python爬虫scrapy之登录知乎
下面我们看看用scrapy模拟登录的基本写法:
注意:我们经常调试代码的时候基本都用chrome浏览器,但是我就因为用了谷歌浏览器(它总是登录的时候不提示我用验证码,误导我以为登录时不需要验证码,其实登录时候必须要验证码的),这里你可以多试试几个浏览器,一定要找个提示你输入验证码的浏览器调试。
1、我们登录的时候,提示我们输入验证码,当验证码弹出之前会有个请求,我们打开这个请求,很明显,type是login,验证码无疑了,就算是看请求的因为名,你也应该知道这个就是验证码的请求,或者打开这个验证码的请求url,这。
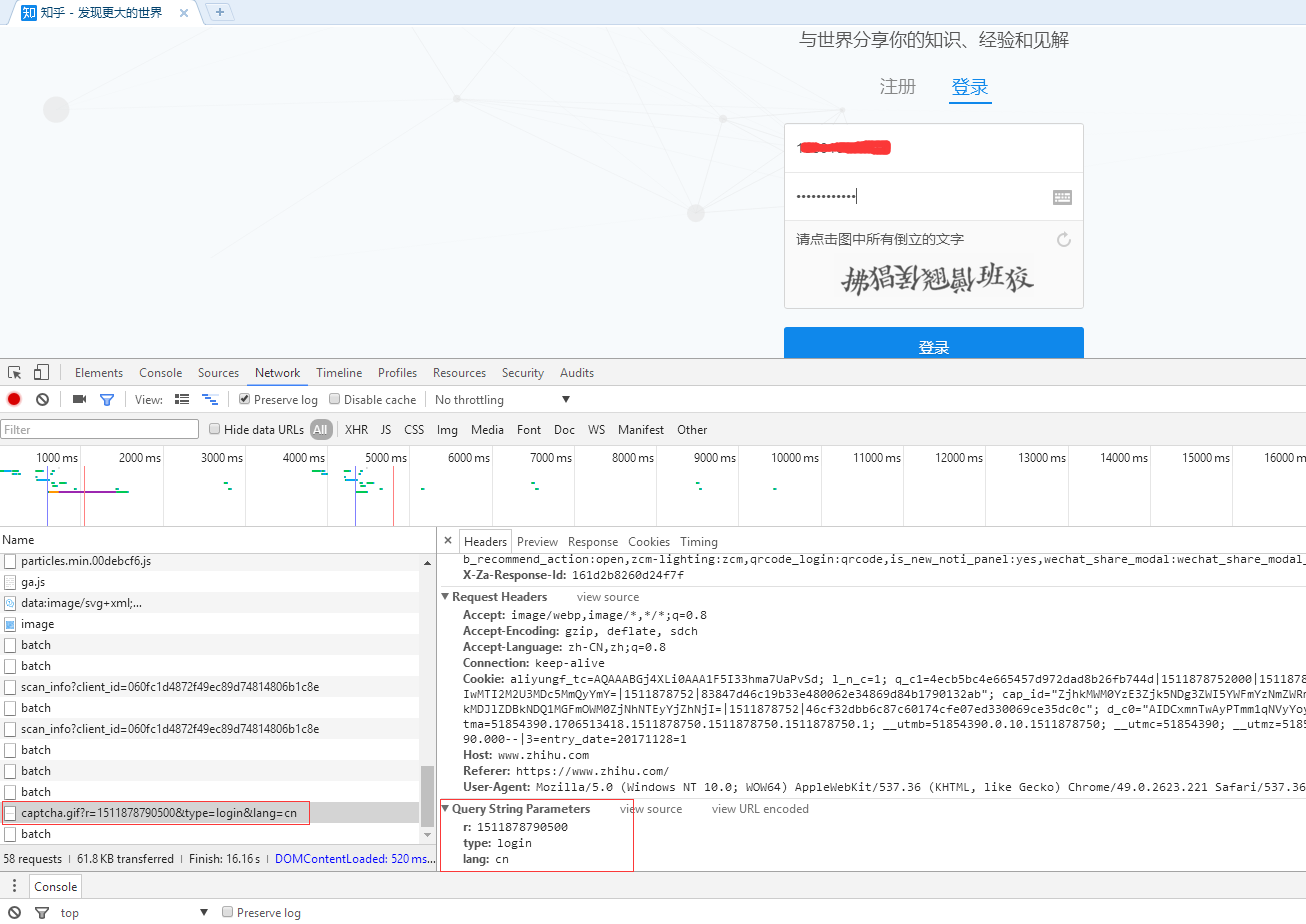
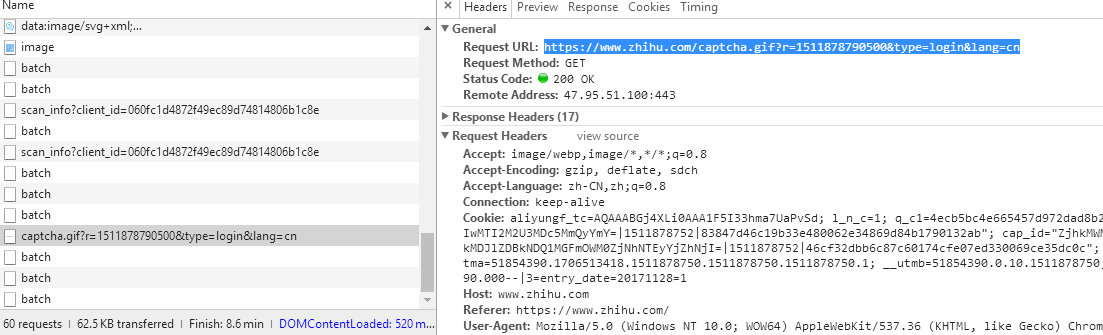
验证码的图片,悲惨了,这怎么整。别着急。。
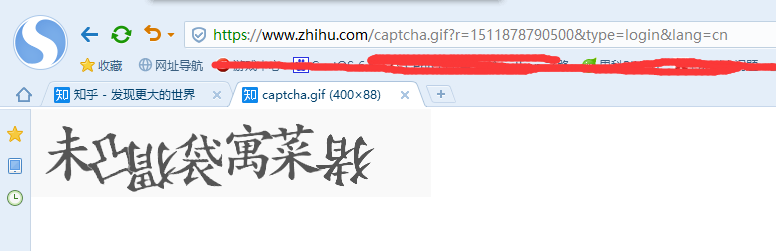
2、验证码提示我们要点击倒着写的字体,这。。。,爬虫和反爬虫就是无休止的互相折磨。这明显就是上面那个图片的信息。
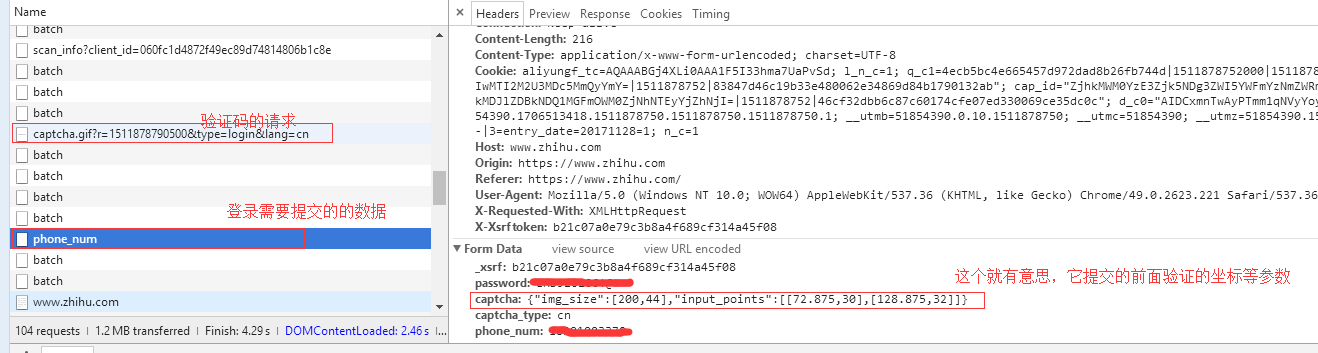
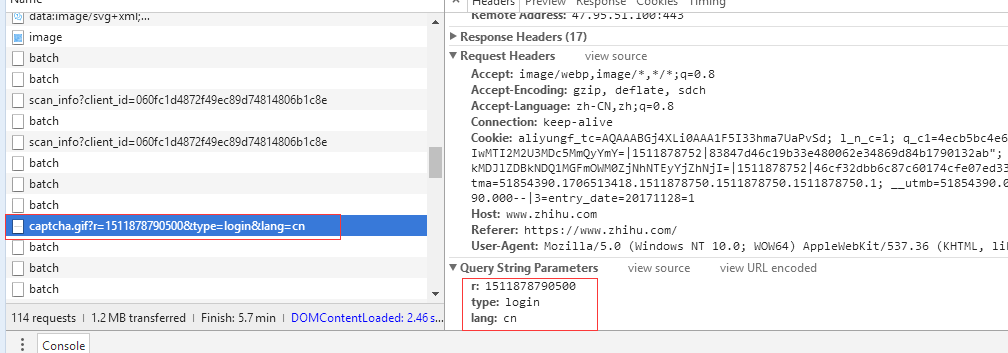
3、机智的我,发现验证码的请求参数里面有三个参数,r是一个13位的数字,type是登录用的,lang很可疑,改改它,把cn给他改成en。mygod这不也是验证码么,就试试它了。
4、页面基本登录原理分析完了,我们接下来看看代码怎么写,首先我们重构scrapy的start_requests方法(有scrapy基础的同学都知道,这个名字可不是瞎写的)。
5、分析这个验证码的请求连接,https://www.zhihu.com/captcha.gif?r=1511878790500&type=login&lang=en,这里面都可以固定,但是这个验证码肯定不行,13位的数字,果断想到了当前时间
最后,我们要请求这个url,这里必须要加上请求头信息,callback就是下面你要执行的方法。
def start_requests(self):
'''
1、首先构造并抓取登录需要提交的验证码
:return:
'''
t = str(int(time.time() * 1000))
captcha_url = 'https://www.zhihu.com/captcha.gif?r={0}&type=login&lang=en'.format(t)
return [scrapy.Request(url=captcha_url, headers=self.header, callback=self.parser_captcha)]
6、上面请求完成后,就会将请求结果直接返回个下面的这个方法,所以它必须有个形式参数,来接收请求的结果,首先我们将请求的的结果,其实就是刚才我们看到的那个图片,图片的信息就在body里面,直接将整个body存成一个文件,然后我这里用的是Image打开我们存入的文件,文件都给你打开了,你还不得看看输入一下(如果你有云大码平台的服务,就直接让云大码平台搞定就行),这里我们只能自己看自己输入了。搞完了验证码,我们现在准备开始登陆,这里可不是直接用登陆的url登陆就行,你仔细的话还有个xrsf参数需要我们获取,那就请求的url直接就是登陆页面,注意你的头部信息,不伪装一下,立马给你请求出错。callback就不说了吧。这需要注意的就是,这直接把验证码存入了scrapy的meta里面了。
def parser_captcha(self, response):
'''
1、根据start_requests方法返回的验证码,将它存入本地
2、打开下载下来的验证码
3、这里是需要手动输入的,这里可以接入打码平台
:param response:
:return:
'''
with open('captcha.jpg', 'wb') as f:
f.write(response.body)
f.close()
try:
im = Image.open('captcha.jpg')
im.show()
im.close()
except:
pass
captcha = input("请输入你的验证>")
return scrapy.FormRequest(url='https://www.zhihu.com/#signin', headers=self.header, callback=self.login, meta={
'captcha': captcha
})
7、下面我们来搞定xsrf参数,这里我用xpath,一句话搞定,下面就是post_url就是上面phone_num请求里面的url,也是真正意义上的post提交登录信息的url。因为我们已经把验证码放进了meta里面了,所以这里直接获取就行。基本登录信息伪装完成以后,开始提交登录信息,登录完成以后,我们设置一个callback回调方法,检查一下登录信息。
def login(self, response):
xsrf = response.xpath("//input[@name='_xsrf']/@value").extract_first()
if xsrf is None:
return ''
post_url = 'https://www.zhihu.com/login/phone_num'
post_data = {
"_xsrf": xsrf,
"phone_num": '你的账户名称',
"password": '你的账户密码',
"captcha": response.meta['captcha']
}
return [scrapy.FormRequest(url=post_url, formdata=post_data, headers=self.header, callback=self.check_login)]
8、上面请求完成以后,会返回我们一个字典,这里我们判断一下是否登录成功,如果登录成功以后,就执行我们start_urls里面的url地址,因为已经登录成功了,所以这里我们的start_urls就是https://www.zhihu.com,这样我们就可以再parse方法里面继续解析我们登录后的html信息了。
def check_login(self, response):
js = json.loads(response.text)
print(js)
if 'msg' in js and js['msg'] == '登录成功':
for url in self.start_urls:
print(url)
yield scrapy.Request(url=url, headers=self.header, dont_filter=True)
else:
print("登录失败,请检查!!!")
代码如下:
import json
import scrapy
import time
from PIL import Image class ZhihuloginSpider(scrapy.Spider):
name = 'zhihu_login'
allowed_domains = ['zhihu.com']
start_urls = ['https://www.zhihu.com/']
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML,'
' like Gecko) Chrome/62.0.3202.94 Safari/537.36',
} def parse(self, response):
#主页爬取的具体内容
print(response.text) def start_requests(self):
'''
1、首先构造并抓取登录需要提交的验证码
:return:
'''
t = str(int(time.time() * 1000))
captcha_url = 'https://www.zhihu.com/captcha.gif?r={0}&type=login&lang=en'.format(t)
return [scrapy.Request(url=captcha_url, headers=self.header, callback=self.parser_captcha)] def parser_captcha(self, response):
'''
1、根据start_requests方法返回的验证码,将它存入本地
2、打开下载下来的验证码
3、这里是需要手动输入的,这里可以接入打码平台
:param response:
:return:
'''
with open('captcha.jpg', 'wb') as f:
f.write(response.body)
f.close()
try:
im = Image.open('captcha.jpg')
im.show()
im.close()
except:
pass
captcha = input("请输入你的验证>")
return scrapy.FormRequest(url='https://www.zhihu.com/#signin', headers=self.header, callback=self.login, meta={
'captcha': captcha
}) def login(self, response):
xsrf = response.xpath("//input[@name='_xsrf']/@value").extract_first()
if xsrf is None:
return ''
post_url = 'https://www.zhihu.com/login/phone_num'
post_data = {
"_xsrf": xsrf,
"phone_num": '你的账户名称',
"password": '你的账户密码',
"captcha": response.meta['captcha']
}
return [scrapy.FormRequest(url=post_url, formdata=post_data, headers=self.header, callback=self.check_login)] # 验证返回是否成功
def check_login(self, response):
js = json.loads(response.text)
print(js)
if 'msg' in js and js['msg'] == '登录成功':
for url in self.start_urls:
print(url)
yield scrapy.Request(url=url, headers=self.header, dont_filter=True)
else:
print("登录失败,请检查!!!")
python爬虫scrapy之登录知乎的更多相关文章
- python爬虫scrapy框架——人工识别知乎登录知乎倒立文字验证码和数字英文验证码
目前知乎使用了点击图中倒立文字的验证码: 用户需要点击图中倒立的文字才能登录. 这个给爬虫带来了一定难度,但并非无法解决,经过一天的耐心查询,终于可以人工识别验证码并达到登录成功状态,下文将和大家一一 ...
- python爬虫scrapy框架——人工识别登录知乎倒立文字验证码和数字英文验证码(2)
操作环境:python3 在上一文中python爬虫scrapy框架--人工识别知乎登录知乎倒立文字验证码和数字英文验证码(1)我们已经介绍了用Requests库来登录知乎,本文如果看不懂可以先看之前 ...
- Python爬虫之模拟登录微信wechat
不知何时,微信已经成为我们不可缺少的一部分了,我们的社交圈.关注的新闻或是公众号.还有个人信息或是隐私都被绑定在了一起.既然它这么重要,如果我们可以利用爬虫模拟登录,是不是就意味着我们可以获取这些信息 ...
- python爬虫Scrapy(一)-我爬了boss数据
一.概述 学习python有一段时间了,最近了解了下Python的入门爬虫框架Scrapy,参考了文章Python爬虫框架Scrapy入门.本篇文章属于初学经验记录,比较简单,适合刚学习爬虫的小伙伴. ...
- python爬虫scrapy项目详解(关注、持续更新)
python爬虫scrapy项目(一) 爬取目标:腾讯招聘网站(起始url:https://hr.tencent.com/position.php?keywords=&tid=0&st ...
- Python爬虫-百度模拟登录(二)
上一篇-Python爬虫-百度模拟登录(一) 接上一篇的继续 参数 codestring codestring jxG9506c1811b44e2fd0220153643013f7e6b1898075 ...
- Python爬虫Scrapy框架入门(0)
想学习爬虫,又想了解python语言,有个python高手推荐我看看scrapy. scrapy是一个python爬虫框架,据说很灵活,网上介绍该框架的信息很多,此处不再赘述.专心记录我自己遇到的问题 ...
- [Python爬虫] scrapy爬虫系列 <一>.安装及入门介绍
前面介绍了很多Selenium基于自动测试的Python爬虫程序,主要利用它的xpath语句,通过分析网页DOM树结构进行爬取内容,同时可以结合Phantomjs模拟浏览器进行鼠标或键盘操作.但是,更 ...
- 安装python爬虫scrapy踩过的那些坑和编程外的思考
这些天应朋友的要求抓取某个论坛帖子的信息,网上搜索了一下开源的爬虫资料,看了许多对于开源爬虫的比较发现开源爬虫scrapy比较好用.但是以前一直用的java和php,对python不熟悉,于是花一天时 ...
随机推荐
- Linux三剑客-AWK
1.什么是awk AWK是一种处理文本文件的语言,是一个强大的文本分析工具.有统计和计算功能. 之所以叫AWK是因为其取了三位创始人 Alfred Aho,Peter Weinberger, 和 Br ...
- 为什么swift是面向协议的编程--对面向对象机制的改进
主要目标是提供抽象能力和解决值类型的多态问题 Actually, Abrahams says, those are all attributes of types, and classes are j ...
- 文本分类实战(一)—— word2vec预训练词向量
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
- Python:Day24 类、类的三大特性
Python有两种编程方式:函数式+面向对象 函数式编程可以做所有的事情,但是否合适? 面向对象: 一.定义 函数: def + 函数名(参数) 面象对象: class bar---> 名字 ...
- day22 Pythonpython 本文xml模块
一.xml介绍 xml是实现不同语言或者程序直接进行数据交换的协议,跟json差不多,单json使用起来更简单.不过现在还有很多传统公司的接口主要是xml xml跟html都是标签语言 我们主要学习的 ...
- Node.js读取某个目录下的所有文件夹名字并将其写入到json文件
针对解决的问题是,有些时候我们需要读取某个文件并将其写入到对应的json文件(xml文件也行,不过目前用json很多,json是主流). 源码如下:index.js var fs = require( ...
- KindEditor 开源得富文本编辑器
正常HTML情况写输入长文本需要textarea 标签 .但textarea 标签局限性很大,切只能输入单一的文本,我们大多情况下看到的新闻类文本信息大多是图文混排得,且有的配有视频和音乐. 我们可以 ...
- linux内存源码分析 - 内存压缩(实现流程)
本文为原创,转载请注明:http://www.cnblogs.com/tolimit/ 概述 本文章最好结合linux内存管理源码分析 - 页框分配器与linux内存源码分析 -伙伴系统(初始化和申请 ...
- Java关键字(六)——super
在 Java关键字(五)——this 中我们说 this 关键字是表示当前对象的引用.而 Java 中的 super 关键字则是表示 父类对象的引用. 我们分析这句话“父类对象的引用”,那说明我们使用 ...
- 【开源】小程序、小游戏和Web运动引擎 to2to 发布
简单轻量跨平台的 Javascript 运动引擎 Github → https://github.com/dntzhang/cax/tree/master/packages/to Simple DEM ...