ORM之EF初识
之前有写过ef的codefirst,今天来更进一步认识EF!
一:EF的初步认识
ORM(Object Relational Mapping):对象关系映射,其实就是一种对数据访问的封装。主要实现流程如下图:
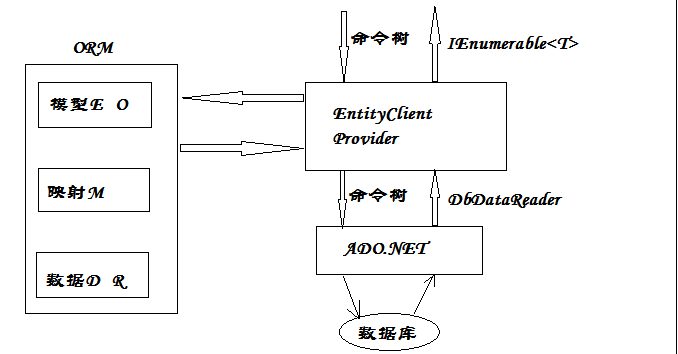
EF:是一种通过映射操作实现数据交互的ORM框架技术
今天我们主要先初步认识一下EF6,EntityFramwork6能支持多数据库;支持函数,存储过程;并且跟VS集成的比较好;能够跟项目完美结合;能基本实现增删改查,里面有两个主要的组成部分:Context(映射数据库实例)和实体类(跟数据库的映射关系表)
Visual Studio可以使用四种方式来创建EF的项目,分别如下:
第一是:EntityFramework DBFirst,这个是数据库优先,传统的开发模式,有个很重的edmx
第二种是:EntityFramework codeFirst from db && codeFirst,这个代码先行,不关心数据库,从业务出发,然后能自动生成数据库。
二:ef中我们如果想要看到底层生成的sql语句,有两种方式:
1:使用sqlserver中的sqlprofiler 监测工具,这个每次执行都会得到相应的sql的
2:在项目中添加context.Database.Log += s => Console.WriteLine($"当前执行sql:{s}"); 这个会把每次操作数据库的日志全部打印出来的,有兴趣的可以自己试一下。
三:如果数据库的字段跟项目中实体的字段名字不匹配,可以通过下面三种方式来实现:
1:使用特性直接完成,比如在实体类头部或者字段头部增加对应的特性,如下面的【Table】和【Column】等特性:
[Table("JD_Commodity_001")]
public partial class JDCommodity001
{
public int Id { get; set; }
public long? ProductId { get; set; }
public int? CategoryId { get; set; }
[StringLength()]
[Column("Title")]
public string Text { get; set; }
}
2:在DbContext中的OnModelCreating中完成链式映射,具体代码如下:
protected override void OnModelCreating(DbModelBuilder modelBuilder)
{
Database.SetInitializer(new CreateDatabaseIfNotExists<CodeFirstFromDBContext>()); modelBuilder.Entity<JDCommodity002>()
.ToTable("JD_Commodity_002")
.Property(c => c.Text).HasColumnName("Title");
}
3:DbContext中的OnModelCreating中增加配置文件,具体代码如下:
A:首先先创建JDCommodity003Mapping映射类然后继承于 EntityTypeConfiguration<JDCommodity003>,具体如下:
public class JDCommodity003Mapping : EntityTypeConfiguration<JDCommodity003>
{
public JDCommodity003Mapping()
{
this.ToTable("JD_Commodity_003");
this.Property(c => c.Text).HasColumnName("Title");
}
}
B:然后在DbContext中的OnModelCreating增加配置文件:
protected override void OnModelCreating(DbModelBuilder modelBuilder)
{
modelBuilder.Configurations.Add(new JDCommodity003Mapping());
}
通过上面三种方式都能实现实体类与数据库表对应的映射。
四:EF中复杂的查询以及写sql语句进行查询
1:EF普通的查询,使用IQuerable和linq的方式查询,如下:
#region 其他查询
using (JDDbContext dbContext = new JDDbContext())
{
{
var list = dbContext.Users.Where(u => new int[] { , , , , , , , , , , }
.Contains(u.Id));//in查询
//这些都是延迟加载,只有用到list的话才会实际去查询数据库
foreach (var user in list)
{
Console.WriteLine(user.Name ?? "Name为空");
}
}
{
//没有任何差别,只有写法上的熟悉
var list = from u in dbContext.Users
where new int[] { , , , , , , , , , , }.Contains(u.Id)
where u.Id>
select u;
//上面这个也是延迟加载,只有用到list的话才会实际去查询数据库
foreach (var user in list)
{
Console.WriteLine(user.Name??"name为空");
}
}
{
var list = dbContext.Users.Where(u => new int[] { , , , , , , , , , , , , , , , , }.Contains(u.Id))
.OrderBy(u => u.Id)
.Select(u => new
{
Account = u.Account,
Pwd = u.Password
}).Skip().Take();
foreach (var user in list)
{
Console.WriteLine(user.Pwd);
}
}
{
var list = (from u in dbContext.Users
where new int[] { , , , , , , , , , , }.Contains(u.Id)
orderby u.Id
select new
{
Account = u.Account,
Pwd = u.Password
}).Skip().Take(); foreach (var user in list)
{
Console.WriteLine(user.Account);
}
} {
var list = dbContext.Users.Where(u => u.Name.StartsWith("小") && u.Name.EndsWith("新"))
.Where(u => u.Name.EndsWith("新"))
.Where(u => u.Name.Contains("小新"))
.Where(u => u.Name.Length < )
.OrderBy(u => u.Id); foreach (var user in list)
{
Console.WriteLine(user.Name);
}
}
{
var list = from u in dbContext.Users
join c in dbContext.Companies on u.CompanyId equals c.Id
where new int[] { , , , , , , }.Contains(u.Id)
select new
{
Account = u.Account,
Pwd = u.Password,
CompanyName = c.Name
};
foreach (var user in list)
{
Console.WriteLine("{0} {1}", user.Account, user.Pwd);
}
}
{
var list = from u in dbContext.Users
join c in dbContext.Categories on u.CompanyId equals c.Id
into ucList
from uc in ucList.DefaultIfEmpty()
where new int[] { , , , , , , }.Contains(u.Id)
select new
{
Account = u.Account,
Pwd = u.Password
};
foreach (var user in list)
{
Console.WriteLine("{0} {1}", user.Account, user.Pwd);
}
}
}
#endregion
2:EF自定义sql语句,然后EF框架自己调用sql执行sql,可以使用ado.net自带的事务来操作。
#region 自定义sql,然后ef框架调用
using (JDDbContext dbContext = new JDDbContext())
{
{
DbContextTransaction trans = null;
try
{
trans = dbContext.Database.BeginTransaction();
string sql = "Update [User] Set Name='小新' WHERE Id=@Id";
SqlParameter parameter = new SqlParameter("@Id", );
dbContext.Database.ExecuteSqlCommand(sql, parameter);
trans.Commit();
}
catch (Exception ex)
{
if (trans != null)
trans.Rollback();
throw ex;
}
finally
{
trans.Dispose();
}
}
{
DbContextTransaction trans = null;
try
{
trans = dbContext.Database.BeginTransaction();
string sql = "SELECT * FROM [User] WHERE Id=@Id";
SqlParameter parameter = new SqlParameter("@Id", );
List<User> userList = dbContext.Database.SqlQuery<User>(sql, parameter).ToList<User>();
trans.Commit();
}
catch (Exception ex)
{
if (trans != null)
trans.Rollback();
throw ex;
}
finally
{
trans.Dispose();
}
}
}
#endregion
五:EF的IQuerable延迟和IEnumerable的延迟加载的比较跟区别,首先我们写了一个例子如下:
#region
//userList是IQueryable类型,数据在数据库里面,
//这个list里面有表达式目录树---返回值类型--IQueryProvider(查询的支持工具,sqlserver语句的生成)
//其实userList只是一个包装对象,里面有表达式目录树,有结果类型,有解析工具,还有上下文,
//真需要数据的时候才去解析sql,执行sql,拿到数据的---因为表达式目录树可以拼装;
IQueryable<User> sources = null;
using (JDDbContext dbContext = new JDDbContext())
{
sources = dbContext.Set<User>().Where(u => u.Id > );
//延迟查询也要注意:a 迭代使用时,用完了关闭连接 b 脱离context作用域则会异常
foreach (var user in sources)//sources必须在该dbContext的using范围内使用
{
Console.WriteLine(user.Name);
}
Console.WriteLine("&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&"); var userList = dbContext.Set<User>().Where(u => u.Id > );//1 这句话执行完,没有数据库查询
foreach (var user in userList)//2 迭代遍历数据才去数据库查询--在真实需要使用数据时,才去数据库查询的
{
Console.WriteLine(user.Name);
}
//IEnumerator
//这就是延迟查询,可以叠加多次查询条件,一次提交给数据库;可以按需获取数据;
userList = userList.Where(u => u.Id < );
userList = userList.Where(u => u.State < );
userList = userList.OrderBy(u => u.Name); var list = userList.ToList<User>();//ToList() ,Count(), FitstOrDefalut()都会自动去调用数据库
}
//这个时候查询,已经超出作用域。会异常,所以必须在using范围内使用
//foreach (var user in sources)
//{
// Console.WriteLine(user.Name);
//} //intList实现了IEnumerable类型,这里是延迟的,其实数据已经在内存里,利用的是迭代器的方式,每次去迭代访问时,才去筛选一次,委托+迭代器
{
List<int> intList = new List<int>() { , , , , , , , , , , , , , , };
var list = intList.Where(i =>
{
Thread.Sleep(i);
return i > ;
});//没有过滤
foreach (var i in list)//才去过滤
{
Console.WriteLine(i);
}
Console.WriteLine("*********************");
}
#endregion
1:IEnumerable:利用的是迭代器的方式,每次去迭代访问时,才去筛选一次,委托+迭代器
2:IQueryable:只是一个包装对象,里面有表达式目录树,有结果类型,有解析工具,还有上下文,真需要数据的时候才去解析sql,执行sql,拿到数据的---因为表达式目录树可以拼装;
六:EF状态的跟踪变化
1:ef内置的监控
User userNew = new User()
{
Account = "Admin",
State = ,
CompanyId = ,
CompanyName = "万达集团",
CreateTime = DateTime.Now,
CreatorId = ,
Email = "loverwangshan@qq.com",
LastLoginTime = null,
LastModifierId = ,
LastModifyTime = DateTime.Now,
Mobile = "",
Name = "intitName",
Password = "",
UserType =
};
using (JDDbContext context = new JDDbContext())
{
Console.WriteLine(context.Entry<User>(userNew).State);//实体跟context没关系 Detached
userNew.Name = "小鱼";
context.SaveChanges();//如果状态为Detached的时候,SaveChanges什么也不会做的 context.Users.Add(userNew);
Console.WriteLine(context.Entry<User>(userNew).State);//Added context.SaveChanges();//插入数据(自增主键在插入成功后,会自动赋值过去)
Console.WriteLine(context.Entry<User>(userNew).State);//Unchanged(跟踪,但是没变化) userNew.Name = "加菲猫";//一旦任何字段修改----内存clone
Console.WriteLine(context.Entry<User>(userNew).State);//Modified
context.SaveChanges();//更新数据库,因为状态是Modified
Console.WriteLine(context.Entry<User>(userNew).State);//Unchanged(跟踪,但是没变化) context.Users.Remove(userNew);
Console.WriteLine(context.Entry<User>(userNew).State);//Deleted
context.SaveChanges();//删除数据,因为状态是Deleted
Console.WriteLine(context.Entry<User>(userNew).State);//Detached已经从内存移除了
}
通过执行上面的代码,我们能看到每一步的操作状态,其实EF本身是依赖监听变化,如果有任何字段发生改变(会拿当前字段的值跟内存进行比较因此晓得是否发生改变),则会把context.Entry<User>(user20).State修改为Modified的,然后SaveChanges是以context为标准的,如果监听到任何数据的变化,会一次性的保存到数据库去,而且会开启事务!
2:因为EF默认会对与context的对象有关系的一些实体进行监控,如果仅仅是做查询而不会做更新,则不需要监控,以提高效率,下面代码是取消监控:
using (JDDbContext context = new JDDbContext())
{
//如果获取对象仅仅为了查询,而不会对其修改,则没有必要进行监听某个对象,
//可以使用AsNoTracking取消监听,这样可以提高一些效率
User user21 = context.Users.Where(u => u.Id == ).AsNoTracking().FirstOrDefault();
Console.WriteLine(context.Entry<User>(user21).State); //Detached
}
3:EF追踪对象的三种方式如下:
User user = null;//声明一个新的对象
using (JDDbContext context = new JDDbContext())
{
User user20 = context.Users.Find();
Console.WriteLine(context.Entry<User>(user20).State);
user = user20;
} user.Name = "滑猪小板123456789";
using (JDDbContext context = new JDDbContext())
{
Console.WriteLine(context.Entry<User>(user).State); //因为user是新的字段,跟context么有关系,所以是Detached //第一种:如果user是新的对象,与context没有关系,则先使用Attach建立关系,然后修改字段
//context.Users.Attach(user);//使user跟context建立关系
//Console.WriteLine(context.Entry<User>(user).State);//Unchanged
//user.Name = "滑猪小板";//只能更新这个字段
//Console.WriteLine(context.Entry<User>(user).State);//Modified //第二种:强制指定State的状态为:EntityState.Modified,这个是默认所有的字段都会追踪
context.Entry<User>(user).State = EntityState.Modified;//全字段更新
Console.WriteLine(context.Entry<User>(user).State);//Modified //第三种:使用context直接查询出来的字段,是默认监听的
user = context.Users.Find(user.Id);//查出来自然是监听
user.Name = "ddds";
Console.WriteLine(context.Entry<User>(user).State);//Modified context.SaveChanges();
}
刚刚有个设置整个对象的字段更新,可以通过:context.Entry<User>(user5).Property("Name").IsModified = true来指定某字段被改过 !
七:EF内置的一些缓存
using (JDDbContext context = new JDDbContext())
{
var userList = context.Users.Where(u => u.Id > ).ToList();
//var userList = context.Users.Where(u => u.Id > 10).AsNoTracking().ToList();
Console.WriteLine(context.Entry<User>(userList[]).State);
Console.WriteLine("*********************************************");
var user5 = context.Users.Find();
Console.WriteLine("*********************************************");
var user1 = context.Users.Find();
Console.WriteLine("*********************************************");
var user2 = context.Users.FirstOrDefault(u => u.Id == );
Console.WriteLine("*********************************************");
var user3 = context.Users.Find();
Console.WriteLine("*********************************************");
var user4 = context.Users.FirstOrDefault(u => u.Id == );
}
Find可以使用缓存,优先从内存查找(限于同一个context),但是linq时不能用缓存,每次都是要查询的
八:DbContext的一些声明周期以及用法
1:DbContext的SaveChanges是开启事务的,任何一个失败直接全部失败,如下:
#region 多个数据操作一次savechange,任何一个失败直接全部失败
using (JDDbContext dbContext = new JDDbContext())
{
User userNew = new User()
{
Account = "Admin",
State = ,
CompanyId = ,
CompanyName = "万达集团",
CreateTime = DateTime.Now,
CreatorId = ,
Email = "dddd@qq.com",
LastLoginTime = null,
LastModifierId = ,
LastModifyTime = DateTime.Now,
Mobile = "",
Name = "aaa",
Password = "",
UserType =
};
dbContext.Users.Add(userNew); User user17 = dbContext.Users.FirstOrDefault(u => u.Id == );
user17.Name += "aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa"; User user18 = dbContext.Set<User>().Find();
user18.Name += "bbb"; //Company company2019 = dbContext.Set<Company>().Find(2019);
//dbContext.Companies.Remove(company2019); dbContext.SaveChanges();
}
#endregion
2:多context实例 join 不行,因为上下文环境不一样;除非把数据都查到内存,再去linq,如下代码会报错:
using (JDDbContext dbContext1 = new JDDbContext())
using (JDDbContext dbContext2 = new JDDbContext())
{
var list = from u in dbContext1.Users
join c in dbContext2.Companies on u.CompanyId equals c.Id
where new int[] { , , , , , , }.Contains(u.Id)
select new
{
Account = u.Account,
Pwd = u.Password,
CompanyName = c.Name
};
foreach (var user in list)
{
Console.WriteLine("{0} {1}", user.Account, user.Pwd);
}
}
3:context的一些使用建议:
- DbContext是个上下文环境,里面内置对象跟踪,会开启链接(就等于一个数据库链接)
- 一次请求,最好是一个context;
- 多个请求 /多线程最好是多个实例;
- 用完尽快释放;
九:多个数据源的事务
在第八条我们晓得不同的DbContext是没办法jioin联合查询的,那现在如果有一个需求,如果我想操作不同的数据源,又想放在一个事务里面统一操作,这个需要怎么做呢,.net帮我们提供了一个TransactionScope,具体实现如下:
using (JDDbContext dbContext1 = new JDDbContext())
using (JDDbContext dbContext2 = new JDDbContext())
{
using (TransactionScope trans = new TransactionScope())
{
User userNew1 = new User()
{
Account = "Admin",
State = ,
CompanyId = ,
CompanyName = "wwww",
CreateTime = DateTime.Now,
CreatorId = ,
Email = "dddd@qq.com",
LastLoginTime = null,
LastModifierId = ,
LastModifyTime = DateTime.Now,
Mobile = "adfadf",
Name = "民工甲123333333",
Password = "",
UserType =
};
dbContext1.Set<User>().Add(userNew1);
dbContext1.SaveChanges(); SysLog sysLog = new SysLog()
{
CreateTime = DateTime.Now,
CreatorId = userNew1.Id,
LastModifierId = ,
LastModifyTime = DateTime.Now,
Detail = "",
Introduction = "sadsfghj",
LogType = ,
UserName = "zhangsanan2zhangsanan2zhangsanan2zhangsanan2333333333"
};
dbContext2.Set<SysLog>().Add(sysLog);
dbContext2.SaveChanges(); trans.Complete();//能执行这个,就表示成功了;
}
}
这样就能实现不同的数据源使用同一个事务了。
十:EF的导航属性
如果EF中有表对应的关系,一对多一对一,则如果想要查询出来一个表的同时把另外一个表也对应的查询出来,则可以使用导航属性,比如我们一个用户表属于某个公司,再查询用户表的时候想要把公司的信息给带出来,则可以进行如下操作:
[Table("User")]
public partial class User
{
public int Id { get; set; }
public int CompanyId { get; set; }
[StringLength()]
public string CompanyName { get; set; }
public int State { get; set; }
public int UserType { get; set; }
public DateTime? LastModifyTime { get; set; }
[ForeignKey("CompanyId")]
public virtual Company Company { get; set; }
}
注意:一般导航属性,实体与主键对应最好使用ForeignKey来标识一下,不要使用.netFramwork对应的框架那种默认方式去做,比较不明确。
然后查询如下:
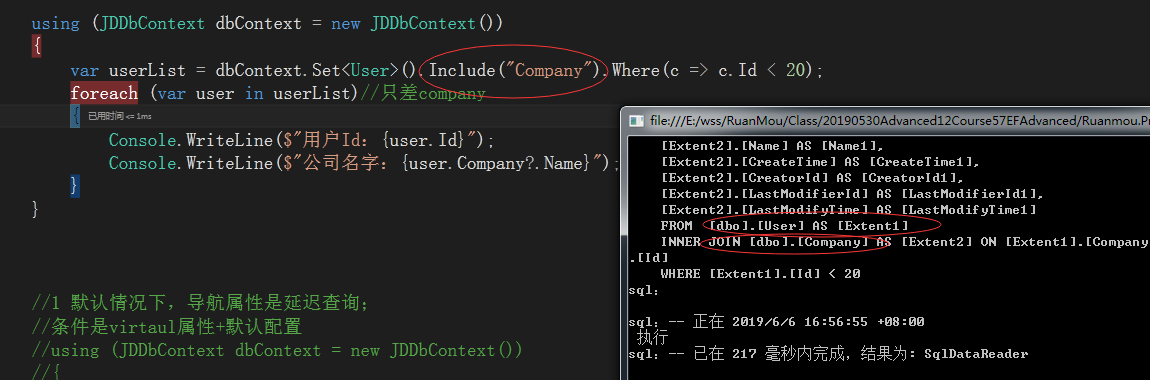
using (JDDbContext dbContext = new JDDbContext())
{
var userList = dbContext.Set<User>().Where(c => c.Id < );
foreach (var user in userList)//只差company
{
Console.WriteLine($"用户Id:{user.Id}");
Console.WriteLine($"公司名字:{user.Company?.Name}"); //每次会重新去加载用户信息
}
}
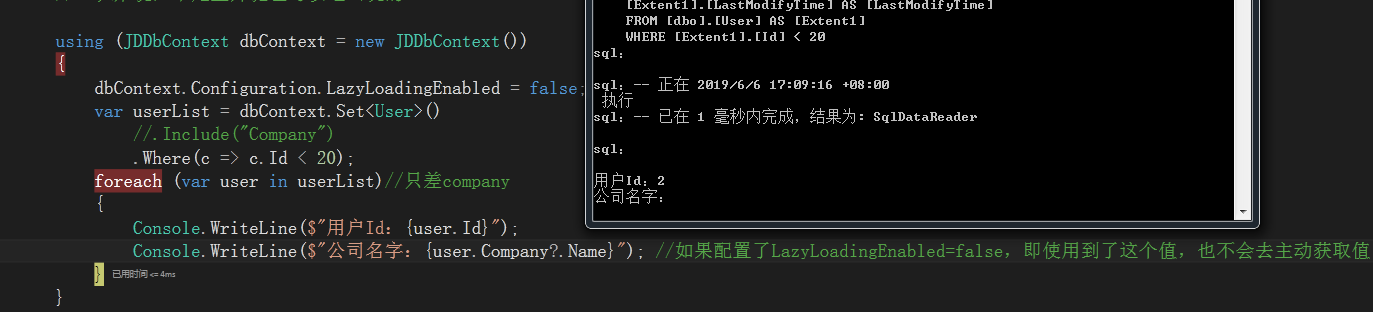
导航加载是懒加载,就是只有用到才会去读取。比如每次使用到user.Company都会重新去查询数据。所以这样会增加了对数据库的频繁打开跟关闭。如果要禁止懒加载,可以通过下面的Include来强制加载:
如果想要禁止懒加载,即每次查询的时候,也不想去查询数据,可以通过下面的方式来配置:
ORM之EF初识的更多相关文章
- 分库分表、读写分离——用Sql和ORM(EF)来实现
分库:将海量数据分成多个库保存,比如:2017年的订单库——Order2017,2018年的订单库——Order2018... 分表:水平分表(Order拆成Order1.....12).垂直分表(O ...
- ORM框架EF
应用程序和数据库采用Tcp协议通讯 ORM框架有: NHibernate ,Dapper ,Mybatis 底层是 ADO.Net 好处: 1.面向对象 2.没有sql减少学习成本,快速开发 3.编译 ...
- ORM之EF
本文大部分内容截取自博客: http://www.cnblogs.com/VolcanoCloud/p/4475119.html (一) 为什么用ORM 处理关系数据库时,我们依据由行和列组成的表, ...
- MVC系列学习(二)-初步了解ORM框架-EF
1.新建 一个控制台项目 2.添加一个数据项 a.选择数据库 注:数据库中的表如下: b.选择EF版本 c.选择表 3.初步了解EF框架 看到了多了一个以 edmx后缀的文件 在edmx文件上,右击打 ...
- ORM框架 EF - code first 的封装
Code first 是Microsoft Entity Framework中的一种模式,CodeFirst不会有可视化的界面来进行拖动编辑DataBase-Entity,但会以一个类来进行对数据表关 ...
- ORM框架 EF - code first 的封装 优化一
上一节我们讲到对EF(EntityFramework)的初步封装,任何事情都不可能一蹴而就,通过大量的实际项目的实战,也发现了其中的各种问题.在这一章中,我们对上一章的EF_Helper_DG进行优化 ...
- ORM 之 EF的使用(一)
早期对数据库进行操作 通过Ado.Net 操作数据库 需要操作sqlCommand/sqlConnection/adapter/datareader 如图 后来 基于面向对象的思想 出现了中间件ORM ...
- 模拟EF CodeFist 实现自己的ORM
一.什么是ORM 对象关系映射(Object Relational Mapping,简称ORM)模式是一种为了解决面向对象与关系数据库存在的互不匹配的现象的技术. 简单来说,ORM 是通过使用描述对象 ...
- ASP.NET MVC学习---(一)ORM框架,EF实体数据模型简介
现如今 对象关系映射(ORM)框架 被大量的使用于企业级应用的开发 为什么要使用ORM? ADO.NET操作数据库不好吗? 我们可以仔细想想 当我们使用ADO.NET操作数据库的时候 我们需要先获取连 ...
随机推荐
- 深度学习accuracy
accuracy=(1+3)/(1+2+3+4),即在所有样本(例子)中做出正确预测的的比例,或者说正确预测的样本数占总预测样本数的比值. precision=(1)/(1+2),指的是正确预测的正样 ...
- arduino雨滴传感器
https://blog.csdn.net/yichu5074/article/details/81074055 功能介绍:接上5V电源,电源指示灯亮,感应板上没有水滴时,DO输出为高电平,开关指示灯 ...
- [LeetCode] 300. Longest Increasing Subsequence 最长递增子序列
Given an unsorted array of integers, find the length of longest increasing subsequence. Example: Inp ...
- BBS 03day
目录 BBS_03 day: 自定义标签 过滤器: 文章的点赞,点彩功能: 文章的评论功能 transaction用法: 自定义 标签代码展示: BBS_03 day: 自定义标签 过滤器: --&g ...
- [LeetCode] 115. Distinct Subsequences 不同的子序列
Given a string S and a string T, count the number of distinct subsequences of S which equals T. A su ...
- 雅礼集训 2017 Day4 编码(2-sat)
题意 题目链接:https://loj.ac/problem/6036 思路 首先,有前缀关系的串不能同时存在,不难看出这是一个 2-sat 问题.先假设所有串都带问号,那么每一个字符串,我们可以 ...
- linux操作记录
cd ~ 是返回根目录cd .. 跳转到上一页cd 目录 是跳转到目录文件 php -i | grep php.ini 是查看php.ini在哪个文件 vi 是查看文件内容,:i 是编辑文件内容 : ...
- 如何用代码设置机器人初始坐标实现 2D Pose Estimate功能
前言:ROS机器人有时候会遇到极端的情况:比如地面打滑严重,IMU精度差,导致积累误差严重,或是amcl匹配错误,导致机器人定位失败, 这时候如何矫正机器人位置变得非常重要,我的思路是利用相机或是在地 ...
- LeetCode 118:杨辉三角 II Pascal's Triangle II
公众号:爱写bug(ID:icodebugs) 作者:爱写bug 给定一个非负索引 k,其中 k ≤ 33,返回杨辉三角的第 k 行. Given a non-negative index k whe ...
- 固定定位导致$(window).scrollTop();获取滚动后到顶部距离总是为0
如下移动端索引列表页面(点击某元素后弹出的页面) 我想用 $(window).scrollTop(); 获取页面滚动后距离顶部的距离,但获取到的值总是0 期间查了很久,但都无疾而终,后来看到一篇 ...