Redis数据结构以及应用场景
1. Redis数据结构以及应用场景
1.1. Memcache VS Redis
1.1.1. 选Memcache理由
- 系统业务以KV的缓存为主,数据量、并发业务量大,memcache较为合适
- memcache将所有数据存储在物理内存中。Redis则有自己的VM机制,当数据超量时,会引发swap,影响计算机服务器性能
- memchache使用多线程的模式(主线程监听,work子线程工作),而Redis使用单线程,难以充分利用目前的多核CPU,我要求的是快快快,压榨光每一个资源的性能
1.1.2. 选Redis的理由
- 虽然Redis在数据的持久化方面并不那么完美,但是可以在系统奔溃发生意外时,提供一层保障
- Redis天然高可用,官方提供了sentinel集群管理工具,释放了我们大量的工作内容
- Redis能存储内容较Memcache的1M要大多了
- Redis代码质量比Memcache好多了
- 系统不仅仅只用到KV,我们需要用到Redis丰富的数据结构以及相关功能函数,Memcache不适合我的系统
1.2. Redis数据结构
1.2.1. String
1.2.1.1. 概念
- key value都是String的map
1.2.1.2. 分布式锁
//设置锁字符串键,若存在则设置失败
SETNX("couponcode","lock") == 1 //成功获取锁
SETNX(lockKey,'lock')==0//有人占用资源获取锁失败
业务处理完毕释放分布式锁
DEL(lockKey);
//设置锁字符串键的失效时间,防止宕机,系统运行意外,导致无法释放锁
PEXPIRE(lockKey, lockMilliSeconds)
1.2.1.3. 字符串键-计数器
通过字符串这两个API即可实现:
INCR key //INCR readcount::{帖子ID} 每阅读一次
GET key //GET readcount::{帖子ID} 获取阅读量

实战情况通常取部分数据到内存再进行分配
1.2.2. Hash键
1.2.2.1. 概念
类似HashMap<String,HashMap<String,String>> h = new HashMap<>();
1.2.2.2. hash键存在的意义何在?
- Hash键可以将信息凝聚在一起,而不是直接分散存储在整个Redis中,这不仅方便了数据管理,还可以尽量避免一定的误操作
- 避免键名冲突
- 减少内存占用
1.2.2.3. 不合适使用Hash键的情况
- 过期功能的使用,过期功能只能使用在key上
- 二进制操作命令,如:SETBIT、GETBIT、BITOP
- 需要考虑数据量分布的问题
1.2.3. 列表(List)键
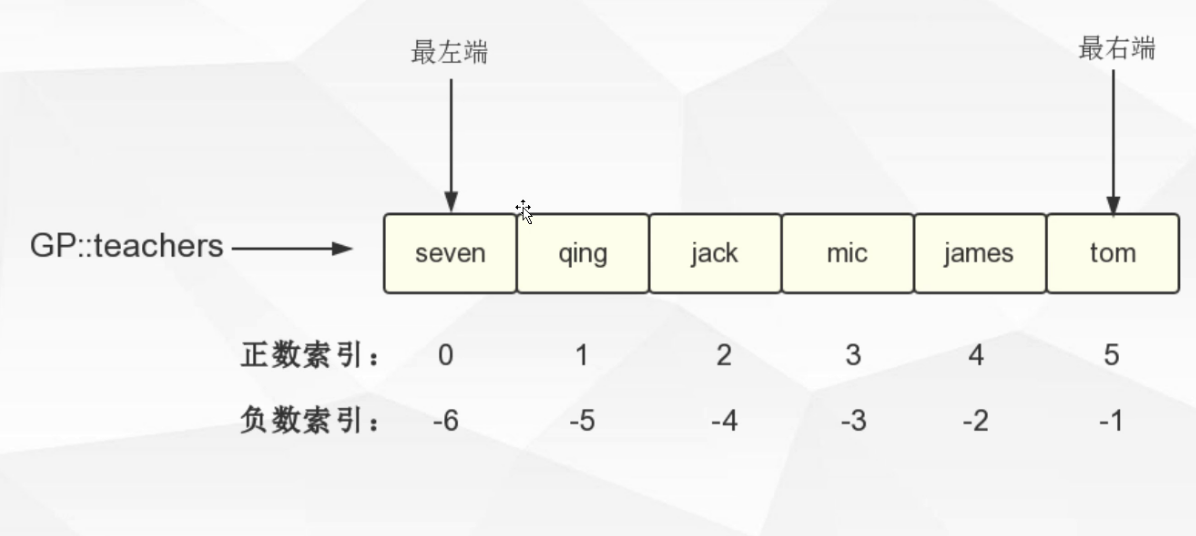
LPUSH key.value [value ...]
RPUSH key value [value ...]
LPOP key
RPOP key
LRANGE key start stop 例如LRANGE key 0 -1 表示拿取所有数据
1.2.3.1. 基于列表(List)键,实现阻塞消息队列
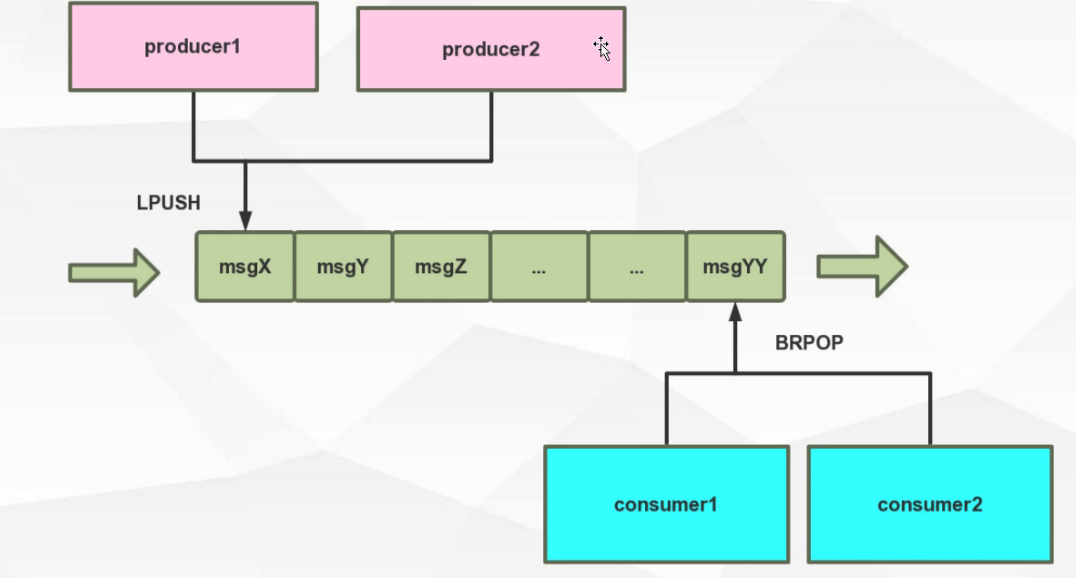
// 阻塞的取队列
BLPOP key [key ...] timeout
BRPOP key [key...] timeout

1.2.4. 集合(set)键
1.2.4.1. 基本操作
SADD key member [member ...] 添加
SREM key member [member ...] 删除
SMEMBERS key 列出所有元素
SCARD key 元素个数
SISMEMBER key member 判断元素是否在集合里 0-不存在 1-存在
SRANDMEMBER key [count] 随机弹出count个元素,默认1,保留元素在集合中
SPOP key [count] 随机弹出count个元素,并且从集合中删除
1.2.4.2. 实现抽奖

1.2.4.3. 实现点赞、签到、like等功能
点赞 --> SADD like::8001 1001
取消点赞 --> SREM like::8001 1001
检查用户是否点过赞 --> SISMEMBER like::8001 1001
获取点赞的用户列表 --> SMEMBERS like::8001
获取点赞用户数 --> SCARD like::8001
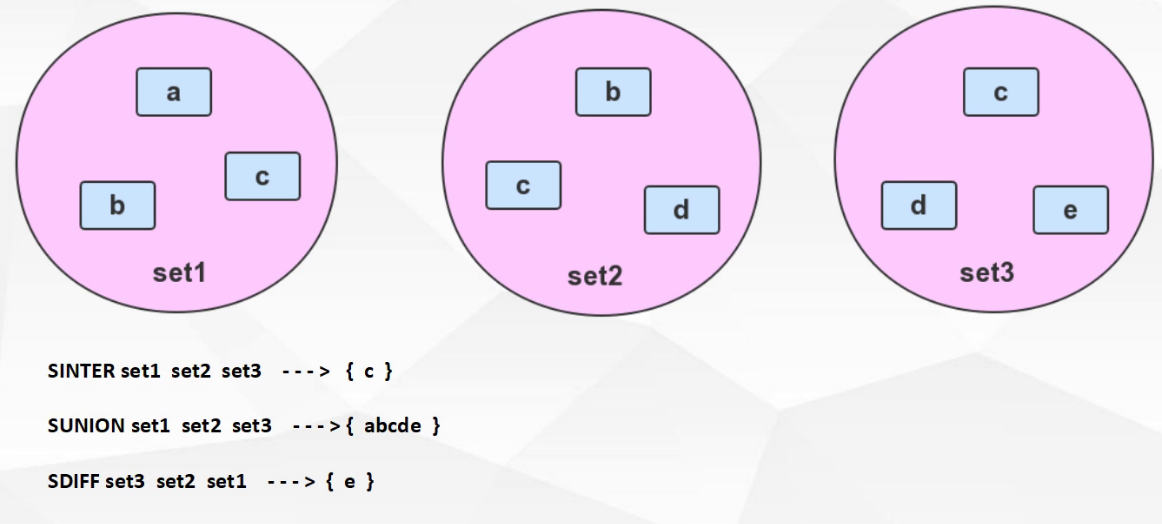
1.2.4.4. 集合运算操作
SINTER key [key ...] SINTERSTORE destination key [key ...] //交集运算 保存到目的key集中
SUNION key [key ...] SUNIONSTORE destination key [key ...] //并集计算
//差集以第一个集合为准,对后方集合进行差集运行
SDIFF key [key ...] SDIFFSTORE destination key [key ...] //差集运算
1.2.4.5. 基于集合键,实现关注模型(可能认识的人)

1.2.4.6. 基于集合运算,实现电商商品筛选
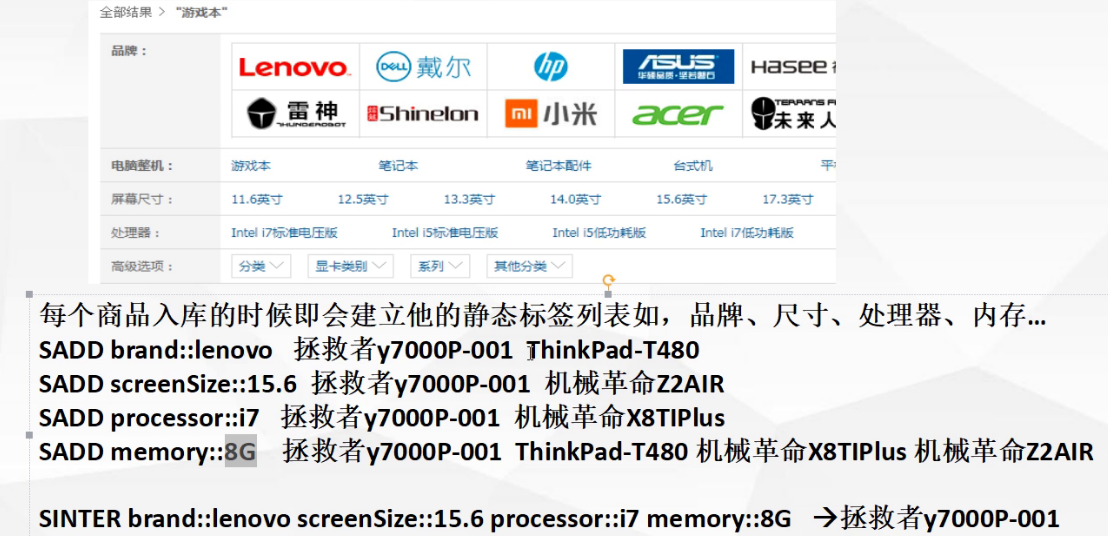
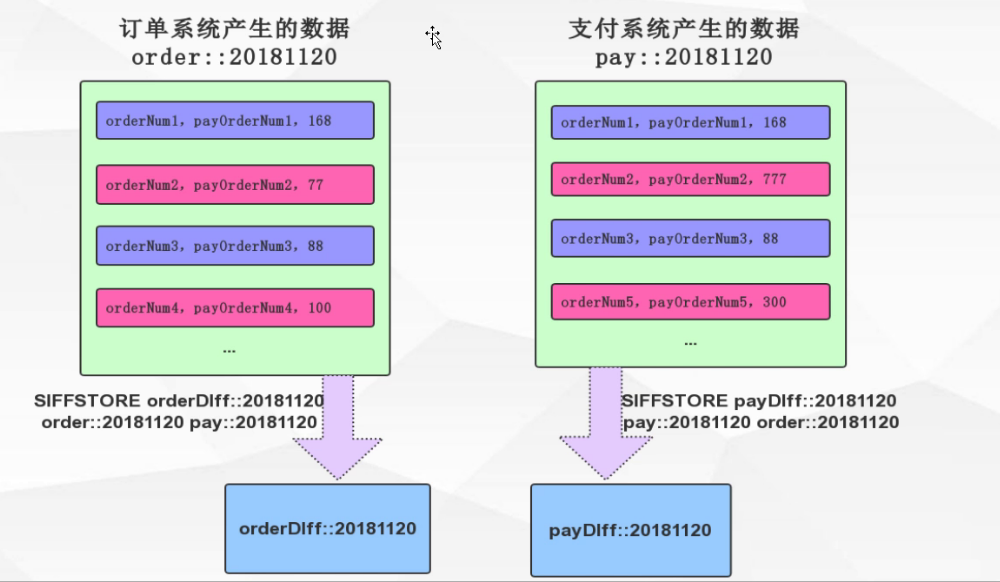
1.2.4.7. 实现与支付系统间对账
1.2.5. 有序集合(Zset)键


ZADD key score element [[score element][score element]...] 添加
ZREM key element [element...] 删除
ZSCORE key element 查看分值
ZINCRBY key increment element
ZCARD key
ZRANGE key start stop [WITHSCORES] //取出范围内元素和值 0 -1 全部
ZREVRANGE key start stop [WITHSCORES] //反向范围
集合运算操作
ZUNIONSTORE destkey numkeys key [key...]
ZINTERSTORE destkey numkeys key [key...]
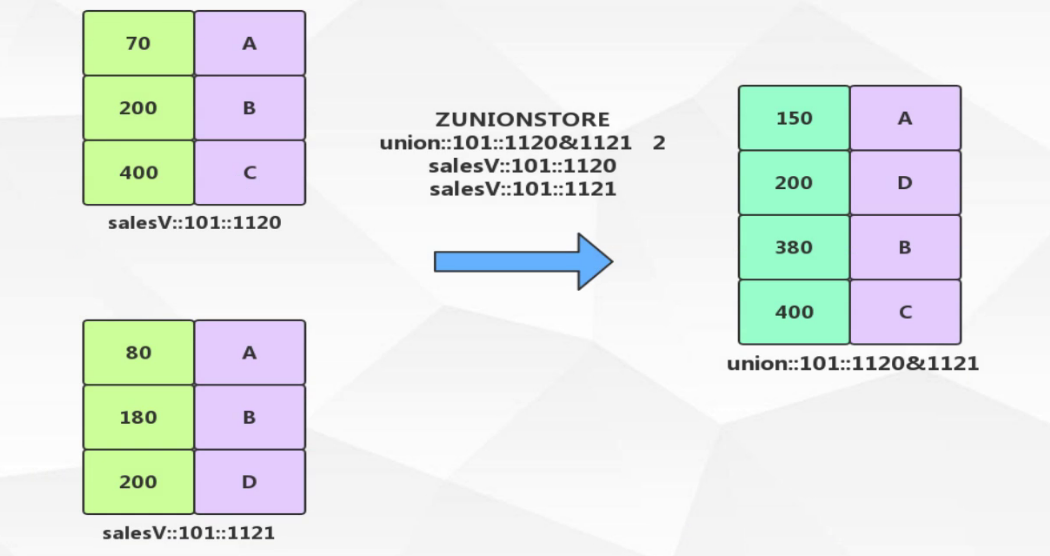
1.2.5.1. ZUNIONSTORE 并集运算
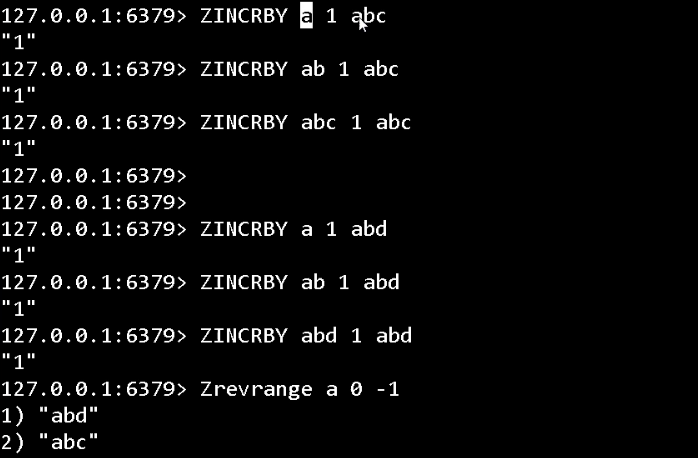
1.2.5.2. 基于有序集合键,实现自动补齐功能
1.2.5.3. 基于有序集合(Zset)键,实现单日排行榜

Redis数据结构以及应用场景的更多相关文章
- Redis数据结构和使用场景,redis内存淘汰策略
什么样的数据适合放入Redis? sql执行耗时特别久,且结果不频繁变动的数据,适合放入Redis. Redis是单线程的,为什么会这么快? 纯内存操作 单线程操作,避免频繁的上下文切换 采用了非阻塞 ...
- redis 数据结构及应用场景
1. String 常用命令: get.set.incr.decr.mget等 应用场景: String是最常用的数据类型,普通的key/value都可以归为此类,value其实不仅是String,也 ...
- Redis中5种数据结构的使用场景介绍
转载于:http://www.itxuexiwang.com/a/shujukujishu/redis/2016/0216/108.html?1455861435 一.redis 数据结构使用场景 原 ...
- Redis 数据结构使用场景
转自http://get.ftqq.com/523.get 一.redis 数据结构使用场景 原来看过 redisbook 这本书,对 redis 的基本功能都已经熟悉了,从上周开始看 redis 的 ...
- Redis中5种数据结构的使用场景
一.redis 数据结构使用场景 原来看过 redisbook 这本书,对 redis 的基本功能都已经熟悉了,从上周开始看 redis 的源码.目前目标是吃透 redis 的数据结构.我们都知道,在 ...
- 细说Redis(一)之 Redis的数据结构与应用场景
这一篇文章主要介绍Redis的数据结构与应用场景 NOSQL之Redis Redis是一款由key-value存储的软件.说起NOSQL,有文档型.键值型.列型存储.图形数据库.其中,在简单的读写性能 ...
- Redis 中 5 种数据结构的使用场景介绍
这篇文章主要介绍了Redis中5种数据结构的使用场景介绍,本文对Redis中的5种数据类型String.Hash.List.Set.Sorted Set做了讲解,需要的朋友可以参考下 一.redis ...
- redis的5种数据结构的使用场景介绍
一.redis 数据结构使用场景 原来看过 redisbook 这本书,对 redis 的基本功能都已经熟悉了,从上周开始看 redis 的源码.目前目标是吃透 redis 的数据结构.我们都知道,在 ...
- Redis学习笔记之Redis中5种数据结构的使用场景介绍
原来看过 redisbook 这本书,对 redis 的基本功能都已经熟悉了,从上周开始看 redis 的源码.目前目标是吃透 redis 的数据结构.我们都知道,在 redis 中一共有5种数据结构 ...
随机推荐
- 网址导航19A
[导航] KIM主页 265导航 好866 [名站] 百度 网易 腾讯 新华 中新 凤凰 [新闻] 联合早报 南方周末 澎湃新闻 [系统] 宋永志 蒲公英 技术员 装机网 系统之家 [软件] 星愿 ...
- Scrapy运行ImportError: No module named win32api错误
windows系统上出现这个问题的解决需要安装Py32Win模块,更方便的做法是: pip install pypiwin32
- buffer IO和direct IO
最近在看很多框架,redis,kafka等底层都涉及到文件IO操作的效率问题,所以查了些资料,看到这篇文章讲的比较明白些,贴出来留存. 链接地址: https://www.ibm.com/develo ...
- laravel-debugbar安装
第一步:找到debugbar扩展包 扩展包的链接:https://packagist.org/packages/barryvdh/laravel-debugbar 第二步:安装 我测试的环境larav ...
- [html]CSS中的margin、border、padding区别
图解CSS padding.margin.border属性W3C组织建议把所有网页上的对像都放在一个盒(box)中,设计师可以通过创建定义来控制这个盒的属性,这些对像包括段落.列表.标题.图片以及层. ...
- win10传奇手册CHM打开无法阅读解决
今天在阅读传奇的帮助文档时候,突然遇到了一个问题.打开为空白. 如图所示 我这个情况打开的时候会提示 这个时候我们把 打开此文件总是询问 这个对勾 去掉 惊喜有没有. 哈哈 .有问题欢迎大家私信我!
- 使用kbmmw中的随机数替换delphi 10.3 自带的随机数
我们在开发中经常会使用随机数模拟各种随机条件,例如生成唯一的密码和令牌. 在计算机中,一般采用PRNG(伪随机序列发生器)模拟真实随机数.既然是随机,就要要没有任何规律, 在取值范围内均匀.独立.以确 ...
- JS-MD5加密
首先,下载MD5文件压缩包 点击下载MD5压缩包 然后,在需要加密的页面引用MD5脚本文件 <script src="js/md5.js" type="text/j ...
- 走进JDK(十一)------LinkedHashMap
概述LinkedHashMap 继承自 HashMap,在 HashMap 基础上,通过维护一条双向链表,解决了 HashMap 不能随时保持遍历顺序和插入顺序一致的问题.除此之外,LinkedHas ...
- JAVA 8 主要新特性 ----------------(五)Lambda方法引用与构造器引用
一.Lambda方法引用 当要传递给Lambda体的操作,已经有实现的方法了,可以使用方法引用!(实现抽象方法的参数列表,必须与方法引用方法的参数列表保持一致!) 方法引用: 使用操作符 “::” 将 ...