【solr filter 介绍--转】http://blog.csdn.net/jiangchao858/article/details/54989025
Solr的Analyzer分析器、Tokenizer分词器、Filter过滤器的区别/联系
- Analyzer负责把文本字段转成token stream,然后自己处理、或调用Tokenzier和Filter进一步处理,Tokenizer和Filter是同等级和顺序执行的关系,一个处理完后交给下一个处理。
- Tokenizer接收text(从solr那里获得一个Reader来读取文本),拆分成tokens,输出token stream
- Filter接收token stream,对每个token进行处理(比如:替换、丢弃、不理),输出token stream。在配置文件中,Tokenizer放在第一位,Filter放在第二位直到最后一位。Filters是顺序执行的,前一个的结果是后一个是输入,所以,一般通用的处理放在前面,特殊的处理靠后
常见的Solr Filter过滤器
ASCII Folding Filter
这个Filter将不属于ASCII(127个字符,包括英文字母,数字,常见符号)的字符转化成与ASCII 字符等价的字符。
没有参数。
例子:
<analyzer>
<filter class="solr.ASCIIFoldingFilterFactory"/>
</analyzer>
输入: “á”
输出:“a”
Classic Filter
这个Filter接受Classic Tokenizer的结果,并处理首字母缩略词和所有格形式(英文中含有 ‘s 的形式)
例子:
<analyzer>
<tokenizer class="solr.ClassicTokenizerFactory"/>
<filter class="solr.ClassicFilterFactory"/>
</analyzer>
原始文本:“I.B.M. cat’s can’t”
输入: “I.B.M”, “cat’s”, “can’t”
输出:“IBM”, “cat”, “can’t
Common Grams Filter
这个Filter结合通用tokens来处理常用词。

例子:
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.CommonGramsFilterFactory" words="stopwords.txt" ignoreCase="true"/>
</analyzer>
原始文本: “the Cat”
输入: “the”, “Cat”
输出: “the_cat”
Edge N-Gram Filter
将输入文本转化成指定范围大小的片段。

例如:
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.EdgeNGramFilterFactory"/>
</analyzer>
原始文本: “four score and twenty”
输入: “four”, “score”, “and”, “twenty”
输出: “f”, “s”, “a”, “t”
例子:
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.EdgeNGramFilterFactory" minGramSize="1" maxGramSize="4"/>
</analyzer>
原始文本: “four score”
输入: “four”, “score”
输出: “f”, “fo”, “fou”, “four”, “s”, “sc”, “sco”, “scor”
例子:
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.EdgeNGramFilterFactory" minGramSize="4" maxGramSize="6"/>
</analyzer>
原始文本: “four score and twenty”
输入: “four”, “score”, “and”, “twenty”
输出: “four”, “scor”, “score”, “twen”, “twent”, “twenty”
English Minimal Stem Filter
这个Filter将英语中的复数处理成单数形式。
没有参数。
例子:
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory "/>
<filter class="solr.EnglishMinimalStemFilterFactory"/>
</analyzer>
原始文本: “dogs cats”
输入: “dogs”, “cats”
输出: “dog”, “cat”
Keep Word Filter
这个Filter将不属于列表中的单词过滤掉。和Stop Words Filter的效果相反。

例子:
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.KeepWordFilterFactory" words="keepwords.txt"/>
</analyzer>
保留词列表keepwords.txt
happy
funny
silly
原始文本: “Happy, sad or funny”
输入: “Happy”, “sad”, “or”, “funny”
输出: “funny”
例子:
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.KeepWordFilterFactory" words="keepwords.txt" ignoreCase="true"/>
</analyzer>
保留词列表keepwords.txt
happy
funny
silly
原始文本: “Happy, sad or funny”
输入: “Happy”, “sad”, “or”, “funny”
输出: “Happy”, “funny”
例子:
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.KeepWordFilterFactory" words="keepwords.txt"/>
</analyzer>
保留词列表keepwords.txt
happy
funny
silly
原始文本: “Happy, sad or funny”
输入: “happy”, “sad”, “or”, “funny”
输出: “Happy”, “funny”
Length Filter
这个Filter处理在给定范围长度的tokens。

例子:
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LengthFilterFactory" min="3" max="7"/>
</analyzer>
原始文本: “turn right at Albuquerque”
输入: “turn”, “right”, “at”, “Albuquerque”
输出: “turn”, “right”
Lower Case Filter
这个Filter将所有的大写字母转化为小写。
没有参数。
例子:
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
原始文本: “Down With CamelCase”
输入: “Down”, “With”, “CamelCase”
输出: “down”, “with”, “camelcase”
N-Gram Filter
将输入文本转化成指定范围大小的片段。

例子:
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.NGramFilterFactory"/>
</analyzer>
原始文本: “four score”
输入: “four”, “score”
输出: “f”, “o”, “u”, “r”, “fo”, “ou”, “ur”, “s”, “c”, “o”, “r”, “e”, “sc”, “co”, “or”, “re”
例子2:
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.NGramFilterFactory" minGramSize="1" maxGramSize="4"/>
</analyzer>
原始文本: “four score”
输入: “four”, “score”
输出: “f”, “fo”, “fou”, “four”, “s”, “sc”, “sco”, “scor”
例子3:
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.NGramFilterFactory" minGramSize="3" maxGramSize="5"/>
</analyzer>
原始文本: “four score”
输入: “four”, “score”
输出: “fou”, “four”, “our”, “sco”, “scor”, “score”, “cor”, “core”, “ore”
Pattern Replace Filter
这个Filter可以使用正则表达式来替换token的一部分内容,与正则表达式想匹配的被替换,不匹配的不变。

例子:
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.PatternReplaceFilterFactory" pattern="cat" replacement="dog"/>
</analyzer>
原始文本: “cat concatenate catycat”
输入: “cat”, “concatenate”, “catycat”
输出: “dog”, “condogenate”, “dogydog”
例子2:
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.PatternReplaceFilterFactory" pattern="cat" replacement="dog" replace="first"/>
</analyzer>
原始文本: “cat concatenate catycat”
输入: “cat”, “concatenate”, “catycat”
输出: “dog”, “condogenate”, “dogycat”
例子3:
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.PatternReplaceFilterFactory" pattern="(\D+)(\d+)$" replacement="$1_$2"/>
</analyzer>
原始文本: “cat foo1234 9987 blah1234foo”
输入: “cat”, “foo1234”, “9987”, “blah1234foo”
输出: “cat”, “foo_1234”, “9987”, “blah1234foo”
Standard Filter
这个Filter将首字母缩略词中的点号(如I.B.M处理为IBM)去除,将英文中的所有格形式中的's除去(如stationer’s处理为stationer)。
没有参数。
在Solr3.1以后已经废弃。
Stop Filter
这个Filter会在解析时忽略给定的停词列表(stopwords.txt)中的内容。

例子:
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" words="stopwords.txt"/>
</analyzer>
保留词列表stopwords.txt
be
or
to
原始文本: “To be or what?”
输入: “To”(1), “be”(2), “or”(3), “what”(4)
输出: “To”(1), “what”(4)
例子2:
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" words="stopwords.txt" ignoreCase="true"/>
</analyzer>
保留词列表stopwords.txt
be
or
to
原始文本: “To be or what?”
输入: “To”(1), “be”(2), “or”(3), “what”(4)
输出: “what”(4)
Synonym Filter
这个Filter用来处理同义词。

注意,常用的同义词列表格式:
1. 以#开头的行为注释内容,忽略
2. 以,分隔的文本,为双向同义词,左右内容等价,互为同义词
3. 以=>分隔的文本,为单向同义词,匹配到左边内容,将替换为右边内容,反之不成立
例子:
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.SynonymFilterFactory" synonyms="mysynonyms.txt"/>
</analyzer>
同义词列表synonyms.txt
couch,sofa,divan
teh => the
huge,ginormous,humungous => large
small => tiny,teeny,weeny
原始文本: “teh small couch”
输入: “teh”(1), “small”(2), “couch”(3)
输出: “the”(1), “tiny”(2), “teeny”(2), “weeny”(2), “couch”(3), “sofa”(3), “divan”(3)
原始文本: “teh ginormous, humungous sofa”
输入: “teh”(1), “ginormous”(2), “humungous”(3), “sofa”(4)
输出: “the”(1), “large”(2), “large”(3), “couch”(4), “sofa”(4), “divan”(4)
Word Delimiter Filter
这个Filter以每个单词为分隔符。
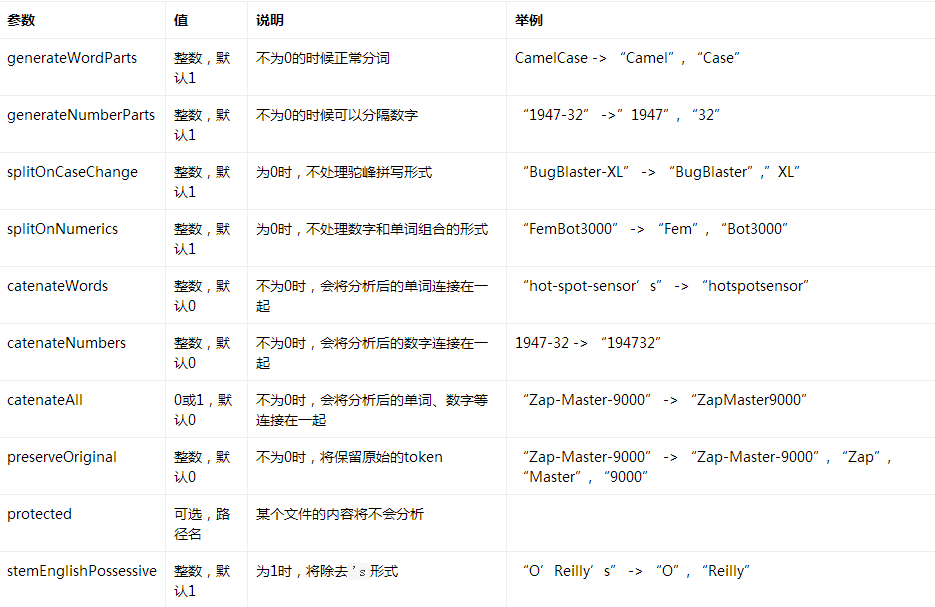
例子:
<analyzer>
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.WordDelimiterFilterFactory"/>
</analyzer>
原始文本: “hot-spot RoboBlaster/9000 100XL”
输入: “hot-spot”, “RoboBlaster/9000”, “100XL”
输出: “hot”, “spot”, “Robo”, “Blaster”, “9000”, “100”, “XL”
例子2:
<analyzer>
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.WordDelimiterFilterFactory" generateNumberParts="0" splitOnCaseChange="0"/>
</analyzer>
原始文本: “hot-spot RoboBlaster/9000 100-42”
输入: “hot-spot”, “RoboBlaster/9000”, “100-42”
输出: “hot”, “spot”, “RoboBlaster”, “9000”,”100”,”42”
例子3:
<analyzer>
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.WordDelimiterFilterFactory" catenateWords="1" catenateNumbers="1"/>
</analyzer>
原始文本: “hot-spot 100+42 XL40”
输入: “hot-spot”(1), “100+42”(2), “XL40”(3)
输出: “hot”(1), “spot”(2), “hotspot”(2), “100”(3), “42”(4), “10042”(4), “XL”(5), “40”(6)
例子4:
<analyzer>
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.WordDelimiterFilterFactory" catenateAll="1"/>
</analyzer>
原始文本: “XL-4000/ES”
输入: “XL-4000/ES”(1)
输出: “XL”(1), “4000”(2), “ES”(3), “XL4000ES”(3)
例子5:
<analyzer>
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.WordDelimiterFilterFactory" protected="protwords.txt"/>
</analyzer>
受保护词列表protwords.txt
AstroBlaster
XL-5000
原始文本: “FooBar AstroBlaster XL-5000 ==ES-34-”
输入: “FooBar”, “AstroBlaster”, “XL-5000”, “==ES-34-”
输出: “FooBar”, “AstroBlaster”, “XL-5000”, “ES”, “34”
【solr filter 介绍--转】http://blog.csdn.net/jiangchao858/article/details/54989025的更多相关文章
- http://blog.csdn.net/LANGXINLEN/article/details/50421988
GitHub上史上最全的Android开源项目分类汇总 今天在看博客的时候,无意中发现了 @Trinea在GitHub上的一个项目 Android开源项目分类汇总, 由于类容太多了,我没有一个个完整地 ...
- matplotlib绘图基本用法-转自(http://blog.csdn.net/mao19931004/article/details/51915016)
本文转载自http://blog.csdn.net/mao19931004/article/details/51915016 <!DOCTYPE html PUBLIC "-//W3C ...
- 转-spring-boot 注解配置mybatis+druid(新手上路)-http://blog.csdn.net/sinat_36203615/article/details/53759935
spring-boot 注解配置mybatis+druid(新手上路) 转载 2016年12月20日 10:17:17 标签: sprinb-boot / mybatis / druid 10475 ...
- RTP协议分析(转自:http://blog.csdn.net/bripengandre/article/details/2238818)
RTP协议分析 第1章. RTP概述 1.1. RTP是什么 RTP全名是Real-time Transport Protocol(实时传输协议).它是IETF提出的一个标准,对应的RFC文 ...
- PL/SQL常用设置 可看引用位置更清晰直观 引自:http://blog.csdn.net/xiaoqforever/article/details/27695569
引自:http://blog.csdn.net/xiaoqforever/article/details/27695569 1,登录后默认自动选中My Objects 默认情况下,PLSQL Deve ...
- http://blog.csdn.net/luoshengyang/article/details/6651971
文章转载至CSDN社区罗升阳的安卓之旅,原文地址:http://blog.csdn.net/luoshengyang/article/details/6651971 在Android系统中,提供了独特 ...
- http://blog.csdn.net/zhanglvmeng/article/details/11928469
本系列主要结合<PHP和MYSQL WEB开发 第四版>,在阅读中提出自己认为比较重要的一些问题,以加深对知识的了解程度. 1.简短.中等以及冗长风格的表单变量 $name; //简短风格 ...
- http://blog.csdn.net/baimafujinji/article/details/10931621
书接上文,本文章是该系列的第二篇,按照总纲中给出的框架,本节介绍三个中值定理,包括它们的证明及几何意义.这三个中值定理是高等数学中非常基础的部分,如果读者对于高数的内容已经非常了解,大可跳过此部分.当 ...
- 学习mongoDB的一些感受(转自:http://blog.csdn.net/liusong0605/article/details/11581019)
曾经使用过mongoDB来保存文件,最一开始,只是想总结一下在开发中如何实现文件与mongoDB之间的交互.在此之前,并没有系统的了解过mongoDB,虽然知道我们用它来存储文件这些非结构化数据,但是 ...
随机推荐
- crontab -e 定时任务中的 脚本文件 路径
crontab -l 57 */1 * * * python /home/data/crontab_chk_url/personas/trunk/plugins/spider/chk_url_stat ...
- Axure Base 03
(三)Axure rp元件的触发事件 l OnClick(点击时): 鼠标点击事件,除了动态面板的所有的其他元件的点击时触发.比如点击按钮. l OnMouseEnter(鼠标移入时): 鼠标进入 ...
- SpringMVC+ajaxFileUpload上传图片 IE浏览器弹下载框问题解决方式
如题,简单记录一下这个问题的解决的方法,导致问题的核心原因是:ajaxfileupload不支持响应头ContentType为application/json的设置.而且IE也不支持这样的格式,而当我 ...
- 20170225-第三件事:FR0002测试
第三件事:FR0002测试 MATNR WERKS BERID 800000217 I010 问题,上for all entrys… 1 ...
- Dom解析XMl文档
XMl文档 <?xml version = "1.0" encoding = "UTF-8"?> <books> <book bo ...
- install build tools 25.0.2 and sync the project
install build tools 25.0.2 and sync the project in android studio bundle.gradle,将buildToolsVersion修改 ...
- dedecms列表页如何调用栏目关键词和描述
问:dedecms列表页如何调用栏目关键词和描述 答:有人问起dedecms列表页如何调用栏目关键词和描述.解答如下: 自己实验了下总结方法如下:(以下方法使用于栏目封面和列表和内容页,其他的地方没有 ...
- Oracle :多实例切换
Connecting to 10.1.4.21:22...Connection established.To escape to local shell, press 'Ctrl+Alt+]'. La ...
- SpringMVC实现ajax文件上传
SpringMVC实现文件上传,直接上代码: 后台代码: 01 @RequestMapping(value = "/uploadApk") 02 @ResponseBody 03 ...
- NOIP提高组2006-金明的预算方案
链接 分析:依赖型0-1背包问题,对于一个主件,可以挂0个,1个,2个附件,所以最终为4种状态情况下的最大值. #include "iostream" #include " ...