[svc]linux正则实战(grep/sed/awk)
企业实战: 过滤ip
过滤出第二行的 192.168.2.11.
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.2.11 netmask 255.255.255.0 broadcast 192.168.2.255
ether 00:0c:29:41:85:df txqueuelen 1000 (Ethernet)
RX packets 17934 bytes 9131091 (8.7 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 13981 bytes 2627375 (2.5 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
深入浅出linux三剑客之sed必杀技一例
深入浅出linux三剑客之awk必杀技一例
方法1: 使用sed替换为空(删除首尾多余)
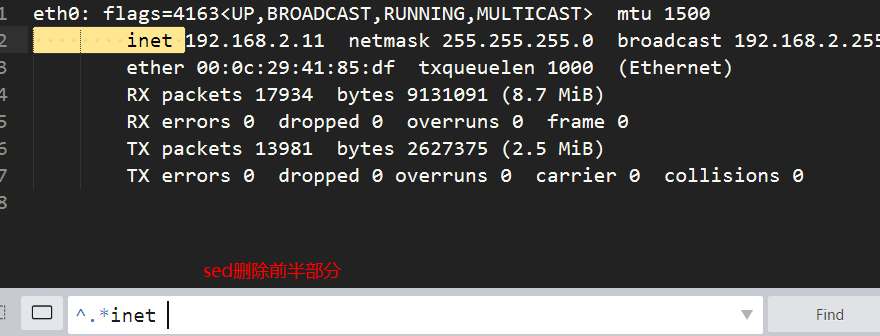
- 先打印第二列
[root@n1 ~]# ifconfig eth0|sed -n '2p'
inet 192.168.2.11 netmask 255.255.255.0 broadcast 192.168.2.255
- 删除前面多余的
[root@n1 ~]# ifconfig eth0|sed -n '2p'|sed 's#^.*inet ##g'
192.168.2.11 netmask 255.255.255.0 broadcast 192.168.2.255
- 删除后面多余的,得到结果
[root@n1 ~]# ifconfig eth0|sed -n '2p'|sed 's#^.*inet ##g'|sed 's#net.*$##g'
192.168.2.11 <==这里有2个空格
[root@n1 ~]# ifconfig eth0|sed -n '2p'|sed 's#^.*inet ##g'|sed 's# net.*$##g'
192.168.2.11
方法2: 使用sed行号指定行
- 取消默认输出
[root@n1 ~]# ifconfig eth0|sed -n 's#^.*inet ##g'
- 仅输出匹配到的内容(可能有多行)
[root@n1 ~]# ifconfig eth0|sed -n 's#^.*inet ##gp'
192.168.2.11 netmask 255.255.255.0 broadcast 192.168.2.255
- 仅输出第二行
[root@n1 ~]# ifconfig eth0|sed -n '2s#^.*inet ##gp'
192.168.2.11 netmask 255.255.255.0 broadcast 192.168.2.255
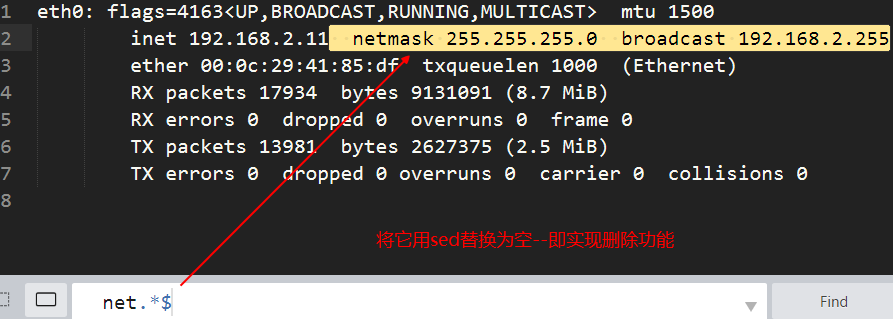
- 删除结尾多余的(-n 取消默认输出)
[root@n1 ~]# ifconfig eth0|sed -n '2s#^.*inet ##gp'|sed -n 's# netmask.*$##g'
- 删除结尾多余的,并打印结果
[root@n1 ~]# ifconfig eth0|sed -n '2s#^.*inet ##gp'|sed -n 's# netmask.*$##gp'
192.168.2.11
另一种理解
[root@n1 ~]# ifconfig eth0|sed -n '2p'
inet 192.168.2.11 netmask 255.255.255.0 broadcast 192.168.2.255
[root@n1 ~]# ifconfig eth0|sed -n '2s#^.*inet ##gp'
192.168.2.11 netmask 255.255.255.0 broadcast 192.168.2.255
方法3: sed的后向引用: 最佳方案
理解sed的后向引用
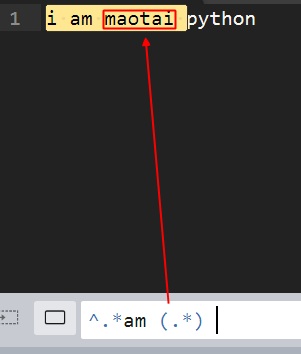
sed 's#()()#\1\2#g' #\1引用第一个括号内容 \2引用第二个括号内容
注意: 如果正则里有了()等,需要转义的字符,特别多,且麻烦. 就需要加上-r参数了. 加上后,无需顾忌正则表达式里的特殊字符.
匹配前面的

匹配后面的

中间括号匹配 maotai
过滤ip:
有空格

- 干掉空格
[root@n1 ~]# ifconfig eth0|sed -nr 's#^.*inet (.*) net.*$#\1#gp'
192.168.2.11
另一种思路: 直接匹配到ip
grep过滤ip和邮箱
这种写的比较烦
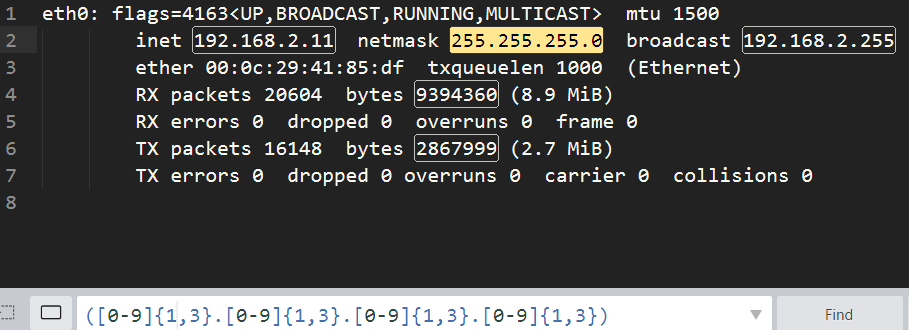
这种简化一下
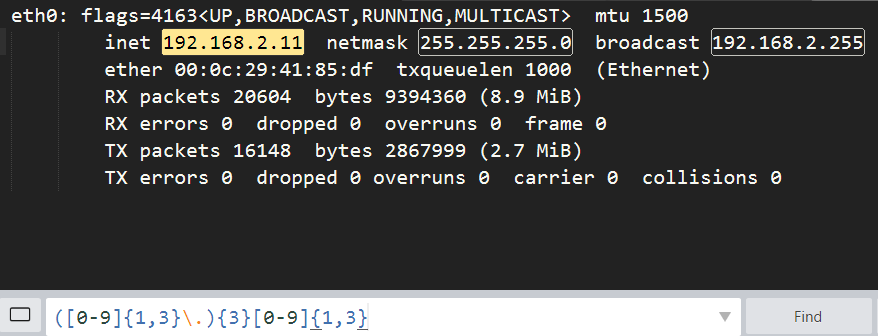
[root@n1 ~]# ifconfig eth0|sed -nr '2s#^.*inet ([0-9]{,3}.[0-9]{,3}.[0-9]{,3}.[0-9]{,3}) net.*$#\1#gp'
192.168.2.11
- 简化写
[root@n1 ~]# ifconfig eth0|sed -nr '2s#^.*inet (([0-9]{,3}.){3}[0-9]{,3}) net.*$#\1#gp'
192.168.2.11
企业案例: 取出stat文件的权限644
[root@n1 ~]# stat a.log
File: ‘a.log’
Size: 19 Blocks: 8 IO Block: 4096 regular file
Device: fd00h/64768d Inode: 68061539 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2018-03-04 11:30:25.072372498 +0800
Modify: 2018-03-04 11:30:23.781372221 +0800
Change: 2018-03-04 11:30:23.781372221 +0800
[root@n1 ~]# stat a.log |sed -nr '4s#^.*\(0(.*)\/-.*$#\1#gp'
644
另一个企业实例: 将maotai.txt文件的权限位rw-r--r-- #将这个转为644打印.
深入浅出linux三剑客之sed必杀技一例
深入浅出linux三剑客之awk必杀技一例
方法1: 使用awk过滤列,使用tr替换后,awk求和打印.
[root@n1 ~]# ll maotai.txt
-rw-r--r-- 1 root root 292 Mar 3 21:28 maotai.txt
rw-r--r-- #将这个转为644打印.
r 4表示
w 2表示
x 1表示
- 0表示
tr命令:
[root@n1 ~]# echo 'mm'|tr 'm' 'Z'
ZZ
[root@n1 ~]# echo "HELLO MAOTAI"|tr 'A-Z' 'a-z'
hello maotai
- 将权限位替换为数字
[root@n1 ~]# ll maotai.txt|awk -F ' ' '{print $1}'|tr 'rwx-' '4210'
0420400400
- 不分隔求每3项的和
[root@n1 ~]# ll maotai.txt|awk -F ' ' '{print $1}'|tr 'rwx-' '4210'|awk -F '' '{print $2+$3+$4""$5+$6+$7""$8+$9+$10}'
644
方法2: 使用cut过滤列,使用tr替换后,awk求和打印.
[root@n1 ~]# ll maotai.txt|cut -c2-10|tr 'rwx-' '4210'
420400400
方法3: 巧用stat命令
[root@n1 ~]# stat maotai.txt |sed -nr '4s#^.*\(0(.*)/-.*$#\1#gp'
644
方法4: 使用stat+awk过滤

- 先过滤出列
[root@n1 ~]# stat maotai.txt |awk -F '[0/]' '{print $2}'
96 regular file
644
18-
18-
18-
- 过滤第四行的某一列
[root@n1 ~]# stat maotai.txt |awk -F '[0/]' 'NR==4 {print $2}'
644
方法5: 使用stat自带参数
[root@n1 ~]# stat -c %a maotai.txt
644
方法6: grep正则过滤
[root@n1 ~]# stat maotai.txt |grep -Eo "^.*/-"
Access: (0644/-
[root@n1 ~]# stat maotai.txt |grep -Eo "^.*/-"|grep -o "[4-6]*"
644
三点思路小结:
1.通过stat输出包含目录的内容
2.通过head tail sed awk grep定位到单行 =>取行
3.通过cut awk等设置分隔符取出所需的段内容 =>取列
4.当结果中包含了我们想要的东西时候,该命令可能有参数可以直接取出结果
企业实例: 用sed替换/etc/passwd的首尾两列
思路: ()()() 第一列,中间的,最后一列, 使用sed的后向引用.
[root@n1 ~]# sed -nr '1s#([^:]+)(:.*:)(/.*$)#\3\2\1#gp' /etc/passwd
/bin/bash:x:0:0:root:/root:root
[svc]linux正则实战(grep/sed/awk)的更多相关文章
- [svc]linux正则及grep常用手法
正则测试 可以用sublime等工具快速的检测正则是否合适 china : 匹配此行中任意位置有china字符的行 ^china : 匹配此以china开关的行 china$ : 匹配以china结尾 ...
- linux 三大利器 grep sed awk 正则表达式
正则表达式目标 正则表达式单字符: 特定字符 范围字符:单个字符[ ] :代表查找单个字符,括号内为字符范围 数字字符:[0-9],[259] 查找 0~9 和 2.5 .9 中的任意一个字符 小写字 ...
- Linux 正则表达式 vi, grep, sed, awk
1. vi 表示内容的元字符 模式 含义 . 匹配任意字符 [abc] 匹配方括号中的任意一个字符.可以使用-表示字符范围,如[a-z0-9]匹配小写字母和阿拉伯数字. [^abc] 在方 ...
- linux 三剑客命令(grep,sed ,awk)
grep 命令 :强大的文本’搜索’工具 1.grep -n 'word' file_name 在file_name文件中找到word所在的所有行并显示.-n 为显示行号. 2 ...
- linux 三大利器 grep sed awk sed
sed主要内容和原理介绍 sed 流处理编辑器 sed一次处理一行内容,读入一行处理一行 sed不改变文件内容(除非重定向) sed 命令行格式 $ sed [options] 'command' f ...
- Linux三剑客grep/sed/awk
grep/sed/awk被称为linux的“三剑客” grep更适合单纯的查找或匹配文本: sed更适合编辑匹配到的文本: awk更适合格式化文本,对文本进行较复杂各式处理: Grep --color ...
- linux三剑客grep|sed|awk实践
最好先学习正则表达式的基本用法,以及正则表达式BREs,EREs,PREs的区别 此坑待填 grep sed awk
- 日志检索实战 grep sed
日志检索实战 grep sed 参考 sed命令 使用 grep -5 'parttern' inputfile //打印匹配行的前后5行 grep -C 5 'parttern' inputfile ...
- 【Linux】 字符串和文本处理工具 grep & sed & awk
Linux字符串&文本处理工具 因为用linux的时候主要用到的还是字符交互界面,所以对字符串的处理变得十分重要.这篇介绍三个常用的字符串处理工具,包括grep,sed和awk ■ grep ...
随机推荐
- Log4j 把不同包的日志打印到不同位置
如果需要将不同的日志打印到不同的地方,则需要定义不同的Appender,然后定义每一个 Appender的日志级别.打印形式.输出位置! 配置log4j.properties文件如下: ####### ...
- update pm storage
BEGIN #Routine body goes here... INSERT INTO EMS_PM_STORAGE ( AMOID, GP_BEGIN_TIME, EMS_RECORD_TIME, ...
- Maven2和ivy比较
Maven 2和Ivy常被放在一起对比,但实际上两者是不同类型的工具.Ivy仅提供依赖管理功能,但是Maven 2是一个软件项目管理综合工具,能够管理构建.报告.文档,以及根据中心化的信息来管理依赖. ...
- @Transactional注解事务不回滚不起作用无效
写在前面 数据库Mysql8.0 添加@Transactional注解后事务并未起作用. 修改表的引擎后ok了.(详看下面转载内容) ================================ ...
- Centos7-Lvs+Keepalived架构
Centos7-Lvs+Keepalived架构 LVS+Keepalived 介绍 1 . LVS LVS 是一个开源的软件,可以实现 LINUX 平台下的简单负载均衡. LVS 是 Lin ...
- 【Spring】spring的7个模块
Spring 是一个开源框架,是为了解决企业应用程序开发复杂性而创建的.框架的主要优势之一就是其分层架构,分层架构允许您选择使用哪一个组件,同时为 J2EE 应用程序开发提供集成的框架. Spring ...
- 【java】JVM的内存区域划分
学过C语言的朋友都知道C编译器在划分内存区域的时候经常将管理的区域划分为数据段和代码段,数据段包括堆.栈以及静态数据区.那么在Java语言当中,内存又是如何划分的呢? 由于Java程序是交由JVM执行 ...
- /struts-tags not found ,/struts-dojo-tags not found 上线后异常解决方案
上线到2003上后发现2个问题:1 缺少/struts-tags2 缺少/struts-dojo-tags在xp上不用直接指定这些文件的位置,但在其他的系统可能无法自动找到它的路径,一定要明确指定在w ...
- GIF Brewery for Mac(录制 Gif 动图工具)安装
1.软件简介 GIF Brewery 一款用于录制 Gif 动图等的工具. 2.资源列表 链接 提取密码 系统要求 软件语言 GIF Brewery for Mac v3.9.5 ltmf ma ...
- android图片等比例缩放 填充屏幕
在ImageView的t同事设置两个属性 android:adjustViewBounds="true"android:scaleType="fitXY"