python机器学习——逻辑回归
我们知道感知器算法对于不能完全线性分割的数据是无能为力的,在这一篇将会介绍另一种非常有效的二分类模型——逻辑回归。在分类任务中,它被广泛使用
逻辑回归是一个分类模型,在实现之前我们先介绍几个概念:
几率(odds ratio):
\[
\frac {p}{(1-p)}
\]
其中p表示样本为正例的概率,当然是我们来定义正例是什么,比如我们要预测某种疾病的发生概率,那么我们将患病的样本记为正例,不患病的样本记为负例。为了解释清楚逻辑回归的原理,我们先介绍几个概念。
我们定义对数几率函数(logit function)为:
\[
logit(p) = log \frac {p}{(1-p)}
\]
对数几率函数的自变量p取值范围为0-1,通过函数将其转化到整个实数范围中,我们使用它来定义一个特征值和对数几率之间的线性关系为:
\[
logit(p(y=1|x)) = w_0x_0+w_1x_1+...+w_mx_m = \sum_i^nw_ix_i=w^Tx
\]
在这里,p(y=1|x)是某个样本属于类别1的条件概率。我们关心的是某个样本属于某个类别的概率,刚好是对数几率函数的反函数,我们称这个反函数为逻辑函数(logistics function),有时简写为sigmoid函数:
\[
\phi(z) = \frac{1}{1+e^{-z}}
\]
其中z是权重向量w和输入向量x的线性组合:
\[
z = w^Tx=w_0+w_1x_1+...+w_mx_m
\]
现在我们画出这个函数图像:
import matplotlib.pyplot as pltimport numpy as npdef sigmoid(z):
return 1.0 / (1.0 + np.exp(-z))z = np.arange(-7, 7, 0.1)phi_z = sigmoid(z)plt.plot(z, phi_z)
plt.axvline(0.0, color='k')
plt.axhspan(0.0, 1.0, facecolor='1.0', alpha=1.0, ls='dotted')
plt.yticks([0.0, 0.5, 1.0])
plt.ylim(-0.1, 1.1)
plt.xlabel('z')
plt.ylabel('$\phi (z)$')
plt.show()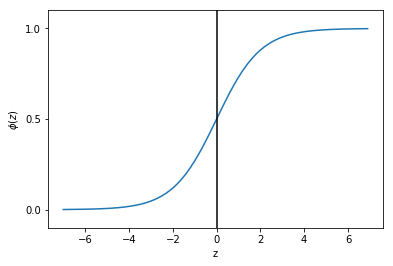
可以看出当z接近于正无穷大时,函数值接近1,同样当z接近于负无穷大时,函数值接近0。所以我们知道sigmoid函数将一个实数输入转化为一个范围为0-1的一个输出。
我们将逻辑函数将我们之前学过的Adaline联系起来,在Adaline中,我们的激活函数的函数值与输入值相同,而在逻辑函数中,激活函数为sigmoid函数。
sigmoid函数的输出被解释为某个样本属于类别1的概率,用公式表示为:
\[
\hat y=\begin{cases}1,\quad \phi(z)\ge 0.5 \\\\0,\quad otherwise\end{cases}
\]
也就是当函数值大于0.5时,表示某个样本属于类别1的概率大于0.5,于是我们就将此样本预测为类别1,否则为类别0。我们仔细观察上面的sigmoid函数图像,上式也等价于:
\[
\hat y=\begin{cases}1,\quad z\ge 0.0 \\\\0,\quad otherwise\end{cases}
\]
逻辑回归的受欢迎之处就在于它可以预测发生某件事的概率,而不是预测这件事情是否发生。
我们已经介绍了逻辑回归如何预测类别概率,接下来我们来看看逻辑回归如何更新权重参数w。
对于Adaline,我们的损失函数为:
\[
J(w) = \sum_i\frac12(\phi(z^{(i)})-y^{(i)})^2
\]
我们通过最小化这个损失函数来更新权重w。为了解释我们如何得到逻辑回归的损失函数,在构建逻辑回归模型时我们要最大化似然L(假设数据集中的所有样本都是互相独立的):
\[
L(w)=P(y|x,w)=\prod^n_{i=1}P(y^{(i)}|x^{(i)};w)=\prod^n_{i=1}(\phi(z^{(i)}))^{y^{(i)}}(1-\phi(z^{(i)}))^{1-y^{(i)}}
\]
通常我们会最大化L的log形式,我们称之为对数似然函数:
\[
l(w)=logL(w)=\sum_{i=1}^n\left[y^{(i)}log(\phi(z^{(i)})+(1-y^{(i)})log(1-\phi(z^{(i)}))\right]
\]
这样做有两个好处,一是当似然很小时,取对数减小了数字下溢的可能性,二是取对数后将乘法转化为了加法,可以更容易的得到函数的导数。现在我们可以使用一个梯度下降法来最大化对数似然函数,我们将上面的对数似然函数转化为求最小值的损失函数J:
\[
J(w)=\sum_{i=1}^n\left[-y^{(i)}log(\phi(z^{(i)}))-(1-y^{(i)})log(1-\phi(z^{(i)}))\right]
\]
为了更清晰的理解上式,我们假设对一个样本计算它的损失函数:
\[
J(\phi(z),y;w)=-ylog(\phi(z))-(1-y)log(1-\phi(z))
\]
可以看出,当y=0时,式子的第一部分为0,当y=1时,式子的第二部分为0,也就是:
\[
J(\phi(z),y;w)=\begin{cases}-log(\phi(z)),\quad if\ y=1 \\\\-log(1-\phi(z)),\quad if \ y=0\end{cases}
\]
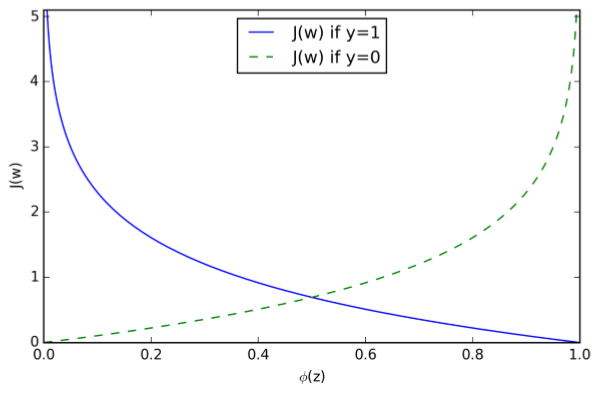
可以看出,当我们预测样本所属于的类别时,当预测类别是样本真实类别的概率越大时,损失越接近0,而当预测类别是真实类别的概率越小时,损失越接近无穷大。
作为举例,我们这里对权重向量w中的一个分量进行更新,首先我们求此分量的偏导数:
\[
\frac{\partial }{\partial w_j}l(w) = \left(y\frac{1}{\phi(z)}-(1-y)\frac{1}{1-\phi(z)}\right)\frac{\partial }{\partial w_j}\phi(z)
\]
在继续下去之前,我们先计算一下sigmoid函数的偏导数:
\[
\frac{\partial }{\partial z}\phi(z) = \frac{\partial }{\partial z}\frac{1}{1+e^{-z}}=\frac{1}{(1+e^{-z})^2}e^{-z}=\frac{1}{1+e^{-z}}(1-\frac{1}{1+e^{-z}})\\=\phi(z)(1-\phi(z))
\]
现在我们继续:
\[
\left(y\frac{1}{\phi(z)}-(1-y)\frac{1}{1-\phi(z)}\right)\frac{\partial }{\partial w_j}\phi(z)\\=\left(y\frac{1}{\phi(z)}-(1-y)\frac{1}{1-\phi(z)}\right)\phi(z)(1-\phi(z))\frac{\partial }{\partial w_j}z\\=\left(y(1-\phi(z))-(1-y)\phi(z)\right)x_j\\=(y-\phi(z))x_j
\]
所以我们的更新规则为:
\[
w_j = w_j + \eta\sum^n_{i=1}\left(y^{(i)}-\phi(z^{(i)})\right)x_j^{(i)}
\]
因为我们要同时更新权重向量w的所有分量,所以我们更新规则为(此处w为向量):
\[
w = w+\Delta w\\\Delta w = \eta\nabla l(w)
\]
因为最大化对数似然函数也就等价于最小化损失函数J,于是梯度下降更新规则为:
\[
\Delta w_j=-\eta\frac{\partial J}{\partial w_j}=\eta\sum^n_{i=1}\left(y^{(i)}-\phi(z^{(i)})\right)x^{(i)}_j\\w=w+\Delta w,\Delta w=-\eta \nabla J(w)
\]
python机器学习——逻辑回归的更多相关文章
- 吴裕雄 python 机器学习——逻辑回归
import numpy as np import matplotlib.pyplot as plt from matplotlib import cm from mpl_toolkits.mplot ...
- python机器学习-逻辑回归
1.逻辑函数 假设数据集有n个独立的特征,x1到xn为样本的n个特征.常规的回归算法的目标是拟合出一个多项式函数,使得预测值与真实值的误差最小: 而我们希望这样的f(x)能够具有很好的逻辑判断性质,最 ...
- 机器学习_线性回归和逻辑回归_案例实战:Python实现逻辑回归与梯度下降策略_项目实战:使用逻辑回归判断信用卡欺诈检测
线性回归: 注:为偏置项,这一项的x的值假设为[1,1,1,1,1....] 注:为使似然函数越大,则需要最小二乘法函数越小越好 线性回归中为什么选用平方和作为误差函数?假设模型结果与测量值 误差满足 ...
- 机器学习---逻辑回归(二)(Machine Learning Logistic Regression II)
在<机器学习---逻辑回归(一)(Machine Learning Logistic Regression I)>一文中,我们讨论了如何用逻辑回归解决二分类问题以及逻辑回归算法的本质.现在 ...
- 机器学习/逻辑回归(logistic regression)/--附python代码
个人分类: 机器学习 本文为吴恩达<机器学习>课程的读书笔记,并用python实现. 前一篇讲了线性回归,这一篇讲逻辑回归,有了上一篇的基础,这一篇的内容会显得比较简单. 逻辑回归(log ...
- 机器学习之使用Python完成逻辑回归
一.任务基础 我们将建立一个逻辑回归模型来预测一个学生是否被大学录取.假设你是一个大学系的管理员,你想根据两次考试的结果来决定每个申请人的录取机会.你有以前的申请人的历史数据,你可以用它作为逻辑回归的 ...
- 机器学习——逻辑回归(Logistic Regression)
1 前言 虽然该机器学习算法名字里面有"回归",但是它其实是个分类算法.取名逻辑回归主要是因为是从线性回归转变而来的. logistic回归,又叫对数几率回归. 2 回归模型 2. ...
- python机器学习《回归 一》
唠嗑唠嗑 依旧是每一次随便讲两句生活小事.表示最近有点懒,可能是快要考试的原因,外加这两天都有笔试和各种面试,让心情变得没那么安静的敲代码,没那么安静的学习算法.搞得第一次和技术总监聊天的时候都不太懂 ...
- 机器学习---逻辑回归(一)(Machine Learning Logistic Regression I)
逻辑回归(Logistic Regression)是一种经典的线性分类算法.逻辑回归虽然叫回归,但是其模型是用来分类的. 让我们先从最简单的二分类问题开始.给定特征向量x=([x1,x2,...,xn ...
随机推荐
- DJango错误日志生成
DJango错误日志生成 setting.py设置 LOGGING = { 'version': 1, 'disable_existing_loggers': False, 'formatters': ...
- HelloWin详解
(注意:遇到程序在弄懂之后一定要自己去敲,一定要自己去敲,一定要自己去敲) (注意:遇到程序在弄懂之后一定要自己去敲,一定要自己去敲,一定要自己去敲) (注意:遇到程序在弄懂之后一定要自己去敲,一定要 ...
- [BZOJ1116] CLO
1116: [POI2008]CLO Time Limit: 10 Sec Memory Limit: 162 MBSubmit: 1311 Solved: 709[Submit][Status] ...
- vue 父组件动态传值至子组件
1.进行数据监听,数据每次变化就初始化一次子组件,进行调取达到传递动态数据的目的普通的监听: watch:{ data: function(newValue,oldValue){ doSomeThin ...
- 全面认识nslookup命令及子命令
- Java11新特性 - 新加一些实用的API
1. 新的本机不可修改集合API 自从Java9开始,JDK里面为集合(List/Set/Map)都添加了of和copyOf方法,他们可以来创建不可变的集合. Question1:什么叫做不可变集合? ...
- Kubernetes2-K8s的集群部署
一.简介 1.架构参考 Kubernetes1-K8s的简单介绍 2.实例架构 192.168.216.51 master etcd 192.168.216.53 node1 192.168.216 ...
- (day27)subprocess模块+粘包问题+struct模块+ UDP协议+socketserver
目录 昨日回顾 软件开发架构 C/S架构 B/S架构 网络编程 互联网协议 socket套接字 今日内容 一.subprocess模块 二.粘包问题 三.struct模块 四.UDP 五.QQ聊天室 ...
- unity 初始化数据存储问题
在用unity进行开发的时初始化的数据和中间实时生成的数据存储不同,初始化文件数据建议安放在asset-StreamingAssets文件下,需要时读取取来.运行时所需的实时文件或数据持久化的xml文 ...
- Python语法入门02
引子 上一篇我们主要了解到了python这门编程语言,今天来说一下关于用户交互,数据类型和运算符方面的学习内容 用户交互 什么是用户交互? 用户交互就是人往计算机里输入数据(input),计算机输出结 ...