Lucene 6.5.0 入门Demo
Lucene 6.5.0 要求jdk 1.8
1.目录结构;
2.数据库环境;

private int id;
private String name;
private float price;
private String pic;
private String description
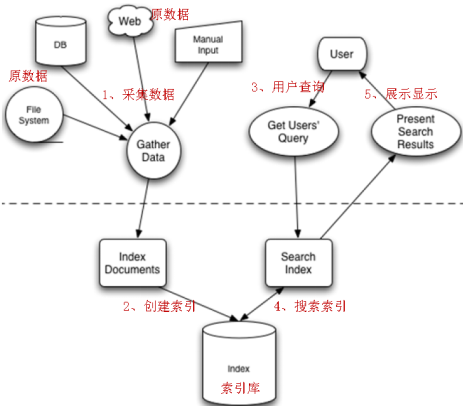
3.
Lucene是Apache的一个全文检索引擎工具包,它不能独立运行,不能单独对外提供服务。
/**
* Created by on 2017/4/25.
*/
public class IndexManager {
@Test
public void createIndex() throws Exception {
// 采集数据
BookDao dao = new BookDaoImpl();
List<Book> list = dao.queryBooks(); // 将采集到的数据封装到Document对象中
List<Document> docList = new ArrayList<Document>();
Document document;
for (Book book : list) {
document = new Document();
// store:如果是yes,则说明存储到文档域中
// 图书ID
// Field id = new TextField("id", book.getId().toString(), Store.YES); Field id = new TextField("id", Integer.toString(book.getId()), Field.Store.YES);
// 图书名称
Field name = new TextField("name", book.getName(), Field.Store.YES);
// 图书价格
Field price = new TextField("price", Float.toString(book.getPrice()), Field.Store.YES);
// 图书图片地址
Field pic = new TextField("pic", book.getPic(), Field.Store.YES);
// 图书描述
Field description = new TextField("description", book.getDescription(), Field.Store.YES); // 将field域设置到Document对象中
document.add(id);
document.add(name);
document.add(price);
document.add(pic);
document.add(description); docList.add(document);
}
//JDK 1.7以后 open只能接收Path///////////////////////////////////////////////////// // 创建分词器,标准分词器
Analyzer analyzer = new StandardAnalyzer(); // 创建IndexWriter
// IndexWriterConfig cfg = new IndexWriterConfig(Version.LUCENE_6_5_0,analyzer);
IndexWriterConfig cfg = new IndexWriterConfig(analyzer); // 指定索引库的地址
// File indexFile = new File("D:\\L\a\Eclipse\\lecencedemo\\");
// Directory directory = FSDirectory.open(indexFile);
Directory directory = FSDirectory.open(FileSystems.getDefault().getPath("D:\\Lpj\\JetBrains\\lucenceIndex1\\")); IndexWriter writer = new IndexWriter(directory, cfg);
writer.deleteAll(); //清除以前的index
// 通过IndexWriter对象将Document写入到索引库中
for (Document doc : docList) {
writer.addDocument(doc);
} // 关闭writer
writer.close();
} }
/**
* Created by on 2017/4/25.
*/
public class IndexSearch {
private void doSearch(Query query) {
// 创建IndexSearcher
// 指定索引库的地址
try {
// File indexFile = new File("D:\\Lpj\\Eclipse\\lecencedemo\\");
// Directory directory = FSDirectory.open(indexFile);
// 1、创建Directory
//JDK 1.7以后 open只能接收Path
Directory directory = FSDirectory.open(FileSystems.getDefault().getPath("D:\\Lpj\\JetBrains\\lucenceIndex1\\"));
IndexReader reader = DirectoryReader.open(directory);
IndexSearcher searcher = new IndexSearcher(reader);
// 通过searcher来搜索索引库
// 第二个参数:指定需要显示的顶部记录的N条
TopDocs topDocs = searcher.search(query, 10); // 根据查询条件匹配出的记录总数
int count = topDocs.totalHits;
System.out.println("匹配出的记录总数:" + count);
// 根据查询条件匹配出的记录
ScoreDoc[] scoreDocs = topDocs.scoreDocs; for (ScoreDoc scoreDoc : scoreDocs) {
// 获取文档的ID
int docId = scoreDoc.doc; // 通过ID获取文档
Document doc = searcher.doc(docId);
System.out.println("商品ID:" + doc.get("id"));
System.out.println("商品名称:" + doc.get("name"));
System.out.println("商品价格:" + doc.get("price"));
System.out.println("商品图片地址:" + doc.get("pic"));
System.out.println("==========================");
// System.out.println("商品描述:" + doc.get("description"));
}
// 关闭资源
reader.close();
} catch (IOException e) {
e.printStackTrace();
}
} @Test
public void indexSearch() throws Exception {
// 创建query对象
Analyzer analyzer = new StandardAnalyzer();
// 使用QueryParser搜索时,需要指定分词器,搜索时的分词器要和索引时的分词器一致
// 第一个参数:默认搜索的域的名称
QueryParser parser = new QueryParser("description", analyzer); // 通过queryparser来创建query对象
// 参数:输入的lucene的查询语句(关键字一定要大写)
Query query = parser.parse("description:java AND lucene"); doSearch(query); }

Lucene 6.5.0 入门Demo的更多相关文章
- Lucene 6.5.0 入门Demo(2)
参考文档:http://lucene.apache.org/core/6_5_0/core/overview-summary.html#overview.description 对于path路径不是很 ...
- vue入门 0 小demo (挂载点、模板、实例)
vue入门 0 小demo (挂载点.模板) 用直接的引用vue.js 首先 讲几个基本的概念 1.挂载点即el:vue 实例化时 元素挂靠的地方. 2.模板 即template:vue 实例化时挂 ...
- Omnet++ 4.0 入门实例教程
http://blog.sina.com.cn/s/blog_8a2bb17d01018npf.html 在网上找到的一个讲解omnet++的实例, 是4.0下面实现的. 我在4.2上试了试,可以用. ...
- spring web flow 2.0入门(转)
Spring Web Flow 2.0 入门 一.Spring Web Flow 入门demo(一)简单页面跳转 附源码(转) 二.Spring Web Flow 入门demo(二)与业务结合 附源码 ...
- 【SSH系列】初识spring+入门demo
学习过了hibernate,也就是冬天,经过一个冬天的冬眠,当春风吹绿大地,万物复苏,我们迎来了spring,在前面的一系列博文中,小编介绍hibernate的相关知识,接下来的博文中,小编将继续介绍 ...
- 基于springboot构建dubbo的入门demo
之前记录了构建dubbo入门demo所需的环境以及基于普通maven项目构建dubbo的入门案例,今天记录在这些的基础上基于springboot来构建dubbo的入门demo:众所周知,springb ...
- lua入门demo(HelloWorld+redis读取)
1. lua入门demo 1.1. 入门之Hello World!! 由于我习惯用docker安装各种软件,这次的lua脚本也是运行在docker容器上 openresty是nginx+lua的各种模 ...
- netty入门demo(一)
目录 前言 正文 代码部分 服务端 客服端 测试结果一: 解决粘包,拆包的问题 总结 前言 最近做一个项目: 大概需求: 多个温度传感器不断向java服务发送温度数据,该传感器采用socket发送数据 ...
- canal入门Demo
关于canal具体的原理,以及应用场景,可以参考开发文档:https://github.com/alibaba/canal 下面给出canal的入门Demo (一)部署canal服务器 可以参考官方文 ...
随机推荐
- C#编写高并发数据库控制
往往大数据量,高并发时, 瓶颈都在数据库上, 好多人都说用数据库的复制,发布, 读写分离等技术, 但主从数据库之间同步时间有延迟.代码的作用在于保证在上端缓存服务失效(一般来说概率比较低)时,形成倒瓶 ...
- Java8新特性Lambda表达式
List<RoleDO> allRoles = roleService.list(); //获取角色中备注不是app的集合List<RoleDO> webRoles = all ...
- ext笔记
命名 The top-level namespaces and the actual class names should be CamelCased. Everything else shoul ...
- C++系统学习之五:表达式
表达式由一个或多个运算对象组成,对表达式求值将得到一个结果.字面值和变量是最简单的表达式,其结果就是字面值和变量的值.把一个运算符和一个或多个运算对象组合起来可以生成较复杂的表达式. 基础 1.基本概 ...
- [LUOGU] P2330 [SCOI2005]繁忙的都市
题目描述 城市C是一个非常繁忙的大都市,城市中的道路十分的拥挤,于是市长决定对其中的道路进行改造.城市C的道路是这样分布的:城市中有n个交叉路口,有些交叉路口之间有道路相连,两个交叉路口之间最多有一条 ...
- Python包,json&pickle,time&datetime,random模块
补充内容: 解决模块循环导入的两种方法:(不得已而为之,表示程序结构不够严谨) 将导入模块语句放在文件最下方 保证语句导入之前函数内代码能够被执行 将导入语句放进函数体内 使其不影响整个函数的运行 包 ...
- Lex与Yacc学习(三)之符号表
符号表 列举单词表的方式虽然简单但是不全面,如果在词法分析程序运行时可以构建一个单词表,那么就可以在添加新的单词时不用修改词法分析程序. 下面示例便利用符号表实现,即在词法分析程序运行时从输入文件中读 ...
- progit 学习笔记-- 1 第一章 第二章
* 1 起步** 关于版本控制*** 什么是版本控制?记录文件变化,查阅特定版本,回溯到之前的状态.任何类型的文件进行版本控制.复制整个目录 加上备份时间 简单 混淆 无法恢复本地版本控制 数据库记 ...
- centos 装 android studio
一.安装前的准备 1.1.如果你还没有安装ubuntu 14.04 LTS系统,请参考下面的文章安装 http://blog.csdn.net/lsyz0021/article/details/521 ...
- PYDay1-洗剑
学习语言的阶段: 第一阶段:所有东西都是新的::一个月 第二阶段:开始懂一些::一个月 第三阶段:感觉自己是不可战胜的:第三~第四个月 第四阶段:突然感觉什么都不知道,开发是无止境的::培训阶段不会遇 ...