[C陷阱和缺陷] 第3章 语义“陷阱”
第3章 语义“陷阱”
一个句子哪怕其中的每个单词都拼写正确,而且语法也无懈可击,仍然可能有歧义或者并非书写者希望表达的意思。程序也有可能表面上是一个意思,而实际上的意思却相去甚远,本章考查了若干种可能引起上述歧义的程序书写方式。
3.1 指针与数组
C语言中指针与数组这两个概念之间的联系是如此密不可分,以至于如果不能理解其中一个概念,就不可能理解另一个概念。而且,C语言对这些概念的处理,
在某些方面与其它任何为人熟知的程序语言都不同。
C语言的数组值得注意的地方有以下两点:
- 1 C语言中只有一维数组,而且数组的大小在初始化时必须确定且要为常数。然而,数组的对象可以是任何类型的对象,当然可以是另一个数组,所以要“仿真”出一个多维数组并不是难事。
- 2 对于数组来说,我们只能够做两件事:确定数组的大小,以及获得指向该数组下标为0的元素的指针。其它有关数组的操作,哪怕乍看上去是以数组下标进行运算的,实际上都是通过指针进行的。
换句话说,任何一个数组下标运算都等同于一个对应的指针运算,因此我们完全可以依据指针行为定义数组下标的行为。
一旦我们理解了上面两点的含义,那么理解数组的运算不过是小菜一碟。需要特别指出的一点是,编程者应该具备将数组运算与它们对应的指针运算融会贯通的能力。许多程序设计语言中都内建有索引运算,在C语言中索引运算是以指针算术的形式来定义的。
现在考虑下面的例子:
int calendar[12][31]; 这个语句声明了calendar数组是一个拥有12个元素的数组,每个元素又是一个拥有31个元素的数组。因此sizeof(calendar)的值为12314。如果calendar不是用于sizeof的操作数,那么在其它场合下,calendar总是被转换成一个指向calendar数组首元素的指针。
假设a是一个拥有3个整型元素的数组,看下面的例子
int *p = a;上面就是把数组a首元素的地址赋给指针p。注意,我们并没有写成:
int *p = &a; 这样写是非法的,因为&a是一个指向数组的指针,而p是一个指向整型变量的指针,它们的类型不匹配。
继续我们的讨论,现在p指向数组a中下标为0的元素,则p+1指向数组下标为1的元素,则p+1指向数组下标为2的元素,依次类推。如果希望p可以指向数组a中下标为1的元素,可以这样写:
p = p + 1; 或者 p++;
除了a作为sizeof的操作数这一情况,在其它的情况下数组名a都表示指向数组中下标为0的元素的指针。sizeof(a) 的结果是整个数组的大小,而不是指向数组a中元素的指针的大小。
从上面的讨论中,我们不难得出一个结论:*a即数组a中下标为0的元素的解引用。例如,我们可以这样写:
*a = 84; 上面语句将数组a中下标为0的元素的值重新设置为84。同理,(a+i)是数组a中下标为i的解引用,这种写法是如此常用,因此它被简记为 a[i] 。
现在我们可以讨论“二维数组”了,正如前面所讨论的,它是以数组为元素的数组。尽管我们可以使用指针来编写操纵一维数组程序,这在一维情况下并不难,但是对于二维数组来说,使用下标的形式更加方便且容易理解。否则只使用指针来操纵二维数组,我们将会很头疼,且容易遭遇到隐藏的BUG。
sizeof(calendar[4])的结果是314,在看下面这个例子:
p = calendar[4];上面语句使p指向calendar[4]中下标为0的元素。i = calendar[4][7]也可以写成下面这样:
i = *(calendar[4] + 7);也可以进一步写成下面这样:
i = *(*(calendar+4)+7); 从这里我们可以看出,使用数组下标的形式,很明显要比完全使用指针的形式看起来简便易懂地多。
下面我们再看:
p = calendar; 上面语句是非法的,因为calendar是一个二维数组,即“数组的数组”,calendar数组名表示一个指向数组的指针,而p是一个指向整型变量的指针,类型不匹配。
很明显,我们需要定义一个指向数组的指针,比如下面这样:
int (*ap)[31];上面语句表明ap是一个指针,指向拥有31个整型元素的数组,即数组指针。而*ap是一个拥有31个整型元素的数组。因此我们可以这样写:
ap = calendar; 这样ap指向数组calendar的第一个元素,也就是数组calendar中第1个拥有31个元素的数组。
假定在新的一年开始时,需要清空calendar数组,用下标形式很容易做到:
int month,day;
for(month=0;month<12;month++)
{
for(day=0;day<12;day++)
ap[month][day] = 0;
}
上面的例子也可以用指针实现:
int month,day;
for(month=0;month<12;month++)
{
for(day=0;day<12;day++)
*( *(ap + month) + day ) = 0;
}
也可以使用数组指针ap用步进的方式来遍历数组:
int (*monthp)[31]
for(monthp=calendar; monthp<&calendar[12]; monthp++)
{
int *dayp;
for(dayp=*monthp; dayp<&(*monthp[31]); dayp++)
*dayp = 0;
}
上面例子的讨论虽然有点偏离本书的主题,但是这个例子能够很好地揭示出C语言中数组和指针之间独特的关系,从而更清楚明白地阐述这两个概念。
3.2 非数组的指针
在C语言中,字符串常量代表了一块包括了字符串中所有字符以及一个空字符'\0'的内存区域的地址。假定我们有两个这样的字符s和t,要求将这两个字符串连接成另一个字符串r。
要做到这一点,我们可以借助常用的库函数strcpy和strcat。下面的方法一目了然,可并不能满足我们的要求:
char *r;
strcpy(r,s);
strcat(r,t);
之所以不行的原因是不能确定r指向何处,指向的地址处有足够的内存空间来容纳这两个字符串。所以我们要让r指向的地址被分配足够的内存空间来容纳字符串,比如下面这样:
char r[100];
strcpy(r,s);
strcat(r,t);
上面程序的缺陷在于,万一字符串r和t的长度太大,超出了数组r的大小,则会造成内存泄漏,这种方法也不是很理性。所以C语言给我们提供了malloc函数,该函数接受一个整数,然后分配能够容纳同样数目字符的一块内存,而且C语言还提供了strlen函数,该函数返回一个字符串的长度(不包括'\0')。有了这两个库函数,下面可以这样操作:
char *r = (char *)malloc( strlen(r) + strlen(t) ); //malloc的返回类型为void *,所以要使用(char *)强制类型转换
strcpy(r,s);
strcat(r,t);
上面这个例子还是错的,第一,malloc有可能无法分配内存失败,分配失败会返回一个NULL(空指针),要判断malloc是否分配成功;
第二,给r分配的内存应该用free函数及时释放掉。因为在前面的例子中,r是一个局部变量,离开r的作用域后r会被自动释放内存。但malloc会显式地给r分配内存,离开作用域后r不再会自动释放内存,所以需要显式地使用free释放内存。
第三也是最重要的,r没有被分配足够的内存空间,因为strlen函数返回的字符串长度没有计算'\0',而字符串要求以'\0'结尾,所以要多分配一个字符的内存。避免上面这些问题的程序如下:
char *r = (char *)malloc( strlen(r) + strlen(t) + 1 );
if(!r)
{
printf("malloc failed!\n");
exit(1);
}
strcpy(r,s);
strcat(r,t);
free(r);3.3 作为参数的数组声明
在C语言中,我们没有办法可以将一个数组作为函数参数直接传递。如果我们使用数组名作为函数参数,那么数组名会被立刻转换为指向该数组第一个元素的指针。例如下面的语句:
char str[ ] = "hello";声明了str是一个字符数组,那么将数组名作为参数传递给函数:
printf("%s\n",str);实际上与将数组第一个元素的指针作为参数传递给函数的作用完全等效,即:
printf("%s\n",&str[0]);
因此将数组作为函数参数毫无意义,C语言会自动将作为参数的数组转换为对应的指针。也就是说,像这样的写法:
int strlen(char str[ ])
{
/* 具体内容 */
}与下面的写法完全相同:
int strlen(char *str)
{
/* 具体内容 */
}3.4 避免“举隅法”
在《牛津英语词典》中,对"举隅法"是这样解释的:以含义更宽泛的词语来代替含义较为狭窄的词语,或者相反;例如,以整体代表部分,以部分代表整体等等。《牛津英语词典》中这一词条的说明,倒是恰如其份地描述了C语言中一个常见的陷阱:混淆指针与指针所指向的数据,尤其是关于字符串,例如:
char *p,*q;
p = "xyz";
q = p;有时候会误认为上面的赋值语句使得p的值就是字符串"xyz",但实际上不是,p的值是一个指向由'x'、'y'、'z'、'\0'组成的字符数组中第一个字符的指针。语句q = p,使q和p指向同一个内存(存储'x'的内存),这个赋值语句并没有同时复制内存中的字符。在ANSI C标准下,试图修改字符串的常量的行为是非法的:
p[1] = 'Y'; //非法,error3.5 空指针并非空字符串
除了一个特殊情况,在C语言中将一个整数转换为一个指针,得到的结果都取决于具体的C编译器实现。这个特殊情况就是常数0,编译器保证由常数0转换而来的指针不等于任何有效的指针。只是出于代码文档化的考虑,常数0这个值经常用一个符号来代替:
#define NULL 0无论使用常数0,还是使用符号NULL,效果都是一样的。需要记住的一点是,当常数0被转换为指针使用时,这个指针不能被解除引用。换句话说,我们将0赋值给一个指针变量时,不能再解引用去访问该指针指向的内存。下面的写法是完全合法的:
if( p == (char *) 0 ) { }但是如果是下面这样就是非法的:
if( strcmp (p, (char *) 0 ) == 0 ) { }非法的原因在于strcmp函数的实现过程中,会解引用 常数0转换成的指针(空指针),来访问其指向的内存,而空指针不能解引用。另外使用printf(p)也是非法的。
3.6 边界计算与不对称边界
在所有常见的程序设计错误中,最难以察觉的一类是“栏杆错误”, 也常被称为“差一错误”。比如这个问题:100英尺长的围栏每隔10英尺需要一根支撑用的栏杆,一共需要多少跟栏杆呢?
如果不加思索,那么最显而易见的答案是将100除以10,得到的结果是10。当然这个答案是错误的,正确结果是11。这就是一个常见的栏杆错误。
下面是避免栏杆错误的两个通用原则:
- (1)首先考虑最简单情况下的特例,然后将得到的结果外推,这是原则一。
- (2)然后仔细计算边界,绝不掉以轻心,这是原则二。
将上面总结的内容牢记于心,我们现在来看整数范围内的计算。例如,假定整数x满足边界条件x>=16且x<37,那么x的可能取值个数有多少个?
根据原则一,我们考虑最简单情况下的特例。这里假定情况是x>=16且x<=17,x的取值个数为2个,为17-16=1,再 + 1。
再根据原则二,考虑一般情况,则x的取值个数为37-16=21,再+1,所以答案是22个。
一种考虑不对称边界的方式是,将上界视为某序列中第一个被占用的元素,将下界视为某序列中第一个被释放的元素, 如下图所示:
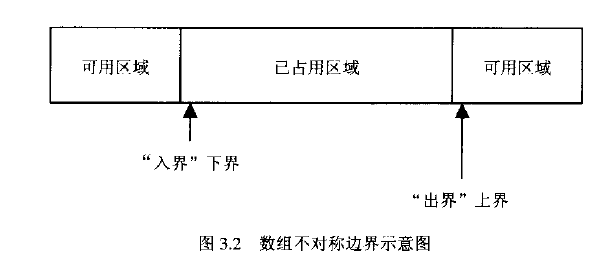
当处理各种不同类型的缓冲区时,这种看待问题的方式就特别有用。例如考虑这么一个函数,该函数的功能是将长度无规律的输入数据送到缓冲区(即一块能容纳N个字符的内存)中去,
每当这块内存被填满时,就将缓冲区的内容写出。缓冲区的声明如下:
#defien N 1024
static char buffer[1024];我们再设置一个指针变量,让它指向缓冲区的当前位置:
static char *bufptr;对于指针bufptr,是让其始终指向缓冲区中最后一个已占用的字符,还是始终指向缓冲区中第一个未占用的字符?前一种很有吸引力,但考虑到我们对“不对称边界”的偏好,后一种更为合适,使指针bufptr始终指向缓冲区中第一个未占用的字符,像下面这样:
*bufptr++ = c; 这个语句将输入字符放到缓冲区中,然后指针bufptr递增1,又指向缓冲区中第一个未占用的字符。
根据前面对“不对称边界”的考查,当指针bufptr与&buffer[0]相等时,缓冲区存放的内容为空,因此初始化时声明缓冲区为0时可以这么写:
bufptr = &buffer[0];也可以更简洁一点,直接写成:
bufptr = buffer; 这样,任何时候缓冲区已存放的字符数都是bufptr-buffer,因此我们可以通过将bufptr-buffer这个表达式与N做比较,来判断缓冲区是否已满。当缓冲区全部“填满”时,表达式bufptr-buffer的结果就是N,可以推断缓冲区中未占用的字符数为N-(bufptr-buffer)。
前面所有的预备知识一旦掌握,我们就可以开始编写程序了:
/*************************************************
功能: 调用flushbuffer函数来把缓冲区中的内容写出,而且flushbuffer函数会重置bufptr,使其指向缓冲区的起始位置
参数:
p 指向将要写入缓冲区的第1个字符
n 代表将要写入缓冲区的字符数
*************************************************/
void bufwrite(char *p,int n)
{
while(--n >= 0)
{
if(bufptr == &buffer[N])
flushbuffer();
*bufptr++ = *p++;
}
}


3.7 求值顺序
C中所有其它的运算符对操作数的求值顺序都是未定义的。事实上,赋值运算符不对求值顺序做出任何保证。
出于这个原因,下面这种将数组x中的前n个元素复制到数组y中的方法是不可行的:
i = 0;
while(i < n)
y[i] = x[i++];其中的问题是y[i]的地址并不保证在i增长之前被求值。在某些实现中,这是可能的;但在另一些实现中却不可能。另一种情况出于同样的原因会失败:
i = 0;
while(i < n)
y[i++] = x[i];而下面的代码是可以工作的:
i = 0;
while(i < n) {
y[i] = x[i];
i++;
}3.7 &&、||和!运算符
&&、||和!运算符将它们的参数视为仅有“真”或“假”,通常约定0代表“假”而其它的任意值都代表“真”。这些运算符返回1表示“真”而返回0表示“假”,而且&&和||运算符当可以通过左边的操作数确定其返回值时,就不会对右边的操作数进行求值。
因此!10是零,因为10非零;10 && 12是1,因为10和12都非零;10 || 12也是1,因为10非零。另外,最后一个表达式中的12不会被求值,10 || f()中的f()也不会被求值。、
考虑下面这段用于在一个表中查找一个特定元素的程序:
i = 0;
while(i < tabsize && tab[i] != x)
i++;这段循环背后的意思是如果i等于tabsize时循环结束,元素x未被找到。否则,i包含了元素x的索引。
假设这个例子中的&&不小心被替换为了&,这个循环可能仍然能够工作,所以要注意不要少打了一个&。
3.9 整数溢出
C语言中存在两类整数算数运算,有符号运算与无符号运算。在无符号算术运算中,没有所谓的“溢出”一说。
如果算术运算符中的一个操作数是有符号整数,另一个是无符号整数,那么有符号整数会被转换为无符号整数,“溢出”也不可能发生。但是当两个操作数都是有符号整数时,“溢出”就有可能发生,而且“溢出”的结果是未定义的。
例如,假设a和b是两个非负整型变量,你希望测试a + b是否溢出。一个明显的办法是这样的:
if(a + b < 0)
complain(); 这并不能正常运行,当a + b确实发生“溢出”时,对于结果的任何假设都不再可靠。例如,在某些机器上,一个加法运算会将一个内部寄存器设置为四种状态:正、负、零或溢出。 在这样的机器上,编译器有权将上面的例子实现为首先将a和b加在一起,然后检查内部寄存器状态是否为负。如果该运算溢出,内部寄存器将处于溢出状态,这个测试会失败。
一种正确的方式是将a和b都强制转换为无符号整数:
if( (unsigned int)a + (unsigned int)b > INT_MAX )
complain(); 此处的INT_MAX是一个已定义常量,代表可能的最大整数值。ANIS C标准在<limit.h>中定义了INT_MAX;如果是在其它C语言上实现,读者也许需要自己重新定义。
不需要用到无符号算术运算的另一个可行办法是:
if( a > INT_MAX - b )\
complain();3.10 为函数main提供返回值
最简单的C程序也许是像下面这样:
main()
{
} 这个程序包含一个不易察觉的错误,main函数与其它任何函数一样,如果并未显式声明返回类型,那么函数返回类型就默认为是整型。但是这个程序中并没有给出任何返回值。
通常来说,这不会造成什么危害。然而,在某些情形下main函数的返回值却并非无关紧要。大多数C语言实现都通过main函数的返回值,来告知操作系统该函数执行成功还是失败。典型的处理方案是,返回值为0代表程序执行成功,返回值非0则表示程序执行失败。如果一个程序的main函数并不返回任何值,那么有可能看上去执行失败,所以返回值是很有必要的。
[C陷阱和缺陷] 第3章 语义“陷阱”的更多相关文章
- [C陷阱和缺陷] 第1章 词法“陷阱”
有感自己的C语言在有些地方存在误区,所以重新仔细把"C陷阱和缺陷"翻出来看看,并写下这篇博客,用于读书总结以及日后方便自身复习. 第1章 词法"陷阱" 1.1 ...
- [C陷阱和缺陷] 第2章 语法“陷阱”
第2章 语法陷阱 2.1 理解函数声明 当计算机启动时,硬件将调用首地址为0位置的子例程,为了模拟开机时的情形,必须设计出一个C语言,以显示调用该子例程,经过一段时间的思考,得出语句如下: ( * ...
- c缺陷与陷阱笔记-第三章 语义陷阱
1.关于数组和数组指针 数组的名字默认是常量指针,值不能改变的,例如 int a[]={1,2,3,...},这个a的类型时int *,所以如果有int *p,那么a=p是合法的,其他的指针类型,例如 ...
- [C陷阱和缺陷] 第7章 可移植性缺陷
C语言在许多不同的系统平台上都有实现.的确,使用C语言编写程序的一个首要原因就是,C程序能够方便地在不同的编程环境中移植. 不同的系统有不同的需求,因此我们应该能够预料到,机器不同则其上的C语 ...
- [C陷阱和缺陷] 第6章 预处理器
在严格意义上的编译过程开始之前,C语言预处理器首先对程序代码作了必要的转换处理.因此,我们运行的程序实际上并不是我们所写的程序.预处理器使得编程者可以简化某些工作,它的重要性可以由两个主要的原因说 ...
- [C陷阱和缺陷] 第5章 库函数
有关库函数的使用,我们能给出的最好建议是尽量使用系统头文件,当然也可以自己造轮子,随个人喜好.本章将探讨某些常用的库函数,以及编程者在使用它们的过程中可能出错之处. 5.1 返回整数的getc ...
- [C陷阱和缺陷] 第4章 连接
一个C程序可能是由多个分别编译的部分组成,这些不同部分通过连接器合并成一个整体.在本章中,我们将考查一个典型的连接器,注意它是如何对C程序进行处理的,从而归纳出一些由于连接器的特点而可能导致的错误. ...
- 《C陷阱与缺陷》之1词法"陷阱"
编译器中负责将程序分解为一个一个符号的部分,一般称为"词法分析器".在C语言中,符号之间的空白(包括空格符.制表符或换行符)将被忽略. 1.=不同于== C语言使用符号" ...
- 《C陷阱与缺陷》之1词法"陷阱"
编译器中负责将程序分解为一个一个符号的部分,一般称为"词法分析器".在C语言中,符号之间的空白(包括空格符.制表符或换行符)将被忽略. 1.=不同于== C语言使用符号" ...
随机推荐
- [luoguP1011] 车站(递推)
传送门 蒟蒻我关系式没有找出来. 直接模拟递推过程好了. 代码 #include <cstdio> #define N 21 int a, n, m, x, y; int up[N][2] ...
- codeforces365A
#include<stdio.h> #include<string.h>//刚做codeforces上的比赛题我都没看懂啊啊啊啊啊啊 int main() { int n,m, ...
- Flask组件:flask-sqlalchemy & flask-script & flask-migrate
flask-sqlalchemy组件 项目目录结构: flask目录 # 项目名 |--- flaskdir |--- static # 静态文件 |--- templates # 模板 |--- m ...
- ci框架(codeigniter)Email发送邮件、收件人、附件、Email调试工具
ci框架(codeigniter)Email发送邮件.收件人.附件.Email调试工具 Email 类 CodeIgniter 拥有强大的 Email 类来提供如下的功能: 多 ...
- [bzoj1895][Pku3580]supermemo_非旋转Treap
supermemo bzoj-1895 Pku-3580 题目大意:给定一个n个数的序列,需支持:区间加,区间翻转,区间平移,单点插入,单点删除,查询区间最小值. 注释:$1\le n\le 6.1\ ...
- Google Chrome Developer Tools
原文:https://www.oschina.net/p/chromedevtools Google发布了Google Chrome Developer Tools,这是一系列面向Chrome开发者的 ...
- Kernel与用户进程通信
测试IPv6 ready logo rfc 3315的时候,遇到一个问题,要求在收到ICMPv6 RA的时候,DHCPv6 Client要发Solicit消息.在平常的应用中,都是启动DHCPv ...
- 在Windows上安装Nexus
在Windows上安装Nexus 学习了:https://www.cnblogs.com/yucongblog/p/6696736.html 下载地址:https://sonatype-downloa ...
- Linux改动/etc/profile配置错误command is not found自救方法
我的CSDN博客地址: http://blog.csdn.net/caicongyang 博主之前在改动了/etc/profile配置文件方法后,导致bash命令无法用 运行ls命令结果例如以下: - ...
- psping
psping工具功能主要包括:ICMP Ping.TCP Ping.延迟测试.带宽测试,是微软出品. 下载地址:https://download.sysinternals.com/files/PSTo ...