spark基础知识一
1. spark是什么
Apache Spark™ is a unified analytics engine for large-scale data processing.
spark是针对于大规模数据处理的统一分析引擎
spark是在Hadoop基础上的改进,是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架,Spark基于map reduce算法实现的分布式计算,
拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Job中间输出和结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的map reduce的算法。
spark是基于内存计算框架,计算速度非常之快,但是它仅仅只是涉及到计算,并没有涉及到数据的存储,后期需要使用spark对接外部的数据源,比如hdfs。
2. spark的四大特性
2.1 速度快

运行速度提高100倍
Apache Spark使用最先进的DAG调度程序,查询优化程序和物理执行引擎,实现批量和流式数据的高性能。
spark比mapreduce快的2个主要原因
1、基于内存
mapreduce任务后期再计算的时候,每一个job的输出结果会落地到磁盘,后续有其他的job需要依赖于前面job的输出结果,这个时候就需要进行大量的磁盘io操作。性能就比较低。
spark任务后期再计算的时候,job的输出结果可以保存在内存中,后续有其他的job需要依赖于前面job的输出结果,这个时候就直接从内存中获取得到,避免了磁盘io操作,性能比较高。2、进程与线程
(1)mapreduce任务以进程的方式运行在yarn集群中,比如程序中有100个MapTask,一个task就需要一个进程,这些task要运行就需要开启100个进程。
(2)spark任务以线程的方式运行在进程中,比如程序中有100个MapTask,后期一个task就对应一个线程,这里就不在是进程,这些task需要运行,这里可以极端一点:
只需要开启1个进程,在这个进程中启动100个线程就可以了。
进程中可以启动很多个线程,而开启一个进程与开启一个线程需要的时间和调度代价是不一样。 开启一个进程需要的时间远远大于开启一个线程。
2.2 易用性
可以快速去编写spark程序通过 java/scala/python/R/SQL等不同语言

2.3 通用性

spark框架不在是一个简单的框架,可以把spark理解成一个生态系统,它内部是包含了很多模块,基于不同的应用场景可以选择对应的模块去使用
sparksql
通过sql去开发spark程序做一些离线分析
sparkStreaming
主要是用来解决公司有实时计算的这种场景
Mlib
它封装了一些机器学习的算法库
Graphx
图计算
2.4 兼容性

spark程序就是一个计算逻辑程序,这个任务要运行就需要计算资源(内存、cpu、磁盘),哪里可以给当前这个任务提供计算资源,就可以把spark程序提交到哪里去运行
standAlone
它是spark自带的集群模式,整个任务的资源分配由spark集群的老大Master负责
yarn
可以把spark程序提交到yarn中运行,整个任务的资源分配由yarn中的老大ResourceManager负责
mesos
它也是apache开源的一个类似于yarn的资源调度平台。
3. spark集群架构
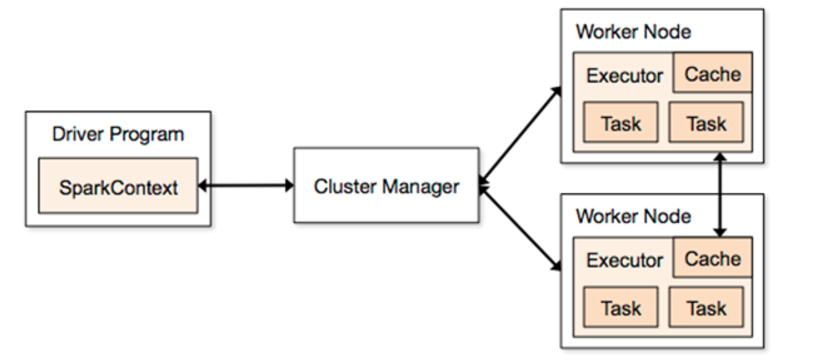

Driver
它会执行客户端写好的main方法,它会构建一个名叫SparkContext对象
该对象是所有spark程序的执行入口
Application
就是一个spark的应用程序,它是包含了客户端的代码和任务运行的资源信息
ClusterManager
它是给程序提供计算资源的外部服务
standAlone
它是spark自带的集群模式,整个任务的资源分配由spark集群的老大Master负责
yarn
可以把spark程序提交到yarn中运行,整个任务的资源分配由yarn中的老大ResourceManager负责
mesos
它也是apache开源的一个类似于yarn的资源调度平台。
Master
它是整个spark集群的老大,负责任务资源的分配
Worker
它是整个spark集群的小弟,负责任务计算的节点
Executor
它是一个进程,它会在worker节点启动该进程(计算资源)
Task
spark任务是以task线程的方式运行在worker节点对应的executor进程中
4. spark集群安装部署
事先搭建好zookeeper集群
1、下载安装包
https://archive.apache.org/dist/spark/spark-2.3.3/spark-2.3.3-bin-hadoop2.7.tgz
spark-2.3.3-bin-hadoop2.7.tgz
2、规划安装目录
/opt/bigdata
3、上传安装包到服务器
4、解压安装包到指定的安装目录
tar -zxvf spark-2.3.3-bin-hadoop2.7.tgz -C /opt/bigdata
5、重命名解压目录
mv spark-2.3.3-bin-hadoop2.7 spark
6、修改配置文件
进入到spark的安装目录下对应的conf文件夹
vim spark-env.sh ( mv spark-env.sh.template spark-env.sh)
#配置java的环境变量
export JAVA_HOME=/usr/java/jdk1.8.0_211-amd64
#配置zk相关信息
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node1:2181,node2:2181,node3:2181 -Dspark.deploy.zookeeper.dir=/spark"vim slaves ( mv slaves.template salves)
#指定spark集群的worker节点
node2
node3
7、分发安装目录到其他机器
[root@node1 bigdata]# scp -r spark node2:/opt/bigdata
[root@node1 bigdata]# scp -r spark node3:/opt/bigdata
#3.修改hive安装目录的所属用户和组为hadoop:hadoop
[root@node1 bigdata]# chown -R hadoop:hadoop spark/
#4.修改hive安装目录的读写权限
[root@node1 bigdata]# chmod -R 755 spark/
[root@node1 bigdata]# chmod -R g+w spark/
[root@node1 bigdata]# chmod -R o+w spark/8、修改spark环境变量
[root@node1 ~]# vim /etc/profile
添加如下内容:
export SPARK_HOME=/opt/bigdata/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin9、分发spark环境变量到其他机器(不一般不这样,我的环境配置文件不统一)
scp /etc/profile node2:/etc
scp /etc/profile node3:/etc10、让所有机器的spark环境变量生效
在所有节点执行
source /etc/profile
5. spark集群的启动和停止
5.1 启动
1、先启动zk
2、启动spark集群
可以在任意一台服务器来执行(条件:需要任意2台机器之间实现ssh免密登录)
[hadoop@node1 sbin]# ./start-all.sh
#位于/opt/bigdata/spark/sbin/
在哪里启动这个脚本,就在当前该机器启动一个Master进程
整个集群的worker进程的启动由slaves文件
后期可以在其他机器单独在启动master
[hadoop@node1 sbin]# ./start-master.sh
#位于/opt/bigdata/spark/sbin/
(1) 如何恢复到上一次活着master挂掉之前的状态?
在高可用模式下,整个spark集群就有很多个master,其中只有一个master被zk选举成活着的master,其他的多个master都处于standby,同时把整个spark集群的元数据信息通过zk中节点进行保存。
后期如果活着的master挂掉。首先zk会感知到活着的master挂掉,下面开始在多个处于standby中的master进行选举,再次产生一个活着的master,
这个活着的master会读取保存在zk节点中的spark集群元数据信息,恢复到上一次master的状态。整个过程在恢复的时候经历过了很多个不同的阶段,每个阶段都需要一定时间,最终恢复到上个活着的master的状态,
整个恢复过程一般需要1-2分钟。
(2) 在master的恢复阶段对任务的影响?
a)对已经运行的任务是没有任何影响
由于该任务正在运行,说明它已经拿到了计算资源,这个时候就不需要master。
b) 对即将要提交的任务是有影响
由于该任务需要有计算资源,这个时候会找活着的master去申请计算资源,由于没有一个活着的master,该任务是获取不到计算资源,也就是任务无法运行。
5.2 停止
在处于active Master主节点执
[hadoop@node1 sbin]# ./stop-all.sh
在处于standBy Master主节点执行
[hadoop@node1 sbin]# ./stop-master.sh
6. spark集群的web管理界面
当启动好spark集群之后,可以访问这样一个地址
http://master主机名:8080
http://node1:8080
可以通过这个web界面观察到很多信息
整个spark集群的详细信息
整个spark集群总的资源信息
整个spark集群已经使用的资源信息
整个spark集群还剩的资源信息
整个spark集群正在运行的任务信息
整个spark集群已经完成的任务信息


7. 初识spark程序
7.1 普通模式提交 (指定活着的master地址)
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://node1:7077 \
--executor-memory 1G \
--total-executor-cores 2 \
examples/jars/spark-examples_2.11-2.3.3.jar \
10
####参数说明
--class:指定包含main方法的主类
--master:指定spark集群master地址
--executor-memory:指定任务在运行的时候需要的每一个executor内存大小
--total-executor-cores: 指定任务在运行的时候需要总的cpu核数
7.2 高可用模式提交 (集群有很多个master)
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://node1:7077,node2:7077,node3:7077 \
--executor-memory 1G \
--total-executor-cores 2 \
examples/jars/spark-examples_2.11-2.3.3.jar \
10
spark集群中有很多个master,并不知道哪一个master是活着的master,即使你知道哪一个master是活着的master,它也有可能下一秒就挂掉,这里就可以把所有master都罗列出来
--master spark://node1:7077,node2:7077,node3:7077
后期程序会轮训整个master列表,最终找到活着的master,然后向它申请计算资源,最后运行程序。
8. spark-shell使用
8.1 运行spark-shell --master local[N] 读取本地文件进行单词统计
--master local[N]
local 表示程序在本地进行计算,跟spark集群目前没有任何关系
N 它是一个正整数,表示使用N个线程参与任务计算
local[N] 表示本地采用N个线程计算任务
spark-shell local[2]
默认会产生一个SparkSubmit进程
spark-shell local[2]
scala> sc.textFile("file:///home/hadoop/words").flatMap(x=>x.split(" ")).map(x=>(x,1)).reduceByKey((x,y)=>x+y).collect
scala> sc.textFile("/words.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
8.2 运行spark-shell --master local[N] 读取HDFS上文件进行单词统计
spark整合HDFS
在node1上修改配置文件
[hadoop@node1 conf]# vim spark-env.sh
export HADOOP_CONF_DIR=/opt/bigdata/hadoop-2.7.3/etc/hadoop
分发到其他节点
scp spark-env.sh node2:/opt/bigdata/spark/conf
scp spark-env.sh node3:/opt/bigdata/spark/confspark-shell --master local[2]
sc.textFile("/user/user.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
sc.textFile("hdfs://node1:9000//user/user.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
8.3 运行spark-shell 指定集群中活着master 读取HDFS上文件进行单词统计
spark-shell --master spark://node1:7077 --executor-memory 1g --total-executor-cores 4
--master spark://node1:7077
指定活着的master地址
--executor-memory 1g
指定每一个executor进程的内存大小
--total-executor-cores 4
指定总的executor进程cpu核数
sc.textFile("hdfs://node1:9000/user/user.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
#实现读取hdfs上文件之后,需要把计算的结果保存到hdfs上
sc.textFile("/user/user.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).saveAsTextFile("/out")
在hdfs查看计算结果:
[hadoop@node1 ~]# hdfs dfs -ls /out
[hadoop@node1 ~]# hdfs dfs -cat /out/part-00000
[hadoop@node1 ~]# hdfs dfs -cat /out/part-00001

9. 通过IDEA开发spark程序
构建maven工程,添加pom依赖
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.3.3</version>
</dependency>
</dependencies><build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<arg>-dependencyfile</arg>
<arg>${project.build.directory}/.scala_dependencies</arg>
</args>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass></mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>创建 src/main/scala 和 src/test/scala 目录

9.1 利用scala语言开发spark程序实现单词统计--本地运行
代码开发
package com.lowi
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
//todo: 利用scala语言开发spark程序实现单词统计
object WordCount {
def main(args: Array[String]): Unit = {
//1、构建sparkConf对象 设置application名称和master地址
val sparkConf: SparkConf = new SparkConf().setAppName("WordCount").setMaster("local[2]")
//2、构建sparkContext对象,该对象非常重要,它是所有spark程序的执行入口
// 它内部会构建 DAGScheduler和 TaskScheduler 对象
val sc = new SparkContext(sparkConf)
//设置日志输出级别
sc.setLogLevel("warn")
//3、读取数据文件
val data: RDD[String] = sc.textFile("E:\\words.txt")
//4、 切分每一行,获取所有单词
val words: RDD[String] = data.flatMap(x=>x.split(" "))
//5、每个单词计为1
val wordAndOne: RDD[(String, Int)] = words.map(x => (x,1))
//6、相同单词出现的1累加
val result: RDD[(String, Int)] = wordAndOne.reduceByKey((x,y)=>x+y)
//按照单词出现的次数降序排列 第二个参数默认是true表示升序,设置为false表示降序
val sortedRDD: RDD[(String, Int)] = result.sortBy( x=> x._2,false)
//7、收集数据打印
val finalResult: Array[(String, Int)] = sortedRDD.collect()
finalResult.foreach(println)
//8、关闭sc
sc.stop()
}
}
9.2 利用scala语言开发spark程序实现单词统计--集群运行
代码开发
package com.lowi
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
//todo: 利用scala语言开发spark程序实现单词统计
object WordCountOnSpark {
def main(args: Array[String]): Unit = {
//1、构建sparkConf对象 设置application名称
val sparkConf: SparkConf = new SparkConf().setAppName("WordCountOnSpark")
//2、构建sparkContext对象,该对象非常重要,它是所有spark程序的执行入口
// 它内部会构建 DAGScheduler和 TaskScheduler 对象
val sc = new SparkContext(sparkConf)
//设置日志输出级别
sc.setLogLevel("warn")
//3、读取数据文件
val data: RDD[String] = sc.textFile(args(0))
//4、 切分每一行,获取所有单词
val words: RDD[String] = data.flatMap(x=>x.split(" "))
//5、每个单词计为1
val wordAndOne: RDD[(String, Int)] = words.map(x => (x,1))
//6、相同单词出现的1累加
val result: RDD[(String, Int)] = wordAndOne.reduceByKey((x,y)=>x+y)
//7、把计算结果保存在hdfs上
result.saveAsTextFile(args(1))
//8、关闭sc
sc.stop()
}
}
打成jar包提交到集群中运行
spark-submit \
--master spark://node1:7077,node2:7077 \
--class com.kaikeba.WordCountOnSpark \
--executor-memory 1g \
--total-executor-cores 4 \
original-spark_class01-1.0-SNAPSHOT.jar \
/words.txt /out
9.3 利用java语言开发spark程序实现单词统计--本地运行
代码开发
package com.lowi;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
import java.util.Arrays;
import java.util.Iterator;
import java.util.List;
//todo: 利用java语言开发spark的单词统计程序
public class JavaWordCount {
public static void main(String[] args) {
//1、创建SparkConf对象
SparkConf sparkConf = new SparkConf().setAppName("JavaWordCount").setMaster("local[2]");
//2、构建JavaSparkContext对象
JavaSparkContext jsc = new JavaSparkContext(sparkConf);
//3、读取数据文件
JavaRDD<String> data = jsc.textFile("E:\\words.txt");
//4、切分每一行获取所有的单词 scala: data.flatMap(x=>x.split(" "))
JavaRDD<String> wordsJavaRDD = data.flatMap(new FlatMapFunction<String, String>() {
public Iterator<String> call(String line) throws Exception {
String[] words = line.split(" ");
return Arrays.asList(words).iterator();
}
});
//5、每个单词计为1 scala: wordsJavaRDD.map(x=>(x,1))
JavaPairRDD<String, Integer> wordAndOne = wordsJavaRDD.mapToPair(new PairFunction<String, String, Integer>() {
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<String, Integer>(word, 1);
}
});
//6、相同单词出现的1累加 scala: wordAndOne.reduceByKey((x,y)=>x+y)
JavaPairRDD<String, Integer> result = wordAndOne.reduceByKey(new Function2<Integer, Integer, Integer>() {
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
//todo java语言,排序方式,只能按照key进行排序,所以需要将次数置为key,作为排序的关键
//按照单词出现的次数降序 (单词,次数) -->(次数,单词).sortByKey----> (单词,次数)
JavaPairRDD<Integer, String> reverseJavaRDD = result.mapToPair(new PairFunction<Tuple2<String, Integer>, Integer, String>() {
public Tuple2<Integer, String> call(Tuple2<String, Integer> t) throws Exception {
return new Tuple2<Integer, String>(t._2, t._1);
}
});
JavaPairRDD<String, Integer> sortedRDD = reverseJavaRDD.sortByKey(false).mapToPair(new PairFunction<Tuple2<Integer, String>, String, Integer>() {
public Tuple2<String, Integer> call(Tuple2<Integer, String> t) throws Exception {
return new Tuple2<String, Integer>(t._2, t._1);
}
});
//7、收集打印
List<Tuple2<String, Integer>> finalResult = sortedRDD.collect();
for (Tuple2<String, Integer> t : finalResult) {
System.out.println("单词:"+t._1 +"\t次数:"+t._2);
}
jsc.stop();
}
}
spark基础知识一的更多相关文章
- 最全的spark基础知识解答
原文:http://www.36dsj.com/archives/61155 一. Spark基础知识 1.Spark是什么? UCBerkeley AMPlab所开源的类HadoopMapReduc ...
- spark基础知识(1)
一.大数据架构 并发计算: 并行计算: 很少会说并发计算,一般都是说并行计算,但是并行计算用的是并发技术.并发更偏向于底层.并发通常指的是单机上的并发运行,通过多线程来实现.而并行计算的范围更广,他是 ...
- spark基础知识
1.Spark是什么? UCBerkeley AMPlab所开源的类HadoopMapReduce的通用的并行计算框架. dfsSpark基于mapreduce算法实现的分布式计算,拥有HadoopM ...
- spark基础知识介绍2
dataframe以RDD为基础的分布式数据集,与RDD的区别是,带有Schema元数据,即DF所表示的二维表数据集的每一列带有名称和类型,好处:精简代码:提升执行效率:减少数据读取; 如果不配置sp ...
- spark基础知识介绍(包含foreachPartition写入mysql)
数据本地性 数据计算尽可能在数据所在的节点上运行,这样可以减少数据在网络上的传输,毕竟移动计算比移动数据代价小很多.进一步看,数据如果在运行节点的内存中,就能够进一步减少磁盘的I/O的传输.在spar ...
- Spark基础知识详解
Apache Spark是一种快速通用的集群计算系统. 它提供Java,Scala,Python和R中的高级API,以及支持通用执行图的优化引擎. 它还支持一组丰富的高级工具,包括用于SQL和结构化数 ...
- spark基础知识四
围绕spark的其他特性和应用.主要包括以下几个方面 spark自定义分区 spark中的共享变量 spark程序的序列化问题 spark中的application/job/stage/task之间的 ...
- spark基础知识三
主要围绕spark的底层核心抽象RDD和原理进行理解.主要包括以下几个方面 RDD弹性分布式数据集的依赖关系 RDD弹性分布式数据集的lineage血统机制 RDD弹性分布式数据集的缓存机制 spar ...
- spark基础知识二
主要围绕spark的底层核心抽象RDD进行理解.主要包括以下几个方面 RDD弹性分布式数据集的概念 RDD弹性分布式数据集的五大属性 RDD弹性分布式数据集的算子操作分类 RDD弹性分布式数据集的算子 ...
随机推荐
- Java中List集合去除重复数据的六种方法
1. 循环list中的所有元素然后删除重复 public static List removeDuplicate(List list) { for ( int i = 0 ; i < list. ...
- Java中转换为十六进制的几种实现
public class HexUtil { private static final String[] DIGITS_UPPER = {"0", "1", & ...
- Mysql序列(七)—— order by优化
前言 在mysql中满足order by的处理方式有两种: 让索引满足排序,即扫描有序索引然后再找到对应的行结果,这样结果即是有序: 使用索引查询出结果或者扫描表得到结果然后使用filesort排序: ...
- linux 下 的串口模拟器 minicom 退出方法
ctrl + a (或 A) 进入 minicom 的配置模式:终端外观上无任何变化! 然后按下 z (或 Z) 方可打开配置帮助界面 然后按下 x (或 X)退出
- aspose.cells导出Demo
/// <summary> /// 导出excel /// </summary> /// <param name="list"></par ...
- 浅聊几种主流Docker网络的实现原理
原文:https://mp.weixin.qq.com/s/Jdxct8qHrBUtkUq-hnxSRw 参考:https://blog.csdn.net/yarntime/article/detai ...
- java实现二叉树常见操作
package com.xk.test.struct.newp; import java.util.ArrayList; import java.util.LinkedList; import jav ...
- centos7启动redis命令
redis安装 yum install redis 安装完成后redis.conf配置文件默认在 /etc/redis.conf 启动命令: redis-server /etc/redis.conf
- set实现交集,并集,差集
let a = new Set([1, 2, 3]); let b = new Set([4, 3, 2]); // 并集 let union = new Set([...a, ...b]); // ...
- Qt中QWidget、QDialog和QMainWindow
QWidget 类是所有用户界面对象的基类.只有一个"页面" QMainWindow 是一个"窗口".含有菜单栏.状态栏.工具栏.停靠窗口.中心窗口 QDial ...