Python网络爬虫实战(五)批量下载B站收藏夹视频
我们除了爬取文本信息,有的时候还需要爬媒体信息,比如视频图片音乐等。就拿B站来说,我的收藏夹内的视频可能随时会失效,所以把它们下载到本地是非常保险的一件事。
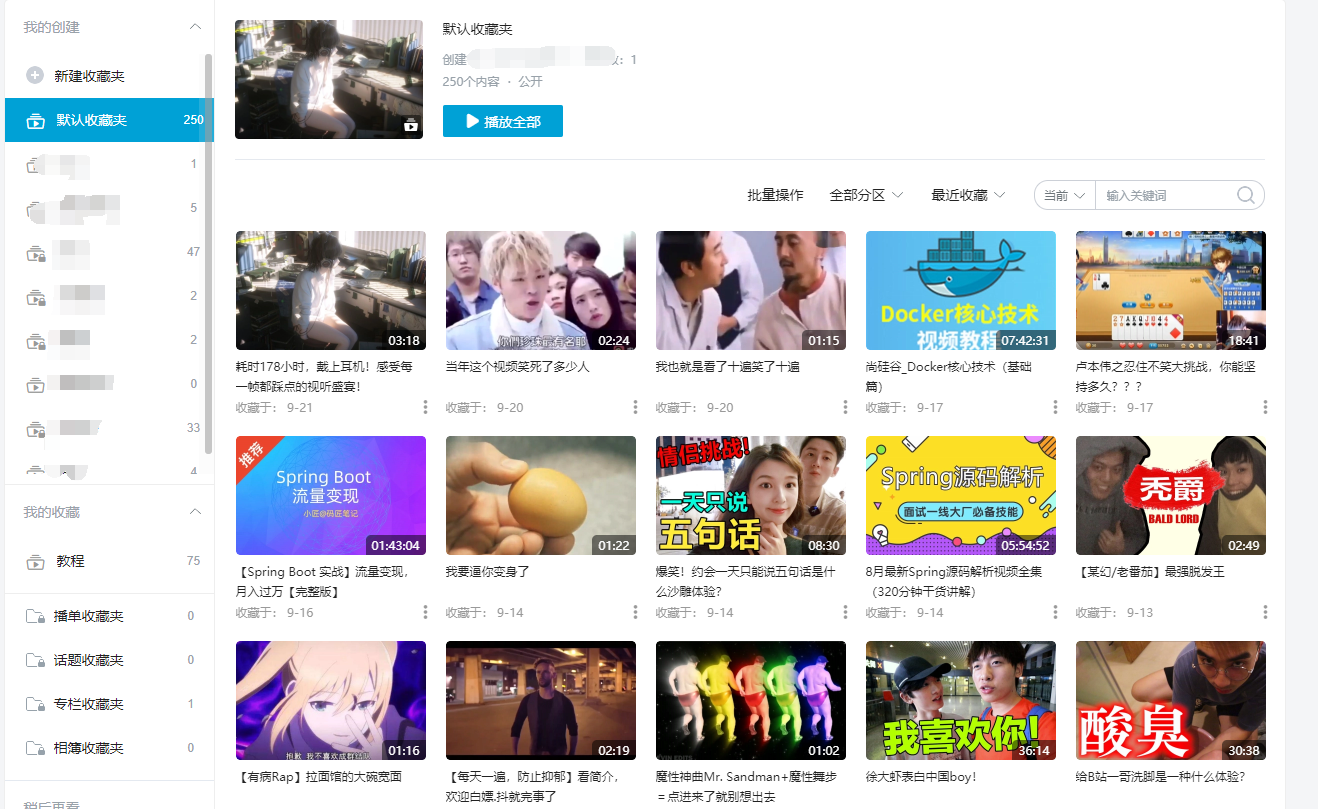
对于这种大量列表型的数据,可以猜测B站收藏夹的请求中,详细的收藏详细可能会是异步加载的,因为这部分数据可能比较庞大。
我们来分析一下网络请求。
可以看到对收藏夹的请求是指定URL加收藏夹的id号,我们爬取的前提是这个收藏夹是公共收藏夹,不然是无法访问的。
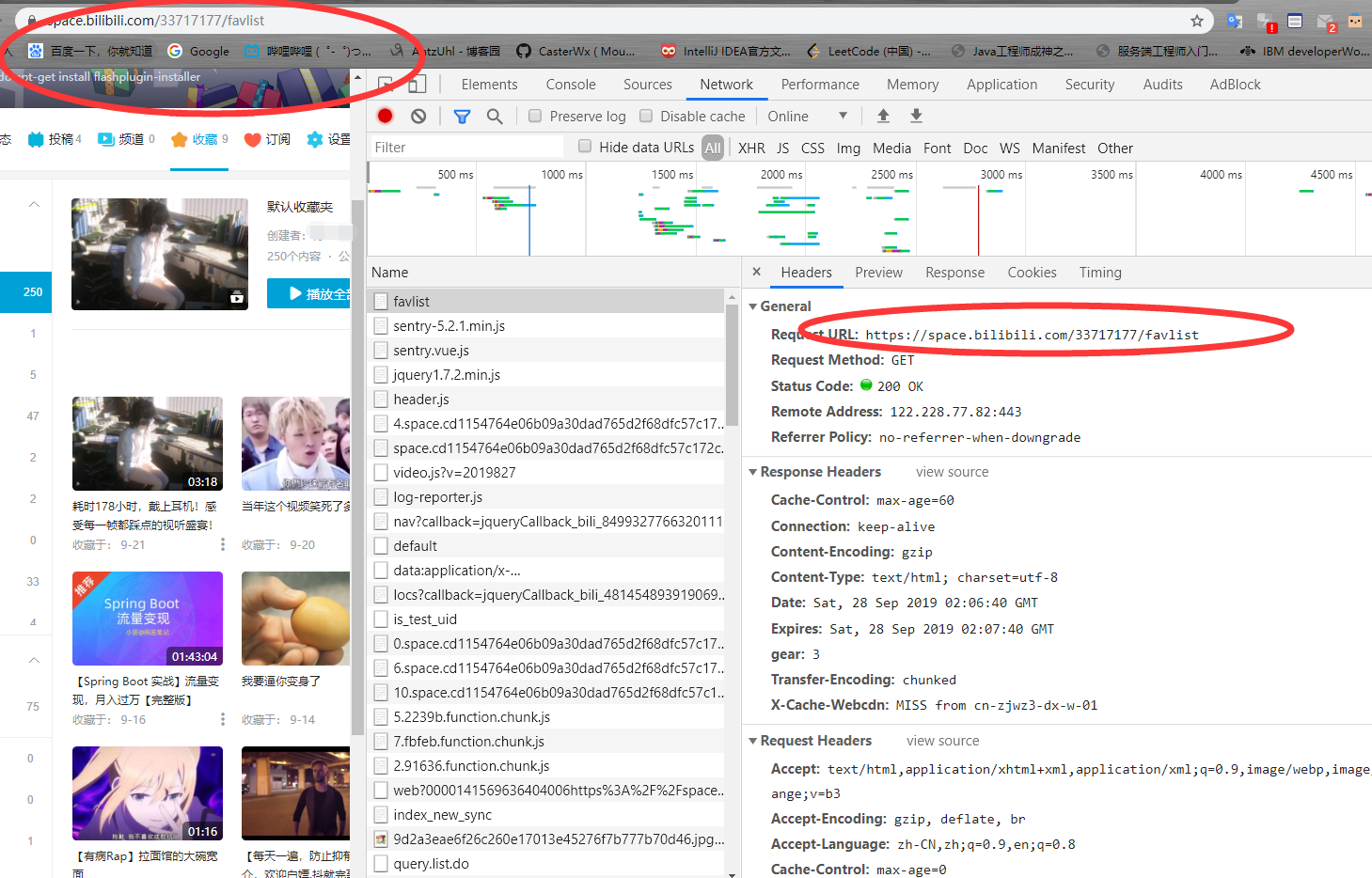
再来看他的返回,明显没有收藏视频的信息,所以可以判断收藏视频的信息是通过api接口异步加载的。
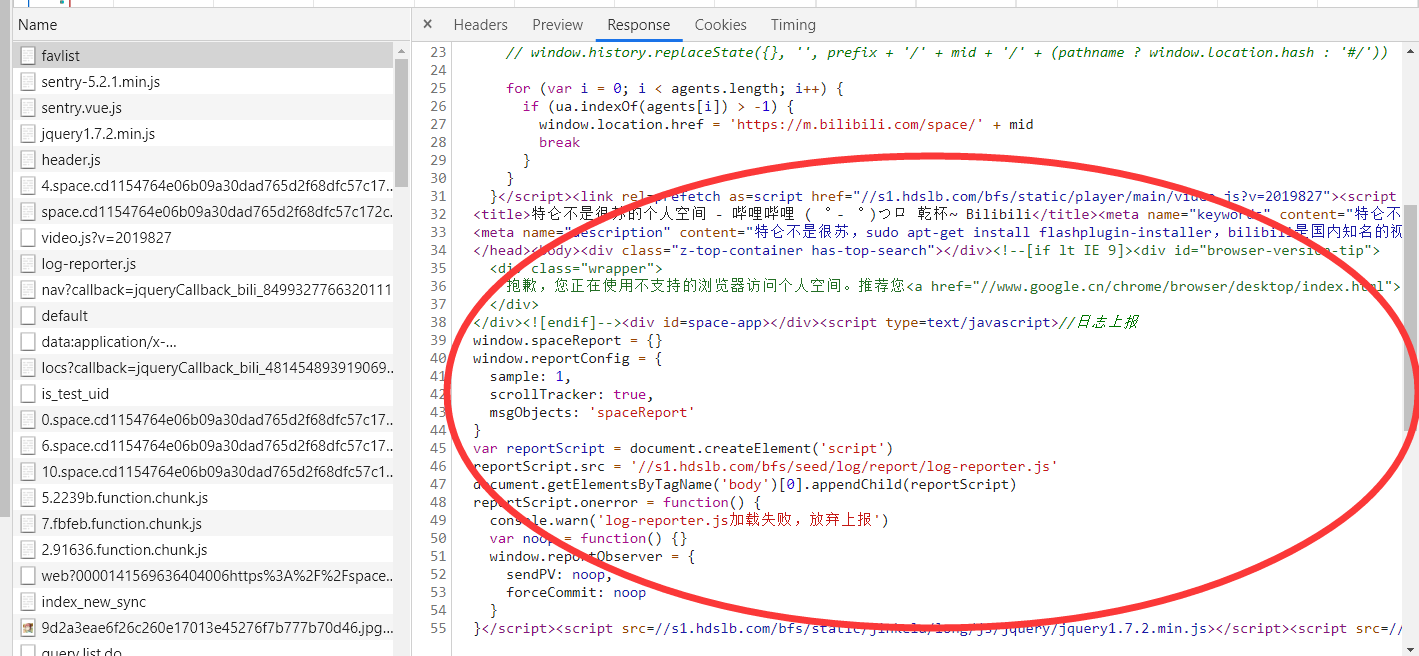
详细查看一下其他的请求,你会发现这样一条。
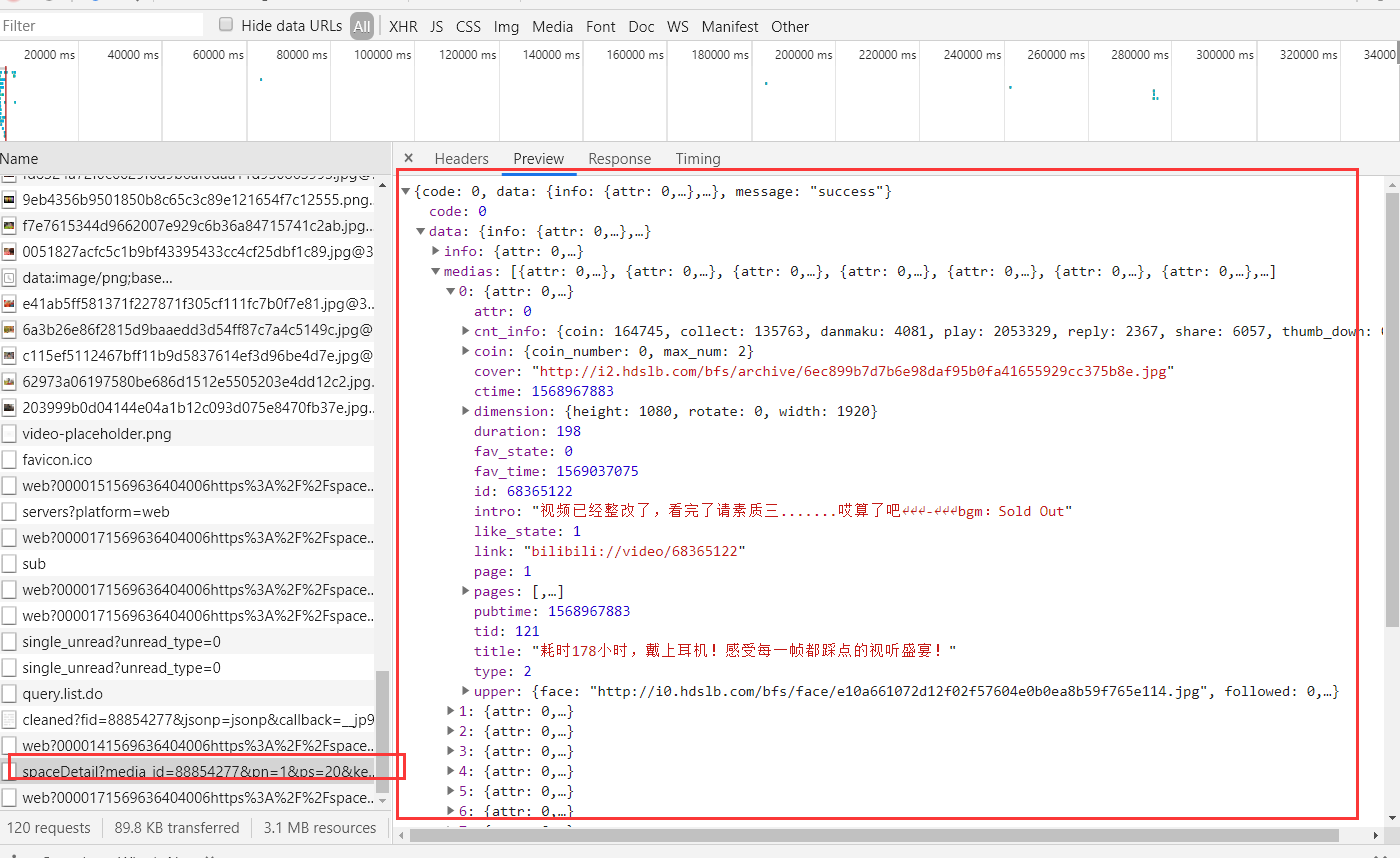
可以看到这里返回了json数据,内容就是我们收藏夹中的视频,但是这里这有20个,再来看请求的URL。

media_id是收藏夹的id号,pn是代表哪一分页,ps是当前分页中视频数量。
那么我们就可以调用这个api来拿到所有收藏的视频了。
我们的视频分页当然不可能只有一页,所以我们可以遍历pn递增。
i = 1
while 1 :
url = 'https://api.bilibili.com/medialist/gateway/base/spaceDetail?media_id=88854277&pn='+ str(i) +'&ps=20&keyword=&order=mtime&type=0&tid=0&jsonp=jsonp'
html = requests.get(url)
i = i + 1
print(html.text)
这样就能拿到一个收藏夹下所有视频了,当i超过收藏夹页数时,直接异常退出即可。
接下来我们需要解析出每一个视频的id。
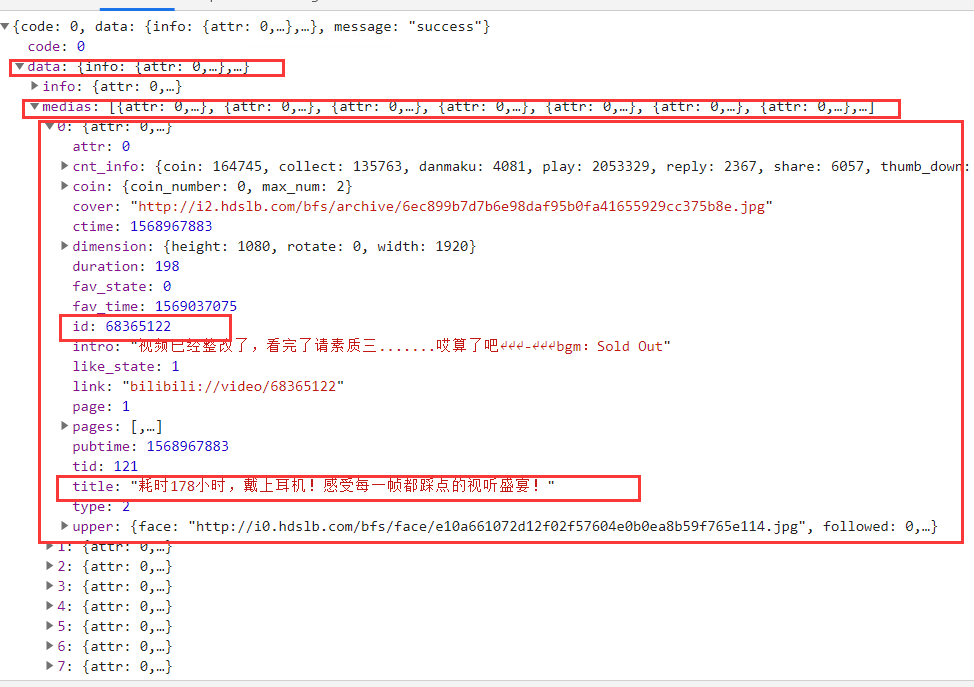
根据之前说的json解析,我们很容易就能用
res['data']['medias']
来获得所有的视频,然后再根据下标解析出每一个视频。
res = json.loads(html.text)
len_video = len(res['data']['medias'])
for id in range(0,len_video):
create_thread(res['data']['medias'][id])
这样我们就可以获取当前页视频数量,然后创建线程进行下载了,因为下载是一个非常占IO的事情,如果你单线程执行,下载一个视频再下载另一个,这样会很慢,我们可以给每一个视频创建一个线程来提高速度。
def create_thread(res):
thread = myThread(res['id'],res['title'],res['id'])
thread.start()
创建线程的线程号是视频的id号,线程名是视频名。
class myThread(threading.Thread): # 继承父类threading.Thread
def __init__(self, threadID, name, counter):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.counter = counter
def run(self):
download_video(self.threadID)
线程类如上,里面有两个函数,__init__是默认的线程初始化函数,里面就是我们创建线程时传入的id和name。第二个函数是线程执行时的run方法,也就是我们定义线程的具体要做的事,里面只有一个download_video方法。
# 下载视频
def download_video(av_id):
os.system('you-get -o d:/vedio/ https://www.bilibili.com/video/av'+str(av_id))
在下载函数中,我们可以调用you-get来帮助我们解析下载视频(不要问为什么调you-get,自己解析太麻烦了)。
这样我们就完成了。
下载完成后:

源码地址: https://github.com/CasterWx/VideoDown
Python网络爬虫实战(五)批量下载B站收藏夹视频的更多相关文章
- Python 网络爬虫实战:爬取 B站《全职高手》20万条评论数据
本周我们的目标是:B站(哔哩哔哩弹幕网 https://www.bilibili.com )视频评论数据. 我们都知道,B站有很多号称“镇站之宝”的视频,拥有着数量极其恐怖的评论和弹幕.所以这次我们的 ...
- 关于Python网络爬虫实战笔记③
Python网络爬虫实战笔记③如何下载韩寒博客文章 Python网络爬虫实战笔记③如何下载韩寒博客文章 target:下载全部的文章 1. 博客列表页面规则 也就是, http://blog.sina ...
- python网络爬虫实战PDF高清完整版免费下载|百度云盘|Python基础教程免费电子书
点击获取提取码:vg1y python网络爬虫实战帮助读者学习Python并开发出符合自己要求的网络爬虫.网络爬虫,又被称为网页蜘蛛,网络机器人,是一种按照一定的规则,自动地抓取互联网信息的程序或者脚 ...
- 关于Python网络爬虫实战笔记①
python网络爬虫项目实战笔记①如何下载韩寒的博客文章 python网络爬虫项目实战笔记①如何下载韩寒的博客文章 1. 打开韩寒博客列表页面 http://blog.sina.com.cn/s/ar ...
- Python网络爬虫实战(一)快速入门
本系列从零开始阐述如何编写Python网络爬虫,以及网络爬虫中容易遇到的问题,比如具有反爬,加密的网站,还有爬虫拿不到数据,以及登录验证等问题,会伴随大量网站的爬虫实战来进行. 我们编写网络爬虫最主要 ...
- python网络爬虫实战之快速入门
本系列从零开始阐述如何编写Python网络爬虫,以及网络爬虫中容易遇到的问题,比如具有反爬,加密的网站,还有爬虫拿不到数据,以及登录验证等问题,会伴随大量网站的爬虫实战来进行. 我们编写网络爬虫最主要 ...
- Python网络爬虫实战:根据天猫胸罩销售数据分析中国女性胸部大小分布
本文实现一个非常有趣的项目,这个项目是关于胸罩销售数据分析的.是网络爬虫和数据分析的综合应用项目.本项目会从天猫抓取胸罩销售数据,并将这些数据保存到SQLite数据库中,然后对数据进行清洗,最后通过S ...
- Python 网络爬虫 006 (编程) 解决下载(或叫:爬取)到的网页乱码问题
解决下载(或叫:爬取)到的网页乱码问题 使用的系统:Windows 10 64位 Python 语言版本:Python 2.7.10 V 使用的编程 Python 的集成开发环境:PyCharm 20 ...
- Python网络爬虫实战入门
一.网络爬虫 网络爬虫(又被称为网页蜘蛛,网络机器人),是一种按照一定的规则,自动地抓取万维网信息的程序. 爬虫的基本流程: 发起请求: 通过HTTP库向目标站点发起请求,也就是发送一个Request ...
随机推荐
- Java虚拟机一看就懂01
Jvm内存结构 --- 线程隔离区域说明: 1.1.程序计数器 线程私有 是一块内存空间 唯一的一个在Java虚拟机规范中没有规定任何OOM情况的区域(不会OOM?) 1.2.Java虚拟机栈 线程私 ...
- 用代码说话:如何在Java中实现线程
并发编程是Java语言的重要特性之一,"如何在Java中实现线程"是学习并发编程的入门知识,也是Java工程师面试必备的基础知识.本文从线程说起,然后用代码说明如何在Java中实现 ...
- from 表单用 GET 方法进行 URL 传值时后台无法获取问题
问题描述 <a href="${pageContext.request.contextPath}/client?method=add">点我</a> < ...
- Spring Boot MyBatis 数据库集群访问实现
Spring Boot MyBatis 数据库集群访问实现 本示例主要介绍了Spring Boot程序方式实现数据库集群访问,读库轮询方式实现负载均衡.阅读本示例前,建议你有AOP编程基础.mybat ...
- Leetcode之深度优先搜索&回溯专题-980. 不同路径 III(Unique Paths III)
Leetcode之深度优先搜索&回溯专题-980. 不同路径 III(Unique Paths III) 深度优先搜索的解题详细介绍,点击 在二维网格 grid 上,有 4 种类型的方格: 1 ...
- 实参&形参
实参VS形参 1.实参 argument 实际参数,在函数调用的时候,传递给函数的参数.实参-按值调用 实际参数可以是变量.常量.表达式以及函数 实际参数必须得有确定的值(赋值.输入等),在函数调用时 ...
- DOM的高级操作-一种JS控制元素的视觉假象
1.运动中的边界处理(让其在一个指定区域内运动) 当元素的offsetLeft值超出一定距离或达到一个我们想要设置的边界值时,停止计时器. var timer; timer = setInterval ...
- Codefroces 939 C Convenient For Everybody
939 C 题意:若干年以后地球会变成n个时区, 为了方便计时, 每个时区的时间从1:00开始到n:00点结束, 现在将要举行一场c赛, 每个时区内都有ai个人参加,并且比赛开始时间不早于当地时间s: ...
- Codeforces Round #479 (Div. 3) B. Two-gram
原题代码:http://codeforces.com/contest/977/problem/B 题解:有n个字符组成的字符串,输出出现次数两个字符组合.例如第二组样例ZZ出现了两次. 方法:比较无脑 ...
- Gym 101482 题解
B:Biking Duck 题意:现在有一个人要从(x1,y1)点走到(x2,y2)点, 现在走路的速度为v. 还有骑自行车的速度v2,自行车要从某个自行车站到另一个自行车站,现在我们可以视地图的边界 ...