笔记 Hadoop
今天有缘看到董西成写的《Hadoop技术内幕:深入解析MapReduce架构设计与实现原理》,翻了翻觉得是很有趣的而且把hadoop讲得很清晰书,就花了一下午的时间大致拜读了一下(仅浏览了感兴趣的部分,没有深入细节)。现把觉得有趣的部分记录如下。
JobControl
把各个job配置好后,放入JobControl中,JobControl会根据它们之间的依赖关系,分别进行调度。
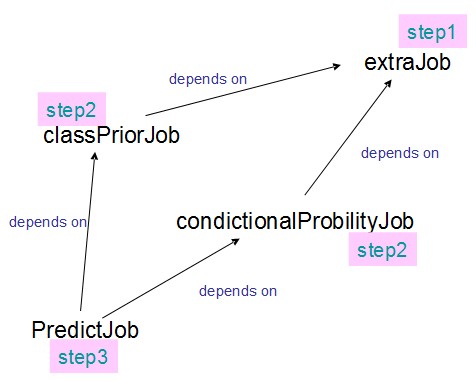
工作流引擎
除了JobControl外,还可以使用Oozie和Azkaban来进行工作流控制。相较于前者而言,Oozie和Azkaban可以使用图形化界面观看工作流的处理进度,另外还有其他更丰富的功能。
JobTracker
(Master)
是一个后台服务程序,启动后会一直监听并接收来自各个TaskTacker发送的心跳信息。心跳信息中包含节点资源的使用情况和任务运行情况。
作业控制:JobTracker在其内部以“三层多叉树”的方式描述和跟踪每个作业的运行状态。

当任何一个Task Attemp运行成功后,其上层对应的TaskInProgress会标注该任务运行成功;而当所有的TaskInProgress运行成功后,JobInProgress会标注整个作业运行成功。
JobTracker如何查找和定位各种对象?
为了查找和定位各种对象,JobTracker将相关信息封装成各种对象后,以key/value的形式保存到Map结构中。(在JDK中,Map以红黑树来实现)
1、作业ID查找对应的JobInProgress对象
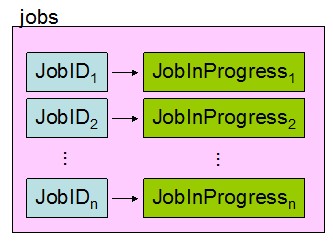
2、查找每个TaskTracker上运行的task

JobTracker的各种 操作(如监控、更新),实际上就是修改这些Map关系。
不过JobTracker存在单点故障(因为是Master/Slave结构)。如果已保存的任务或节点状态丢失,则所有正在运行的作业将会失败。
TaskTracker
(slave)
①运行于各个节点上的服务
②是JobTracker与Task之间的沟通桥梁,在两者间使用RPC进行通信。
对JobTracker和TaskTracker而言,前者为server,后者为client。
对TaskTracker和Task而言,前者为server,后者为client。
③执行两个功能:汇报心跳和执行命令
Hadoop对快排的优化
(1)轴枢选择
Hadoo将序列的首尾和中间元素的中位数作为轴枢,以避免出现极端不对称子序列的情况。(极端不对称子序列会导致快排算法的退化)
(2)子序列的划分
使用两个索引 i 和 j 分别从左右两端对序列进行扫描,并让索引i扫描到大于等于轴枢的元素停止,j扫描到小于等于轴枢的元素停止,然后交互两个元素(交换时索引不动),重复这个过程知道i和j相遇。
(3)对相同元素的优化
在每次划分子序列时,将与枢轴相同的元素集中存放在中间位置,让它们不再参与后续的递归处理,即将序列划分为三部分:小于轴枢、等于轴枢、大于轴枢。(这也是由于hadoop排序中会出现大量相等值的原因,这样做可以通过减少递归排序的数量从而提高算法的效率)
(4)减少递归次数
当子序列中元素数目小于13时,直接使用插入排序算法,不再使用递归。
第一代MapReduce框架的局限性
①扩展性差
JobTracker兼具资源管理和作业控制两个功能,因此成为系统性能扩展的最大瓶颈。
②单点故障
master/salve结构的通病
③资源利用率低
因为使用slot为资源分配模型,但slot粒度大,而且MapSlot和ReduceSlot不能share,因而会出现一种slot资源紧张而另一种空闲的尴尬状况。
④无法支持多种计算框架
几种比较vogue的框架有:
MapReduce:支持离线处理,可以被搜索引擎公司用于建立网页索引。
Storm:支持在线处理,tweeter使用的框架
Spark:迭代式计算框架,可以用于自然语言处理、数据挖掘,如PageRank计算、分类、聚类。对性能要求高的DM,可以使用MPI。
S4:流式处理框架,Yahoo。
而第一代的Hadoop只能支持MapReduce这一种计算框架。
互联网公司希望可以将这些框架统一用到自己的集群资源上,因此诞生了资源管理与调度平台,典型的代表有:
YARN(Apache),现可以运行MapReduce和Storm(今天才在InfoQ上看到的新闻)
Corona(Facebook)
Mesos(Berkeley)
笔记 Hadoop的更多相关文章
- 分布式计算框架学习笔记--hadoop工作原理
(hadoop安装方法:http://blog.csdn.net/wangjia55/article/details/53160679这里不再累述) hadoop是针对大数据设计的一个计算架构.如果你 ...
- Hadoop学习笔记Hadoop伪分布式环境建设
建立一个伪分布式Hadoop周围环境 1.主办(Windows)顾客(安装在虚拟机Linux)网络连接. a) Host-only 主机和独立客户端联网: 好处:网络隔离: 坏处:虚拟机和其他serv ...
- 二十六、Hadoop学习笔记————Hadoop Yarn的简介复习
1. 介绍 YARN(Yet Another Resource Negotiator)是一个通用的资源管理平台,可为各类计算框架提供资源的管理和调度. 之前有提到过,Yarn主要是为了减轻Hadoop ...
- [hadoop读书笔记] Hadoop下各技术应用场景
1.数据采集 对于数据采集主要分为三类,即结构化数据库采集,日志和文件采集,网页采集. 对于结构化数据库,采用Sqoop是合适的,可以实现结构化数据库中数据并行批量入库到hdfs存储.对于网页采集,前 ...
- Hadoop学习笔记——Hadoop经常使用命令
Hadoop下有一些经常使用的命令,通过这些命令能够非常方便操作Hadoop上的文件. 1.查看指定文件夹下的内容 语法: hadoop fs -ls 文件文件夹 2.打开某个已存在的文件 语法: h ...
- 大数据学习笔记——Hadoop编程实战之Mapreduce
Hadoop编程实战——Mapreduce基本功能实现 此篇博客承接上一篇总结的HDFS编程实战,将会详细地对mapreduce的各种数据分析功能进行一个整理,由于实际工作中并不会过多地涉及原理,因此 ...
- 大数据学习笔记——Hadoop编程之SequenceFile
SequenceFile(Hadoop序列文件)基础知识与应用 上篇编程实战系列中本人介绍了基本的使用HDFS进行文件读写的方法,这一篇将承接上篇重点整理一下SequenceFile的相关知识及应用 ...
- 大数据学习笔记——Hadoop编程实战之HDFS
HDFS基本API的应用(包含IDEA的基本设置) 在上一篇博客中,本人详细地整理了如何从0搭建一个HA模式下的分布式Hadoop平台,那么,在上一篇的基础上,我们终于可以进行编程实操了,同样,在编程 ...
- 大数据学习笔记——Hadoop高可用完全分布式模式完整部署教程(包含zookeeper)
高可用模式下的Hadoop集群搭建 本篇博客将会在之前写过的Linux的完整部署的基础上进行,暂时不会涉及到伪分布式或者完全分布式模式搭建,由于HA模式涉及到的配置文件较多,维护起来也较为复杂,相信学 ...
随机推荐
- jqueryMobile 动态添加元素,展示刷新视图方法
jqueryMobile动态添加元素jqueryMobile郏高阳 jQuery Mobile的是一个很好的移动开发框架,你可能已经知道,虽然它有很多难以解决的问题,但是我相信后续版本jquery会修 ...
- Linux指令范例速查手册
linux命令繁多,命令就是AK的子弹,对上口径,百发百中! 无意发现一本介绍Linux命令的手册--->[Linux指令范例速查手册] 下载: https://pan.baidu.com/s/ ...
- Windows开机BIOS启动快捷按键
Window装系统,开机需要调整启动选项...不同的机型,进入BIOS按键不同 按键列表
- js代码实现购物车效果
页面分上下两部分,上部分是所有的数据,下部分是购物车.通过在上面选择需要处理的数据添加进到购物车,实现对购物车数据的统一处理. 需要注意的有两点:①购物车数据可删除,且不能重复添加 ②响应时间考虑,购 ...
- Navicat sqlserver2016 08001
环境: Windows10(主机是联想的) SqlServer2016 Navicat11 错误: 启动SqlServer各种服务, 端口1433 没错, Navicat连接时08001错误 分析: ...
- 【MATLAB】matlabR2010a与vs2010联合编译设置
在matlab中编译C++程序,首先要配置编译器>> mex -setupPlease choose your compiler for building external interfa ...
- IT编年史 技术生命周期起步,成长,成熟和衰退四个阶段 IT历史总结
IT编年史 最近查看了大量的正史或者野史,体会了整个IT夜发展的风气云涌,颇为激动,撰写如下. 感谢google黑板报的浪潮之巅http://googlechinablog.com/2007/07/a ...
- 使用 scp命令免登陆
多台服务器之间互相拷贝文件一般常用scp命令但是让人困扰的是还要输入密码, 能不能不输入密码直接拷贝? 所幸方法是有的,ssh服务是支持免登陆的,不过需要密钥文件 方法如下: [root@WebSer ...
- VS2010 C++环境下DLL和LIB文件的生成与调试
利用VS2010工具,调试DLL文件的方法现总结如下: 在一个解决方案中生成两个工程,假设MYDLL和MYDLG两个工程,前者是DLL工程,后者DLG调用前边的DLL工程.设置如下: 目录如下:图,本 ...
- SQL数据缓存依赖总结
以前只听过SQL server数据缓存依赖,但一直没使用,由于项目需要,才研究了一番,发现了一个很诡异的问题,竟然是一个操作顺序问题导致的. SQL server数据缓存依赖有两种实现模式,轮询模式, ...