MySQL Index--BNL/ICP/MRR/BKA
MySQL关联查询算法
BNL(Block Nested-Loop)
ICP(Index Condition Pushdown)
MRR(Multi-Range Read)
BKA(Batched Key Access)
BNL(Block Nested-Loop)
场景:
假设TB1和TB2进行关联查询,以TB1为外表循环扫描每行数据到TB2中查找匹配的记录行,但由于TB2中没有可以使用的索引,需要扫描整个T2表的数据,因此外层TB1的数据行数决定内层TB2的扫描次数。
优化:
将外层表TB1的数据行进行拆分N个Block,每个Block中包含M条数据,对TB2进行N次扫描,在扫描TB2数据的每一行时将其与一个Block的数据进行匹配,将原来对TB2表的扫描次数从M*N次降低到N次。
重点:
1、内表没有可利用的索引
2、内表和外表的顺序不能对换,如LEFT JOIN操作
该算法在MySQL 5.1版本中便已存在。
ICP(Index Condition Pushdown)
场景:
假设表TB1上有索引IDX_C1_C2_C3(C1,C2,C3),对于查询SELECT * FROM TB1 WHERE C1='XXX' AND C3='XXX'
在MySQL 5.6版本以前,由于缺少C2的过滤条件,Innodb存储引擎层只能使用索引IDX_C1_C2_C3按照C1='XXX'条件找出所有满足条件的索引记录,再根据这些索引记录去聚集索引中查找,将找到的表数据返回给MySQL Server层,然后由MySQL Server层使用C3='XXX'条件进行过滤得到最终结果。
再MySQL 5.6版本中引入ICP特性,Innodb存储引擎层只能使用索引IDX_C1_C2_C3按照C1='XXX'条件去扫描所有满足条件的索引记录,再将这些索引记录按照C3='XXX'条件进行过滤,并按照过滤后的索引记录去去聚集索引中查找,将找到的表数据返回给MySQL Server层,得到最终结果。
假设满足C1='XXX'条件的数据行为100000条,而满足C1='XXX' AND C3='XXX'的数据行为100条,则:
1、在MySQL 5.5版本中,需要对TB1的聚集索引进行100000次Index Seek操作,Innodb存储引擎层向MySQL Server层传递100000行数据。
2、在MySQL 5.6版本中,使用ICP仅需要对TB1的聚集索引进行100次的Index Seek操作,Innodb存储引擎层向MySQL Server层传递100行数据。
ICP通过将过滤条件由MySQL Server层"下沉"到存储引擎层,从而达到:
1、减少对聚集索引查找的操作次数;
2、减少从存储引擎层返回给MySQL Server层的数据量;
3、减少MySQL Server层访问存储引擎层的次数。
PS1: ICP仅使用于非聚集索引。
PS2: 在MySQL 5.6中仅支持普通表进行ICP操作,而MySQL 5.7中支持对分区表进行ICP操作。
MRR(Multi-Range Read)
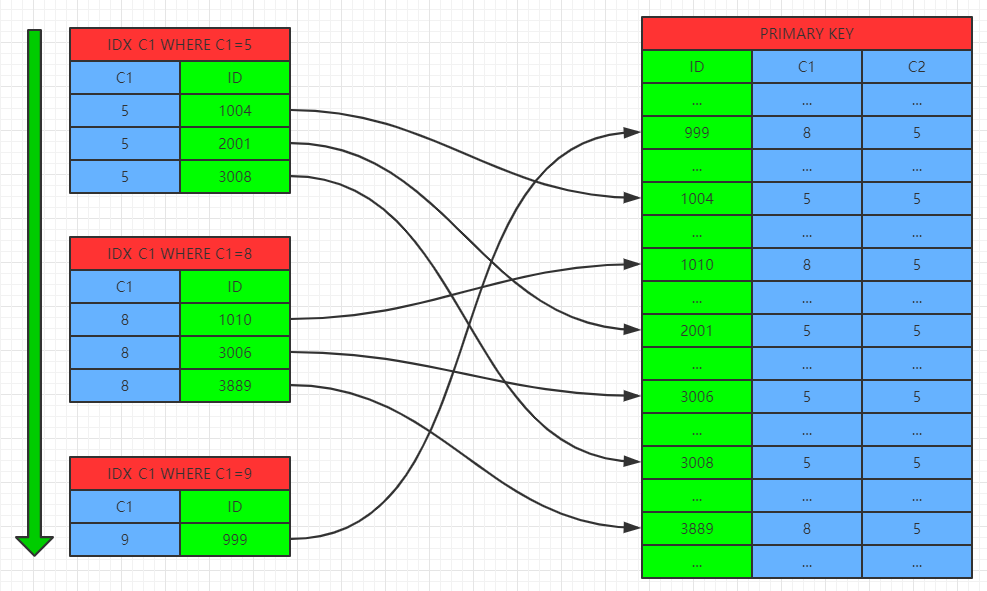
假设表TB1上有索引IDX_C1(C1),对于查询SELECT * FROM TB1 WHERE C1 IN('XXX1','XXX2',....,'XXXN')
在MySQL 5.6版本以前,先按照C1='XXX1'条件对IDX_C1进行索引查找,再按照找到的索引记录去TB1的聚集索引中找到对应数据记录,再按照C1='XXX2'...到C1='XXXN'进行操作,将每次操作的结果集合并得到最终结果集。由于根据C1条件得到的索引记录中的包含的聚集键数据时无序的,导致对聚集索引的Index seek操作造成较多的随机IO,影响服务器存储性能。
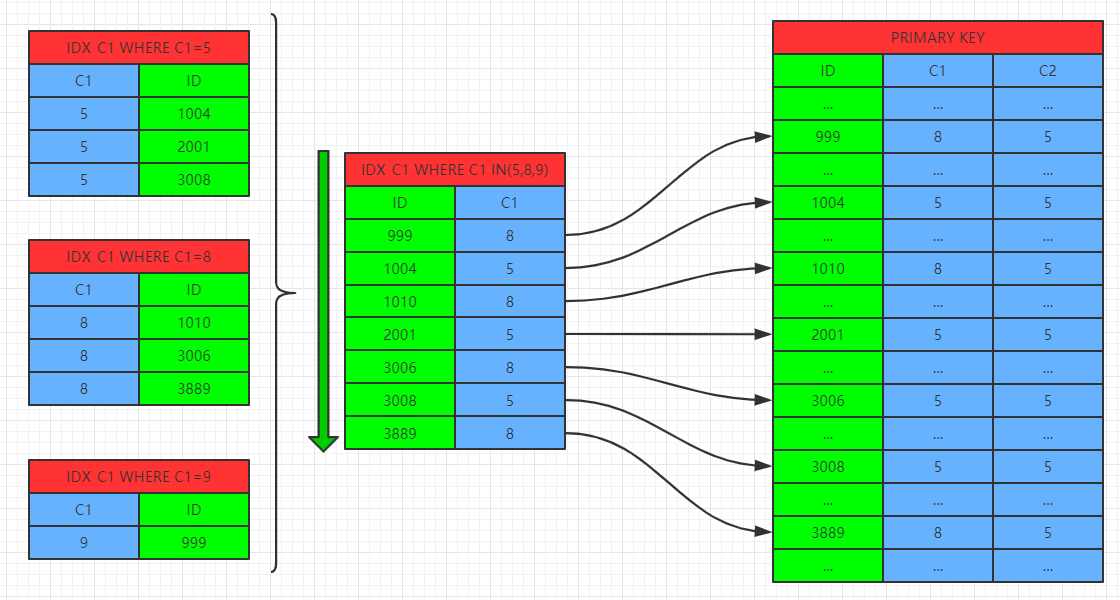
在MySQL 5.6版本中引入MRR特性,先按照C1='XXX1'....和C1='XXXM'的条件找到满足条件的索引记录放到buffer中,当Buffer满时再将buffer中的索引记录按照聚集键进行排序,按照排序后的结果去聚集索引中找到相应记录,通过排序,可以有效地将原来的随机查找改为顺序查找,将部分随机IO转换为顺序IO,提示查询性能,降低查询对服务器IO性能的消耗。
PS1: MRR也仅适用于非聚集索引,且根据非聚集索引得到的结果集在聚集键上是随机无序的。
PS2: 假设上面TB1的聚集索引为ID,那么IDX_C1(C1)等价于IDX_C1(C1,ID),如果仅对非聚集索引进行单个等值查询,那么得到的结果集对聚集键也是有序的,无需使用MRR特性。
PS3: MRR中涉及到的Buffer的大小取决于参数read_rnd_buffer_size的设置
不使用MRR特性时:
使用MRR特性时:
BKA(Batched Key Access)
场景:
假设TB1和TB2进行关联查询,以TB1为外表循环到TB2中进行关联匹配,表TB2上有可使用的索引。
在MySQL 5.6版本前,只能循环TB1中的数据依次到TB2上进行索引查找,如果TB1上的数据是无序的,则对TB2的索引查找也是随机的,产生大量的随机IO操作。
在MySQL 5.6版本中,按照MRR的特性,先将TB1中的数据放入Buffer中,当Buffer满时对Buffer中的数据按照关联键进行排序,然后有序地对TB2进行索引查找,将部分随机IO操作转换为顺序IO操作。
PS1: BKA依赖于MRR,因此要使用BKA必须开启MRR特性,但又由于基于mrr_cost_based的成本估算不能保证MRR被使用,因此官方推荐关闭mrr_cost_based。
PS2: BKA使用的Buffer的大小取决于参数join buffer siz
设置开启MRR和BKA并关闭mrr_cost_based
SET optimizer_switch='mrr=on,mrr_cost_based=off,batched_key_access=on';
BKA和BNL的区别:
1、内表索引,BKA要求内表有可以使用的索引,而BNL则是因为内表没有可使用的索引而不得已的优化
2、算法目的,BKA算法的目的是减少对内表的随机Index Seek操作和降低随机IO,而BNL算法的目的是减少对内表的扫描次数和减少扫描带来的IO开销。
MySQL Index--BNL/ICP/MRR/BKA的更多相关文章
- MySQL--BNL/ICP/MRR/BKA
#======================================================##MySQL关联查询算法:BNL(Block Nested-Loop)ICP(Index ...
- MySQL中有关icp mrr和bka的特性
文辉考我的问题,有关这三个的特性,如果在面试过程中,个人见解可以答以下 icp MyQL数据库会在取出索引的同时,判断是否进行WHERE条件过滤,也就是把WHERE的部分过滤操作放在存储引擎层,在某些 ...
- MySQL · 特性分析 · 优化器 MRR & BKA【转】
MySQL · 特性分析 · 优化器 MRR & BKA 上一篇文章咱们对 ICP 进行了一次全面的分析,本篇文章小编继续为大家分析优化器的另外两个选项: MRR & batched_ ...
- MySQL Index Condition Pushdown 原理与解析
Index Condition Pushdown(ICP)是针对mysql使用索引从表中检索行数据时的一种优化方法. 原理: 在没有ICP特性之前,存储引擎根据索引去基表查找并将数据返回给mysq ...
- MySQL Index详解
FROM:http://blog.csdn.net/tianmo2010/article/details/7930482 ①MySQL Index 一.SHOW INDEX会返回以下字段 1.Tabl ...
- 【mysql】关于ICP、MRR、BKA等特性
一.Index Condition Pushdown(ICP) Index Condition Pushdown (ICP)是mysql使用索引从表中检索行数据的一种优化方式,从mysql5.6开始支 ...
- Mysql优化,ICP、BNL算法、BKA算法、MMR算法
ICP(Index Condition Pushdown,索引条件下推)是MySQL5.6版本中的新特性,是一种在存储引擎层使用索引过滤数据的一种优化方式. 出现原因:ICP出现Mysql5.6以前, ...
- MRR,BKA,ICP相关
MRR Multi-Range Read,多范围读,5.6以上版本开始支持 工作原理&优化效果: 将查询到的辅助索引结果放在一个缓冲(read_rnd_buffer_size = 4M)中 将 ...
- MySQL 优化之 ICP (index condition pushdown:索引条件下推)
ICP技术是在MySQL5.6中引入的一种索引优化技术.它能减少在使用 二级索引 过滤where条件时的回表次数 和 减少MySQL server层和引擎层的交互次数.在索引组织表中,使用二级索引进行 ...
随机推荐
- 【转载】 TensorFlow函数:tf.Session()和tf.Session().as_default()的区别
原文地址: https://blog.csdn.net/Enchanted_ZhouH/article/details/77571939 ------------------------------- ...
- Python3基础 内置函数 dir 查询对象的方法列表
Python : 3.7.3 OS : Ubuntu 18.04.2 LTS IDE : pycharm-community-2019.1.3 ...
- Linux远程连接ssh工具(FinalShell)xshell替代神器
对对对 FinalShell SSH工具,服务器管理,远程桌面加速软件,支持Windows,macOS,Linux,版本2.9.8,更新时间2019.6.19 wntr 2017-01-17 11:0 ...
- 【C#】使用C# 读取Http的Post数据
private string Post(string num) { Encoding myEncoding = Encoding.GetEncoding("gb2312"); // ...
- SVN中trunk,branches,tags用法详解[重要]
Subversion有一个很标准的目录结构,是这样的.比如项目是proj,svn地址为svn://proj/,那么标准的svn布局是 svn://proj/|+-trunk+-branches+-ta ...
- 升级libstdc++、libgcc_s.so、libc.so.6
参考资料:https://blog.csdn.net/ltl451011/article/details/7763892/ https://blog.csdn.net/na_beginning/art ...
- Maven手动导本地jar到项目
第一步:先把目标jar安装在本地,下面是安装到本地的步骤:在cmd命令中,输入:mvn install:install-file -Dfile=C:\Users\Ter\Desktop\jqd_doc ...
- jquery监听回车
jquery监听回车 <pre> $("#loginusername, #loginpassword, #code").keydown(function() { if( ...
- JavaEE 期末总结
struts2部分 一.struts2框架的集成: 1.web.xml配置struts2过滤器:前端控制器.核心控制器 如果有多个过滤器,需要将该过滤器放置到最后一个 2.struts.xml配置:主 ...
- PAT 1093
The string APPAPT contains two PAT's as substrings. The first one is formed by the 2nd, the 4th, and ...