Python攻破淘宝网各类反爬手段,采集淘宝网ZDB(女用)的销量!
声明:
由于某些原因,我这里会用手机代替,其实是一样的!
环境:
windows
python3.6.5
模块:
time
selenium
re
环境与模块介绍完毕后,就可以来实行我们的操作了。
第一步:
进入淘宝首页:
driver = webdriver.Chrome()
driver.get('http://www.taobao.com')
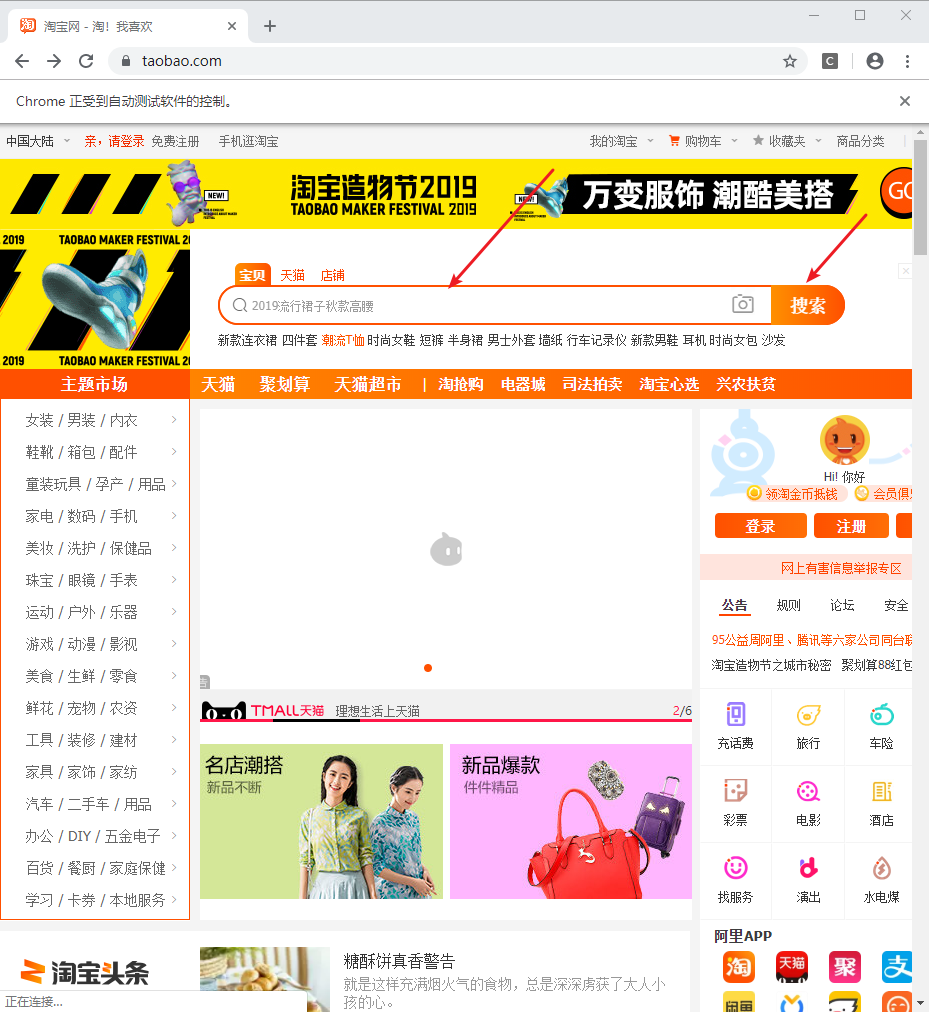
第二步:
- 在输入框中,输入想要查找的商品(keyword),往后用手机代替。
- 点击搜索按钮
driver.find_element_by_id('q').send_keys(keyword)
driver.find_element_by_class_name('btn-search').click()
它会跳转到我们的登陆界面:
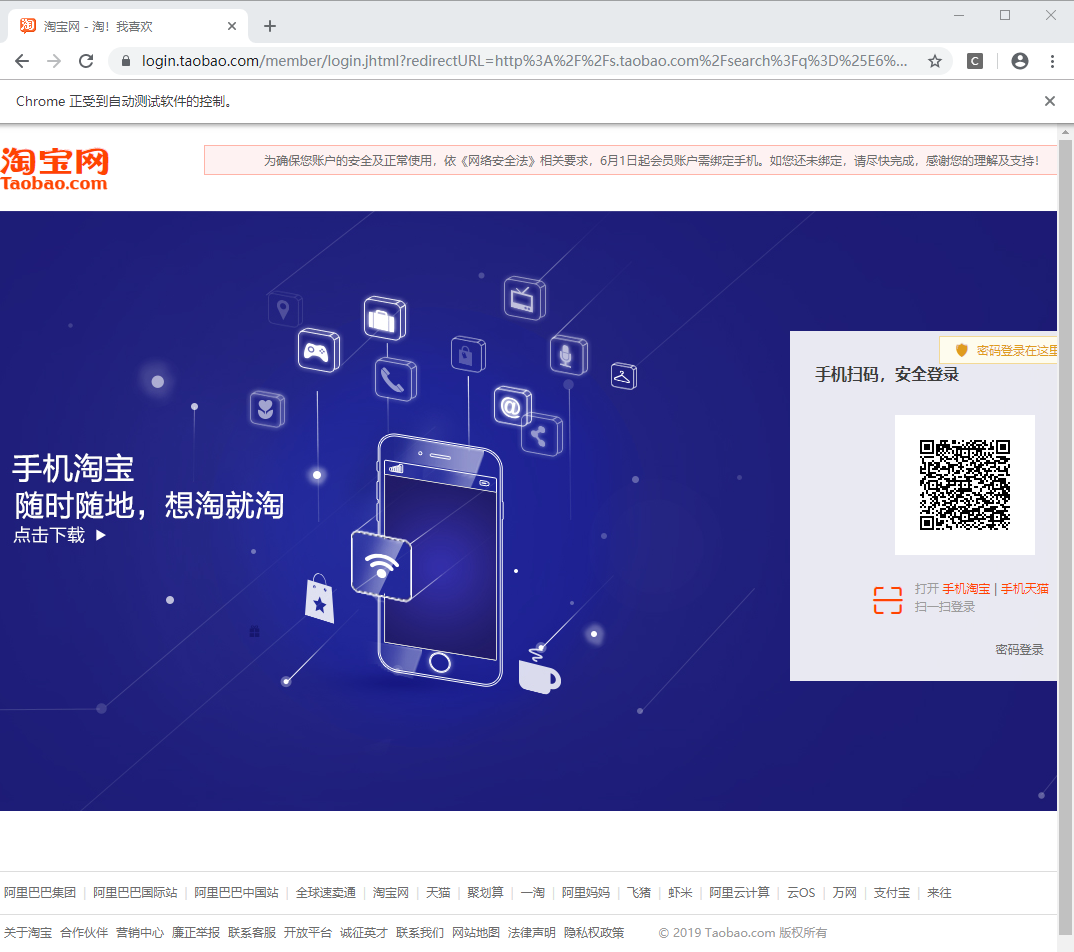
我们选择扫码登陆,那么既然要扫码,肯定就需要等待时间。一般提供10S即可,取决于你单身的年龄
time.sleep(10)
登陆后,我们跳转到了 含有信息的页面:
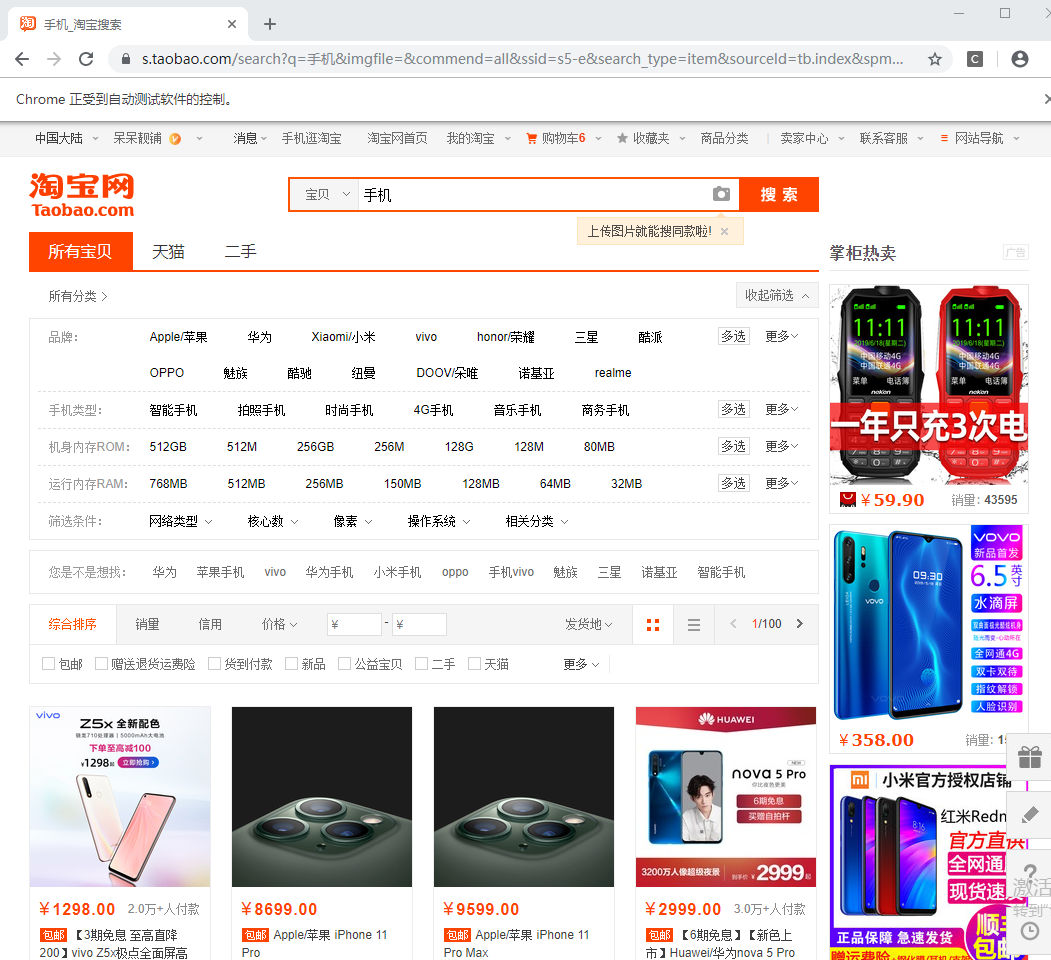
第三步:
提取出我们需要的信息,价格、订单量、商品信息、卖家地址:
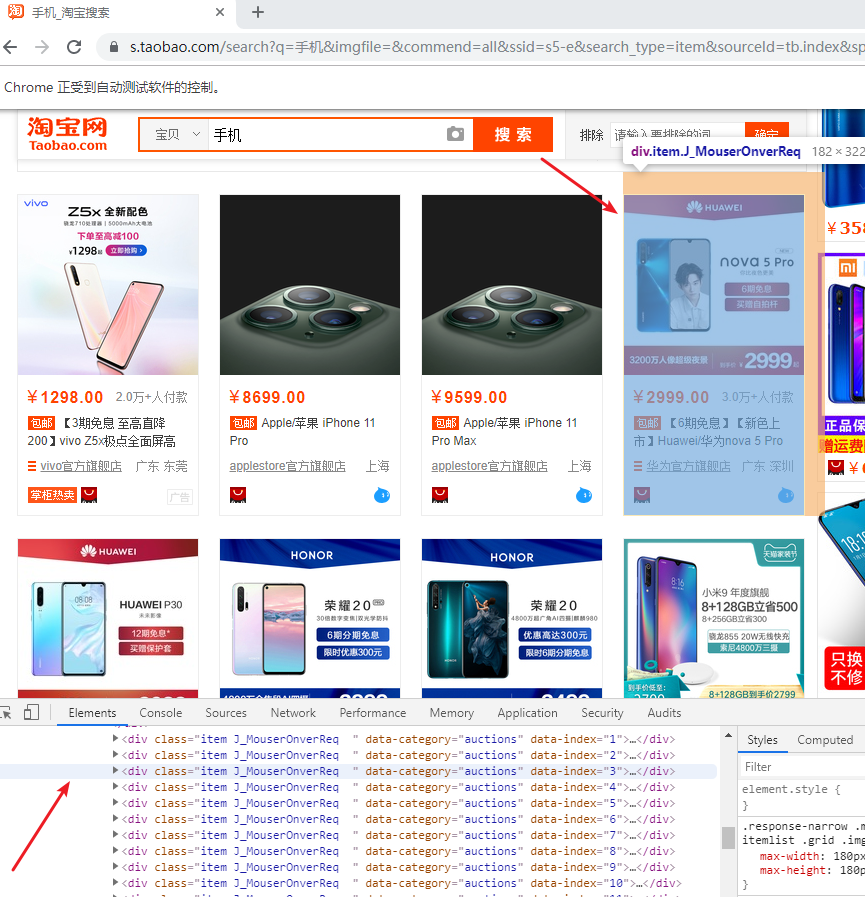
很容易发现我们的商品信息都是包括在了class属性为item J_MouserOnverReq 的div标签当中。
所以可以写出我们的xpath规则:
info = li.find_element_by_xpath('.//div[@class="row row-2 title"]').text
price = li.find_element_by_xpath('.//a[@class="J_ClickStat"]').get_attribute('trace-price') + '元'
deal = li.find_element_by_xpath('.//div[@class="deal-cnt"]').text
name = li.find_element_by_xpath('.//div[@class="shop"]/a/span[2]').text
position = li.find_element_by_xpath('.//div[@class="row row-3 g-clearfix"]/div[@class="location"]').text
第四步:
第一页采集完毕后,我们需要进行翻页操作。
记住,这里千万不要去模拟点击下一页,会被反爬虫策略命中!
我们可以构造url,
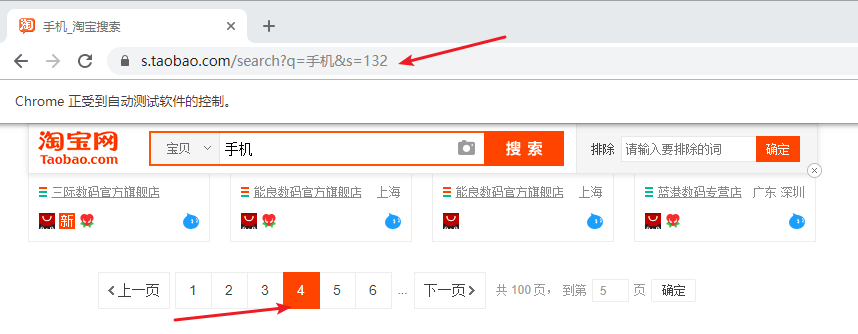
很容易发现我们的url的步长为44,并且总页数为100。那么我们可以先提取出我们的总页数:
token = driver.find_element_by_xpath('//*[@id="mainsrp-pager"]/div/div/div/div[1]')
token = token.text
token = int(re.compile('(\d+)').search(token).group(1))
然后循环构造url:
num = 1
while num != token - 1:
driver.get('https://s.taobao.com/search?q={}&s={}'.format(keyword, 44 * num))
driver.implicitly_wait(10)
drop_down()
get_product()
num += 1
效果:
少儿不宜
好了今天的教程到此结束,希望对你有所帮助!
Python攻破淘宝网各类反爬手段,采集淘宝网ZDB(女用)的销量!的更多相关文章
- k 近邻算法解决字体反爬手段|效果非常好
字体反爬,是一种利用 CSS 特性和浏览器渲染规则实现的反爬虫手段.其高明之处在于,就算借助(Selenium 套件.Puppeteer 和 Splash)等渲染工具也无法拿到真实的文字内容. 这种反 ...
- python之爬虫(十一) 实例爬取上海高级人民法院网开庭公告数据
通过前面的文章已经学习了基本的爬虫知识,通过这个例子进行一下练习,毕竟前面文章的知识点只是一个 一个单独的散知识点,需要通过实际的例子进行融合 分析网站 其实爬虫最重要的是前面的分析网站,只有对要爬取 ...
- python爬虫--爬虫与反爬
爬虫与反爬 爬虫:自动获取网站数据的程序,关键是批量的获取. 反爬虫:使用技术手段防止爬虫程序的方法 误伤:反爬技术将普通用户识别为爬虫,从而限制其访问,如果误伤过高,反爬效果再好也不能使用(例如封i ...
- 关于使用scrapy框架编写爬虫以及Ajax动态加载问题、反爬问题解决方案
Python爬虫总结 总的来说,Python爬虫所做的事情分为两个部分,1:将网页的内容全部抓取下来,2:对抓取到的内容和进行解析,得到我们需要的信息. 目前公认比较好用的爬虫框架为Scrapy,而且 ...
- 常见的反爬措施:UA反爬和Cookie反爬
摘要:为了屏蔽这些垃圾流量,或者为了降低自己服务器压力,避免被爬虫程序影响到正常人类的使用,开发者会研究各种各样的手段,去反爬虫. 本文分享自华为云社区<Python爬虫反爬,你应该从这篇博客开 ...
- python爬虫实例,一小时上手爬取淘宝评论(附代码)
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 1 明确目的 通过访问天猫的网站,先搜索对应的商品,然后爬取它的评论数据. ...
- python高级—— 从趟过的坑中聊聊爬虫、反爬以及、反反爬,附送一套高级爬虫试题
前言: 时隔数月,我终于又更新博客了,然而,在这期间的粉丝数也就跟着我停更博客而涨停了,唉 是的,我改了博客名,不知道为什么要改,就感觉现在这个名字看起来要洋气一点. 那么最近到底咋不更新博客了呢?说 ...
- Python爬虫入门教程 63-100 Python字体反爬之一,没办法,这个必须写,反爬第3篇
背景交代 在反爬圈子的一个大类,涉及的网站其实蛮多的,目前比较常被爬虫coder欺负的网站,猫眼影视,汽车之家,大众点评,58同城,天眼查......还是蛮多的,技术高手千千万,总有五花八门的反爬技术 ...
- Python爬虫反反爬:CSS反爬加密彻底破解!
刚开始搞爬虫的时候听到有人说爬虫是一场攻坚战,听的时候也没感觉到特别,但是经过了一段时间的练习之后,深以为然,每个网站不一样,每次爬取都是重新开始,所以,爬之前谁都不敢说会有什么结果. 前两天,应几个 ...
随机推荐
- Spring框架介绍及使用(转载)
原文链接 Spring框架—控制反转(IOC) 1 Spring框架概述1.1 什么是SpringSpring是一个开源框架,Spring是于2003 年兴起的一个轻量级的Java 开发框架,由Rod ...
- office web apps server安装
1.准备服务器 准备一台windows server 2012 R2服务器,修改计算机名称加入域,如果是通过虚拟机复制导致sid冲突,可以先运行 c:\windows\system32\sysprep ...
- 2019 Multi-University Training Contest 3
B.Blow up the city solved by F0_0H 210min 题意 给一个DAG,每次询问给定u,v,求使得u或v不能与中心点联通的关键点个数 做法 按照拓扑序建树 新加节点的父 ...
- 牛客小白月赛6 B 范围 数学
链接:https://www.nowcoder.com/acm/contest/135/B来源:牛客网 题目描述 已知与均为实数,且满足: 给定A,B,求x的取值范围? 由于Apojacsleam的计 ...
- 牛客小白月赛6 E 对弈 思维
链接:https://www.nowcoder.com/acm/contest/136/E来源:牛客网 题目描述 善弈者谋势,不善弈者谋子. ...
- yzoj P1412 & 洛谷P1629 邮递员送信 题解
有一个邮递员要送东西,邮局在结点1.他总共要送N-1样东西,其目的地分别是2~N.由于这个城市的交通比较繁忙,因此所有的道路都是单行的,共有M条道路,通过每条道路需要一定的时间.这个邮递员每次只能带一 ...
- 【笔记 Jvm-并发】
概述 并发处理 是使得Amadahl定律代替摩尔定律成为计算机性能发展源动力的根本原因: Amdahl定律 通过系统中串行化与并行化的比重来描述多处理器系统所能获得到的运算加速能力: 摩尔定律 描述处 ...
- 利用GPU训练网络时遇到的一些问题
1. OSError: [Error 12] Cannot allocate memory 解决办法: 出现这个错误时我是绝望的...因为我看了别人的解决办法,要加内存条才能解决...但是我不甘心,想 ...
- 使用Spring Boot和RxJava的构建响应式REST API
我不打算解释什么是响应式编程,也不解释为什么要使用它.我希望你已经在其他地方了解过,如果没有,你可以使用Google去搜索它.在本文中,我将告诉您如何使用专门针对Spring Boot和RxJava的 ...
- Cookie与Seesion的作用
1.什么是Cookie与Session? cookie:首次访问服务器,服务器返回cookie置浏览器,存到用户电脑.之后去访问同一服务器,浏览器会携带相应cookie判断是否是同一浏览器的访问,告知 ...