[转]构建高性能MySQL体系
来源:http://www.yunweipai.com/archives/21232.html
构建高性能MySQL系统涵盖从单机、硬件、OS、文件系统、内存到MySQL 本身的配置,以及schema 设计、索引设计 ,再到数据库架构上的水平和垂直拓展。
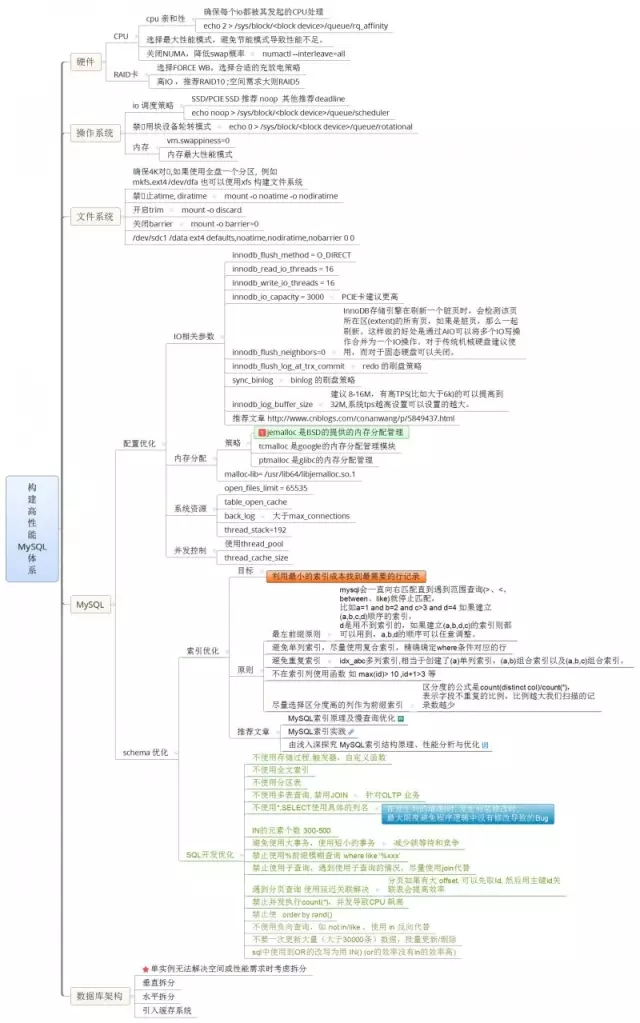
内容描述:
硬件
(1)CPU
CPU亲和性:确保每个io都被其发起的CPU处理
echo 2 > /sys/block/<block device>/queue/rq_affinity
选择最大性能模式,避免节能模式导致性能不足
关闭NUMA,降低swap概率
numactl –interleave=all
(2)RAID卡
选择FORCE WB读写策略
选择合适的充放电策略
高IO,推荐RAID10
空间需求大则RAID5
操作系统
(1)IO调度策略
SSD/PCIE SSD推荐noop,其它推荐deadline
echo noop > /sys/block/<block device>/queue/scheduler
(2)禁用块设备轮转模式
echo 0 > /sys/block/<block device>/queue/rotational
(3)内存
vm.swappiness=0
内存最大性能模式
文件系统
确保4K对⻬,如果使用全盘一个分区,例如mkfs.ext4 /dev/dfa也可以使用xfs 构建文件系统。
禁止atime、diratime
mount -o noatime -o nodiratime
开启trim
mount -o discard
关闭barrier
mount -o barrier=0
/dev/sdc1 /data ext4 defaults,noatime,nodiratime,nobarrier 0 0
MySQL
(1)配置优化
IO相关参数
innodb_flush_method = O_DIRECT
innodb_read_io_threads = 16
innodb_write_io_threads = 16
innodb_io_capacity = 3000(PCIE卡建议更高)
innodb_flush_neighbors=0InnoDB存储引擎在刷新一个脏页时,会检测该页所在区(extent)的所有页,如果是脏页,那么一起刷新。这样做的好处是通过AIO可以将多个IO写操作合并为一个IO操作。对于传统机械硬盘建议使用,而对于固态硬盘可以关闭
innodb_flush_log_at_trx_commitredo 的刷盘策略
sync_binlogbinlog 的刷盘策略
innodb_log_buffer_size建议8-16M,有高TPS(比如大于6k)的可以提高到32M,系统tps越高设置可以设置的越大
推荐文章 www.cnblogs.com/conanwang/p/5849437.html
内存分配
策略:
jemalloc是BSD的提供的内存分配管理
tcmalloc是google的内存分配管理模块
ptmalloc是glibc的内存分配管理
malloc-lib= /usr/lib64/libjemalloc.so.1
系统资源:
malloc-lib= /usr/lib64/libjemalloc.so.1
back_log:大于max_connections
thread_stack=192
并发控制:
使用thread_pool
thread_cache_size
(2)schema优化
索引优化
目标:利用最小的索引成本找到最需要的行记录。
原则:
最左前缀原则:MySQL会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如a=1 and b=2 and c>3 and d=4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整
避免重复索引:idx_abc多列索引,相当于创建了(a)单列索引,(a,b)组合索引以及(a,b,c)组合索引。不在索引列使用函数 如 max(id)> 10 ,id+1>3 等
尽量选择区分度高的列作为前缀索引:区分度的公式是count(distinct col)/count(*),表示字段不重复的比例,比例越大我们扫描的记录数越少
推荐文章:
MySQL索引原理及慢查询优化http://tech.meituan.com/mysql-index.html
MySQL索引实践http://blog.coderland.net/mysql/2015/08/26/MySQL%E7%B4%A2%E5%BC%95%E5%AE%9E%E8%B7%B5/
由浅入深探究 MySQL索引结构原理、性能分析与优化http://blog.jobbole.com/87107/
SQL开发优化
不使用存储过程、触发器,自定义函数
不使用全文索引
不使用分区表
针对OTLP业务尽量避免使用多表join和子查询
不使用*,SELECT使用具体的列名:在发生列的增/删时,发生列名修改时,最大限度避免程序逻辑中没有修改导致的BUG,IN的元素个数300-500
避免使用大事务,使用短小的事务:减少锁等待和竞争
禁止使用%前缀模糊查询 where like ‘%xxx’
禁止使用子查询,遇到使用子查询的情况,尽量使用join代替
遇到分页查询,使用延迟关联解决:分页如果有大offset,可以先取Id,然后用主键id关联表会提高效率
禁止并发执行count(*),并发导致CPU飙高
禁止使⽤order by rand()
不使用负向查询,如 not in/like,使用in反向代替
不要一次更新大量(大于30000条)数据,批量更新/删除
SQL中使用到OR的改写为用 IN() (or的效率没有in的效率高)
数据库架构
单实例无法解决空间和性能需求时考虑拆分
垂直拆分
水平拆分
引入缓存系统
说明
IO相关的优化可能还不完整,以后会逐步完善。
关于数据库系统水平和垂直拆分是一个比较大的命题,这里略过,每个公司的业务规模不一样,选取的拆分策略也有所不同。
[转]构建高性能MySQL体系的更多相关文章
- 如何构建高性能MySQL索引
本文的重点在于如何构建一个高性能的MySQL索引,从中你可以学到如何分析一个索引是不是好索引,以及如何构建一个好的索引. 索引误区 多列索引 一个索引的常见误区是为每一列创建一个索引,如下面创建的索引 ...
- MySQL全面瓦解24:构建高性能索引(策略篇)
学习如果构建高性能的索引之前,我们先来了解下之前的知识,以下两篇是基础原理,了解之后,对面后续索引构建的原则和优化方法会有更清晰的理解: MySQL全面瓦解22:索引的介绍和原理分析 MySQL全面瓦 ...
- MySQL全面瓦解25:构建高性能索引(案例分析篇)
回顾一下上面几篇索引相关的文章: MySQL全面瓦解22:索引的介绍和原理分析 MySQL全面瓦解23:MySQL索引实现和使用 MySQL全面瓦解24:构建高性能索引(策略篇) 索引的十大原则 1. ...
- 【读书笔记】2016.12.10 《构建高性能Web站点》
本文地址 分享提纲: 1. 概述 2. 知识点 3. 待整理点 4. 参考文档 1. 概述 1.1)[该书信息] <构建高性能Web站点>: -- 百度百科 -- 本书目录: 第1章 绪论 ...
- 高性能Mysql主从架构的复制原理及配置详解
温习<高性能MySQL>的复制篇. 1 复制概述 Mysql内建的复制功能是构建大型,高性能应用程序的基础.将Mysql的数据分布到多个系统上去,这种分布的机制,是通过将Mysql的某一台 ...
- 《构建高性能web站点》随笔 无处不在的性能问题
前言– 追寻大牛的足迹,无处不在的“性能”问题. 最近在读郭欣大牛的<构建高性能Web站点>,读完收益颇多.作者从HTTP.多级缓存.服务器并发策略.数据库.负载均衡.分布式文件系统多个方 ...
- 高性能MySQL --- 读书笔记(1) - 2016/8/2
此书不但帮助MySQL初学者提高使用技巧,更为有经验的MySQL DBA指出了开发高性能MySQL应用的途径.全书包括14章,内容覆盖MySQL系统架构.设计应用技巧.SQL语句优化.服务器性能调优. ...
- 转:高性能Mysql主从架构的复制原理及配置详解
温习<高性能MySQL>的复制篇. 1 复制概述 Mysql内建的复制功能是构建大型,高性能应用程序的基础.将Mysql的数据分布到多个系统上去,这种分布的机制,是通过将Mysql的某一台 ...
- 构建高性能WEB站点笔记三
构建高性能WEB站点笔记三 第10章 分布式缓存 10.1数据库的前端缓存区 文件系统内核缓冲区,位于物理内存的内核地址空间,除了使用O_DIRECT标记打开的文件以外,所有对磁盘文件的读写操作都要经 ...
随机推荐
- GIS案例学习笔记-三维生成和可视化表达
GIS案例学习笔记-三维生成和可视化表达 联系方式:谢老师,135-4855-4328,xiexiaokui#qq.com 目的:针对栅格或者矢量数值型数据,进行三维可视化表达 操作时间:15分钟 案 ...
- java.lang.OutOfMemoryError:GC overhead limit exceeded解决方法
异常如下:Exception in thread "main" java.lang.OutOfMemoryError: GC overhead limit exceeded 一.解 ...
- foreach和List.Foreach 退出循环相关问题
foreach: continue;:退出本次循环 break;:退出循环 return;:退出循环 List.Foreach: return;:退出本次循环 小结:list.Foreach中不能退出 ...
- eclipse中的web项目部署路径
elipse添加了server之后,如果不对tomcat的部署路径做更改,则eclipse默认对工程的部署在 eclipse-workspace\.metadata.plugins\org.eclip ...
- ExpandableListView解析JSON数据
效果图: 说明:刚开始使用这个控件我花费了3天的时间,但是一直都没有达到预期的效果,要么就是直接全部不显示,要么就是数据累加 ...
- JSP(介绍,语法,指令)
什么是JSP JSP全名为Java Server Pages,java服务器页面.JSP是一种基于文本的程序,其特点就是HTML和Java代码共同存在! JSP的工作原理 其实JSP在第一次被访问的时 ...
- 20175314薛勐 MyCP(课下作业,必做)
MyCP(课下作业,必做) 要求 编写MyCP.java 实现类似Linux下cp XXX1 XXX2的功能,要求MyCP支持两个参数: java MyCP -tx XXX1.txt XXX2.bin ...
- 【Spring学习】【Java基础回顾-数据类型】
Java基础回顾过程中,之前对于Java相关基础知识都是从这个人的博客看一些,那边的内容看一下,觉得不够系统化,决定用xmind脑图的形式,将Java基础知识回顾的作为一个系列,当前正在做的会包含: ...
- JAVA常用注解
摘自:https://www.cnblogs.com/guobm/p/10611900.html 摘要:java引入注解后,编码节省了很多需要写代码的时间,而且精简了代码,本文主要罗列项目中常用注解. ...
- javascript Hoisting变量提升
1. 看人家举的两个例子,我认为这里的判断是否定义: !var 其实就是 指是否在函数function里面定义了.只有在funciton里面定义了了,js才hoist到最上面去找这个变量的值,否则就按 ...