本地spark下保存rdd为文件
写随笔大概也是做笔记记录下自己思考的意思吧,之前有些事情觉得做随笔还是比较有用的,mark一下一个有用的网址
关于rdd的操作,网上有很多很多的教程,当初全部顺一遍,除了对rdd这个类型有了点概念,剩下具体的方法以及方法的写法已经快忘记了,所以具体还是记一下对某些事情的思考吧。
关于将rdd保存为文件,我使用的是
import org.apache.spark.{SparkConf, SparkContext}
object Wordcount {
def main(args: Array[String]): Unit = {
val conf=new SparkConf().setAppName("wordcount").setMaster("local")
val sc=new SparkContext(conf)
val rdd1 = sc.parallelize(List(("tom", 1), ("jerry", 3), ("kitty", 2)))
val rdd2 = sc.parallelize(List(("jerry", 2), ("tom", 1), ("shuke", 2)))
//求jion
val rdd3 = rdd1.union(rdd2)
//按key进行聚合
val rdd4 = rdd3.reduceByKey(_ + _)
rdd4.collect().foreach({println})
//按value的降序排序
val rdd5 = rdd4.map(t => (t._2, t._1)).sortByKey(false).map(t => (t._2, t._1))
rdd5.collect().foreach({println})
rdd5.saveAsTextFile("aaaaa1")
}
}
以上代码,rdd是我通过将两个rdd合并后得到,查看的时候发现rdd5是有两个分区的,输出结果是:

而保存的文件aaaa1则是一个文件夹,所以如果已存在会报文件已存在的错误无法运行(源代码里应该没有做相关的判断和处理),最终结果生成在文件夹中,如下:
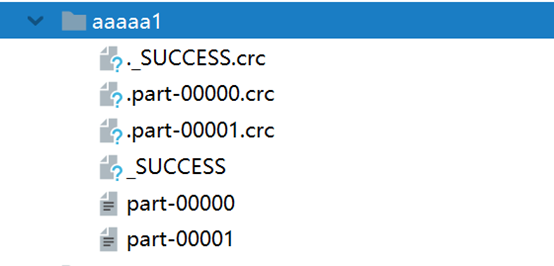
具体的数据保存在后两个文件夹中:
part-00000:
(jerry,5)
part-00001:
(tom,2)
(shuke,2)
(kitty,2)
这是按rdd5里面本身的分区数,各分区内容来生成的,而crc指的是循环冗余,.crc文件是指文件摘要,好像并没有什么特殊的,就是进行crc校验的文件。我本来以为crc和几个分区文件的联系有关系,后来想想spark处理大量数据的时候各分区数据的联系也并不算紧密,基本不会去区分前后顺序,并不需要保存彼此的联系。
大概发现了两件事情:
1、是小文件产生的大量冗余,有时候这些是没必要的,给读写它带来了一些麻烦,但是这个是有方法解决的,暂时还没有涉猎。
2、分区间不平衡,虽然只是很少条数据,但是之前也有做过某些RDD练习也说明rdd里分区并不会实时帮你平衡各分区的数据数量,但是spark有提供相应的方法,其他的,比如hive可能就不一定了。
本地spark下保存rdd为文件的更多相关文章
- 判断本地系统目录下是否存在XML文件,如果不存在就创建一个XMl文件,若存在就在里面执行添加数据
这是我为项目中写的一个测试的例子, 假如,您需要这样一个xml文件, <?xml version="1.0" encoding="utf-8"?> ...
- Spark:将RDD[List[String,List[Person]]]中的List[Person]通过spark api保存为hdfs文件时一直出现not serializable task,没办法找到"spark自定义Kryo序列化输入输出API"
声明:本文转自<在Spark中自定义Kryo序列化输入输出API> 在Spark中内置支持两种系列化格式:(1).Java serialization:(2).Kryo seriali ...
- Spark RDD 多文件输入
1.将多个文本文件读入一个RDD中 SparkConf conf=new SparkConf() .setMaster("local") .setAppName("sav ...
- 用Python删除本地目录下某一时间点之前创建的所有文件
因为工作原因,需要定期清理某个文件夹下面创建时间超过1年的所有文件,所以今天集中学习了一下Python对于本地文件及文件夹的操作.网上 这篇文章 简明扼要地整理出最常见的os方法,抄袭如下: os.l ...
- Spark(十)【RDD的读取和保存】
目录 一.文件类型 1.Text文件 2.Json文件 3.对象文件 4.Sequence文件 二.文件系统 1. MySQL 2. Hbase 一.文件类型 1.Text文件 读写 读取 scala ...
- 一个获取指定目录下一定格式的文件名称和文件修改时间并保存为文件的python脚本
摘自:http://blog.csdn.net/forandever/article/details/5711319 一个获取指定目录下一定格式的文件名称和文件修改时间并保存为文件的python脚本 ...
- linux下保存下位机输出的串口信息为文件
linux下保存下位机输出的串口信息为文件 1.stty -F /dev/ttyUSB0 raw (转换成raw模式) 2.stty -F /dev/ttyUSB0 speed 115200 (设置波 ...
- Windows下拷贝Linux的文件到本地(Putty)
去官网下载的Putty中包含了如下文件: 其中pscp.exe是一个远程复制文件的工具. 官网:https://www.chiark.greenend.org.uk/~sgtatham/putty/l ...
- 用Python删除本地目录下某一时间点之前创建的文件
参考http://www.cnblogs.com/iderek/p/8035757.html os.listdir(dirname):列出dirname下的目录和文件 os.getcwd():获得当前 ...
随机推荐
- C# vb .net实现发光效果
在.net中,如何简单快捷地实现Photoshop滤镜组中的发光效果呢?答案是调用SharpImage!专业图像特效滤镜和合成类库.下面开始演示关键代码,您也可以在文末下载全部源码: 设置授权 第一步 ...
- fiddler数据过滤功能
设置会话过滤的菜单如下图: 1.勾选Use Filters选项表示使用过滤设置,不勾选则不使用 2.Actions:有四个选项 Run Filterset now:立即运行过滤设置: Load Fil ...
- CarbonCopyCloner 硬盘对拷
CarbonCopyCloner 硬盘对拷 建议使用 5.1.14-b1以上的版本. 安装文件包 CarbonCopyCloner-5.1.14-b1.dmg ================== E ...
- 提高QPS
常用方案 1.异步化+MQ 即非阻塞,化繁为简,拿到你需要处理的资源后尽快回复.适用于事务处理场景,且无需对上游返回数据场景. 2.无锁设计 本质上是要降低锁冲突,基于数据版本的乐观锁 有效的减少了互 ...
- 【转载】Javascript使用Math.floor方法向下取整
在Javascript的数值运算中,很多时候需要对最后计算结果向下取整,Math.floor是javascript中对计算结果向下取整的函数,它总是将数值向下舍入为最接近的整数.此外Math.ceil ...
- dede 对 单个 字段 编辑
{dede:field.body runphp='yes'} $body = str_replace("src=\"/uploads","src=\" ...
- python中的嵌套类
python中的嵌套类 在.NET和JAVA语言中看到过嵌套类的实现,作为外部类一个局部工具还是很有用的,今天在python也看到了很不错支持一下.动态语言中很好的嵌套类的实现,应该说嵌套类解决设计问 ...
- "人工智能",你怕了吗?
近期“人工智能+”,已经是市场上非常火的一个风口,人工智能已经渗透到人类生活的方方面面,服务于我们的生活.但是人工智能的迅速发展,也引起了我的担忧,一系列科技电影展示出来的人工智能奴役人类的场景,让人 ...
- CentOS7 yum方式 安装mysql 5.7.28步骤
CentOS7系统yum方式安装MySQL5.7 最新的yum源可以去http://dev.mysql.com/downloads/repo/yum下载 1.获取mysql官方yum reposito ...
- 二.protobuf3数据类型
定义数据类型 首先让我们看一个非常简单的例子.假设您想要定义搜索请求消息格式,其中每个搜索请求都有一个查询字符串.您感兴趣的特定结果页面以及每页的结果数量.这是用来定义消息类型的.proto文件. s ...