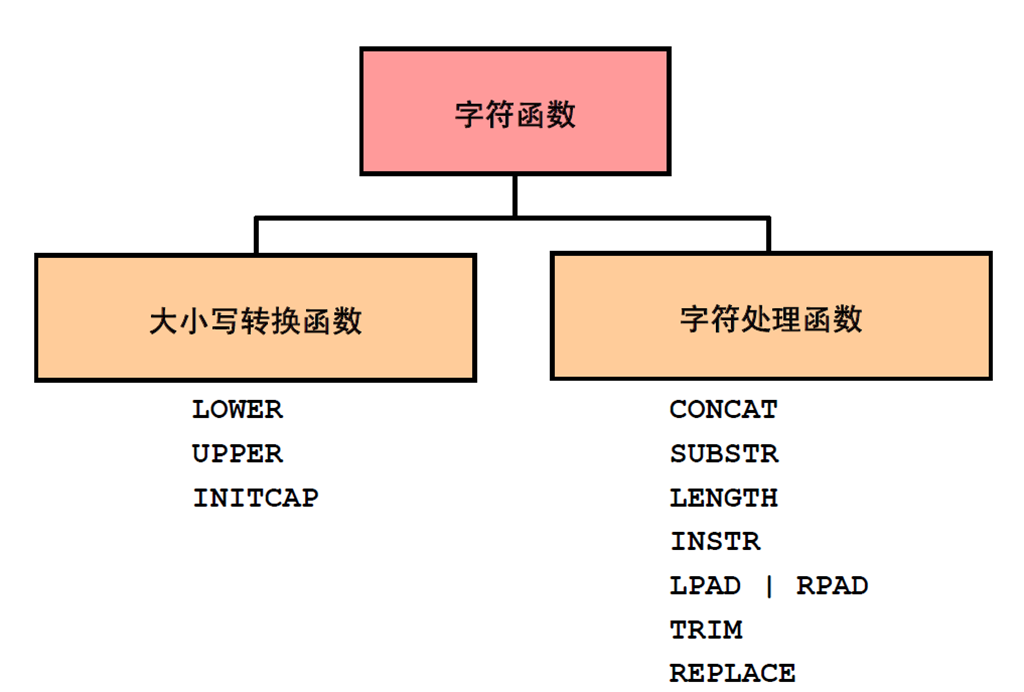
1:字符函数
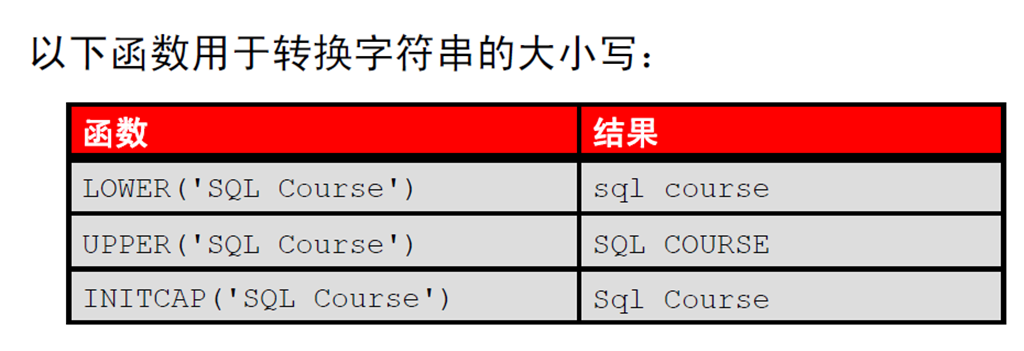
2:大小写转换函数
3:使用大小写转换函数
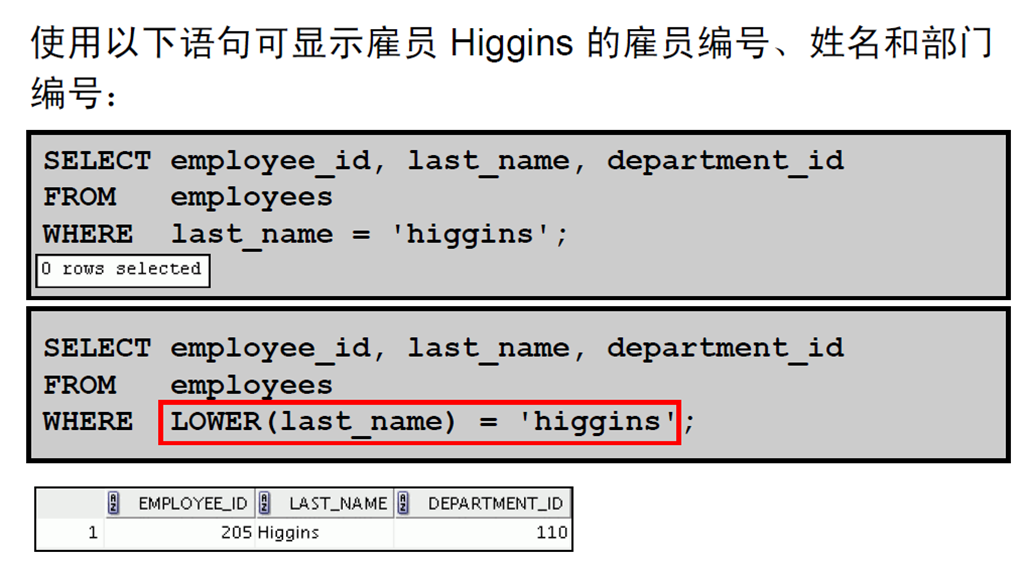
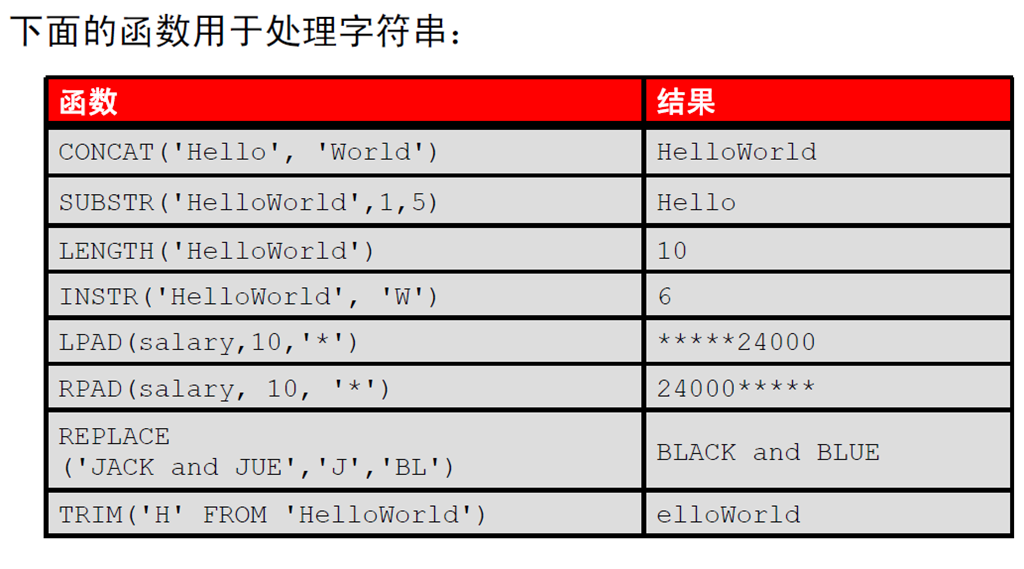
4:字符处理函数
5:使用字符处理函数
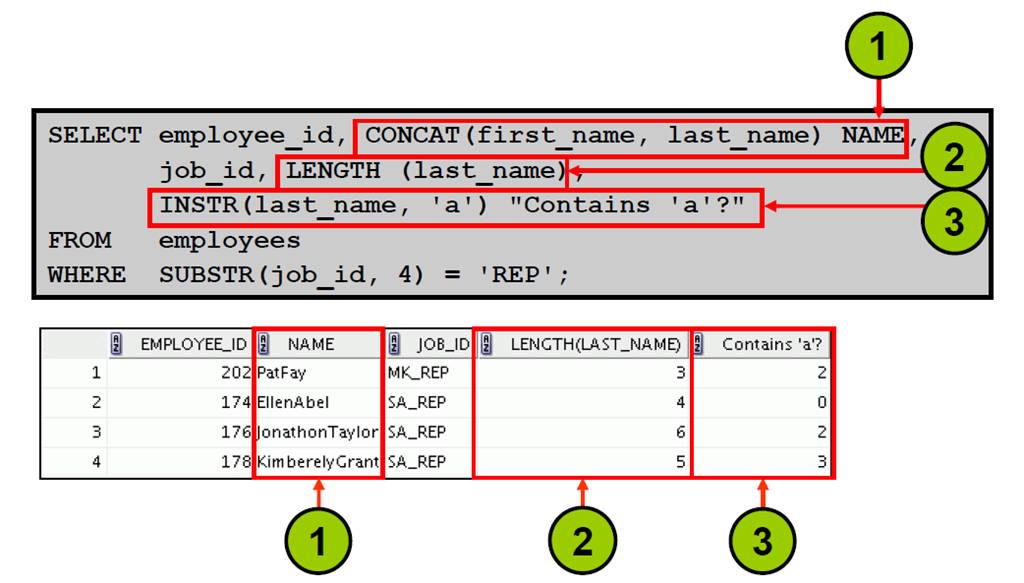
3:数字函数
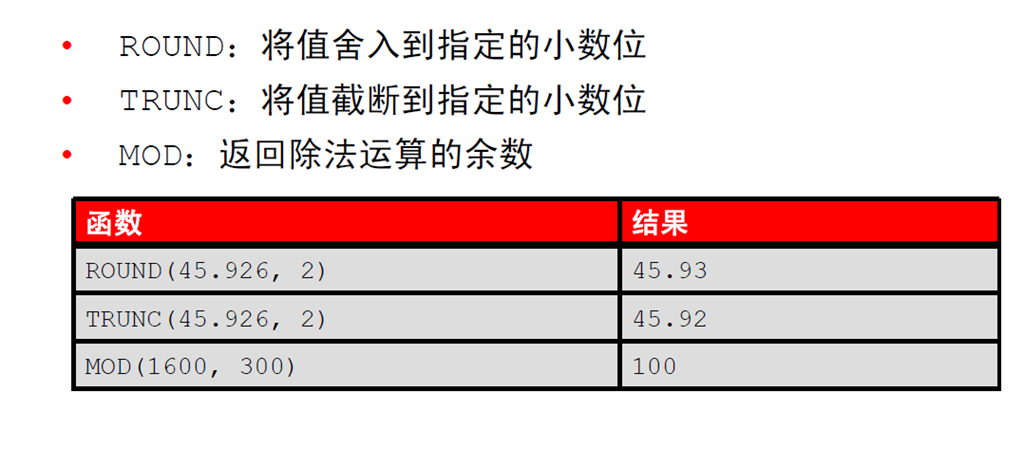
1:数字函数
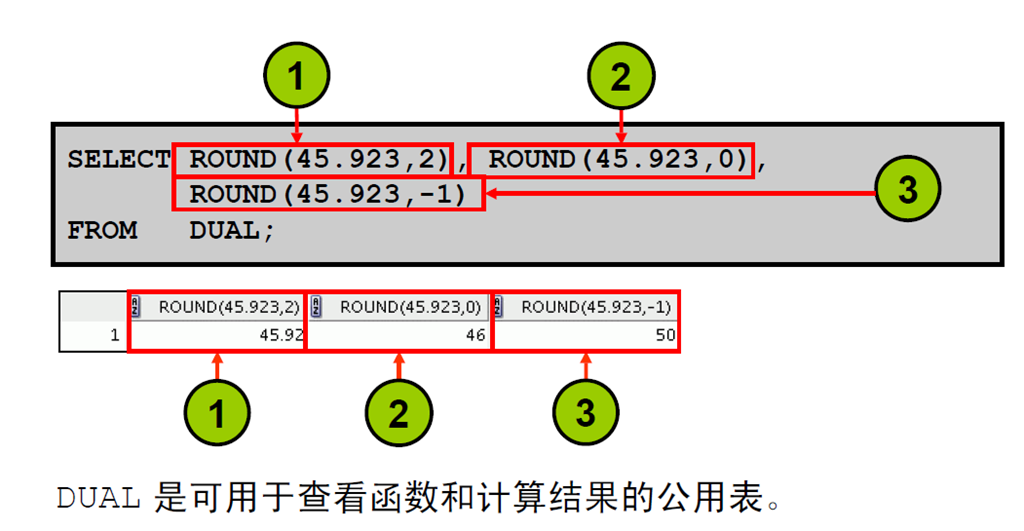
2:使用ROUND 函数
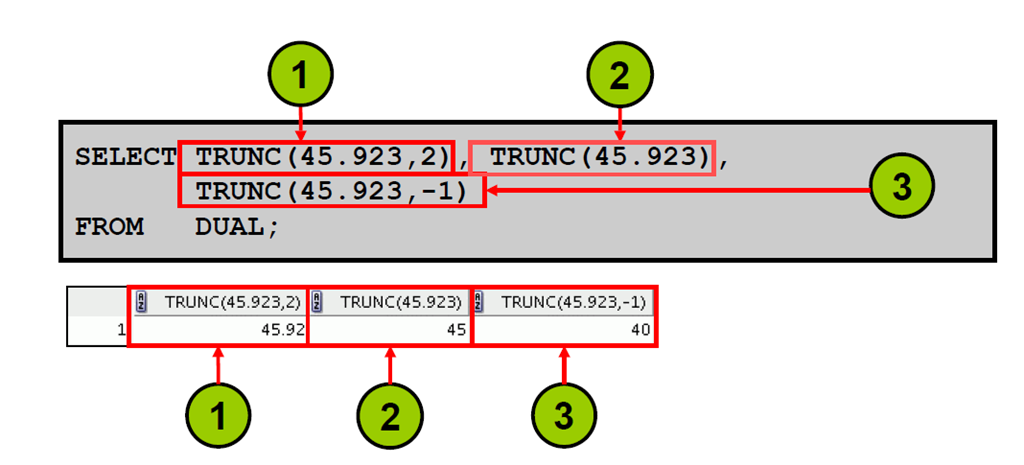
3:使用TRUNC 函数
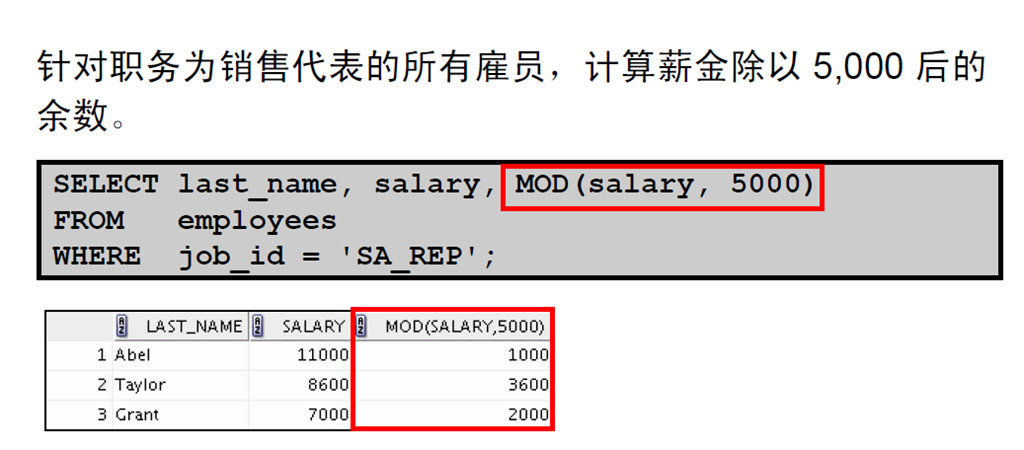
4:使用MOD 函数
4:处理日期
1:处理日期
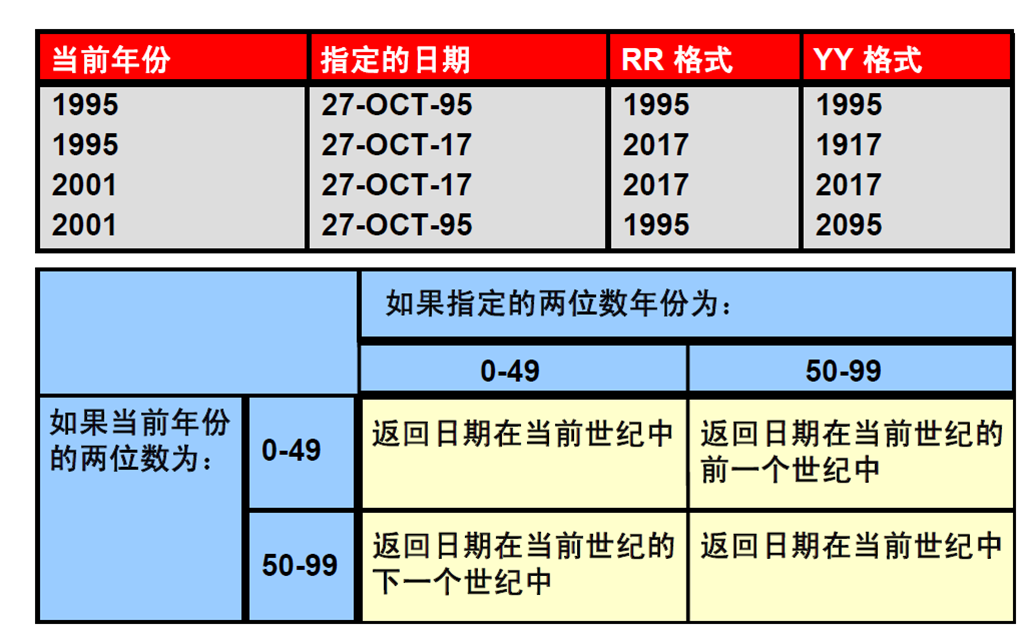
2:RR 日期格式
3:使用SYSDATE 函数
4:与日期有关的运算
5:使用算术运算符处理日期
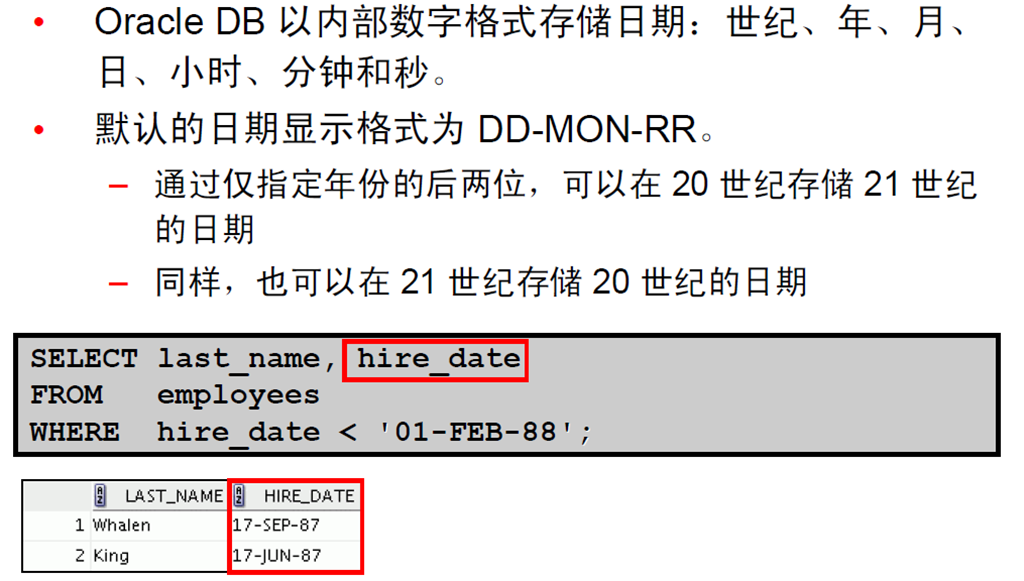


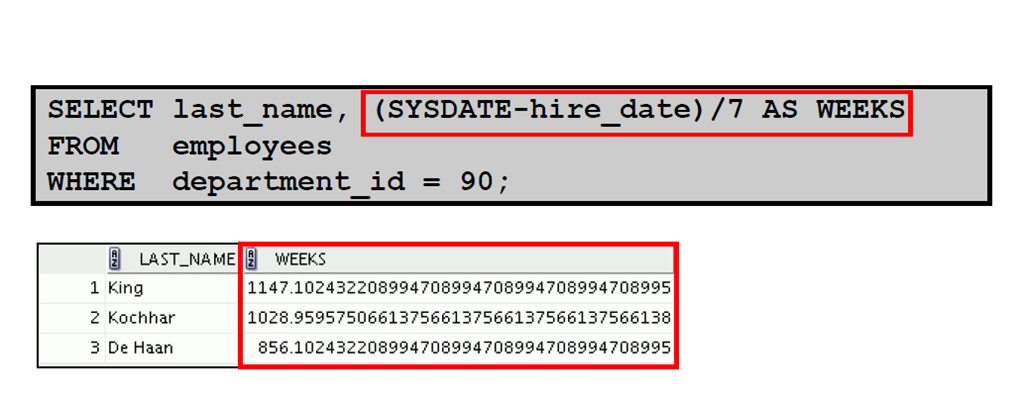
5:日期函数
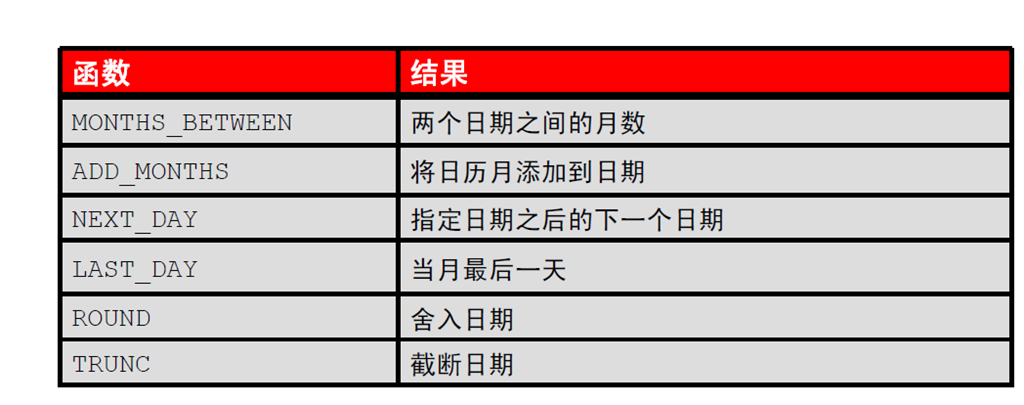
1:日期处理函数
2:使用日期函数
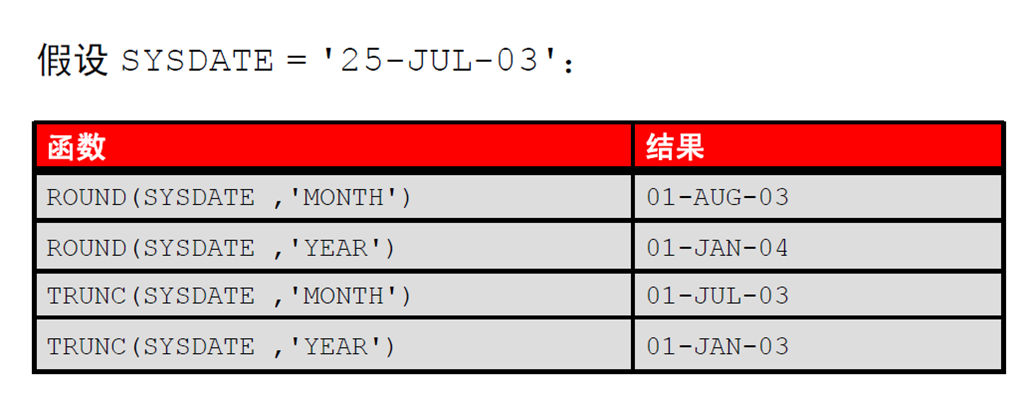
3:使用ROUND 函数和TRUNC 函数处理日期
4:小测验
5:小结



第四章:使用转换函数和条件表达式
1:隐式和显式数据类型转换
1:转换函数
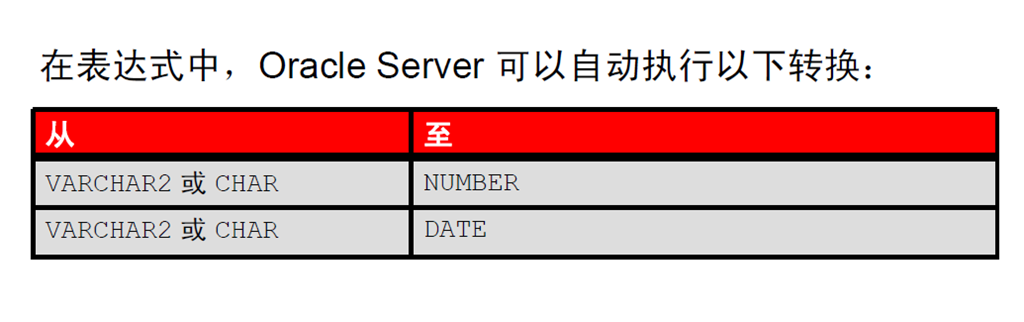
2:隐式数据类型转换
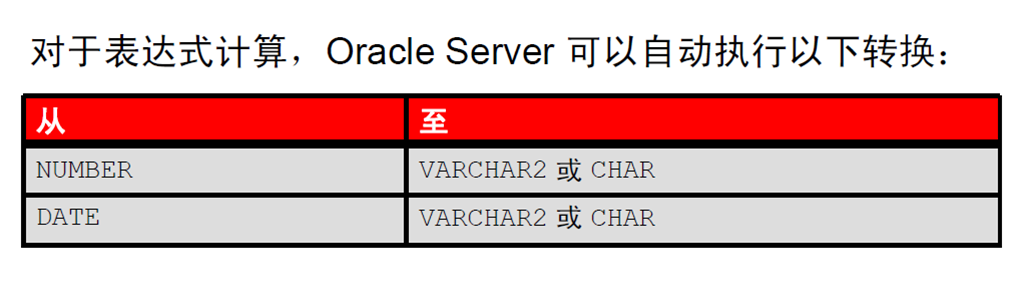
3:显式数据类型转换

2:TO_CHAR、TO_DATE、TO_NUMBER 函数
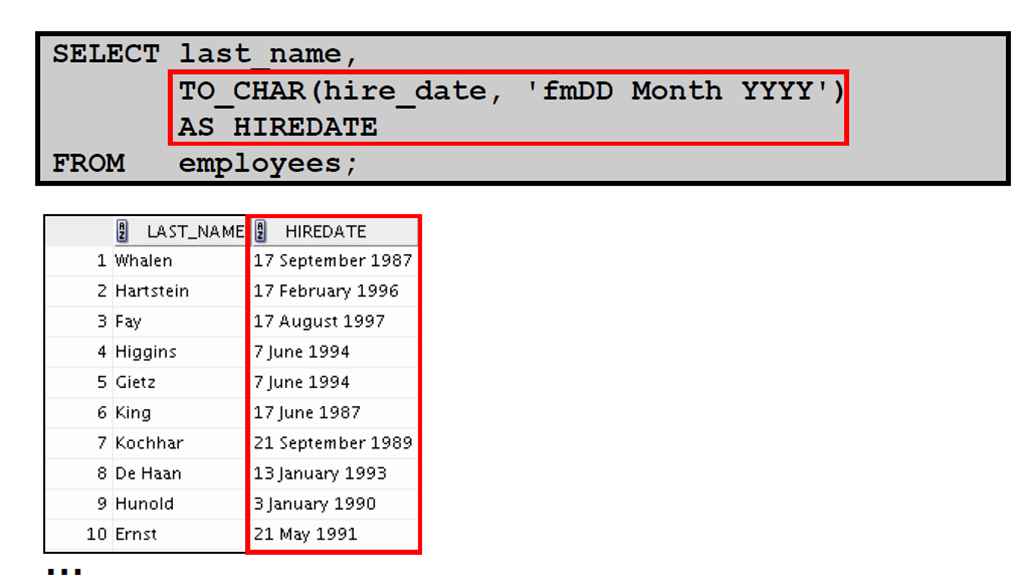
1:使用TO_CHAR 函数处理日期
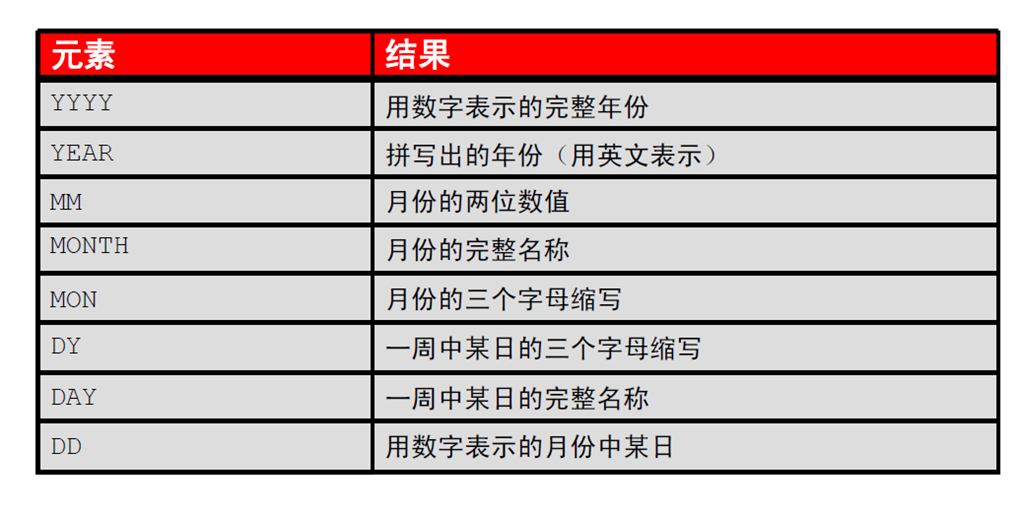
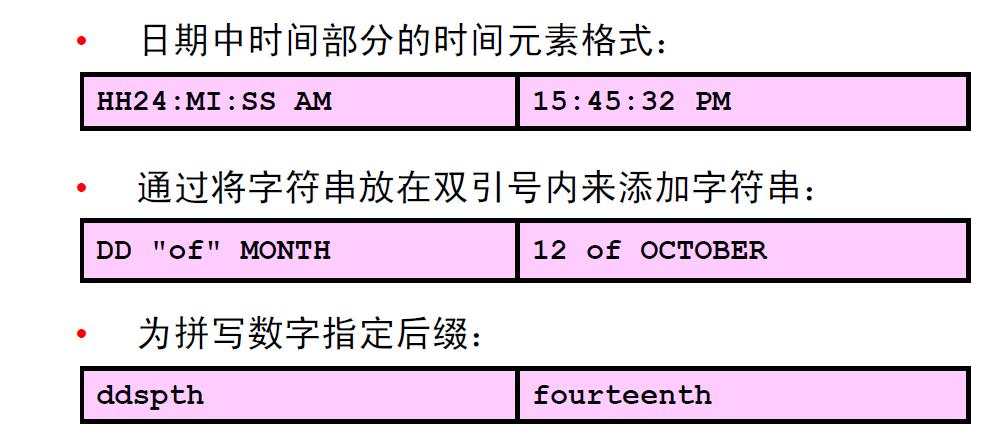
2:日期格式样式的元素
3:日期格式样式的元素
4:使用TO_CHAR 函数处理日期
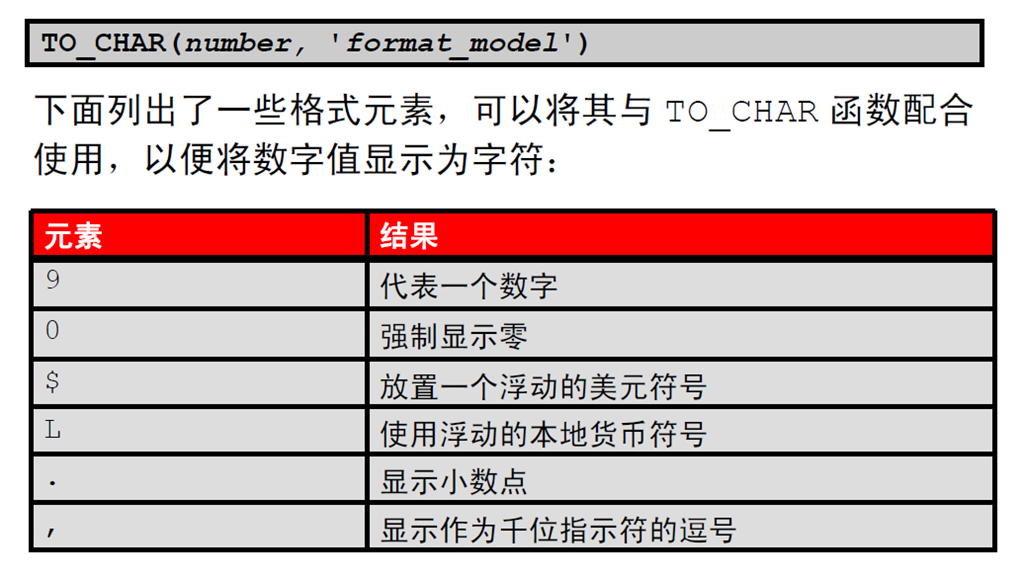
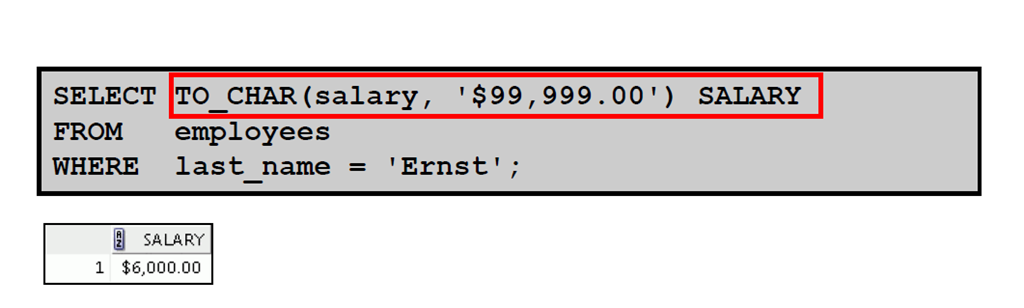
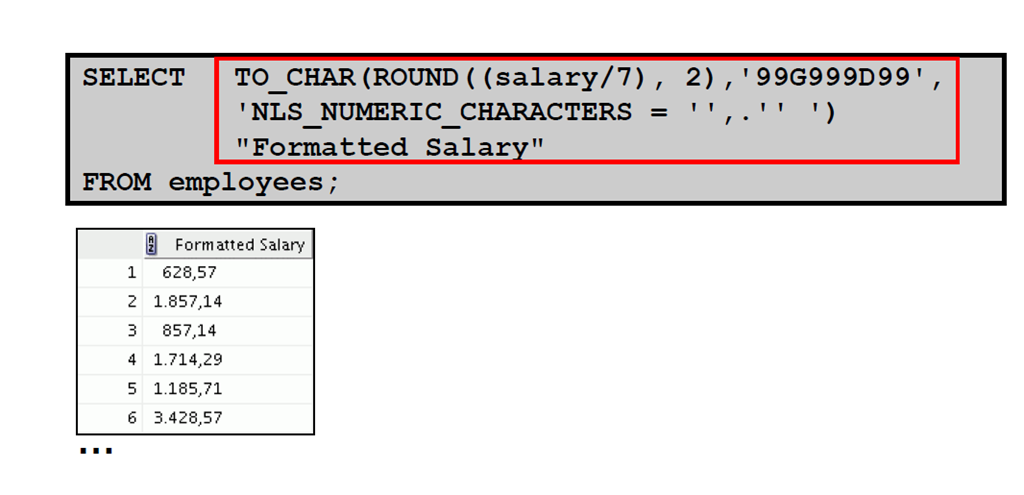
5:使用TO_CHAR 函数处理数字
6:使用TO_NUMBER 和TO_DATE 函数
7:将TO_CHAR 和TO_DATE 函数 与RR 日期格式结合使用



3:嵌套函数
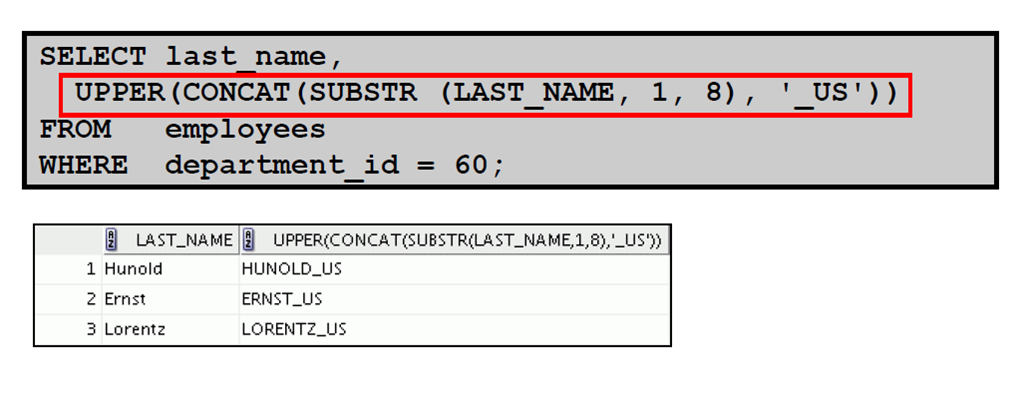
1:嵌套函数
2:嵌套函数:示例1
2:嵌套函数:示例2

4:常规函数: – NVL – NVL2 – NULLIF – COALESCE
1:常规函数
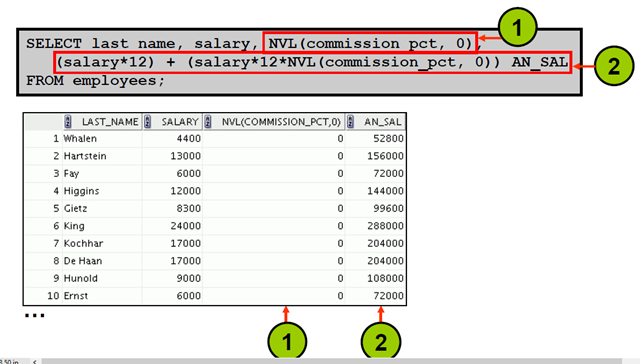
2:NVL 函数
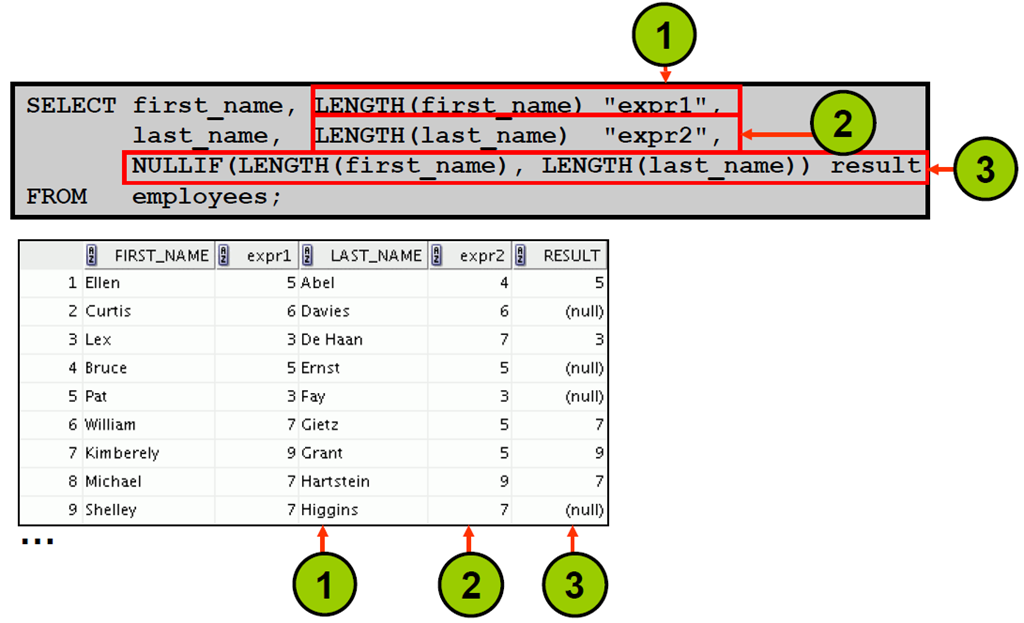
3:使用NULLIF 函数
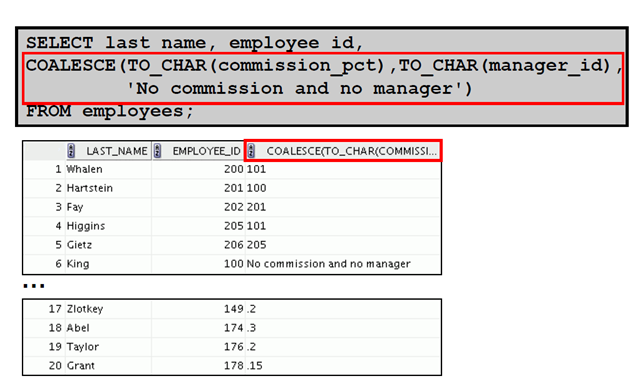
4:使用COALESCE 函数




5:条件表达式: – CASE – DECODE
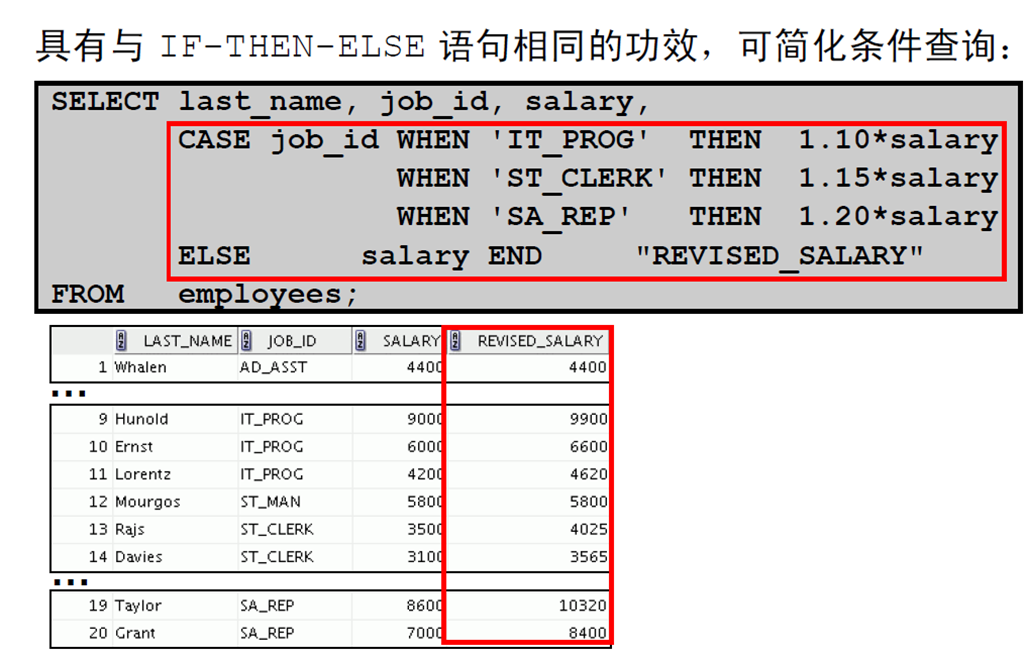
1:条件表达式
2:CASE 表达式
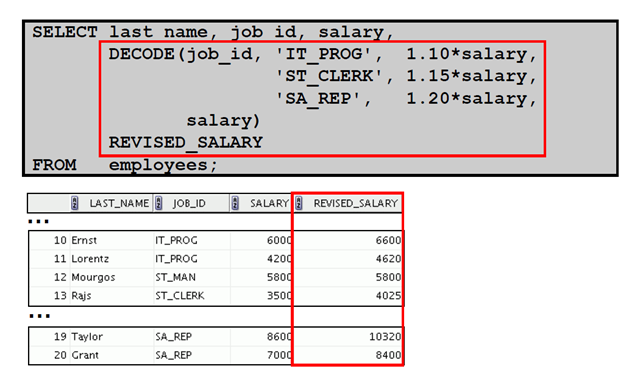
3:DECODE 函数



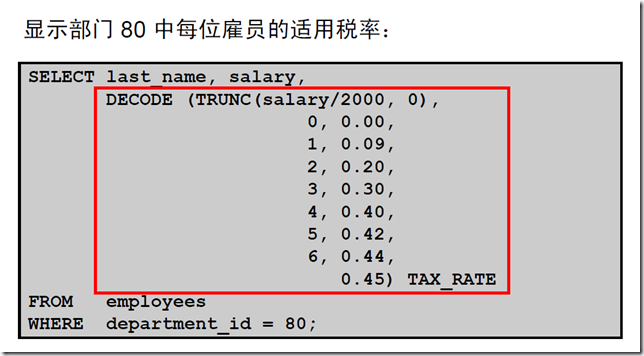
第五章:使用组函数报告聚集数据
1: 组函数: – 类型和语法 – 使用AVG、SUM、MIN、MAX、COUNT – 在组函数中使用DISTINCT 关键字 – 组函数中的NULL 值
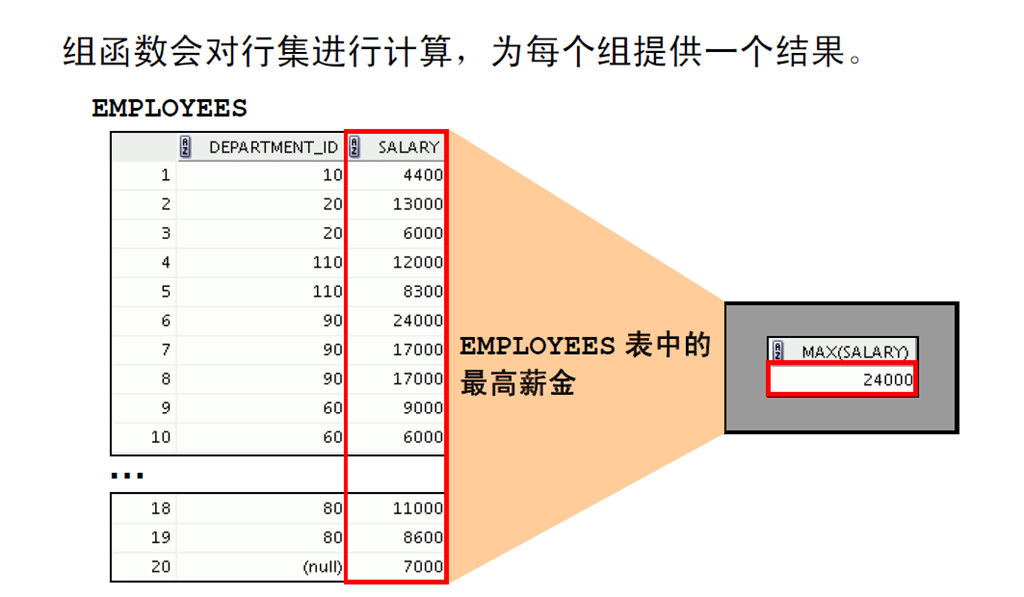
1:何谓组函数
2:组函数的类型
3:组函数:语法
4:使用AVG 和SUM 函数
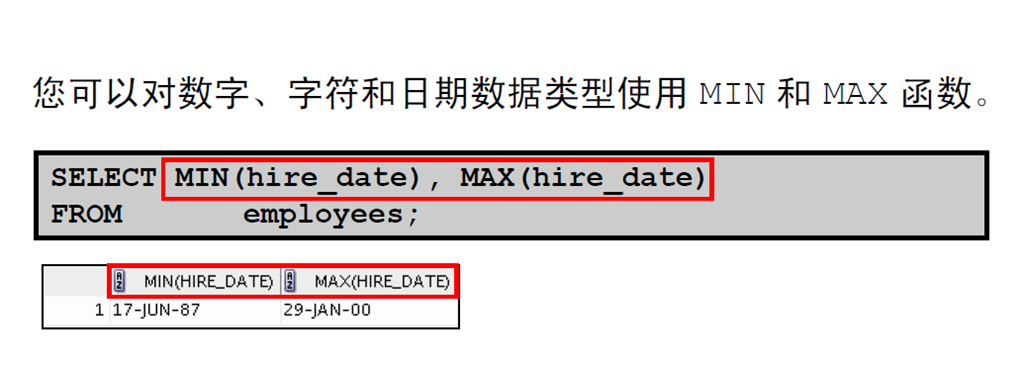
5:使用MIN 和MAX 函数
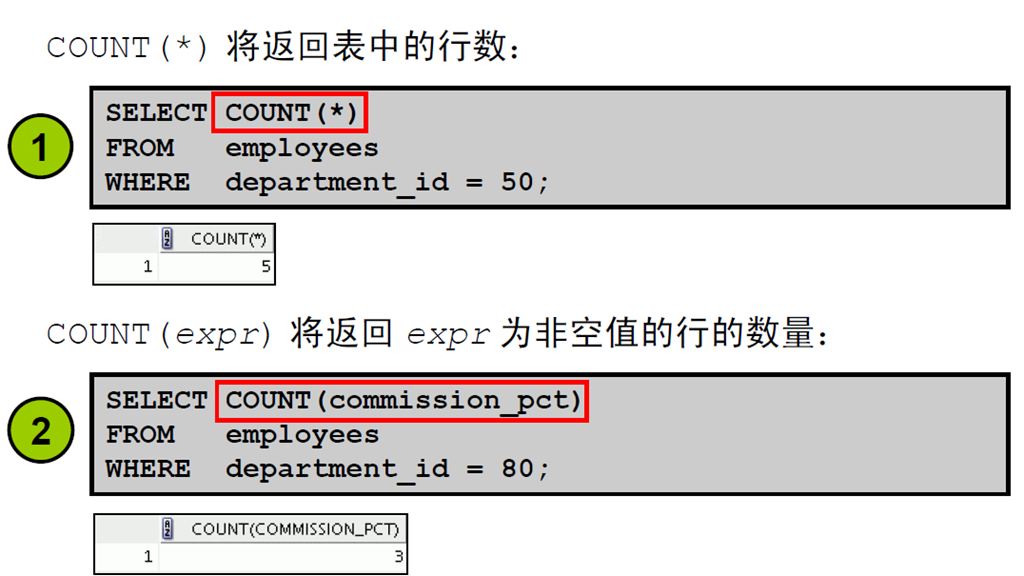
6:使用COUNT 函数
7:使用DISTINCT 关键字
8:组函数和空值




2:对行进行分组: – GROUP BY 子句 – HAVING 子句
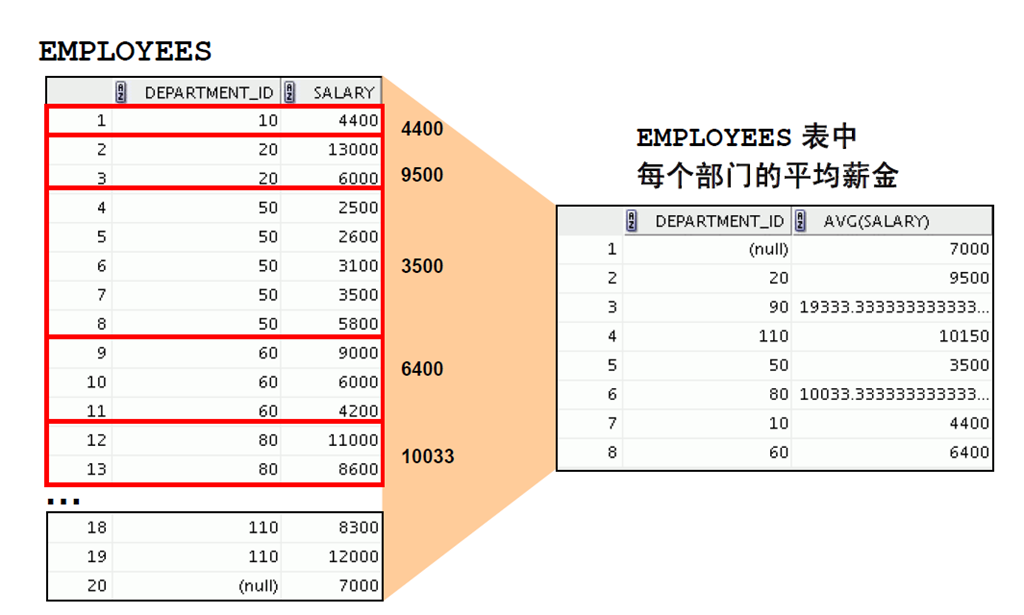
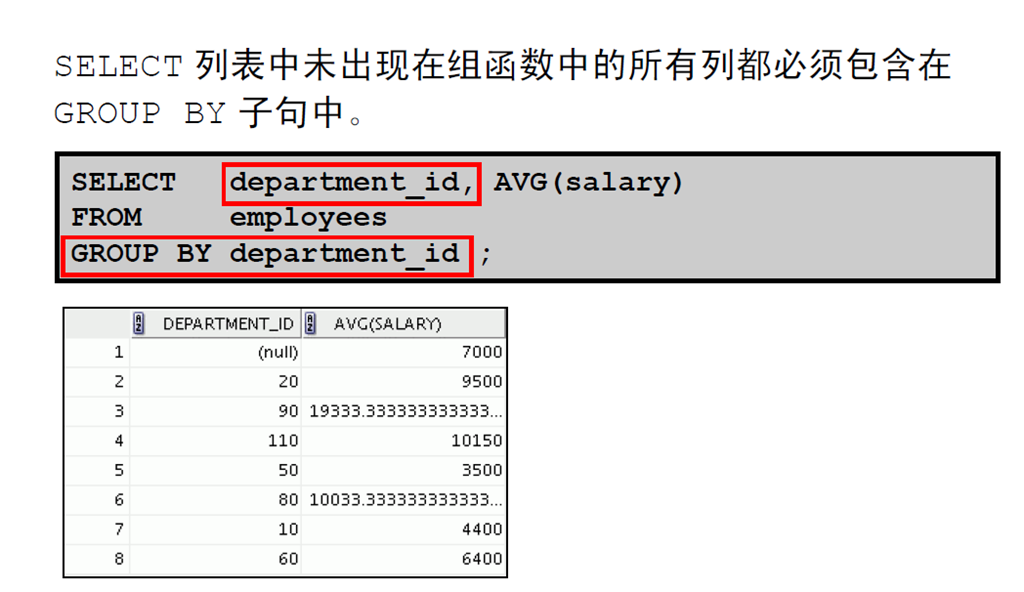
1:创建数据组
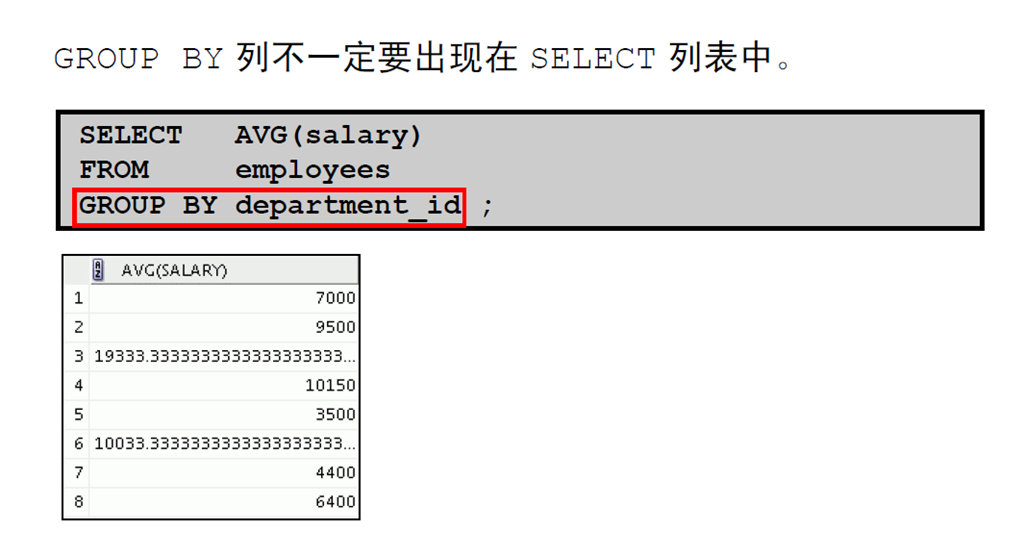
2:创建数据组:GROUP BY 子句的语法
3:按多个列进行分组
4:对多个列使用GROUP BY 子句
5:使用组函数的非法查询
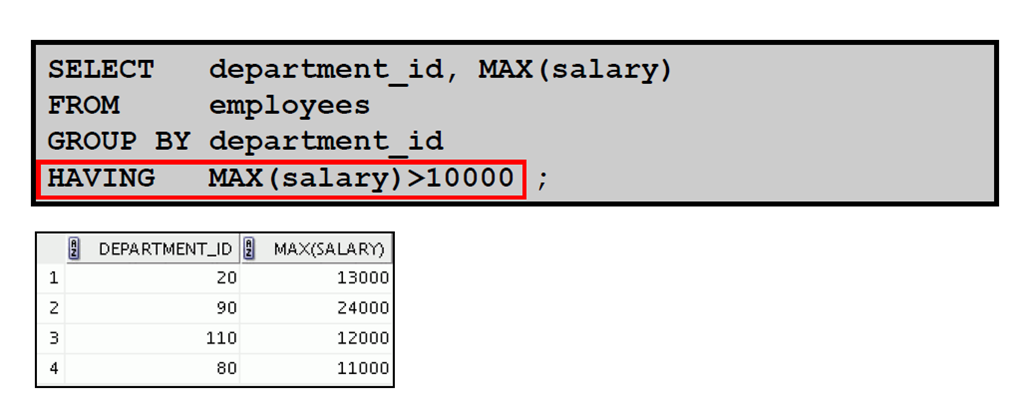
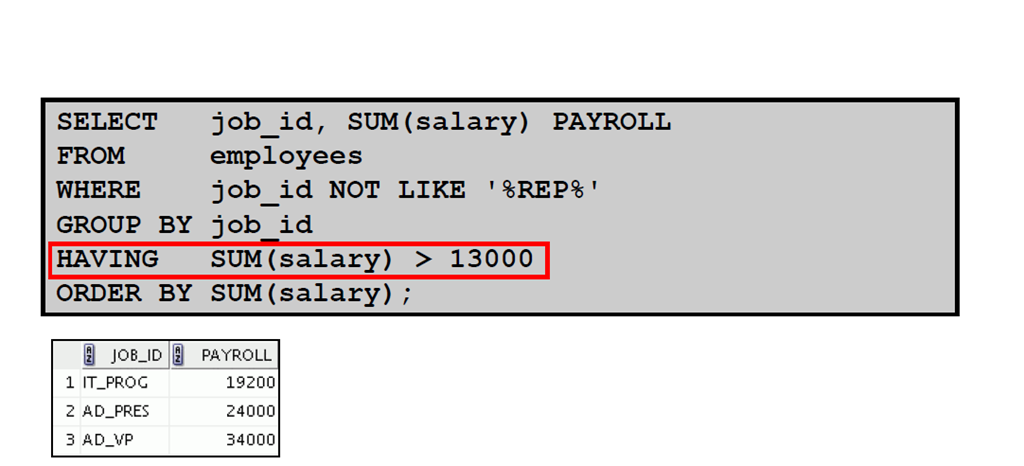
6:限定组结果
7:使用HAVING 子句限定组结果

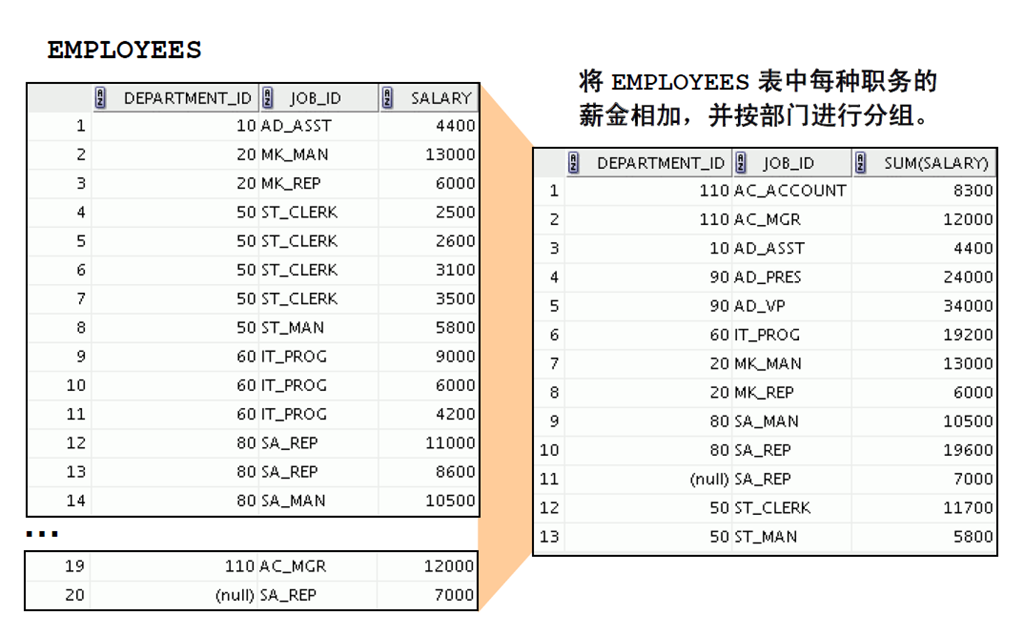
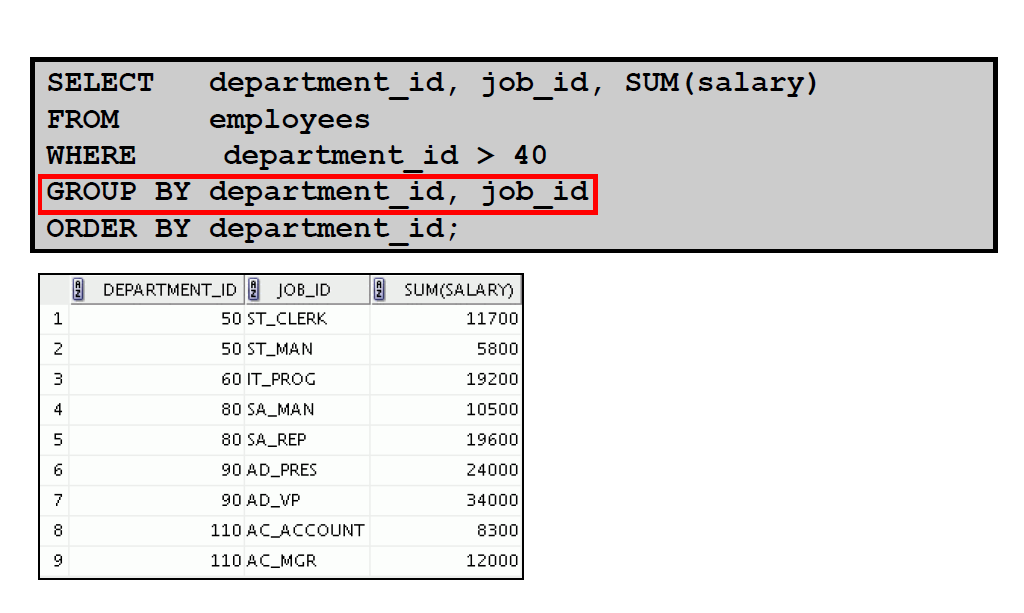

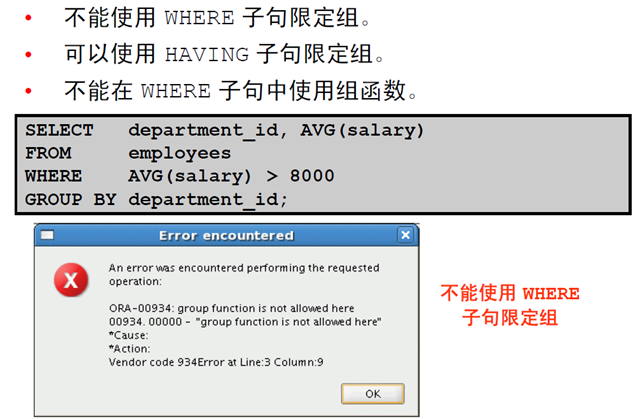
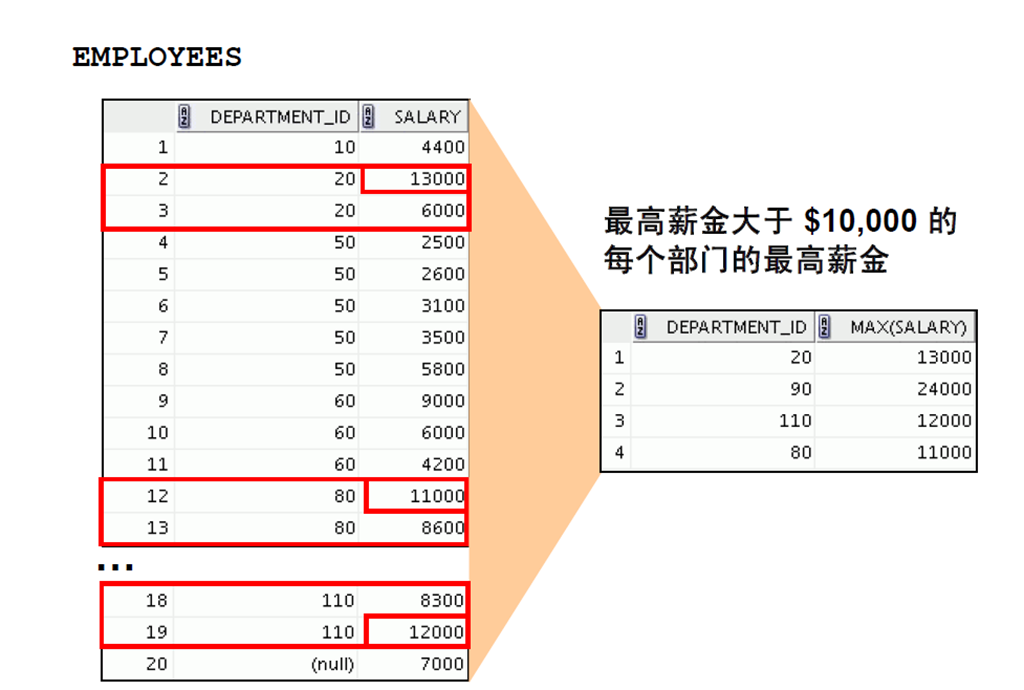

4:嵌套组函数
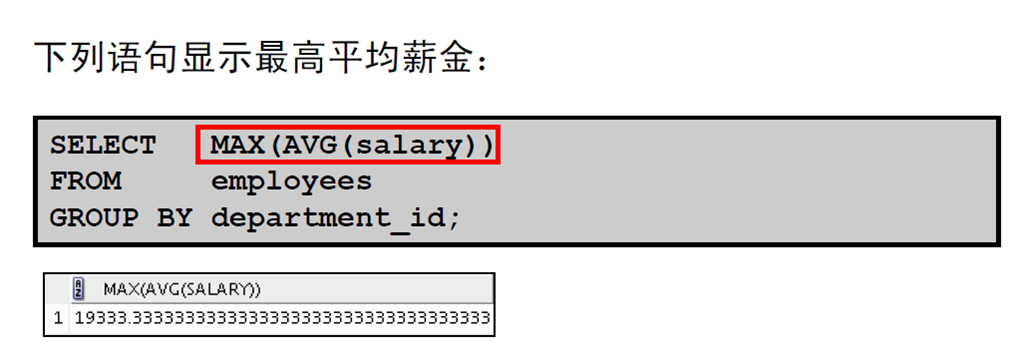
1:嵌套组函数
第六章:使用联接显示多个表中的数据
1:JOIN 的类型及其语法
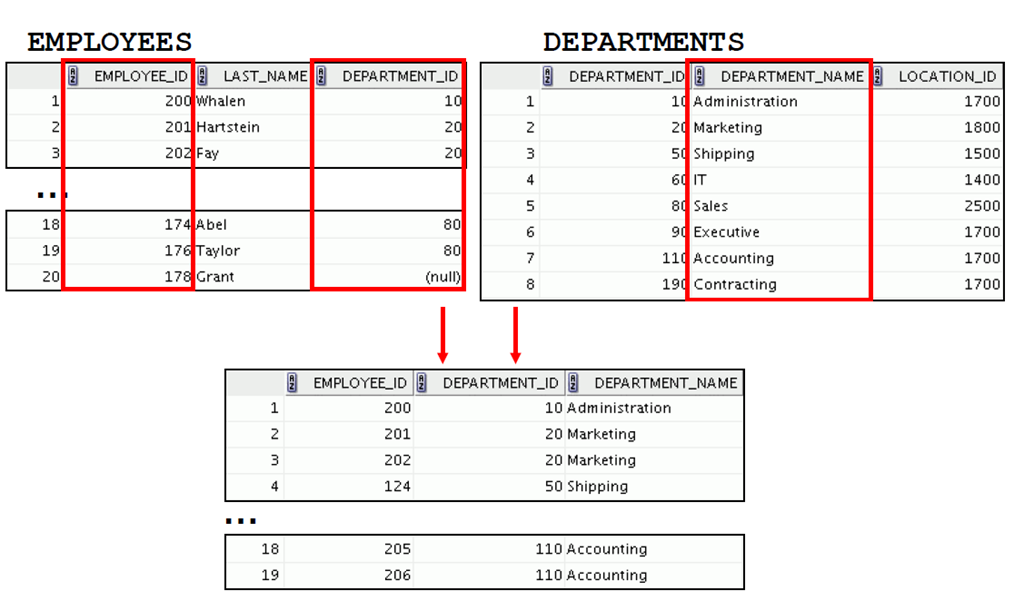
1:获取多个表中的数据
2:联接类型
3:使用SQL:1999 语法将表联接起来
4:限定不确定的列名



2:自然联接: – USING 子句 – ON 子句
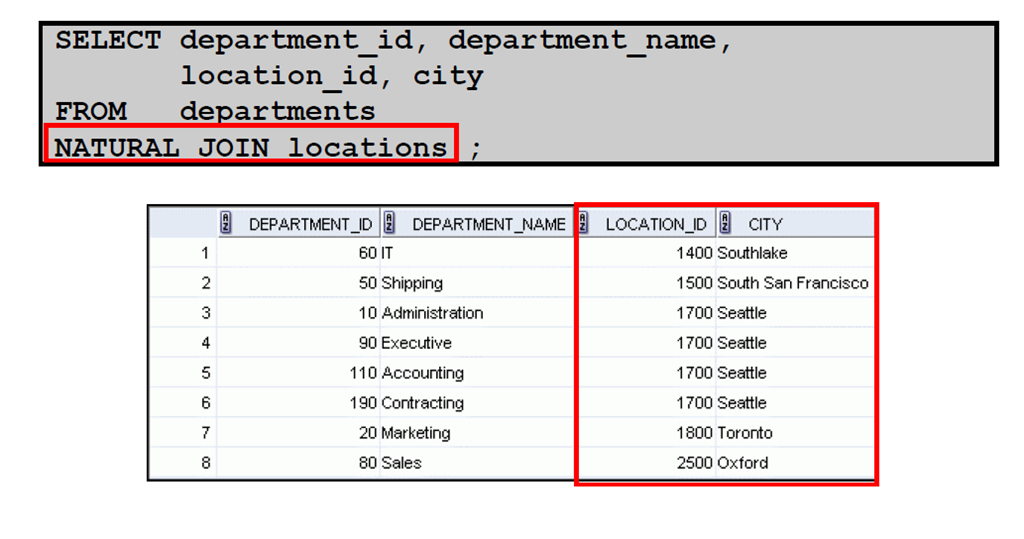
1:创建自然联接
2:使用自然联接检索记录
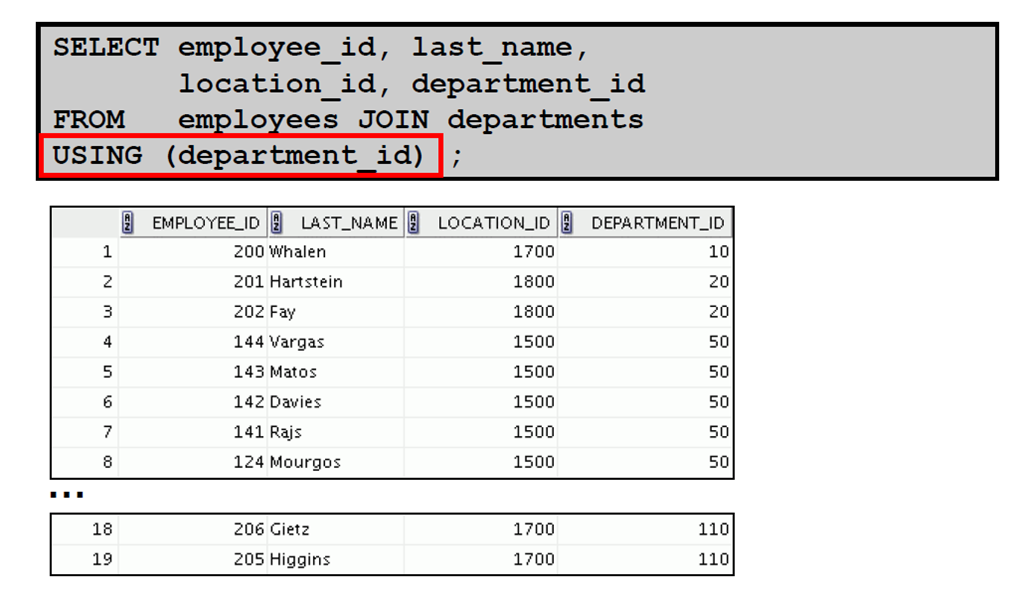
3:使用USING 子句创建联接
4:联接列名
5:使用USING 子句检索记录
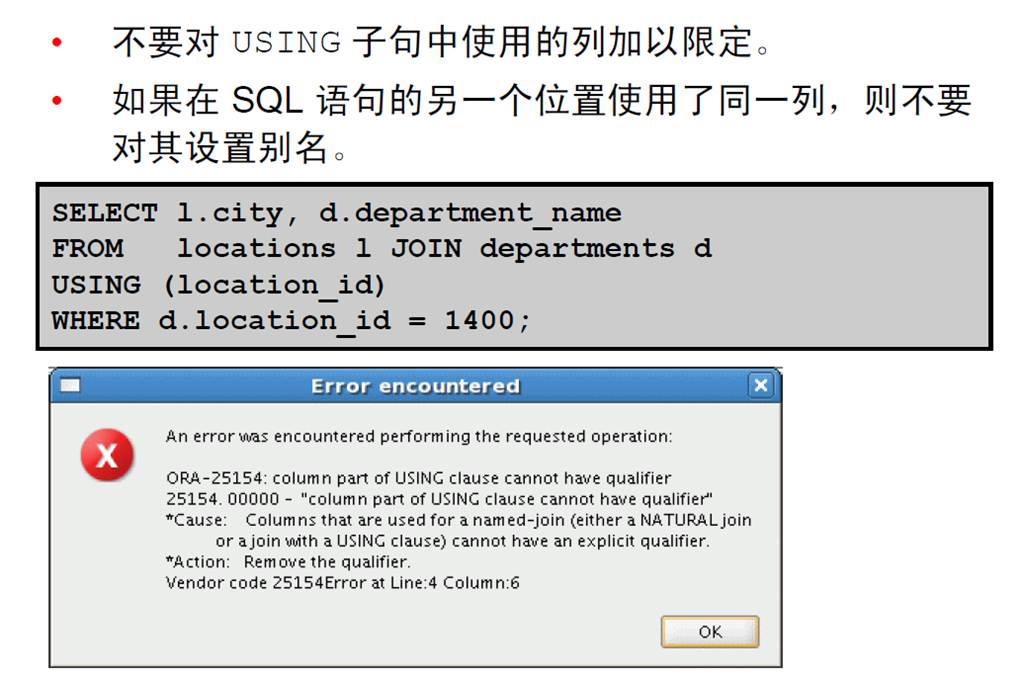
6:在USING 子句中使用表别名
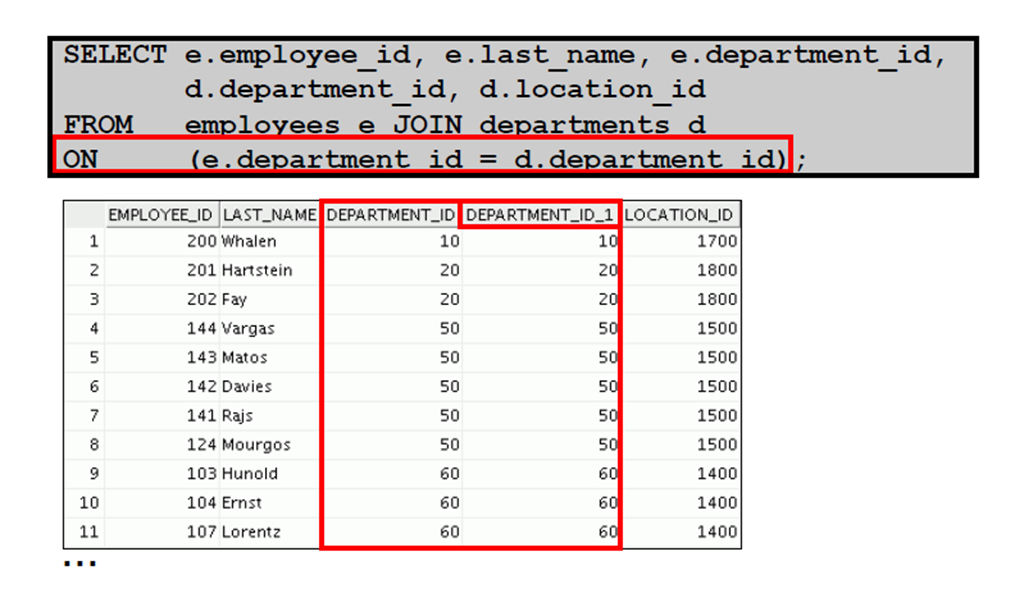
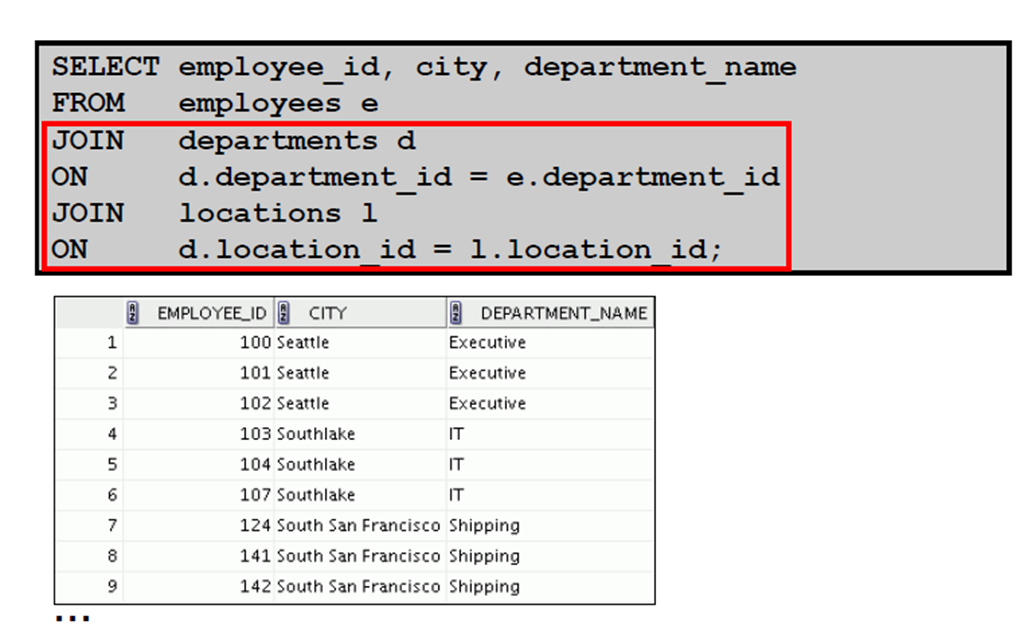
7:使用ON 子句创建联接
8:使用ON 子句创建三向联接
9:对联接应用附加条件





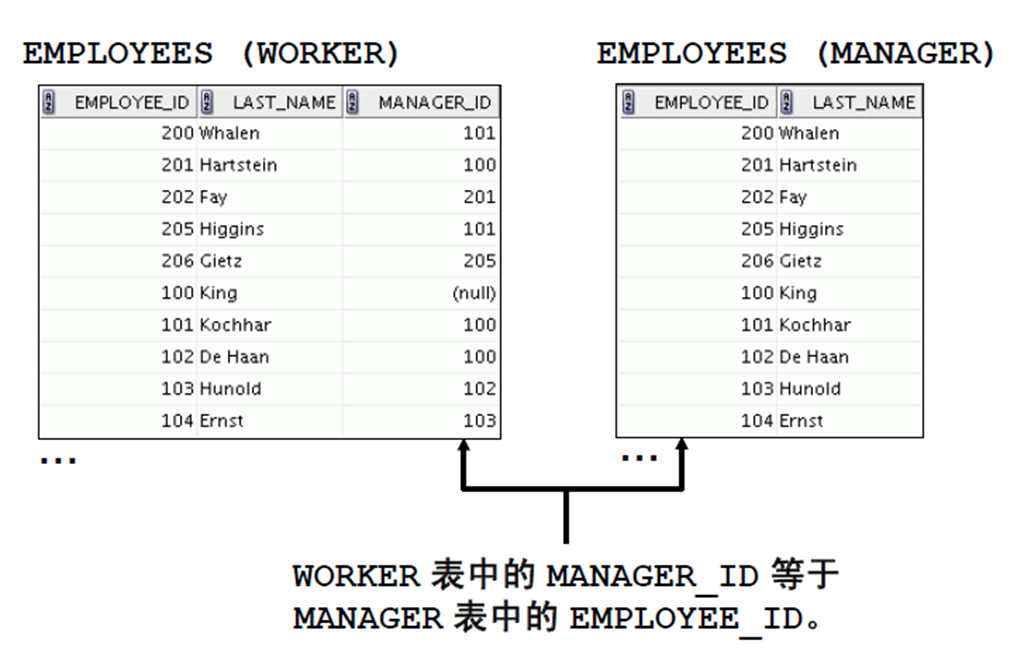
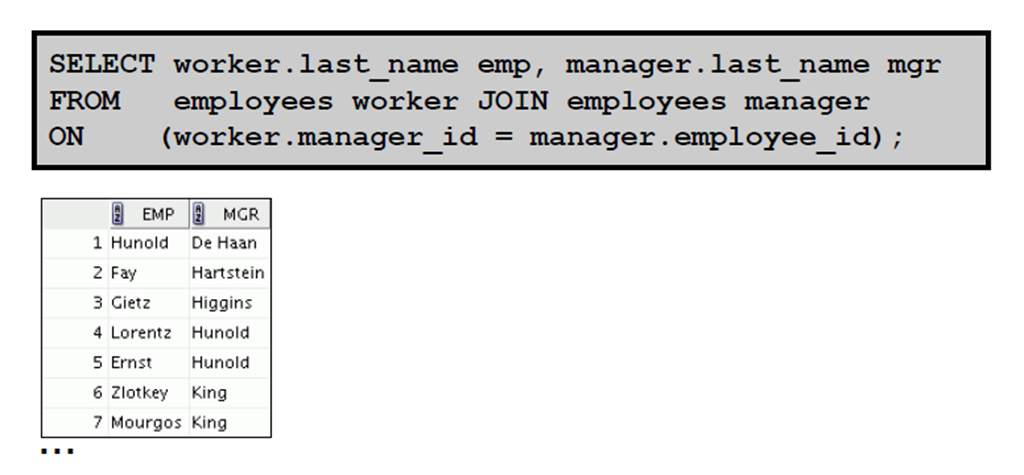
3:自联接
1:将表联接到自身
2:使用ON 子句进行自联接
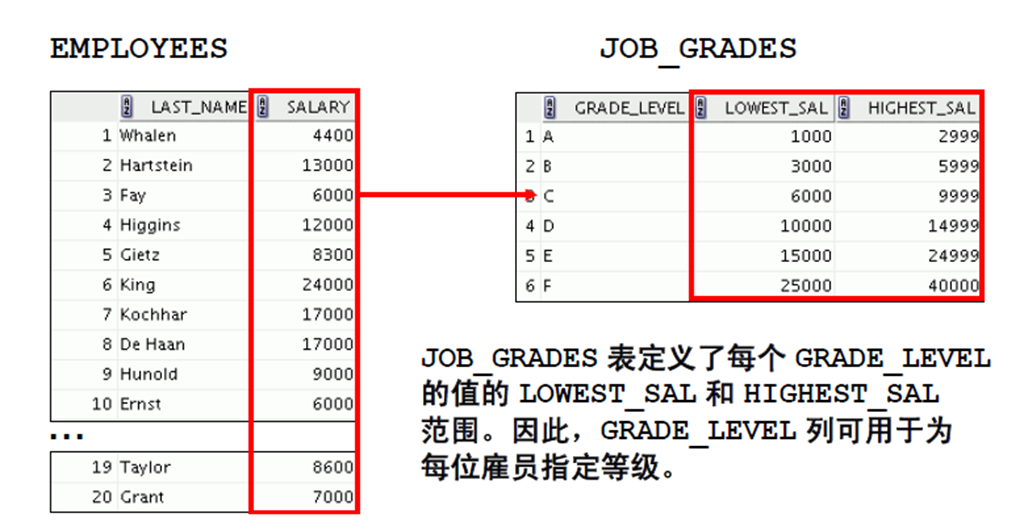
3:非等值联接
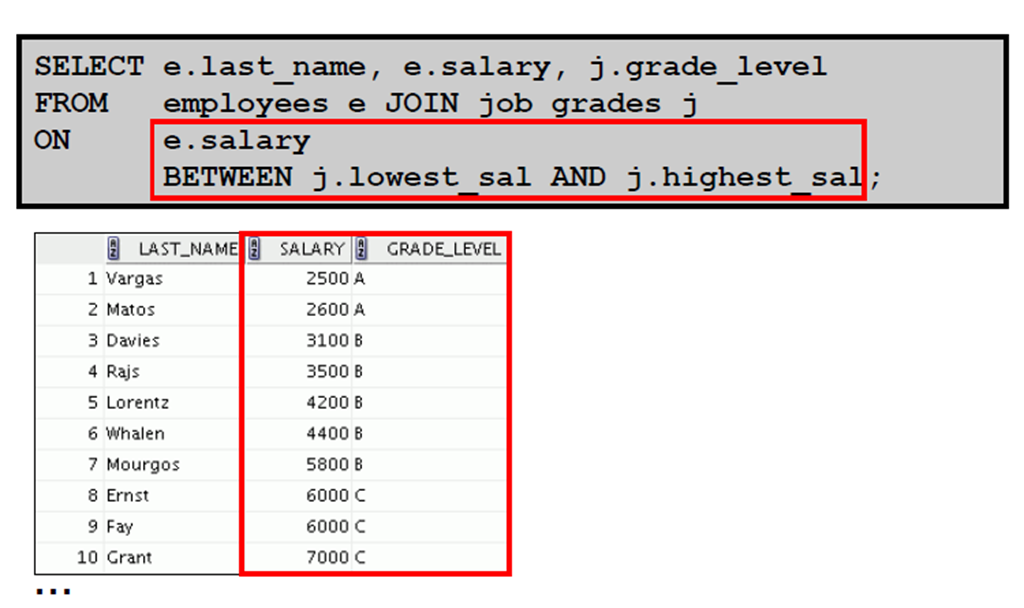
1:非等值联接
2:使用非等值联接检索记录
5:OUTER 联接: – LEFT OUTER 联接 – RIGHT OUTER 联接 – FULL OUTER 联接
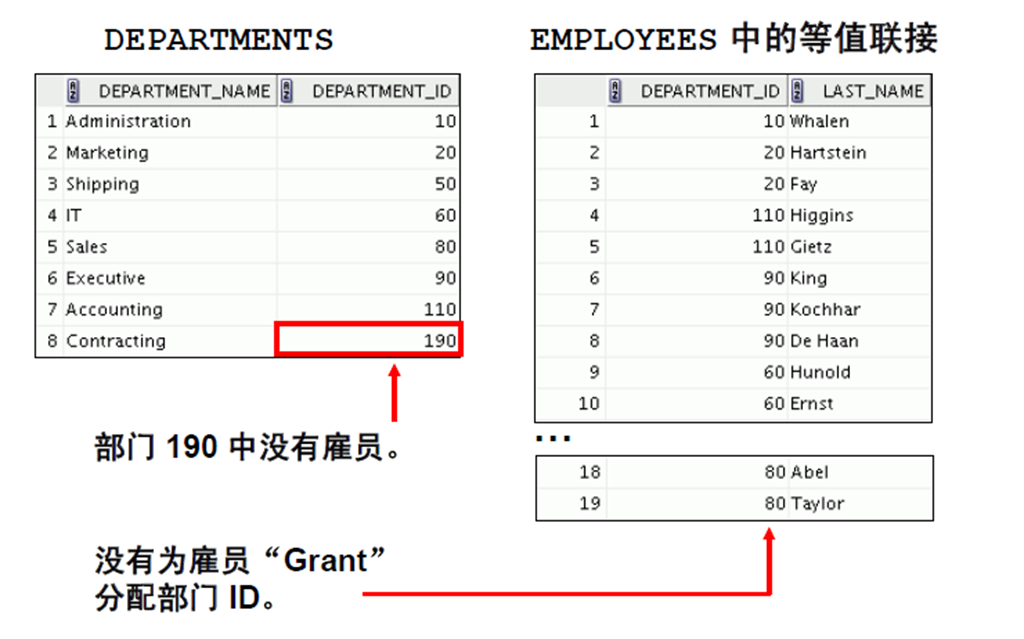
1:使用OUTER 联接返回没有直接匹配的记录
2:INNER 联接与OUTER 联接
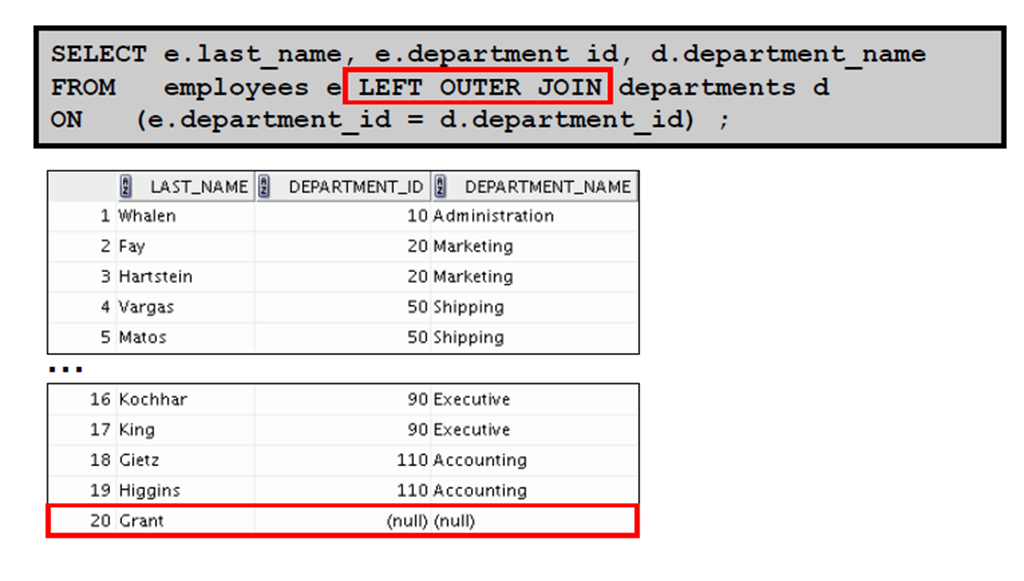
3:LEFT OUTER JOIN
4:RIGHT OUTER JOIN
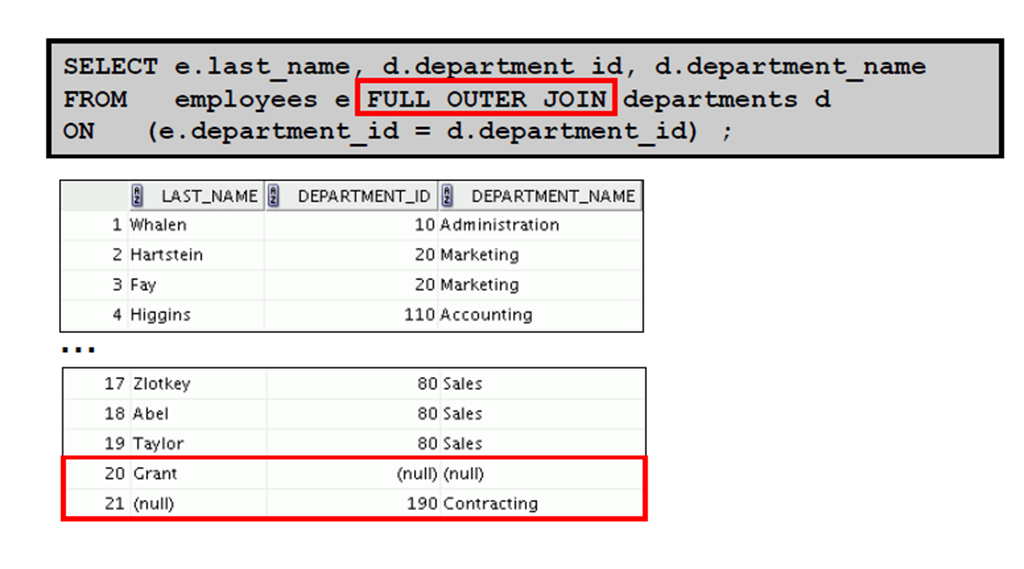
5:FULL OUTER JOIN


6:笛卡尔积 – 交叉联接
1:笛卡尔积
2:生成笛卡尔积
3:创建交叉联接



第七章:使用子查询来解决查询
1:子查询:类型、语法和准则
1:使用子查询解决问题
2:子查询语法
3:使用子查询
4:使用子查询的准则
5:子查询的类型
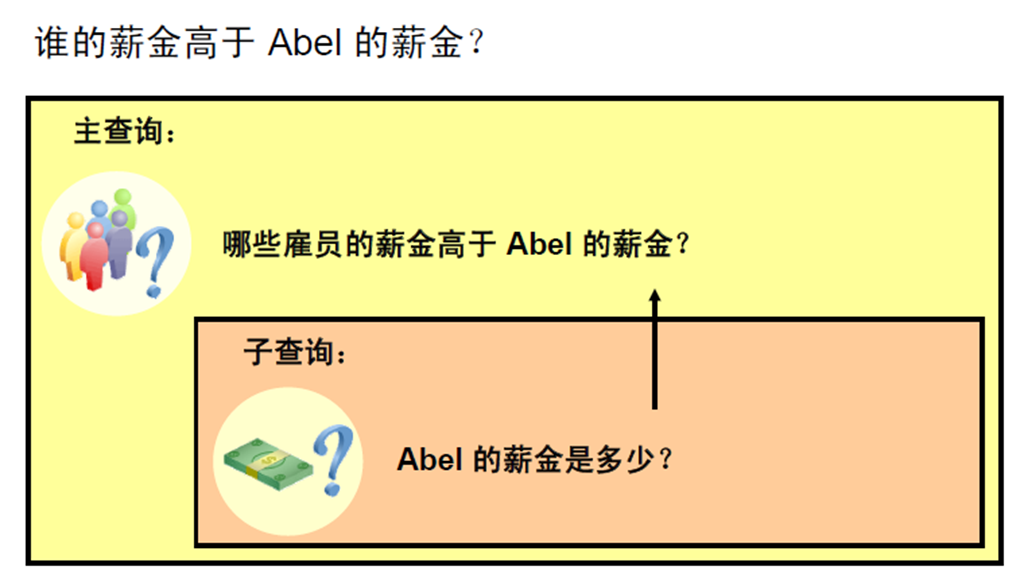

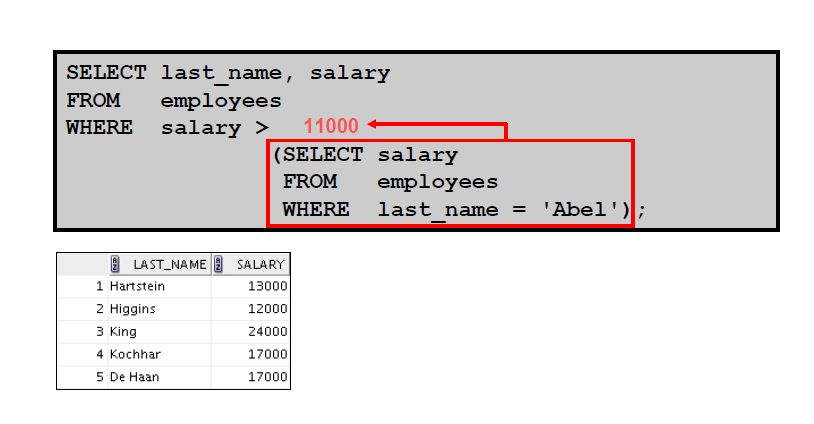

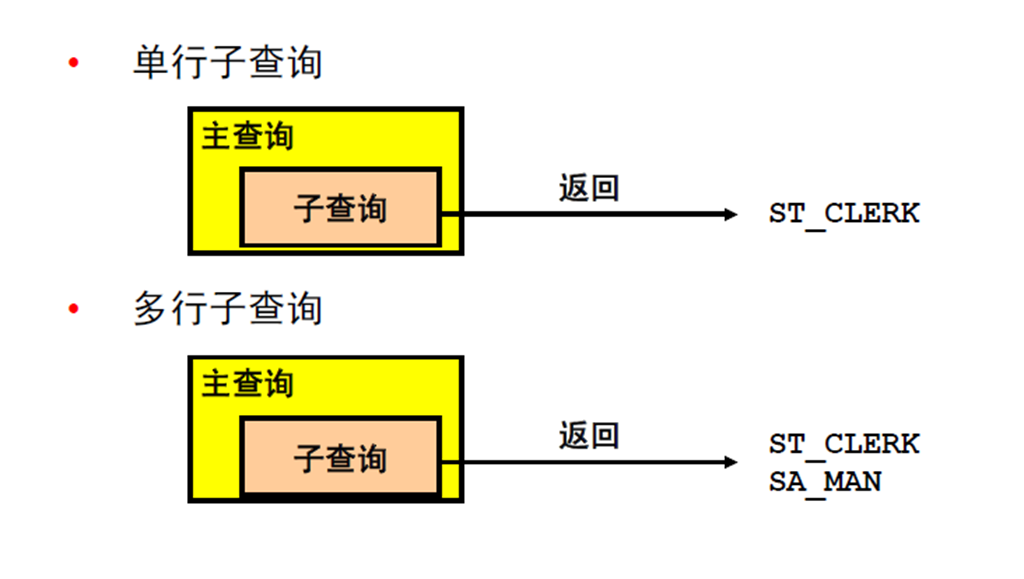
2:单行子查询: – 子查询中的组函数 – 带有子查询的HAVING 子句
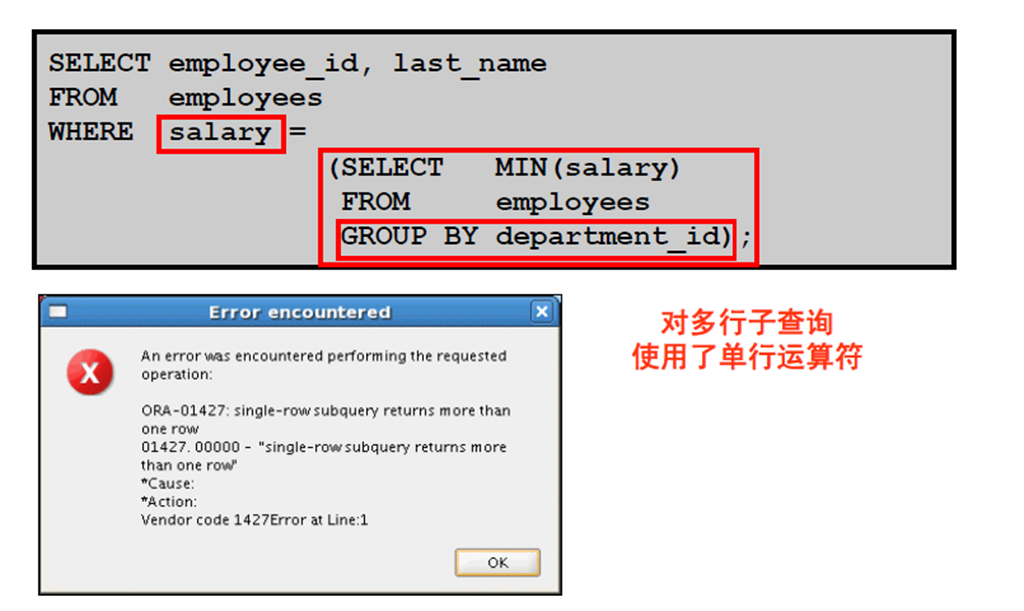
1:单行子查询
2:执行单行子查询
3:在子查询中使用组函数
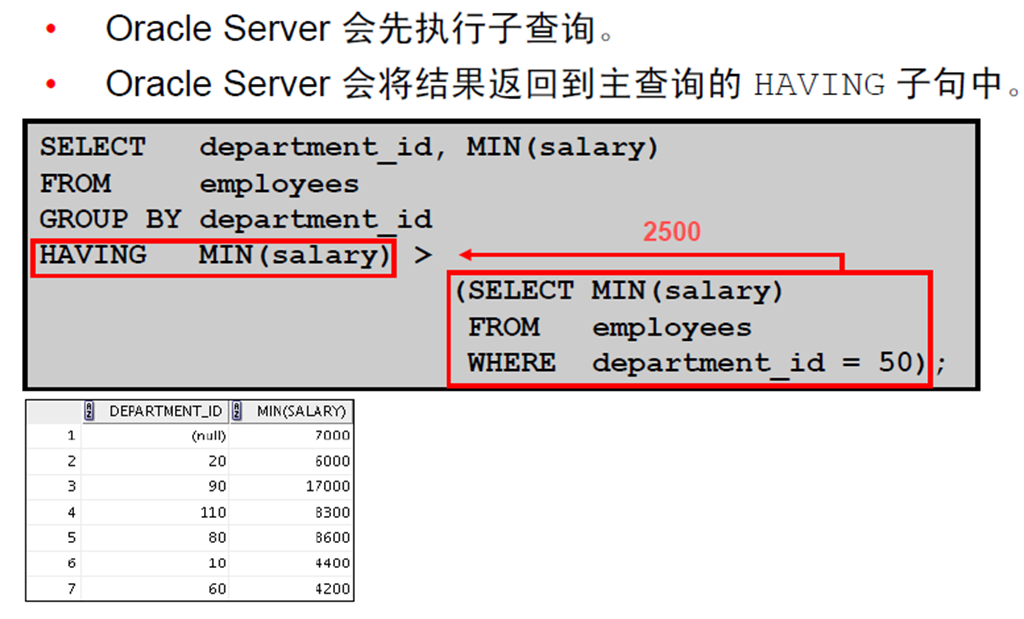
4:带有子查询的HAVING 子句
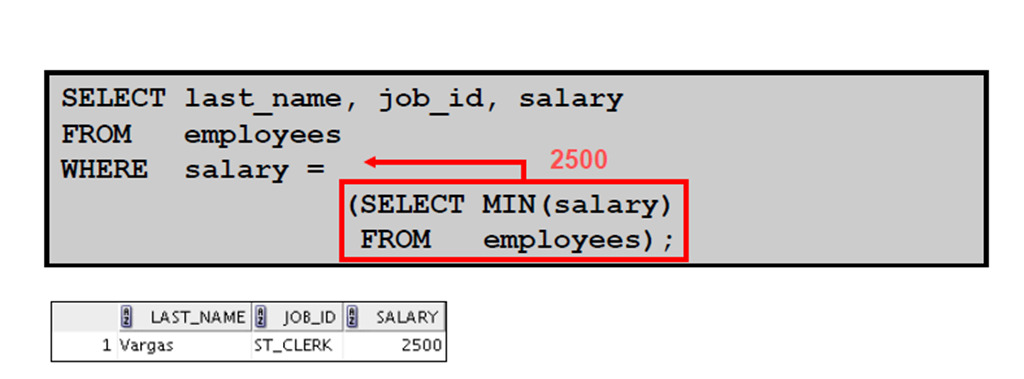
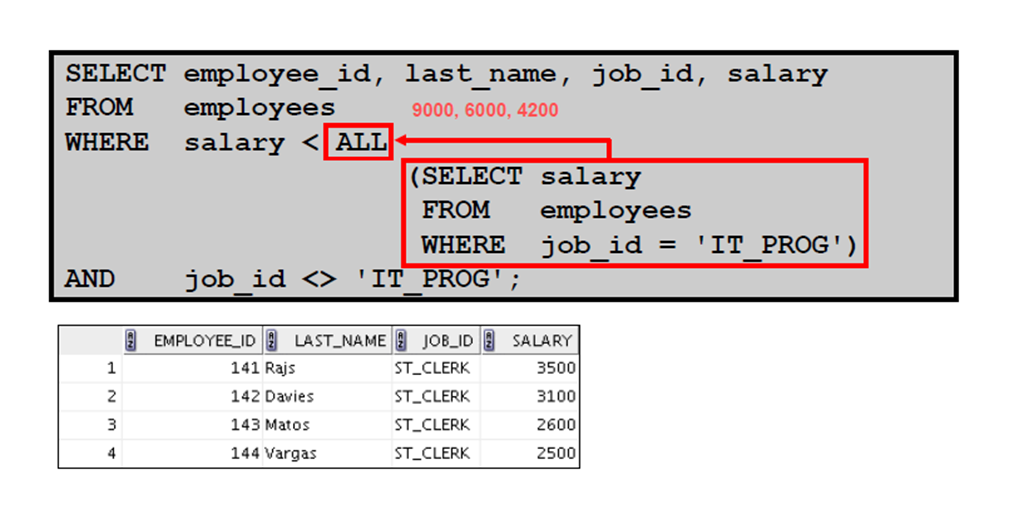
5:此语句中有什么错误
6:内部查询没有返回任何行
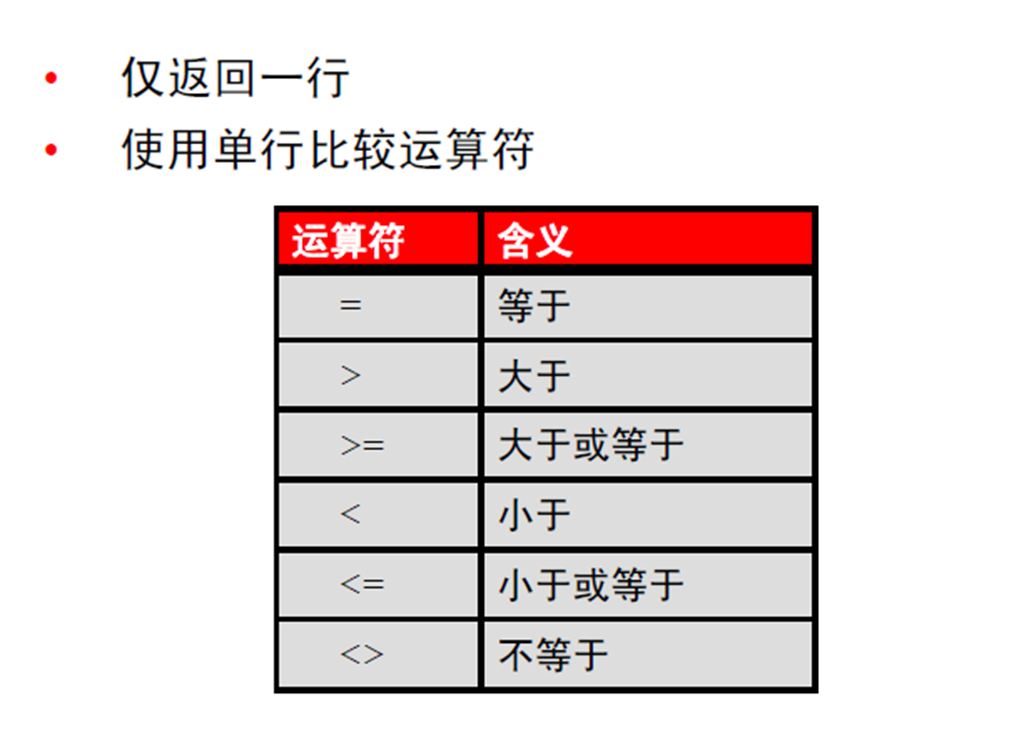


3:多行子查询 – 使用IN、ALL 或ANY
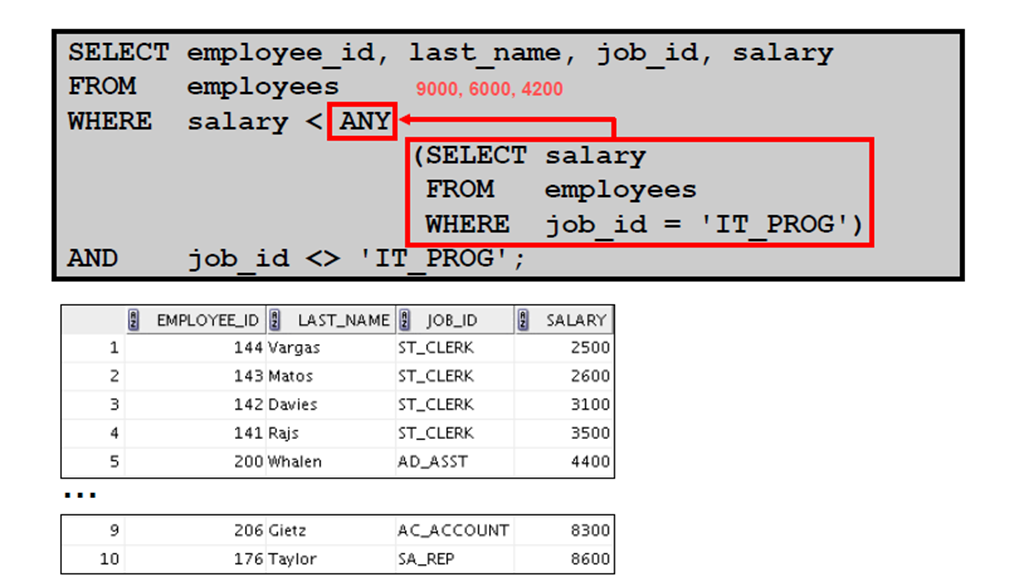
1:多行子查询
2:在多行子查询中使用ANY 运算符
3:在多行子查询中使用ALL 运算符
4:使用EXISTS 运算符

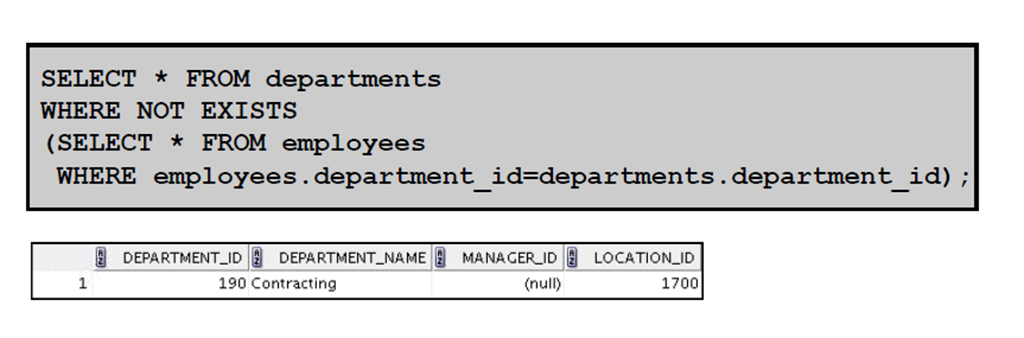
4:子查询中的空值
1:子查询中的空值
第八章:使用集合运算符
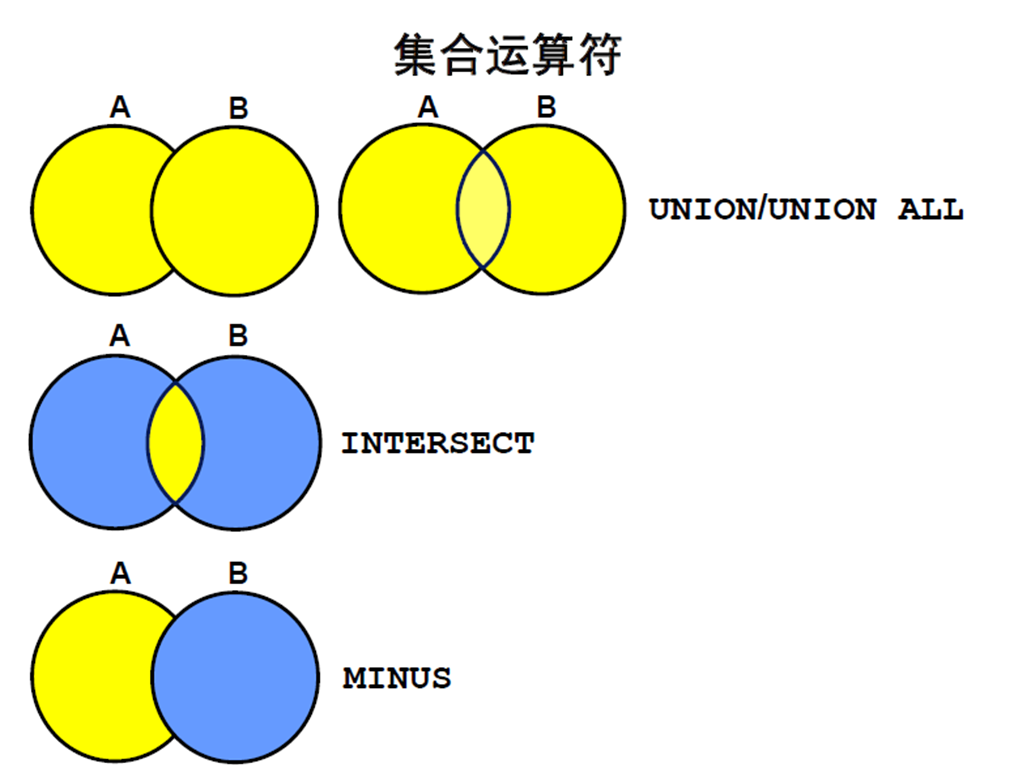
1:集合运算符:类型和准则
1:集合运算符
2:集合运算符准则
3:Oracle Server 和集合运算符


2:本课中使用的表
1:本课中使用的表

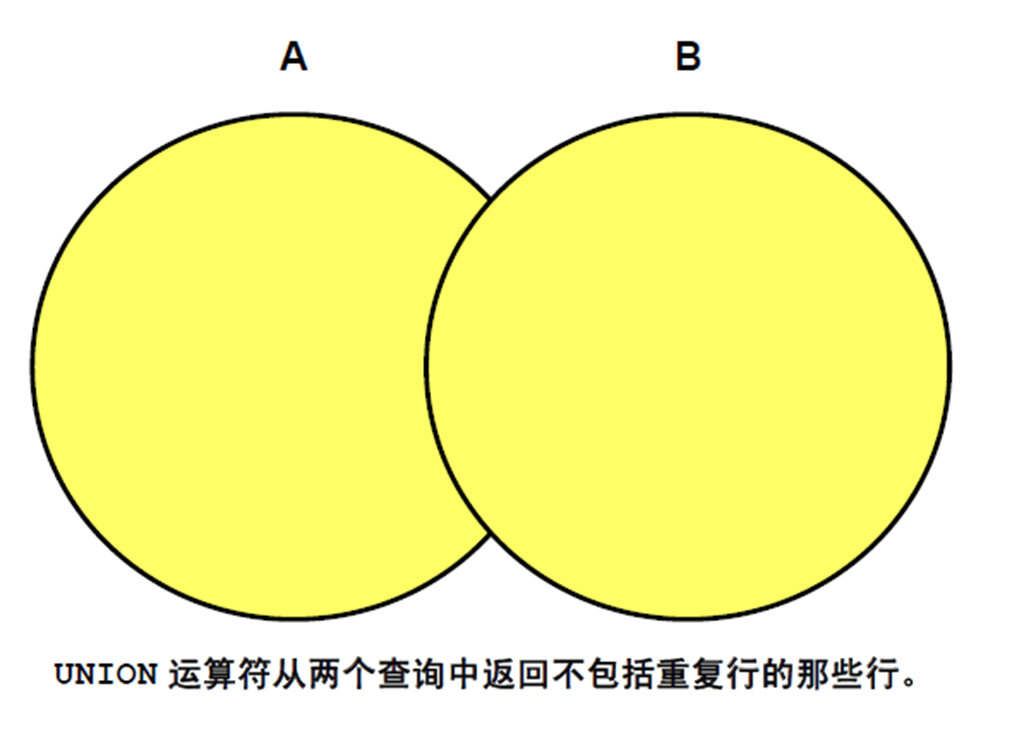
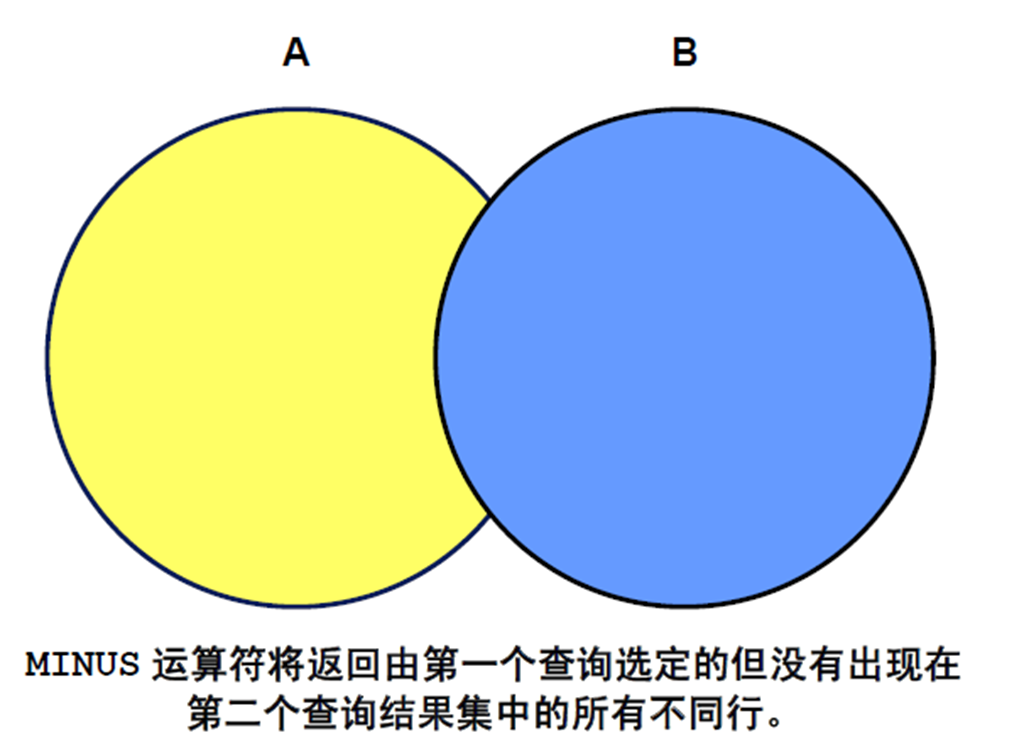
3:UNION 和UNION ALL 运算符
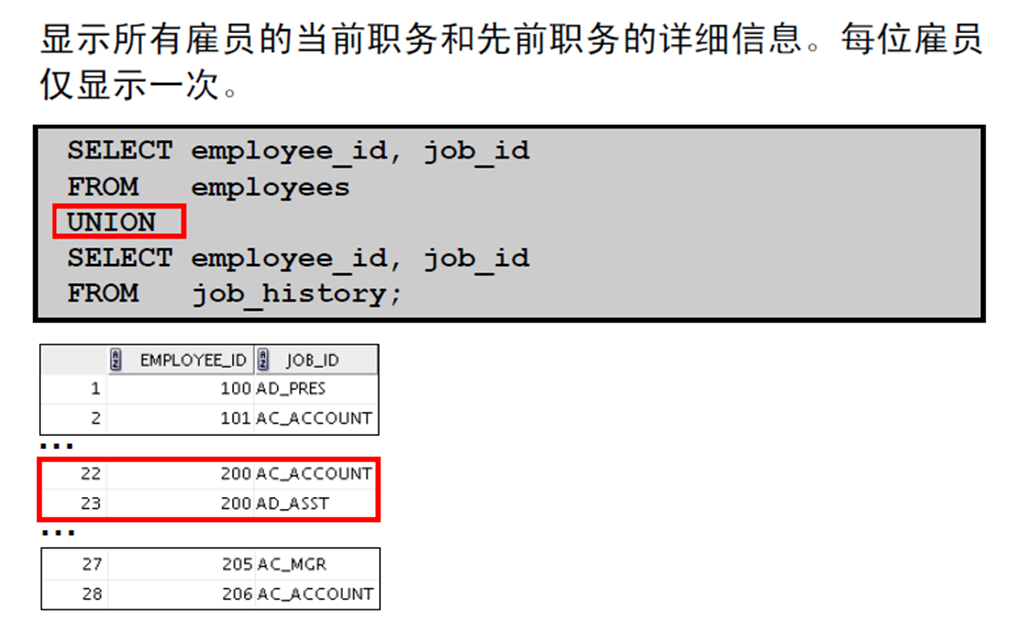
1:UNION 运算符
2:使用UNION 运算符
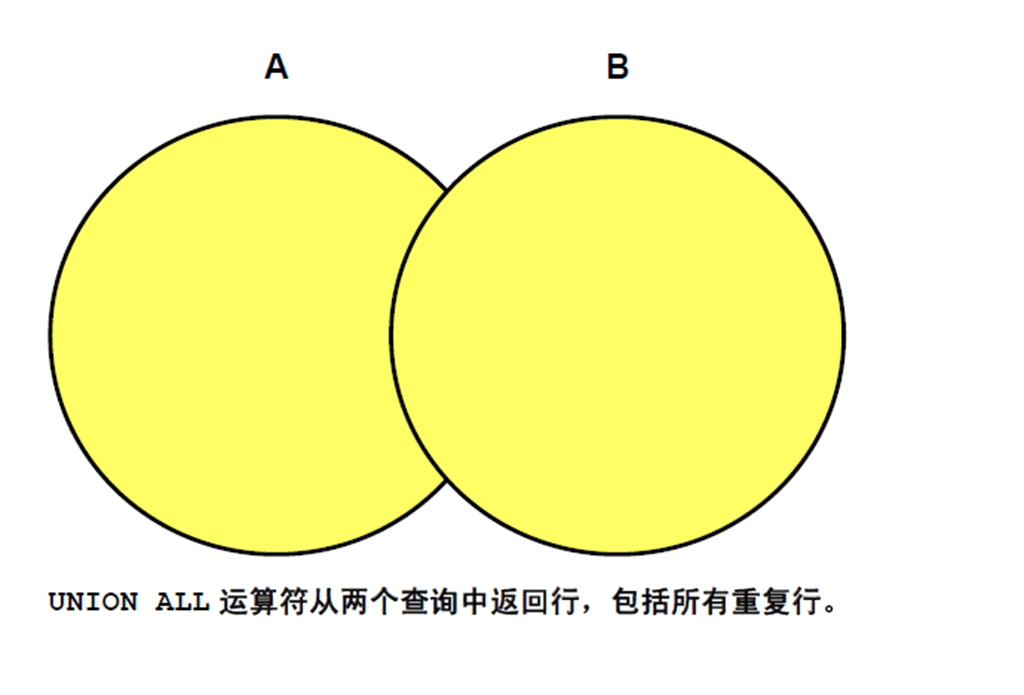
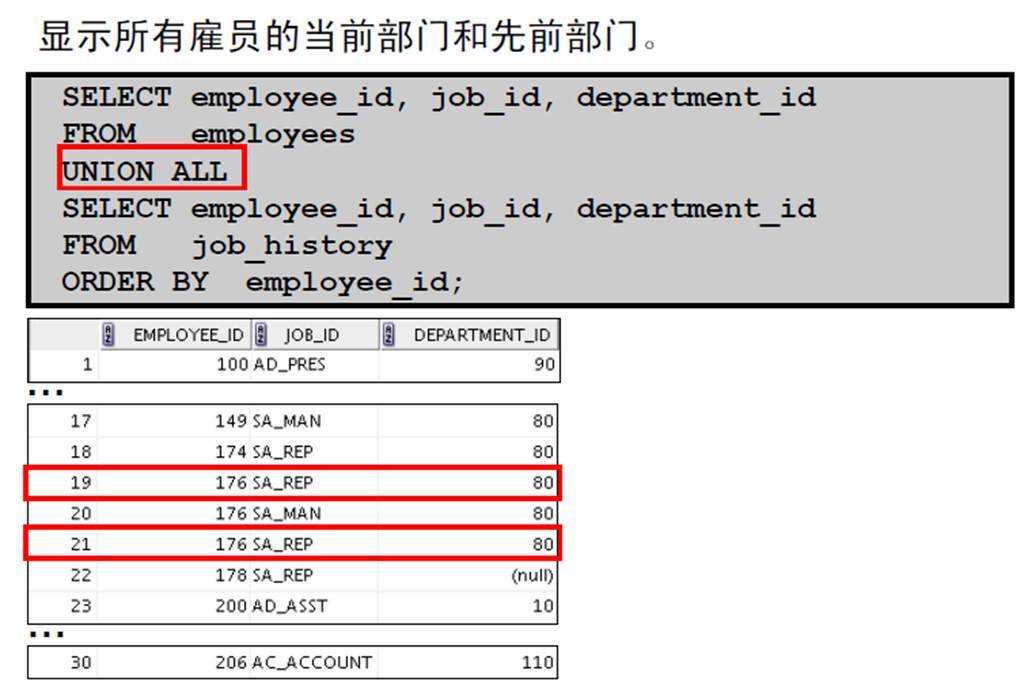
3:UNION ALL 运算符
4:使用UNION ALL 运算符
3:INTERSECT 运算符
1:INTERSECT 运算符
2:使用INTERSECT 运算符
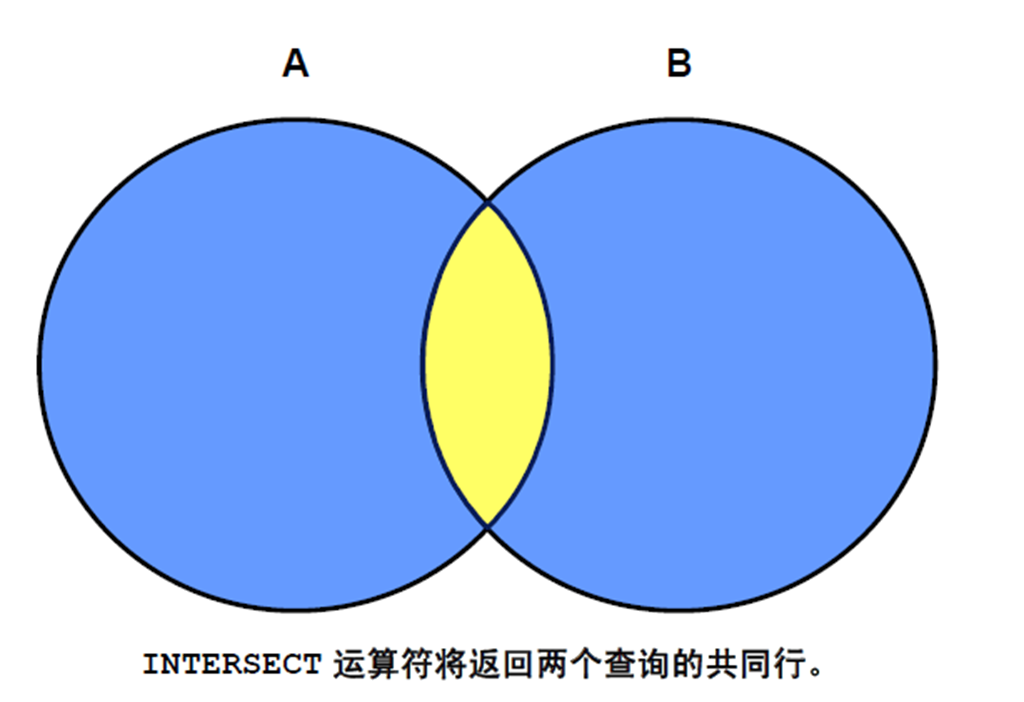

5:MINUS 运算符
1:MINUS 运算符
2:使用MINUS 运算符

6:匹配SELECT 语句
1:匹配SELECT 语句
2:匹配SELECT 语句:示例

7:在集合运算中使用ORDER BY 子句
1:在集合运算中使用ORDER BY 子句

第九章:处理数据
1:在表中添加新行 – INSERT 语句
1:数据操纵语言
2:在表中添加新行
3:INSERT 语句语法
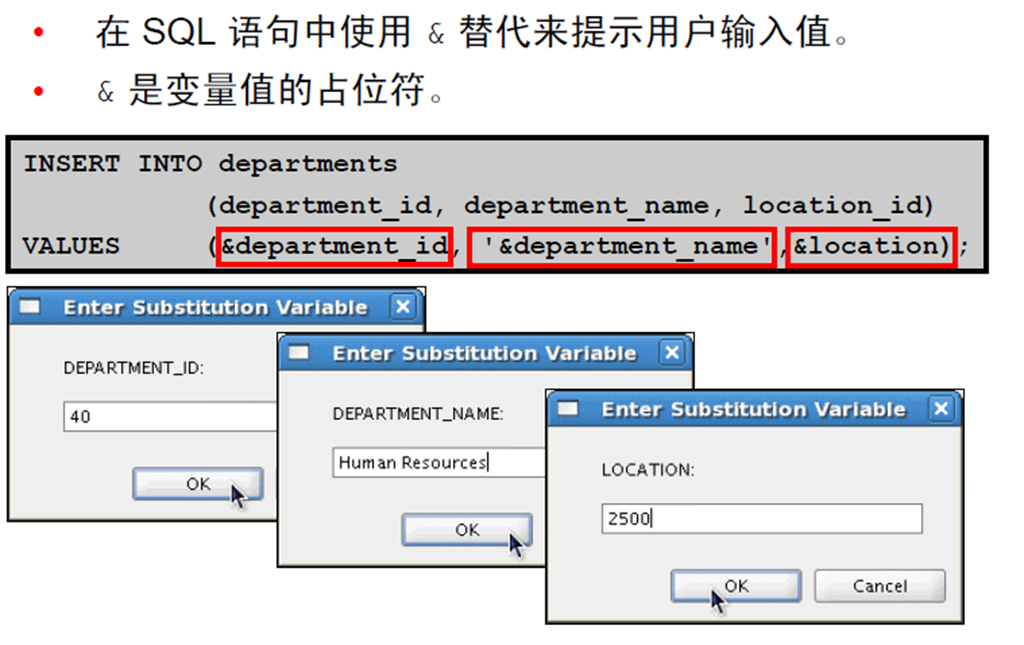
4:插入新行
5:插入带有空值的行
6:插入特殊值
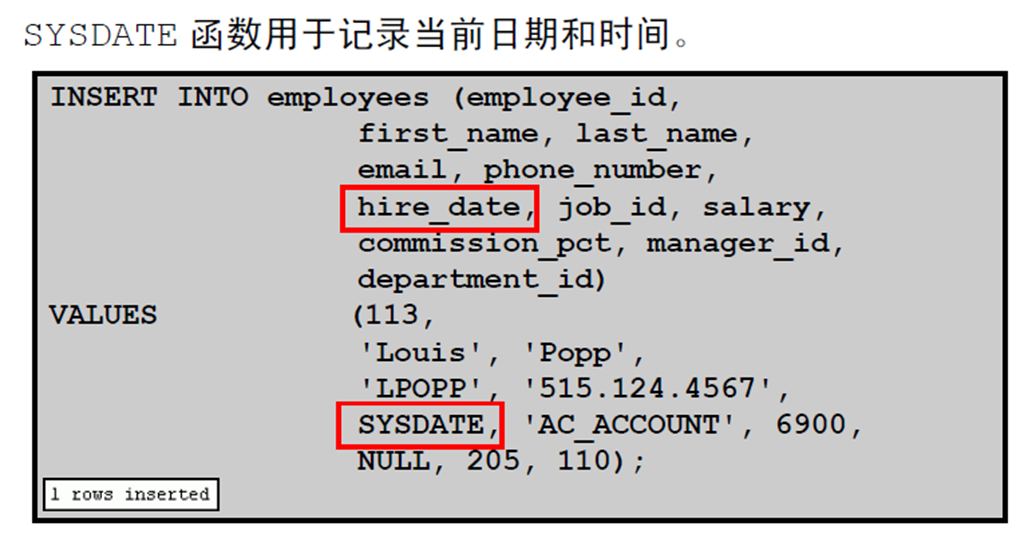
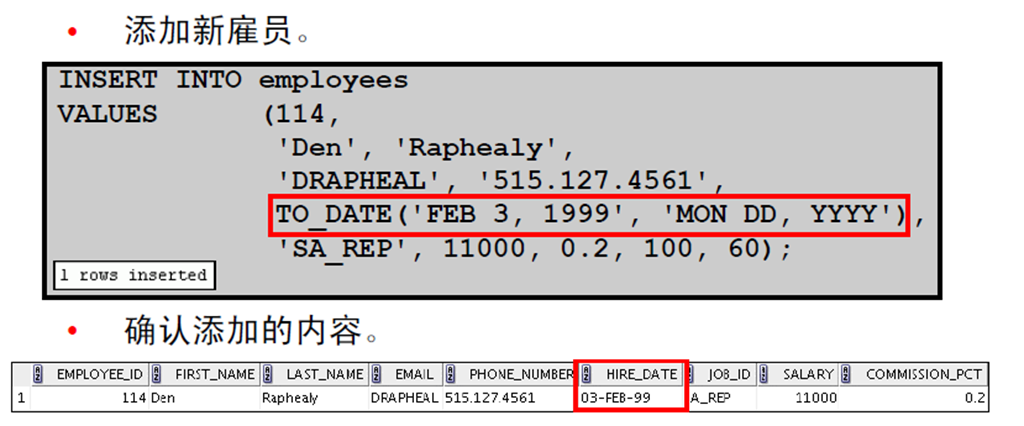
7:插入特定日期和时间值
8:创建脚本
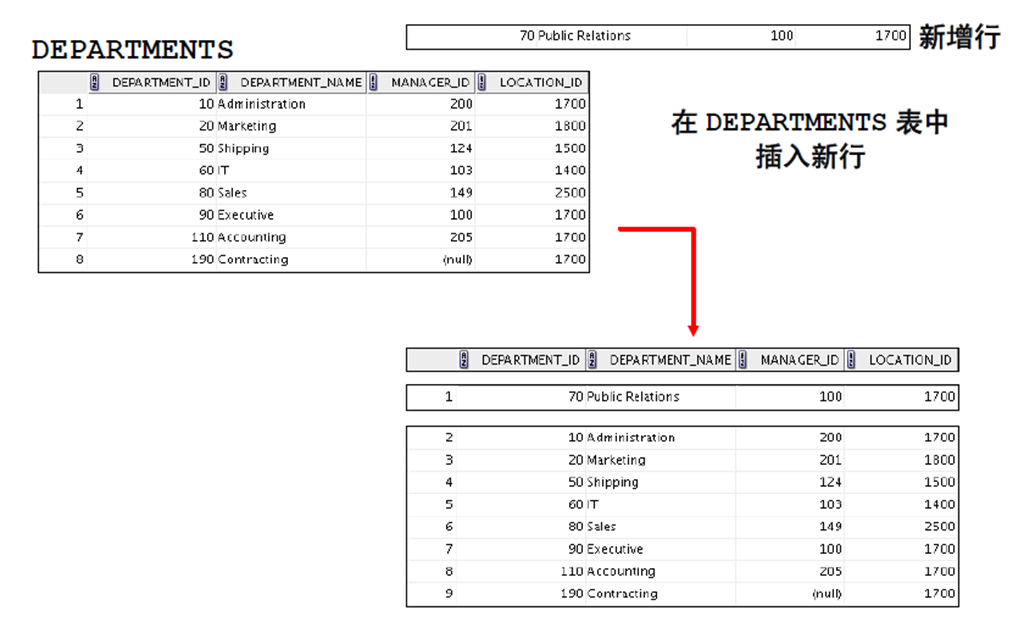
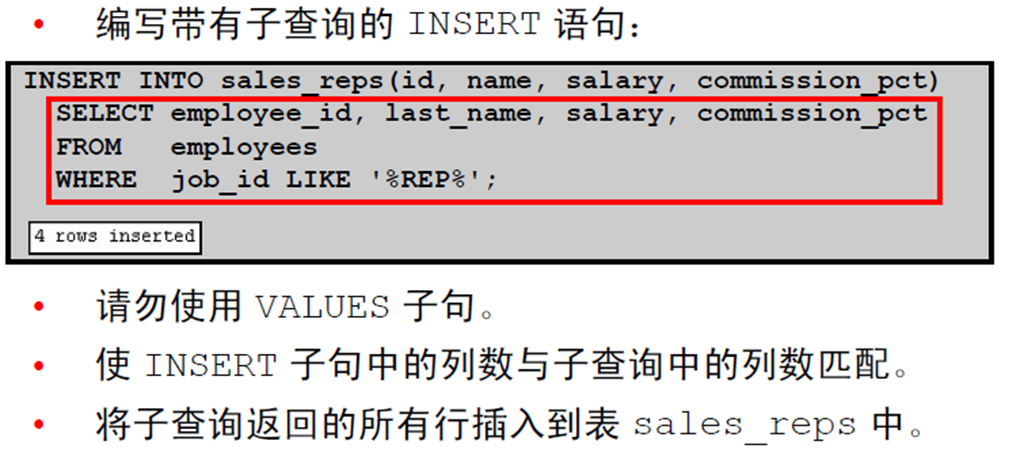
9:从其它表中复制行




2:更改表中的数据 – UPDATE 语句
1:更改表中的数据
2:UPDATE 语句语法
3:更新表中的行
4:使用子查询更新两列
5:根据另一个表更新行
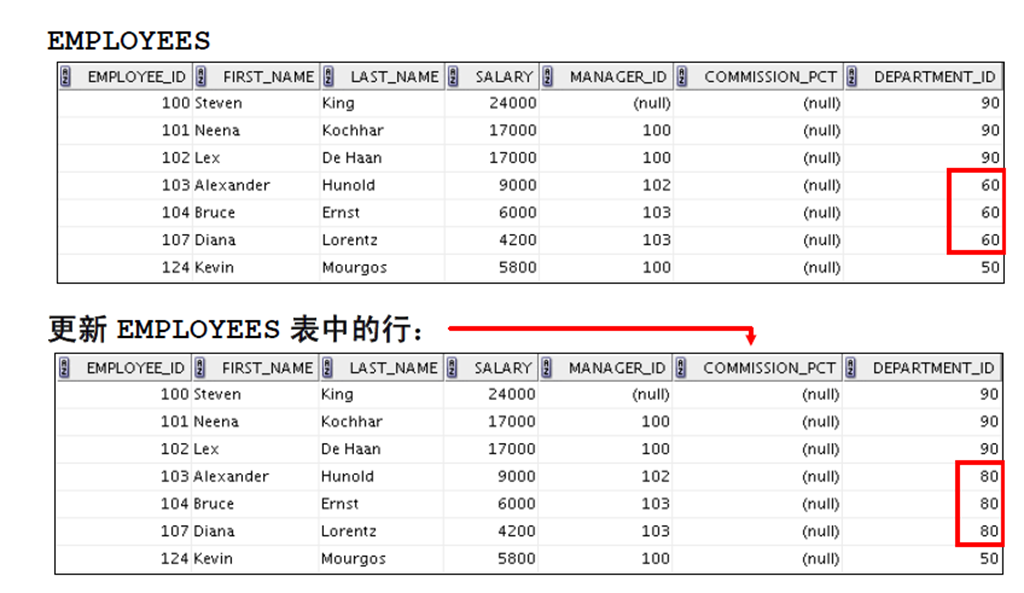




3:从表中删除行: – DELETE 语句 – TRUNCATE 语句
1:从表中删除行
2:DELETE 语句
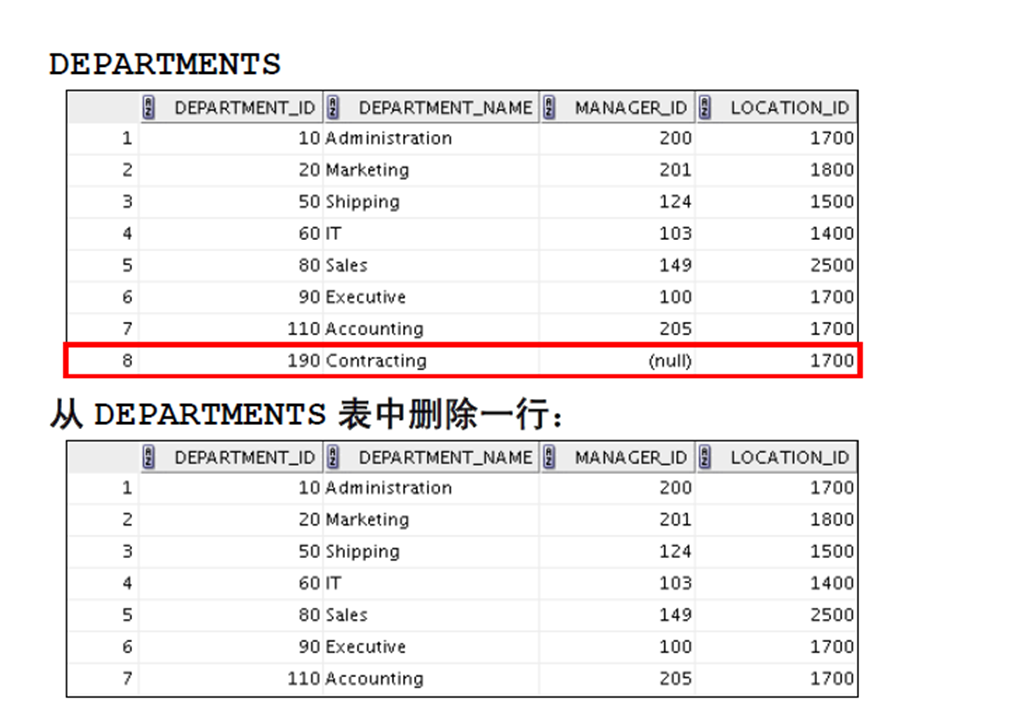
3:从表中删除行
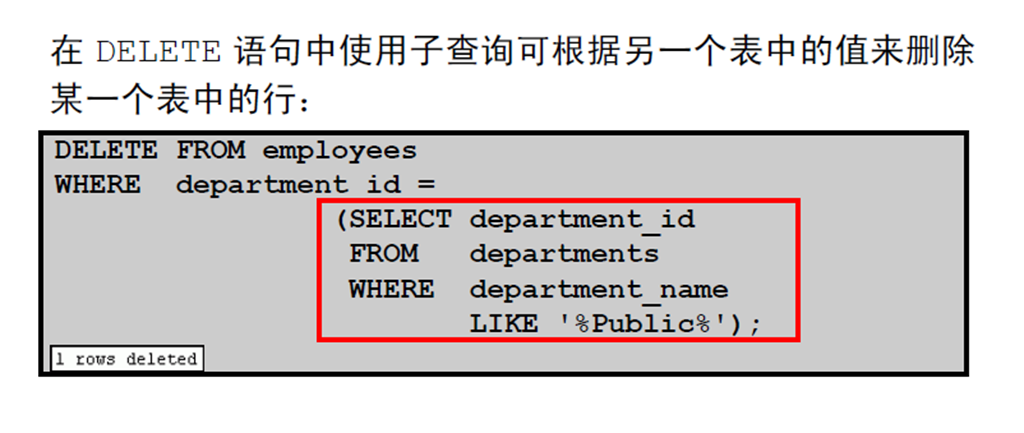
4:根据另一个表删除行
5:TRUNCATE 语句



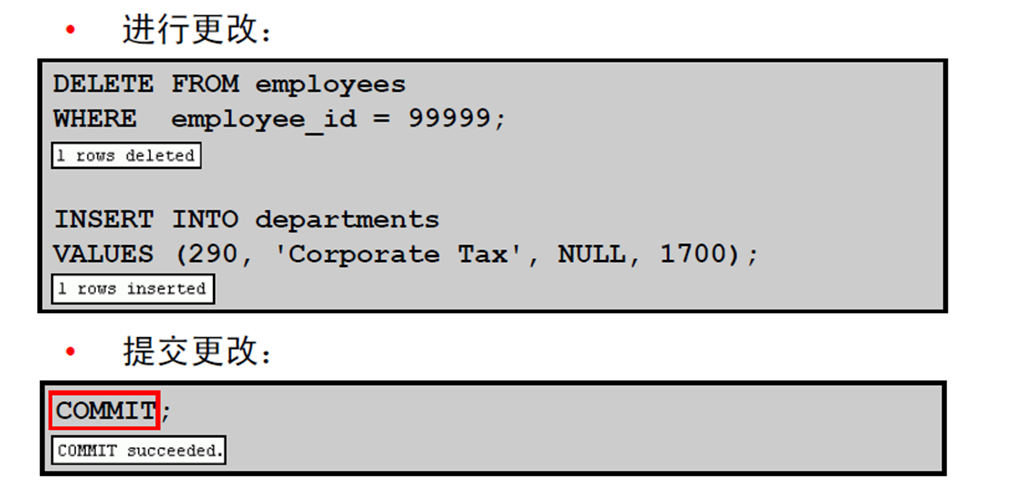
4:使用COMMIT、ROLLBACK 和SAVEPOINT 执行数据库 事务处理控制
1:数据库事务处理
2:数据库事务处理:开始和结束
3:COMMIT 和ROLLBACK 语句的优点
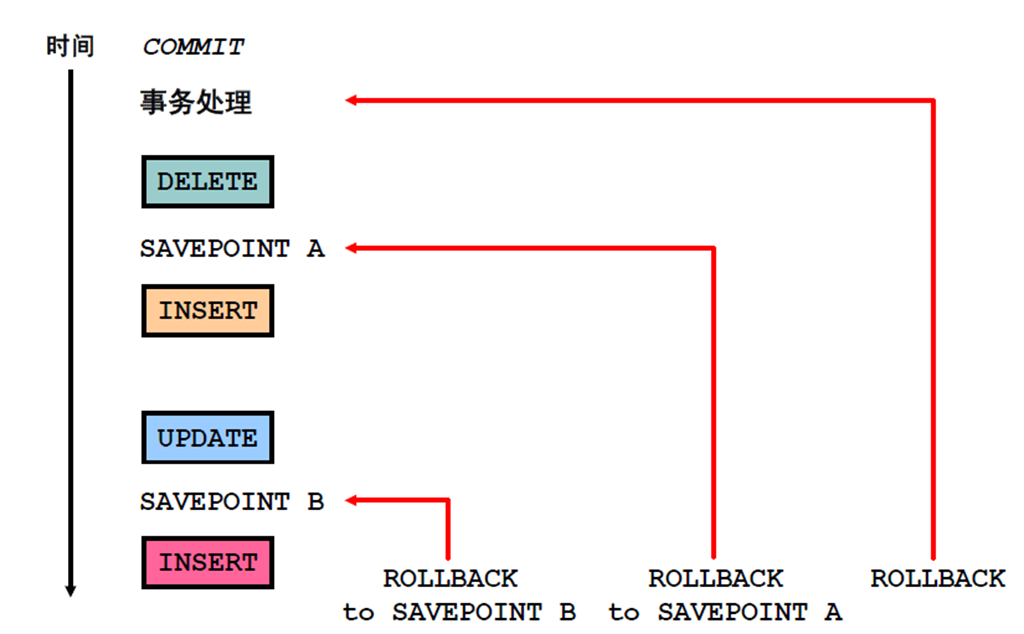
4:显式事务处理控制语句
5:将更改回退到某个标记
6:隐式事务处理
7:执行COMMIT 或ROLLBACK 操作之前的数据状态
8:执行COMMIT 操作之后的数据状态
9:提交数据
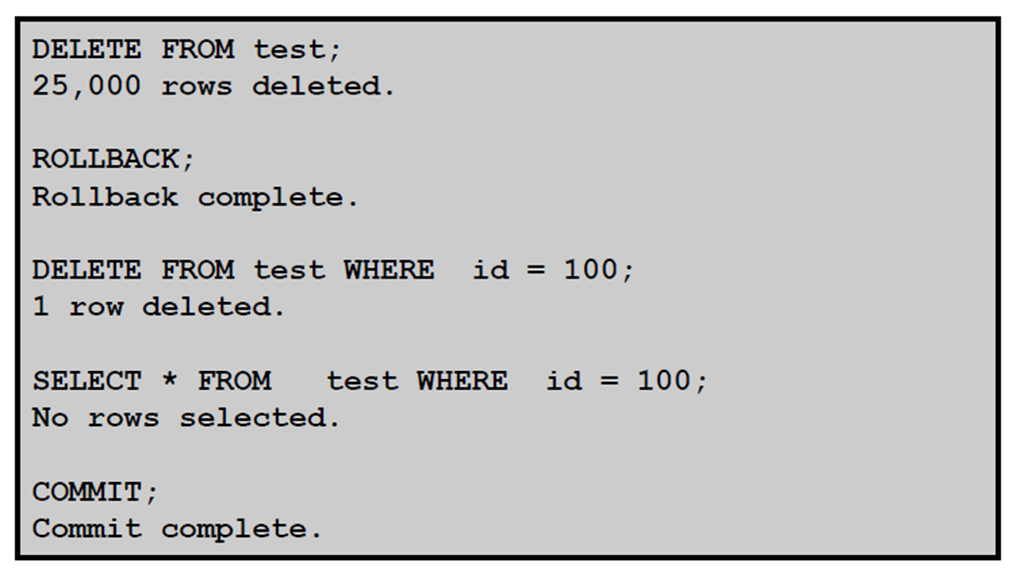
10:执行ROLLBACK 操作之后的数据状态:示例
11:执行ROLLBACK 操作之后的数据状态
12:语句级回退









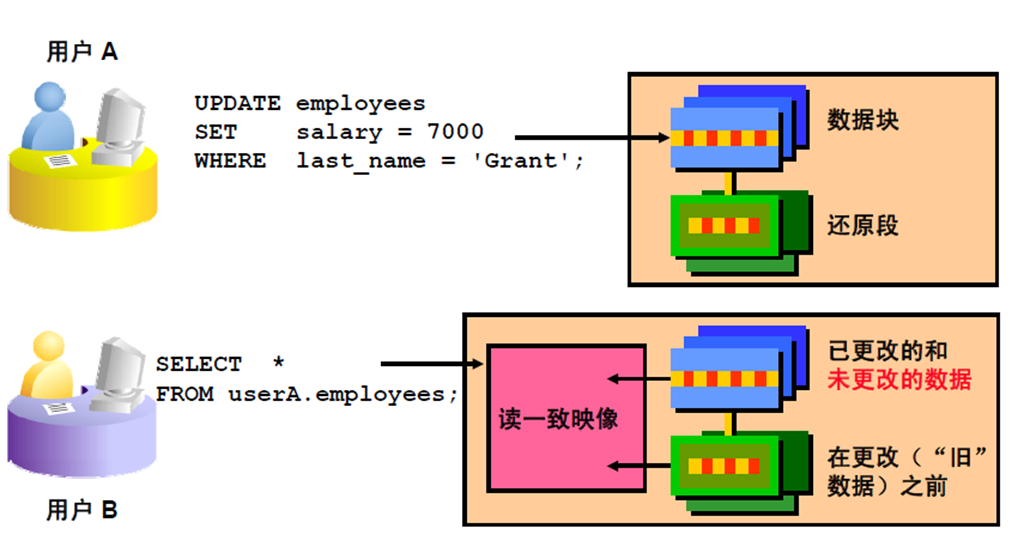
5:读一致性
1:读一致性
2:实施读一致性

6:SELECT 语句中的FOR UPDATE 子句
1:SELECT 语句中的FOR UPDATE 子句
2:FOR UPDATE 子句:示例


第十章:使用DDL 语句创建和管理表
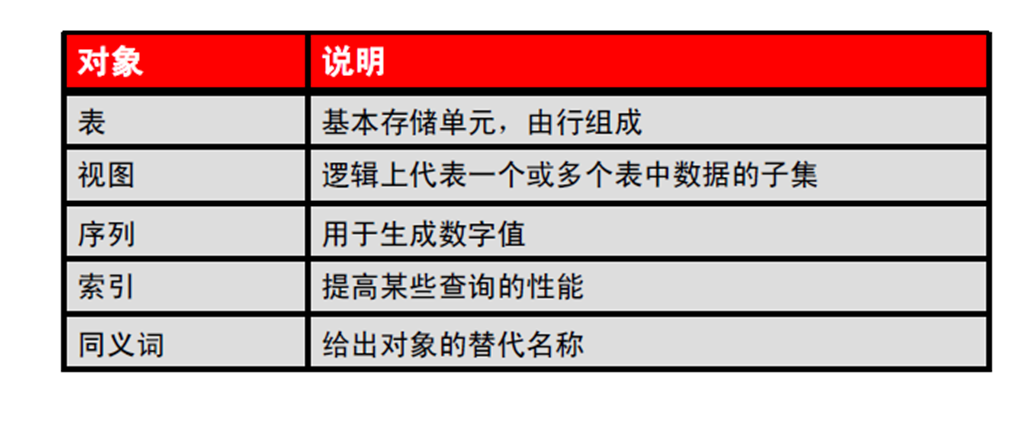
1:数据库对象 – 命名规则
1:数据库对象
2:命名规则

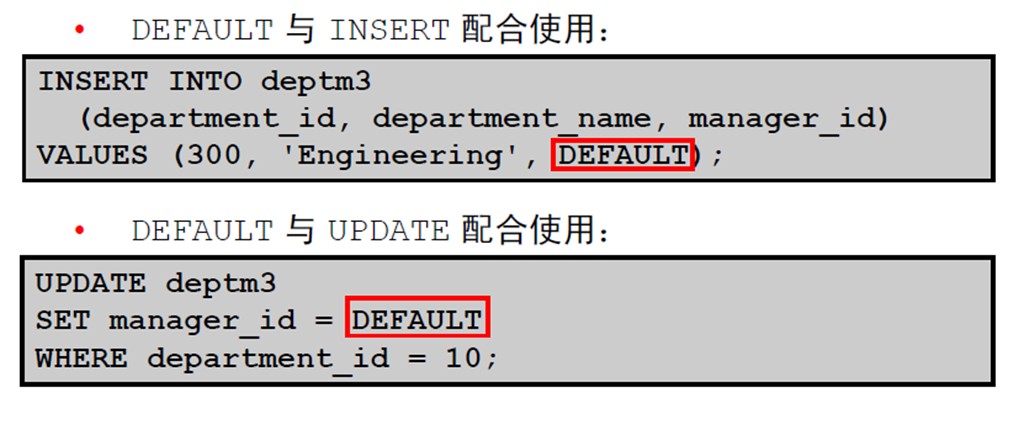
2:CREATE TABLE 语句: – 访问另一个用户的表 – DEFAULT 选项
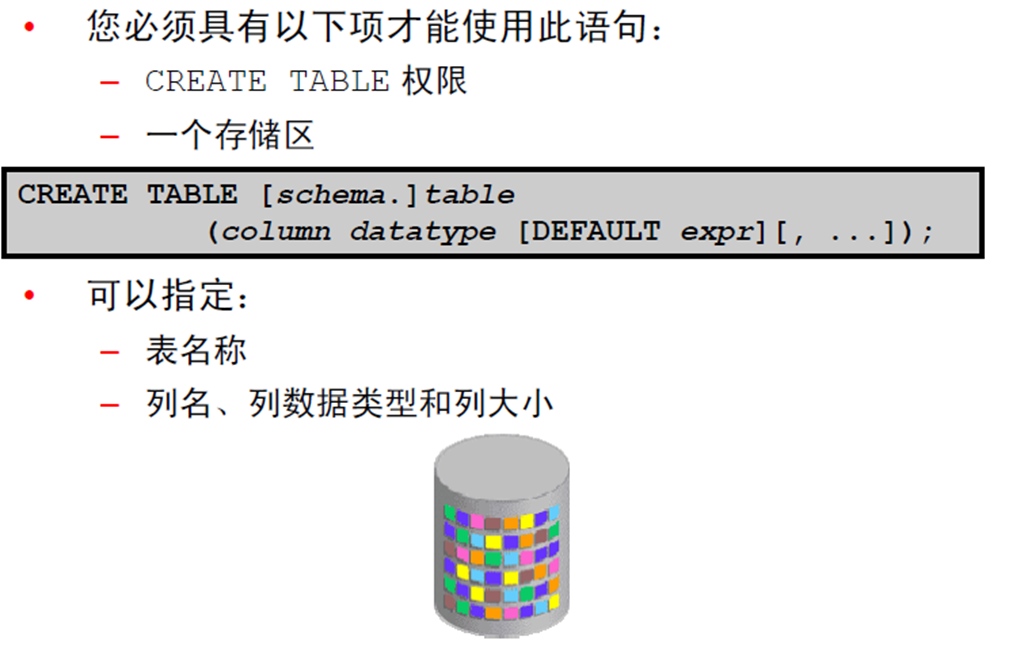
1:CREATE TABLE 语句
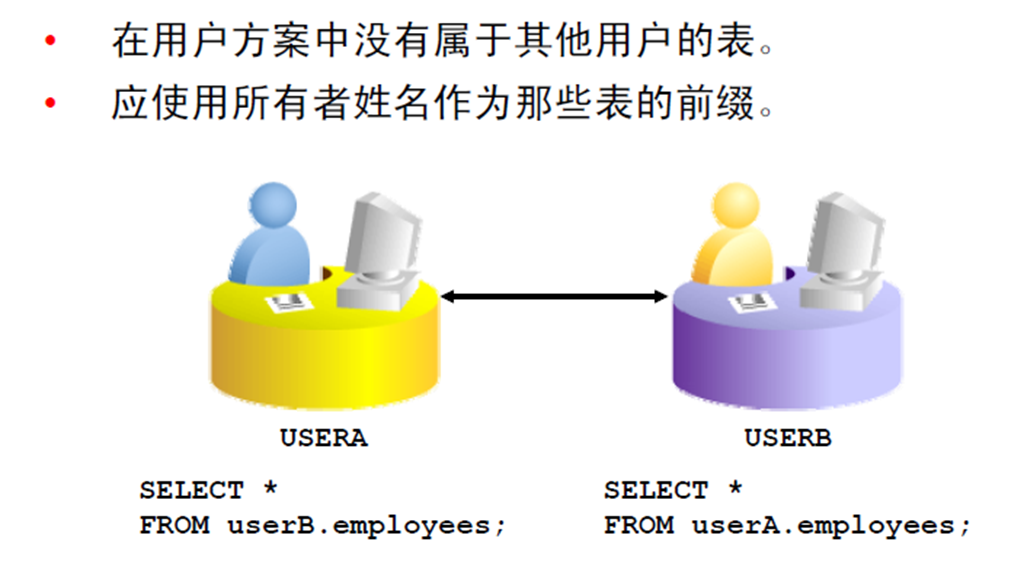
2:引用另一个用户的表
3:DEFAULT 选项
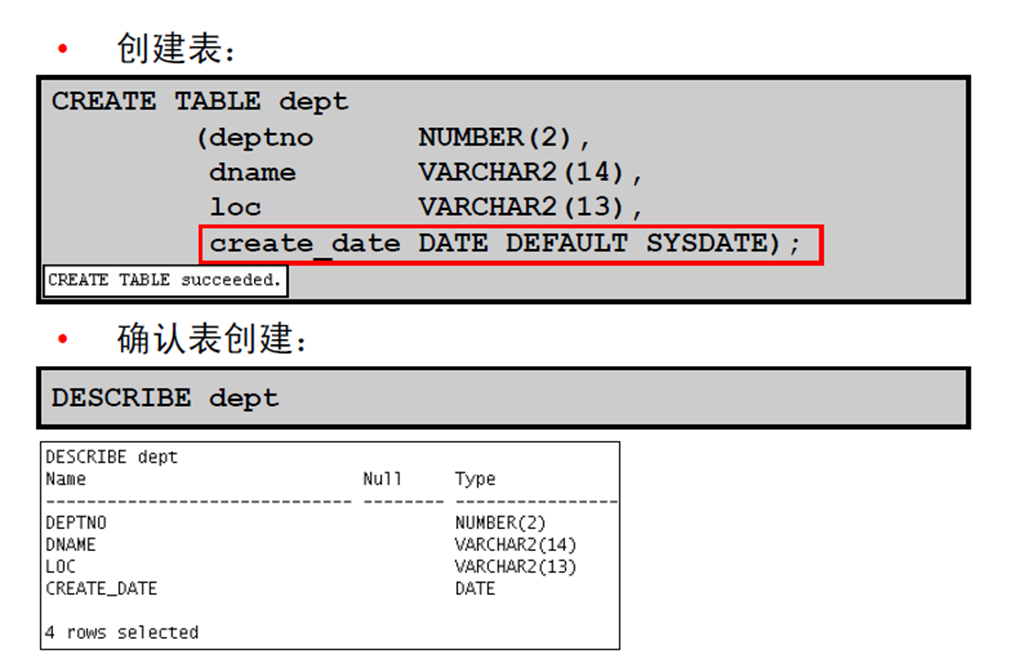
4:创建表

3:数据类型
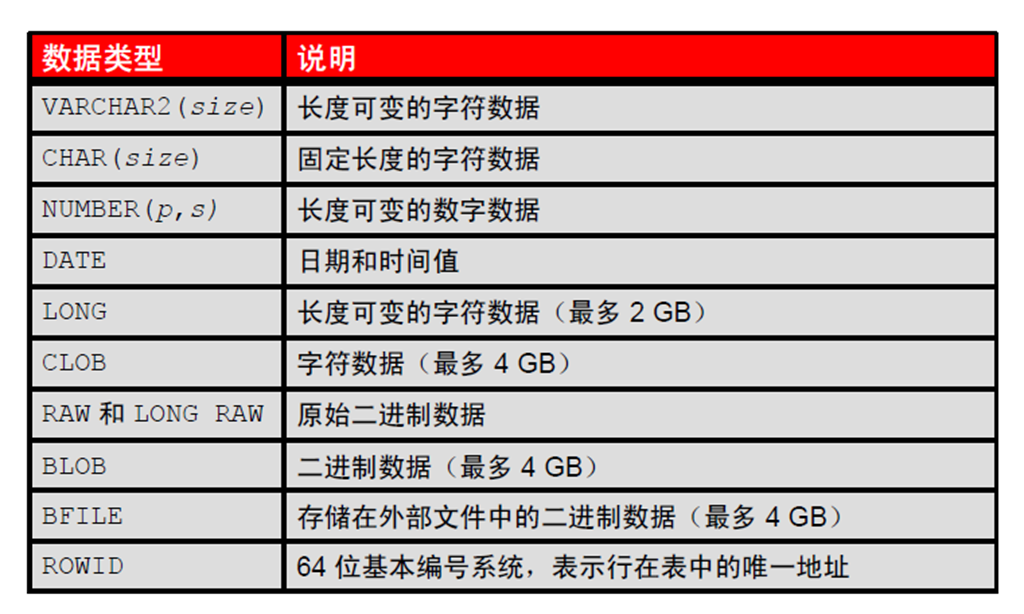
1:数据类型
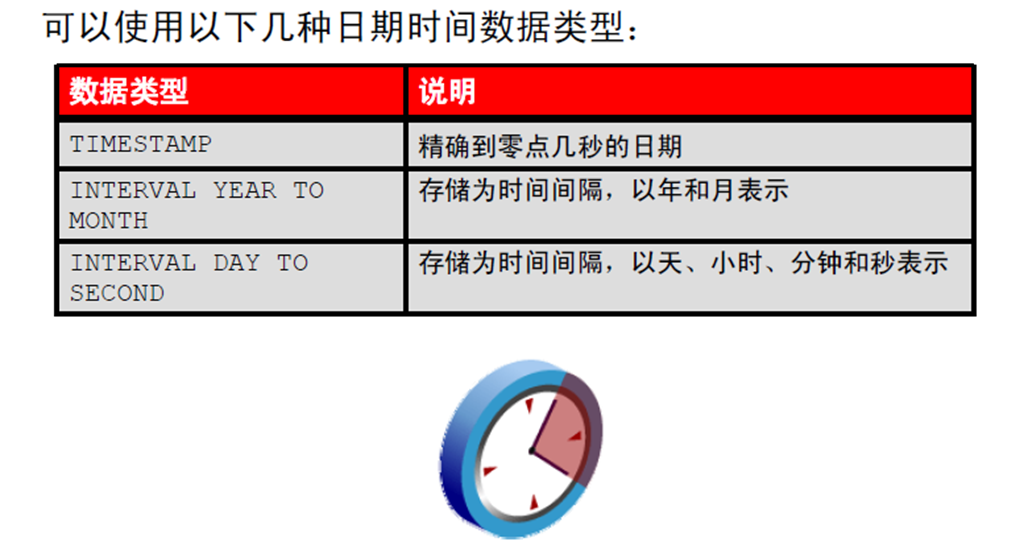
2:日期时间数据类型
4:约束条件概览:NOT NULL、UNIQUE、PRIMARY KEY、 FOREIGN KEY、CHECK 约束条件
1:包括约束条件
2:约束条件准则
3:定义约束条件
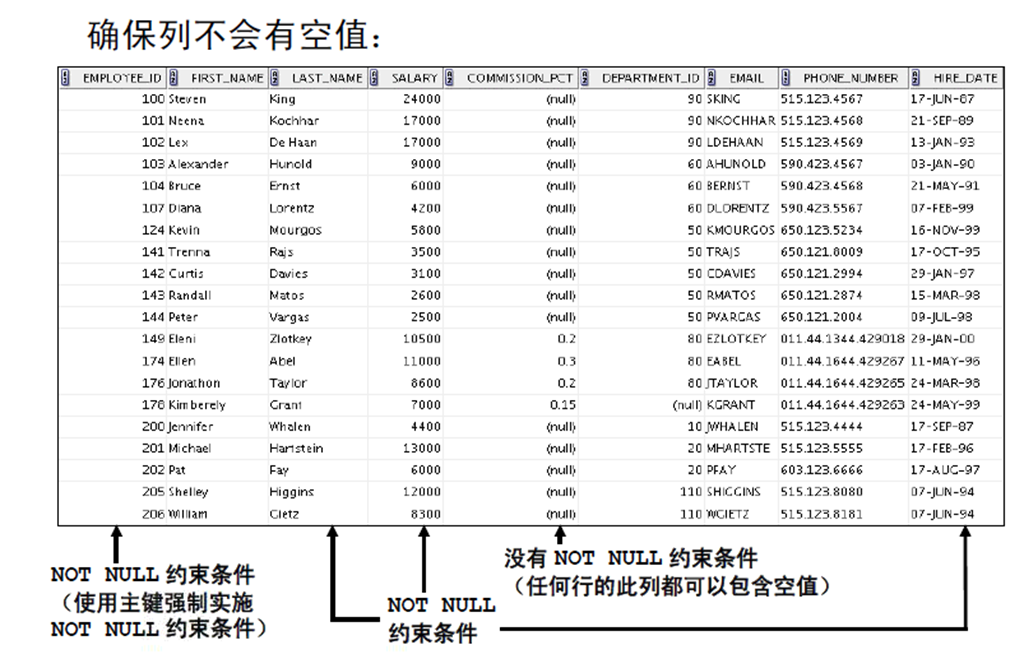
4:NOT NULL 约束条件
5:UNIQUE 约束条件
6:PRIMARY KEY 约束条件
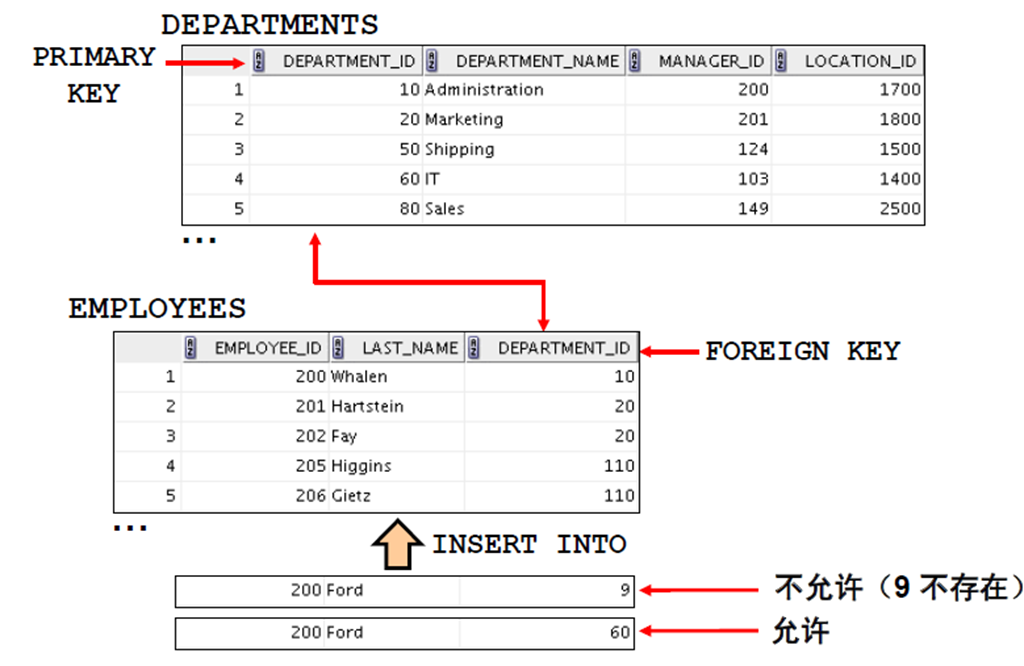
7:FOREIGN KEY 约束条件
8:FOREIGN KEY 约束条件:关键字
9:CHECK 约束条件
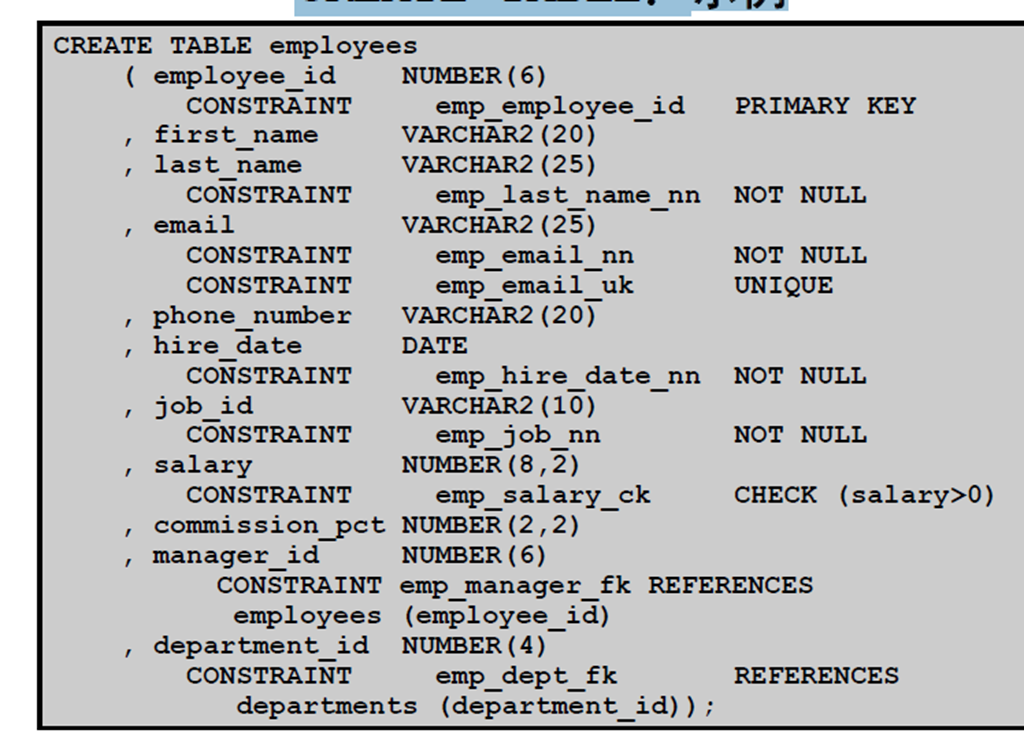
10:CREATE TABLE:示例
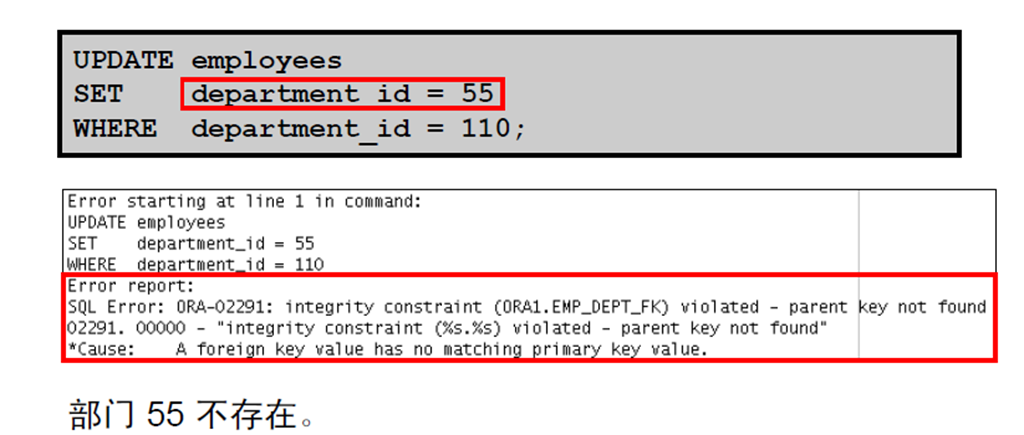
11:违反约束条件







5:使用子查询创建表
1:使用子查询创建表

6: ALTER TABLE
– 只读表
1:只读表

7:DROP TABLE 语句
1:删除表

第十一章:创建其它方案对象
1:视图概览:
– 创建、修改和检索视图中的数据
– 对视图执行数据操纵语言(DML) 操作
– 删除视图
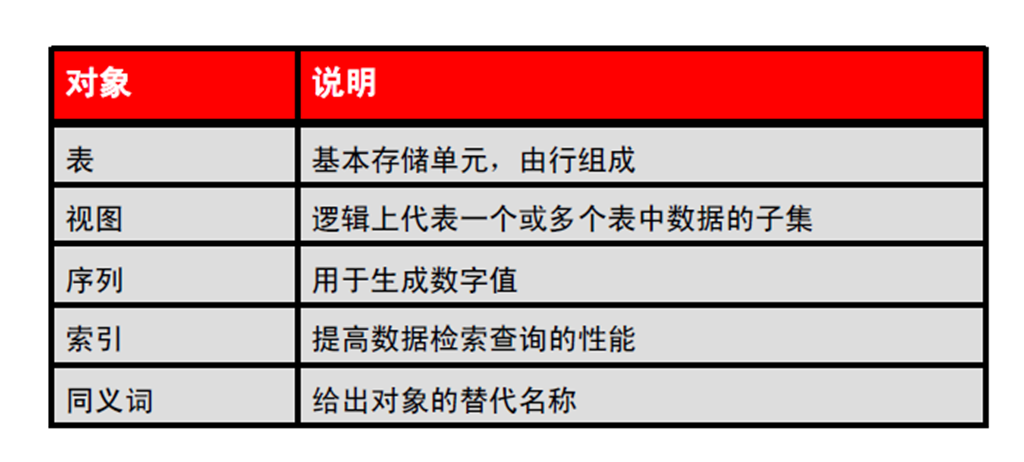
1:数据库对象
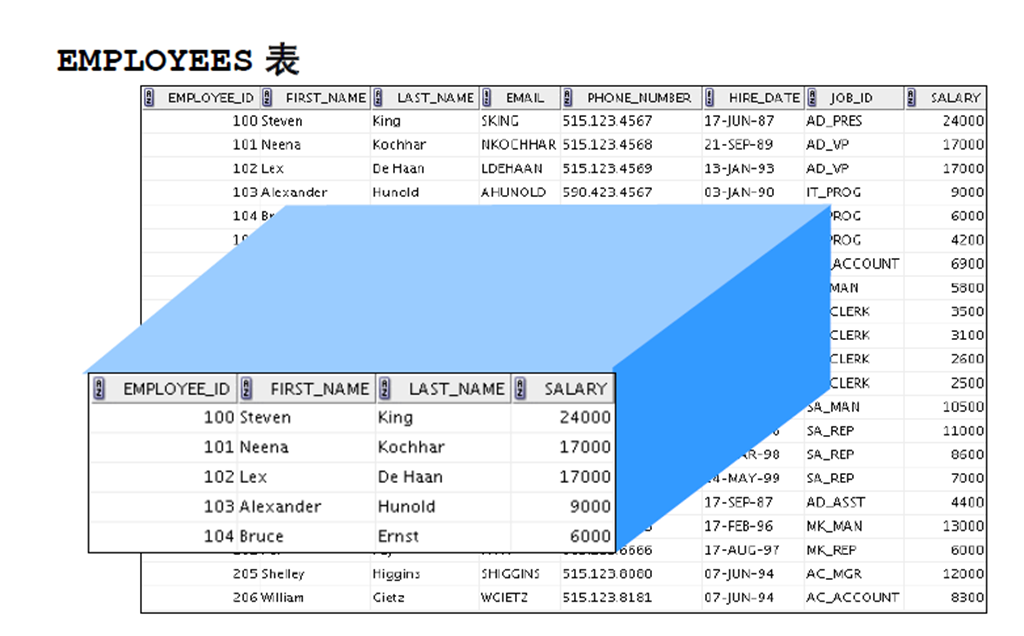
2:什么是视图
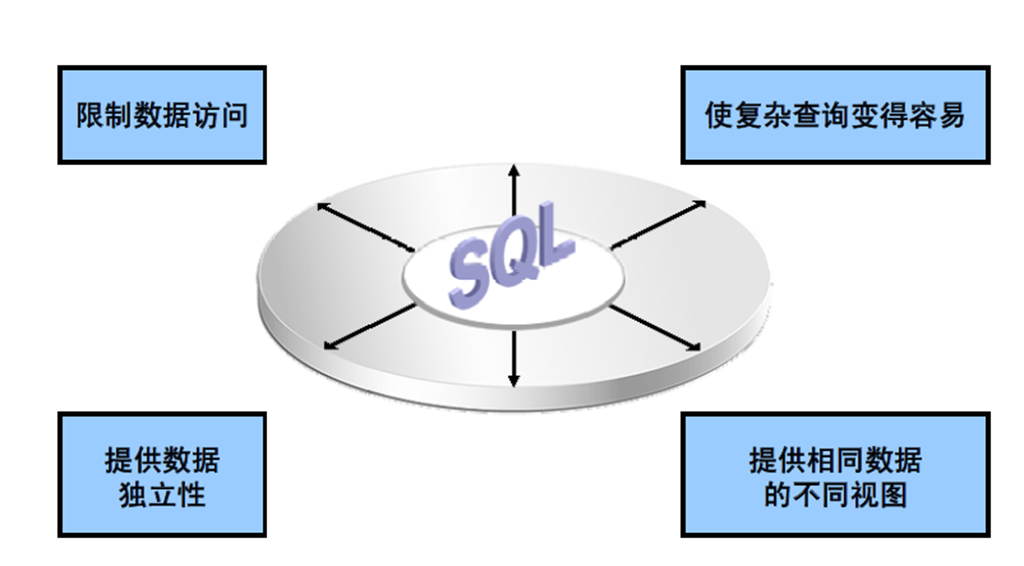
3;视图的优点
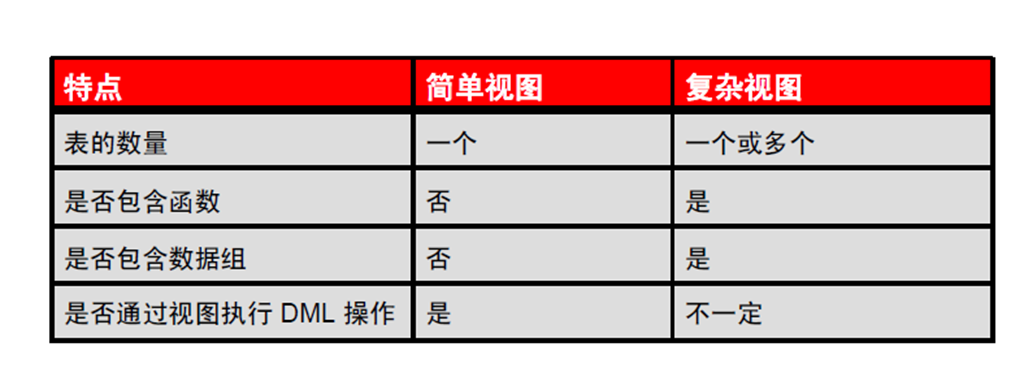
4:简单视图和复杂视图
5:创建视图
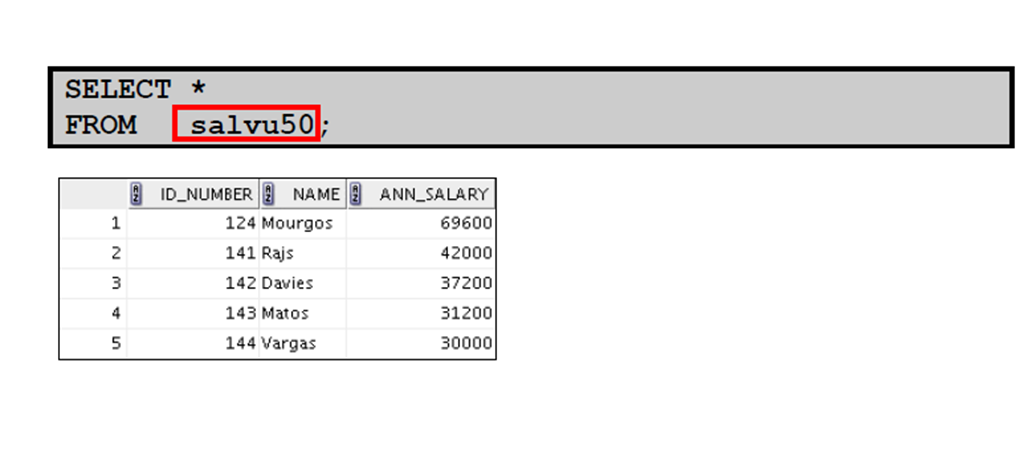
6:从视图中检索数据
7:修改视图
8:创建复杂视图
9:对视图执行DML 操作的规则
10:使用WITH CHECK OPTION 子句
11:拒绝DML 操作






2:序列概览:
– 创建、使用和修改序列
– 高速缓存序列值
– NEXTVAL 和CURRVAL 伪列
1:CREATE SEQUENCE 语句:语法
2:创建序列
3:NEXTVAL 和CURRVAL 伪列
4:使用序列
5:高速缓存序列值
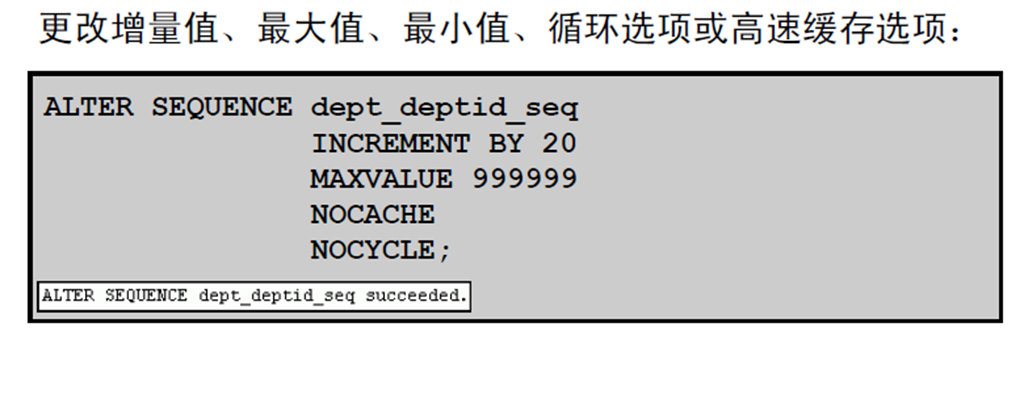
6:修改序列
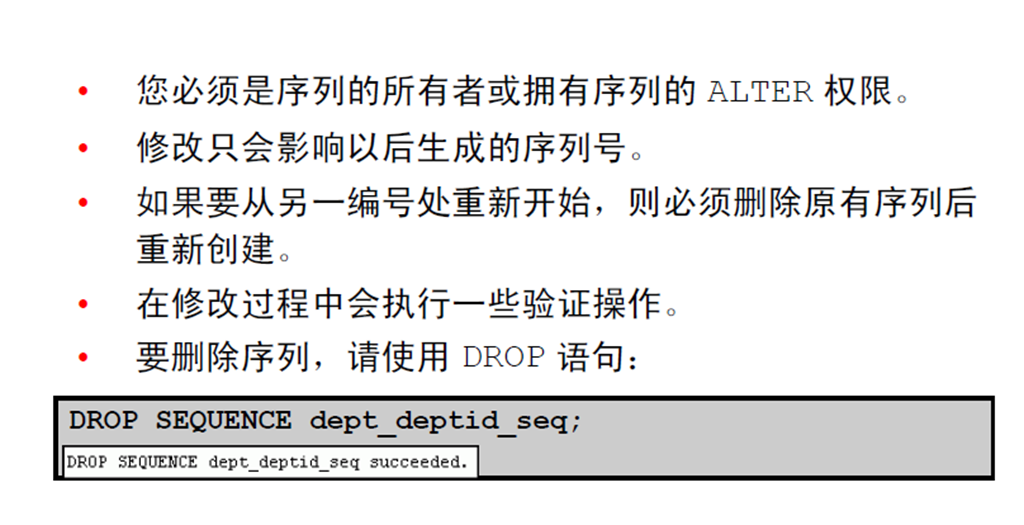
7:修改序列的准则





3:索引概览
– 创建、删除索引
1:索引
2:如何创建索引
3:创建索引
4:索引创建准则
5:删除索引
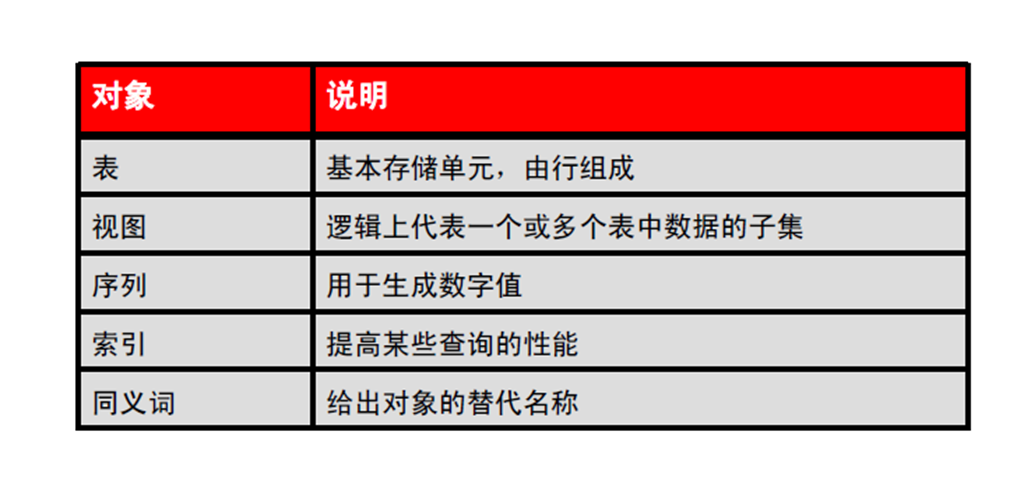




4:同义词概览
– 创建、删除同义词
1:创建对象的同义词
2:创建和删除同义词

第十二章:控制授权
1:系统权限
1:控制用户访问
2:权限
3:系统权限
4:创建用户
5:用户系统权限
6:授予系统权限
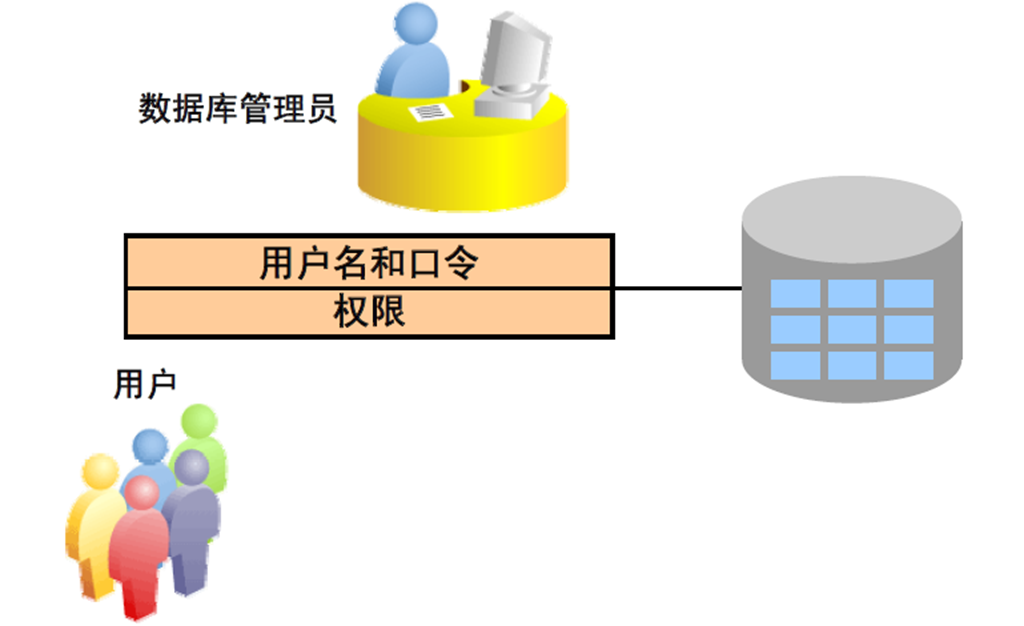





2:创建角色
1:角色是什么
2:创建角色和为角色授予权限
3:更改口令


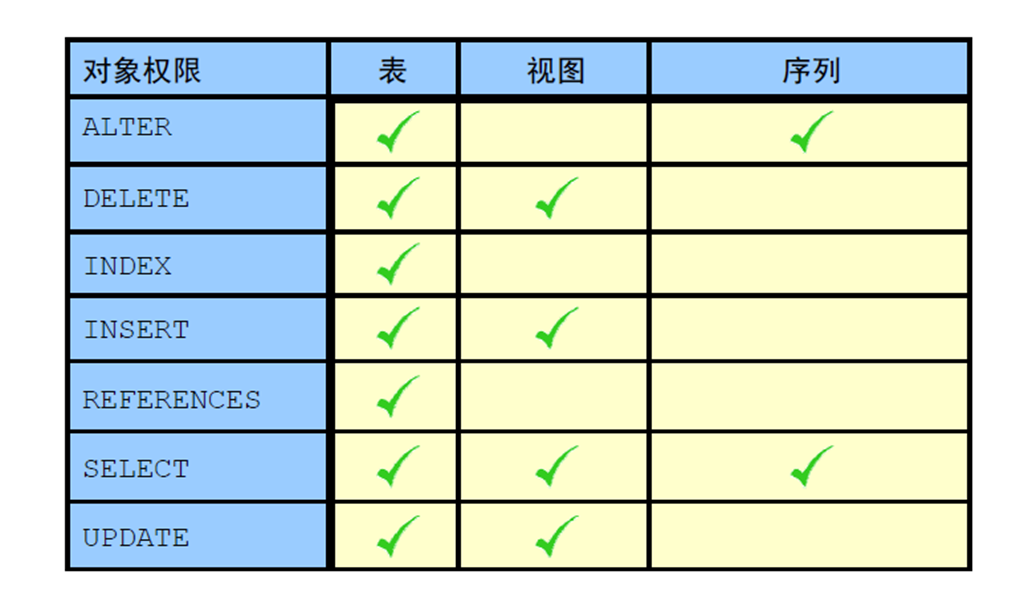
3:对象权限
1:对象权限
2:授予对象权限
3:传递权限
4:确认授予的权限


4:撤消对象权限
1:撤消对象权限

第十三章:管理方案对象
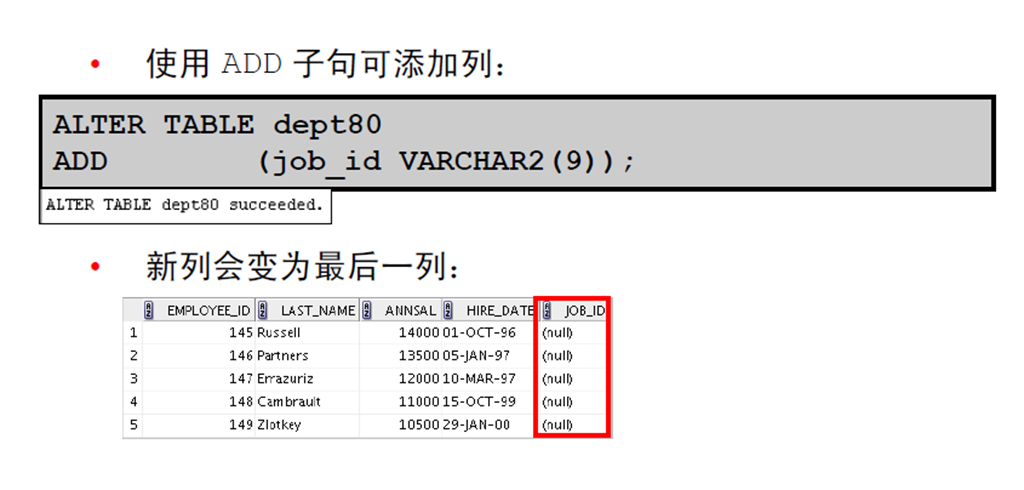
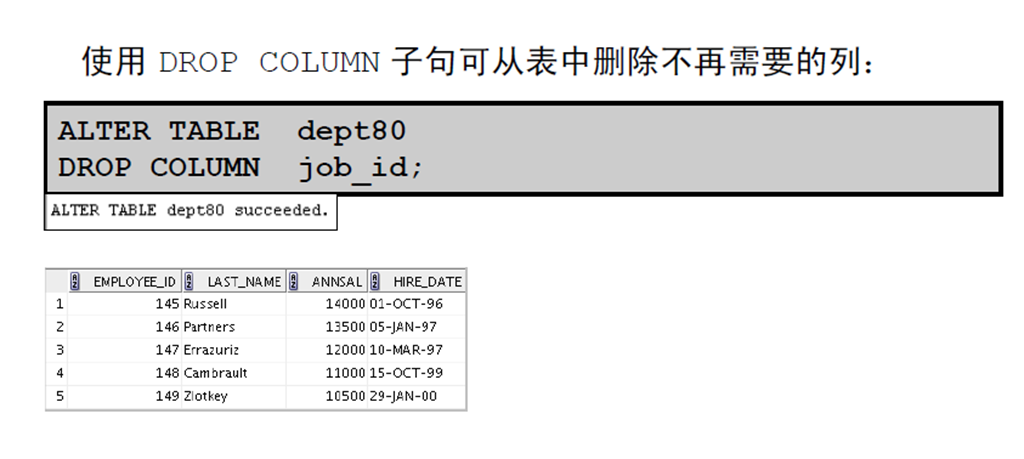
1:使用ALTER TABLE 语句添加、修改或删除列
1:ALTER TABLE 语句
2:添加列
3:修改列
4:删除列
5:SET UNUSED 选项



2:管理约束条件:
– 添加和删除约束条件
– 延迟约束条件
– 启用和禁用约束条件
1:添加约束条件语法
2:
添加约束条件
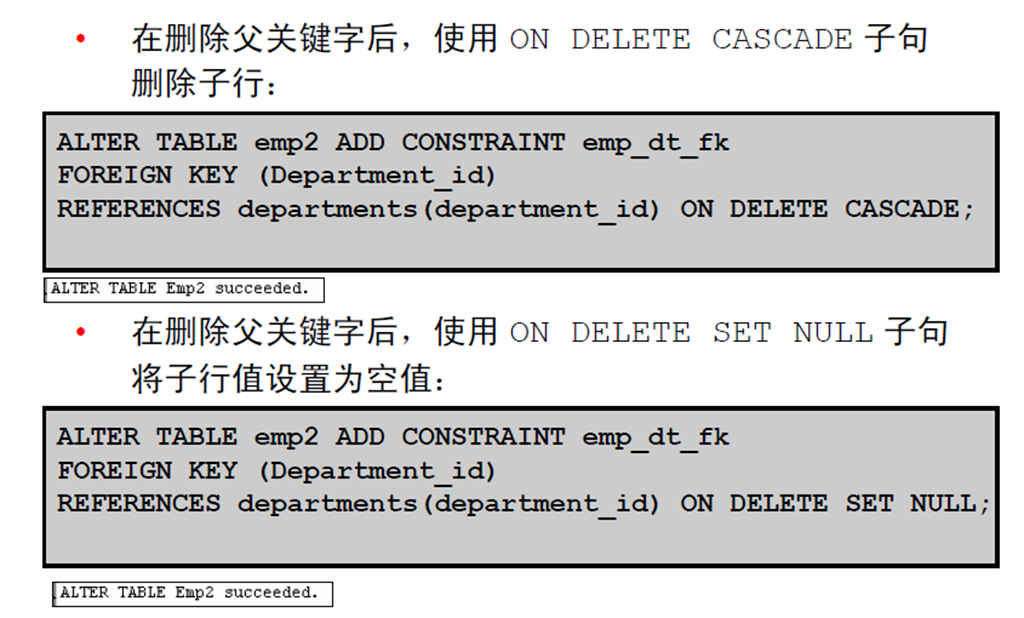
4:ON DELETE 子句
5:延迟约束条件
6:INITIALLY DEFERRED 与
INITIALLY IMMEDIATE 之间的区别
7:删除约束条件
8:禁用约束条件
9:启用约束条件
10:级联约束条件
11:重命名表列和约束条件









3:创建索引:
– 使用CREATE TABLE 语句
– 创建基于函数的索引
– 删除索引
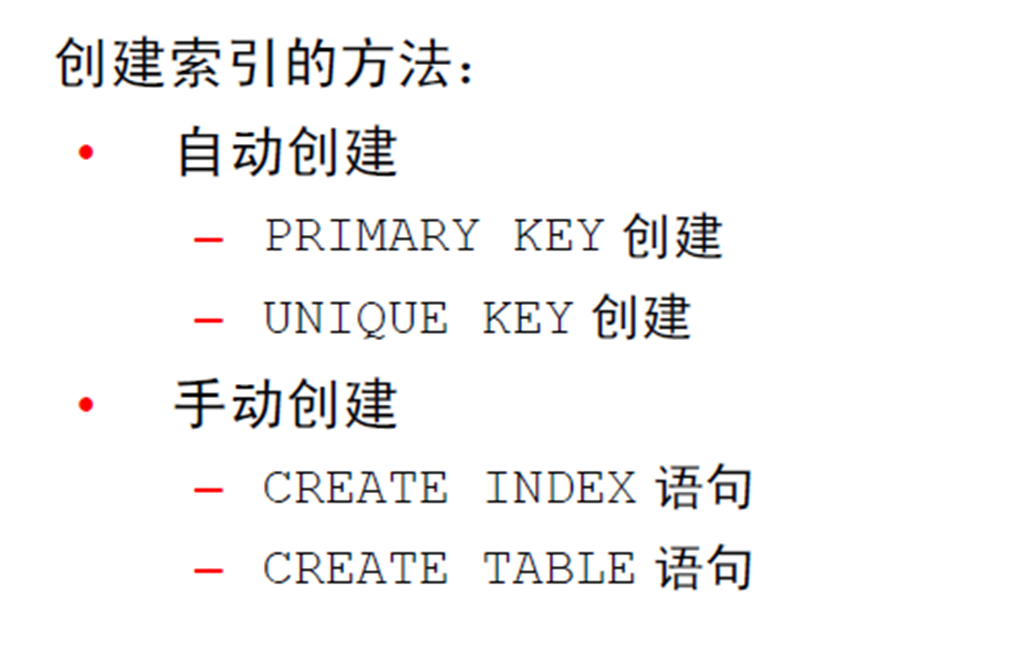
1:索引概览
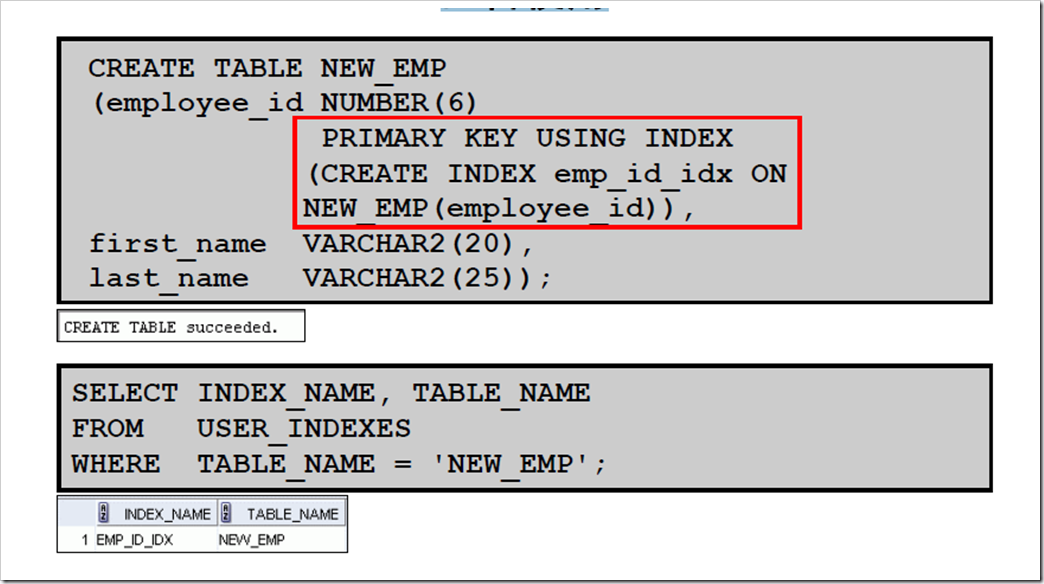
2:CREATE INDEX 与CREATE TABLE 语句
配合使用
3:基于函数的索引
4:删除索引
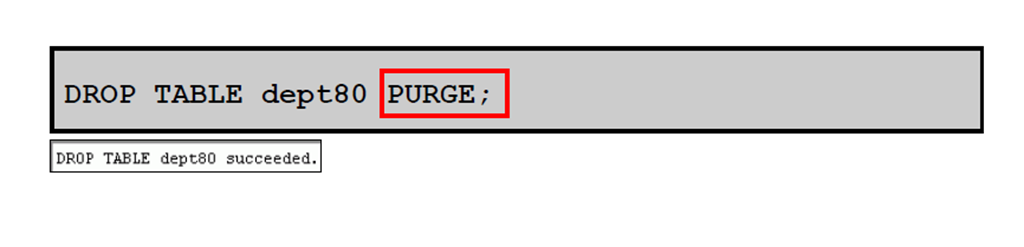
5:DROP TABLE … PURGE


4:执行闪回操作
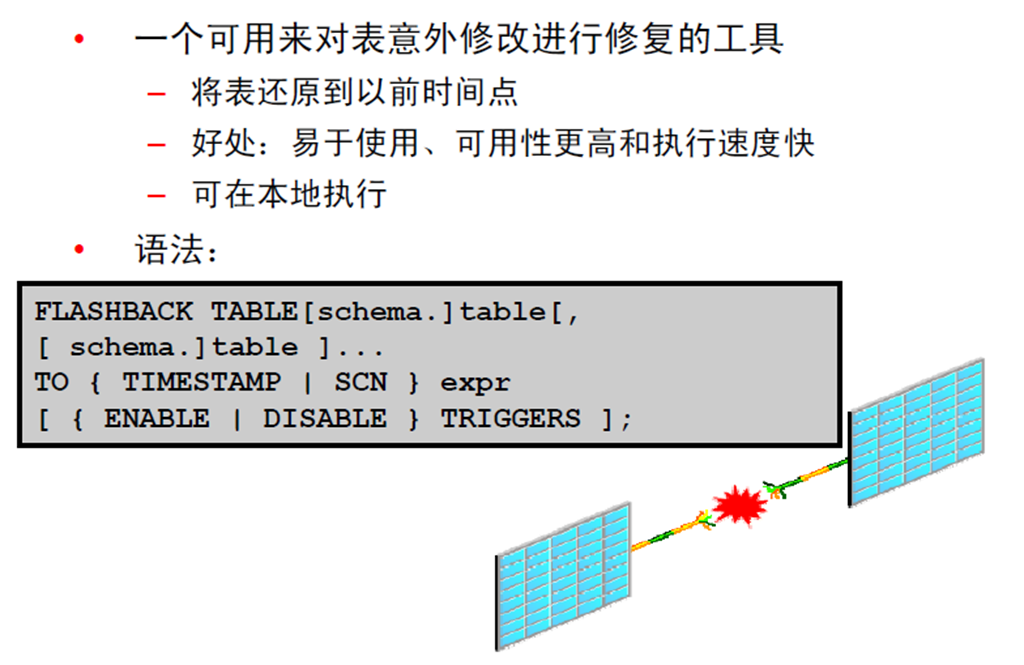
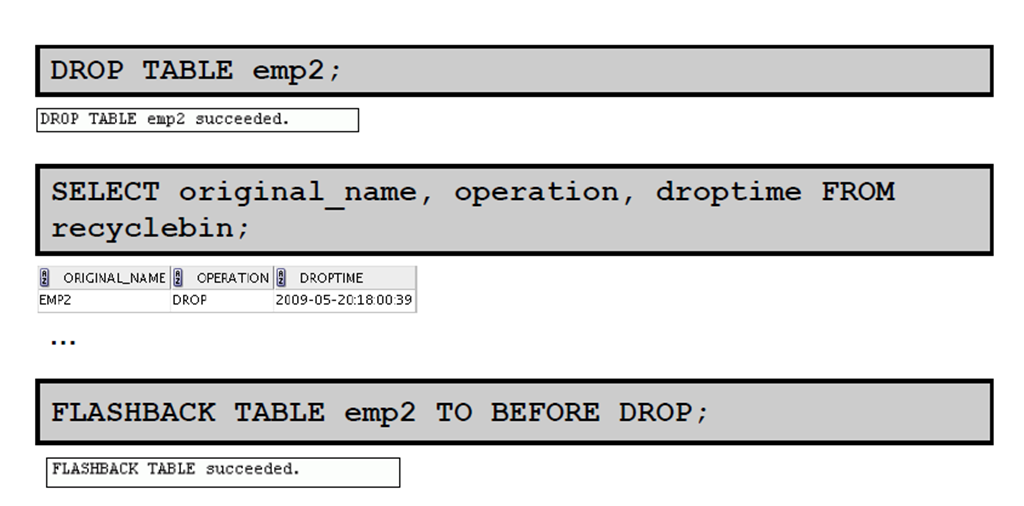
1:FLASHBACK TABLE 语句
2:使用FLASHBACK TABLE 语句
5:创建和使用临时表
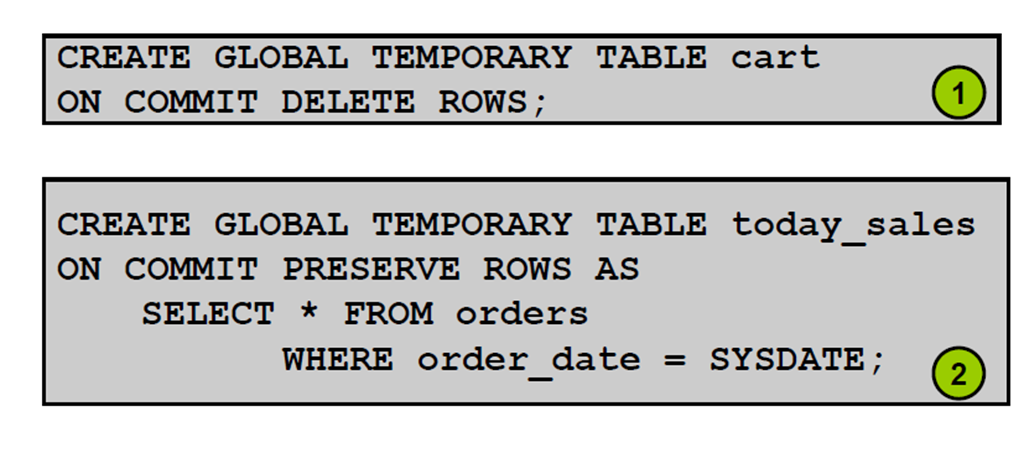
1:临时表
2:创建临时表
6:创建和使用外部表
1:外部表
2:创建外部表目录
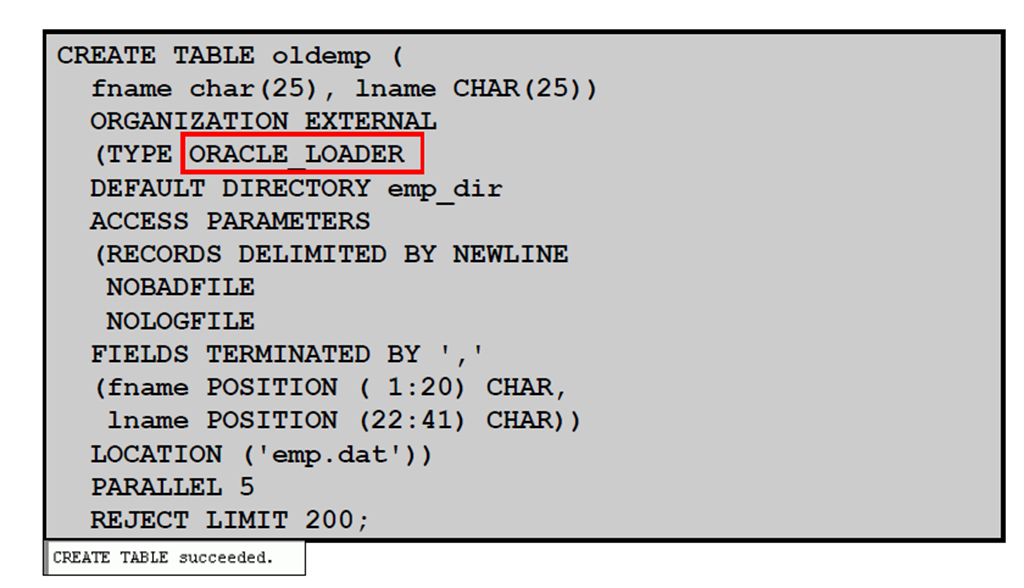
3:创建外部表
4:使用ORACLE_LOADER 创建外部表
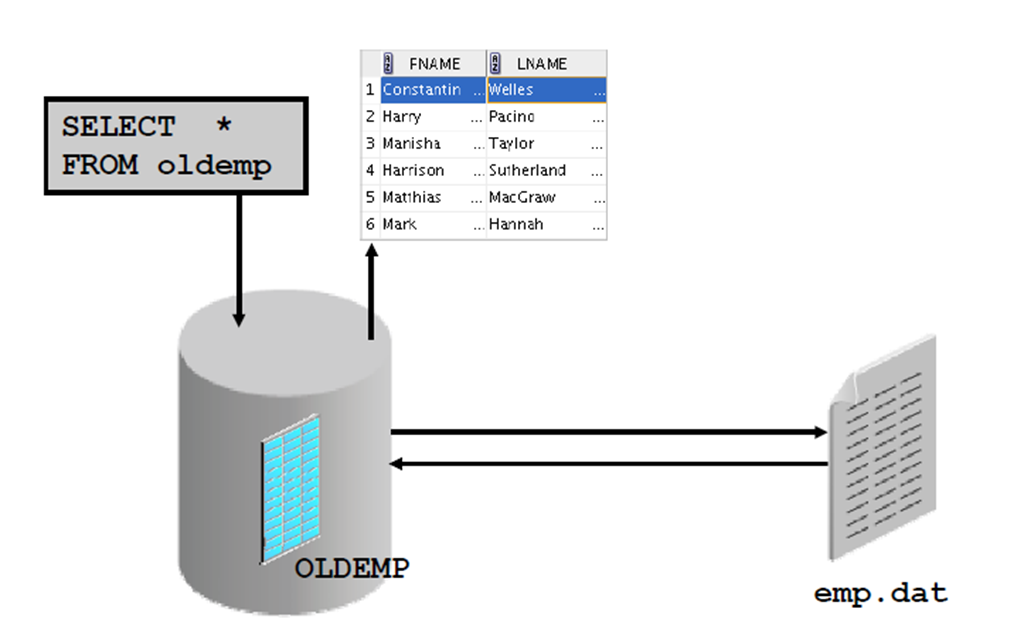
5:查询外部表
6:使用ORACLE_DATAPUMP 创建外部表:示例


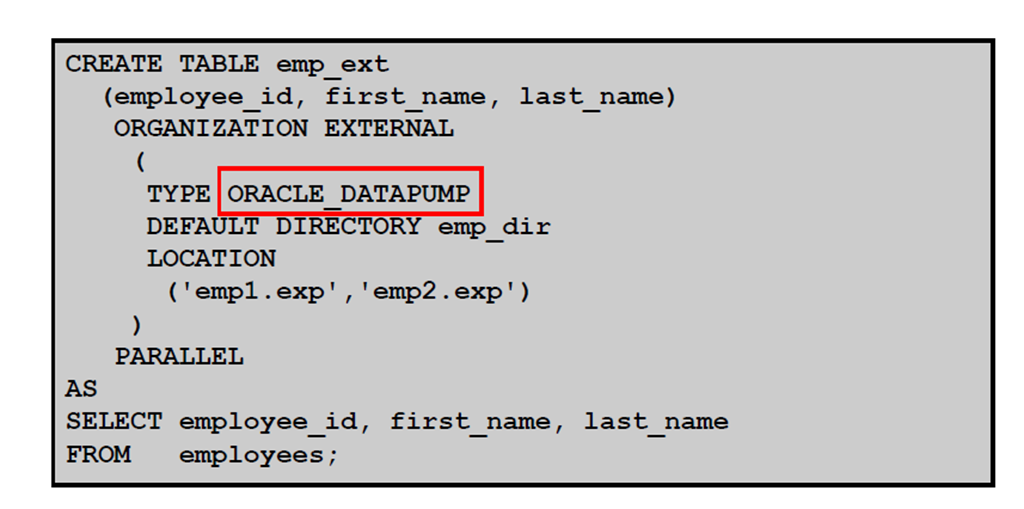
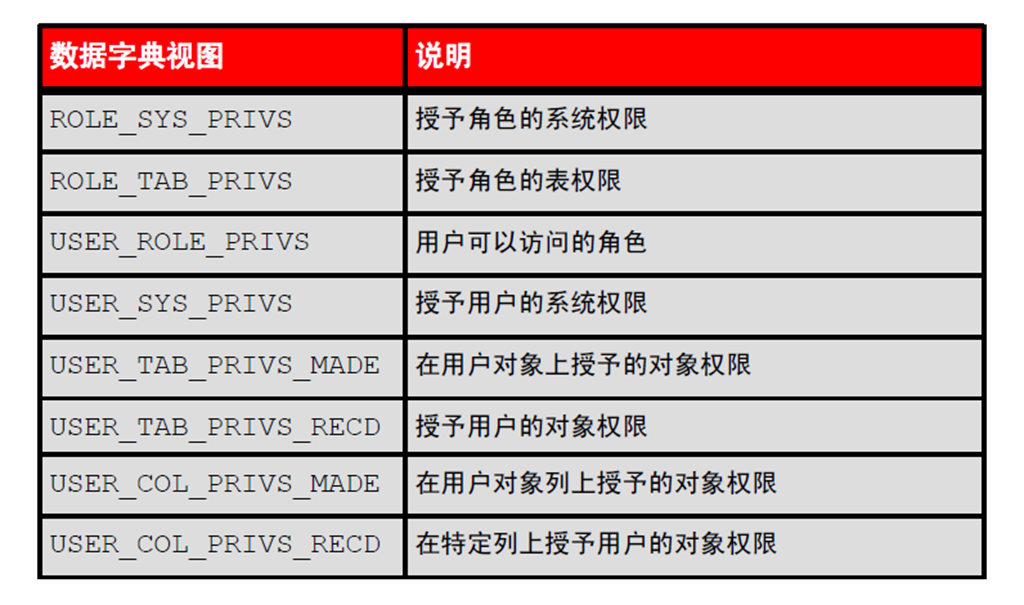
第十四章:使用数据字典视图管理对象
1:数据字典简介
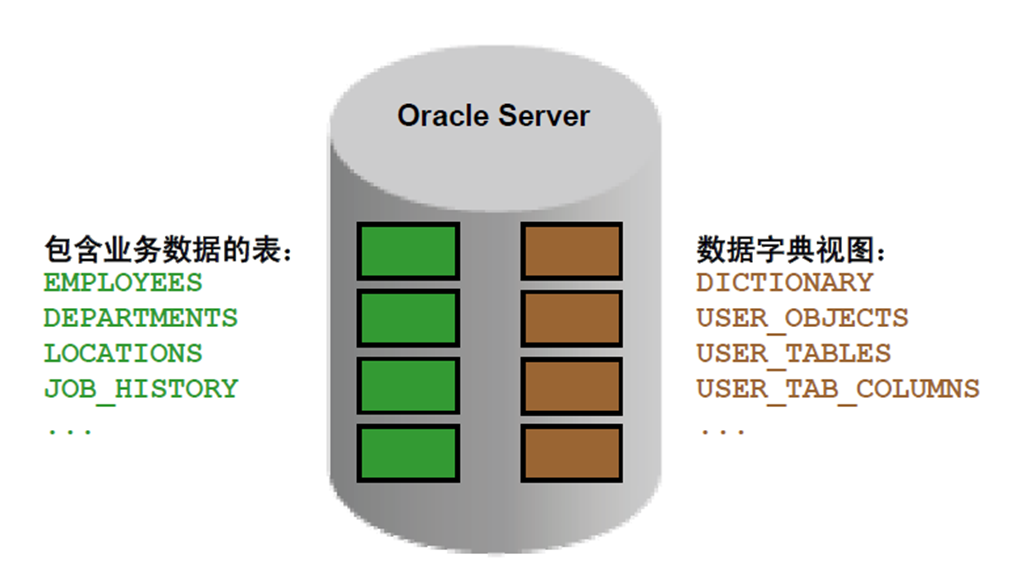
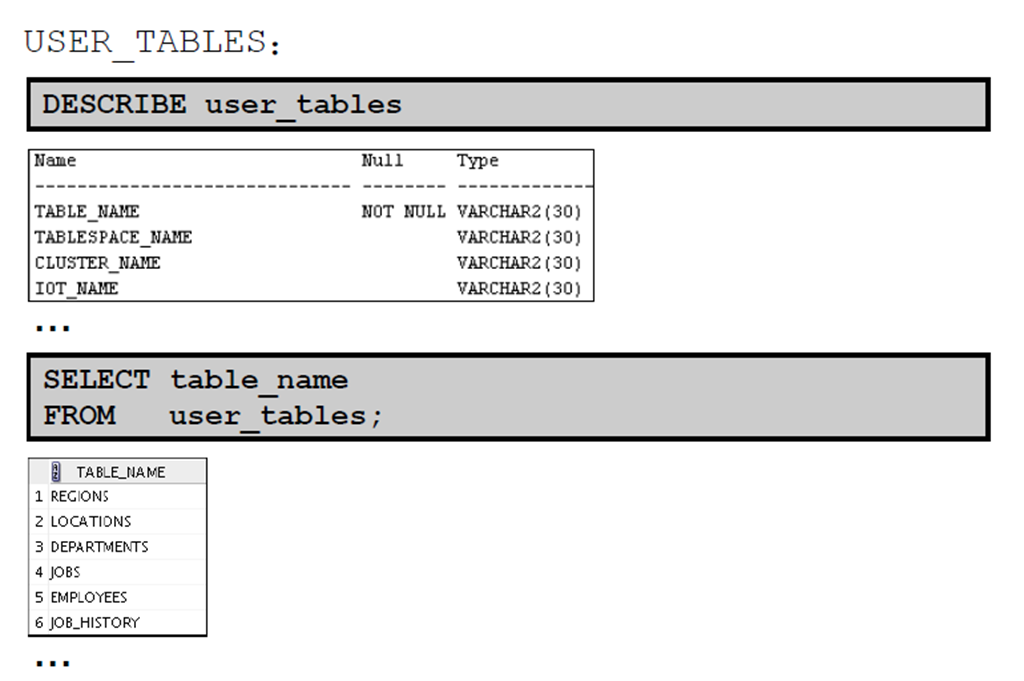
1:数据字典
2:数据字典结构
3:如何使用字典视图
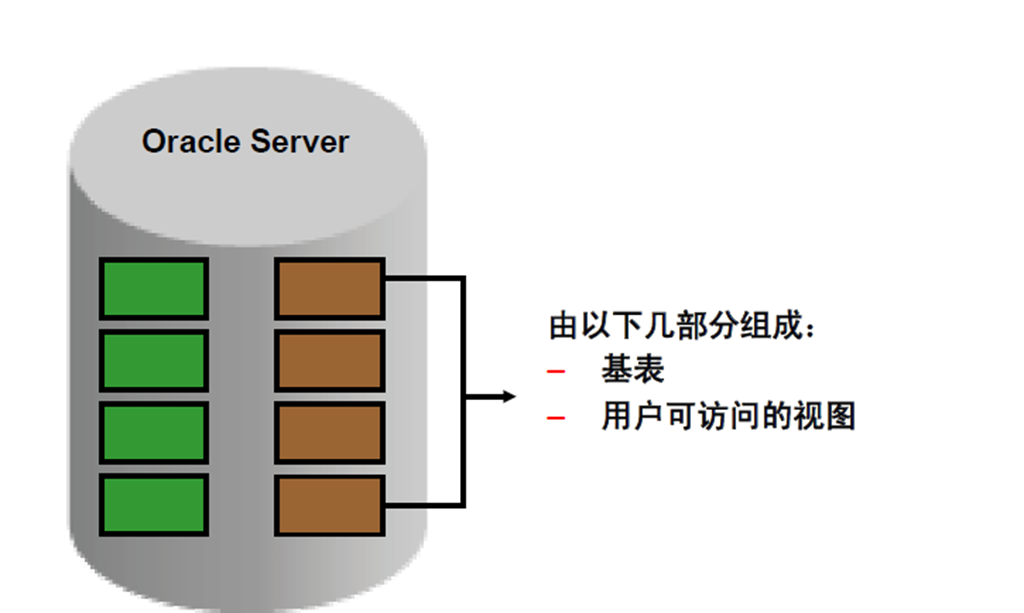
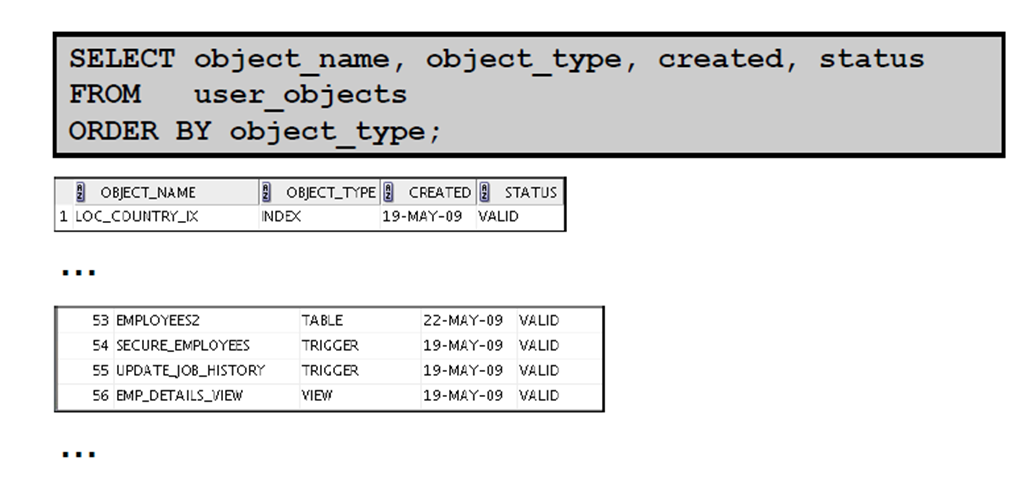
4:USER_OBJECTS 和ALL_OBJECTS 视图
5:USER_OBJECTS 视图


2:在字典视图中查询以下信息:
– 表信息
– 列信息
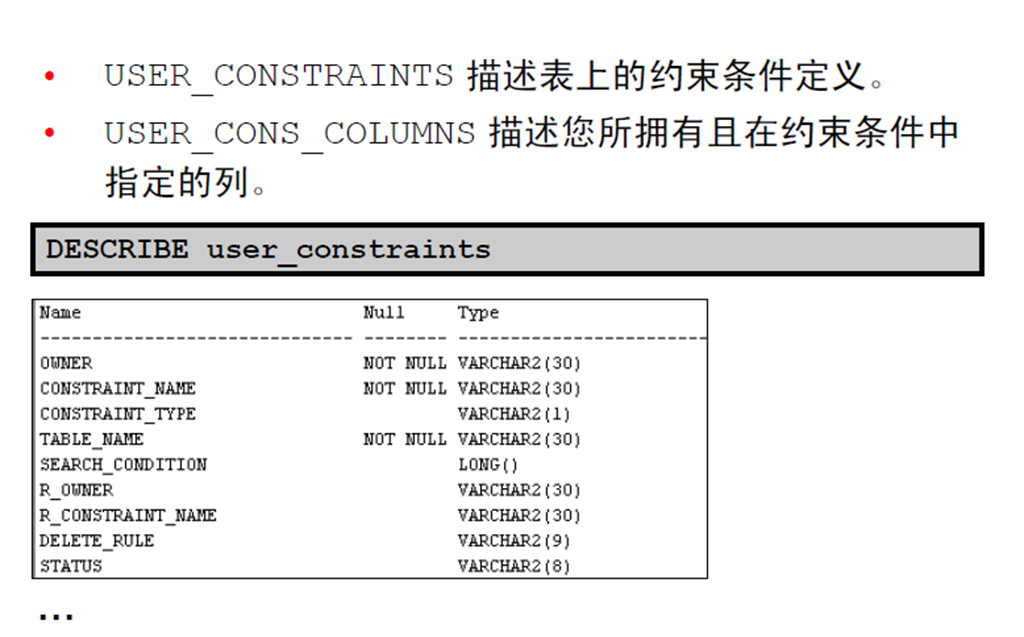
– 约束条件信息
1:表信息
2:列信息
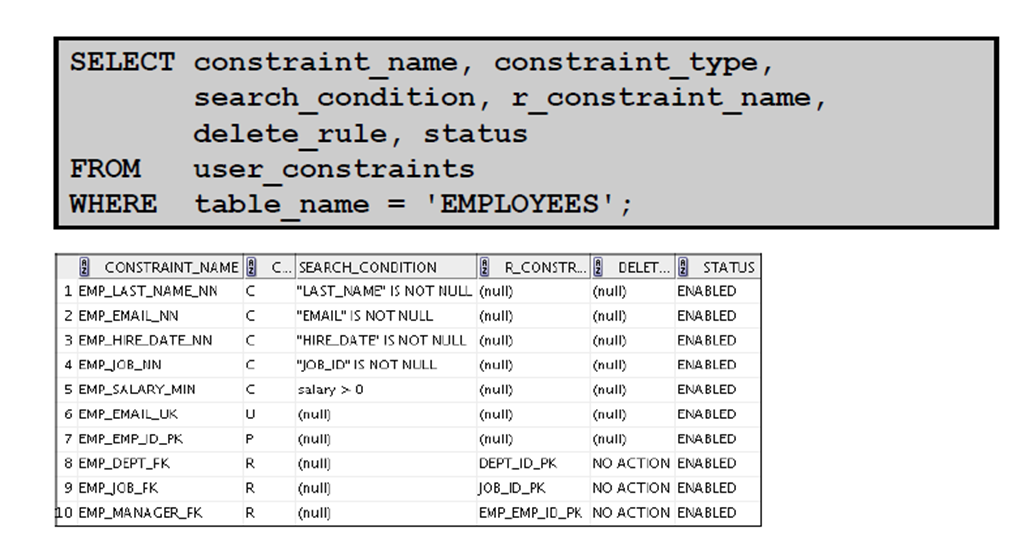
3:约束条件信息
4:USER_CONSTRAINTS:示例
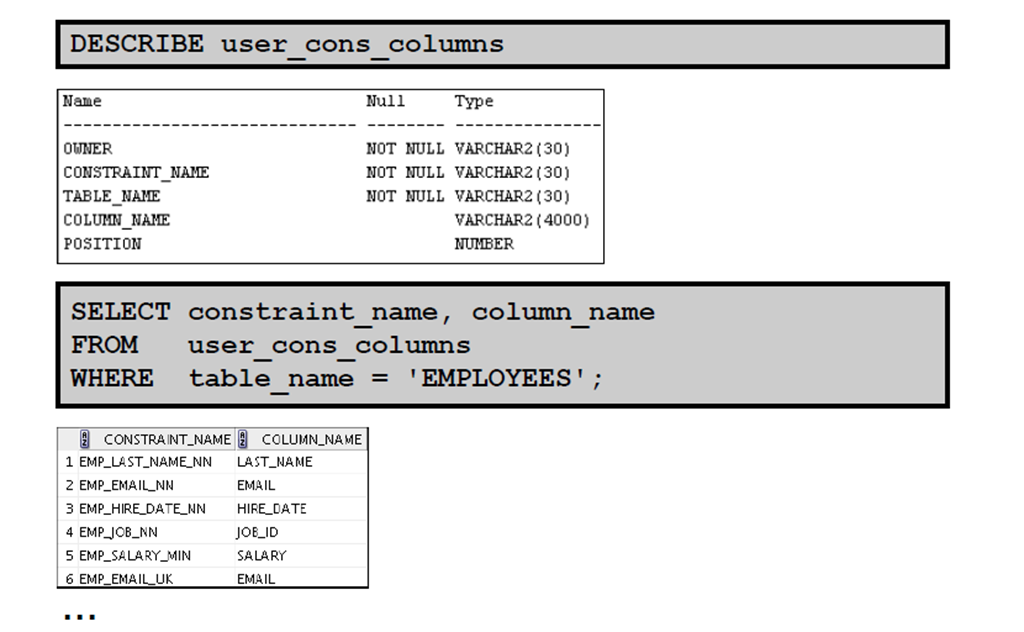
5:
在USER_CONS_COLUMNS 中进行查询

3:在字典视图中查询以下信息:
– 视图信息
– 序列信息
– 同义词信息
– 索引信息
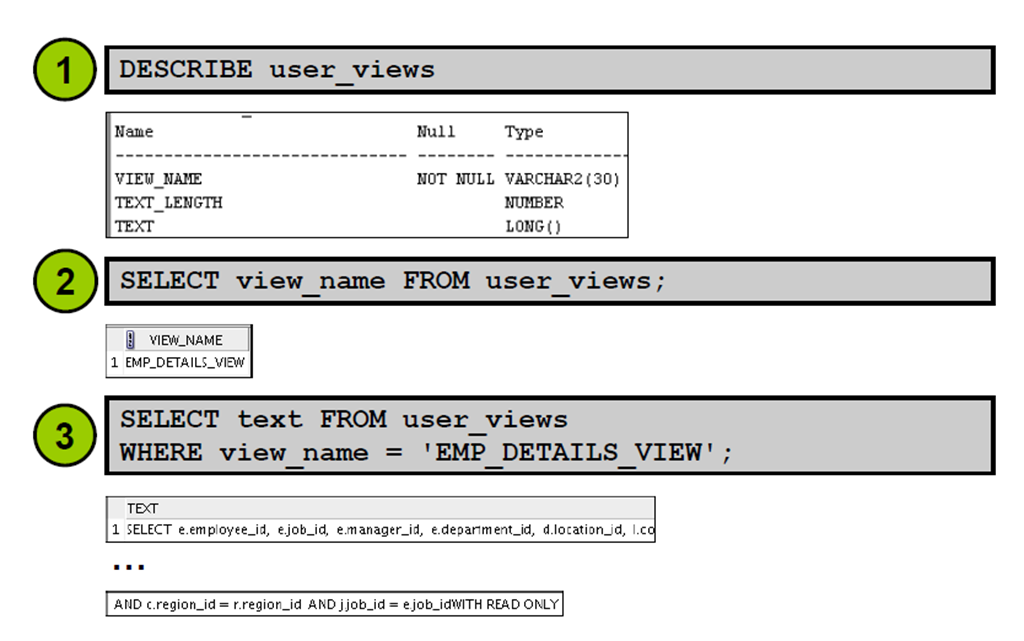
1:视图信息
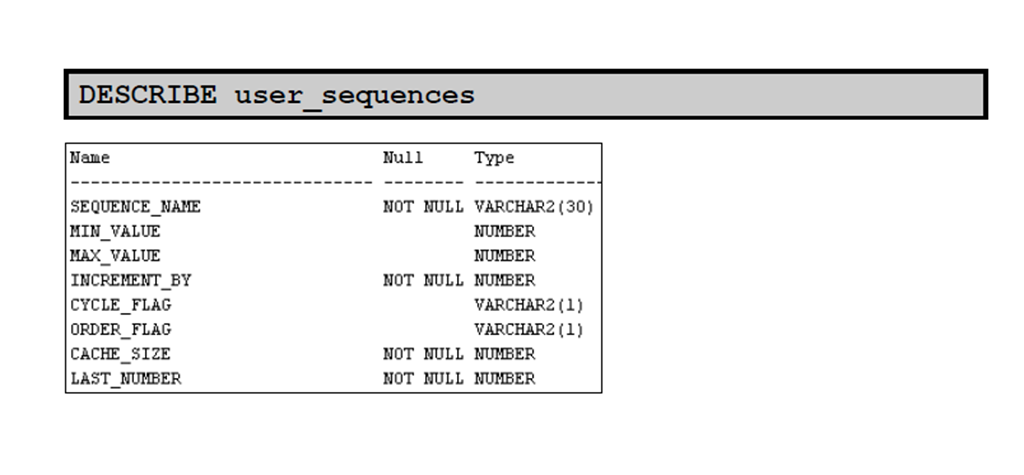
2:序列信息
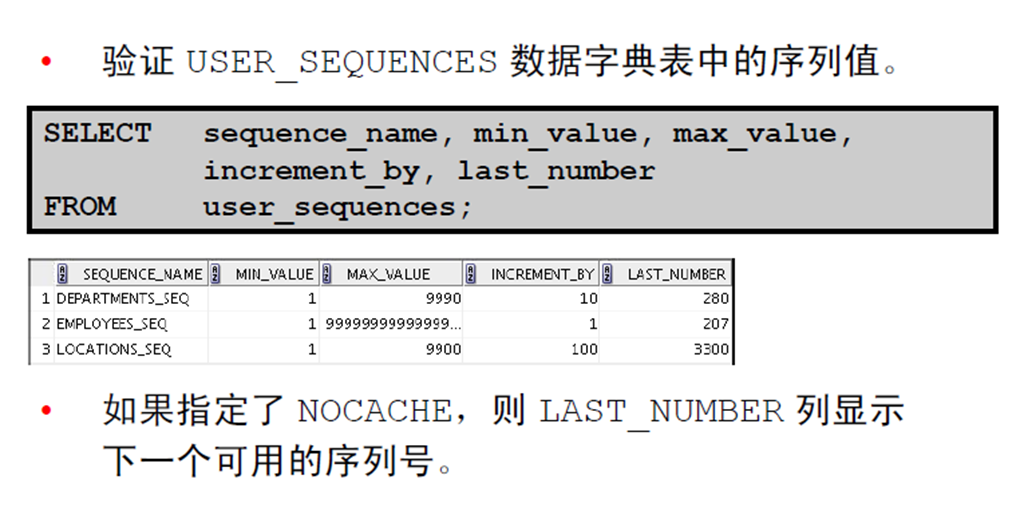
3:确认序列
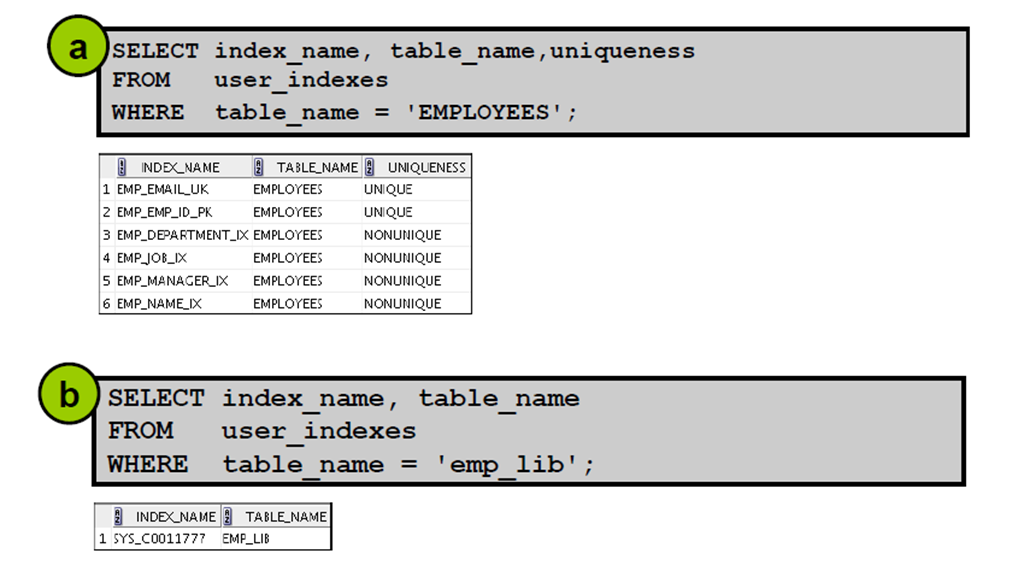
4:索引信息
5:USER_INDEXES:示例
6:在USER_IND_COLUMNS 中进行查询
7:同义词信息


4:在表中添加注释以及在字典视图中查询注释信息
1:在表中添加注释

第十五章:处理大型数据集
1:使用子查询处理数据
1:使用子查询处理数据
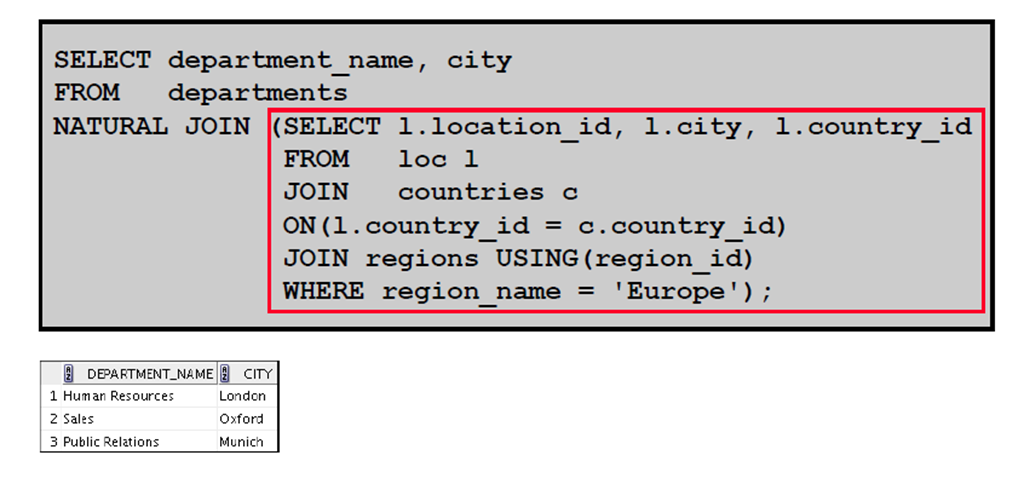
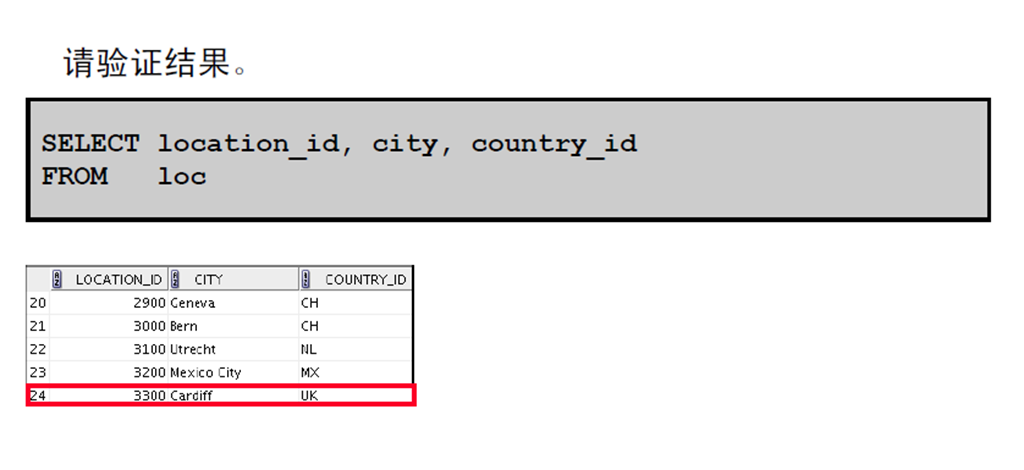
2:通过将子查询用作源来检索数据
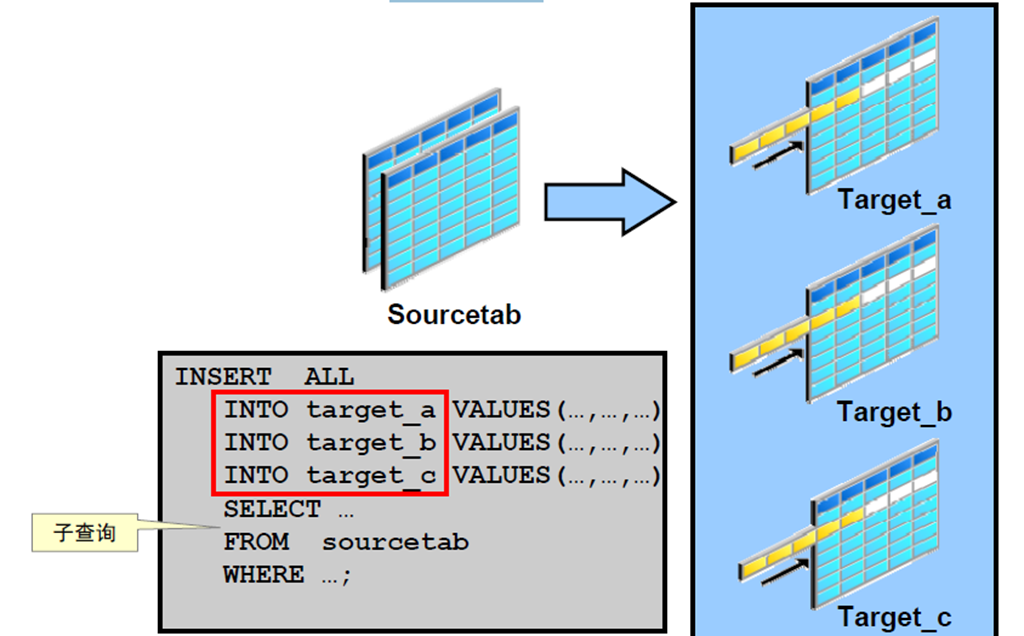
3:通过将子查询用作目标来执行插入
4:通过将子查询用作目标来执行插入
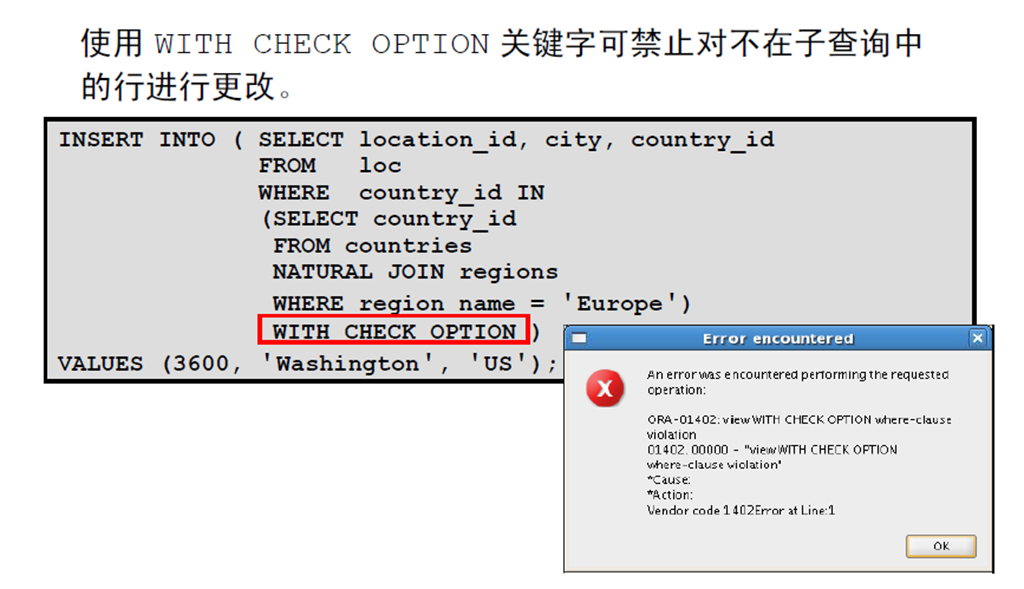
5:在DML 语句中使用WITH CHECK OPTION 关键字


2:在INSERT 和UPDATE 语句中指定显式默认值
1:显式默认值功能概览
2:使用显式默认值
3:从其它表中复制行


3:使用以下类型的多表INSERT:
– 无条件INSERT
– 转换INSERT (Pivoting INSERT)
– 条件INSERT ALL
– 条件INSERT FIRST
1:多表INSERT 语句概览
2:多表INSERT 语句的类型
3:多表INSERT 语句
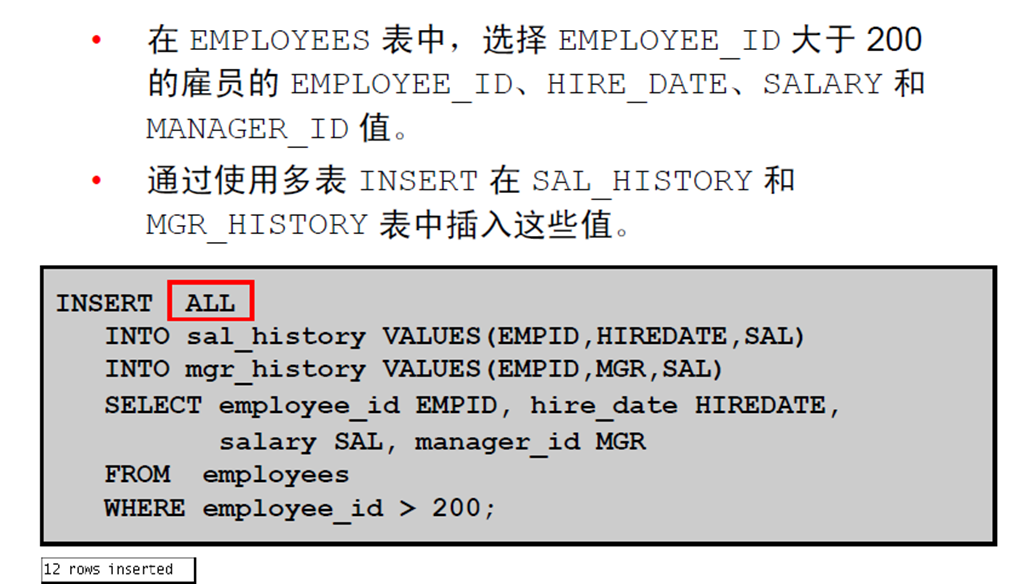
4:无条件INSERT ALL
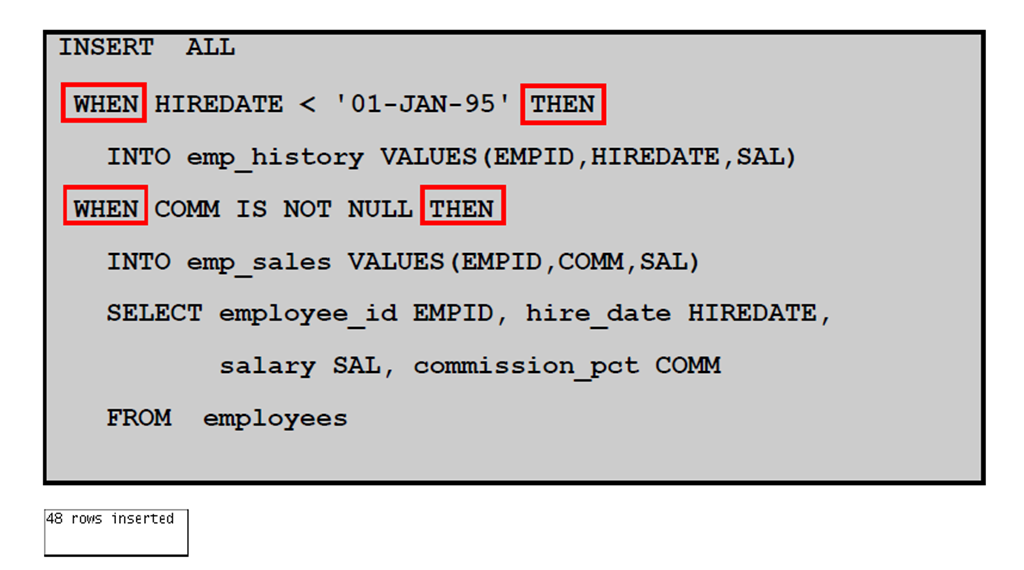
5:条件INSERT ALL:示例
6:条件INSERT ALL
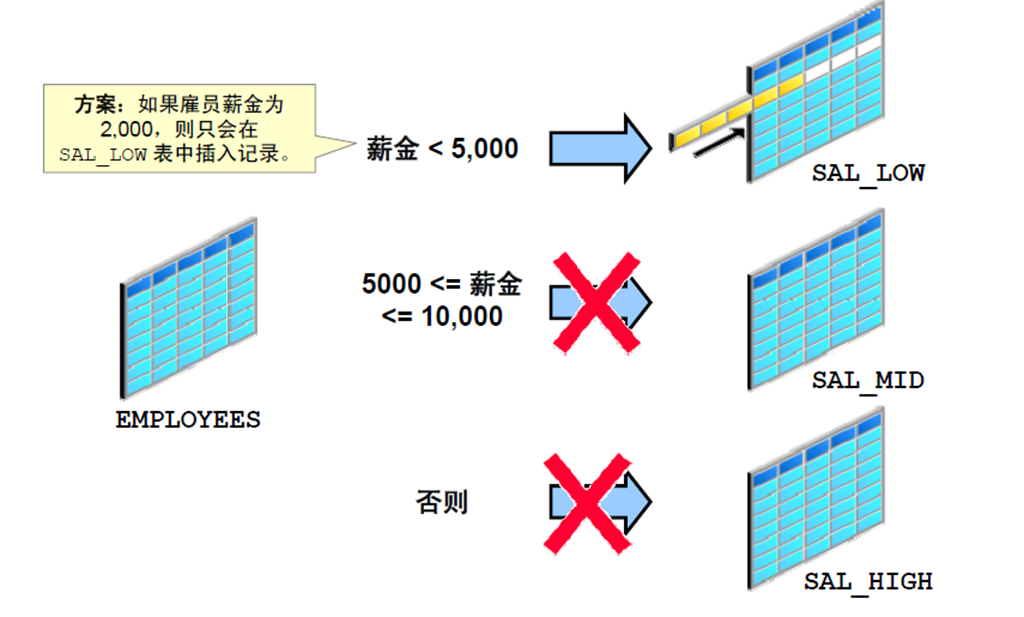
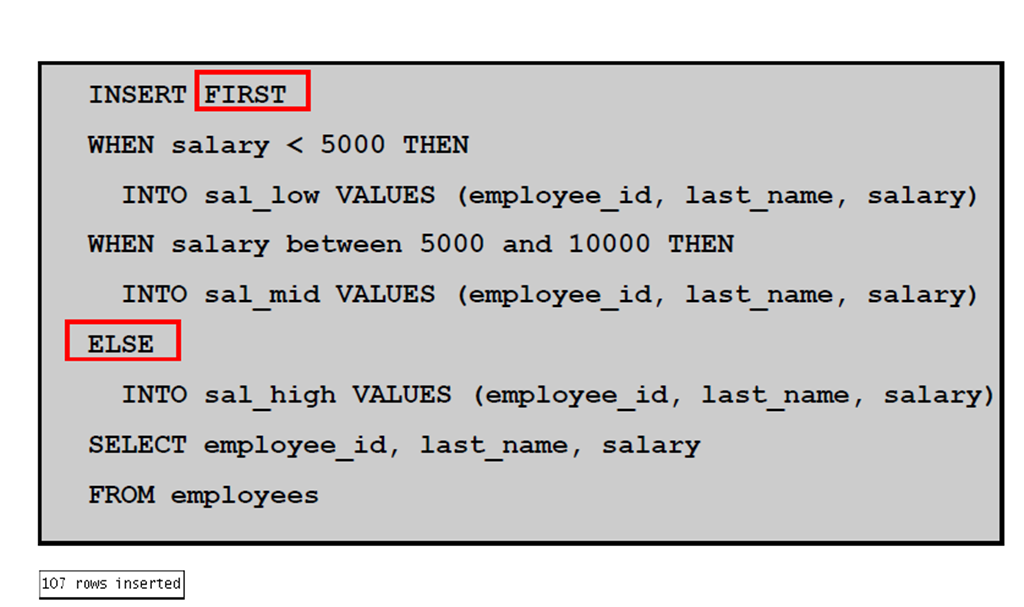
7:条件INSERT FIRST:示例
8:条件INSERT FIRST
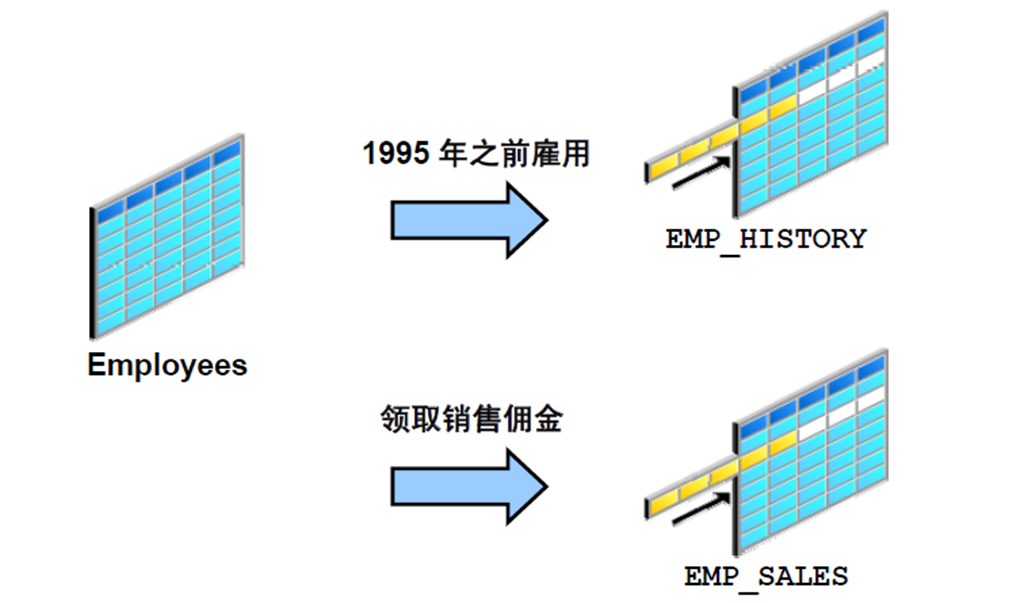
9:转换INSERT (Pivoting INSERT)


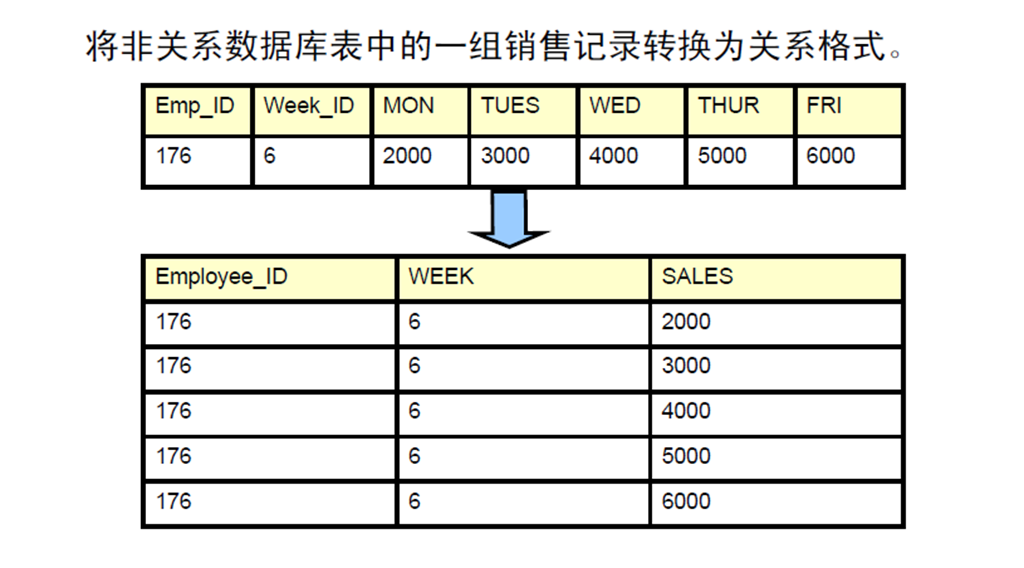
4:合并表行
1:MERGE 语句
2:MERGE 语句的语法
3:合并行:示例




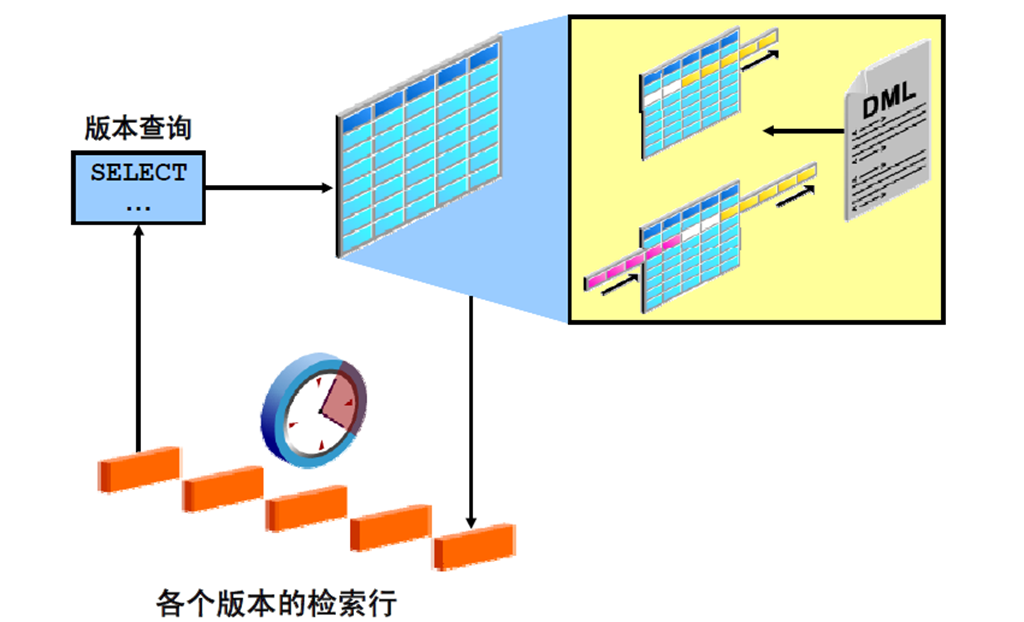
4:跟踪一段时间内的数据更改
1:跟踪数据更改
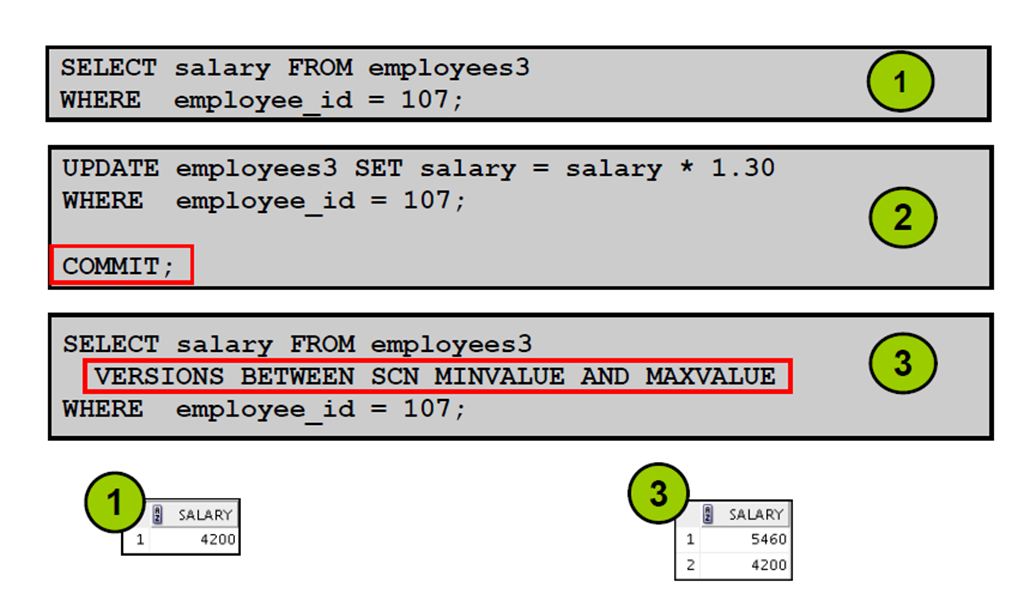
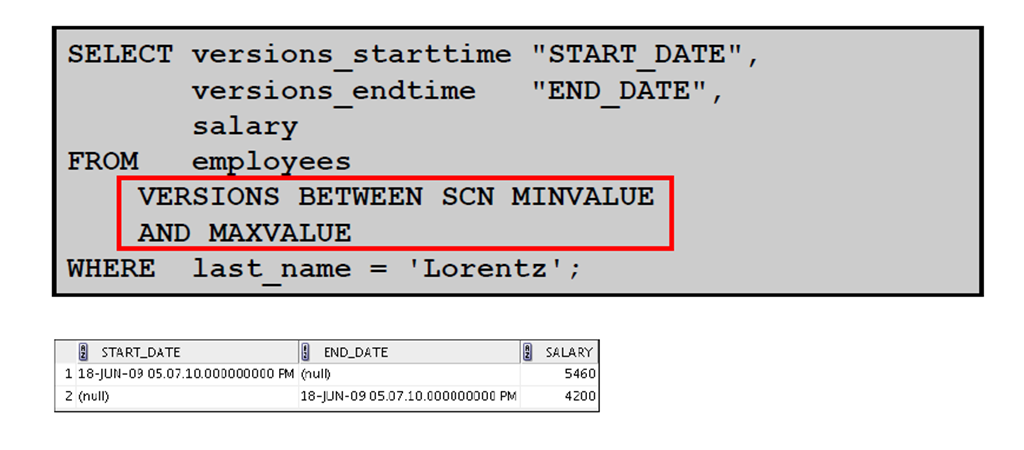
2:闪回版本查询示例
3:VERSIONS BETWEEN 子句
第十六章:管理不同时区中的数据
1:CURRENT_DATE、CURRENT_TIMESTAMP
和LOCALTIMESTAMP
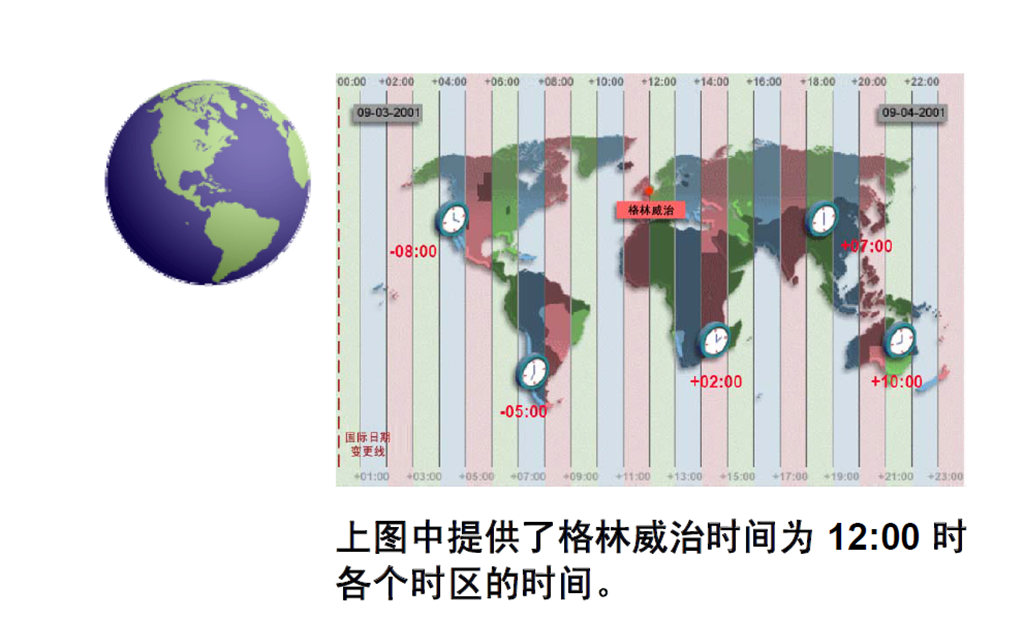
1:时区
/*如果需要支持一个国际化的应用,那么数据库端的国际化特性的支持也就显得尤其重要。Oracle中有很多特性支持国际化,如字符集、时区等等。如果相关参数设置不当,以至于在设计阶段没有考虑完全,那么肯定会对应用造成一定的损失。 Oracle中相关的时区大体分为两类:数据库时区和session时区。 0、查看os时区*/
[oracle@wl ~]$ cat /etc/sysconfig/clock --sysdate是调用操作系统里的gettimeofday函数,不依赖oracle数据库里设置的时区,用的是操作系统的时区。 --1、查看数据库和session时区 --//查看数据库时区
SQL> select dbtimezone from dual; --//查看session时区 SQL> select sessiontimezone from dual; --2、修改数据库和session时区 ---//修改数据库时区
SQL> ALTER DATABASE SET TIME_ZONE='+08:00'; ---//修改当前会话时区
SQL> ALTER SESSION SET TIME_ZONE='+08:00'; --其它修改方式
--//偏移量
ALTER SESSION SET TIME_ZONE = '-05:00';
--//数据库时区
ALTER SESSION SET TIME_ZONE = dbtimezone;
--//系统本地时区
ALTER SESSION SET TIME_ZONE = local;
---//时区名称
ALTER SESSION SET TIME_ZONE = 'America/New_York'; --//使用数据字典v$timezone_names查时区名称
SYS@orcl>select tzname from v$timezone_names where tzname like '%hai%'; ALTER SESSION SET NLS_DATE_FORMAT = 'DD-MON-YYYY HH24:MI:SS';
ALTER SESSION SET TIME_ZONE = '+8:00';
--返回当前的时间
SELECT SESSIONTIMEZONE, CURRENT_DATE FROM DUAL;
--系统当前的时间戳
SELECT SESSIONTIMEZONE, CURRENT_TIMESTAMP FROM DUAL;
--用户会话级别的当前时间戳
SELECT SESSIONTIMEZONE, LOCALTIMESTAMP FROM DUAL; --3、和时区相关的数据类型
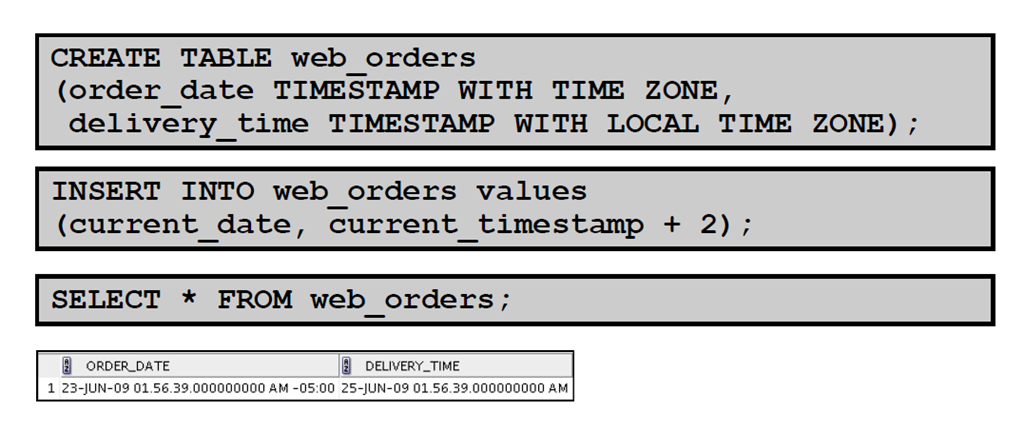
DATE、TIMESTAMP、TIMESTAMP WITH TIME ZONE、TIMESTAMP WITH LOCAL TIME ZONE --DATE:存储日期和时间信息,精确到秒。 SQL> alter session set nls_date_format='YYYY-MM-DD HH24:MI:SS';
SQL> select to_date('2009-01-12 13:24:33','YYYY-MM-DD HH24:MI:SS') from dual; --TIMESTAMP:DATE类型的扩展,保留小数级别的秒,默认为小数点后6位。不保存时区和地区信息。 SQL> select localtimestamp from dual; ALTER SESSION SET NLS_TIMESTAMP_FORMAT='DD-MON-YY HH:MI:SSXFF';
CREATE TABLE table_ts(c_id NUMBER, c_ts TIMESTAMP);
INSERT INTO table_ts VALUES(1, '01-JAN-2009 2:00:00');
INSERT INTO table_ts VALUES(2, TIMESTAMP '2009-01-01 2:00:00');
INSERT INTO table_ts VALUES(3, TIMESTAMP '2009-01-01 2:00:00 -08:00');
commit;
set linesize 120
select * from table_ts;
--第三条数据的时区信息丢失! -------------------------------------------
/* TIMESTAMP WITH TIME ZONE:存储带时区信息的TIMESTAMP(以和UTC时间差或者地区信息的形式保存)。
ALTER SESSION SET NLS_TIMESTAMP_TZ_FORMAT='DD-MON-RR HH:MI:SSXFF AM TZR';
ALTER SESSION SET TIME_ZONE='-7:00';
CREATE TABLE table_tstz (c_id NUMBER, c_tstz TIMESTAMP WITH TIME ZONE);
INSERT INTO table_tstz VALUES(1, '01-JAN-2009 2:00:00 AM -07:00');
INSERT INTO table_tstz VALUES(2, TIMESTAMP '2009-01-01 2:00:00');
INSERT INTO table_tstz VALUES(3, TIMESTAMP '2009-01-01 2:00:00 -8:00');
commit;
select * from table_tstz;
数据保存了时区信息!
如果没有指定时区,用会话时区
--------------------------------------------
TIMESTAMP WITH LOCAL TIME ZONE:以数据库时区时间保存在数据库中,用户请求数据时,以客户端会话(session)时区时间返回,是另一种不同类型的TIMESTAMP。 TIMESTAMP WITH LOCAL TIME ZONE和
TIMESTAMP WITH TIME ZONE类型的区别在于:
数据库不保存时区相关信息,而是把客户端输入的时间转换为基于database timezone的时间后存入数据库。当用户请求此类型信息时,Oracle把数据转换为用户session的时区时间返回给用户。所以Oracle建议把database timezone设置为标准时间UTC,这样可以节省每次转换所需要的开销,提高性能。 TIMESTAMP WITH TIME ZONE、TIMESTAMP WITH LOCAL TIME ZONE两种数据类型是timestamp的变种,Date和timestamp数据类型不包含时区信息。 */
SQL>ALTER SESSION SET TIME_ZONE='-07:00'; CREATE TABLE table_tsltz (c_id NUMBER, c_tsltz TIMESTAMP WITH LOCAL TIME ZONE); INSERT INTO table_tsltz VALUES(1,'01-JAN-2009 2:00:00');
INSERT INTO table_tsltz VALUES(2, TIMESTAMP '2009-01-01 2:00:00');
INSERT INTO table_tsltz VALUES(3, TIMESTAMP '2009-01-01 2:00:00 -08:00');
commit; select * from table_tsltz;
/*
注意:
插入的第三条数据指定为UTC-8时区的时间,然后存入数据库后按照database timezone的时间保存,最后在客户端请求的时候,转换为客户端时区的时间返回!
//查看数据库时区 */
SQL> select dbtimezone from dual; --//查看session时区 SQL> select sessiontimezone from dual; --更改UTC-5
SYS@orcl>ALTER SESSION SET TIME_ZONE='-05:00';
SYS@orcl>select * from table_tsltz;
--当客户端时区改为UTC-5的时候,TIMESTAMP WITH LOCAL TIME ZONE数据类型的返回信息会相应改变的。
/* Oracle语法:
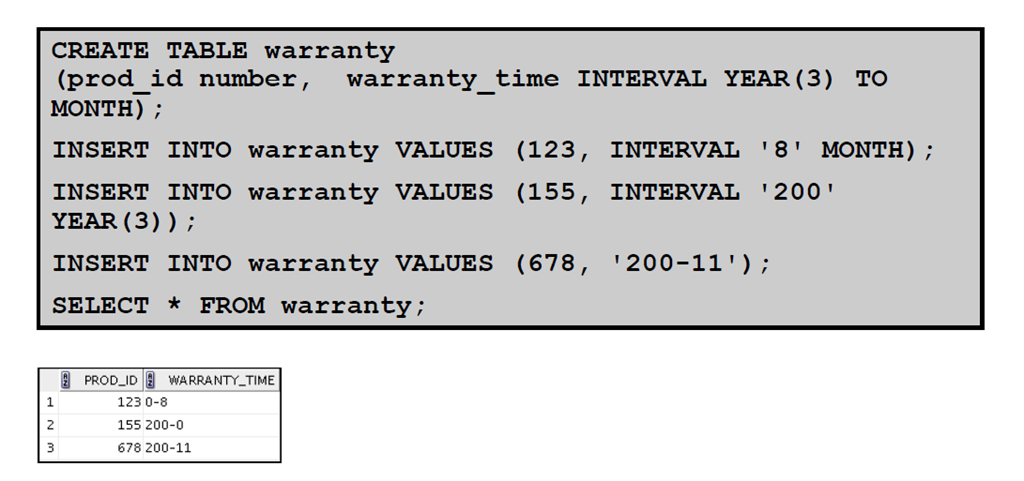
INTERVAL 'integer [- integer]' {YEAR | MONTH} [(precision)][TO {YEAR | MONTH}] 该数据类型常用来表示一段时间差, 注意时间差只精确到年和月,precision为年或月的精确域, 有效范围是0到9, 默认值为2。 例:
INTERVAL '123-2' YEAR(3) TO MONTH
表示: 123年2个月, "YEAR(3)" 表示年的精度为3, 可见"123"刚好为3为有效数值, 如果该处YEAR(n), n<3就会出错, 注意默认是2。 INTERVAL '123' YEAR(3)
表示: 123年0个月 INTERVAL '300' MONTH(3)
表示: 300个月, 注意该处MONTH的精度是3啊. INTERVAL '4' YEAR
表示: 4年, 同 INTERVAL '4-0' YEAR TO MONTH 是一样的 INTERVAL '50' MONTH
表示: 50个月, 同 INTERVAL '4-2' YEAR TO MONTH 是一样 INTERVAL '123' YEAR
表示: 该处表示有错误, 123精度是3了, 但系统默认是2, 所以该处应该写成 INTERVAL '123' YEAR(3) 或"3"改成大于3小于等于9的数值都可以的 INTERVAL '5-3' YEAR TO MONTH + INTERVAL '20' MONTH=INTERVAL '6-11' YEAR TO MONTH
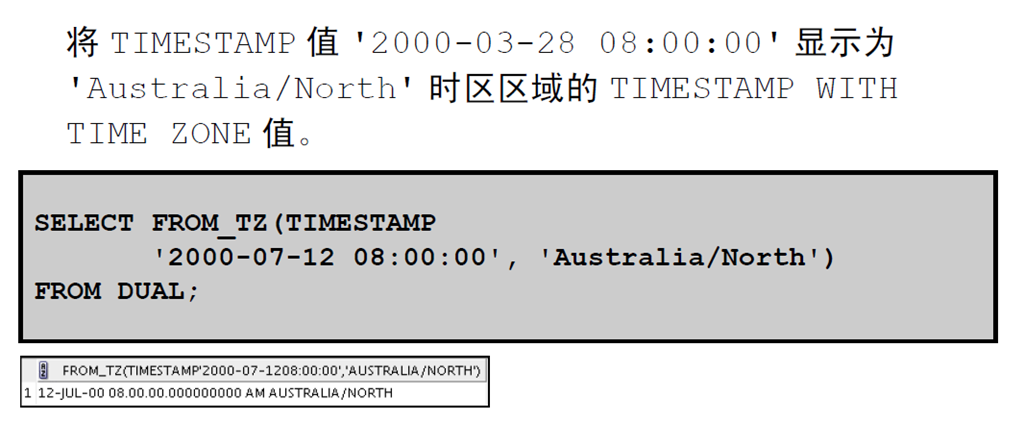
表示: 5年3个月 + 20个月 = 6年11个月 TZ_OFFSET函数根据时区名称,返回时区与0时区相差的小时和分钟数
from_tz函数将一个timstamp和timzone拼成一个timestamp with time zone
TO_TIMESTAMP函数将字符型转成timestamp
TO_YMINTERVAL 将字符型CHAR, VARCHAR2, NCHAR, or NVARCHAR2 转换为 INTERVAL YEAR TO MONTH 类型
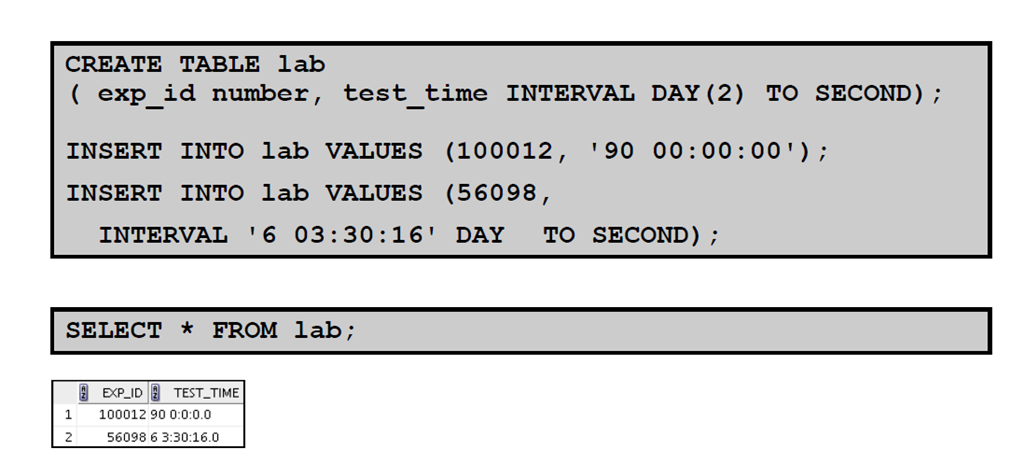
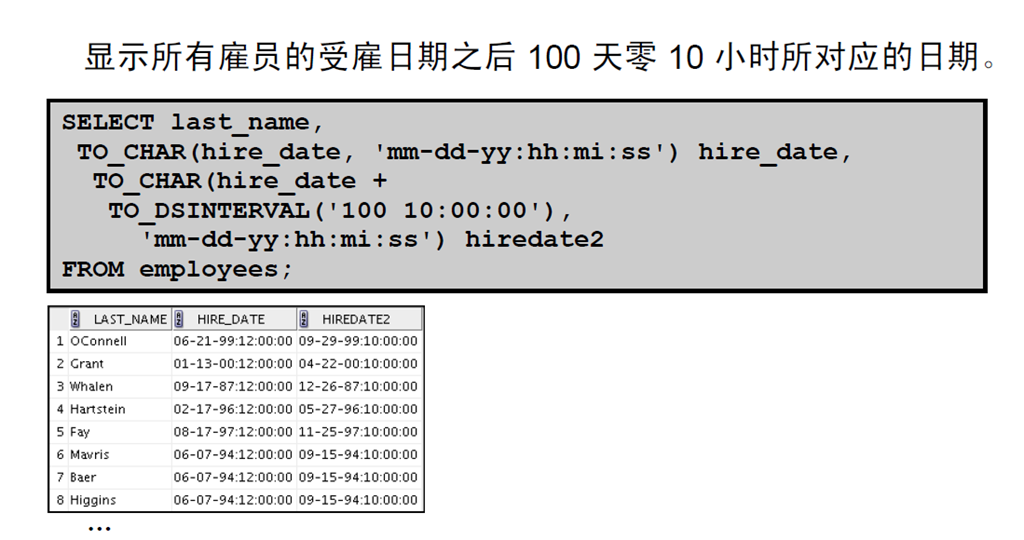
TO_DSINTERVAL 将字符型 CHAR, VARCHAR2, NCHAR, or NVARCHAR2 转换为 INTERVAL DAY TO SECOND
*/2:TIME_ZONE 会话参数
3:CURRENT_DATE、CURRENT_TIMESTAMP 和LOCALTIMESTAMP
4:对会话时区的日期和时间进行比较
5:DBTIMEZONE 和SESSIONTIMEZONE
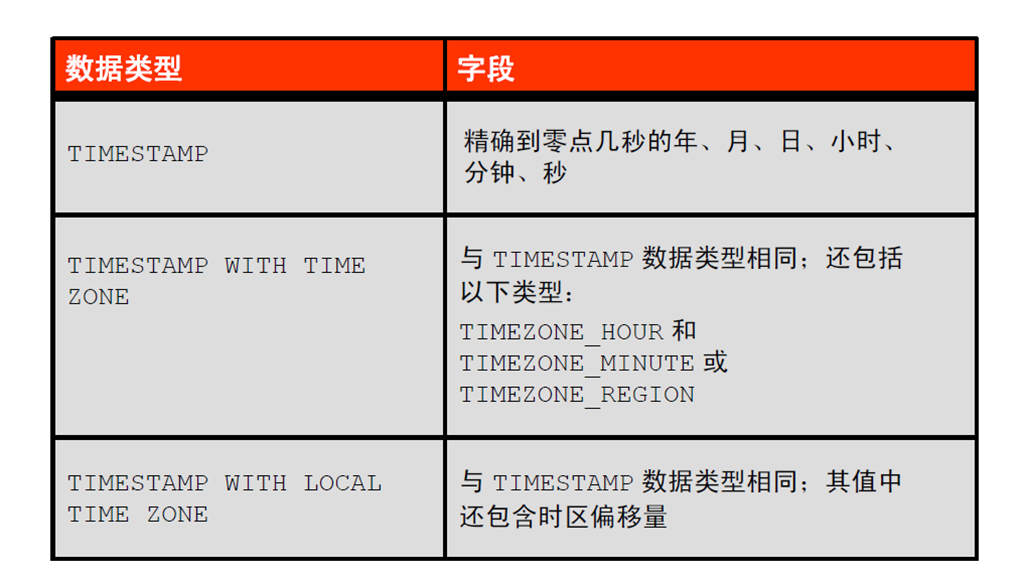
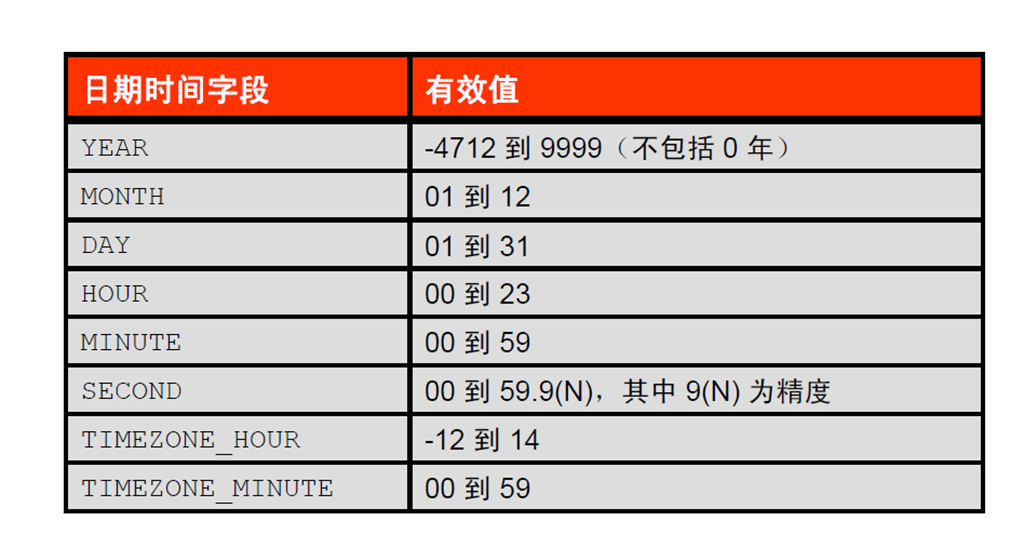
6:TIMESTAMP 数据类型
7:TIMESTAMP 字段
8:DATE 和TIMESTAMP 之间的区别
9:TIMESTAMP 数据类型的比较





2:INTERVAL 数据类型
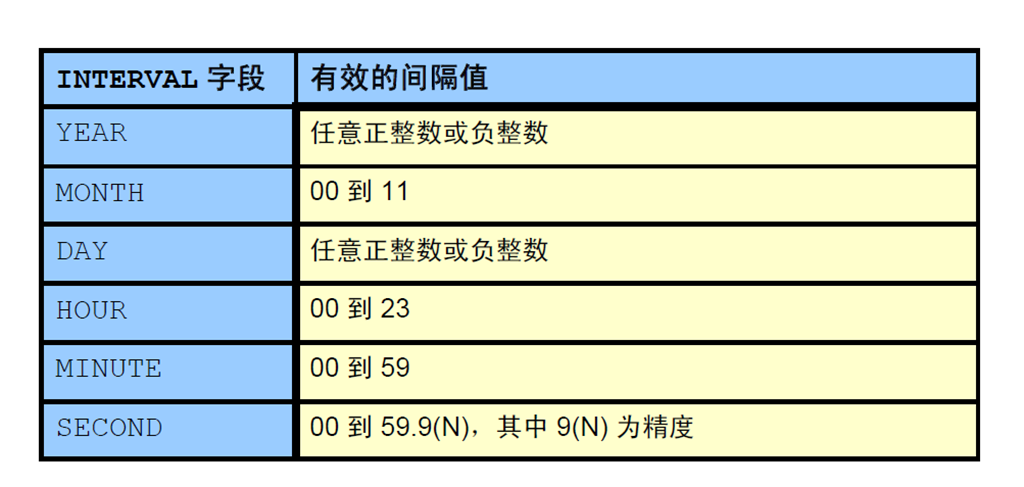
1:INTERVAL 数据类型
2:INTERVAL 字段
3:INTERVAL YEAR TO MONTH:示例
4:INTERVAL DAY TO SECOND 数据类型:示例

3:使用以下函数: – EXTRACT – TZ_OFFSET – FROM_TZ – TO_TIMESTAMP – TO_YMINTERVAL – TO_DSINTERVAL
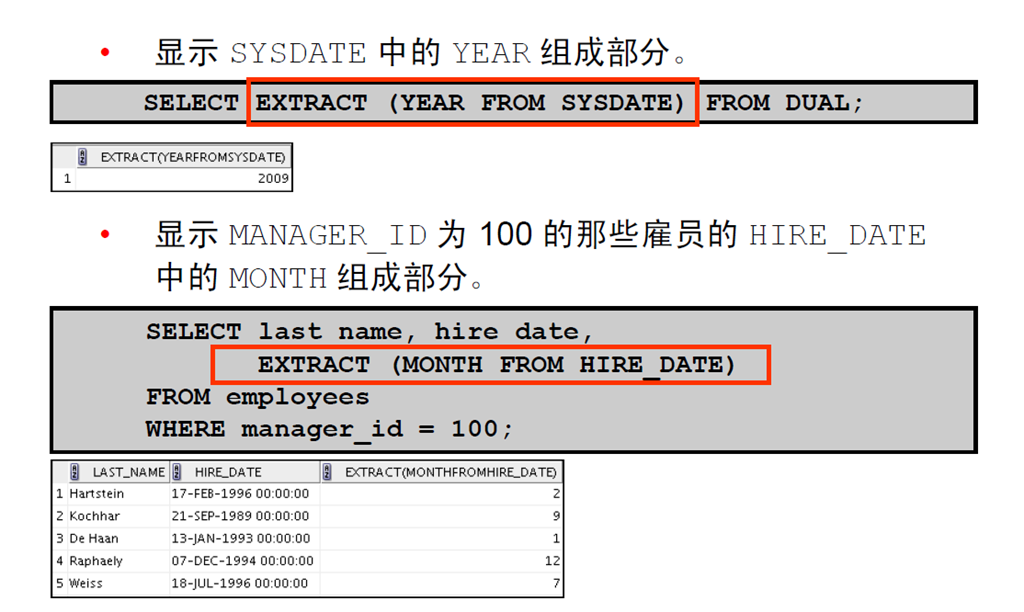
1:EXTRACT
2:TZ_OFFSET
3:FROM_TZ
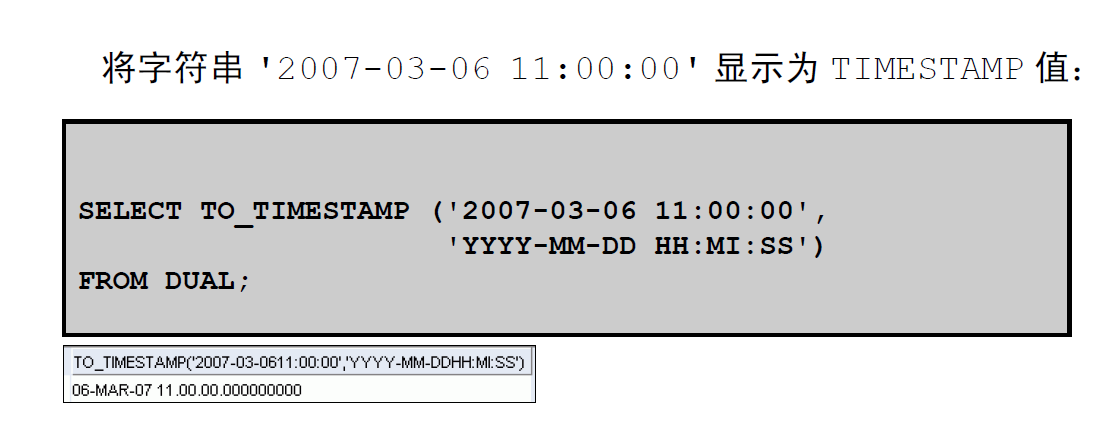
4:TO_TIMESTAMP
5:TO_YMINTERVAL
6:TO_DSINTERVAL
7:夏令时



第十七章:使用子查询检索数据
1:编写多列子查询
1:多列子查询
2:列比较
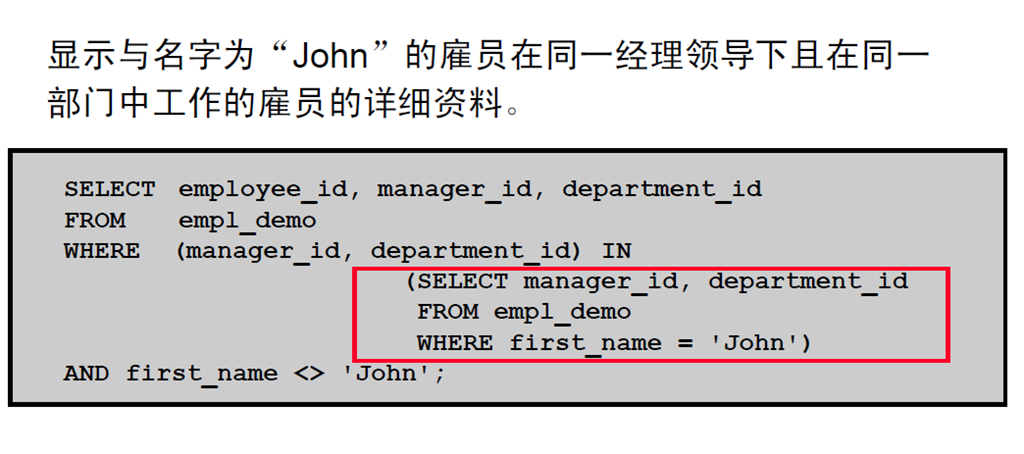
3:成对比较子查询
4:不成对比较子查询



2:在SQL 中使用标量子查询
1:标量子查询表达式
2:标量子查询:示例


3:使用相关子查询解决问题
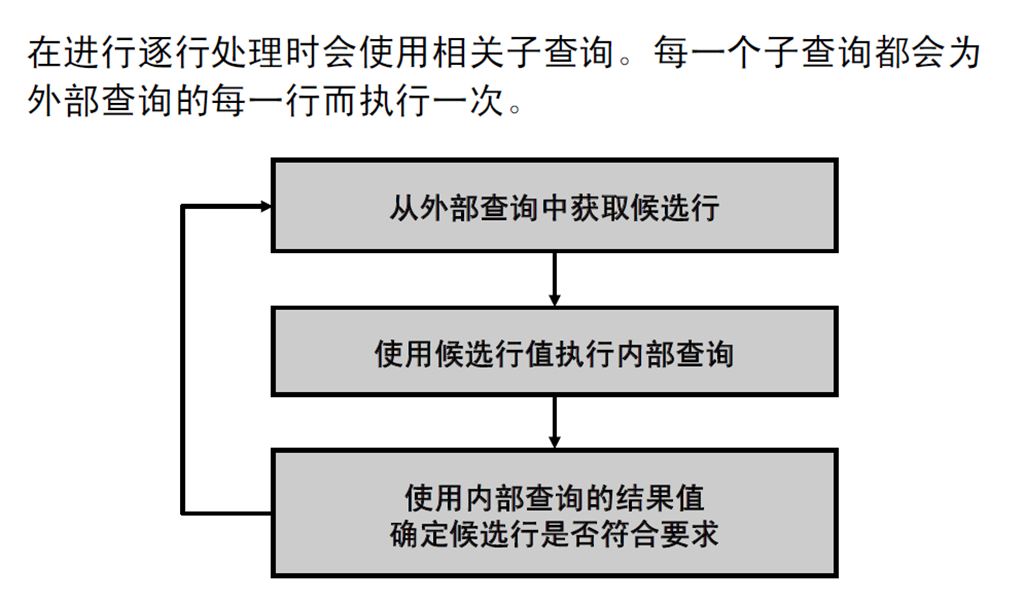
1:相关子查询
2:使用相关子查询
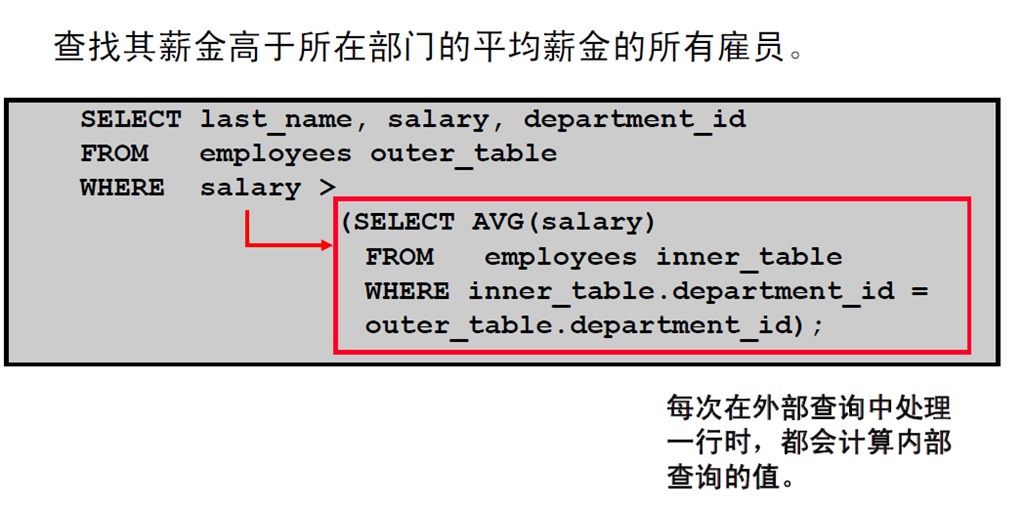
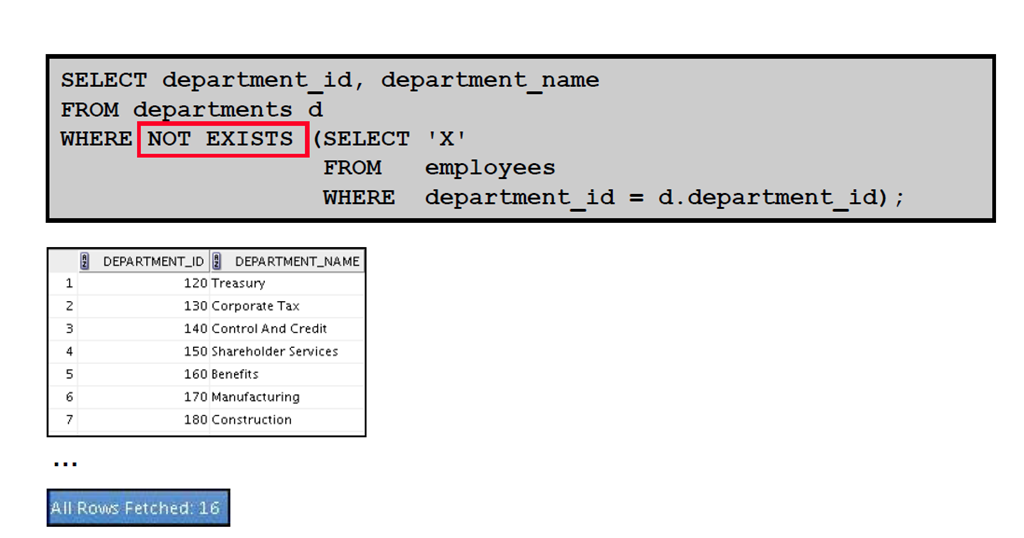
4:使用EXISTS 和NOT EXISTS 运算符
1:使用EXISTS 运算符
2:查找没有任何雇员的所有部门
3:相关UPDATE
4:使用相关UPDATE
5:相关DELETE
6:使用相关DELETE





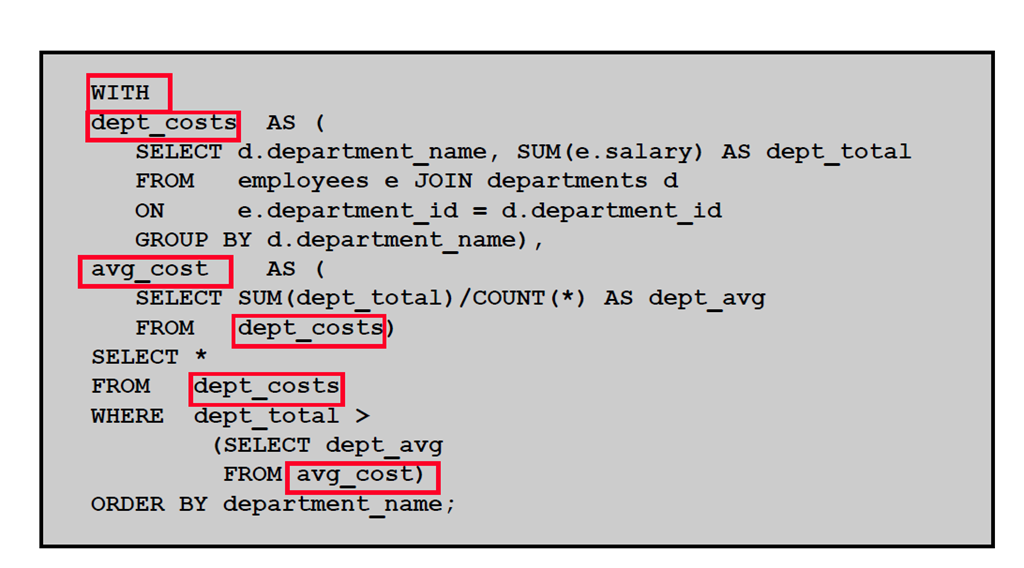
4:使用WITH 子句
1:WITH 子句
2:WITH 子句:示例
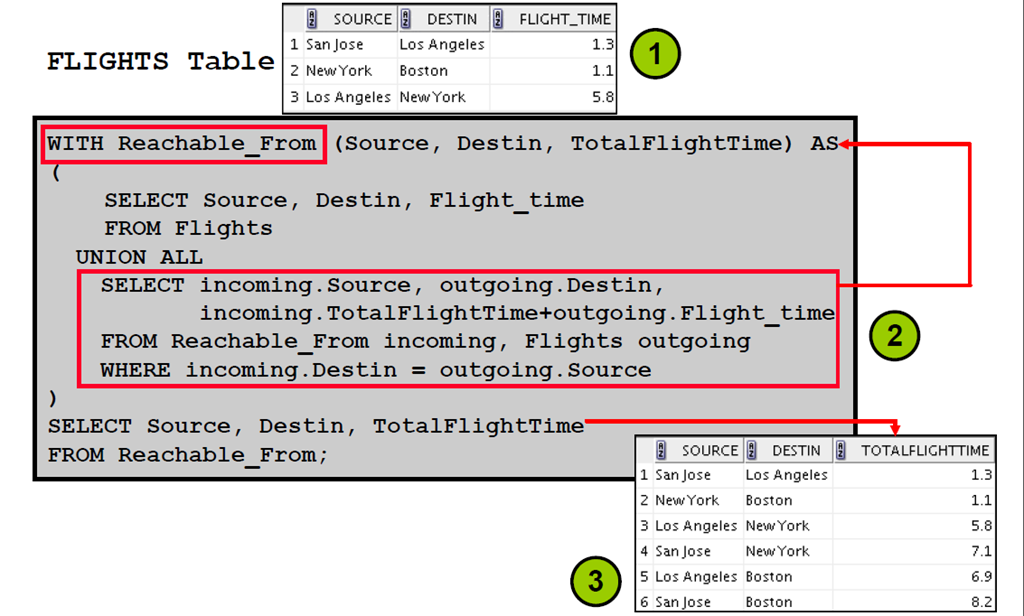
3:递归WITH 子句
4:递归WITH 子句:示例



第十八章 :正则表达式支持功能
1:正则表达式简介
1:正则表达式是什么
ORACLE 正则表达式
一、正则表达式简介
正则表达式,就是以某种模式来匹配一类字符串。例如,判断匹配性,进行字符串的重新组合等。正则表达式提供了字符串处理的快捷方式。Oracle 10g及以后的版本中也支持正则表达式。
二、正则表达式相对通配符的优势
1、正则表达式中不仅存在着代表模糊字符的特殊字符,而且存在着量词等修饰字符,使得模式的控制更加灵活和强大。
2、通配符的使用一般是在特定的环境下,不同的环境下,通配符有可能不同。而正则表达式,不但广泛应用于各种编程语言,而且在各种编程语言中,保持了语法的高度一致性。
三、元字符
元字符是指在正则表达式中表示特殊含义的字符。
四、量词
量词用来指定量词的前一个字符出现的次数。量词的形式主要有“?”、“*”、“+”、“{}”。
五、字符转义:
元字符在正则表达式中有特殊含义。如果需要使用其原义,则需要用到字符转义。字符转义使用字符“\”来实现。其语法模式为:“\”+元字符。例如,“\.”表示普通字符“.”; “\.doc”匹配字符串“.doc”;而普通字符“\”需要使用“\\”来表示。
六、字符组.
字符组是指将模式中的某些部分作为一个整体。这样,量词可以来修饰字符组,从而提高正则表达式的灵活性。字符组通过()来实现。
许多编程语言中,可以利用“$1”、“$2”等来获取第一个、第二个字符组,即所谓的后向引用。在Oracle中,引用格式为“\1”、“\2”。
七、正则表达式分支
可以利用“|”来创建多个正则表达式分支。例如,“\d{4}|\w{4}”可以看做两个正则表达式“\d{4}”和“\w{4}”,匹配其中任何一个正则表达式的字符串都被认为匹配整个正则表达式。如果该字符串两个正则表达式分支都匹配,那么将被处理为匹配第一个正则表达式分支。
八、字符类.
在Oracle中,正则表达式的用法与标准用法略有不同。这种不同主要体现在对于字符类的定义上。Orale中不使用字符“\”与普通字符组合的形式来实现字符类,而是具有其特殊语法.
九、ORACLE中的四个正则表达式相关函数。
1、regexp_like(expression, regexp)
返回值为一个布尔值。如果第一个参数匹配第二个参数所代表的正则表达式,那么将返回真,否则将返回假。
举例: select * from people where regexp_like(name, '^J.*$');
2、regexp_instr(expression, regexp, startindex, times)
返回找到的匹配字符串的位置。参数startindex表示开始进行匹配比较的位置;参数times表示第几次匹配作为最终匹配结果。
举例: select regexp_instr('12.158', '\.') position from dual;
regexp_instr('12.158', '\.')用于获取第一个小数点的位置。
3、regexp_substr(expression, regexp)
返回第一个字符串参数中,与第二个正则表达式参数相匹配的子字符串。
举例: create table html(id integer, html varchar2(2000));
insert into html values (1, '<a href="http://mail.google.com/2009/1009.html">mail link</a>');
表html中存储了HTML标签及内容。现欲从标签<a>中获得链接的url,那么可以利用regexp_substr()函数。
select id, regexp_substr(html, 'http[a-zA-Z0-9\.:/]*') url from html;
4、regexp_replace(expression, regexp, replacement)
将expression中的按regexp匹配到的部分用replacement代替。在参数replacement中,可以含有后向引用,以便将正则表达式中的字符组重新捕获。
例如,某些国家和地区的日期格式可能为“MM/DD/YYYY”,那么可以利用regexp_replace()函数来转换日期格式。
select regexp_replace('09/29/2008', '^([0-9]{2})/([0-9]{2})/([0-9]{4})$', '\3-\1-\2') replace from dual;
十、正则表达式练习
第一:REGEXP_LIKE函数用法 EMP表结构及数据如下:
SQL> desc emp;
SQL> select empno,ename,sal,hiredate from emp;
1、查找员工编号为4位数字的员工信息
SQL> select empno,ename from emp where regexp_like(empno,'^[[:digit:]]{4}$');
2、查找员工姓名为全英文的员工信息
SQL> select empno,ename from emp where regexp_like(ename,'^[[:alpha:]]+$');
或者:
SQL> select empno,ename from emp where regexp_like(ename,'^[a-zA-Z]+$');
3、查找员工姓名以“a”字母开头,不区分大小写
SQL> select empno,ename from emp where regexp_like(ename,'^a','i');
4、查找员工姓名为全英文,且以“N”结尾的员工信息
SQL> select empno,ename from emp where regexp_like(ename,'^[[:alpha:]]+N$');
5、查找员工编号以非数字的员工信息
SQL> select empno,ename from emp where regexp_like(empno,'[^[:digit:]]');
以数字开头
select empno,ename from emp where regexp_like(empno,'^[[:digit:]]');
数字
select empno,ename from emp where regexp_like(empno,'[[:digit:]]');
非数字开头
select empno,ename from emp where regexp_like(empno,'^[^[:digit:]]');
第二:REGEXP_INSTR函数用法
1、查找员工编号中第一个非数字字符的位置
SQL> select regexp_instr(empno,'[^[:digit:]]') position from emp;
2、从第三个字符开始,查找员工编号中第二个非数字字符的位置
SQL> select regexp_instr(empno,'[^[:digit:]]',3,2) position from emp;
第三:REGEXP_SUBSTR函数用法
1、返回从ename的第二个位置开始查找,并且是以“L”开头到结尾的字串
SQL> select regexp_substr(ename,'L.*','2') substr from emp;
第四:REGEXP_REPLACE函数用法
1、把ename中所有非字母字符替换为“A”
SQL>update emp set ename=regexp_replace(ename, '[^[:alpha:]]','A') where regexp_like(ename, '[^[:alpha:]]');2:使用正则表达式的好处
3:在SQL 和PL/SQL 中使用 正则表达式函数和条件


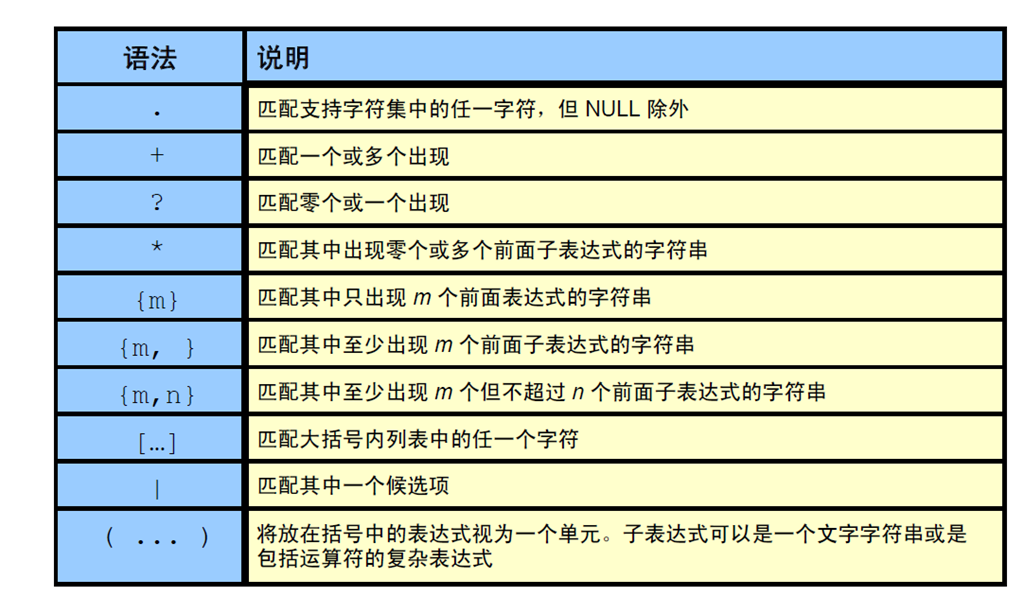
2:在正则表达式中使用元字符
1:元字符是什么
2:在正则表达式中使用元字符

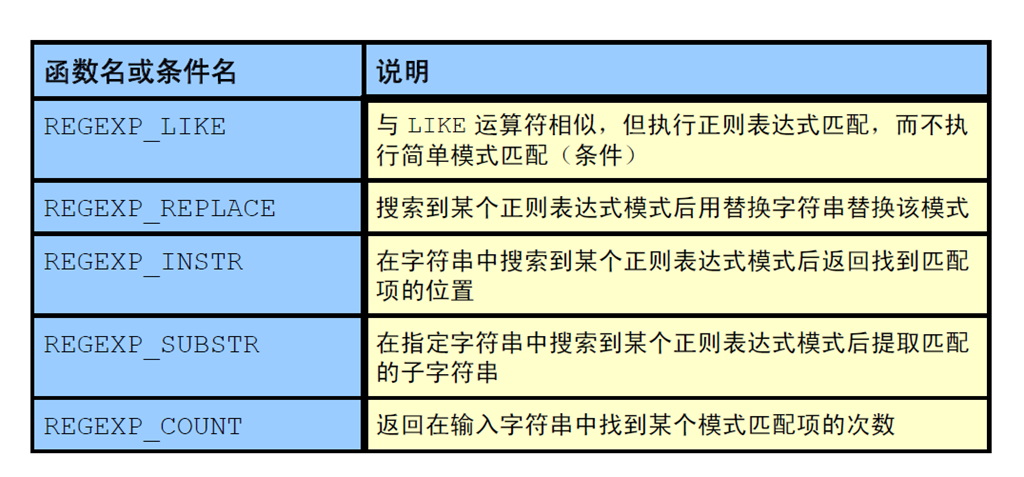
3:使用正则表达式函数: – REGEXP_LIKE – REGEXP_REPLACE – REGEXP_INSTR – REGEXP_SUBSTR
1:正则表达式函数和条件:语法
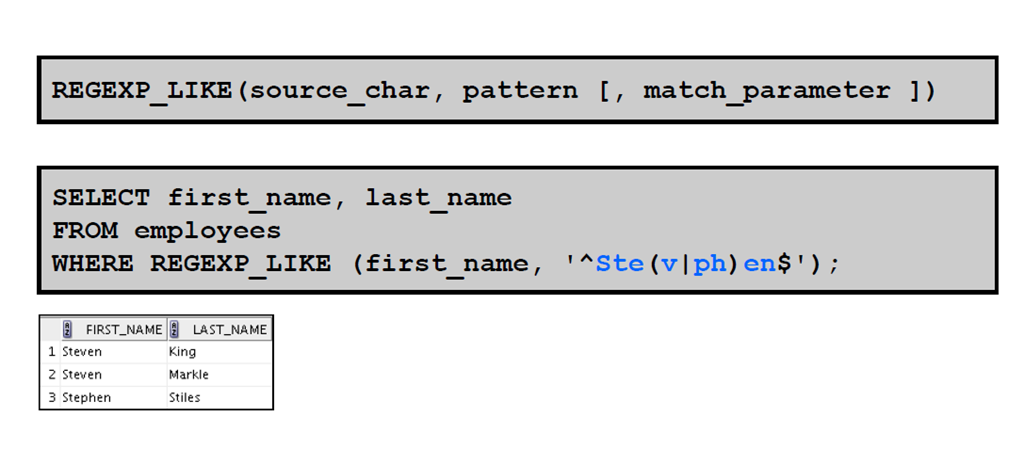
2:使用REGEXP_LIKE 条件执行基本搜索
3:使用REGEXP_REPLACE 函数替换模式
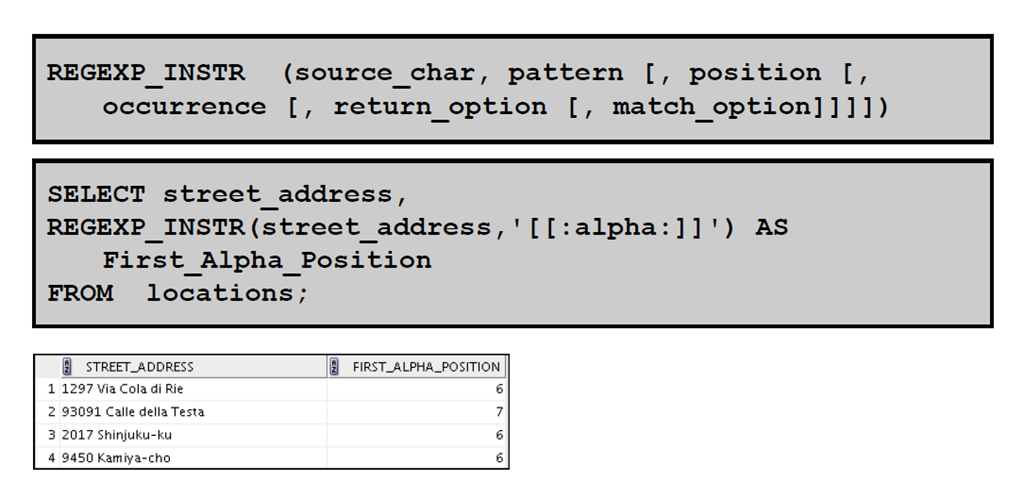
4:使用REGEXP_INSTR 函数查找模式
5:使用REGEXP_SUBSTR 函数提取子字符串


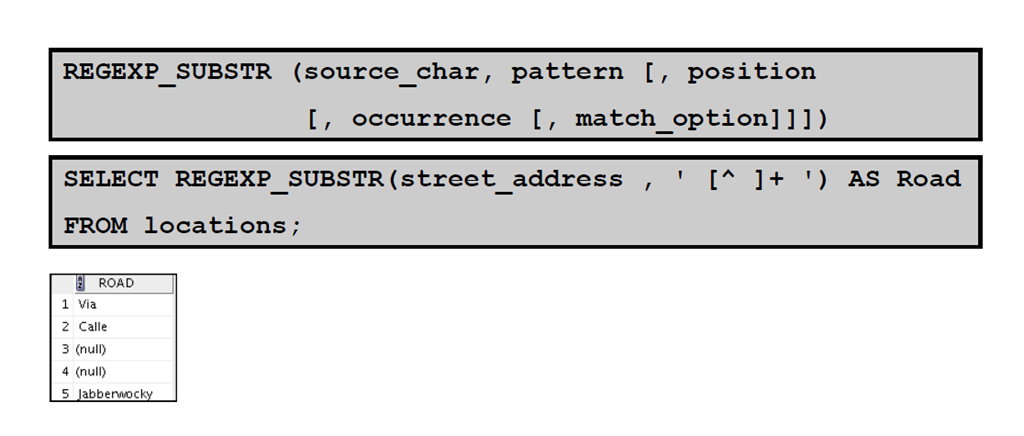
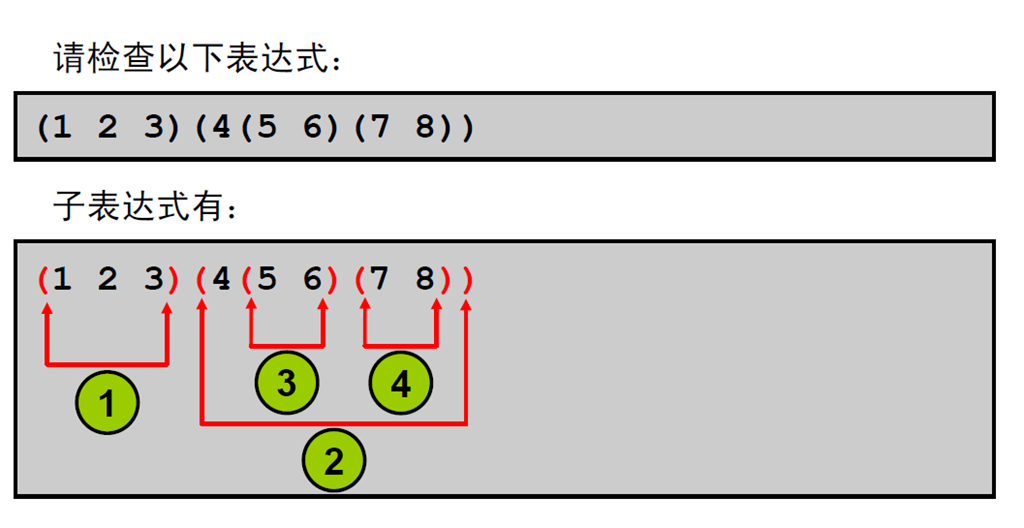
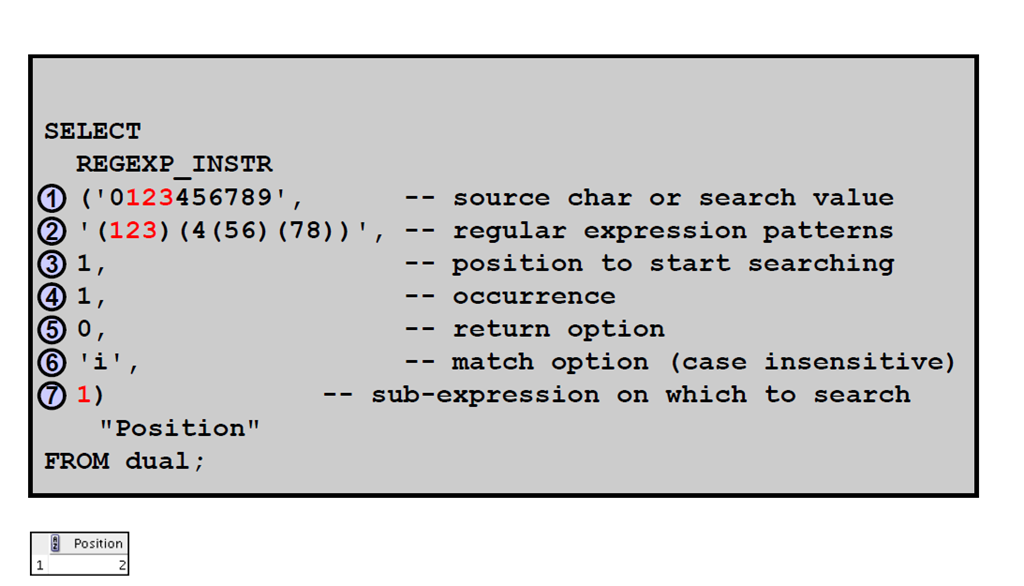
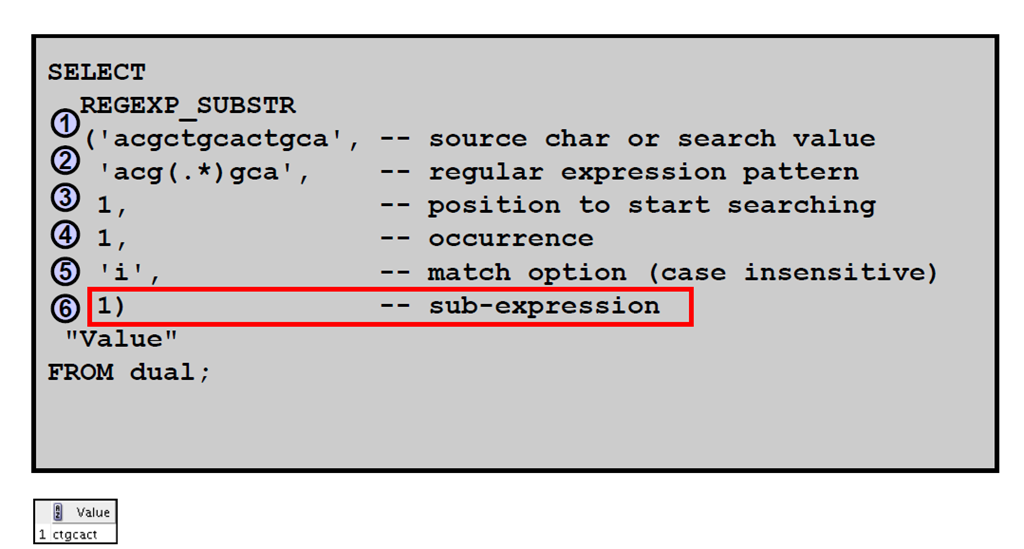
4:访问子表达式
1:子表达式
2:结合使用正则表达式支持与子表达式
3:为什么要访问第n 个子表达式
4:REGEXP_SUBSTR:示例

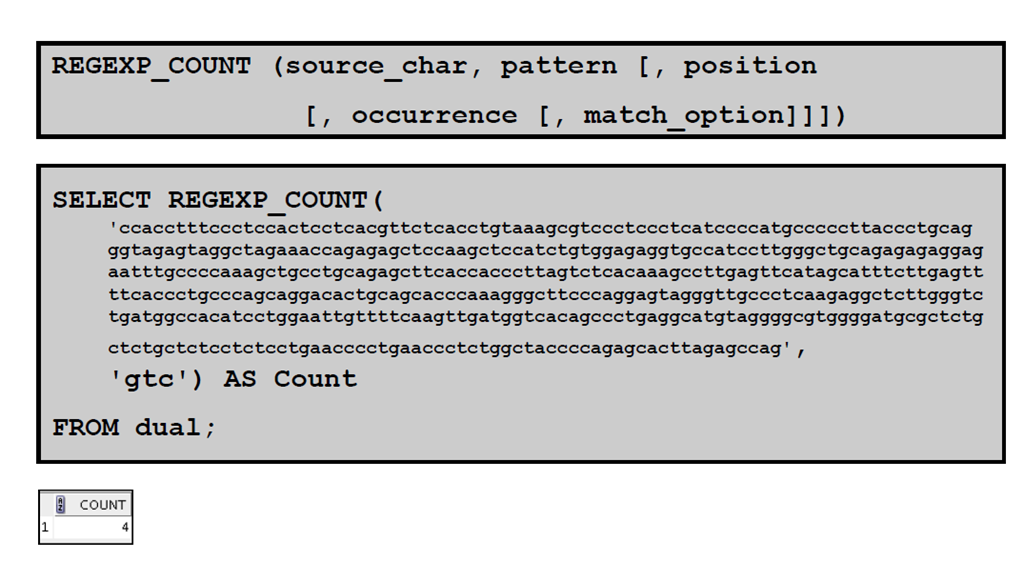
5:使用REGEXP_COUNT 函数
1:使用REGEXP_COUNT 函数
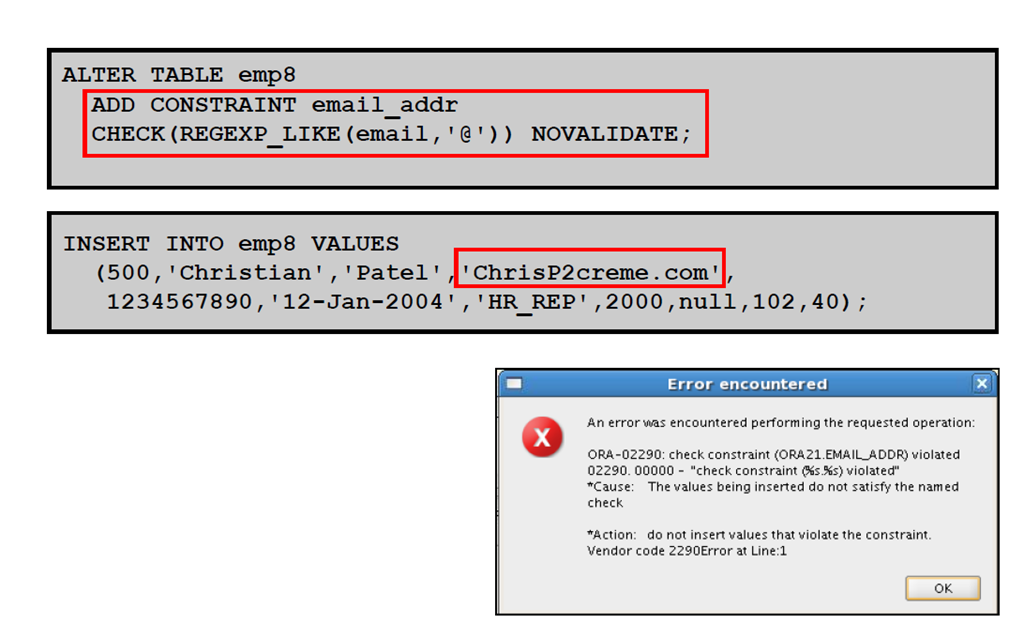
2:正则表达式和检查约束条件:示例
第十九章:通过将相关数据分组来生成报表
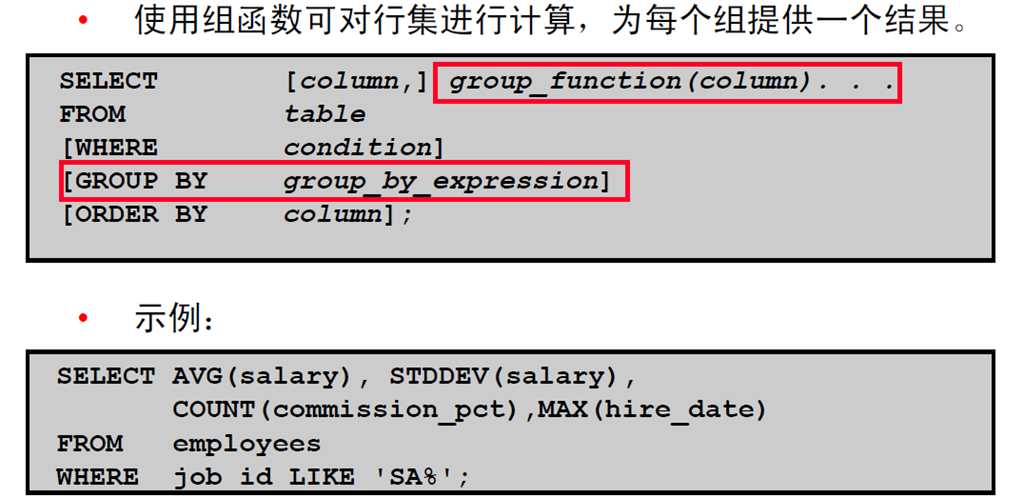
1:复习组函数
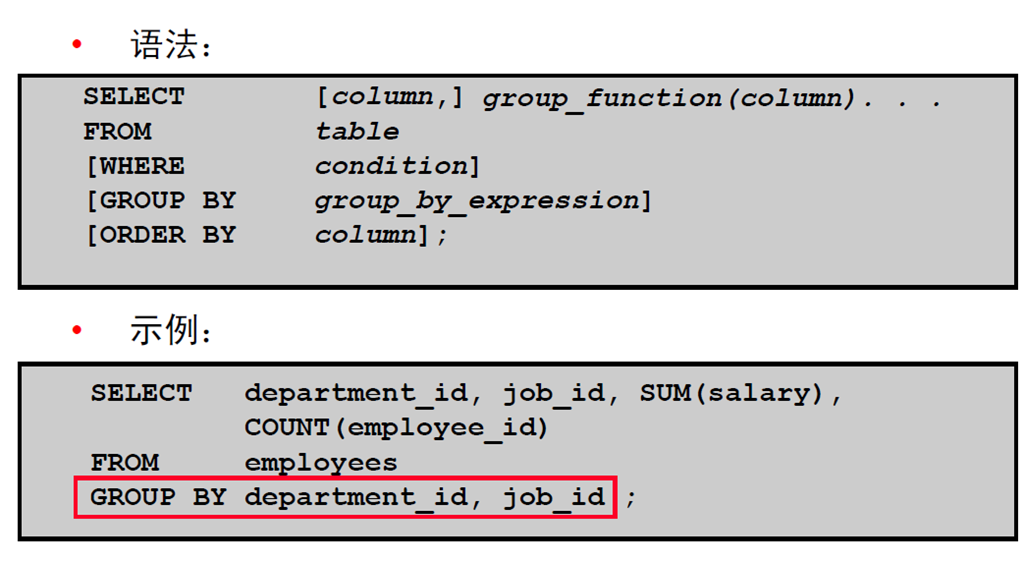
2:复习GROUP BY 子句
3:复习HAVING 子句

4:GROUP BY 与ROLLUP 和CUBE 运算符一起使用

5:ROLLUP 运算符

6:ROLLUP 运算符:示例
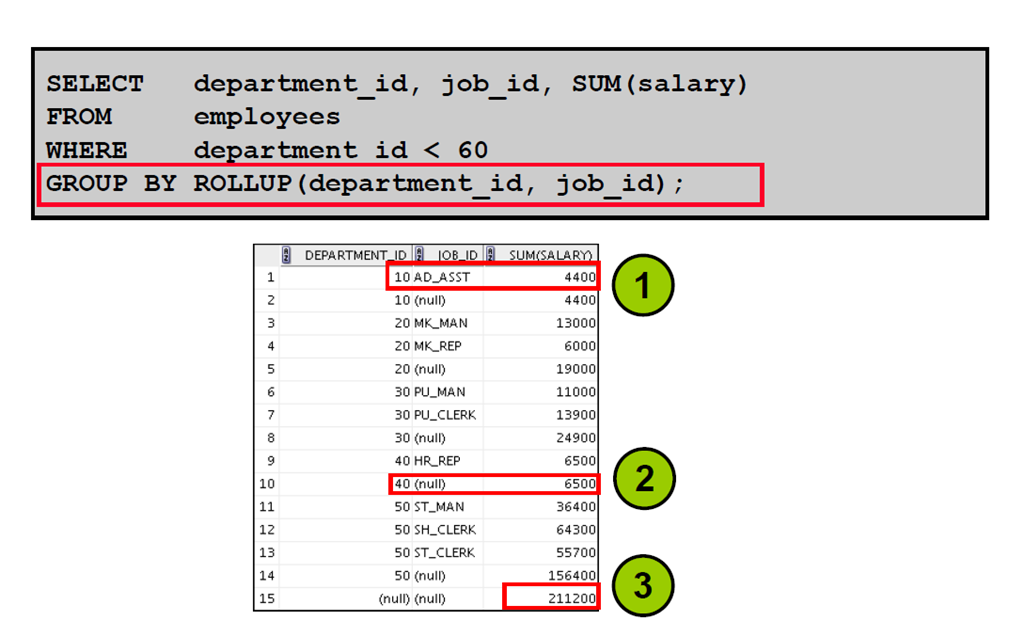
7:CUBE 运算符

8:CUBE 运算符:示例
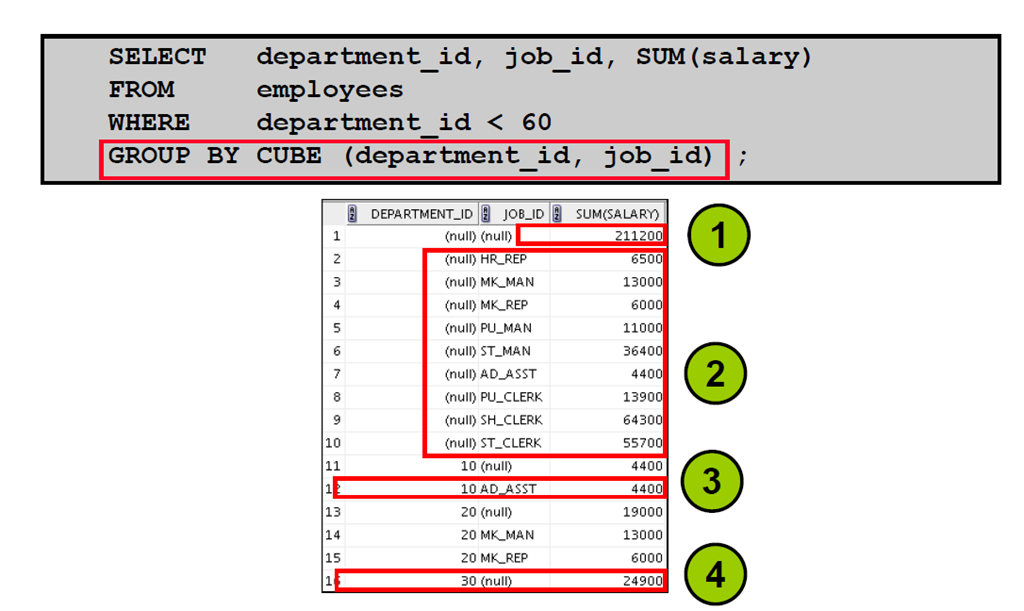
9:GROUPING 函数

10:GROUPING 函数:示例
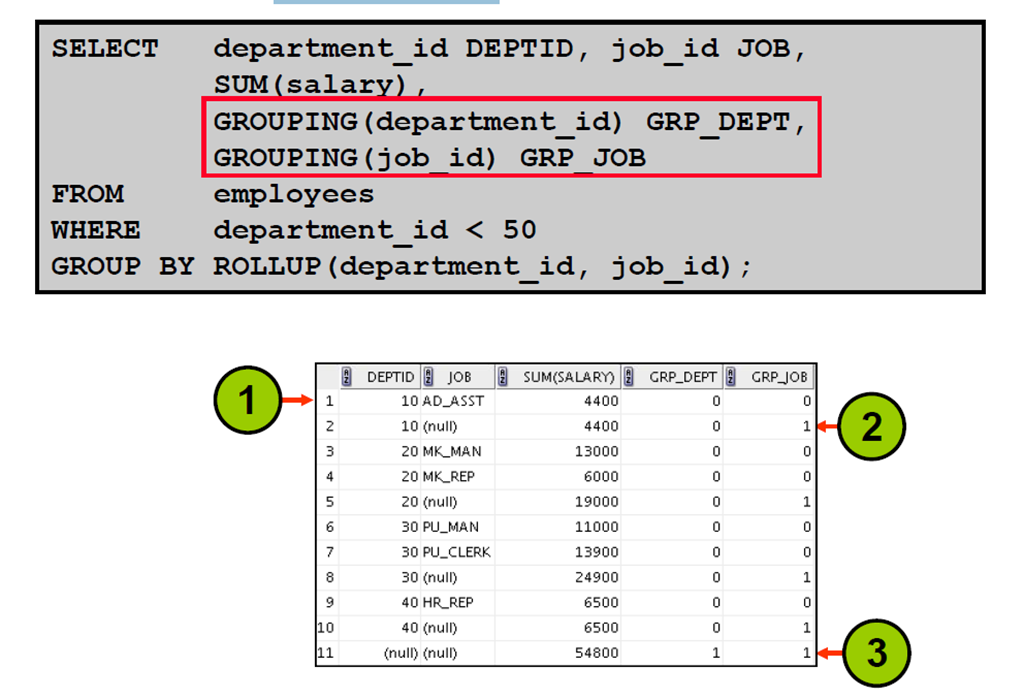
11:GROUPING SETS

12:GROUPING SETS:示例
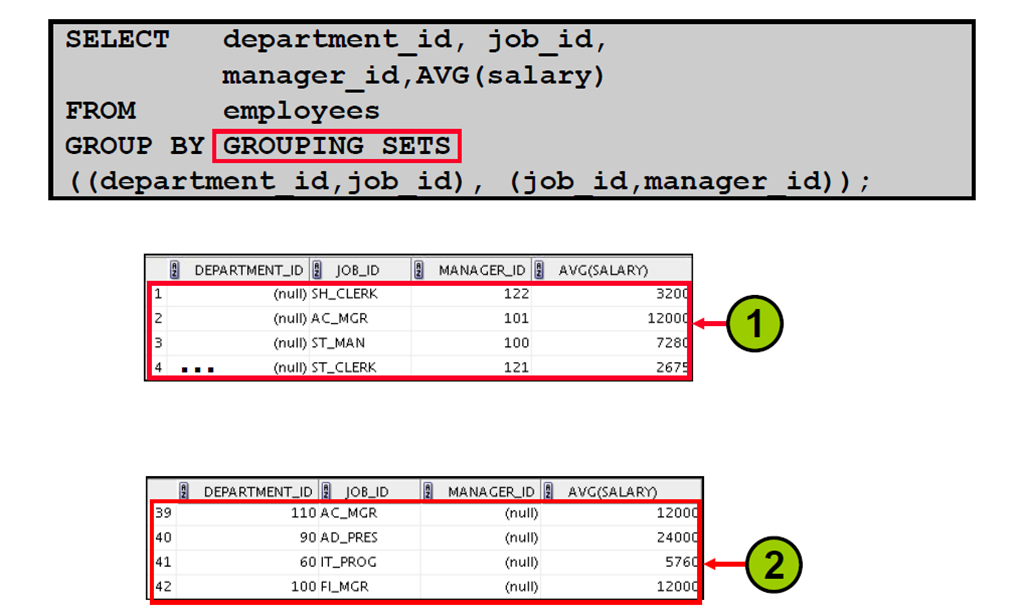
13:组合列

14:组合列:示例
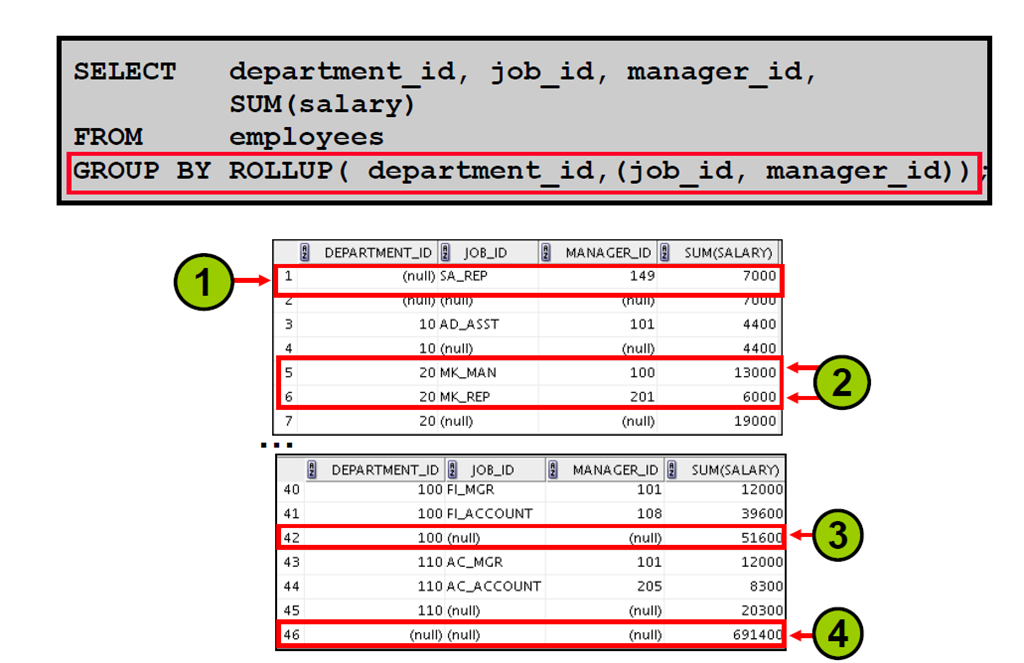
15:级联分组

16:级联分组:示例
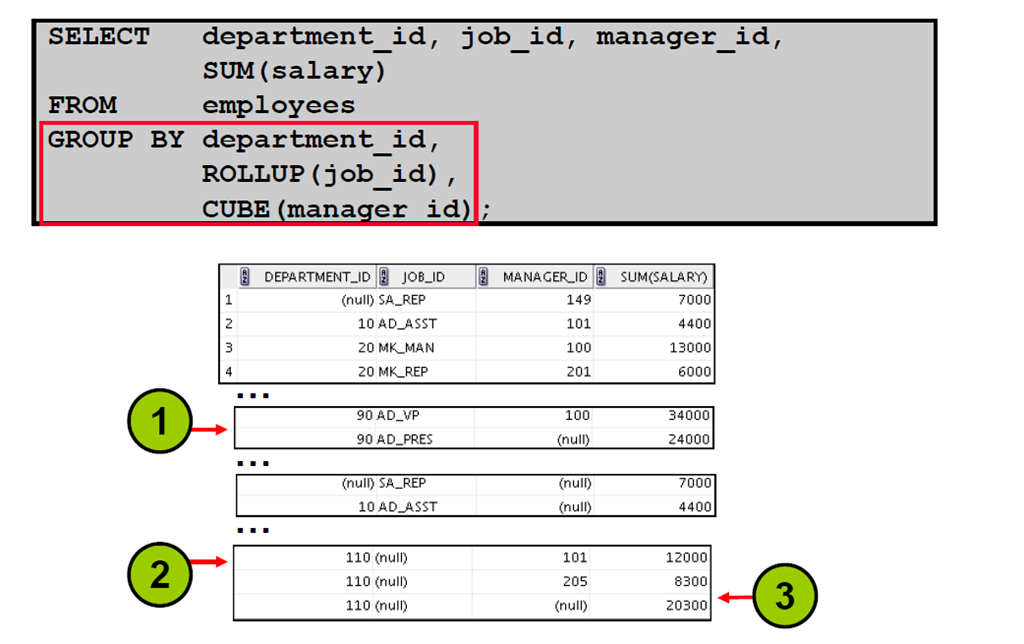
17:小结

第二十章:分层检索
1:课程目标
--1、从根节点开始遍历(start with ...connect by prior ) Conn scott/scott
SQL> select empno,mgr,ename,job from emp start with empno = 7839 connect by prior empno = mgr;
SQL> select level,empno,mgr,ename,job from emp start with ename = 'KING' connect by prior empno = mgr order by level;
-- 注:prior表示前一条记录,即下一条返回记录的mgr应当等于前一条记录的empno
-- 2、获得层次数
SQL> select count(distinct level) "Level" from emp start with ename = 'KING' connect by prior empno = mgr;
--3、格式化层次查询结果(使用左填充* level - 1个空格)
SQL> col Ename for a30
SQL> select level,lpad(' ',2 * level - 1) || ename as "Ename",job from emp start with ename = 'KING' connect by prior empno = mgr;
--4、从非根节点开始遍历(只需修改start with 中的条件即可)
SQL> select level,lpad(' ',2 * level - 1) || ename as "Ename",job from emp start with ename = 'SCOTT' connect by prior empno = mgr;
--5、从下向上遍历(交换connect by prior中的条件即可,使用mgr = empno),prior表示前一条记录,即下一条返回记录的empno应当等于前一条记录的mgr
SQL> select level,lpad(' ',2 * level - 1) || ename as "Ename",job from emp start with ename = 'SCOTT' connect by prior mgr = empno;
--从下向上遍历(也可以将prior置于等号右边,得到相同的结果)
SQL> select level,lpad(' ',2 * level - 1) || ename as "Ename",job from emp start with ename = 'SCOTT' connect by empno = prior mgr;
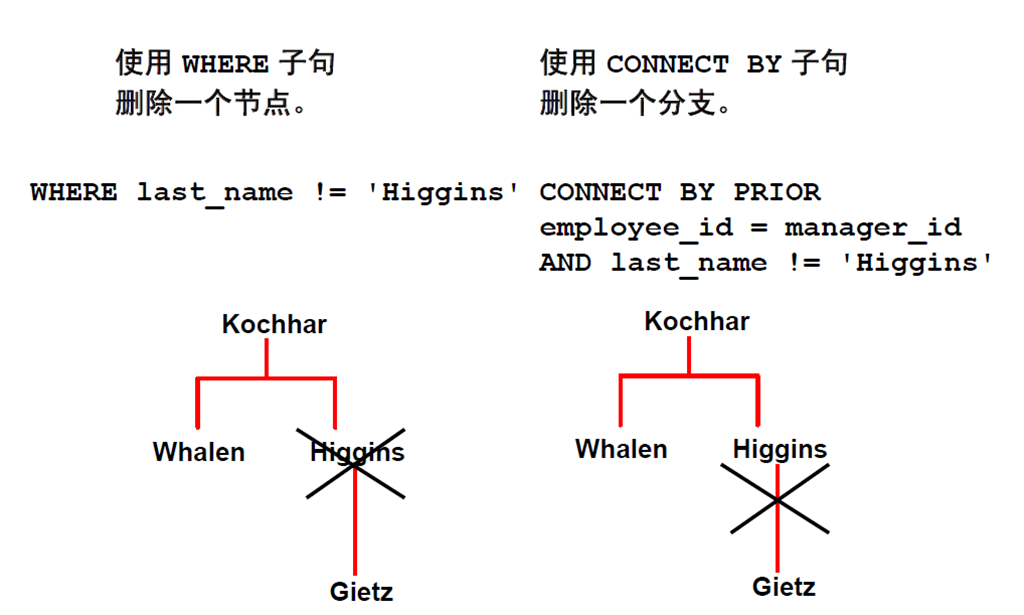
--6、从层次查询中删除节点和分支,通过where子句来过滤SCOTT用户,但SCOTT的下属ADAMS并没有过滤掉
SQL> select level,lpad(' ',2 * level - 1) || ename as "Ename",job from emp where ename != 'SCOTT' start with empno = 7839 connect by prior empno = mgr;
--7、通过将过滤条件由where 子句的内容移动到connect by prior 子句中过滤掉SCOTT及其下属
SQL> select level,lpad(' ',2 * level - 1) || ename as "Ename",job from emp start with empno = 7839 connect by prior empno = mgr and ename != 'SCOTT';
--8、在层次化查询中增加过滤条件或使用子查询
SQL> select level,lpad(' ',2 * level - 1) || ename as "Ename",job from emp where sal > 2500 start with empno = 7839 connect by prior empno = mgr;
SQL> select level,lpad(' ',2 * level - 1) || ename as "Ename",job from emp where sal > (select avg(sal) from emp) start with empno = 7839 connect by prior empno = mgr ;



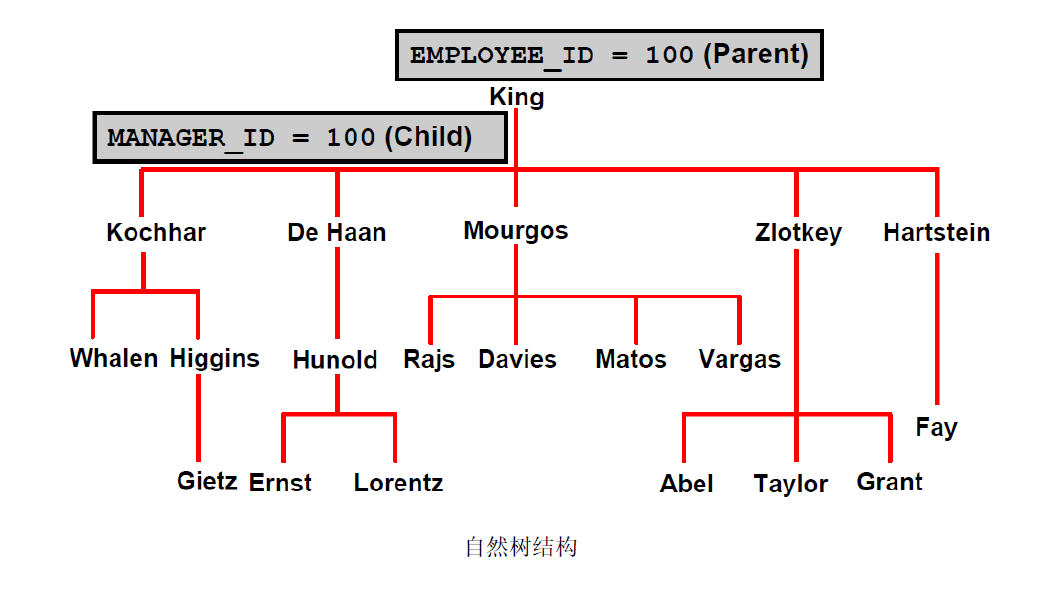
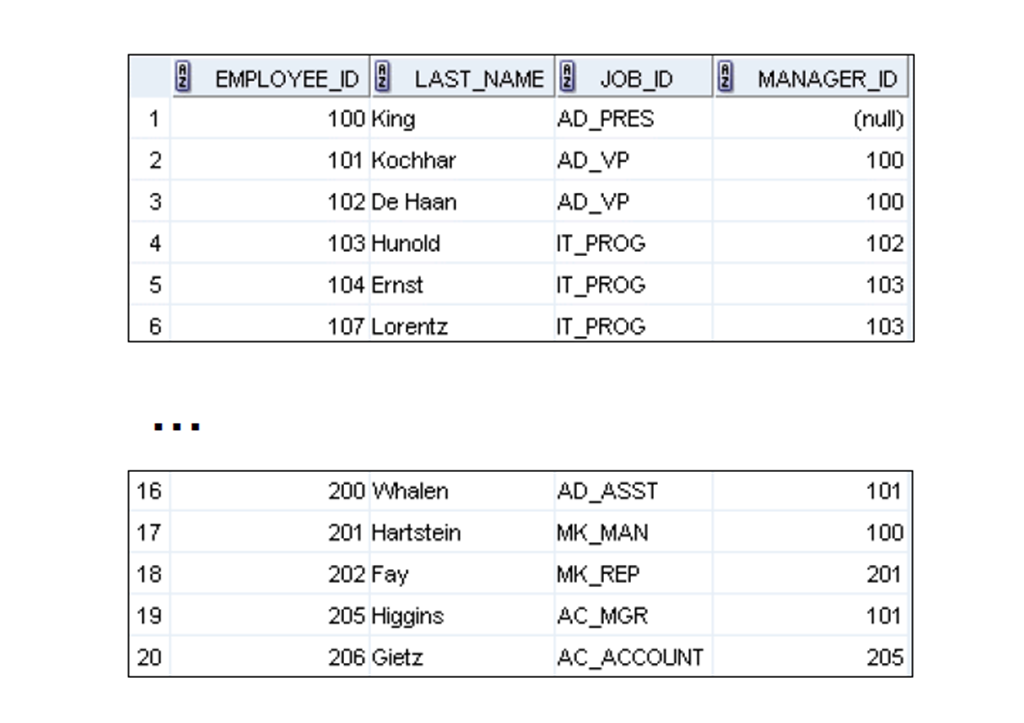
2:EMPLOYEES 表中的示例数据
3:自然树结构
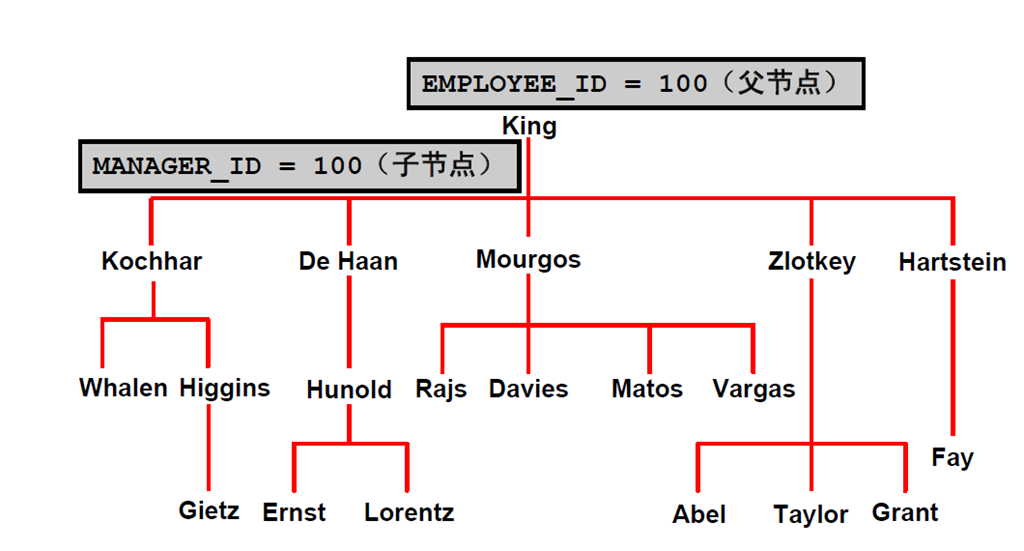
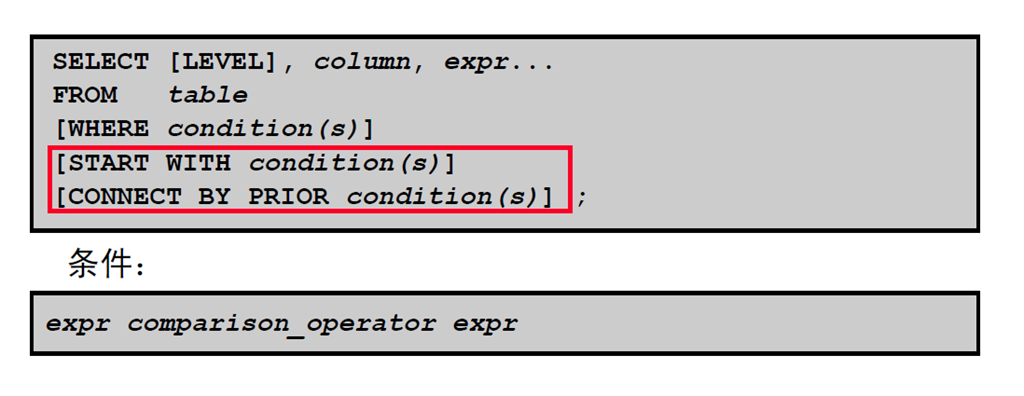
4:分层查询
5:遍历树

6:遍历树:自下而上
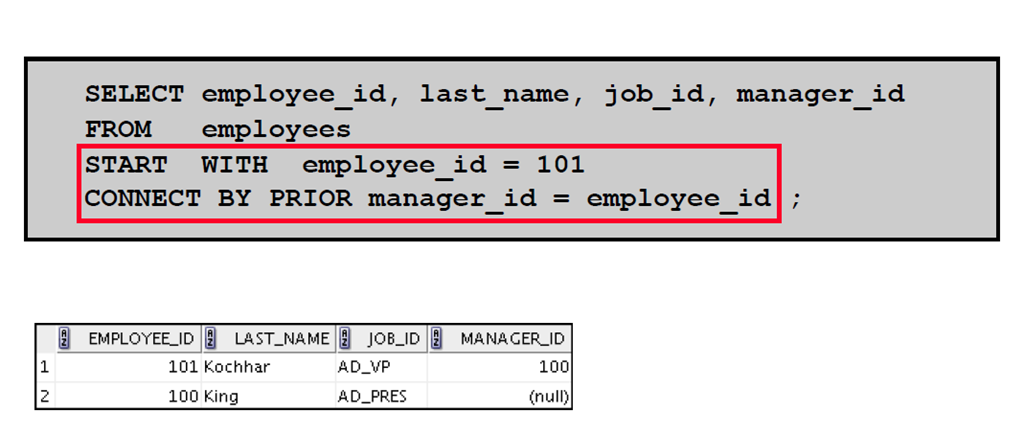
7:遍历树:自上而下
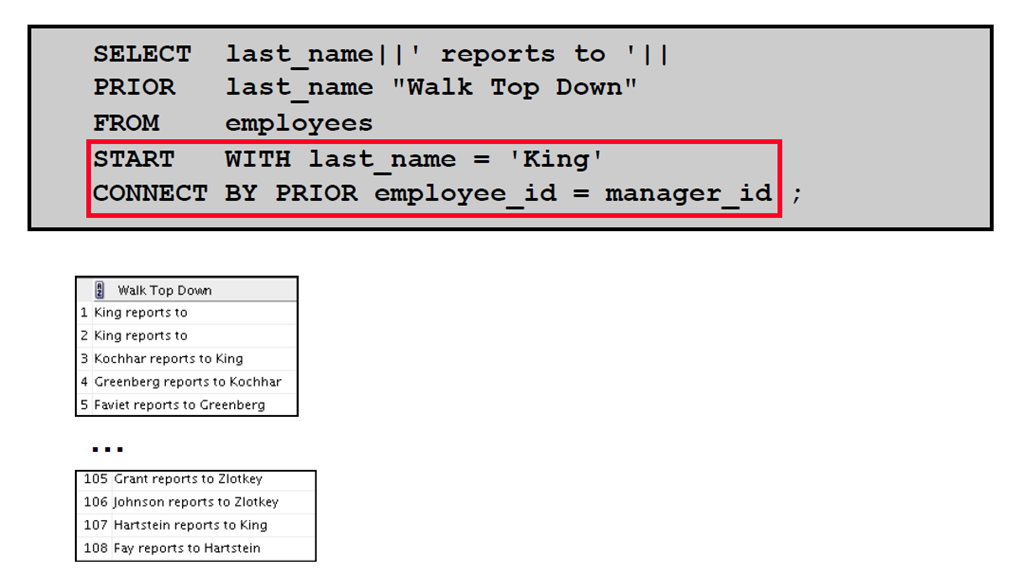
8:使用LEVEL 伪列确定行的等级
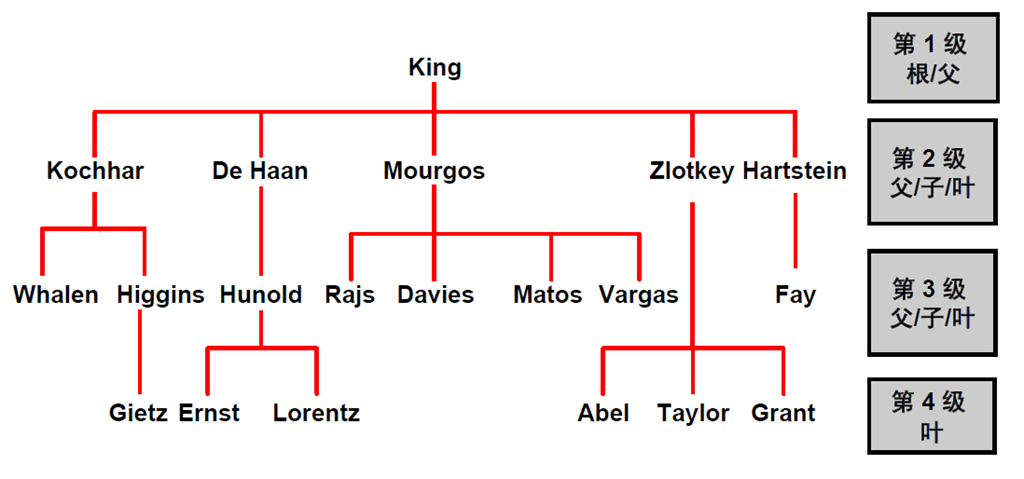
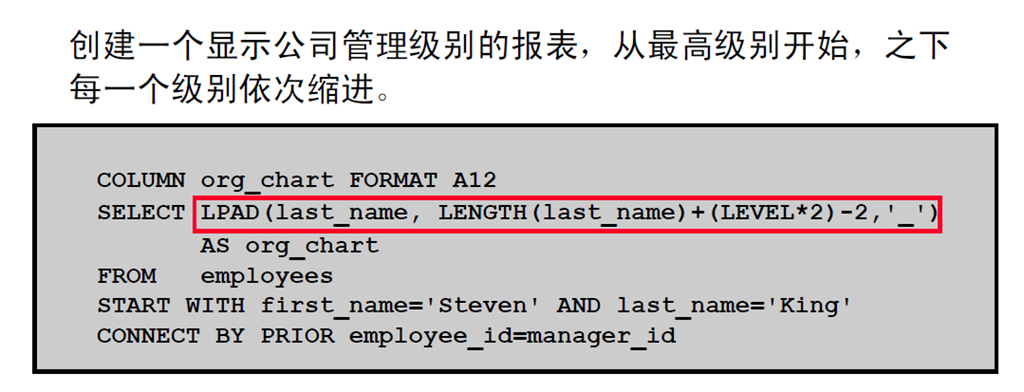
9:使用LEVEL 和LPAD 设置分层报表的格式
10:修剪分支
11:小结

第二十一章:Oracle DB 体系结构组件
1:课程目标

2:Oracle DB 体系结构:概览

3:Oracle DB Server 结构
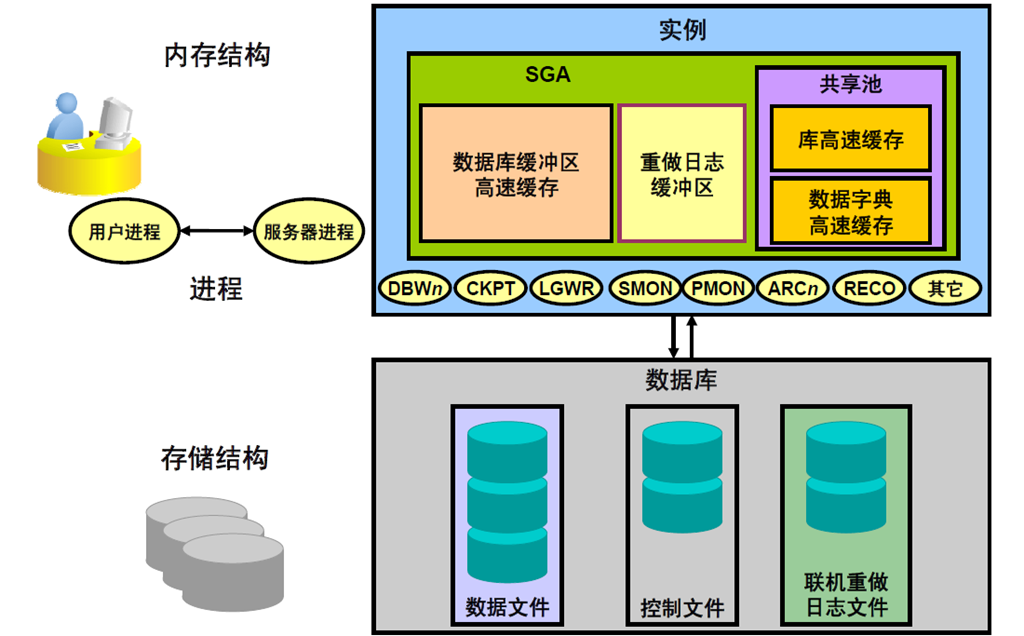
4:连接到数据库
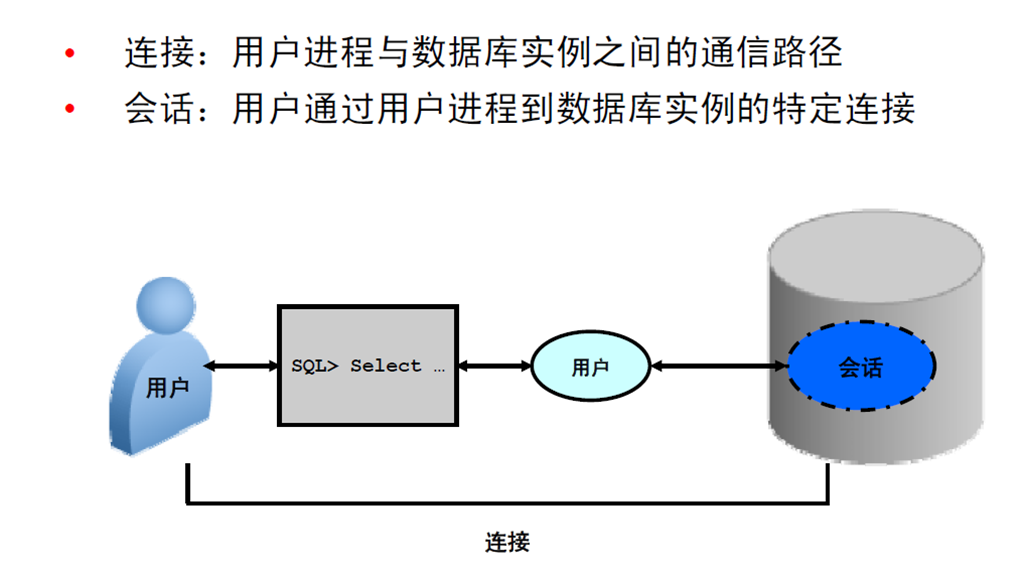
5:与Oracle DB 交互
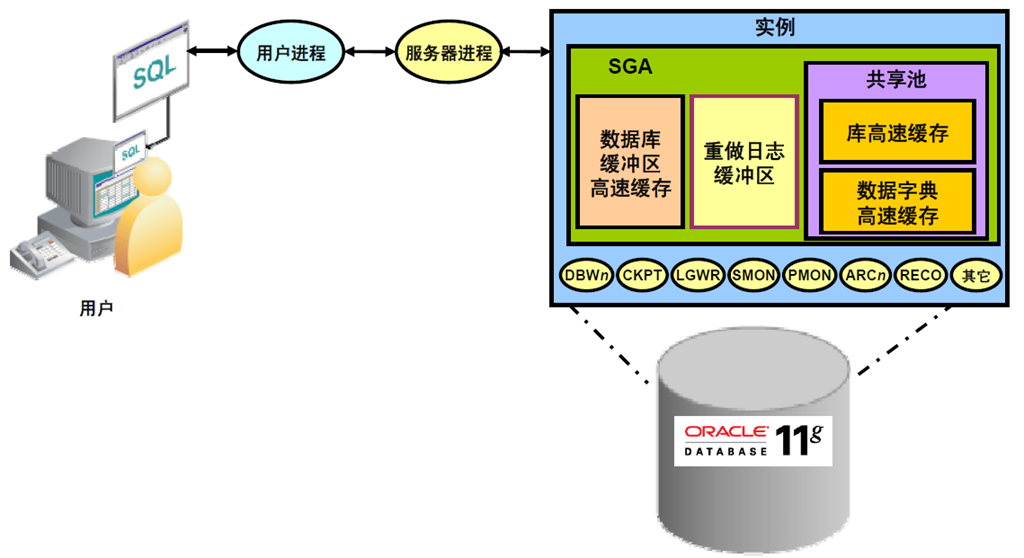
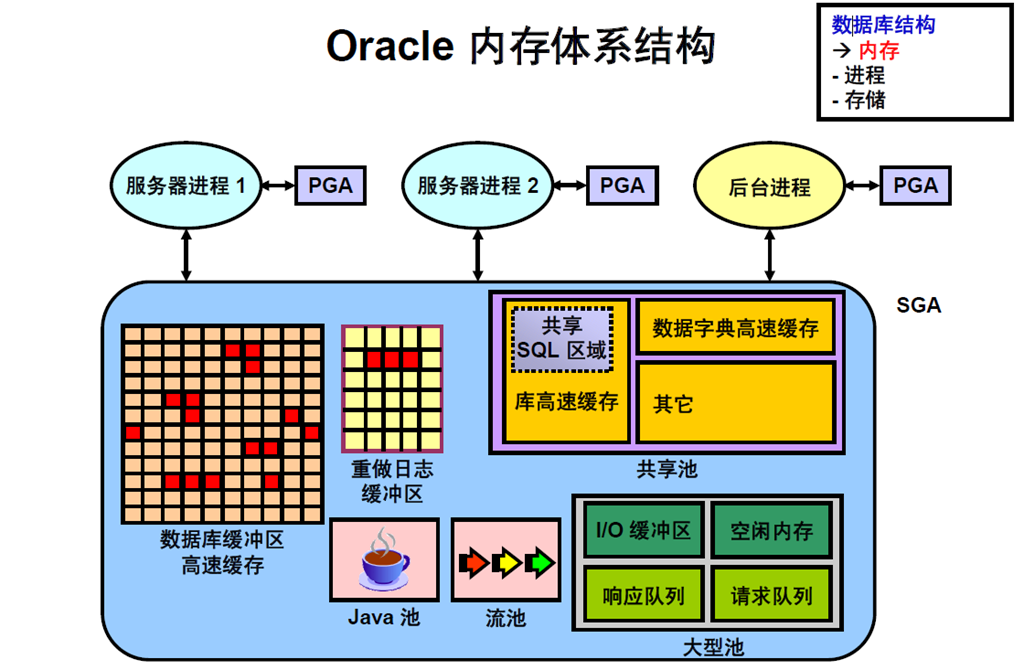
6:Oracle 内存体系结构
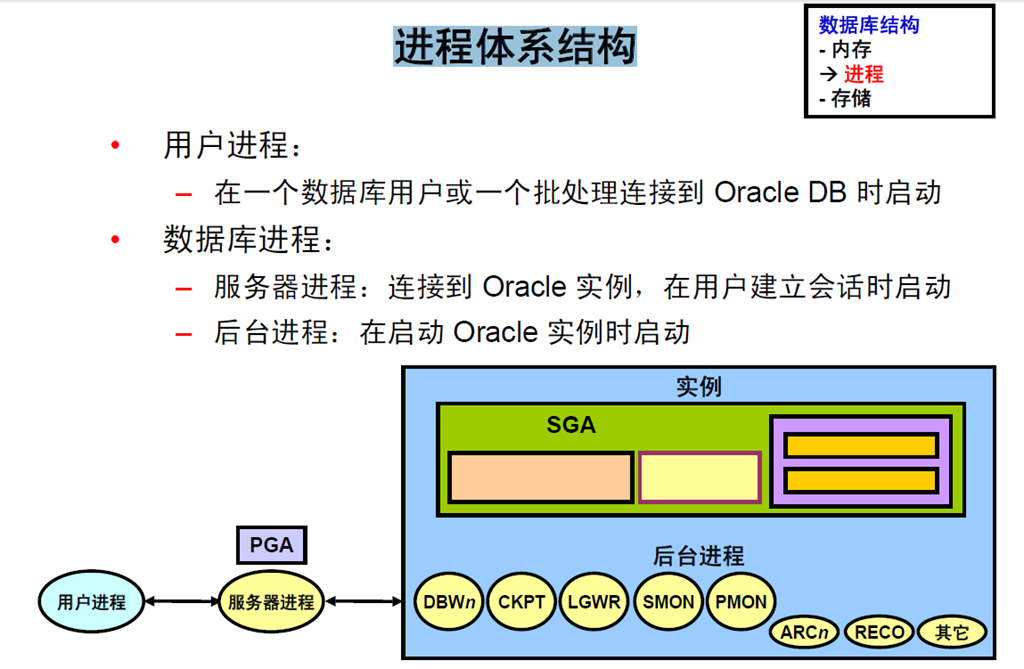
7:进程体系结构
8:数据库写进程
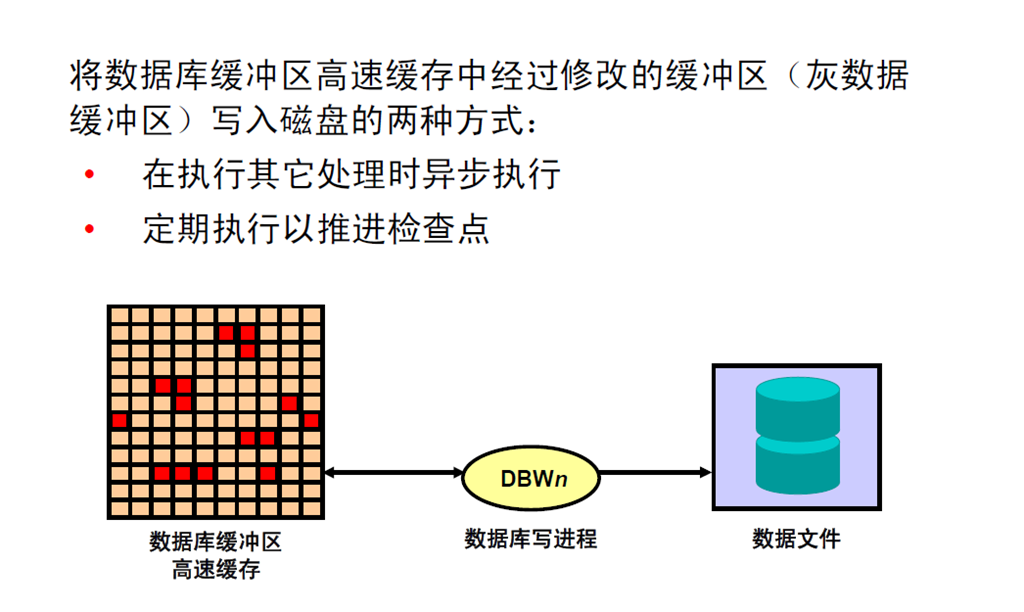
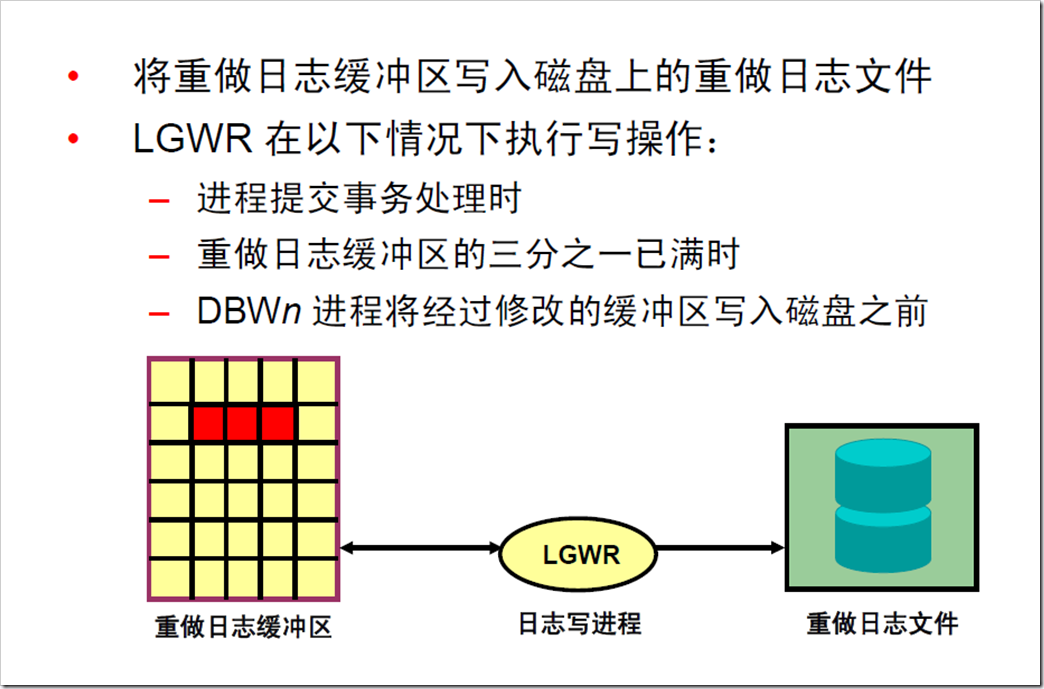
9:日志写进程
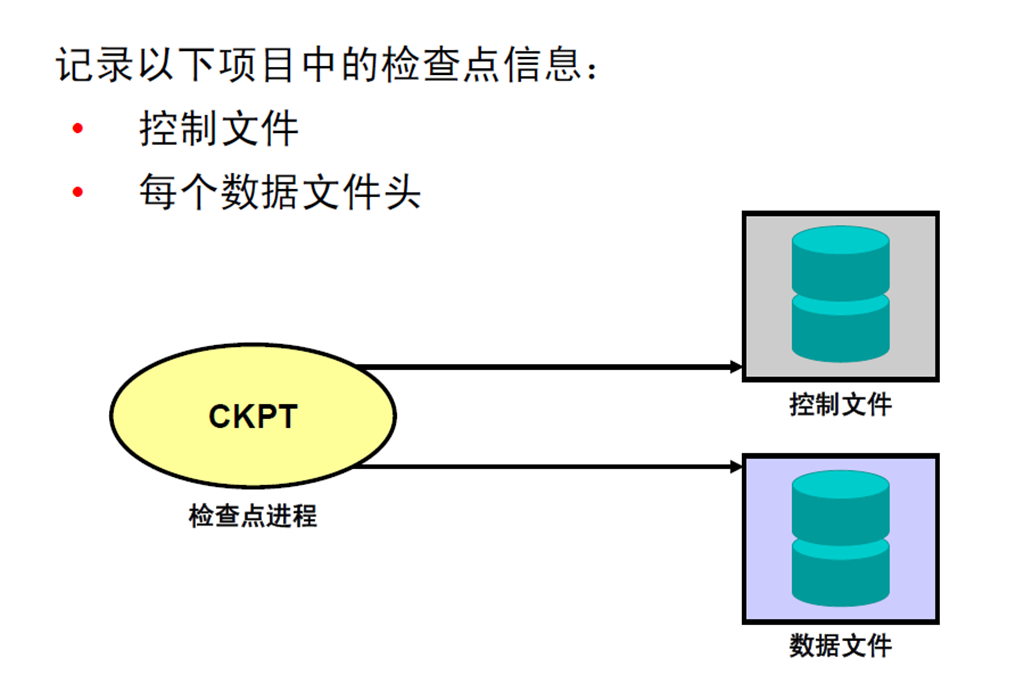
10:检查点进程
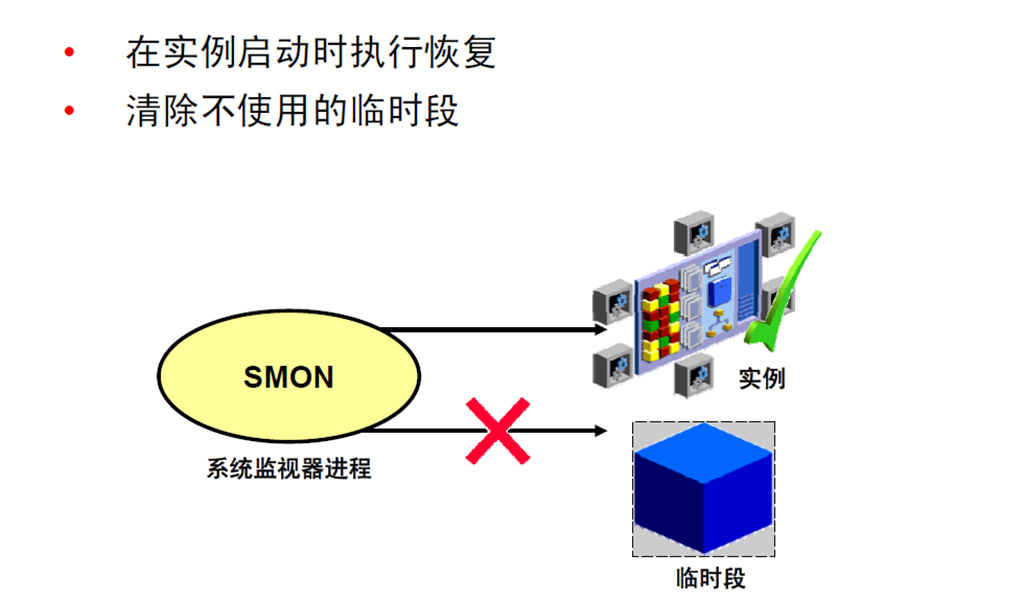
11:系统监视器进程
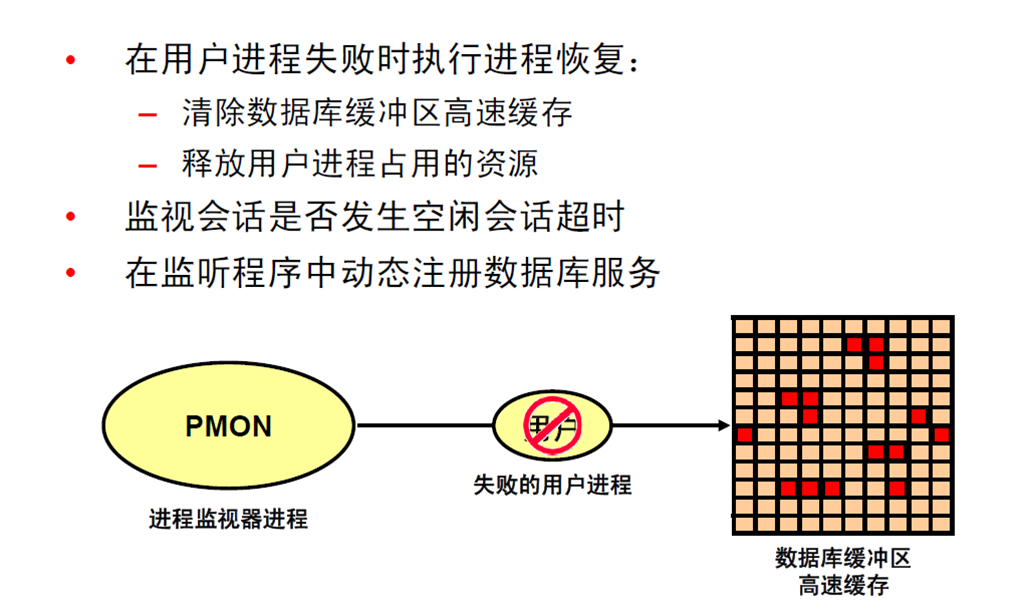
12:进程监视器进程
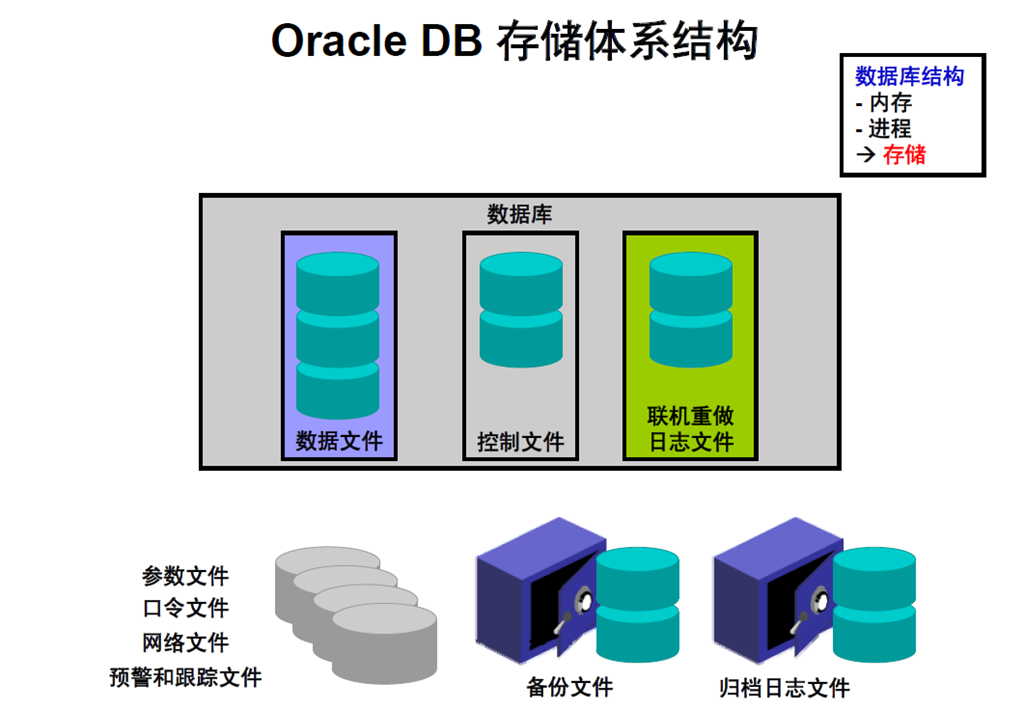
13:Oracle DB 存储体系结构
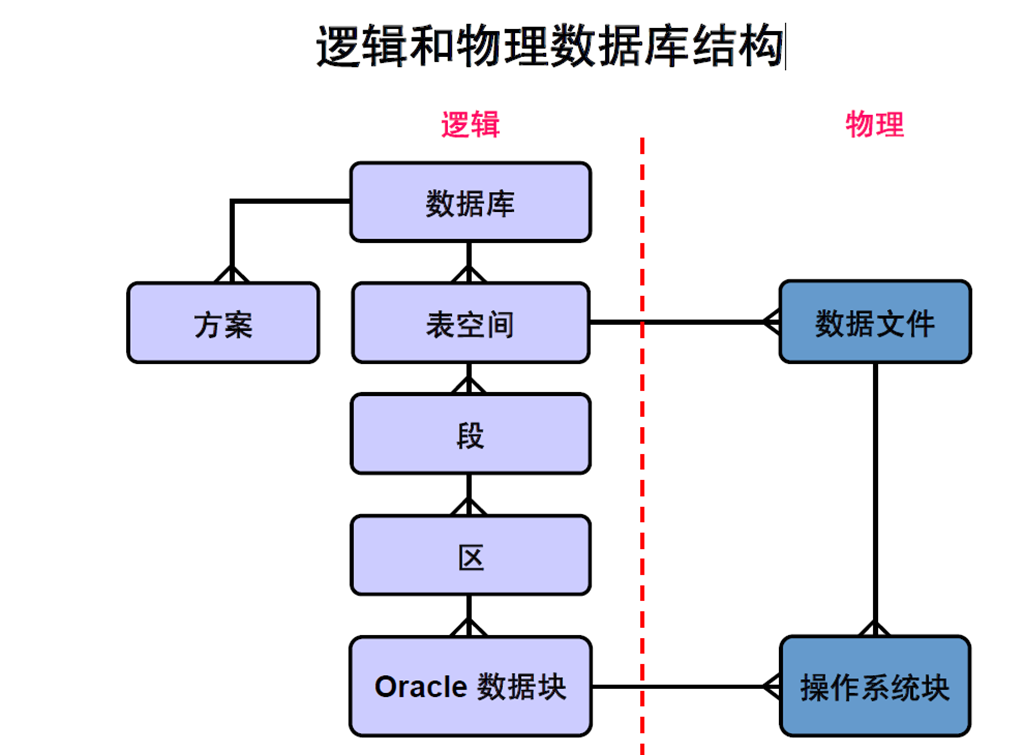
14:逻辑和物理数据库结构
15:处理SQL 语句

16:处理查询

17:共享池
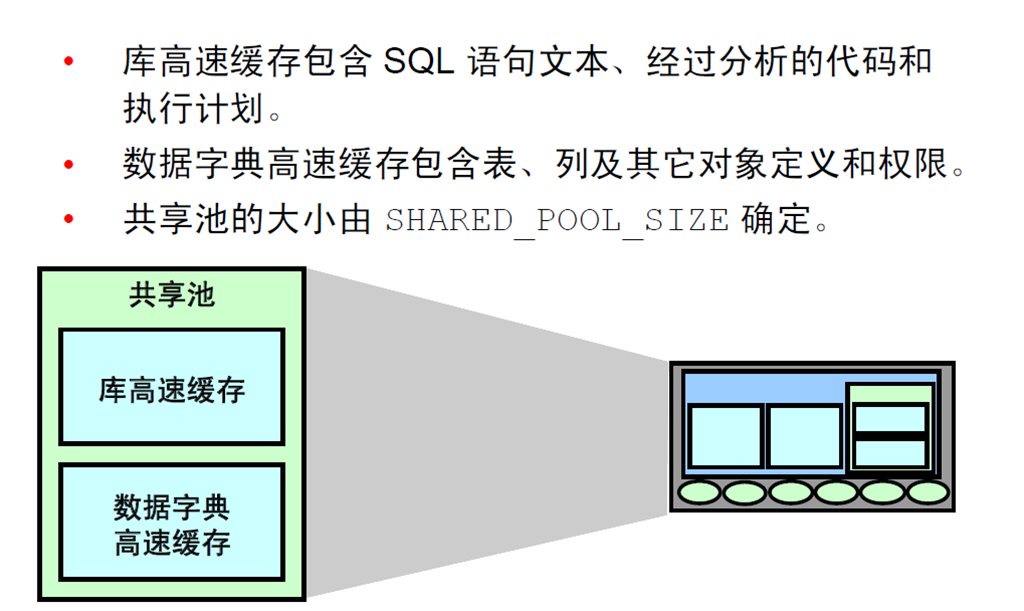
18:数据库缓冲区高速缓存
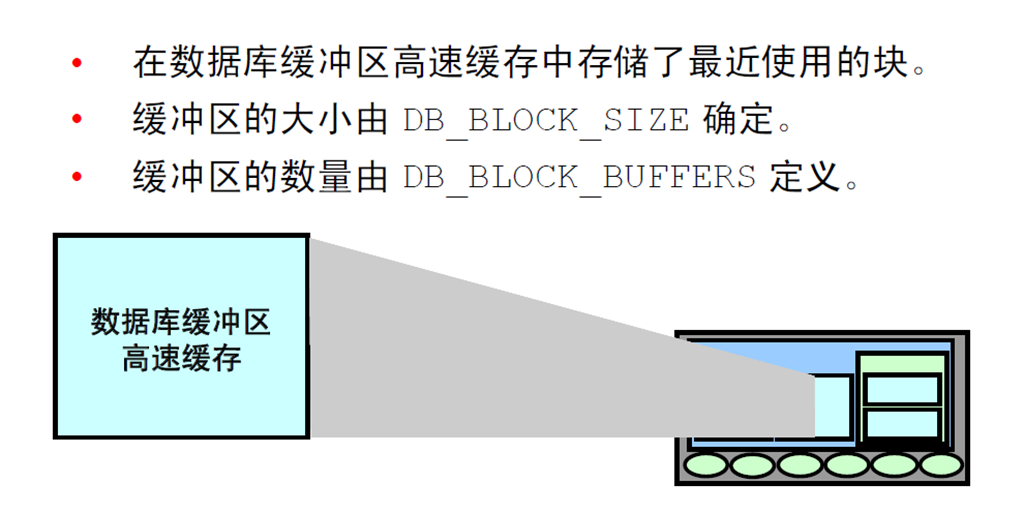
19:程序全局区(PGA)

20:处理DML 语句
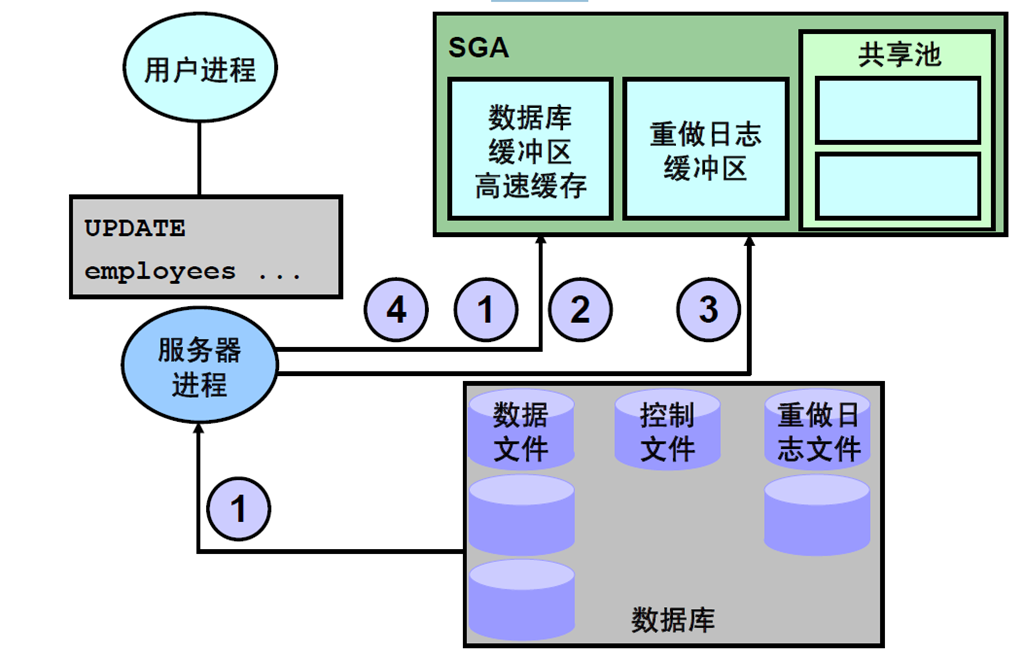
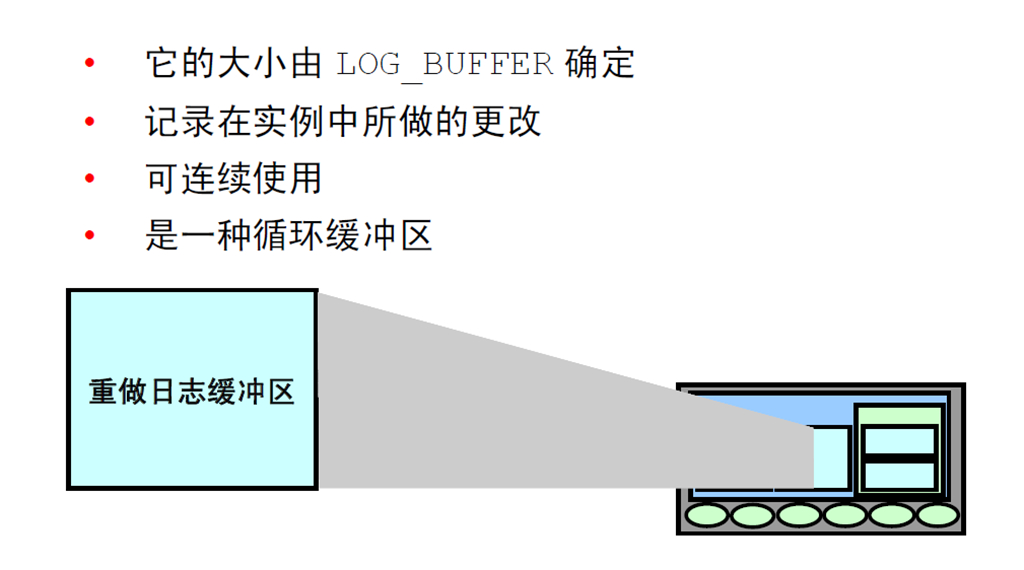
21:重做日志缓冲区
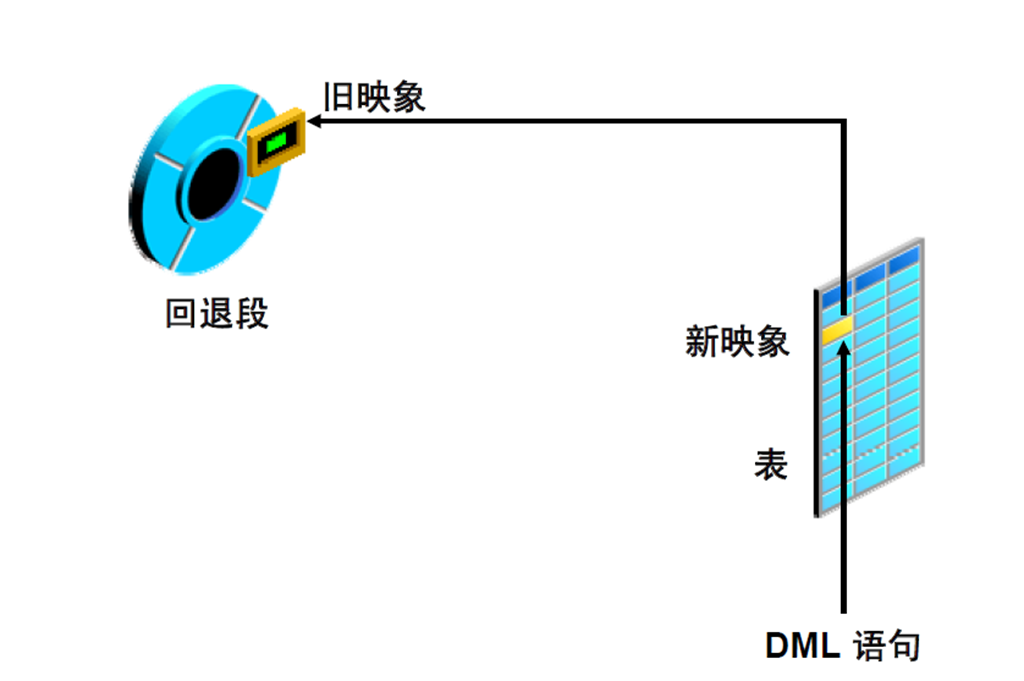
22:回退段
23:COMMIT 处理
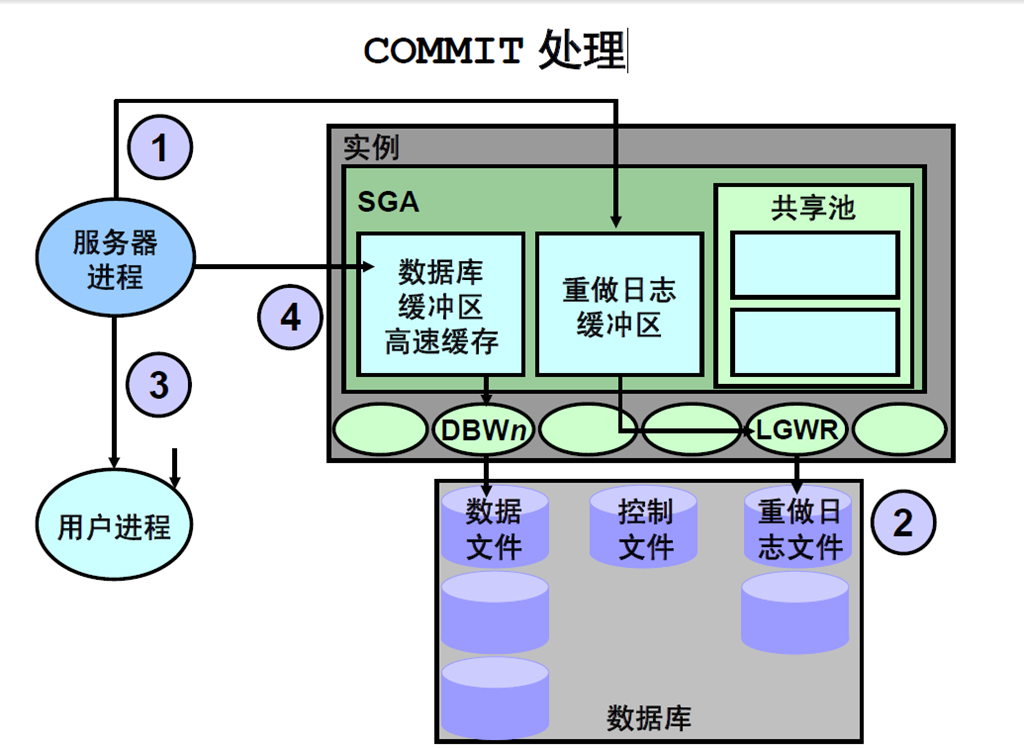
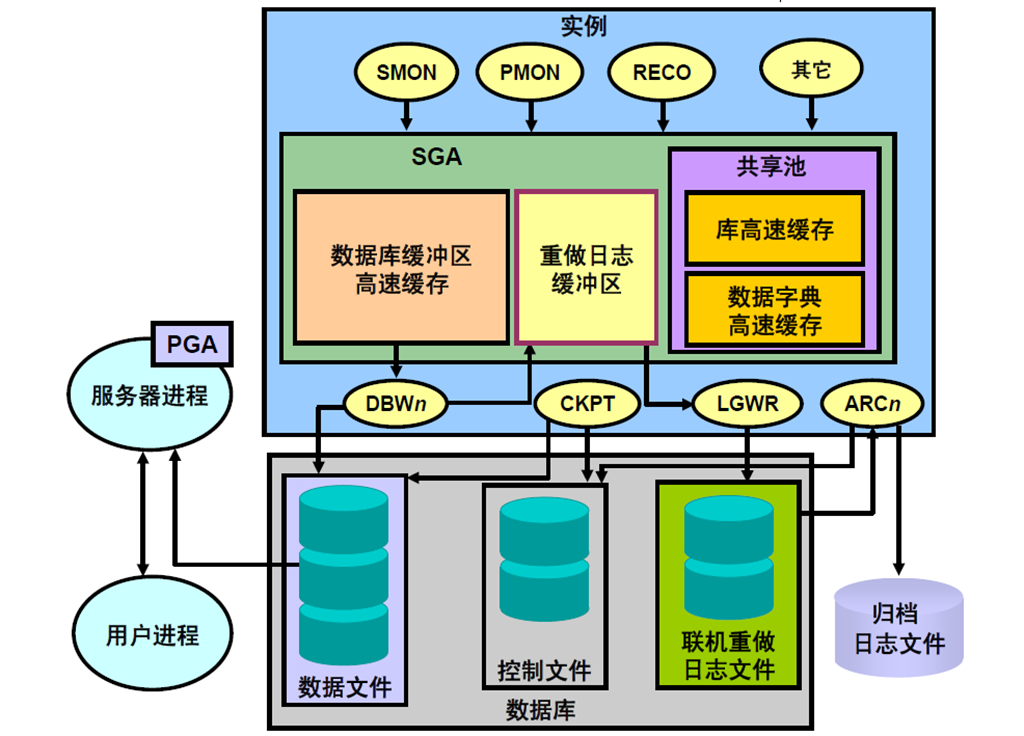
24:Oracle DB 体系结构小结
=======================================================================================================================================
_____________________________________________________________________________________________________________________________________________________________________________
Oracle Database 11g : SQL 基础的更多相关文章
- Oracle Database 11g Express Editon介绍及安装
一.Oracle Database 11g Express版本介绍 公司项目开发中,使用的数据库是Oracle 10g和MySQL 5.5,最新因为开发需要,需要从后台读取一些数据.使用的客户端是PL ...
- 结合使用 Oracle Database 11g 和 Python
结合使用 Oracle Database 11g 和 Python 本教程介绍如何结合使用 Python 和 Oracle Database 11g. 所需时间 大约 1 个小时 概述 Python ...
- Oracle Database 11g Release 2(11.2.0.3.0) RAC On Redhat Linux 5.8 Using Vmware Workstation 9.0
一,简介 二,配置虚拟机 1,创建虚拟机 (1)添加三块儿网卡: 主节点 二节点 eth0: 公网 192.168.1.20/24 NAT eth0: 公网 192.168.1 ...
- Oracle Database 11g Express Edition学习笔记
修改字符集 使用用户system,通过sqlplus程序连接到Oracle数据库,输入以下命令,查看字符集: SQL> select userenv('language') from dual; ...
- Oracle Database 11G R2 标准版 企业版 下载地址(转)
转自:http://blog.itpub.net/628922/viewspace-759245/ 不需要注册,直接复制到迅雷或其他下载软件中即可下载. oracle 11.2.0.3 下载地址: L ...
- Oracle Database 11g Express Edition 使用小结(windows)
如何启动oraclewindows系统服务中有一个服务叫:[OracleService[SID]]SID是你安装oracle xe时候的实例名,如果你没有改默认的是[XE], OracleServic ...
- 如何安装Oracle Database 11g数据库
先选择你适合你的系统版本,32位系统的请选择32位的,64位系统可以使用32位也可以使用64位,建议采用64位的! 适用于 Microsoft Windows(32 位)的 Oracle Databa ...
- 使用PLSQL Developer连接Oracle Database 11g Express Edition
要使用oracle数据库,需要准备三部分: 1.oracle服务端 2.oracle客户端 3.连接工具 你装的Oracle Database 11g Express Edition就是服务端,pls ...
- Opatching PSU in Oracle Database 11g Release 2 RAC on RHEL6
Opatching PSU in Oracle Database 11g Release 2(11.2.0.4) RAC on RHEL6 1) 升级opatch工具 1.1) For GI home ...
随机推荐
- Js JSON.stringify()与JSON.parse()与eval()详解及使用案例
(1)JSON.parse函数 作用:将json字符串转换成json对象. 语法:JSON. parse(text[,reviver]). 参数:text 必须:一个有效的json字符串. revi ...
- luogu P3242 [HNOI2015]接水果
传送门 其实这题难点在于处理路径包含关系 先求出树的dfn序,现在假设路径\(xy\)包含\(uv(dfn_x<dfn_y,dfn_u<dfn_v)\) 如果\(lca(u,v)!=u\) ...
- 洛谷P1972 【[SDOI2009]HH的项链】
这道题想了很久,发题解是为了理解的更深刻一点...(管理放我过好嘛qwq) 步入正题:这道题应该是很多做法,我选择的是离线+树状数组. 首先输入数组.用fisrt数组先记录元素最开始出现的位置,对应的 ...
- Oracle简单学习笔记
创建用户 CREATE USER username identified by password;//这是最简单的用户创建SQL语句. CREATE USER username identified ...
- A Simple Problem with Integers POJ - 3468 (分块)
题目链接:https://cn.vjudge.net/problem/POJ-3468 题目大意:区间加减+区间查询操作. 具体思路:本来是一个线段树裸题,为了学习分块就按照分块的方法做吧. 分块真的 ...
- 方法join()使用详解
在线程的常见方法一节中,已经接触过join()方法的使用. 在很多情况下,主线程创建并启动子线程,如果子线程中要进行大量的耗时运算,主线程将早于子线程结束.这时,如果主线程想等子线程执行完成才结束,比 ...
- DataGrid列中加入CheckBox 全选 点击Header全选 和 只操作选中部分 功能的实现
先写个效果 中午接着写 反正没人看 只是给自己记录
- 手写代码 - java.lang.String/StringBuilder 相关
语言:Java 9-截取某个区间的string /** * Returns a string that is a substring of this string. The * substring b ...
- 拦截RESTful API并做相应处理的方式
⒈使用Filter(过滤器) package cn.coreqi.security.filter; import org.springframework.stereotype.Component; i ...
- canves绘制北京地铁线路图,包括线路绘制,优先路线,单路径选择。
canves绘制北京地铁线路图,包括线路绘制,优先路线,单路径选择. 即将推出,后台涵盖各种语言,php,C#,java,nodejs等.