[AWS] 01 - What is Amazon EMR
- Amazon Athena 是一种交互式查询服务,让您能够轻松使用标准 SQL 直接分析 Amazon S3 中的数据。
- EMR 解决Hadoop集群部署和管理的难题;
- Amazon CloudSearch 是一款在 AWS 云中托管的服务,可让您简单且经济高效地为网站或应用程序设置、管理或扩展搜索解决方案。
- Elasticsearch Service
- Kinesis 让实时数据的捕捉与分析变得不再困难。
- QuickSight 云BI服务。
- Data Pipeline 使用它安排将输入数据移入 Amazon S3 的时间,以及安排启动集群处理这些数据的时间。
- AWS Glue 一项完全托管的提取、转换和加载 (ETL) 服务,让客户能够轻松加载数据仓库中的数据进行分析。
- AWS Lake Formation 数据湖是一个安全的集中式辅助存储库,它以数据原始形式和可用于分析的形式存储所有数据。
- MSK 完全托管服务,可让您轻松构建并运行使用 Apache Kafka 的应用程序来处理流数据。
常见问题:Can we consider AWS Glue as a replacement for EMR?
了解集群和节点
向集群提交工作
处理数据
启动集群时,您需要选择要安装的框架和应用程序,以满足您的数据处理需求。要处理 Amazon EMR 集群中的数据,您可以直接向已安装的应用程序提交作业或查询,或在集群中运行步骤。
直接向应用程序提交作业
您可以直接向安装在 Amazon EMR 集群中的应用程序提交作业和与之交互。
为此,您通常需要通过安全连接与主节点连接,并访问可用于直接运行在集群上的软件的接口和工具。有关更多信息,请参阅 连接到集群。
运行步骤以处理数据
您可以向 Amazon EMR 集群提交一个或多个有序的步骤。每个步骤都是一个工作单位,其中包含可由集群上安装的软件处理的数据操作指令。
下面是一个使用四个步骤的示例处理操作:
提交要处理的输入数据集。
使用 Pig 程序处理第一个步骤的输出。(是MapReduce的一个抽象;使用 Pig Latin ,程序员可以轻松地执行MapReduce作业,而无需在Java中键入复杂的代码。)
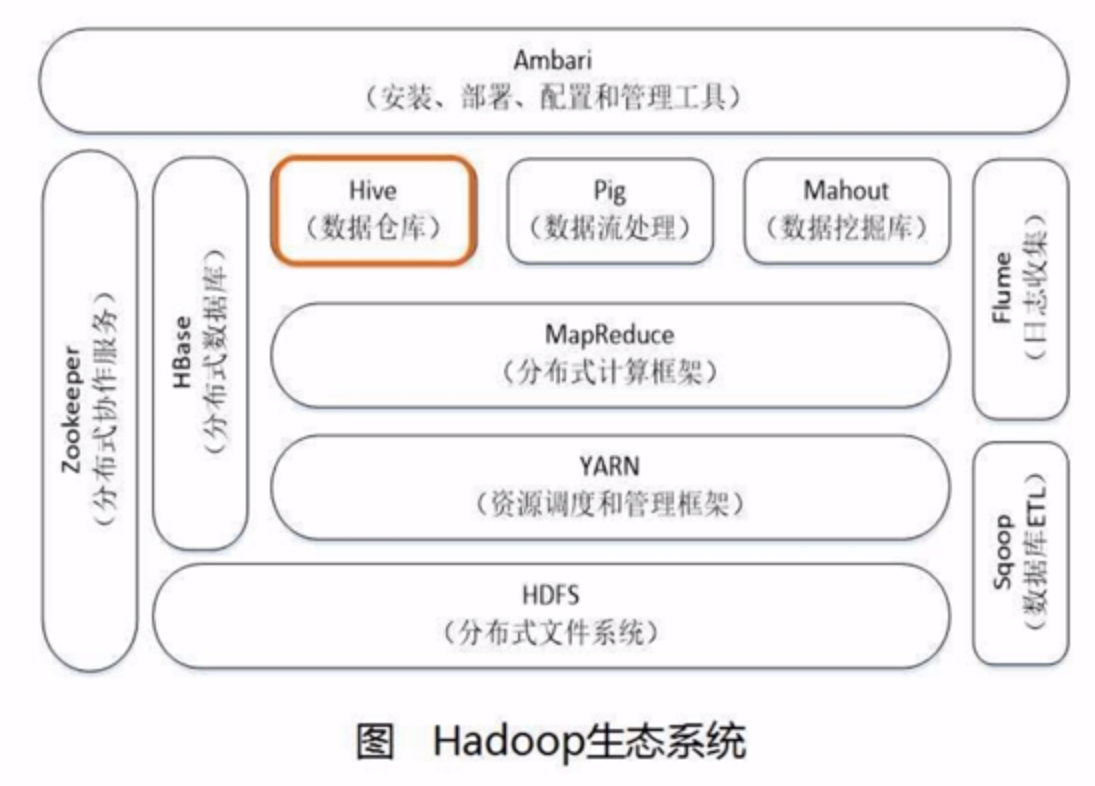
使用 Hive 程序处理第二个输入数据集。(hive是数据仓库,在hadoop基础上处理结构化数据。)
写入一个输出数据集。
数据仓库和数据库的区别?
一般来说,传统数据库是为存储而生,而数据仓库很明显,是为分析而生。
运行状态(正常)切换
通常,在 Amazon EMR 中处理数据时,输入为以文件形式存储在您选择的底层文件系统(如 Amazon S3 或 HDFS)中的数据。数据从处理序列中的一个步骤传递到下一个。最后一步将输出数据写入指定位置,如 Amazon S3 存储桶。
步骤按下面的序列运行:
提交请求以开始处理步骤。
所有步骤的状态均设为 PENDING (待处理)。
序列中的第一个步骤启动时,其状态更改为 RUNNING (正在运行)。其他步骤仍处于 PENDING (待处理) 状态。
第一个步骤完成后,其状态更改为 COMPLETED (已完成)。
序列中的下一个步骤启动,其状态更改为 RUNNING (正在运行)。完成时,其状态更改为 COMPLETED (已完成)。
对每个步骤重复这一模式,直到所有步骤均完成,处理结束。
下图显示了此步骤序列及随着处理的进行各步骤的状态更改。

运行状态(异常)切换
如果处理期间步骤失败,其状态会更改为 TERMINATED_WITH_ERRORS。您可以确定接下来如何处理每个步骤。默认情况下,序列中的任何其余步骤设置为 CANCELLED (取消) 并且不运行。您也可以选择忽略失败并允许继续执行其余步骤,或者立即终止集群。
下图显示了此步骤序列和处理期间某个步骤失败时默认的状态变更。

理解集群的生命周期
成功的 Amazon EMR 集群会遵循这个流程:
根据您指定的设置,Amazon EMR 先为每个实例预置集群中的 EC2 实例。在这个期间,集群的状态是
STARTING。Amazon EMR 在每个实例上运行您指定的引导操作。您可以使用引导操作安装自定义应用程序并执行所需的自定义。
Amazon EMR 安装在创建集群时指定的本机应用程序,例如,Hive、Hadoop 和 Spark 等。
在成功完成引导操作并安装本机应用程序后,集群状态为
RUNNING。此时,您可以连接到集群实例,集群将按顺序运行在创建集群时指定的任何步骤。您可以提交额外的步骤,这些步骤在任何以前的步骤完成后运行。在成功运行步骤后,集群将进入
WAITING状态。如果集群配置为在完成最后一个步骤后自动终止,则会进入SHUTTING_DOWN状态。在终止所有实例后,集群将进入
COMPLETED状态。
集群生命周期中的故障将导致 Amazon EMR 终止集群及其所有实例,除非启用了终止保护。如果集群由于故障而终止,则会删除集群上存储的任何数据并将集群状态设置为FAILED。如果启用了终止保护,您可以从集群中检索数据,然后删除终止保护并终止集群。
Amazon EMR 体系结构概述
存储
Hadoop 分布式文件系统 (HDFS)
- 不同的实例上存储多份数据副本。
- 暂时性存储,会在集群终止时收回。
- 在缓存 MapReduce 处理期间的中间结果或具有大量随机 I/O 的工作负载时非常有用。
EMR 文件系统 (EMRFS)
本地文件系统 (Local FS)
集群资源管理
默认情况下,Amazon EMR 使用 YARN (Yet Another Resource Negotiator) (Apache Hadoop 2.0 中引入的一个组件) 集中管理多个数据处理框架的集群资源。
数据处理框架
数据处理框架层是用于分析和处理数据的引擎。在 YARN 上运行并具有自己的资源管理功能的框架有很多,Hadoop MapReduce 和 Spark 是可用于 Amazon EMR 的主处理框架。
Spark 是一种用于处理大数据工作负载的集群框架和编程模型。与 Hadoop MapReduce 一样,Spark 是开源、分布式的处理系统,但它为执行计划使用有向无环图并为数据集使用内存缓存。在 Amazon EMR 上运行 Spark 时,您可以使用 EMRFS 直接访问 Amazon S3 中的数据。Spark 支持多种交互式查询模块,如 SparkSQL。
应用程序和项目
Amazon EMR 支持许多应用程序,如 Hive、Pig 和 Spark Streaming 库,以提供使用更高级的语言创建处理工作负载、运用机器学习算法、制作流处理应用程序、构建数据仓库等功能。此外,Amazon EMR 还支持拥有自己的集群管理功能而不使用 YARN 的开源项目。
End.
[AWS] 01 - What is Amazon EMR的更多相关文章
- 使用Apache Hudi + Amazon S3 + Amazon EMR + AWS DMS构建数据湖
1. 引入 数据湖使组织能够在更短的时间内利用多个源的数据,而不同角色用户可以以不同的方式协作和分析数据,从而实现更好.更快的决策.Amazon Simple Storage Service(amaz ...
- Amazon EMR(Elastic MapReduce):亚马逊Hadoop托管服务运行架构&Hadoop云服务之战:微软vs.亚马逊
http://s3tools.org/s3cmd Amazon Elastic MapReduce (Amazon EMR)简介 Amazon Elastic MapReduce (Amazon EM ...
- 使用Amazon EMR和Apache Hudi在S3上插入,更新,删除数据
将数据存储在Amazon S3中可带来很多好处,包括规模.可靠性.成本效率等方面.最重要的是,你可以利用Amazon EMR中的Apache Spark,Hive和Presto之类的开源工具来处理和分 ...
- 官宣!Amazon EMR正式支持Apache Hudi
Apache Hudi是一个开源的数据管理框架,其通过提供记录级别的insert, update, upsert和delete能力来简化增量数据处理和数据管道开发.Upsert指的是将记录插入到现有 ...
- [AWS - EC2] 如何向 Amazon Linux 2 实例传输文件,下载文件。How to send/ download files from Amazon Linux 2 Instance
1. 需要: 安装 WinSCP 2. 需要: PuTTY 生成的ppk格式密钥, 没有的话请移步此文章,完成1, 2, 3步即可. 3. 打开 WinSCP , 如果提示已经有PuTTY配置是否导入 ...
- [AI] 深度数据 - Data
Data Engineering Data Pipeline Outline [DE] How to learn Big Data[了解大数据] [DE] Pipeline for Data Eng ...
- hadoop发行版本
Azure HDInsight Azure HDInsight is Microsoft's distribution of Hadoop. The Azure HDInsight ecosystem ...
- Apache Hudi助力nClouds加速数据交付
1. 概述 在nClouds上,当客户的业务决策取决于对近实时数据的访问时,客户通常会向我们寻求有关数据和分析平台的解决方案.但随着每天创建和收集的数据量都在增加,这使得使用传统技术进行数据分析成为一 ...
- AWS EMR上搭建HBase环境
0. 概述 AWS的EMR服务为客户提供的托管 Hadoop 框架可以让您轻松.快 速.经济高效地在多个动态可扩展的 Amazon EC2 实例之间分发和处理 大量数据.您还可以运行其他常用的分发框架 ...
随机推荐
- 蔡勒(Zeller)公式及其推导:快速将任意日期转换为星期数
0. 本文的初衷及蔡勒公式的用处 前一段时间,我在准备北邮计算机考研复试的时候,做了几道与日期计算相关的题目,在这个过程中我接触到了蔡勒公式.先简单的介绍一下蔡勒公式是干什么用的. 我们有时候会遇到这 ...
- 解决Selenium弹出新页面无法定位元素问题(Unable to locate element)
Python 2.7 IDE Pycharm 5.0.3 环境细节详见Python+Selenium+PIL+Tesseract真正自动识别验证码进行一键登录 对于同一页面无法定位元素问题请见姊妹篇解 ...
- Kali Linux-装机后通用配置
目录 前言 一. 网络优化 更换host 更换dns 添加源 二. 更新系统 三 .安装N卡驱动 四.修复 add-apt-repository 五.安装常用软件 安装apt自带的包 安装第三方的de ...
- 使用Makefile构建Docker
使用Makefile构建Docker 刚开始学习docker命令的时候,很喜欢一个字一个字敲,因为这样会记住命令.后来熟悉了之后,每次想要做一些操作的时候就不得不 重复的输入以前的命令.当切换一个项目 ...
- C#中的扩展方法(向已有类添加方法,但无需创建新的派生类型)
C#中的扩展方法 扩展方法使你能够向现有类型"添加"方法,而无需创建新的派生类型.重新编译或以其他方式修改原始类型. 扩展方法是一种特殊的静态方法,但可以像扩展类型上的实例方法一样 ...
- Python: 转换文本编码
最近在做周报的时候,需要把csv文本中的数据提取出来制作表格后生产图表. 在获取csv文本内容的时候,基本上都是用with open(filename, encoding ='UTF-8') as f ...
- getline()与get()(c++学习笔记)
istream中的类(如cin)提供了一些面向行的类成员函数:getline()和get() 1.getline()函数 读取整行,使用回车键输入的换行符来确定输入结尾. 调用方法:cin.getli ...
- Java之戳中痛点 - (8)synchronized深度解析
概览: 简介:作用.地位.不控制并发的影响 用法:对象锁和类锁 多线程访问同步方法的7种情况 性质:可重入.不可中断 原理:加解锁原理.可重入原理.可见性原理 缺陷:效率低.不够灵活.无法预判是否成功 ...
- Spring框架的重要问题
这篇文章总结了一些关于Spring框架的重要问题,这些问题都是你在面试或笔试过程中可能会被问到的. 目录 Spring概述 依赖注入 Spring Beans Spring注解 Spring的对象访问 ...
- Leetcode之回溯法专题-131. 分割回文串(Palindrome Partitioning)
Leetcode之回溯法专题-131. 分割回文串(Palindrome Partitioning) 给定一个字符串 s,将 s 分割成一些子串,使每个子串都是回文串. 返回 s 所有可能的分割方案. ...