Python网络爬虫实战(五)批量下载B站收藏夹视频
我们除了爬取文本信息,有的时候还需要爬媒体信息,比如视频图片音乐等。就拿B站来说,我的收藏夹内的视频可能随时会失效,所以把它们下载到本地是非常保险的一件事。
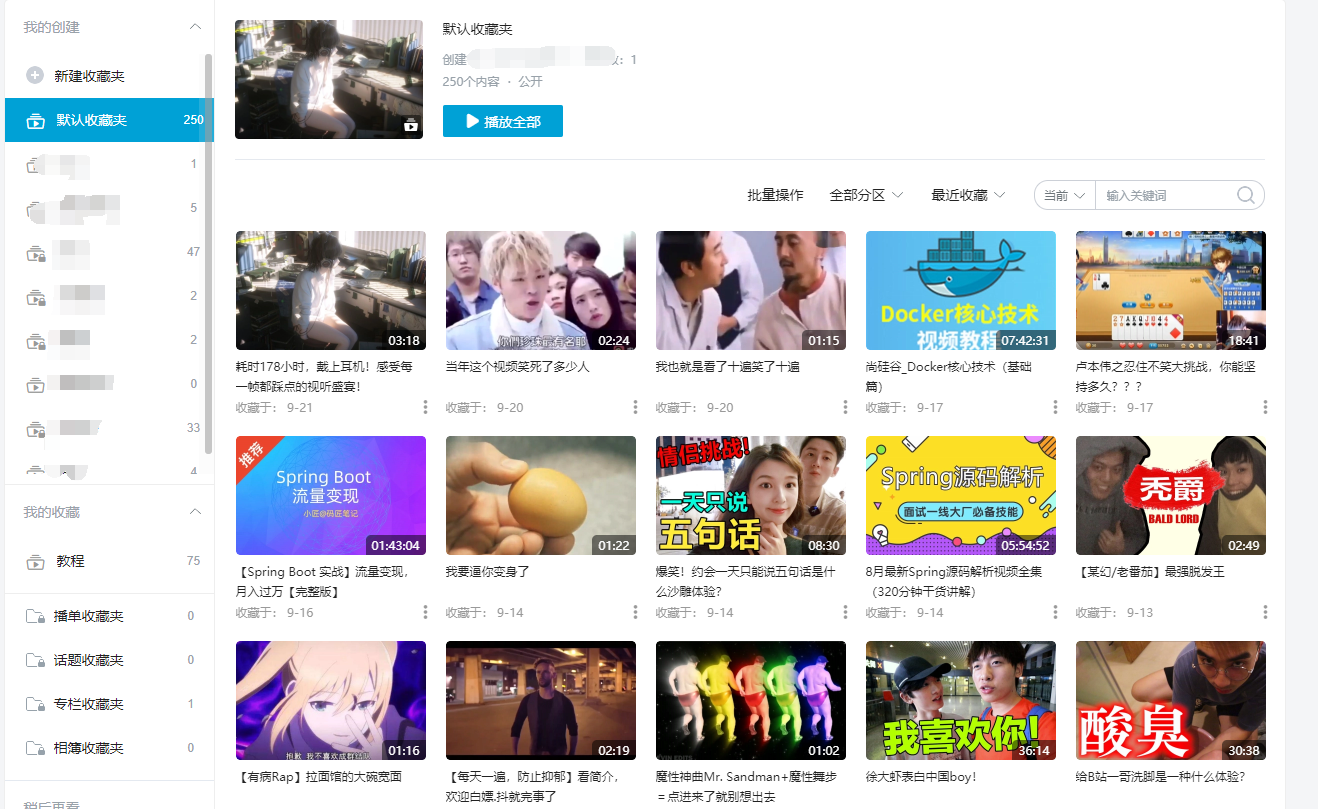
对于这种大量列表型的数据,可以猜测B站收藏夹的请求中,详细的收藏详细可能会是异步加载的,因为这部分数据可能比较庞大。
我们来分析一下网络请求。
可以看到对收藏夹的请求是指定URL加收藏夹的id号,我们爬取的前提是这个收藏夹是公共收藏夹,不然是无法访问的。
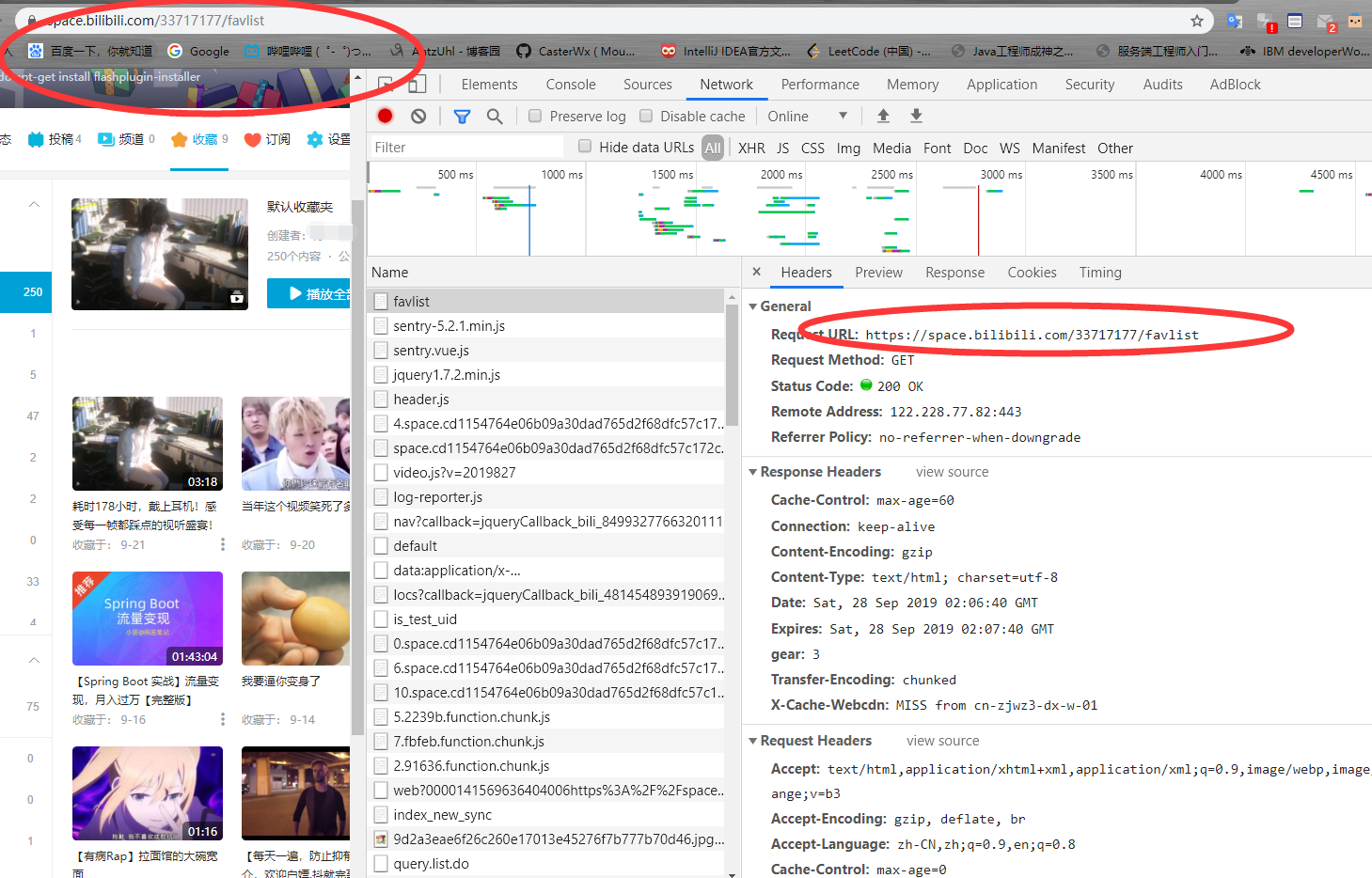
再来看他的返回,明显没有收藏视频的信息,所以可以判断收藏视频的信息是通过api接口异步加载的。
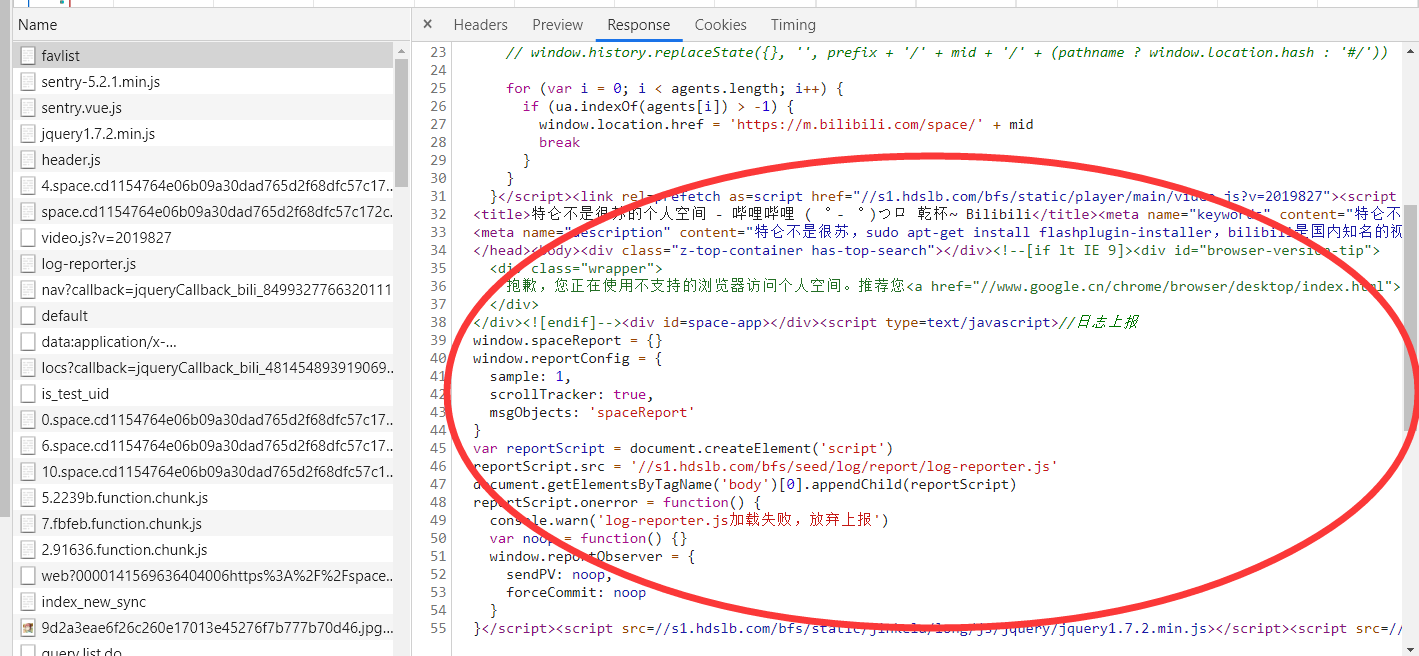
详细查看一下其他的请求,你会发现这样一条。
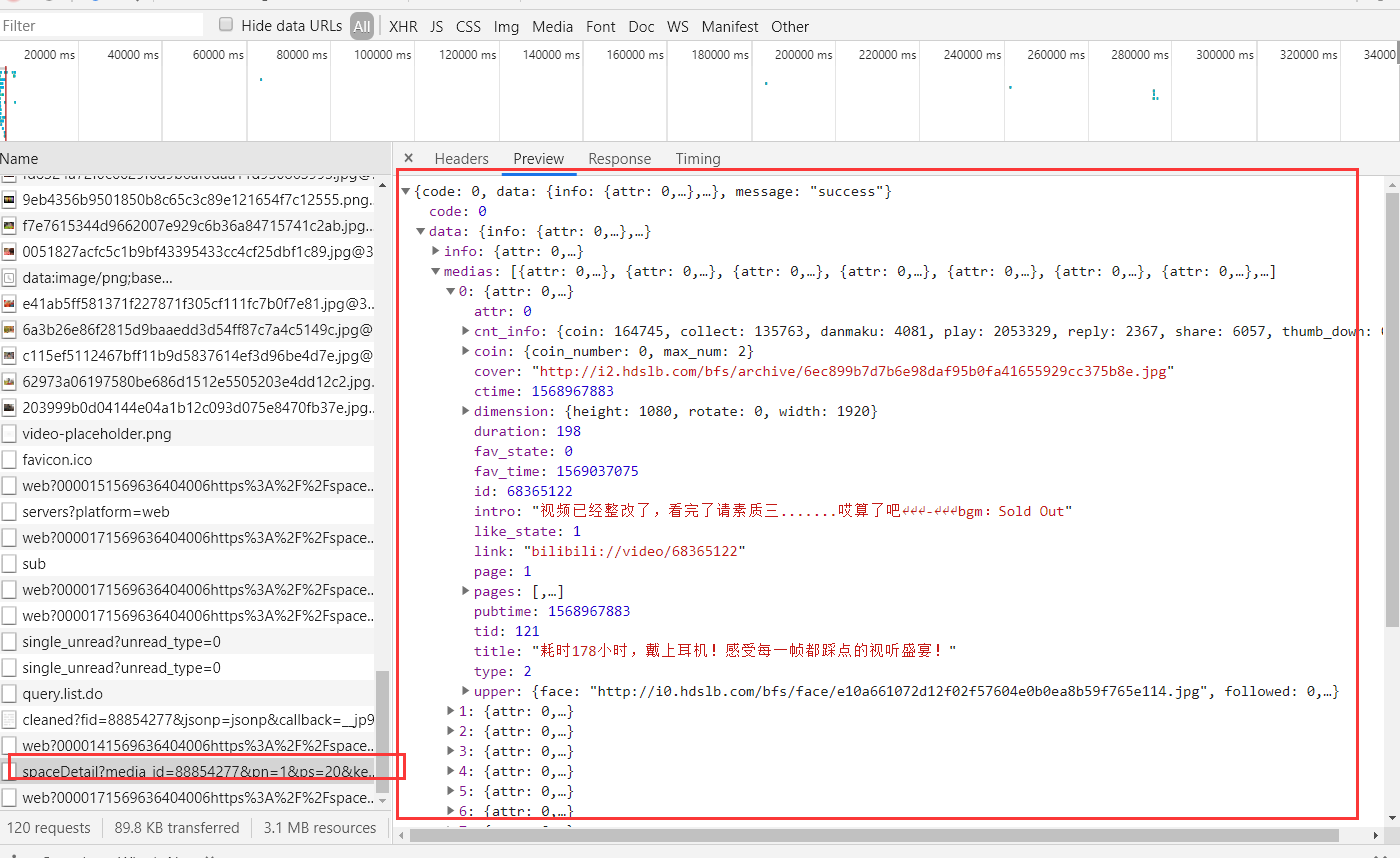
可以看到这里返回了json数据,内容就是我们收藏夹中的视频,但是这里这有20个,再来看请求的URL。

media_id是收藏夹的id号,pn是代表哪一分页,ps是当前分页中视频数量。
那么我们就可以调用这个api来拿到所有收藏的视频了。
我们的视频分页当然不可能只有一页,所以我们可以遍历pn递增。
i = 1
while 1 :
url = 'https://api.bilibili.com/medialist/gateway/base/spaceDetail?media_id=88854277&pn='+ str(i) +'&ps=20&keyword=&order=mtime&type=0&tid=0&jsonp=jsonp'
html = requests.get(url)
i = i + 1
print(html.text)
这样就能拿到一个收藏夹下所有视频了,当i超过收藏夹页数时,直接异常退出即可。
接下来我们需要解析出每一个视频的id。
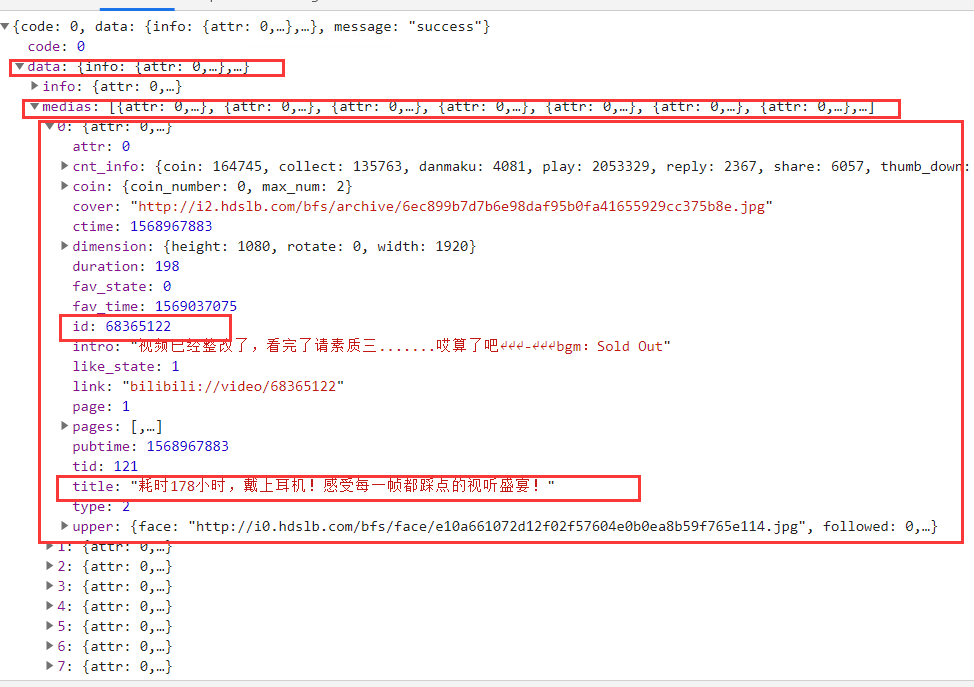
根据之前说的json解析,我们很容易就能用
res['data']['medias']
来获得所有的视频,然后再根据下标解析出每一个视频。
res = json.loads(html.text)
len_video = len(res['data']['medias'])
for id in range(0,len_video):
create_thread(res['data']['medias'][id])
这样我们就可以获取当前页视频数量,然后创建线程进行下载了,因为下载是一个非常占IO的事情,如果你单线程执行,下载一个视频再下载另一个,这样会很慢,我们可以给每一个视频创建一个线程来提高速度。
def create_thread(res):
thread = myThread(res['id'],res['title'],res['id'])
thread.start()
创建线程的线程号是视频的id号,线程名是视频名。
class myThread(threading.Thread): # 继承父类threading.Thread
def __init__(self, threadID, name, counter):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.counter = counter
def run(self):
download_video(self.threadID)
线程类如上,里面有两个函数,__init__是默认的线程初始化函数,里面就是我们创建线程时传入的id和name。第二个函数是线程执行时的run方法,也就是我们定义线程的具体要做的事,里面只有一个download_video方法。
# 下载视频
def download_video(av_id):
os.system('you-get -o d:/vedio/ https://www.bilibili.com/video/av'+str(av_id))
在下载函数中,我们可以调用you-get来帮助我们解析下载视频(不要问为什么调you-get,自己解析太麻烦了)。
这样我们就完成了。
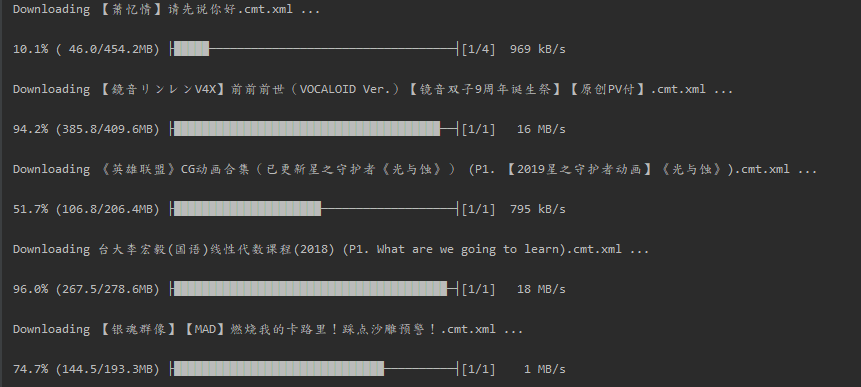
下载完成后:

源码地址: https://github.com/CasterWx/VideoDown
Python网络爬虫实战(五)批量下载B站收藏夹视频的更多相关文章
- Python 网络爬虫实战:爬取 B站《全职高手》20万条评论数据
本周我们的目标是:B站(哔哩哔哩弹幕网 https://www.bilibili.com )视频评论数据. 我们都知道,B站有很多号称“镇站之宝”的视频,拥有着数量极其恐怖的评论和弹幕.所以这次我们的 ...
- 关于Python网络爬虫实战笔记③
Python网络爬虫实战笔记③如何下载韩寒博客文章 Python网络爬虫实战笔记③如何下载韩寒博客文章 target:下载全部的文章 1. 博客列表页面规则 也就是, http://blog.sina ...
- python网络爬虫实战PDF高清完整版免费下载|百度云盘|Python基础教程免费电子书
点击获取提取码:vg1y python网络爬虫实战帮助读者学习Python并开发出符合自己要求的网络爬虫.网络爬虫,又被称为网页蜘蛛,网络机器人,是一种按照一定的规则,自动地抓取互联网信息的程序或者脚 ...
- 关于Python网络爬虫实战笔记①
python网络爬虫项目实战笔记①如何下载韩寒的博客文章 python网络爬虫项目实战笔记①如何下载韩寒的博客文章 1. 打开韩寒博客列表页面 http://blog.sina.com.cn/s/ar ...
- Python网络爬虫实战(一)快速入门
本系列从零开始阐述如何编写Python网络爬虫,以及网络爬虫中容易遇到的问题,比如具有反爬,加密的网站,还有爬虫拿不到数据,以及登录验证等问题,会伴随大量网站的爬虫实战来进行. 我们编写网络爬虫最主要 ...
- python网络爬虫实战之快速入门
本系列从零开始阐述如何编写Python网络爬虫,以及网络爬虫中容易遇到的问题,比如具有反爬,加密的网站,还有爬虫拿不到数据,以及登录验证等问题,会伴随大量网站的爬虫实战来进行. 我们编写网络爬虫最主要 ...
- Python网络爬虫实战:根据天猫胸罩销售数据分析中国女性胸部大小分布
本文实现一个非常有趣的项目,这个项目是关于胸罩销售数据分析的.是网络爬虫和数据分析的综合应用项目.本项目会从天猫抓取胸罩销售数据,并将这些数据保存到SQLite数据库中,然后对数据进行清洗,最后通过S ...
- Python 网络爬虫 006 (编程) 解决下载(或叫:爬取)到的网页乱码问题
解决下载(或叫:爬取)到的网页乱码问题 使用的系统:Windows 10 64位 Python 语言版本:Python 2.7.10 V 使用的编程 Python 的集成开发环境:PyCharm 20 ...
- Python网络爬虫实战入门
一.网络爬虫 网络爬虫(又被称为网页蜘蛛,网络机器人),是一种按照一定的规则,自动地抓取万维网信息的程序. 爬虫的基本流程: 发起请求: 通过HTTP库向目标站点发起请求,也就是发送一个Request ...
随机推荐
- vux-scroller实现移动端上拉加载功能
本文将讲述vue-cli+vux-scroller实现移动端的上拉加载功能: 纠错声明:网上查阅资料看到很多人都将vux和vuex弄混,在这里我们先解释一下,vuex是vue框架自带的组件,是数据状态 ...
- 玩转SpringBoot 2 之项目启动篇
SpringBoot 启动方式有那些? SpringBoot 有4种方式进行启动,具体方式如下: IDEA方式启动 Eclipse 方式启动 Maven 启动方式 通过SpringBoot 程序 ja ...
- 交完论文才发现spss数据分析做错了
上周,终于把毕业论文交给导师了.然而,今天导师却邮件我,叫我到他办公室谈谈.具体是谈什么呢?我百思不得其解:对论文几次大修小修后,重复率已经低于学校的上限了,论文结构也很完整,我已经在做答辩的ppt了 ...
- java程序员学习路线阶段总结20190903
算法:锻炼写代码的逻辑 刷题位置:leetcode 书籍:小灰漫画算法 leecode使用方法: 转载自http://blog.csdn.net/tostq 又到了一年毕业就业季了,三年前的校招季我逃 ...
- 问题.spring源码转换为eclipse遇到的问题
1.下载spring源码 2.下载安装gradle,配置环境变量 3.在spring子项目下执行命令:gradle cleanidea eclipse,会生成对应的.project及.classpat ...
- 2019 ICPC南京网络预选赛 I Washing clothes 李超线段树
题意:有n个人,每个人有一件衣服需要洗,可以自己手洗花费t时间,也可以用洗衣机洗,但是洗衣机只有一台,即每个时刻最多只能有·一个人用洗衣机洗衣服.现在给你每个人最早可以开始洗衣服的时间,问当洗衣机的洗 ...
- CM & CDH 基本概念
什么是 CDH Hadoop 是开源项目,所以很多公司在这个基础上进行商业化,不收费的 Hadoop 主要有三个: Apache,最原始的版本,所有发行版均基于这个版本进行 Cloudear,全称 C ...
- SpringBoot + JPA问题汇总
实体类有继承父类,但父类没有单独标明注解 异常表现 Caused by: org.hibernate.AnnotationException: No identifier specified for ...
- Android如何管理sqlite
Android中使用SQlite进行数据操作 标签: sqliteandroid数据库sqlintegerstring 2012-02-28 14:21 8339人阅读 评论(2) 举报 分类: a ...
- 纯css制作电闪雷鸣的天气图标
效果 效果图如下 实现思路 使用box-shadow属性写几个圆,将这些圆错落的组合在一起,形成云朵图案 after伪元素写下面的投影样式 before伪元素写黄色闪电的样式 dom结构 用两个嵌 ...