Hadoop环境部署
1.虚拟机克隆
在VM界面点击查看-自定义-库,然后在左边我的计算机下右键点击安装好的第一个系统,然后管理-克隆,选择克隆系统所在的文件路径即可。
2.三台主机名字修改
root用户下:
(1)编辑network配置文件
gedit /etc/sysconfig/network
(2)在配置文件中增加如下配置,保存退出
NETWORKING=yes
HOSTNAME=master
(3)输入hostname master,然后关闭当前终端,重新打开一个终端,可以看到已经修改生效,由于上这些操作只是修改了瞬态主机名,并没有修改静态主机名
(4)编辑hostname配置文件
gedit /etc/hostname
(5)删除原来的配置并写入自己的名字
master
(6)然后对slave0和slave1重复操作即可。
3.hosts文件
(1)将三台主机的IP修改成静态IP
点击master系统桌面右上角网络连接图标-Wired Connected-Wired Setting-Wired后面的“+”,然后配置静态地址,掩码和网关
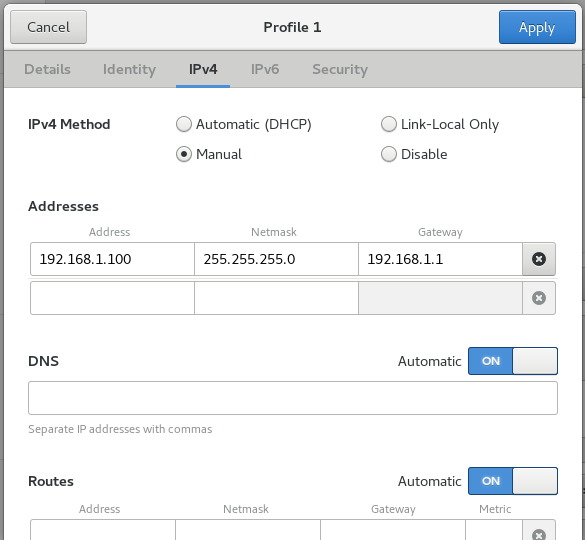
同理,将slave0的IP设置成192.168.1.101,slave1的IP设置成192.168.1.102,网关的掩码不变。
通过在master上执行ping 192.168.1.101能通就说明设置成功。
(2)修改hosts文件
[jun@master ~]$ gedit /etc/hosts
增加下面的配置
192.168.1.100 master
192.168.1.101 slave0
192.168.1.102 slave1
然后在master上直接执行ping slave0看是否能通,如果能通,就说明配置成功。另外两个slave上配置同理。
4.JDK下载与安装
(1)在JDK官网上下载jdk-8u171-linux-x64.tar.gz
(2)鼠标点击桌面上的home文件夹,新建Resources文件夹,将jdk压缩文件拷贝到Resources文件夹下
(3)使用root用户,将jdk压缩文件移动至自己新建的文件夹下
mkdir /usr/java
mv /home/jun/Resources/jdk-8u171-linux-x64.tar.gz /usr/java
(4)进入/usr/java中解压文件
tar -zxvf jdk-8u171-linux-x64.tar.gz
(5)在/usr/java文件夹下有解压出来的文件
[jun@master java]$ ls
jdk1..0_171 jdk-8u171-linux-x64.tar.gz
(6)使用gedit打开配置文件
gedit /home/jun/.bash_profile
(7)在配置文件最后面添加两条环境变量并保存退出
export JAVA_HOME=/usr/java/jdk1..0_171/
export PATH=$JAVA_HOME/bin:$PATH
(8)使配置文件生效
source /home/jun/.bash_profile
(9)查看是否配置成功
[root@slave0 .ssh]# java -version
openjdk version "1.8.0_161"
OpenJDK Runtime Environment (build 1.8.0_161-b14)
OpenJDK -Bit Server VM (build 25.161-b14, mixed mode)
5.关闭防火墙
三个节点上都需要配置,需要使用root用户
(1)查看系统防火墙当前的运行状态,主要看active后面的内容
systemctl status firewalld.service
(2)关闭防火墙,关闭之后可以再次查看一下状态,如果是Active: inactive (dead)就说明已经关闭
systemctl stop firewalld.service
(3)在下次启动计算机时取消防火墙服务
systemctl disable firewalld.service
6.ssh免密登录
(1)master节点的配置
使用非root用户,生成master节点的密钥,执行下面的命令,然后一路回车即可,生成的目录在/home/jun/.ssh中
[jun@master .ssh]$ ssh-keygen -t rsa
将公钥文件复制到.ssh目录中
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
修改文件权限
[jun@master .ssh]$ chmod 600 ~/.ssh/authorized_keys
将公钥文件复制到slave0节点和slave1节点上
[jun@master .ssh]$ scp ~/.ssh/authorized_keys jun@slave0:~/
[jun@master .ssh]$ scp ~/.ssh/authorized_keys jun@slave1:~/
(2)slave节点的配置
同样使用非root用户,生成slave节点的密钥,执行下面的命令,然后一路回车即可,生成的目录在/home/jun/.ssh中
[jun@slave0 ~]$ ssh-keygen -t rsa
将从master节点复制过来的公钥文件移动到.ssh文件夹下
[jun@slave0 ~]$ mv authorized_keys ~/.ssh/
然后cd到.ssh中给文件赋权限
[jun@slave0 .ssh]$ chmod 600 authorized_keys
在slave1上重复同样的操作
(3)测试是否成功
在master节点上直接执行ssh slave0命令,就可以登录到slave0的主机,并且不需要输入密码,输入exit命令可退回到原来的主机。slave1同理。
[jun@master .ssh]$ ssh slave0
Last login: Fri Jul 20 15:25:00 2018
[jun@slave0 ~]$ exit
logout
Connection to slave0 closed.
7.hadoop下载和安装
(1)下载地址:http://mirrors.hust.edu.cn/apache/hadoop/common/hadoop-2.8.4/hadoop-2.8.4.tar.gz
(2)将下载下来的文件复制到master节点的/home/Resources下
(3)在usr下新建hadoop文件夹并把hadoop-2.8.4.tar.gz移动到hadoop文件夹下
[root@master usr]# mkdir hadoop
[root@master usr]# mv /home/jun/Resources/hadoop-2.8..tar.gz /usr/hadoop/
(4)在/usr/hadoop下解压hadoop-2.8.4.tar.gz
hadoop-2.8..tar.gz
(5)在/usr/hadoop下有解压出来的hadoop-2.8.4文件夹,打开可以看到里面有很多文件
[root@master hadoop]# ls
hadoop-2.8.4 hadoop-2.8.4.tar.gz
[root@master hadoop]# cd hadoop-2.8.4/
[root@master hadoop-2.8.4]# ls -l
total 124
drwxr-xr-x. 2 1001 1001 194 May 8 10:58 bin
drwxr-xr-x. 3 1001 1001 20 May 8 10:58 etc
drwxr-xr-x. 2 1001 1001 106 May 8 10:58 include
drwxr-xr-x. 3 1001 1001 20 May 8 10:58 lib
drwxr-xr-x. 2 1001 1001 239 May 8 10:58 libexec
-rw-r--r--. 1 1001 1001 99253 May 8 10:58 LICENSE.txt
-rw-r--r--. 1 1001 1001 15915 May 8 10:58 NOTICE.txt
-rw-r--r--. 1 1001 1001 1366 May 8 10:58 README.txt
drwxr-xr-x. 2 1001 1001 4096 May 8 10:58 sbin
drwxr-xr-x. 4 1001 1001 31 May 8 10:58 share
[root@master hadoop-2.8.4]#
8.hadoop相关配置
(1)为了便于之后的配置,将hadoop-2.8.4移动到/home/jun/下,同时建立一个软链接
[root@master hadoop]# cp hadoop-2.8. /home/jun/ -rf
[root@master jun]# cd /home/jun/
[root@master jun]# ln -s hadoop-2.8./ hadoop
[root@master jun]# ls
Desktop Downloads hadoop-2.8. Pictures Resources Videos
Documents hadoop Music Public Template
(2)配置hadoop环境变量,打开hadoop-env.sh
[root@master hadoop]# gedit /home/jun/hadoop/etc/hadoop/hadoop-env.sh
将export JAVA_HOME=${JAVA_HOME}替换成export JAVA_HOME=/usr/java/jdk1.8.0_171/保存退出
(3)配置Yarn环境变量
[root@master hadoop]# gedit /home/jun/hadoop/etc/hadoop/yarn-env.sh
在# export JAVA_HOME=/home/y/libexec/jdk1.6.0/下面增加export JAVA_HOME=/usr/java/jdk1.8.0_171/保存退出即可
(4)配置核心组件文件core-site.xml
[root@master hadoop]# gedit /home/jun/hadoop/etc/hadoop/core-site.xml
增加下面的配置代码
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/jun/hadoopdata</value>
</property>
</configuration>
(5)配置文件系统hdfs-site.xml
[root@master hadoop]# gedit /home/jun/hadoop/etc/hadoop/hdfs-site.xml
增加下面的代码,配置HDFS数据块的副本数由默认的3变成1
<configuration>
<property>
<name>dfs.replication</name>
<value></value>
</property>
</configuration>
(6)配置Yarn站点yarn-site.xml
[root@master hadoop]# gedit /home/jun/hadoop/etc/hadoop/yarn-site.xml
增加下面的代码
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:</value>
</property>
<!-- Site specific YARN configuration properties -->
</configuration>
(7)配置MapReduce计算框架文件
先复制一份mapred-site.xml.template并改名,然后打开
[root@master hadoop]# cp /home/jun/hadoop/etc/hadoop/mapred-site.xml.template /home/jun/hadoop/etc/hadoop/mapred-site.xml
[root@master hadoop]# gedit /home/jun/hadoop/etc/hadoop/mapred-site.xml
增加下面的代码
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
(8)配置Master的slaves文件
slaves文件给出了Hadoop集群的Slave节点列表,Hadoop在启动的时候,系统根据当前slaves中的Slave节点名称列表启动集群。
[root@master hadoop]# gedit /home/jun/hadoop/etc/hadoop/slaves
增加两个节点的名称
slave0
slave1
(9)复制Master节点上的hadoop,和之前的复制文件一样,由于已经设置了免密登录,因此不会输入密码
[jun@master java]$ scp -r /home/jun/hadoop jun@slave0:~/
[jun@master java]$ scp -r /home/jun/hadoop jun@slave1:~/
9.Hadoop集群的启动配置
(1)配置操作系统环境变量
普通用户下使用gedit打开系统配置文件
[jun@master java]$ gedit ~/.bash_profile
增加下面的环境变量
#hadoop
export HADOOP_HOME=/home/jun/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
执行source使得配置生效
[jun@master java]$ source ~/.bash_profile
在另外两个节点上进行相同配置
(2)创建Hadoop数据目录
创建的数据目录要和之前配置过的<name>hadoop.tmp.dir</name> <value>/home/jun/hadoopdata</value>一致
[jun@master java]$ mkdir /home/jun/hadoopdata
在另外两个节点也要进行相同的配置
(3)格式化文件系统
只需在master上进行下面的操作,会将数据删除掉,要谨慎使用这条命令
[jun@master java]$ hdfs namenode -format
10.启动Hadoop集群
此时,启动hadoop还有一些问题,需要先将hadoop文件的所有者赋给系统用户,需要在三台虚拟机上都执行
chown -R jun /home/jun/hadoop
(1)启动HDFS,执行start-dfs.sh脚本,但是slave结点中的datanode没有启动
Starting namenodes on [master]
master: starting namenode, logging to /home/jun/hadoop/logs/hadoop-jun-namenode-master.out
slave0: starting datanode, logging to /home/jun/hadoop/logs/hadoop-jun-datanode-slave0.out
slave1: starting datanode, logging to /home/jun/hadoop/logs/hadoop-jun-datanode-slave1.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /home/jun/hadoop/logs/hadoop-jun-secondarynamenode-master.out
[jun@master hadoop]$ jps
Jps
NameNode
SecondaryNameNode [jun@slave0 ~]$ jps
Jps
在slave0节点上的/home/jun/hadoop/logs中查看datanode日志,发现下面的问题
-- ::, WARN org.apache.hadoop.hdfs.server.common.Storage: Failed to add storage directory [DISK]file:/home/jun/hadoopdata/dfs/data/
java.io.IOException: Incompatible clusterIDs in /home/jun/hadoopdata/dfs/data: namenode clusterID = CID-31d3821f-143c-45ca-97ed-1b37db24c6ef; datanode clusterID = CID-f9dbd23c-001e-4e81-bf06-2432b44c3676
异常信息里显示的是,namenode和datanode的clusterID不一致,这些异常就导致了后面提示初始化失败、DataNode进程退出等异常、警告信息。这是由于多次执行namenode格式化导致的。
首先停止HDFS
[jun@master logs]$ stop-dfs.sh
Stopping namenodes on [master]
master: stopping namenode
slave1: no datanode to stop
slave0: no datanode to stop
Stopping secondary namenodes [0.0.0.0]
0.0.0.0: stopping secondarynamenode
然后删除slave结点下相关文件夹下的内容,即
rm /home/jun/hadoopdata/dfs/data/* -rf
再次启动HDFS发现都正常了
[jun@master logs]$ start-dfs.sh
Starting namenodes on [master]
master: starting namenode, logging to /home/jun/hadoop/logs/hadoop-jun-namenode-master.out
slave1: starting datanode, logging to /home/jun/hadoop/logs/hadoop-jun-datanode-slave1.out
slave0: starting datanode, logging to /home/jun/hadoop/logs/hadoop-jun-datanode-slave0.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /home/jun/hadoop/logs/hadoop-jun-secondarynamenode-master.out
[jun@master logs]$ jps
Jps
SecondaryNameNode
NameNode [jun@slave0 data]$ jps
Jps
DataNode Jps
[jun@slave1 ~]$ rm /home/jun/hadoopdata/dfs/data/* -rf
[jun@slave1 ~]$ jps
6618 DataNode
6730 Jps
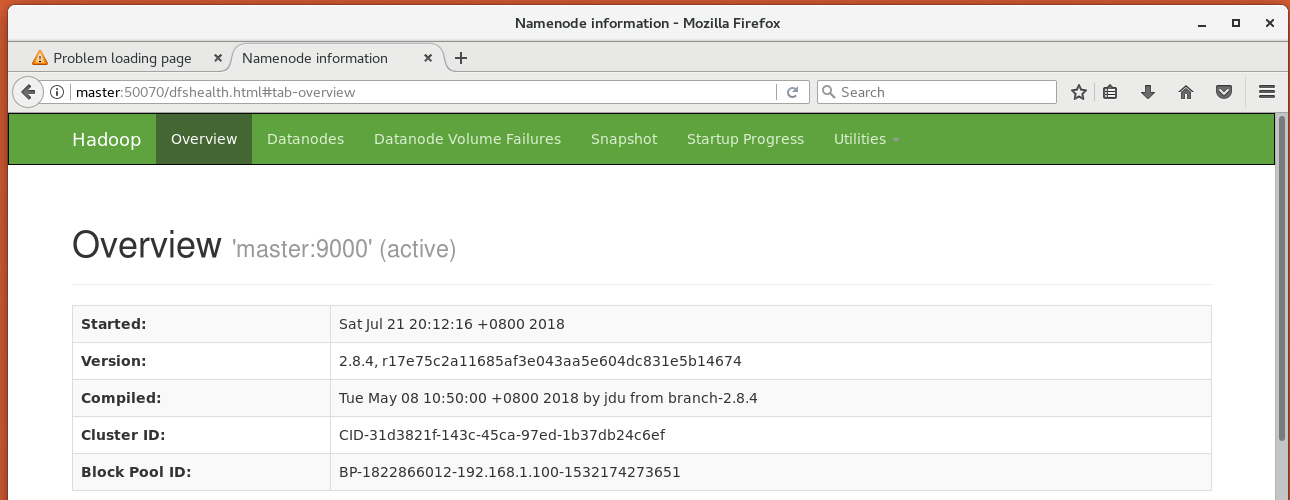
在master上的浏览器中输入http://master:50070即可通过web监视HDFS系统的运行情况
(2)启动Yarn,通过start-yarn.sh脚本,然后查看master和slave
[jun@master ~]$ start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /home/jun/hadoop/logs/yarn-jun-resourcemanager-master.out
slave0: starting nodemanager, logging to /home/jun/hadoop/logs/yarn-jun-nodemanager-slave0.out
slave1: starting nodemanager, logging to /home/jun/hadoop/logs/yarn-jun-nodemanager-slave1.out
[jun@master ~]$ jps
SecondaryNameNode
NameNode
Jps
ResourceManager [jun@slave0 ~]$ jps
NodeManager
DataNode
Jps [jun@slave1 ~]$ jps
DataNode
Jps
NodeManager
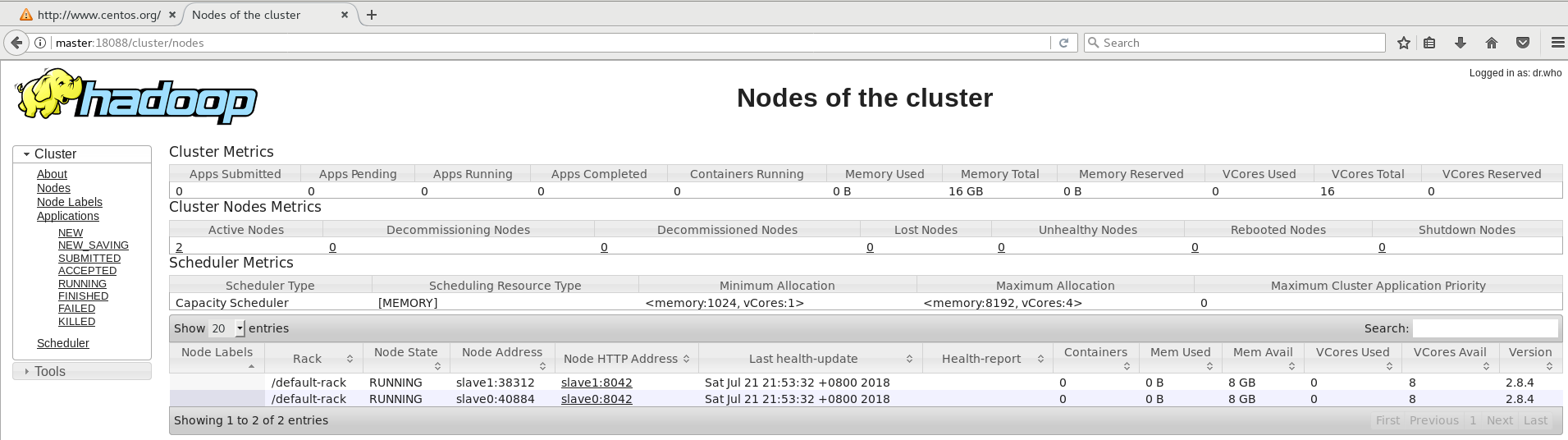
在master上的浏览器中输入http://master:50070即可通过web监视Yarn系统的运行情况
(11)关闭Hadoop集群
执行下面两个脚本即可
stop-dfs.sh
stop-yarn.sh
Hadoop环境部署的更多相关文章
- Hadoop生态圈-HUE环境部署
Hadoop生态圈-HUE环境部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.HUE简介 1>.HUE的由来 HUE全称是HadoopUser Experienc ...
- 通过Hadoop安全部署经验总结,开发出以下十大建议,以确保大型和复杂多样环境下的数据信息安全。
通过Hadoop安全部署经验总结,开发出以下十大建议,以确保大型和复杂多样环境下的数据信息安全. 1.先下手为强!在规划部署阶段就确定数据的隐私保护策略,最好是在将数据放入到Hadoop之前就确定好保 ...
- Hadoop记录-部署hadoop环境shell实现
#!/bin/bash menu() { echo "---欢迎使用hadoop部署管理程序---" echo "# 1.初始化Linux环境" echo &q ...
- Hadoop 学习笔记 (八) hadoop2.2.0 测试环境部署 及两种启动方式
1基本流程步骤1:准备硬件(linux操作系统)步骤2:准备软件安装包,并安装基础软件(主要是JDK)步骤3:修改配置文件步骤4:分发hadoop步骤5:启动服务步骤6:验证是否启动成功!2硬件配置要 ...
- Hadoop环境搭建--Docker完全分布式部署Hadoop环境(菜鸟采坑吐血整理)
系统:Centos 7,内核版本3.10 本文介绍如何从0利用Docker搭建Hadoop环境,制作的镜像文件已经分享,也可以直接使用制作好的镜像文件. 一.宿主机准备工作 0.宿主机(Centos7 ...
- ubuntu12.04+hadoop2.2.0+zookeeper3.4.5+hbase0.96.2+hive0.13.1伪分布式环境部署
目录: 一.hadoop2.2.0.zookeeper3.4.5.hbase0.96.2.hive0.13.1都是什么? 二.这些软件在哪里下载? 三.如何安装 1.安装JDK 2.用parallel ...
- Flume环境部署和配置详解及案例大全
flume是一个分布式.可靠.和高可用的海量日志采集.聚合和传输的系统.支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(比如文本.HDF ...
- kafka 基础知识梳理及集群环境部署记录
一.kafka基础介绍 Kafka是最初由Linkedin公司开发,是一个分布式.支持分区的(partition).多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特 ...
- Hadoop环境准备
1. 集群简介 HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起. HDFS集群负责海量数据的存储,集群中的角色主要有: NameNode.DataN ...
随机推荐
- uptimerobot 监控
前言 由于搞了多个公共服务于多台vps,需要监控项目稳定性与服务器稳定性,考察了阿里云云监控与uptimerobot,最后选择了uptimerobot 教程 访问官网,注册账号 : https://u ...
- 让视频丝滑流畅——N/A通用补帧傻瓜解决方案
补帧就是字面意思,把24帧的视频通过算法即时补偿到更高的帧数,获得更优秀的观感体验 索尼大法brivia电视的中高端产品线中的motionflow技术,都可以实现硬件补帧,只需要把动态打开,相应的画面 ...
- [LeetCode] 824. Goat Latin
Description A sentence S is given, composed of words separated by spaces. Each word consists of lowe ...
- Object.keys方法详解
一.官方解释 Object.keys() 方法会返回一个由一个给定对象的自身可枚举属性组成的数组,数组中属性名的排列顺序和使用 for...in 循环遍历该对象时返回的顺序一致 .如果对象的键-值都不 ...
- 网关我选 Spring Cloud Gateway
网关可提供请求路由与组合.协议转换.安全认证.服务鉴权.流量控制与日志监控等服务.可选的网关有不少,比如 Nginx.高性能网关 OpenResty.Linkerd 以及 Spring Cloud G ...
- Airport Express UVA - 11374
In a small city called Iokh, a train service, Airport-Express, takes residents to the airport more q ...
- HashTable、Dictionary、ConcurrentDictionary三者区别
转载自https://blog.csdn.net/yinghuolsx/article/details/72952857 1.HashTable HashTable表示键/值对的集合.在.NET Fr ...
- ubuntu使用uwsgi+nginx部署django
ls -lha export WORKON_HOME=~/venv source /usr/local/bin/vitualenvwrapper.sh VIRTUALENVWRAPPER_PYTHON ...
- linux系统下使用宝塔面板安装owncloud常见问题
在安装owncloud时出现 无法写入“config”目录! 解决方法 在宝塔面板,找到owncloud根目录,点击"权限“设置权限 将权限设置为777,应用到子目录打勾(如下图) 确定后再 ...
- Flask中多APP应用以及admin后台系统
一.多APP from werkzeug.wsgi import DispatcherMiddleware from werkzeug.serving import run_simple from f ...