Graylog源码分析
上文主要介绍了Graylog的功能与架构,本篇我们来看看Graylog的源码
一. 项目启动(CmdLineTool)
启动基本做了这几件事:初始化logger,插件加载(这里用到了Java SPI机制),性能度量Metrics初始化(用的是codahale metrics,这个在开源软件中用的
还挺多的,Kafka用的也是这个),最后将使用了JMXReporter将性能监控暴露给JMX。
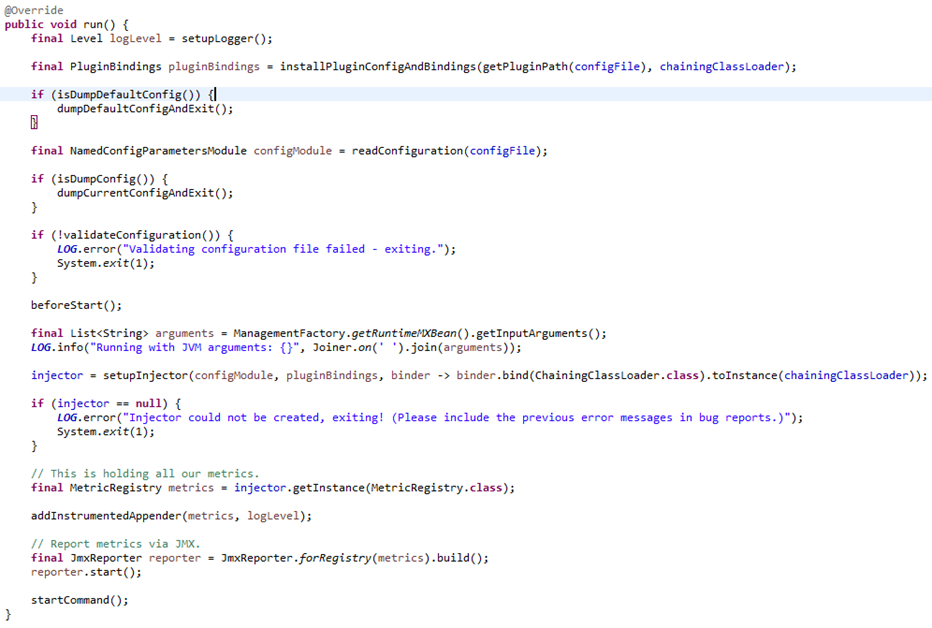
1. 插件加载(CmdLineTools类):
Graylog自定义了一个ClassLoader用于加载指定目录下的插件(ChainingClassLoader),将插件加载至内存后做了一个简单的版本校验。
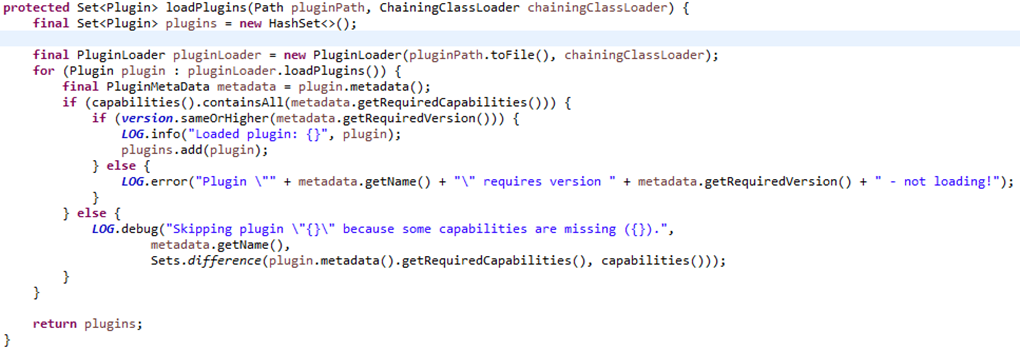
之前有提到Graylog插件采用的是Java SPI机制,可以在PluginLoader这个类中看到:

这里,终于看到了熟悉的ServiceLoader类,对SPI机制感兴趣的朋友,可以搜索相关文章。
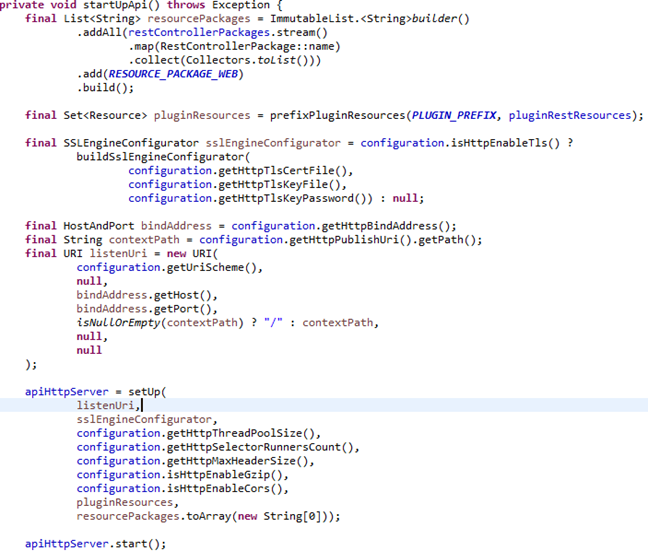
2.Rest接口服务(JerseyService类):
Rest方面,Graylog使用的是Jersey提供的web service,Jersey在国内好像一直不温不火,但是国外的开源项目里用到的还挺多的。
项目启动就介绍到这儿,Graylog在依赖注入方面,大量用到了Google的Guice框架,不过我对Guice一直是只闻其名,有机会再研究吧 :)。
二.Graylog的Journal机制
通常,在项目中,如果遇到大量日志处理问题,我们很可能会选择Kafka做消息队列,但在有些客户系统资源有限的情况下,消息队列集群显然是一个
奢侈的选择,Graylog的处理方式很有意思,它并没有完全实现自己的一套消息队列机制,而是使用了Kafka日志处理底层的API,你可以认为,Graylog
将Kafka做的一些工作(磁盘日志管理,日志缓冲,定时清理等)放到自己进程里进行。
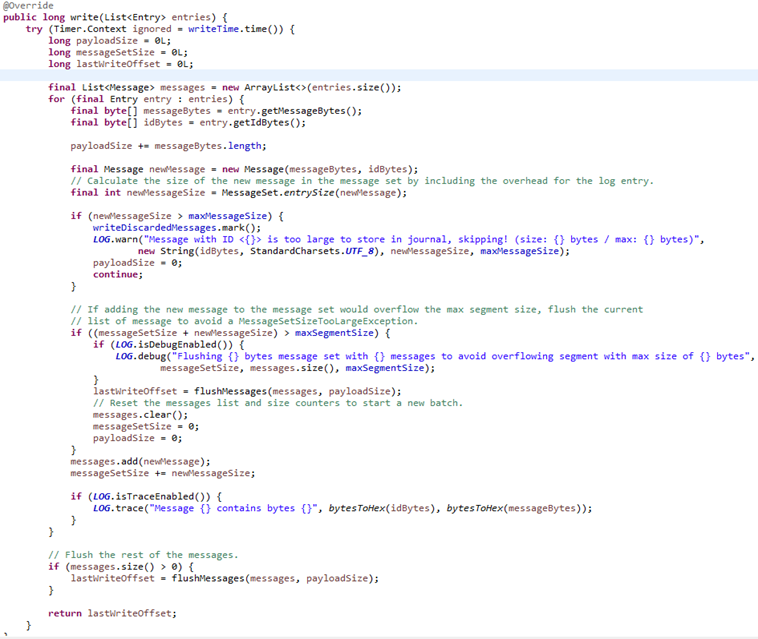
熟悉Kafka的朋友看到这里应该不会陌生了,Graylog同Kafka一样,将磁盘上的日志分为Segments进行管理。
我们来看下Graylog写入磁盘的文件,你会发现和Kafka并没有什么不同

此外Graylog中还有PeriodicalsService定时服务(负责系统所有定时任务),ActivityWriter用户操作入库服务.etc,比较简单,在此不一一列举.。
三. Graylog中的数据流转
说了这么多,Graylog既然是日志处理软件,那么一条来自系统外部的日志进入Graylog server后的处理流程是什么呢?
我将Graylog对日志的处理进行了简单的分层,数据的处理流程大致是:
系统外部的原始数据->Transport(数据传输层) -> Input(数据接入层)-> InputBuffer(接入层缓冲ringBuffer)-> Encoder/Decoder(数据编解码层)-> 自带的Kafka(可选)->Process Buffer(业务处理层缓冲ringBuffer)-> ProcessBufferProcessor(日志业务处理器) –> OutputBuffer(日志输出/入库/转发缓冲RingBuffer) –> OutputBufferProcessor(输出/入库/转发处理器)
下面以Kafka日志接入为例,看看数据在graylog的整体处理流程:
- 日志接入层(KafkaTransport):
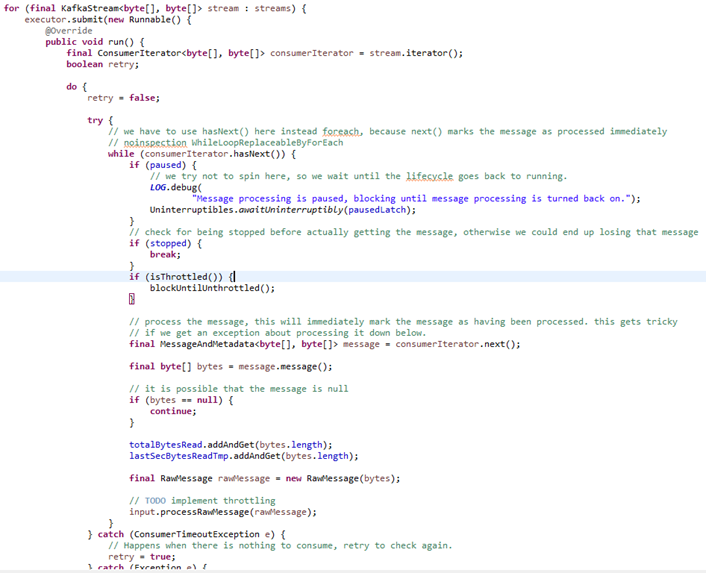
2.数据进入接入层缓冲(MessageInput)
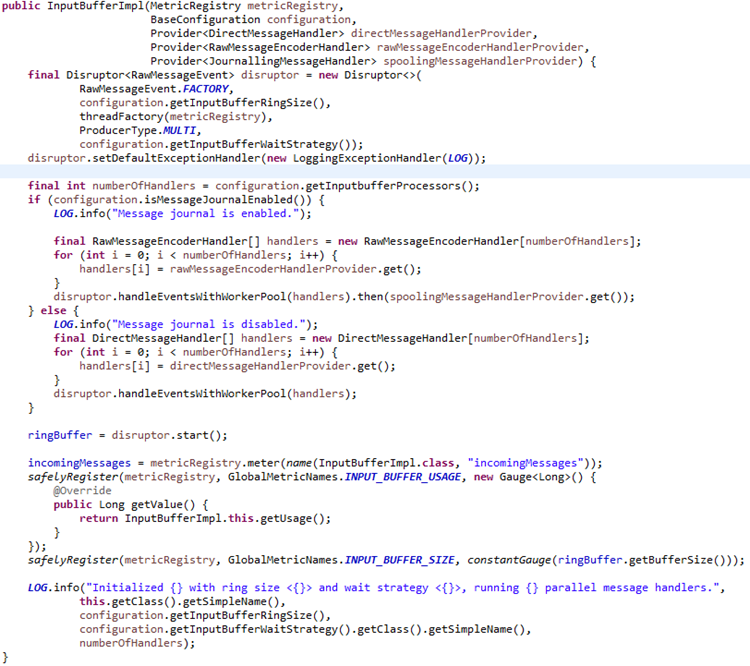
InputBufferImpl

3. 日志解码处理器+日志业务处理器+写入自带的Kafka,通过Disruptor Handler (InputBufferImpl)
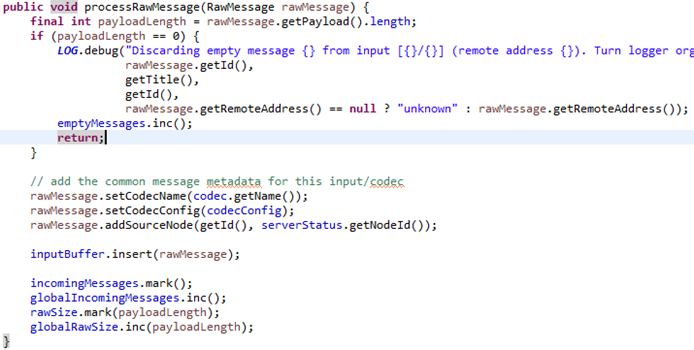
4. 日志直接写入业务逻辑缓冲RingBuffer(不通过Kafka)

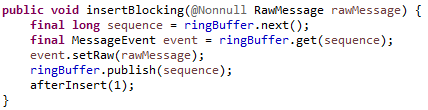
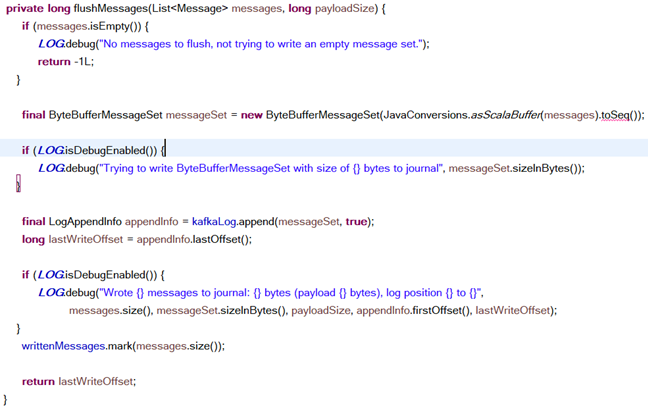
5. 日志写入kafka,由后续流程消费(JournallingMessageHandler)
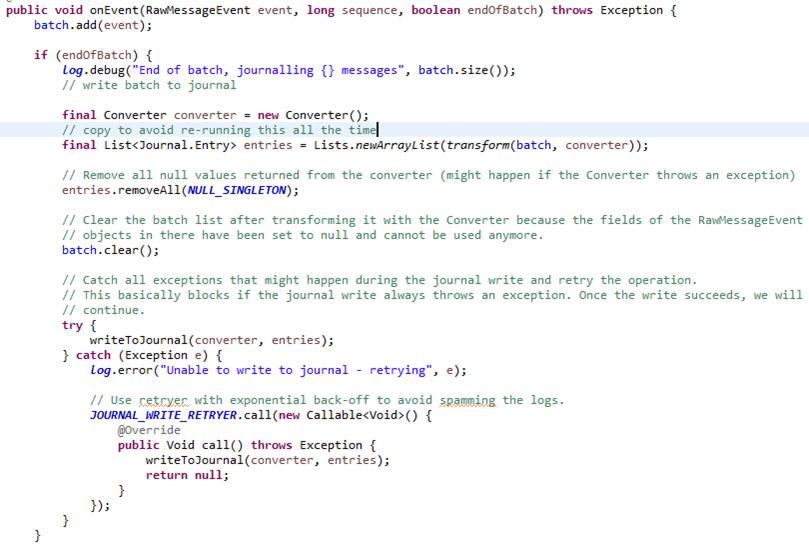
6. 一个后台线程,不断从自带的Kafka中读取数据,写入到下个流程的Buffer里(JournalReader类)
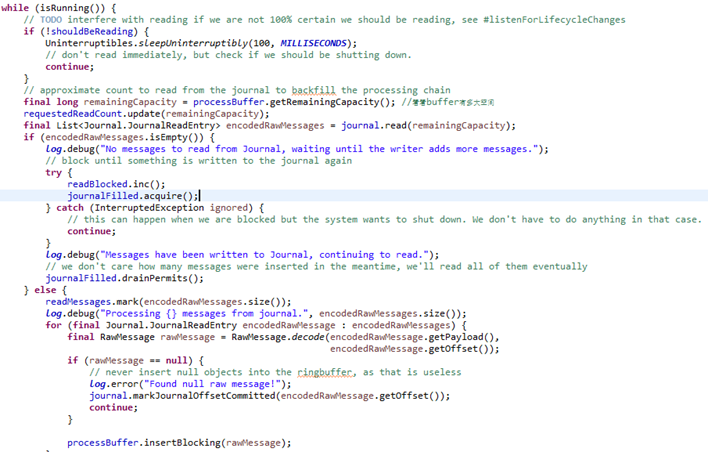
7. 业务处理器 ProcessBufferProcessor(graylog所有对日志进行的业务处理都绑定到了这个类里,如日志过滤,规则,威胁情报富化,地理位置富化,知识库…)

具体的处理器实现比较复杂,放到最后讲吧。
8. 数据输出/转发/入库Buffer

9. 数据输出(OutputBufferProcessor)
数据可能会有多个output,输出到output的过程是异步而且有时间限制,不会影响到系统整体吞吐量。
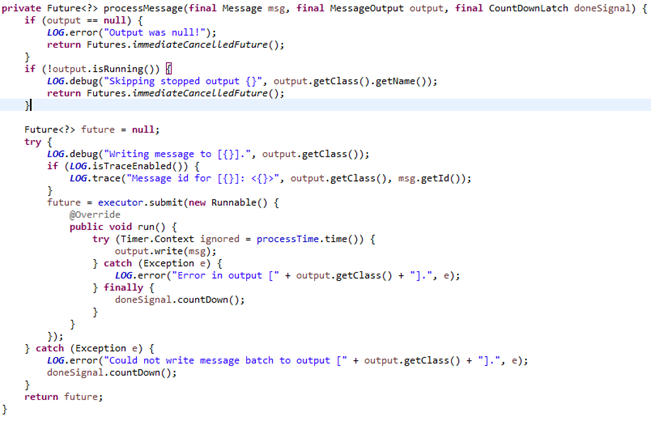
以写入ES为例(BlockingBatchedESOutput)

此外,系统还有一个线程负责定时将内存数据flush到ES,这里就不贴代码了。
10. MessageProcessor
系统自带的数据处理器包括GeoIpProcessor,MessageFilterChainProcessor,PipelineInterpreter
(1) GeoIpProcessor:数据富化(为原始日志添加地理位置,后续可视化时使用)

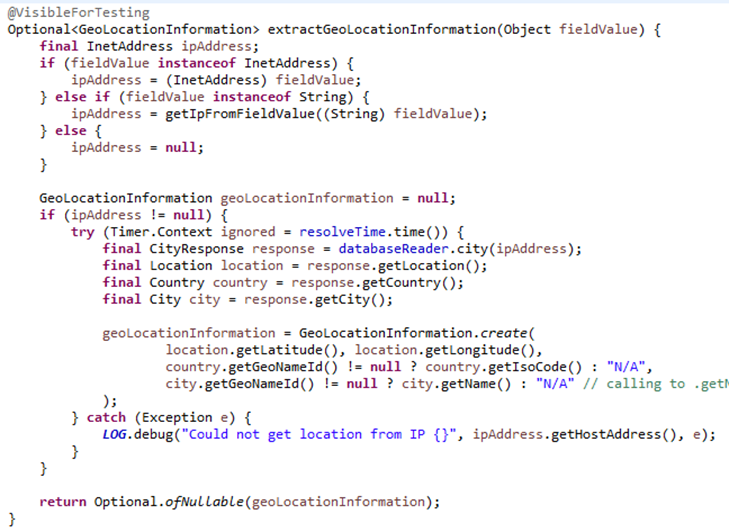
(2)MessageFilterChainProcessor(包含了所有的日志过滤器MessageFilter)

日志会一一经过排序后的过滤器,如果满足filter条件,标记为丢弃,并更新kafka offset。下面逐一分析过滤器。
Graylog源码分析的更多相关文章
- ABP源码分析一:整体项目结构及目录
ABP是一套非常优秀的web应用程序架构,适合用来搭建集中式架构的web应用程序. 整个Abp的Infrastructure是以Abp这个package为核心模块(core)+15个模块(module ...
- HashMap与TreeMap源码分析
1. 引言 在红黑树--算法导论(15)中学习了红黑树的原理.本来打算自己来试着实现一下,然而在看了JDK(1.8.0)TreeMap的源码后恍然发现原来它就是利用红黑树实现的(很惭愧学了Ja ...
- nginx源码分析之网络初始化
nginx作为一个高性能的HTTP服务器,网络的处理是其核心,了解网络的初始化有助于加深对nginx网络处理的了解,本文主要通过nginx的源代码来分析其网络初始化. 从配置文件中读取初始化信息 与网 ...
- zookeeper源码分析之五服务端(集群leader)处理请求流程
leader的实现类为LeaderZooKeeperServer,它间接继承自标准ZookeeperServer.它规定了请求到达leader时需要经历的路径: PrepRequestProcesso ...
- zookeeper源码分析之四服务端(单机)处理请求流程
上文: zookeeper源码分析之一服务端启动过程 中,我们介绍了zookeeper服务器的启动过程,其中单机是ZookeeperServer启动,集群使用QuorumPeer启动,那么这次我们分析 ...
- zookeeper源码分析之三客户端发送请求流程
znode 可以被监控,包括这个目录节点中存储的数据的修改,子节点目录的变化等,一旦变化可以通知设置监控的客户端,这个功能是zookeeper对于应用最重要的特性,通过这个特性可以实现的功能包括配置的 ...
- java使用websocket,并且获取HttpSession,源码分析
转载请在页首注明作者与出处 http://www.cnblogs.com/zhuxiaojie/p/6238826.html 一:本文使用范围 此文不仅仅局限于spring boot,普通的sprin ...
- ABP源码分析二:ABP中配置的注册和初始化
一般来说,ASP.NET Web应用程序的第一个执行的方法是Global.asax下定义的Start方法.执行这个方法前HttpApplication 实例必须存在,也就是说其构造函数的执行必然是完成 ...
- ABP源码分析三:ABP Module
Abp是一种基于模块化设计的思想构建的.开发人员可以将自定义的功能以模块(module)的形式集成到ABP中.具体的功能都可以设计成一个单独的Module.Abp底层框架提供便捷的方法集成每个Modu ...
随机推荐
- Mysql - 关于relay_log_recovery参数的测试
一.概述 官方文档中对relay_log_recovery参数的解释 Enables automatic relay log recovery immediately following server ...
- java Swing 界面化查询数据库表
两天从0基础写的.没有按钮对话框功能,只是简单的实现. 当然代码上有很多需要优化的,基本需要重写哈哈哈.但是我怕以后有需要所以还是存一下好了.<把RS结果集,放vector里面,用vector构 ...
- chsime.exe cpu占用高
打开管理员的命令提示符,运行 if exist "%SystemRoot%\System32\InputMethod\CHS\ChsIME.exe" (takeown /f &qu ...
- 23种设计模式之单例(Singleton Pattern)
单例 在软件系统中,经常有这样一些特殊的类,必须保证它们在系统中只存在一个实例(eg:应对一些特殊情况,比如数据库连接池(内置了资源) 全局唯一号码生成器),才能确保它们的逻辑正确性.以及良好的效率 ...
- Linux下查看版本信息
Linux下如何查看版本信息, 包括位数.版本信息以及CPU内核信息.CPU具体型号等. 1.# uname -a (Linux查看版本当前操作系统内核信息) 2.# cat /proc/ ...
- Hyperion: Building the Largest In memory Search Tree
Introduction 索引在数据管理中起到很重要的作用,很多索引结构都会采用访问速度快而且内存消耗少的trie树,但一般常见的trie树索引结构都强调效率而忽视内存的效率,他们的效率虽然高,但内存 ...
- 【linux】Tomcat 安装
登录linux后,切换目录到 /usr/local cd /user/local 在/usr/local目录新建文件夹servers用于存放tomcat文件 mkdir servers 在文件夹ser ...
- .Net Core删除ClientApp目录,重新生成报错解决办法
因为在老的项目上做修改,需要删除单独的spa目录,就把ClientApp删掉了.但是重新生成报错,在VS2017界面上也没找到在什么地方配置.最后发现在csproj上里面可以去掉spa的配置 < ...
- Java8新特性时间日期库DateTime API及示例
Java8新特性的功能已经更新了不少篇幅了,今天重点讲解时间日期库中DateTime相关处理.同样的,如果你现在依旧在项目中使用传统Date.Calendar和SimpleDateFormat等API ...
- Android开发——RecyclerView实现下载列表
本篇记录的是使用Jsoup框架爬取网页内容,结合Android的RecyclerView,从而实现批量下载小说的功能(也是我的APP星之小说下载器Android版的核心功能),思路仅供参考 本文使用了 ...