七、数据提取之JSON与JsonPATH
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,它使得人们很容易的进行阅读和编写。同时也方便了机器进行解析和生成。适用于进行数据交互的场景,比如网站前台与后台之间的数据交互。
JSON和XML的比较可谓不相上下。
Python 2.7中自带了JSON模块,直接import json就可以使用了。
官方文档:http://docs.python.org/library/json.html
Json在线解析网站:http://www.json.cn/#
JSON
json简单说就是javascript中的对象和数组,所以这两种结构就是对象和数组两种结构,通过这两种结构可以表示各种复杂的结构
对象:对象在js中表示为
{ }括起来的内容,数据结构为{ key:value, key:value, ... }的键值对的结构,在面向对象的语言中,key为对象的属性,value为对应的属性值,所以很容易理解,取值方法为 对象.key 获取属性值,这个属性值的类型可以是数字、字符串、数组、对象这几种。数组:数组在js中是中括号
[ ]括起来的内容,数据结构为["Python", "javascript", "C++", ...],取值方式和所有语言中一样,使用索引获取,字段值的类型可以是 数字、字符串、数组、对象几种。
import json
json模块提供了四个功能:dumps、dump、loads、load,用于字符串 和 python数据类型间进行转换。
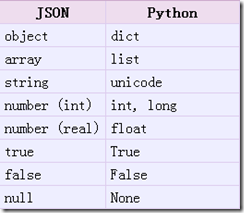
1. json.loads()
把Json格式字符串解码转换成Python对象 从json到python的类型转化对照如下:
# json_loads.py
import json
strList = '[1, 2, 3, 4]'
strDict = '{"city": "北京", "name": "大猫"}'
json.loads(strList)
# [1, 2, 3, 4]
json.loads(strDict) # json数据自动按Unicode存储
# {u'city': u'\u5317\u4eac', u'name': u'\u5927\u732b'}
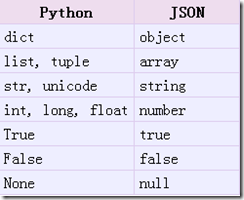
2. json.dumps()
实现python类型转化为json字符串,返回一个str对象 把一个Python对象编码转换成Json字符串
从python原始类型向json类型的转化对照如下:
# json_dumps.py import json
import chardet listStr = [1, 2, 3, 4]
tupleStr = (1, 2, 3, 4)
dictStr = {"city": "北京", "name": "大猫"} json.dumps(listStr)
# '[1, 2, 3, 4]'
json.dumps(tupleStr)
# '[1, 2, 3, 4]' # 注意:json.dumps() 序列化时默认使用的ascii编码
# 添加参数 ensure_ascii=False 禁用ascii编码,按utf-8编码
# chardet.detect()返回字典, 其中confidence是检测精确度 json.dumps(dictStr)
# '{"city": "\\u5317\\u4eac", "name": "\\u5927\\u5218"}' chardet.detect(json.dumps(dictStr))
# {'confidence': 1.0, 'encoding': 'ascii'} print json.dumps(dictStr, ensure_ascii=False)
# {"city": "北京", "name": "大刘"} chardet.detect(json.dumps(dictStr, ensure_ascii=False))
# {'confidence': 0.99, 'encoding': 'utf-8'}
chardet是一个非常优秀的编码识别模块,可通过pip安装
3. json.dump()
将Python内置类型序列化为json对象后写入文件
# json_dump.py
import json
listStr = [{"city": "北京"}, {"name": "大刘"}]
json.dump(listStr, open("listStr.json","w"), ensure_ascii=False)
dictStr = {"city": "北京", "name": "大刘"}
json.dump(dictStr, open("dictStr.json","w"), ensure_ascii=False)
4. json.load()
读取文件中json形式的字符串元素 转化成python类型
# json_load.py
import json
strList = json.load(open("listStr.json"))
print strList
# [{u'city': u'\u5317\u4eac'}, {u'name': u'\u5927\u5218'}]
strDict = json.load(open("dictStr.json"))
print strDict
# {u'city': u'\u5317\u4eac', u'name': u'\u5927\u5218'}
JsonPath
JsonPath 是一种信息抽取类库,是从JSON文档中抽取指定信息的工具,提供多种语言实现版本,包括:Javascript, Python, PHP 和 Java。
JsonPath 对于 JSON 来说,相当于 XPATH 对于 XML。
下载地址:https://pypi.python.org/pypi/jsonpath
安装方法:点击
Download URL链接下载jsonpath,解压之后执行python setup.py install
JsonPath与XPath语法对比:
Json结构清晰,可读性高,复杂度低,非常容易匹配,下表中对应了XPath的用法。
| XPath | JSONPath | 描述 |
|---|---|---|
/ |
$ |
根节点 |
. |
@ |
现行节点 |
/ |
.or[] |
取子节点 |
.. |
n/a | 取父节点,Jsonpath未支持 |
// |
.. |
就是不管位置,选择所有符合条件的条件 |
* |
* |
匹配所有元素节点 |
@ |
n/a | 根据属性访问,Json不支持,因为Json是个Key-value递归结构,不需要。 |
[] |
[] |
迭代器标示(可以在里边做简单的迭代操作,如数组下标,根据内容选值等) |
| | | [,] |
支持迭代器中做多选。 |
[] |
?() |
支持过滤操作. |
| n/a | () |
支持表达式计算 |
() |
n/a | 分组,JsonPath不支持 |
示例:
我们以拉勾网城市JSON文件 http://www.lagou.com/lbs/getAllCitySearchLabels.json 为例,获取所有城市。
# jsonpath_lagou.py import urllib2
import jsonpath
import json
import chardet url = 'http://www.lagou.com/lbs/getAllCitySearchLabels.json'
request =urllib2.Request(url)
response = urllib2.urlopen(request)
html = response.read() # 把json格式字符串转换成python对象
jsonobj = json.loads(html) # 从根节点开始,匹配name节点
citylist = jsonpath.jsonpath(jsonobj,'$..name') print citylist
print type(citylist)
fp = open('city.json','w') content = json.dumps(citylist, ensure_ascii=False)
print content fp.write(content.encode('utf-8'))
fp.close()
注意事项:
json.loads() 是把 Json格式字符串解码转换成Python对象,如果在json.loads的时候出错,要注意被解码的Json字符的编码。
如果传入的字符串的编码不是UTF-8的话,需要指定字符编码的参数 encoding
dataDict = json.loads(jsonStrGBK);
dataJsonStr是JSON字符串,假设其编码本身是非UTF-8的话而是GBK 的,那么上述代码会导致出错,改为对应的:
dataDict = json.loads(jsonStrGBK, encoding="GBK");
如果 dataJsonStr通过encoding指定了合适的编码,但是其中又包含了其他编码的字符,则需要先去将dataJsonStr转换为Unicode,然后再指定编码格式调用json.loads()
``` python
dataJsonStrUni = dataJsonStr.decode("GB2312"); dataDict = json.loads(dataJsonStrUni, encoding="GB2312");
##字符串编码转换 这是中国程序员最苦逼的地方,什么乱码之类的几乎都是由汉字引起的。
其实编码问题很好搞定,只要记住一点: ####任何平台的任何编码 都能和 Unicode 互相转换 UTF-8 与 GBK 互相转换,那就先把UTF-8转换成Unicode,再从Unicode转换成GBK,反之同理。 ``` python
# 这是一个 UTF-8 编码的字符串
utf8Str = "你好地球" # 1. 将 UTF-8 编码的字符串 转换成 Unicode 编码
unicodeStr = utf8Str.decode("UTF-8") # 2. 再将 Unicode 编码格式字符串 转换成 GBK 编码
gbkData = unicodeStr.encode("GBK") # 1. 再将 GBK 编码格式字符串 转化成 Unicode
unicodeStr = gbkData.decode("gbk") # 2. 再将 Unicode 编码格式字符串转换成 UTF-8
utf8Str = unicodeStr.encode("UTF-8")
decode的作用是将其他编码的字符串转换成 Unicode 编码
encode的作用是将 Unicode 编码转换成其他编码的字符串
一句话:UTF-8是对Unicode字符集进行编码的一种编码方式
糗事百科实例:
爬取糗事百科段子,假设页面的URL是 http://www.qiushibaike.com/8hr/page/1
要求:
使用requests获取页面信息,用XPath / re 做数据提取
获取每个帖子里的
用户头像链接、用户姓名、段子内容、点赞次数和评论次数保存到 json 文件内
参考代码
#qiushibaike.py #import urllib
#import re
#import chardet import requests
from lxml import etree page = 1
url = 'http://www.qiushibaike.com/8hr/page/' + str(page)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36',
'Accept-Language': 'zh-CN,zh;q=0.8'} try:
response = requests.get(url, headers=headers)
resHtml = response.text html = etree.HTML(resHtml)
result = html.xpath('//div[contains(@id,"qiushi_tag")]') for site in result:
item = {} imgUrl = site.xpath('./div/a/img/@src')[0].encode('utf-8')
username = site.xpath('./div/a/@title')[0].encode('utf-8')
#username = site.xpath('.//h2')[0].text
content = site.xpath('.//div[@class="content"]/span')[0].text.strip().encode('utf-8')
# 投票次数
vote = site.xpath('.//i')[0].text
#print site.xpath('.//*[@class="number"]')[0].text
# 评论信息
comments = site.xpath('.//i')[1].text print imgUrl, username, content, vote, comments except Exception, e:
print e
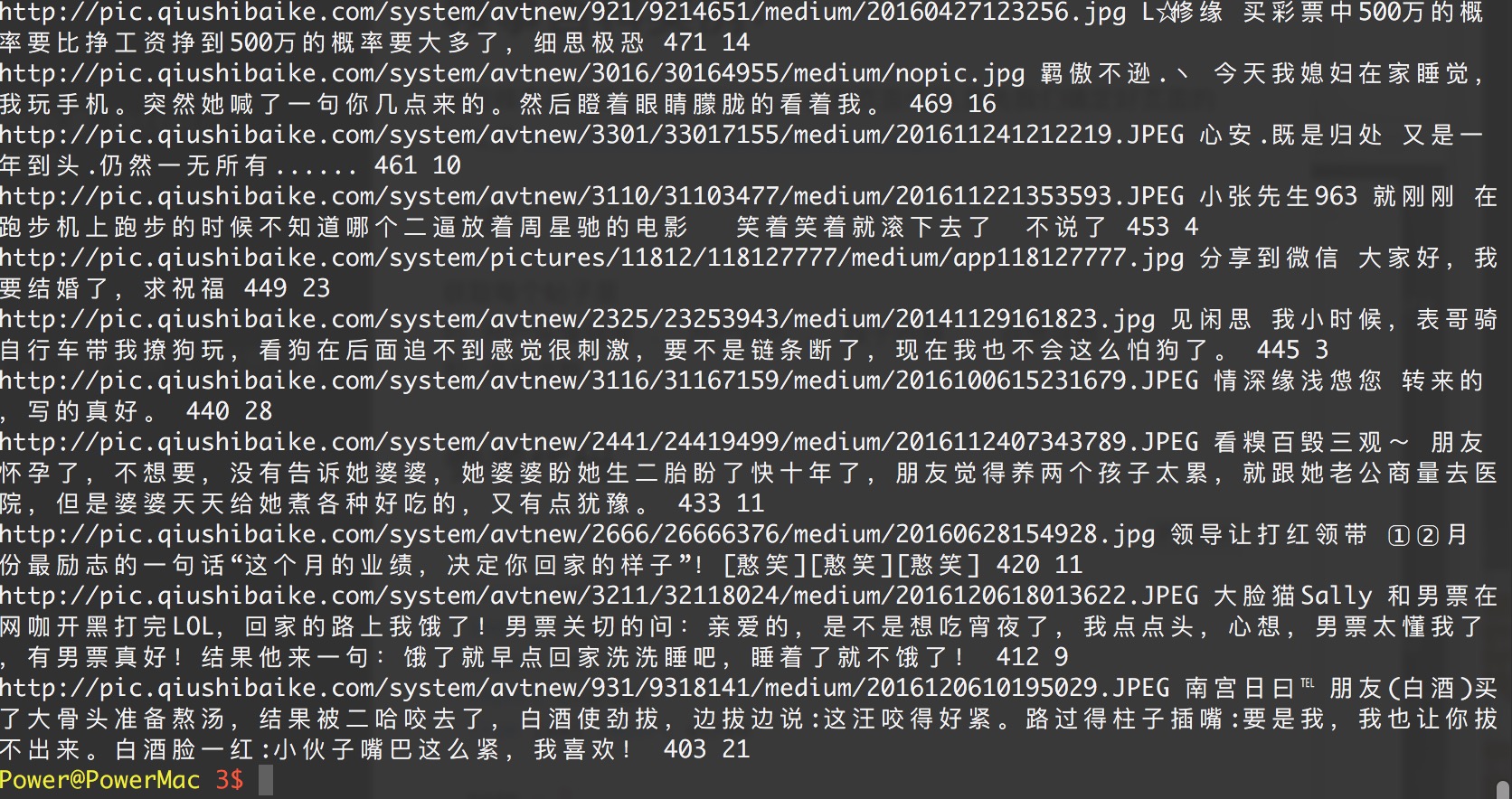
效果
七、数据提取之JSON与JsonPATH的更多相关文章
- 爬虫数据提取之JSON与JsonPATH
数据提取之JSON与JsonPATH JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,它使得人们很容易的进行阅读和编写.同时也方便了机器进行解析和生成.适 ...
- 数据提取之JSON与JsonPATH
数据提取之JSON与JsonPATH JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,它使得人们很容易的进行阅读和编写.同时也方便了机器进行解析和生成.适 ...
- python 数据提取之JSON与JsonPATH
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,它使得人们很容易的进行阅读和编写.同时也方便了机器进行解析和生成.适用于进行数据交互的场景,比如网站前台与 ...
- 9.json和jsonpath
数据提取之JSON与JsonPATH JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,它使得人们很容易的进行阅读和编写.同时也方便了机器进行解析和生成.适 ...
- 【python接口自动化】- 使用json及jsonpath转换和提取数据
前言 JSON(JavaScript Object Notation)是一种轻量级的数据交换格式.它可以让人们很容易的进行阅读和编写,同时也方便了机器进行解析和生成,适用于进行数据交互的场景,比如 ...
- jmeter之断言、数据提取器(正则表达式、jsonpath、beanshell)、聚合报告、参数化
ctx - ( JMeterContext) - gives access to the context vars - ( JMeterVariables) - gives read/write ac ...
- 数据提取--JSON
什么是数据提取? 简单的来说,数据提取就是从响应中获取我们想要的数据的过程 非结构化的数据:html等 结构化数据:json,xml等 处理方法:正则表达式.xpath 处理方法:转化为python数 ...
- JSON数据提取
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,它使得人们很容易的进行阅读和编写.同时也方便了机器进行解析和生成.JSON在数据交换中起到了一个载体的作用 ...
- 爬虫之re数据提取的使用
本文将业务场景中最常用的几点实例,给大家列举出来,不常见的不再一一赘述. 使用urllib库可以模拟浏览器发送请求获得服务器返回的数据,下一步就是把有用的数据提取出来.数据分为两种形式:结构化和非结 ...
随机推荐
- QJsonObject与QString转化封装
经常使用QT的同学可能会发现有时候需要json字符串和json对象之间的转换,今天他来了,直接上代码: QString InfoBase::JsonToString(const QJsonObject ...
- Nginx之HTTPS
Nginx之HTTPS 1. HTTPS安全证书基本概述 为什么需要使用HTTPS,因为HTTP不安全,当我们使用http网站时,会遭到劫持和篡改,如果采用https协议,那么数据在传输过程中是加密的 ...
- Linux—chattr 命令详解
chattr命令的用法:chattr [ -RV ] [ -v version ] [ mode ] files…最关键的是[mode]部分,[mode]部分是由+-=和[ASacDdIijsTtu] ...
- いくnotepad++
再见!Notepad++,好走不送! 1No zuo No Die 上周就发现Notepad++开发者在作妖,新版本放了个啥恶心的标注上来,本来想直接发文说一说,后来想想是不是这样又给它做了宣传,就决 ...
- React 创建一个自动跟新时间的组件
componentDidMount声明周期函数 表示组件渲染完成后 componentWillUnmount声明周期函数 组件将要卸载 通常用于(为了防止内存泄漏 清除定时器) 11==>创建组 ...
- 基于阿里云平台的使用python脚本发送短信
第一步:点击短信服务下的帮助文档 第二步:安装python的SDK:点击安装python sdk 第三步:直接通过python的pip工具安装即可,方便快捷: 第四步:点击红框进行测试: 第五步:测试 ...
- 201871010115-马北《面向对象程序设计(java)》第一周学习总结
博文正文开头格式:(3分) 项目 内容 这个作业属于哪个课程 <https://www.cnblogs.com/nwnu-daizh/> 这个作业的要求在哪里 <https://ww ...
- 爬取沪深a股数据
首先从东方财富网获取股票代码 再从网易财经下载股票历史数据 import requests import random from bs4 import BeautifulSoup as bs impo ...
- 微信小程序开发练习
微信小程序开发工具git管理 https://blog.csdn.net/qq_36672905/article/details/82887102 这个开发工具的界面和交互真的是熟悉又友好,吹爆他
- matlab练习程序(计算图像旋转角度)
比如有图像1,将其旋转n度得到图像2,问如何比较两张图像得到旋转的度数n. 算法思路参考logpolar变换: 1.从图像中心位置向四周引出射线. 2.计算每根射线所打到图像上的像素累计和,得到极坐标 ...