【论文阅读】Between-class Learning for Image Classification
文章:Between-class Learning for Image Classification
链接:https://arxiv.org/pdf/1711.10284.pdf
CVPR2018

作者尝试了将在音频上的方法用在图像上的,并提出了一种将图像作为波形处理的混合方法(作者认为图形波长融合人类没法识别,但对机器而言却是有意义的信息)。cnns有将输入数据作为波形处理的操作,作者提出的BC learning 其实就是将两个不同类的图像混合,并训练模型输出混合比,靠近哪个就分为哪类。

一、Between-Class learning (BC learning)
在分类问题的标准学习中,从数据集中选取一个单一的训练示例并输入到模型中。然后,该模型被训练为输出一个热标签。相比之下,在bc学习中,从数据集中选取了属于不同类的两个训练示例,并与随机比例混合。然后,将混合数据输入到模型中,并对模型进行了输出各类混合比的训练。模型的输出和比例标签之间KL-divergence(散度)作为损失函数,而不是通常的交叉熵损失。注意在测试阶段不进行混合。
BC learning旨在通过解决预测两个不同类的混合比例的问题来学习分类问题。它们通过将属于不同类的两个声音以随机比例混合在一起,生成了类之间的例子。然后将混合声音输入模型,并训练模型输出每个类的混合比。对特征分布施加限制,而这是标准学习所不能实现的,因此提高了泛化能力。在声音分类任务中取得了超过人类水平的性能。
举个例子,有两个类的集合{x1,t1},{x2,t2},x表示数据,t为它们的标签(one-hot编码表示)。按照一定的比例r将两个类混合,得到新的类别和标签{rx1+(1-r)x2,rt1+(1-r)t2}。当然这是最简单的融合方式。由于声能与振幅的平方成正比,通常表示成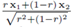 。换句话说,如果两个类的声压等级分别为G1,G2,则融合后的变成
。换句话说,如果两个类的声压等级分别为G1,G2,则融合后的变成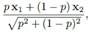
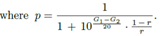 。
。
理论支持的话,从物理学上讲,两个人的声音混在一起,我们人类还是能分辨出来谁的声音大,BC learning根据这个提出的。。。。
二、BC learning 的效果(在音频上)
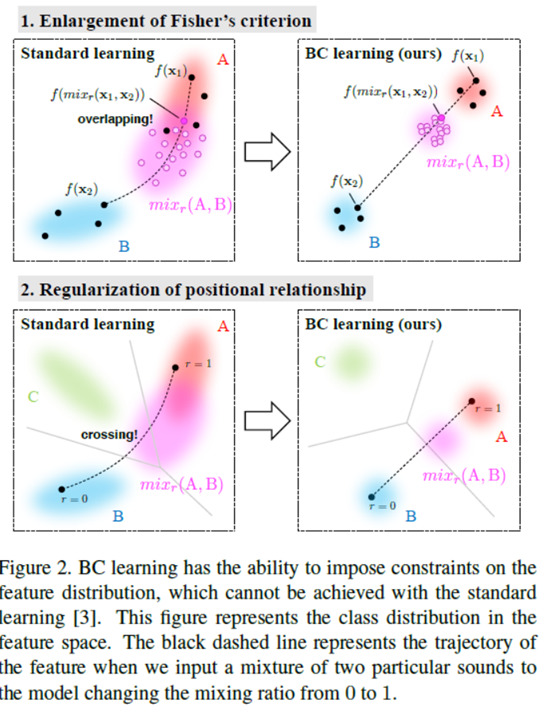
黑色虚线表示特征的轨迹,当我们输入两个特定声音的混合到模型中,将混合比从0改为1。
1模拟BC learning enlarges Fisher’s criterion。如果fisher在a类(红色)和b类(蓝色)的特征分布之间的标准很小,如图2(左上)所示,将类a和b按一定比例(品红)混合得到的声音的特征分布变得很大,并且会与类a和类b的一个或两个特征分布有很大的重叠。在这种情况下,模型不能输出投影到重叠区域的混合示例的混合比,并且bc学习给出了很大的损失。为了使模型输出混合比并使bc学习损失小,费舍尔的准则应该如图2(右上)所示是大的。在这种情况下,重叠会变得很小,bc学习会带来很小的损失。因此,bc学习扩大了费舍尔在特征空间中的标准
2考虑特征分布之间位置关系的正则化。如果每个类别的特征没有如图2所示的标准分布(左下),则除a和b类外,c类的判定边界将出现在a类和b类之间,而A类和B类的一些混合音会被错误地归为C类。这是一种不理想的情况,因为两个类的混杂音几乎不可能变成其他类的音。bc学习给这种情况带来很大的损失,因为bc学习训练模型输出a类和b类的混合比。如果每个类的特征如图2(右下)所示正则分布,另一方面,c类的判定边界不出现在a类和b类之间,该模型可以输出混音比,而不是将混音错归为c类。因此,bc学习的损失变得很小。因此,bc学习具有规范特征分布的位置关系的作用。通过这种方法,他们认为bc学习具有约束特征分布的能力,从而提高了泛化能力
三、为啥能用到图像上
图像作为像素值,可以通过二维傅里叶变换转换成各种频率区域的组件。而且一些卷积滤波器可以作为频率滤波器。因此,由于对机器来说,两张图像的混合物是两张波形的混合物,所以对声音有效的东西对图像也有效。当然,傅里叶变换、小波变换只是提出来时候怕麻烦找现成的,实验的时候是卷积网络办到的(卷积网络的确有这个方面的应用,不得不说一句,真是万能的卷积网络啊)。
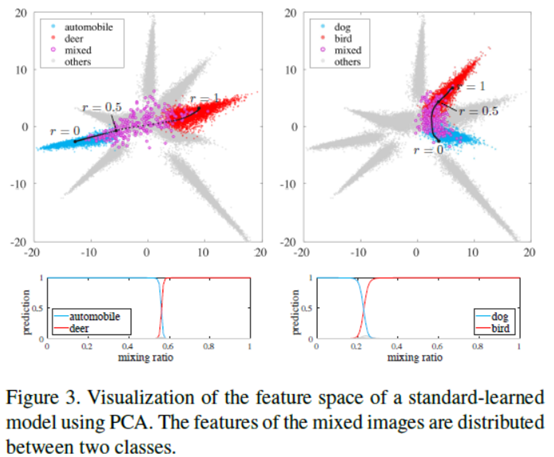
作者可视化了一下,用的是PCA。模型是CIFAR-10上的11层卷积,第10层卷积出来的特征图用PCA可视化。看起来图还是不错的,与之前在声音上的图挺相似的。哦,这里的混合比例是0.5:0.5.所以之后作者就改了混合比例改名为BC+。
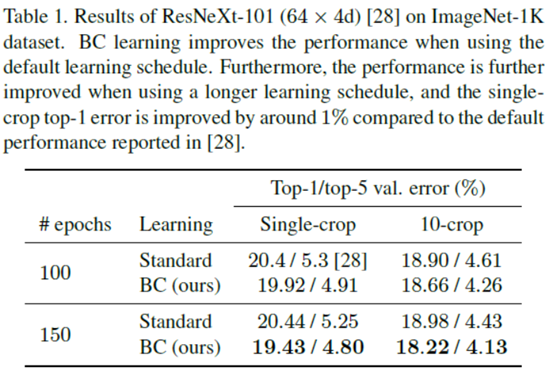
先看下BC learning的结果吧。
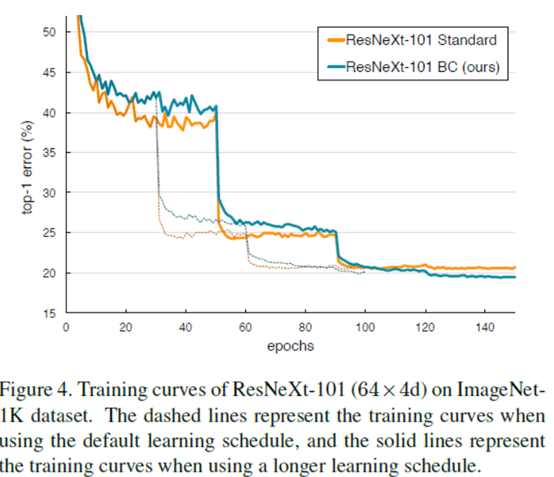
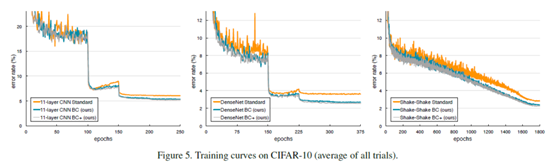
虚线表示使用默认学习计划时的训练曲线,实线表示使用较长学习计划时的训练曲线。像迭代次数衰减什么的直接去看文章吧,这里不说了。
其实BC+,就是考虑了音频的特性,把图像转换的和音频尽量相似。例如0均值啊,归一化啊什么的。然后混合起来就变成了
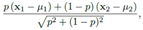
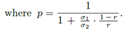
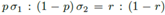 ,δ是方差,u是均值。
,δ是方差,u是均值。
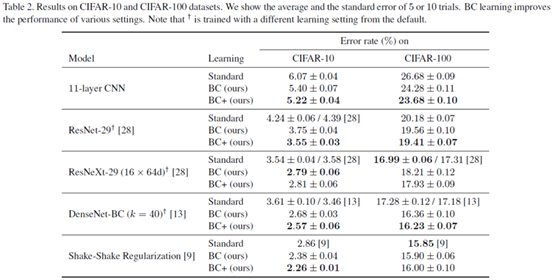
对比试验。没有太明显的下降。毕竟这篇文章主要是创意新,结果不那么差就够了。
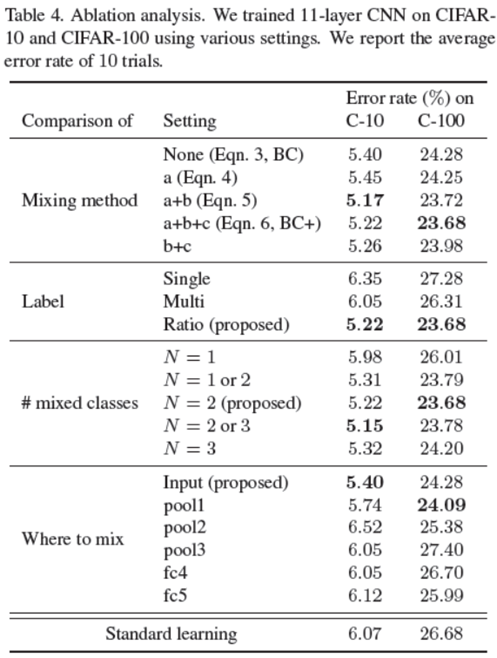
这里解释一下,mixing method那块,a表示每张图像减去这张图像素均值,b表示归一化了,c考虑了能量(振幅平方)。Label那块,single : t = t1 if r > 0.5, otherwise t = t2;;multi : t = t1 + t2。。#mix class那块,N=1: 两张图像来源于同一类。N=1or2:完全随机地选择两个图像,并且允许这两个图像有时是同一个类,有时是来自两个类。
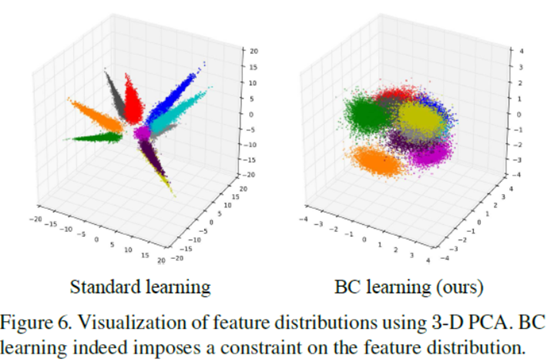
最后,我们在图6中可视化了标准和bc学习的特征(其实之前可视化的也是这个,不过只是选择了两个类上色,并画出了0.5:0.5的混合类)。我们将pca应用于11层cnn的第10层的激活,针对cifar-10的训练数据。如下图所示,bc学习所获得的特征是球状分布的,并且在班级内差异很小,而标准学习所获得的特征则是从近到远的决策边界上广泛分布的。我们对附录中的学习特征进行了进一步的分析。这样,bc学习确实对特征分布施加了限制,而标准学习是无法实现的。我们猜想这就是为什么bc学习提高了分类性能。
【论文阅读】Between-class Learning for Image Classification的更多相关文章
- [论文阅读笔记] Adversarial Learning on Heterogeneous Information Networks
[论文阅读笔记] Adversarial Learning on Heterogeneous Information Networks 本文结构 解决问题 主要贡献 算法原理 参考文献 (1) 解决问 ...
- 论文阅读:Multi-task Learning for Multi-modal Emotion Recognition and Sentiment Analysis
论文标题:Multi-task Learning for Multi-modal Emotion Recognition and Sentiment Analysis 论文链接:http://arxi ...
- 论文阅读 Inductive Representation Learning on Temporal Graphs
12 Inductive Representation Learning on Temporal Graphs link:https://arxiv.org/abs/2002.07962 本文提出了时 ...
- 【论文阅读】CVPR2022: Learning from all vehicles
Column: March 23, 2022 1:08 PM Last edited time: March 23, 2022 11:13 PM Sensor/组织: 现leaderboard第一名, ...
- [论文阅读] Deep Residual Learning for Image Recognition(ResNet)
ResNet网络,本文获得2016 CVPR best paper,获得了ILSVRC2015的分类任务第一名. 本篇文章解决了深度神经网络中产生的退化问题(degradation problem). ...
- 论文阅读《End-to-End Learning of Geometry and Context for Deep Stereo Regression》
端到端学习几何和背景的深度立体回归 摘要 本文提出一种新型的深度学习网络,用于从一对矫正过的立体图像回归得到其对应的视差图.我们利用问题(对象)的几何知识,形成一个使用深度特征表示的代价量(c ...
- 论文阅读:MDNet: Learning Multi-Domain Convolutional Neural Networks for Visual Tracking
前言 CVPR2016 来自Korea的POSTECH这个团队 大部分算法(例如HCF, DeepLMCF)只是用在大量数据上训练好的(pretrain)的一些网络如VGG作为特征提取器,这些做法 ...
- Deep Reinforcement Learning for Dialogue Generation 论文阅读
本文来自李纪为博士的论文 Deep Reinforcement Learning for Dialogue Generation. 1,概述 当前在闲聊机器人中的主要技术框架都是seq2seq模型.但 ...
- 论文阅读笔记 Improved Word Representation Learning with Sememes
论文阅读笔记 Improved Word Representation Learning with Sememes 一句话概括本文工作 使用词汇资源--知网--来提升词嵌入的表征能力,并提出了三种基于 ...
随机推荐
- Vue优化:常见会导致内存泄漏问题及优化
1. 监听在window/body等事件没有解绑2. 绑在EventBus的事件没有解绑3. 模块形成的闭包内部变量使用完后没有置成null4. 使用第三方库创建,没有调用正确的销毁函数5 . ech ...
- 下载达 10 万次的 IDEA 插件,K8s 一键部署了解一下?
作者 | 铃儿响叮当 导读:涉及开发的技术人员,永远绕不开的就是将应用部署到相应服务器上,本文将给大家讲解:对于容器服务 ACK,怎么实现真正"一键部署",提高开发部署效率,在 K ...
- mp-vue实现小程序回顶操作踩坑,wx.pageScrollTo使用无效填坑
本来项目都写的差不多了,测试测着侧着就冒出了新的想法,我因为做的是问卷,因此会有用户必答题未答完的可能存在,本来市场部给的需求就是做一个弹窗就好了,她说想要做出跳回到用户未答的第一道题,好吧,既然都这 ...
- LNMP与LAMP的工作原理
LAMP的实现原理 LAMP=Linux+Apache+Mysql+PHP.#工作原理:浏览器向服务器发送http请求,服务器 (Apache) 接受请求,由于php作为Apache的组件模块也会一 ...
- 获取用户地理位置.html
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- dom 创建时间
下面讲述如何在页面生成一个装有日期的盒子 首先写出一个日期的函数进行赋值使用document.createElement创建一个文档节点div,然后将时间函数输出在div之中,利用document.b ...
- JVM三部曲之运行时数据区 (第一部)
在接下来的几天想总结下,JVM相关的一些内容,比如下面的这三个内容算是比较核心知识点了 1.运行时数据区域: 在运行时数据区里存储类Class文件元数据(方法区),对象和数组(堆),方法参数局部变量( ...
- Java对象"后事处理"那点事儿——垃圾回收(一)
1.Dead Or Alive 我们都知道对象死亡的时候需要进行垃圾回收来回收这些对象从而释放空间,那么什么样的对象算是死亡呢,有哪些方法可以找出内存中的死亡对象呢?一般来说,我们可以这样认为:如果内 ...
- SAP Web Service简介与配置方法
[版权声明]本文为博主原创文章,转载请在明显位置注明出处. 一. SAP Web Service简介 二. SAP Web Service配置准备工作 1. 通过RZ10配置服务器名称和其他参数 2. ...
- [wcp部署]Linux(Ubuntu)安装部署WCP
1.安装JAVA运行环境 配置环境变量及安装jdk mkdir /usr/local/java tar -zxvf jdk-8u31-linux-x64.gz #解压jdk包 mv jdk1.8.0_ ...