Hive中笔记 :三种去重方法,distinct,group by与ROW_Number()窗口函数
一、distinct,group by与ROW_Number()窗口函数使用方法
1. Distinct用法:对select 后面所有字段去重,并不能只对一列去重。
(1)当distinct应用到多个字段的时候,distinct必须放在开头,其应用的范围是其后面的所有字段,而不只是紧挨着它的一个字段,而且distinct只能放到所有字段的前面
(2)distinct对NULL是不进行过滤的,即返回的结果中是包含NULL值的
(3)聚合函数中的DISTINCT,如 COUNT( ) 会过滤掉为NULL 的项
2.group by用法:对group by 后面所有字段去重,并不能只对一列去重。
3. ROW_Number() over()窗口函数
注意:ROW_Number() over (partition by id order by time DESC) 给每个id加一列按时间倒叙的rank值,取rank=1
select m.id,m.gender,m.age,m.rank
from (select id,gender,age,ROW_Number() over(partition by id order by id) rank
from temp.control_201804to201806
where id!='NA' and gender!='' or age!=''
) m
where m.rank=1
二、案例:
1.表中有两列:id ,superid,按照superid倒序排序选出前100条不同的id,如下:
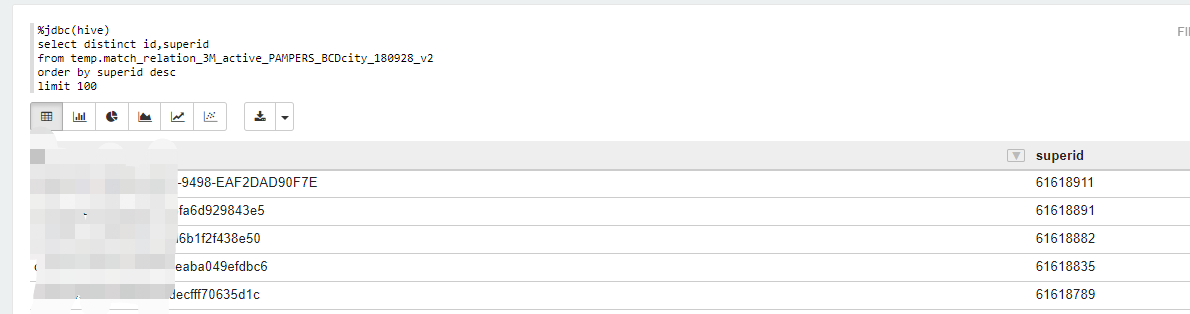
1.方案一:
子查询中对id,superid同时去重,可能存在一个id对应的superid不同,id这一列有重复的id,但 是结果只需要一列不同的id,如果时不限制数量,则可以选择这种方法
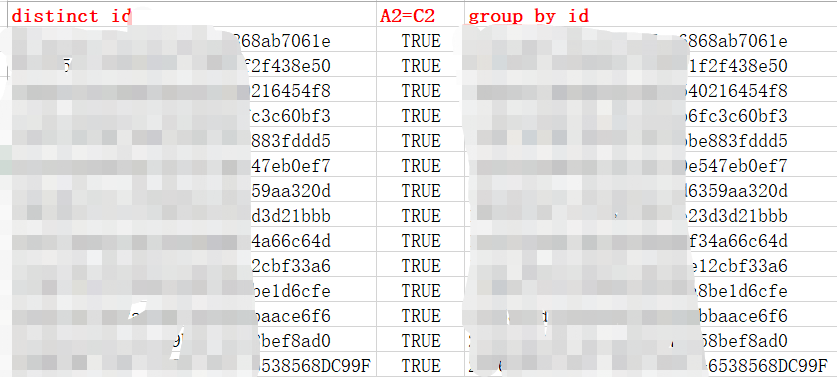
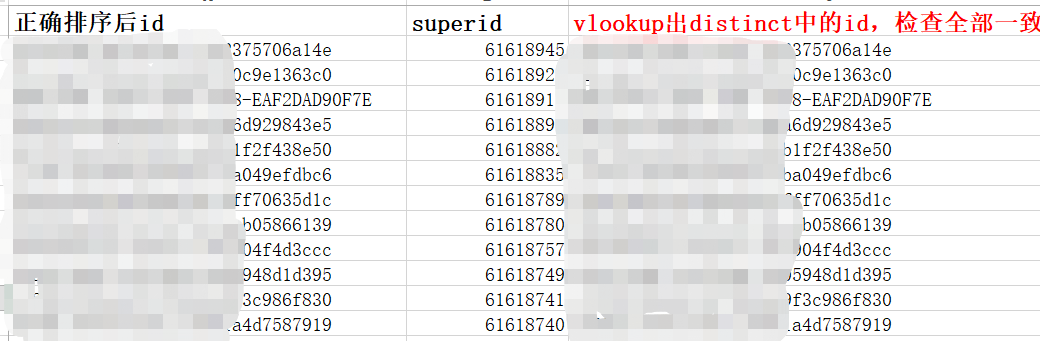
方案二:
因为要求按照superid倒序排序选出,而一个id对应的superid不同,必有大有小,选出最大的那一个,即可。 同理若是按照superid正序排列,可以选出最小的一列
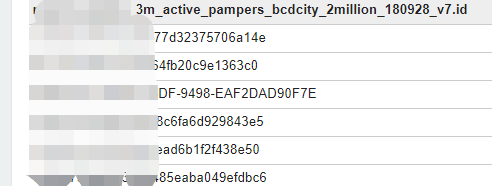
方案三:
首先利用窗口函数ROW_Number() over()窗口函数对id这一列去重,不能用distinct或者group by对id,superid同时去重

Hive中笔记 :三种去重方法,distinct,group by与ROW_Number()窗口函数的更多相关文章
- 061 hive中的三种join与数据倾斜
一:hive中的三种join 1.map join 应用场景:小表join大表 一:设置mapjoin的方式: )如果有一张表是小表,小表将自动执行map join. 默认是true. <pro ...
- JS中的五种去重方法
JS中的五种去重方法 第一种方法: 第二种方法: 第三种方法: 第四种方法: 第五种方法:优化遍历数组法 思路:获取没重复的最右一值放入新数组 * 方法的实现代码相当酷炫,* 实现思路:获取没重复的 ...
- SuperDiamond在JAVA项目中的三种应用方法实践总结
SuperDiamond在JAVA项目中的三种应用方法实践总结 1.直接读取如下: @Test public static void test_simple(){ PropertiesConfigur ...
- Hive中的三种不同的数据导出方式介绍
问题导读:1.导出本地文件系统和hdfs文件系统区别是什么?2.带有local命令是指导出本地还是hdfs文件系统?3.hive中,使用的insert与传统数据库insert的区别是什么?4.导出数据 ...
- js oop中的三种继承方法
JS OOP 中的三种继承方法: 很多读者关于js opp的继承比较模糊,本文总结了oop中的三种继承方法,以助于读者进行区分. <继承使用一个子类继承另一个父类,子类可以自动拥有父类的属性和方 ...
- java数组中的三种排序方法中的冒泡排序方法
我记得我大学学java的时候,怎么就是搞不明白这三种排序方法,也一直不会,现在我有发过来学习下这三种方法并记录下来. 首先说说冒泡排序方法:冒泡排序方法就是把数组中的每一个元素进行比较,如果第i个元素 ...
- Hive总结(八)Hive数据导出三种方式
今天我们再谈谈Hive中的三种不同的数据导出方式. 依据导出的地方不一样,将这些方式分为三种: (1).导出到本地文件系统. (2).导出到HDFS中: (3).导出到Hive的还有一个表中. 为了避 ...
- hive 数据导出三种方式
今天我们再谈谈Hive中的三种不同的数据导出方式.根据导出的地方不一样,将这些方式分为三种:(1).导出到本地文件系统:(2).导出到HDFS中:(3).导出到Hive的另一个表中.为了避免单纯的文字 ...
- Jquery中each的三种遍历方法
Jquery中each的三种遍历方法 $.post("urladdr", { "data" : "data" }, function(dat ...
随机推荐
- MongoDB 菜鸟入门“秘籍”
1.MongoDB介绍 1.1 什么是MongoDB ? MongoDB 是由C++语言编写的,是一个基于分布式文件存储的开源数据库系统. 在高负载的情况下,添加更多的节点,可以保证服务器性能. Mo ...
- docker使用ssh远程连接容器(没钱买服务器又不想安装虚拟机患者必备)
突然有需求,需要使用go语言写个ssh终端连接功能,这时候手上又没有服务器,虚拟机也没有,正好使用docker搞起来 docker容器开启sshd服务,模拟服务器 我们知道docker是可以用exec ...
- MySQL高可用之组复制(4):详细分析组复制理论
MySQL组复制系列文章: MySQL组复制大纲 MySQL组复制(1):组复制技术简介 MySQL组复制(2):配置单主模型的组复制 MySQL组复制(3):配置多主模型的组复制 MySQL组复制( ...
- oracle9i的erp数据库无法正常关闭的解决方法。
oracle9i版本的ERP数据库无法正常关闭. 场景描述:oracle9i数据库正常关闭的时候,hang住在一个地方无法正常关闭. 解决思路:查看alert日志,分析问题. [oraprod@erp ...
- 【golang-GUI开发】项目的编译
在上一篇文章里,我们讲到了安装therecipe/qt(https://www.cnblogs.com/apocelipes/p/9296754.html),现在我们来讲讲如何编译使用了thereci ...
- 我的python渗透测试工具之主机嗅探
嗅探工具的主要目标是基于UDP发现目标网络中的存活主机,选择UDP的原因是UDP访问过程开销小. 由于很多的操作系统在处理UDP端口的闭合时都会存在一个共性,我们也正是利用这个共性来开展确定此IP上是 ...
- 分部视图(Partial View)及Html.Partial和Html.Action差异
参考资料: https://www.cnblogs.com/Leon-Hu/p/5575311.html
- Python网络编程Socket之协程
一.服务端 __author__ = "Jent Zhang" import socket import gevent from gevent import monkey monk ...
- ASP.NET Core中使用Graylog记录日志
以下基于.NET Core 2.1 定义GrayLog日志记录中间件: 中间件代码: public class GrayLogMiddleware { private readonly Request ...
- [PHP] 多进程通信-消息队列使用
向消息队列发送数据和获取数据的测试 <?php $key=ftok(__FILE__,'a'); //获取消息队列 $queue=msg_get_queue($key,0666); //发送消息 ...