初学Python之爬虫的简单入门
初学Python之爬虫的简单入门
一、什么是爬虫?
1.简单介绍爬虫
爬虫的全称为网络爬虫,简称爬虫,别名有网络机器人,网络蜘蛛等等。
网络爬虫是一种自动获取网页内容的程序,为搜索引擎提供了重要的数据支撑。搜索引擎通过网络爬虫技术,将互联网中丰富的网页信息保存到本地,形成镜像备份。我们熟悉的谷歌、百度本质上也可理解为一种爬虫。
如果形象地理解,爬虫就如同一只机器蜘蛛,它的基本操作就是模拟人的行为去各个网站抓取数据或返回数据。
2.爬虫的分类
网络爬虫一般分为传统爬虫和聚焦爬虫。
传统爬虫从一个或若干个初始网页的URL开始,抓取网页时不断从当前页面上抽取新的URL放入队列,直到满足系统的一定条件才停止,即通过源码解析来获得想要的内容。
聚焦爬虫需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入待抓取的URL队列,再根据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到满足系统的一定条件时停止。另外,所有被爬虫抓取的网页都将会被系统存储、分析、过滤,并建立索引,以便之后的查询和检索;对于聚焦爬虫来说,这一过程所得到的分析结果还可能对以后的抓取过程给出反馈和指导。
防爬虫:KS-WAF(网站统一防护系统)将爬虫行为分为搜索引擎爬虫及扫描程序爬虫,可屏蔽特定的搜索引擎爬虫节省带宽和性能,也可屏蔽扫描程序爬虫,避免网站被恶意抓取页面。使用防爬虫机制的基本上是企业,我们平时也能见到一些对抗爬虫的经典方式,如图片验证码、滑块验证、封禁 IP等等。
3.爬虫的工作原理
下图是一个网络爬虫的基本框架:

对应互联网的所有页面可划分为五部分:

1.已下载未过期网页。
2.已下载已过期网页:抓取到的网页实际上是互联网内容的一个镜像文件,互联网是动态变化的,一部分互联网上的内容已经发生了变化,这时,这部分抓取到的网页就已经过期了。
3.待下载网页:待抓取URL队列中的页面。
4.可知网页:既没有被抓取也没有在待抓取URL队列中,但可通过对已抓取页面或者待抓取URL对应页面进行分析获取到的URL,认为是可知网页。
5.不可知网页:爬虫无法直接抓取下载的网页。
待抓取URL队列中的URL顺序排列涉及到抓取页面的先后次序问题,而决定这些URL排列顺序的方法叫做抓取策略。下面介绍六种常见的抓取策略:
1.深度优先遍历策略
深度优先遍历策略是指网络爬虫从起始页开始,由一个链接跟踪到另一个链接,这样不断跟踪链接下去直到处理完这条线路,之后再转入下一个起始页,继续跟踪链接。以下图为例:
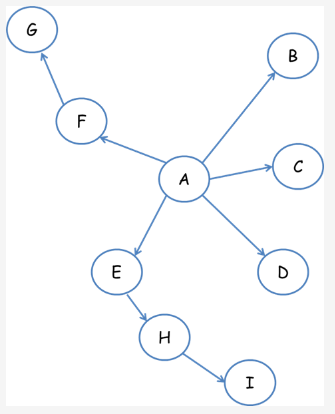
遍历路径:A-F-G E-H-I B C D
需要注意的是,深度优先可能会找不到目标节点(即进入无限深度分支),因此,深度优先策略不一定能适用于所有情况。
2.宽度优先遍历策略
宽度优先遍历策略的基本思路是,将新下载网页中发现的链接直接插入待抓取URL队列的末尾。也就是指网络爬虫会先抓取起始网页中链接的所有网页,然后再选择其中的一个链接网页,继续抓取在此网页中链接的所有网页。还是以上图为例:

遍历路径:第一层:A-B-C-D-E-F,第二层:G-H,第三层:I
广度优先遍历策略会彻底遍历整个网络图,效率较低,但覆盖网页较广。
3.反向链接数策略
反向链接数是指一个网页被其他网页链接指向的数量。反向链接数反映一个网页的内容受到其他人推荐的程度。因此,很多时候搜索引擎的抓取系统会使用这个指标来评价网页的重要程度,从而决定不同网页的抓取先后顺序。
而现实是网络环境存在各种广告链接、作弊链接的干扰,使得许多反向链接数反映的结果并不可靠。
4.Partial PageRank策略
Partial PageRank策略借鉴了PageRank算法的思想:对于已下载网页,连同待抓取URL队列中的URL,形成网页集合,计算每个页面的PageRank值,然后将待抓取URL队列中的URL按照PageRank值的大小进行排列,并按照该顺序抓取页面。
若每次抓取一个页面,就重新计算PageRank值,则效率太低。
一种折中方案是:每抓取K个页面后,重新计算一次PageRank值。而对于已下载页面中分析出的链接,即暂时没有PageRank值的未知网页那一部分,先给未知网页一个临时的PageRank值,再将这个网页所有链接进来的PageRank值进行汇总,这样就形成了该未知页面的PageRank值,从而参与排序。以下图为例:

设k值为3,即每抓取3个页面后,重新计算一次PageRank值。
已知有{1,2,3}这3个网页下载到本地,这3个网页包含的链接指向待下载网页{4,5,6}(即待抓取URL队列),此时将这6个网页形成一个网页集合,对其进行PageRank值的计算,则{4,5,6}每个网页得到对应的PageRank值,根据PageRank值从大到小排序,由图假设排序结果为5,4,6,当网页5下载后,分析其链接发现指向未知网页8,这时先给未知网页8一个临时的PageRank值,如果这个值大于网页4和6的PageRank值,则接下来优先下载网页8,由此思路不断进行迭代计算。
5.OPIC策略
此算法其实也是计算页面重要程度。在算法开始前,给所有页面一个相同的初始现金(cash)。当下载了某个页面P之后,将P的现金分摊给所有从P中分析出的链接,并且将P的现金清空。对于待抓取URL队列中的所有页面按照现金数大小进行排序。
6.大站优先策略
对于待抓取URL队列中的所有网页,根据所属的网站进行分类。待下载页面数多的网站优先下载。
二、爬虫的基本流程
首先简单了解关于Request和Response的内容:
Request:浏览器发送消息给某网址所在的服务器,这个请求信息的过程叫做HTTP Request。
Response:服务器接收浏览器发送的消息,并根据消息内容进行相应处理,然后把消息返回给浏览器。这个响应信息的过程叫做HTTP Response。浏览器收到服务器的Response信息后,会对信息进行相应处理,然后展示在页面上。
根据上述内容将网络爬虫分为四个步骤:
1.发起请求:通过HTTP库向目标站点发起请求,即发送一个Request,请求可以包含额外的headers等信息,等待服务器响应。
常见的请求方法有两种,GET和POST。get请求是把参数包含在了URL(Uniform Resource Locator,统一资源定位符)里面,而post请求大多是在表单里面进行,也就是让你输入用户名和秘密,在url里面没有体现出来,这样更加安全。post请求的大小没有限制,而get请求有限制,最多1024个字节。
2.获取响应内容:如果服务器能正常响应,会得到一个Response,Response的内容便是所要获取的页面内容,类型可能有HTML,Json字符串,二进制数据(如图片视频)等类型。
3.解析内容:得到的内容可能是HTML,可以用正则表达式、网页解析库进行解析。可能是Json,可以直接转为Json对象解析,可能是二进制数据,可以做保存或者进一步的处理。
在Python语言中,我们经常使用Beautiful Soup、pyquery、lxml等库,可以高效的从中获取网页信息,如节点的属性、文本值等。
Beautiful Soup库是解析、遍历、维护“标签树”的功能库,对应一个HTML/XML文档的全部内容。安装方法非常简单,如下:
#安装方法 pips install beautifulsoup4 #验证方法 from bs4 import BeautifulSoup
4.保存数据:如果数据不多,可保存在txt 文本、csv文本或者json文本等。如果爬取的数据条数较多,可以考虑将其存储到数据库中。也可以保存为特定格式的文件。
保存后的数据可以直接分析,主要使用的库如下:NumPy、Pandas、 Matplotlib。
NumPy:它是高性能科学计算和数据分析的基础包。
Pandas : 基于 NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。它可以算得上作弊工具。
Matplotlib:Python中最著名的绘图系统Python中最著名的绘图系统。它可以制作出散点图,折线图,条形图,直方图,饼状图,箱形图散点图,折线图,条形图,直方图,饼状图,箱形图等。
三、爬虫简单实例
运行平台: Windows
Python版本: Python3.7
首先查看网址的源代码,使用google浏览器,右键选择检查,查看需要爬取的网址源代码,在Network选项卡里面,点击第一个条目可看到源代码。
第一部分是General,包括了网址的基本信息,比如状态 200等,第二部分是Response Headers,包括了请求的应答信息,还有body部分,比如Set-Cookie,Server等。第三部分是,Request headers,包含了服务器使用的附加信息,比如Cookie,User-Agent等内容。
上面的网页源代码,在python语言中,我们只需要使用urllib、requests等库实现即可,具体如下。
import urllib.request
import socket
from urllib import error
try:
response = urllib.request.urlopen('https://www.python.org')
print(response.status)
print(response.read().decode('utf-8'))
except error.HTTPError as e:
print(e.reason,e.code,e.headers,sep='\n')
except error.URLError as e:
print(e.reason)
else:
print('Request Successfully')
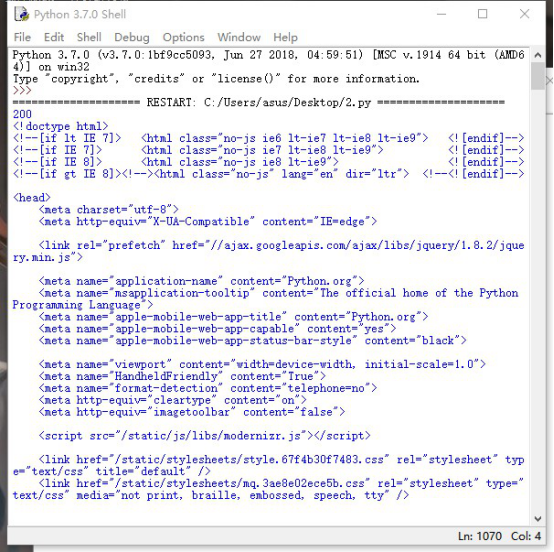
运行结果如下:
四、关于入门爬虫
在如今这个信息爆炸的大数据时代,数据的价值是可观的,而网络爬虫无疑是一个获取数据信息的便捷途径。合理利用爬虫爬取有价值的数据,可以为我们的生活提供不少帮助。
实际上,关于网络爬虫,我完全是一个新手,写下这篇博客的途中也同时在零基础学习。
首先,我了解到python3的语法是需要掌握的,因为要打好基础。不过python3语法很简洁,学起来应该不会过分吃力。
接着是python的各种库,目前接触的不多,像我这种还是从基础的库开始学习会比较好,比如urlib、requests。
在学习过程中也了解到现在很多大型企业在使用反爬虫机制,爬虫过程中可能会返回非法请求,需要使用代理防止封禁IP,爬取网页需要伪装成平时正常使用浏览器那样。这又是另外要解决的问题了。
总之,对于新手来说是需要一步一步花时间深入学习的,平时也得多加练习,毕竟学习之事并非一朝一夕就能促成,重要的是坚持吧。
参考资料:
https://blog.csdn.net/a575553272/article/details/80265182
https://blog.csdn.net/byweiker/article/details/79234854
https://blog.csdn.net/weixin_42530834/article/details/80787875
初学Python之爬虫的简单入门的更多相关文章
- Python爬虫的简单入门(一)
Python爬虫的简单入门(一) 简介 这一系列教学是基于Python的爬虫教学在此之前请确保你的电脑已经成功安装了Python(本教程使用的是Python3).爬虫想要学的精通是有点难度的,尤其是遇 ...
- Python基础——爬虫以及简单的数据分析
目标:使用Python编写爬虫,获取链家青岛站的房产信息,然后对爬取的房产信息进行分析. 环境:win10+python3.8+pycharm Python库: import requests imp ...
- 这个Python爬虫的简单入门及实用的实例,你会吗?
前言本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理.作者:HOT_and_COOl 利用爬虫可以进行数据挖掘,比如可以爬取别人的网 ...
- Java爬虫——Gecco简单入门程序(根据下一页一直爬数据)
为了完成作业,所以学习了一下爬虫Gecco,这个爬虫集合了以往所有的爬虫的特点,但是官方教程中关于Gecco的教程介绍的过于简单,本篇博客是根据原博客的地址修改的,原博客中只有程序的截图,而没有给出一 ...
- [初学Python]编写一个最简单判断SQL注入的检测工具
0x01 背景 15年那会,几乎可以说是渗透最火的一年,各种教程各种文章,本人也是有幸在那几年学到了一些皮毛,中间因学业问题将其荒废至今.当初最早学的便是,and 1=1 和 and 1=2 这最简单 ...
- Python网络爬虫 - 一个简单的爬虫例子
下面我们创建一个真正的爬虫例子 爬取我的博客园个人主页首页的推荐文章列表和地址 scrape_home_articles.py from urllib.request import urlopen f ...
- python网络爬虫之四简单爬取豆瓣图书项目
一.爬虫项目一: 豆瓣图书网站图书的爬取: import requests import re content = requests.get("https://book.douban.com ...
- Python 3 + Selenium 3 简单入门学习示例 126邮箱登录
这是一个很多基础演示的书上的例子,但是一般按照这些书上的代码可能都不能成功登录.也许是网易修改了126的页面导致的吧,下面给出最新的能够work的版本 from selenium import web ...
- Python开发爬虫之动态网页抓取篇:爬取博客评论数据——通过Selenium模拟浏览器抓取
区别于上篇动态网页抓取,这里介绍另一种方法,即使用浏览器渲染引擎.直接用浏览器在显示网页时解析 HTML.应用 CSS 样式并执行 JavaScript 的语句. 这个方法在爬虫过程中会打开一个浏览器 ...
随机推荐
- flex招式心法
flex布局绝对是我们平常在布局中用的最多的一个属性,我们来看看它在can i use中的浏览器支持度:(截止到2019/11/16) 挖藕,凹森!支持度居然这么好,好到连ie也能支持大部分的flex ...
- FloatingActionButton动态更换背景色
版权声明:本文为xing_star原创文章,转载请注明出处! 本文同步自http://javaexception.com/archives/186 FloatingActionButton 动态更换背 ...
- DialogHost 关闭对话框
<Window x:Class="DialogHost.ClosingConfirmation.CodeBehind.MainWindow" xmlns="http ...
- mysql 8.0 忘记root密码后重置
最近状态很不好,一直晕晕晕晕晕晕乎乎的,一个测试实例,下班前修改了一下root的密码,接着就下班走人,第二天来发现root密码忘了 刚好自动化安装脚本整理好了,本来想着算了直接重装实例得了,简单省事也 ...
- 快速排序 Vs. 归并排序 Vs. 堆排序——谁才是最强的排序算法
知乎上有一个问题是这样的: 堆排序是渐进最优的比较排序算法,达到了O(nlgn)这一下界,而快排有一定的可能性会产生最坏划分,时间复杂度可能为O(n^2),那为什么快排在实际使用中通常优于堆排序? 昨 ...
- c#中的跳转语句
break:跳出循环,执行循环外的语句:continue:跳出此次循环,进入下一次循环: goto:不建议使用 return:终止它所在的方法的执行,并将控制权返回给调用方法.
- Markdown语法教程
标题 # 一级标题 ## 二级标题 ### 三级标题 #### 四级标题 ##### 五级标题 ###### 六级标题 效果如下: 一级标题 二级标题 三级标题 四级标题 五级标题 六级标题 段落 换 ...
- PHP捕获异常register_shutdown_function和error_get_last的使用
register_shutdown_function 注册一个会在php中止时执行的函数,注册一个 callback ,它会在脚本执行完成或者 exit() 后被调用. error_get_last ...
- Springboot对SpringMVC如何扩展配置
原文地址:http://www.javayihao.top/detail/171 概述 Springboot在web层的开发基本都是采用Springmvc框架技术,但是Springmvc中的某些配置在 ...
- 硬盘容量统计神器WinDirStat
最近遇到C盘快要爆满的问题,我的笔记本是128G SSD + 1t HDD,给C盘分配的空间是80G固态,由于平时疏远管理,造成了C盘臃肿,迁移一些软件,但还是没有太好的解决,这是上知乎发现有大神推荐 ...